Fast R-CNN论文解析
文章目录
- 一、介绍
- 二、拟解决的关键问题
- 三、Fast R-CNN结构以及训练算法
-
- 1. 整体结构
- 2. ROI Pooling Layer
- 3. Pre-Trained Network
- 4. 目标检测任务的微调
- 5. 尺度不变性
- 四、总结
- 五、参考文献
本篇博客将要解析的论文是Fast R-CNN,论文地址为: https://arxiv.org/abs/1504.08083
一、介绍
本文是Ross Girshick于2015年发表的一篇文章,该论文提出了Fast R-CNN模型,改进了R-CNN系列的算法流程和网络结构,在SPPNet的基础上,继续提高了目标检测模型的运算速度和准确率。
二、拟解决的关键问题
不同于分类任务,目标检测算法还需要获取物体的精准定位信息,目前准确率较高的几种目标检测算法如R-CNN、SPPNet等大都是基于区域推荐算法来实现以上目标,但这种方式目前也存在一些问题:
- 大量的推荐框会被产生并处理——耗时耗内存
- 推荐框只能提供粗略定位,仍然需要再次处理去获得精确定位——训练流程较为复杂
下面简单分析一下R-CNN以及SPPNet的主要缺陷:
- R-CNN
-
训练过程是一个多阶段的流程
- 使用log loss在推荐框上微调一个卷积网络
- 将卷积神经网络提取到的特征送入SVM中训练一个SVM分类器
- Bounding Box Regression
-
训练过程既耗时又耗空间
对于SVM和Regressor的训练过程,特征是每张图片的所有推荐框提取得到的特征,并事先保存在硬盘中,训练时再重新读取
-
目标检测慢
由于测试时需要为每张图片的每个检测框提取特征,导致运行很慢
- SPPNet
与R-CNN类似,仍然是一个多阶段的流程:提取特征,使用log loss微调网络,训练SVM,应用Bounding Box Regressor。不同于R-CNN,SPPNet的微调算法不能更新SPP Layer之前的卷积层,这个部分内容后续再做更为详细地阐述。
R-CNN慢的重要原因在于:其没有共享权重,而是为每个推荐框运行一次卷积网络。而SPPNet通过共享权重则是加快了运行速度:SPPNet为整张图片提取一个卷积特征图,然后使用从共享特征图中提取的固定长度的特征完成分类。但其微调算法限制了检测准确率。
Fast R-CNN则是提出了一个Single-Stage训练算法,可以同时学习去分类推荐框以及优化推荐框的空间位置,并采用多任务学习的方式,同时提升子任务——分类和回归的准确率。
三、Fast R-CNN结构以及训练算法
1. 整体结构
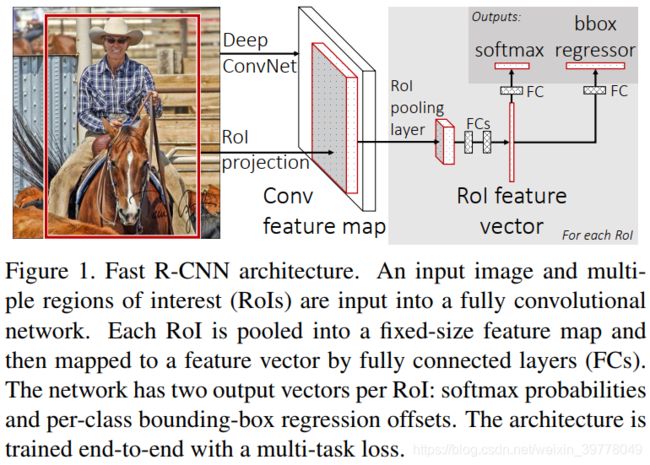
输入:一整张图片以及该张图片对应的一系列的推荐框
网络:
- 一系列的卷积层和最大池化层,用于产生一个卷积特征图
- 针对每个推荐框,使用ROI Pooling Layer从特征图中提取一个固定长度的特征向量
- 送入一系列的全连接层,并产生两路分支:
-
1. 分类头:产生一个softmax概率(K + 1),用于推荐框的分类 2. 回归头:为每个类别(K)产生一个四维向量,用于推荐框位置的修正
2. ROI Pooling Layer
ROI Pooling Layer使用Max Pooling将任何大小的ROI都转化为一个具有固定空间尺度H * W的特征图,例如7 * 7,H和W是一个与ROI无关的超参数,每个ROI通过四个参数定义 ( r , c , h , w ) (r,c,h,w) (r,c,h,w),其中 ( r , c ) (r,c) (r,c)是左上角坐标, h h h和 w w w是高度和宽度。
ROI pooling将h*w的ROI分为H * W的格子,每个格子大小大致为 h / H ∗ w / W h/H * w/W h/H∗w/W,然后再使用Max Pooling对每个格子进行池化。各个通道的Max Pooling是独立的。ROI Pooling是Spatial Pyramid Pooling仅具有一层金字塔层级的一个特例,至于SPP具体情况,可以参考我的另一篇博客:SPPNet论文解析。
ROI Pooling Layer的反向传播
这个部分可以参考这篇博客以及这份PPT。其实ROI Pooling与正常的Max Pooling的反向传播没有太大的区别,但ROI Pooling时,某个像素可能同时是多个ROI中某个池化window的最大值,此时,对于该像素反向传播计算梯度时,需要累加多个window对应的梯度值。
3. Pre-Trained Network
每个预训练网络需要经过以下三个变换,以适应Fast R-CNN的需求:
- 将最后一个池化层改为ROI Pooling Layer
- 将最后的全连接层和softmax层改为两个同级全连接层,用于分类和回归
- 修改网络输入为一系列的图片以及其对应的ROI
4. 目标检测任务的微调
为什么SPPNet中位于SPP Layer以下的卷积层无法进行微调?

