容器云系列之Docker Swarm集群管理
Docker Swarm是Docker的集群管理工具,它提供了标准的Docker API,所有任何已经与Docker守护程序通信的工具都可以使用Swarm轻松地扩展到多个主机。支持的工具包括Dokku、Docker Compose、Docker Machine和Jenkins等。
1、Swarm原理
Swarm集群由多个运行在swarm mode的docker主机组成,这些docker主机分为管理节点(manager)和工作节点(work node)。Swarm mananger节点负责整个集群的管理工作包括集群配置、服务管理等;Work node节点主要负责运行相应的服务来执行任务(task)。
Swarm集群和standalone部署的docker有以下优点:1)在线修改Service的配置,包括networks和volumes,不需要重启docker服务;2)Swarm集群时候,可以将其它standalone模式的docker主机加入到Swarm集群。
Swarm中有几个基本概念,包括nodes、Service和tasks以及load balancing:
- Node
Node是加入到Swarm集群中的Docker实例,也可以认为是一个docker节点,包括管理节点和工作节点。在部署应用到Swarm集群的时候,会向管理节点提交service定义,管理节点会将这些这些work也就是tasks分发到work节点中。Work节点接收并执行管理节点分配的任务,work节点也会将当前tasks的状态通知到管理节点以维护节点的状态信息。
- Service and tasks
Service是manage和work节点上执行的task的定义,当创建service的时候可以指定使用哪个container image以及执行的命令。在replicated service模式下,swarm管理节点会根据desired state中设置的scale分发replica tasks;对于global service模式,swarm集群会向每个可用的节点运行tasks。
- Load balancing
Swarm集群使用ingress loading balancing提供集群服务,Swarm集群会自动为service分配PublishedPort,默认使用30000-32767范围。
1.1 Node节点
Swarm中node节点包括manage管理节点和work工作节点。
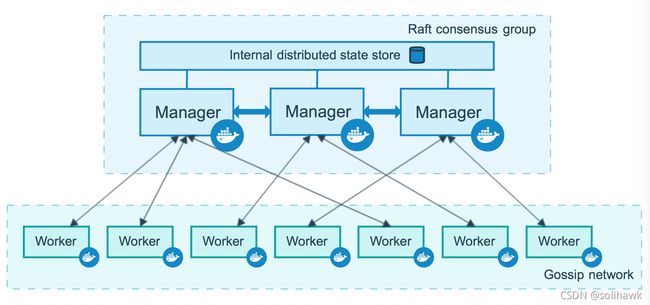
- Manager node
Manager使用raft算法维护整个集群和运行的service的internal状态,主要完成以下tasks:
- 维护cluster state
- scheduling服务
- service swarm mode集群服务
Docker建议使用基数manager节点以保证可用性,最大使用7个manager节点。
- Work node
Work节点是容器实际运行的实例,在Swarm集群中必须存在manager节点。默认情况下manager节点也是work节点,但在多节点的Swarm集群中为了避免调度任务运行在manager节点,可以将manager节点设置为Drain模式,这样调度不会将任务分配到Drain模式,只会在Active模式的节点上分配任务。
- Role变化
通过运行命令docker node promote可以将worker节点变为manager节点,同样也可以将manager节点转换为worker节点。
1.2 Service
当Service部署到Swarm集群的时候,swarm管理节点会将service定义作为service的理想状态,然后会将service调度到集群的节点上,以一个或多个tasks执行,这些nodes上运行的tasks之间是相互独立的。

如图所示,在三个HTTP listener实例中实现负载均衡,service中有三个replica tasks,每个实例是Swarm集群中的一个task。Task是Swarm集群中调度的最小单元,当创建或更新service时候给定了desired state,集群会调度tasks来实现这种理想状态。Task是一种单向机制,在它的整个周期过程中会完成一系列的状态,如assigned、prepared和running等。如果tasks失败了,集群会remove这个tasks并创建新的tasks来替代。
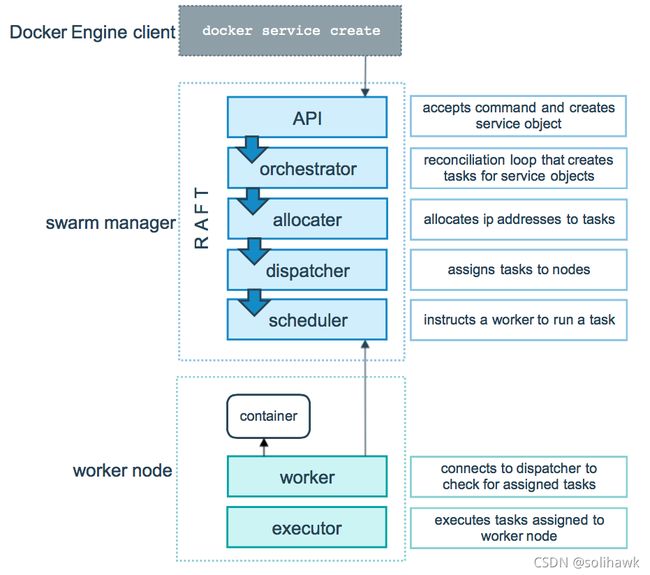
上图展示了Swarm集群中service创建请求并将tasks调度到worker节点的过程:
-
Client发送创建service请求
-
Swarm manager节点
a) API:接收到命令并创建service
b) Orchestrator:协调者为service循环创建tasks
c) Allocater:为tasks分配ip地址
d) Dispatcher:将tasks分配到node
e) Scheduler:引导worker节点运行tasks -
Swarm Work节点
a) Worker:连接到dispatcher并检查分配的tasks
b) Executor:执行分配到worker节点的tasks
1.3 Swarm task状态
Docker创建service运行tasks,service是desired state和work task的描述。在Swarm集群中work按照以下顺序执行:
- 使用docker service create创建service
- Request进入Docker manager node
- Docker manager节点将service调度到指定的node上运行
- 每个service可以启动多个tasks
- 每个tasks有一个生命周期,task状态如NEW、PENDING和COMPLETE
Tasks是执行的单元,当一个tasks停止的时候,它将不再执行,并且会被新的tasks替代。在整个运行周期中,Tasks会依次进入以下状态:
| 状态 | 描述 |
