为什么基于DNS的全局负载均衡(GSLB)不起作用?
Why DNS Based Global Server Load Balancing (GSLB) Doesn’t Work
序言
弗雷德:乔,我要去赶一班飞机,从好莱坞到洛杉矶国际机场需要多长时间?
乔:恩。。。这取决于你走哪条路。
弗雷德:恩。。。我觉得我应该走高速公路,对吧?
乔:好吧,这是一个技术性问题,我能回答它。如果以60km/h的速度,走高速需要20分钟。
弗雷德:好的,谢啦。
(费雷德登机前一小时去了罗迪欧大道购物,然后在去洛杉矶国际机场的路上堵了两个小时,错过了航班。)
弗雷德:(在电话里)乔,交通太糟糕了,我错过了我的航班!,你说过路程只需要20分钟!
乔:噢,你没有问在交通拥堵的情况下需要多长时间啊。
弗雷德:每天这个时间段交通都很糟糕吗?
乔:你在开玩笑吗?交通一直很糟糕,这可是洛杉矶!
一个问题的答案在给定的条件下可能是正确的,但是如果答案忽略已知的细节,那就失去了讨论的意义。也许作为技术人员我们很希望每一个问题都有解决方案,因此有时候我们忽略了最显而易见的东西。也许有太多细节需要考虑会让我们犯糊涂。抑或有些细节过一会我们就忘记关注它了。
摘录
基于DNS的全局负载均衡(GSLB)解决方案是为了提供互联网DNS服务以及标准DNS服务之外的其他功能与特性。本文阐述了大多数互联网服务,比HTTP,HTTPS,FTP,流媒体,和其他基于B/S架构的应用程序或协议,使用GSLB特性时会产生的问题。此时我本应该加上“如果GSLB能够同时增强B/S架构互联网服务的高可用性”,但是我没有,因为人们总是预期GSLB解决方案可以很好的部署高可用。这是“显而易见”的。
THE Punch line
在DNS 响应中返回多个A记录,是GSLB高可用部署的最佳实践1,但是返回多个A记录会从某种程度上影响GSLB的负载均衡特性(比如流量控制或站点选择算法)。因此全局负载均衡(或多站点流量控制)的实际价值是值得怀疑的(见 为什么基于DNS的全局负载均衡(GSLB)不起作用? II)。人们必须在高可用和负载均衡之间做出妥协。下文会做出技术性的解释。
GSLB的根本目标
多站点部署互联网网站增强高可用性是无法争辩的,如果灾难性事件导致一个站点不可用,其他站点必须能够接替处理用户的请求,这样事务方可持续。下面给出一个例子,服务器站点分别部署在洛杉矶和纽约:

互联网连接失效,断电事故、SLB设备故障、Dos攻击或者灾难性事件都会造成整个站点停止服务,GSLB设备必须检测到故障并且将请求路由到其余的站点,以保证客户端请求得到响应,事务可以继续。
DNS 解析
出于完整性考虑,这节回顾一下使用GSLB的DNS解析过程。如果您是GSLB的专家可以跳过这一部分。下图展示了客户端解析全域名(FQDN)www.trapster.net的 的步骤

站点A在洛杉矶,使用虚IP 1.1.1.1。站点B在纽约城,使用虚IP 2.2.2.2
。GSLB设备作为www.trapster.net 的权威名字服务器。当DNS请求到达GSLB时,GLSB负责决定返回 1.1.1.1 或 2.2.2.2。
1)边缘解析者(运行在客户端PC上的软件程序)向本地DNS发起解析请求,在这个例子中,“本地DNS”指的是客户端在佐治亚州亚特兰大的互联网提供商(ISP)的DNS服务器。客户端要么收到DNS的解析结果,要么收到错误消息。这种查询叫做“递归”查询。注:边缘解析者不支持在互联网上“挖掘”查询出结果,这是DNS服务器的工作。