论文中给出的理由是SPP Layer在训练时,反向传播是非常低效的。
关键问题在于RoI-centric sampling和image-centric sampling的区别,知乎上也有大神给出了更为详细的解释。在此我结合我自己的理解,再做一次更为详细地阐述。
下面先简单回顾一下R-CNN的微调过程:

R-CNN在微调过程中送入的是图片域的RoIs,因此,和正常的前传、反传的流程一致,可以完成对卷积层和全连接层的微调。
SPPNet的微调流程:
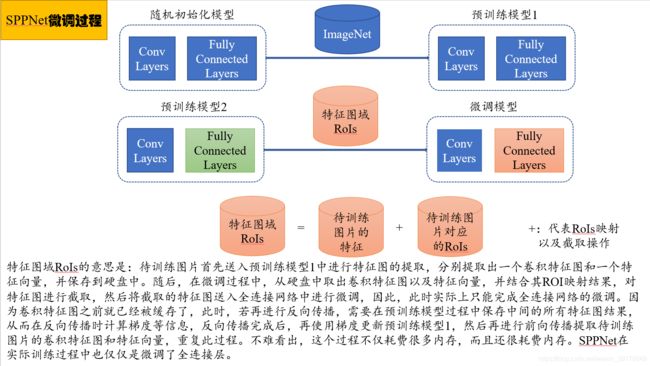
与R-CNN不同的是,SPPNet在微调时,需要首先获取其特征图,然后再将RoIs投影至特征图上,最后再进行微调。因此,特征图的获取需要率先完成并缓存至硬盘。在微调过程中,由于特征图已经获取,因此,实际上微调过程中预训练模型2中的卷积层并不需要进行前向传播,因此,也就无法进行反向传播。此时,若想进行反向传播,需要在预训练模型1中进行。具体内容在图4中我有给出具体说明。简单说来就是,SPPNet微调时使用的RoIs可能来自于很多张图片,例如N,此时若要进行反向传播,就需要运行N次预训练模型1,并保存中间所有的权重值,以进行后续反向传播的梯度计算,当N很大时,计算量和内存消耗量都非常大。
为了解决这一问题,Fast R-CNN采取的是Image-Centric Sampling这种采样策略。
首先采样N张图片,然后再每张图片上采样R/N个RoIs。来自同一图片的ROI在前向传播和反向传播中就可以共享计算和内存,从而能够一定程度上提升速度(提升R/N倍)。
这种策略可能带来一个担忧:可能会导致训练收敛变慢,因为来自同一张图片的ROI可能高度相关,但实验过程中没有出现这种情况(N=2,R=128)。
除了这种采样策略,Fast R-CNN还使用了一种单阶段的训练流程:同时优化一个softmax分类器和一个bounding box回归器。
多任务loss中回归器的loss采用的是一个 L 1 L o s s L_1 Loss L1Loss。相较于 L 2 l o s s L_2 loss L2loss,由于 L 2 L o s s L_2 Loss L2Loss是没有边界的,可能会导致梯度过大,对学习率的细心设置要求比较高。而 L 1 L o s s L_1 Loss L1Loss就更为鲁棒,对异常值也没有那么敏感。
5. 尺度不变性
- 暴力习得
在训练和测试过程中,每张图片经过预处理后变为一个特定的尺寸,网络需要从训练数据中自行学习尺度不变性 - 图像金字塔
训练阶段:每次采样图片时,会随机选择一个金字塔尺度
测试阶段:为每个ROI从多个尺度中挑选某个尺度图片用于测试,在该尺度下变换后的ROI的尺寸最接近某个固定尺寸如224*224
四、总结
Fast R-CNN使得目标检测算法中除了候选框产生的部分,已经成为了一个可以完整训练的简单流程,多任务学习的思想也在后续大部分算法中被保留下来,并命名为head。目前还存在的问题就是推荐框的产生还是用的是Selective Search等传统方法,无法进行端到端的训练和学习,而后续的Faster R-CNN则进一步解决了这个问题。
最后附上一些优秀参考博客。
五、参考文献
[1] https://zhuanlan.zhihu.com/p/59692298
[2] https://blog.csdn.net/xunan003/article/details/86597954
[3] http://www.robots.ox.ac.uk/~tvg/publications/talks/fast-rcnn-slides.pdf
[4] http://www.dengfanxin.cn/?p=423