|---|---|
| NEW | Tasks初始化 |
| PENDING | Tasks分配资源 |
| ASSIGNED | Docker将tasks分配到node |
| ACCEPTED | Worker node接受tasks,如果reject,状态会变成REJECTED. |
| PREPARING | Docker正在准备task |
| STARTING | Docker启动the task |
| RUNNING | Task正在执行 |
| COMPLETE | Task成功结束 |
| FAILED | Task出错 |
| SHUTDOWN | Docker请求将task shut down. |
| REJECTED | Worker node reject task |
| ORPHANED | Node宕掉时间过长 |
| REMOVE | Task没有结束但是对应的service已经被remove |
使用命令docker service ps 可以获得task的状态:
docker@swarm-manager:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
j8txqvg8t73c helloworld.1 alpine:latest swarm-manager Running Running 51 seconds ago
1.4 Swarm mode中的Raft算法
Docker在Swarm模式下,管理节点应用Raft Consensus算法来维护集群的全局状态,这样可以保证所有的管理节点处于相同的一致性状态。集群中的一致性状态可以保证在管理节点出现故障的时候,其它的管理节点能够接管任务并恢复到稳定的状态。Raft算法可以忍受(N-1)/2的节点故障,并且需要集群中多数派(N/2+1)节点选举同意。比如在5个管理节点的集群中,如果3个节点不可用,则系统不能接收任何新的请求,但是当前正在运行的tasks可以继续工作。
1.5 Service Placement
Swarm service提供了不同的方法来控制不同节点上service的scale和placement:
- 配置Service运行的replicas
- 配置CPU和内存
- Placement constraints限制service运行在某些特定的节点
- Placement preferences为节点设置标签,并将服务根据算法分发到这些节点上
- REPLICATED OR GLOBAL SERVICES
Swarm有两种service模式:replicated和global,replicated模式会根据指定的任务副本分发到节点上,global模式会在每个可用的节点上分发任务。通过–mode标签可以控制service的模式,默认为replicated模式。
docker service create --name my_web --replicas 3 nginx
docker service create --name myservice --mode global alpine top
- 限制service的CPU和内存使用
使用–reserve-memory或–reserve-cpu关键字可以限制service的CPU和内存使用,如果没有节点满足条件,则service会处于pending状态。如果service使用的内存超过节点可用的内存,会出现内存溢出OOME。
- Placement Constraints
使用placement constraints可以限制service分发的节点,如下service只会运行在region标签为east的节点上,如果该类标签的节点不存在,tasks会处于pending状态。
docker service create \
--name my-nginx \
--replicas 5 \
--constraint node.labels.region==east \
nginx
节点的标签可在Swarm中通过命令“docker node update --label-add”添加
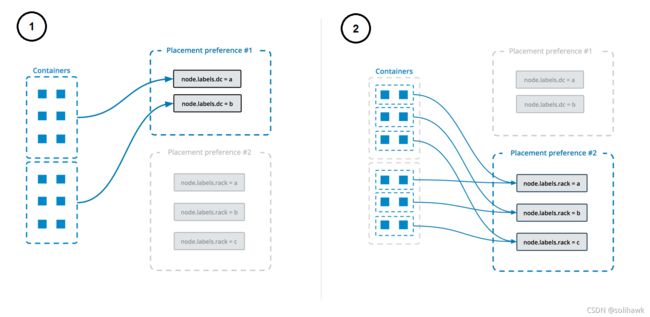
- Placement Preferences
Placement preference是根据算法将任务分发到目标节点上,如下会根据“datacenter”标签来分发服务:
$ docker service create \
--replicas 9 \
--name redis_2 \
--placement-pref 'spread=node.labels.datacenter' \
redis:3.0.6
创建service时候可以指定多个placement references,任务会根据定义的顺序进行分发。下图描述了placement references的原理:
2、Swarm使用
以下案例环境是在Centos环境上通过docker machine和virtualbox创建了虚拟机,也可以直接在Centos主机上通过“docker swarm init”命令创建swarm管理节点以及“docker swarm join”命令创建swarm工作节点。
2.1 创建swarm集群管理节点(manager)
1)创建swarm管理节点swarm-manager:
[root@tango-01 ~]# docker-machine create -d virtualbox swarm-manager
Running pre-create checks...
(swarm-manager) Unable to get the latest Boot2Docker ISO release version: Get https://api.github.com/repos/boot2docker/boot2docker/releases/latest: read tcp 192.168.112.10:45354->54.169.195.247:443: read: connection reset by peer