2)客户端的本地DNS服务器为客户端代理“迭代”查询,向根域名服务器查询,并最终查询到www.trapster.net 的权威名字服务器。在本例中GSLB做为权威的名字服务器。
3)GSLB同每个站点的软件或设备之间运行某种通信程序,收集各个站点的信息,比如,站点的健康状态、会话连接数、响应时间等。
4)每个站点的软件或设备运行某种动态特性的度量程序,比如测量该站点到客户端local DNS服务器的往返时间(RTT)、地理间隔、BGP跳数等。
5)GSLB使用从步骤3和4 收集到的信息,向客户端的local DNS服务器返回计算最优的结果,这个结果是1.1.1.1 或 2.2.2.2 两者之一,如果DNS保活时间(TTL)不为0,这个结果会缓存到客户端本地 DNS服务器上,以便其他共享该本地DNS服务器的客户端可以直接使用这个结果(不在重复步骤2-4)。
DNS 解析结束后,客户端会向相对最优的站点建立TCP连接。
浏览器DNS缓存
IE 浏览器,Netscape 浏览器,其他浏览器,甚至Web 代理缓存程序和邮件服务器,都内建“DNS 缓存”。DNS 缓存是一个小型数据库,可以将DNS解析结果存储一段时间。通常情况下,DNS结果的存储时间由回答这条结果的权威DNS服务器指定。这段时间被称作保活时间(TTL)。不幸的是,浏览器的缓存不能够获得DNS服务器返回的TTL。这是因为DNS请求是由通过调用操作系统的gethostbyname()函数(或其他提供类似功能的函数)完成的,该函数调用仅返回请求域名对应的一个或多个IP地址(该系统调用不允许请求应用程序获取TTL)。为了解决这个问题,浏览器的开发者引入了一个可配置的TTL值。在IE浏览器中,该值默认是30分钟,可以通过Windos 的注册表修改。在Netscape 中,这个值默认是15分钟,可以通过修改prefs.js文件中的一行来配置该值。
DNS解析请求的频率主要取决于不同的浏览器。旧版的浏览器请求时间间隔是固定的,对应每个站点,IE浏览器每30分钟执行一次请求,Netscape是15分钟,不管用户/客户端这个时间段内连接多少次该站点。点击刷新,甚至其他组合操作都不会改变这一行为。唯一能够刷新浏览器DNS缓存的办法就是退出并且重启浏览器(或者重启计算机)。在大多数情形下,“重启浏览器”意味着关闭所有正在浏览的页面,不光是出现连接问题的这个页面——当页面发生连接问题时,这件事(重启浏览器),用户不一定会自行去做。Microsoft 很早以前修复了这一问题。但是在最近的统计中(2007-8),仍有相当一部分的浏览器受该问题影响。更多关于DNS缓存与浏览器的问题请参见http://www.tenereillo.com/BrowserDNSCache.htm
浏览器缓存带来的问题
浏览器缓存会给GSLB带来相当大的影响。如果一个站点因为灾难性的事故不能提供服务,所有当前连接到该站点的客户端都会遭遇连接故障直到浏览器中的DNS缓存过期,或者用户重启浏览器或计算机。同时,任何指定缓存了失效站点IP的DNS服务器作为Local DNS服务器的客户端,也会遭遇连接故障。这显然是不能接受的。
