网络编程之TIME_WAIT详解
我们了解了 TCP 四次挥手,在四次挥手的过程中,发起连接断开的一方会有一段时间处于 TIME_WAIT 的状态,你知道 TIME_WAIT 是用来做什么的么?今天我们来详细的介绍一下。
TIME_WAIT 发生的场景
如果有一天,我们发现该服务的可用性变得时好时坏,一段时间可以对外提供服务,一段时间突然又不可以。我们使用 netstat 命令查看后才发现,主机上有成千上万处于 TIME_WAIT 状态的连接。
经过层层剖析后,我们发现罪魁祸首就是 TIME_WAIT。为什么呢?我们这个应用服务需要通过发起 TCP 连接对外提供服务。每个连接会占用一个本地端口,当在高并发的情况下,TIME_WAIT 状态的连接过多,多到把本机可用的端口耗尽,应用服务对外表现的症状,就是不能正常工作了。当过了一段时间之后,处于 TIME_WAIT 的连接被系统回收并关闭后,释放出本地端口可供使用,应用服务对外表现为,可以正常工作。这样周而复始,便会出现了一会儿不可以,过一两分钟又可以正常工作的现象。
那么为什么会产生这么多的 TIME_WAIT 连接呢?这里我们就要从TCP四次挥手说起了。
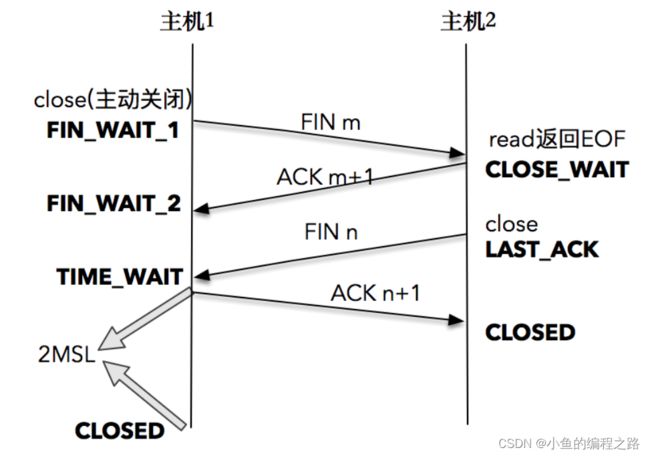
TCP 连接终止时,主机 1 先发送 FIN 报文,主机 2 进入 CLOSE_WAIT 状态,并发送一个 ACK 应答,同时,主机 2 通过 read 调用获得 EOF,并将此结果通知应用程序进行主动关闭操作,发送 FIN 报文。主机 1 在接收到 FIN 报文后发送 ACK 应答,此时主机 1 进入 TIME_WAIT 状态。
主机 1 在 TIME_WAIT 停留持续时间是固定的,是最长分节生命期 MSL(maximum segment lifetime)的两倍,一般称之为 2MSL。和大多数 BSD 派生的系统一样,Linux 系统里有一个硬编码的字段,名称为TCP_TIMEWAIT_LEN,其值为 60 秒。也就是说,Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。过了这个时间之后,主机 1 就进入 CLOSED 状态。
请大家一定要记住,,只有发起连接终止的一方会进入 TIME_WAIT 状态。
TIME_WAIT 的作用
你可能会问,为什么不直接进入 CLOSED 状态,而要停留在 TIME_WAIT 这个状态?