Creating machine...
(swarm-manager) Unable to get the latest Boot2Docker ISO release version: Get https://api.github.com/repos/boot2docker/boot2docker/releases/latest: read tcp 192.168.112.10:45356->54.169.195.247:443: read: connection reset by peer
(swarm-manager) Copying /root/.docker/machine/cache/boot2docker.iso to /root/.docker/machine/machines/swarm-manager/boot2docker.iso...
(swarm-manager) Creating VirtualBox VM...
(swarm-manager) Creating SSH key...
(swarm-manager) Starting the VM...
(swarm-manager) Check network to re-create if needed...
(swarm-manager) Waiting for an IP...
Waiting for machine to be running, this may take a few minutes...
Detecting operating system of created instance...
Waiting for SSH to be available...
Detecting the provisioner...
Provisioning with boot2docker...
Copying certs to the local machine directory...
Copying certs to the remote machine...
Setting Docker configuration on the remote daemon...
Checking connection to Docker...
Docker is up and running!
To see how to connect your Docker Client to the Docker Engine running on this virtual machine, run: docker-machine env swarm-manager
[root@tango-01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
swarm-manager - virtualbox Running tcp://192.168.99.101:2376 v19.03.12
2)初始化swarm集群,进行初始化的这台机器,就是集群的管理节点
[root@tango-01 ~]# docker-machine ssh swarm-manager
( '>')
/) TC (\ Core is distributed with ABSOLUTELY NO WARRANTY.
(/-_--_-\) www.tinycorelinux.net
docker@swarm-manager:~$ docker swarm init --advertise-addr 192.168.99.101
Swarm initialized: current node (jlcr3zi9dc38ihljnwwp10cwe) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1pdftuve6z8jqub8pgw5p6mrpl07dinkd7p8tgeqd0filf1uw2-91z7ukqoxeb2f25tgncdz3gqf 192.168.99.101:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
需要把以下这行复制出来,在增加工作节点时会用到:
docker swarm join --token SWMTKN-1-1pdftuve6z8jqub8pgw5p6mrpl07dinkd7p8tgeqd0filf1uw2-91z7ukqoxeb2f25tgncdz3gqf 192.168.99.101:2377
2.2 创建swarm集群工作节点(worker)
1)创建两台工作节点swarm-worker1 和 swarm-worker2 :
[root@tango-01 ~]# docker-machine create -d virtualbox swarm-worker1
[root@tango-01 ~]# docker-machine create -d virtualbox swarm-worker2
[root@tango-01 ~]# docker-machine ls
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
swarm-manager - virtualbox Running tcp://192.168.99.101:2376 v19.03.12
swarm-worker1 - virtualbox Running tcp://192.168.99.102:2376 v19.03.12
swarm-worker2 - virtualbox Running tcp://192.168.99.103:2376 v19.03.12
2)添加节点到Swarm集群
分别进入swarm-worker1 和 swarm-worker2,指定添加至上一步中创建的集群
[root@tango-01 ~]# docker-machine ssh swarm-worker1
( '>')
/) TC (\ Core is distributed with ABSOLUTELY NO WARRANTY.
