python小说爬虫练习
本篇文章主要用于记录爬虫练习,所以具体网址将不显示(如果真的出现没有完全打码的情况请联系我,谢谢!),希望大家支持正版!
大纲
- 需求描述
- 最终效果展示
- 步骤拆解
-
- 1. 获取章节信息(URL及名称)
-
- 1.1 采用requests模块获取html返回内容
- 1.2 采用bs4中BeautifulSoup模块解析返回文本
- 1.3. 对list进行解析,转化为目录的字典列表
- 2. 获取每章节文本内容
-
- 2.1 循环获取指定章节文本内容,加入整个list中
- 2.2 利用time.sleep,增加请求失败重试功能
- 3. 生成txt文本
- 4. 重复工作模块化
- 代码展示
- 后续进阶(进行中)
需求描述
通过爬取盗版小说网站数据,获取某本书的章节目录信息及指定章节的文本内容,生成.txt文件。
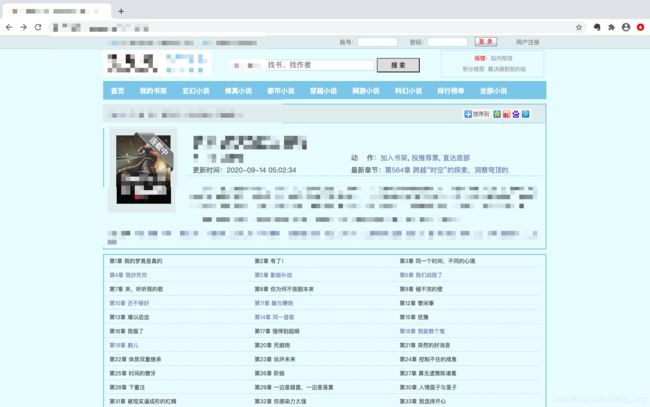
最终效果展示
选择指定章节生成txt文本,可以在手机阅读器查看。

步骤拆解
1. 获取章节信息(URL及名称)
1.1 采用requests模块获取html返回内容
# -*- coding: utf-8 -*-
import requests
import random
url = "http://********/"#说好的不给你们看哦
headers1 = [{
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"},
{
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36 "}]
headers=random.choice(headers1)#随机选择某一headers,减少反爬虫可能
r = requests.get(url, headers=headers)
r.encoding = "utf-8" #解决乱码问题
r.text
输出结果:

1.2 采用bs4中BeautifulSoup模块解析返回文本
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser')
soup
输出结果:

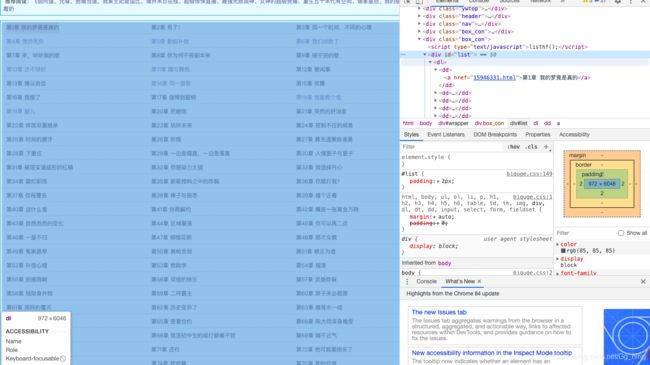
通过Chrome检查功能,我们可以确认目录菜单在该网页body id='list" 的布局处。
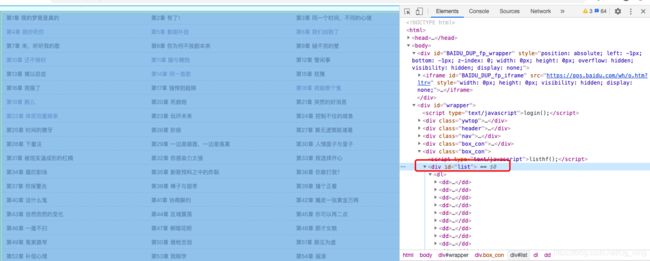
list12 = soup.body.find_all("div", id="list")
list12
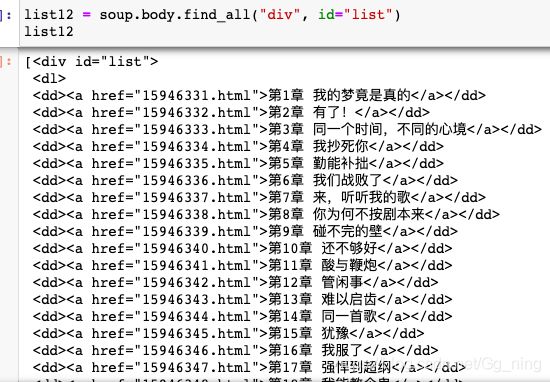
输出为list格式,只有一个元素。
1.3. 对list进行解析,转化为目录的字典列表
import re
#转化为str格式,并删除无效内容
list13 = str(list12[0]).replace('', '').replace(''
, '').replace('', '').replace('', '')
#以 = list13.split(')
lenth = len(list1)
title_list=[]
nn = 1
for n in range(1, lenth):
dict1 = {
}
place= list1[n].find('">')
url1 = list1[n][0:place]
#有些章节以"正文 "开头,需要去掉,方便下一步排除非正文部分
title = list1[n][place+2:-10].replace("正文 ","")
#排除非正文的部分,re.S:"."代表全部
if re.match("^第.{0,6}(章|张|篇)", title, re.S) is not None