这要从两个方面来说。
首先,这样做是为了确保最后的 ACK 能让被动关闭方接收,从而帮助其正常关闭。
TCP 在设计的时候,做了充分的容错性设计,比如,TCP 假设报文会出错,需要重传。在这里,如果图中主机 1 的 ACK 报文没有传输成功,那么主机 2 就会重新发送 FIN 报文。
如果主机 1 没有维护 TIME_WAIT 状态,而直接进入 CLOSED 状态,它就失去了当前状态的上下文,只能回复一个 RST 操作,从而导致被动关闭方出现错误。
现在主机 1 知道自己处于 TIME_WAIT 的状态,就可以在接收到 FIN 报文之后,重新发出一个 ACK 报文,使得主机 2 可以进入正常的 CLOSED 状态。
第二个理由和连接“化身”和报文迷走有关系,为了让旧连接的重复分节在网络中自然消失。
我们知道,在网络中,经常会发生报文经过一段时间才能到达目的地的情况,产生的原因是多种多样的,如路由器重启,链路突然出现故障等。如果迷走报文到达时,发现 TCP 连接四元组(源 IP,源端口,目的 IP,目的端口)所代表的连接不复存在,那么很简单,这个报文自然丢弃。
我们考虑这样一个场景,在原连接中断后,又重新创建了一个原连接的“化身”,说是化身其实是因为这个连接和原先的连接四元组完全相同,如果迷失报文经过一段时间也到达,那么这个报文会被误认为是连接“化身”的一个 TCP 分节,这样就会对 TCP 通信产生影响。

所以,TCP 就设计出了这么一个机制,经过 2MSL 这个时间,足以让两个方向上的分组都被丢弃,使得原来连接的分组在网络中都自然消失,再出现的分组一定都是新化身所产生的。
因此,2MSL 的时间是从主机 1 接收到 FIN 后发送 ACK 开始计时的;如果在 TIME_WAIT 时间内,因为主机 1 的 ACK 没有传输到主机 2,主机 1 又接收到了主机 2 重发的 FIN 报文,那么 2MSL 时间将重新计时。道理很简单,因为 2MSL 的时间,目的是为了让旧连接的所有报文都能自然消亡,现在主机 1 重新发送了 ACK 报文,自然需要重新计时,以便防止这个 ACK 报文对新可能的连接化身造成干扰。
TIME_WAIT 的危害
过多的 TIME_WAIT 的主要危害有两种。
第一是内存资源占用,这个目前看来不是太严重,基本可以忽略。
第二是对端口资源的占用,一个 TCP 连接至少消耗一个本地端口。要知道,端口资源也是有限的,一般可以开启的端口为 32768~61000 ,也可以通过net.ipv4.ip_local_port_range指定,如果 TIME_WAIT 状态过多,会导致无法创建新连接。这个也是我们在一开始讲到的那个例子。
如何优化 TIME_WAIT?
在高并发的情况下,如果我们想对 TIME_WAIT 做一些优化,来解决我们一开始提到的例子,该如何办呢?
net.ipv4.tcp_max_tw_buckets
一个暴力的方法是通过 sysctl 命令,将系统值调小。这个值默认为 18000,当系统中处于 TIME_WAIT 的连接一旦超过这个值时,系统就会将所有的 TIME_WAIT 连接状态重置,并且只打印出警告信息。这个方法过于暴力,而且治标不治本,带来的问题远比解决的问题多,不推荐使用。
调低 TCP_TIMEWAIT_LEN,重新编译系统
这个方法是一个不错的方法,缺点是需要“一点”内核方面的知识,能够重新编译内核。我想这个不是大多数人能接受的方式。
SO_LINGER 的设置
我们可以通过设置套接字选项,来设置调用 close 或者 shutdown 关闭连接时的行为。
int setsockopt(int sockfd, int level, int optname, const void *optval,
socklen_t optlen);struct linger {
int l_onoff; /* 0=off, nonzero=on */
int l_linger; /* linger time, POSIX specifies units as seconds */
}设置 linger 参数有几种可能:
- 如果
l_onoff为 0,那么关闭本选项。l_linger的值被忽略,这对应了默认行为,close 或 shutdown 立即返回。如果在套接字发送缓冲区中有数据残留,系统会将试着把这些数据发送出去。- 如果
l_onoff为非 0, 且l_linger值也为 0,那么调用 close 后,会立该发送一个 RST 标志给对端,该 TCP 连接将跳过四次挥手,也就跳过了 TIME_WAIT 状态,直接关闭。这种关闭的方式称为“强行关闭”。 在这种情况下,排队数据不会被发送,被动关闭方也不知道对端已经彻底断开。只有当被动关闭方正阻塞在recv()调用上时,接受到 RST 时,会立刻得到一个“connet reset by peer”的异常。- 如果
l_onoff为非 0, 且l_linger的值也非 0,那么调用 close 后,调用 close 的线程就将阻塞,直到数据被发送出去,或者设置的l_linger计时时间到。
struct linger so_linger;
so_linger.l_onoff = 1;
so_linger.l_linger = 0;
setsockopt(s,SOL_SOCKET,SO_LINGER, &so_linger,sizeof(so_linger));总结
在今天的内容里,我讲了 TCP 的四次挥手,重点对 TIME_WAIT 的产生、作用以及优化进行了讲解,你需要记住以下三点:
- TIME_WAIT 的引入是为了让 TCP 报文得以自然消失,同时为了让被动关闭方能够正常关闭;
- 不要试图使用
SO_LINGER设置套接字选项,跳过 TIME_WAIT;- 现代 Linux 系统引入了更安全可控的方案,可以帮助我们尽可能地复用 TIME_WAIT 状态的连接。