(/-_--_-\) www.tinycorelinux.net
docker@swarm-worker1:~$ docker swarm join --token SWMTKN-1-1pdftuve6z8jqub8pgw5p6mrpl07dinkd7p8tgeqd0filf1uw2-91z7ukqoxeb2f25tgncdz3gqf 192.168.99.101:2377
This node joined a swarm as a worker.
docker@swarm-worker1:~$ exit
logout
[root@tango-01 ~]# docker-machine ssh swarm-worker2
( '>')
/) TC (\ Core is distributed with ABSOLUTELY NO WARRANTY.
(/-_--_-\) www.tinycorelinux.net
docker@swarm-worker2:~$ docker swarm join --token SWMTKN-1-1pdftuve6z8jqub8pgw5p6mrpl07dinkd7p8tgeqd0filf1uw2-91z7ukqoxeb2f25tgncdz3gqf 192.168.99.101:2377
This node joined a swarm as a worker.
docker@swarm-worker2:~$
出现信息“This node joined a swarm as a worker.”表示添加成功

2.3 查看集群信息
进入管理节点swarm-manager,执行docker info 可以查看当前集群的信息:
[root@tango-01 ~]# docker-machine ssh swarm-manager
( '>')
/) TC (\ Core is distributed with ABSOLUTELY NO WARRANTY.
(/-_--_-\) www.tinycorelinux.net
docker@swarm-manager:~$ docker info
……
Swarm: active
NodeID: jlcr3zi9dc38ihljnwwp10cwe
Is Manager: true
ClusterID: 8f98onsca8dnl45yo5cd06510
Managers: 1
Nodes: 3
Default Address Pool: 10.0.0.0/8
SubnetSize: 24
Data Path Port: 4789
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Number of Old Snapshots to Retain: 0
Heartbeat Tick: 1
Election Tick: 10
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Force Rotate: 0
Autolock Managers: false
Root Rotation In Progress: false
Node Address: 192.168.99.101
Manager Addresses:
192.168.99.101:2377
……
Swarm信息中可以知道当前运行的集群中有三个节点,其中有一个是管理节点。通过docker node ls可以看到节点信息:
docker@swarm-manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe * swarm-manager Ready Active Leader 19.03.12
93hi5m0i0lpf1ier4ymemv8of swarm-worker1 Ready Active 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
2.4 部署服务到集群中
在管理节点上为其中一个工作节点创建一个名为 helloworld 的服务,这里是随机指派给一个工作节点:
docker@swarm-manager:~$ docker service create --replicas 1 --name helloworld alpine ping docker.com
jbg09xbutgjt6tyb2gu1xz368
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
2.5 查看服务部署情况
查看 helloworld 服务运行在哪个节点上,可以看到目前是在swarm-manager 节点:
docker@swarm-manager:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
j8txqvg8t73c helloworld.1 alpine:latest swarm-manager Running Running 51 seconds ago
查看 helloworld 部署的具体信息:
docker@swarm-manager:~$ docker service inspect --pretty helloworld
ID: jbg09xbutgjt6tyb2gu1xz368
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:c0e9560cda118f9ec63ddefb4a173a2b2a0347082d7dff7dc14272e7841a5b5a
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vip
2.6 扩展集群服务
将上述的 helloworld 服务扩展到2个节点
docker@swarm-manager:~$ docker service scale helloworld=2
helloworld scaled to 2
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
可以看到helloworld服务已经从一个节点,扩展到两个节点
docker@swarm-manager:~$ docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
j8txqvg8t73c helloworld.1 alpine:latest swarm-manager Running Running 3 hours ago
r28ytdtsony1 helloworld.2 alpine:latest swarm-worker1 Running Running about a minute ago
2.7 删除服务
使用docker service rm删除服务
docker@swarm-manager:~$ docker service rm helloworld
helloworld
docker@swarm-manager:~$ docker service ps helloworld
no such service: helloworld
docker@swarm-manager:~$
2.8 滚动升级服务
以redis版本如何滚动升级至更高版本为例
1)创建一个 3.0.6 版本的 redis
docker@swarm-manager:~$ docker service create --replicas 1 --name redis --update-delay 10s redis:3.0.6
eqlobo3vwbxatb0zdsb1l5up2
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
docker@swarm-manager:~$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
2u248hxu23qr redis.1 redis:3.0.6 swarm-worker2 Running Running 2 minutes ago
2)滚动升级 redis
docker@swarm-manager:~$ docker service update --image redis:3.0.7 redis
redis
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
docker@swarm-manager:~$ docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
mve6j6um9knl redis.1 redis:3.0.7 swarm-worker1 Running Running 22 seconds ago
2u248hxu23qr \_ redis.1 redis:3.0.6 swarm-worker2 Shutdown Shutdown 45 seconds ago
以上信息可以知道redis的版本已经从3.0.6升级到了3.0.7,说明服务已经升级成功。
2.9 停止某个节点接收新的任务
1)查看所有的节点
docker@swarm-manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe * swarm-manager Ready Active Leader 19.03.12
93hi5m0i0lpf1ier4ymemv8of swarm-worker1 Ready Active 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
可以看到目前所有的节点都是 Active, 可以接收新的任务分配。
2)停止节点swarm-manager
docker@swarm-manager:~$ docker node update --availability drain swarm-manager
swarm-manager
docker@swarm-manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe * swarm-manager Ready Drain Leader 19.03.12
93hi5m0i0lpf1ier4ymemv8of swarm-worker1 Ready Active 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
注意:swarm-manager状态变为Drain状态,不会影响到集群的服务,只是swarm-manager节点不再接收新的任务,集群的负载能力有所下降。
3)可以通过以下命令重新激活节点
docker@swarm-manager:~$ docker node update --availability active swarm-manager
swarm-manager
docker@swarm-manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe * swarm-manager Ready Active Leader 19.03.12
93hi5m0i0lpf1ier4ymemv8of swarm-worker1 Ready Active 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
2.10 节点的升级和降级
1)使用命令docker node promote可以将worker节点升级为manager节点
docker@swarm-manager:~$ docker node promote swarm-worker1
Node swarm-worker1 promoted to a manager in the swarm.
docker@swarm-manager:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe * swarm-manager Ready Active Leader 19.03.12
93hi5m0i0lpf1ier4ymemv8of swarm-worker1 Ready Active Reachable 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
状态Reachable表示参与到Raft仲裁算法的管理者节点,当管理节点不可用的时候,该节点有资格被选举为管理节点。
2)使用命令docker node demote可以将manager节点降级为worker节点
docker@swarm-manager:~$ docker node demote swarm-manager
Manager swarm-manager demoted in the swarm.
docker@swarm-manager:~$ docker node ls
Error response from daemon: This node is not a swarm manager. Worker nodes can't be used to view or modify cluster state. Please run this command on a manager node or promote the current node to a manager.
切换到swarm-worker1节点,看到manager管理节点已经发生变化
[root@tango-01 ~]# docker-machine ssh swarm-worker1
( '>')
/) TC (\ Core is distributed with ABSOLUTELY NO WARRANTY.
(/-_--_-\) www.tinycorelinux.net
docker@swarm-worker1:~$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
jlcr3zi9dc38ihljnwwp10cwe swarm-manager Ready Active 19.03.12
93hi5m0i0lpf1ier4ymemv8of * swarm-worker1 Ready Active Leader 19.03.12
5eqml7demkoxogrc9p2emgzfw swarm-worker2 Ready Active 19.03.12
2.11 Swarm集群备份恢复
- 备份Swarm集群
- 如果Swarm开启了auto-lock,需要unlock key从backup中恢复swarm
- 停止管理节点
- 备份/var/lib/docker/swarm整个目录
- 重启管理节点
- 恢复Swarm集群
- 在目标主机关闭docker
- 将Swarm节点的/var/lib/docker/swarm目录移除
- 恢复/var/lib/docker/swarm目录的内容
- 在新的节点启动Swarm,使用如下命令重新初始化swarm集群,–force-new-cluster命令执行后Swarm变成只有manager节点的单节点Swarm集群
docker swarm init --force-new-cluster
- 检查Swarm节点的状态
- 添加manage节点和worker节点
参考资料:
- https://docs.docker.com/engine/swarm/
- http://thesecretlivesofdata.com/raft/
转载请注明原文地址:https://blog.csdn.net/solihawk/article/details/121581187
文章会同步在公众号“牧羊人的方向”更新,感兴趣的可以关注公众号,谢谢!