下图可以帮助展示这个相当严重的问题。以一个金融行业站点(提供证券、股票交易,网上银行等)为例,使用active/backup 负载方案,该方案是最简单,并且最广泛使用的GSLB配置,见下图:
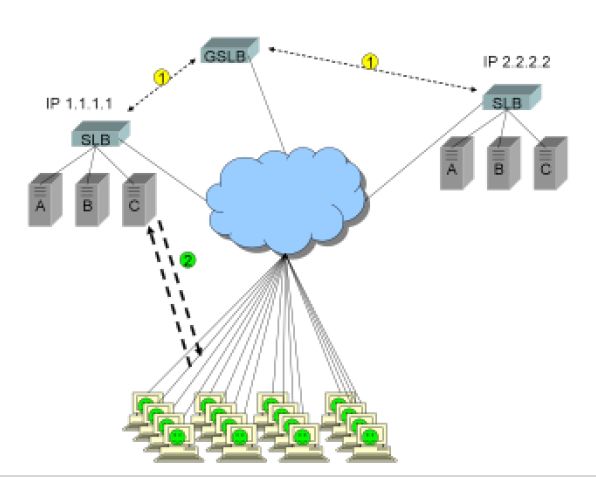
虚构一个站点 www.ReallyBigWellTrustedFinancialSite.com,使用位于洛杉矶的站点A(1.1.1.1)作为主要站点,站点B(2.2.2.2)作为备用站点。
1)为了实现该方案。 www.ReallyBigWellTrustedFinancialSite.com 的DNS解析响应中需回复唯一的结果,或者说“A 记录”——IP 地址1.1.1.1。一个GSLB设备部署在互联网上,使用最优秀的高级站点健康监控技术。
2)数千用户连接在站点A,顺利的进行交易事务,所有用户将IP 地址1.1.1.1缓存在其浏览器中。
现在灾难发生了,如下图所示:

1)GSLB优秀的高级站点健康监控技术立即检测到了故障。
2)GSLB注意到站点B仍然健康,开始返回IP地址2.2.2.2,以便将新请求路由到站点B。
3)所有在线的用户仍然将站点A的IP地址1.1.1.1,缓存在其浏览器中。GSLB没有任何办法通知这些用户,因为这些用户在浏览器缓存过期之前,不会发起新的DNS请求。
对于所有在线用户,站点故障实际上持续了半个小时,完全超出基于高级站点健康监测技术的GSLB设备的控制。
然而这还不是最坏的,情况还会更糟,如下图:
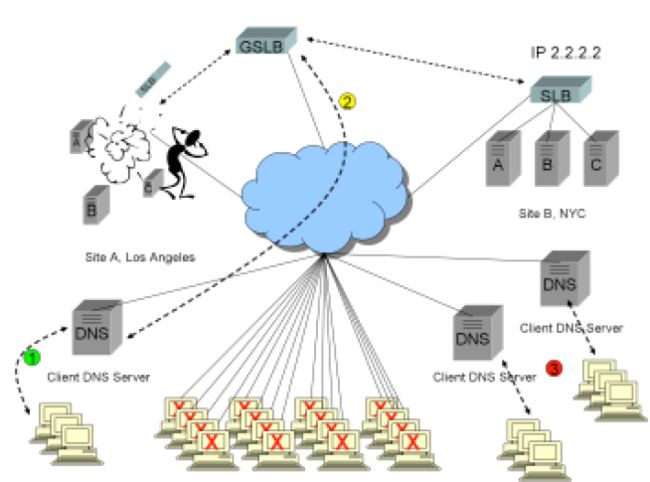
1) 一些新客户端的浏览器缓存和local DNS服务器缓存中没有解析结果1.1.1.1。这些用户会请求www.ReallyBigWellTrustedFinancialSite.com 。
2)这些客户端的local DNS会代理其发起迭代地址解析(至少会为第一个请求代理解析),最终请求到GSLB,GSLB 会响应健康站点的结果——IP 2.2.2.2 ,一切都很正常。
3)然而一些客户端的local DNS服务器缓存中已经有解析结果1.1.1.1,或者是因为这条结果中由GSLB设置的TTL没过期,要么是local DNS服务器器忽略了过低或为零的TTL值(事实上,有些DNS服务器确实这么做)。因为解析结果仍在缓存中,local DNS服务器不会向GSLB发起迭代请求,并且无法感知到站点A——1.1.1.1 已经失效,因此这些新加入客户端也会经历半个小时的故障,完全不受GSLB的控制。
解决浏览器缓存问题的方法
对于浏览器缓存问题有一个存在已久的解决方案,就是权威DNS服务器(或GSLB)在解析响应中返回多个DNS结果(”A 记录”)。
在解析响应中返回多个A记录并不是什么诀窍。也不是负载均衡设备厂商的持有的特性。DNS协议在设计之初就支持在解析响应中返回多个A记录。例如浏览器、代理服务器、邮件服务器等应用程序都可以使用该特性。
下图展示了他是如何工作的:
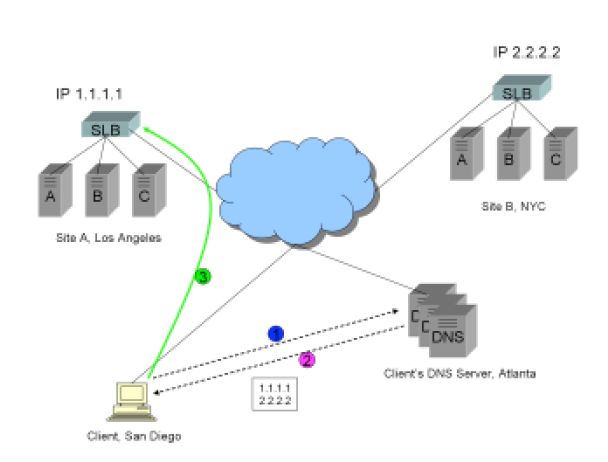
1)客户端请求解析FQDN www.trapster.net。
2)迭代查询之后(未显示),客户端的Local DNS服务器返回两个A记录——1.1.1.1 和 2.2.2.2 (按照这个次序)。
3)客户端向站点1的IP 1.1.1.1 建立请求。
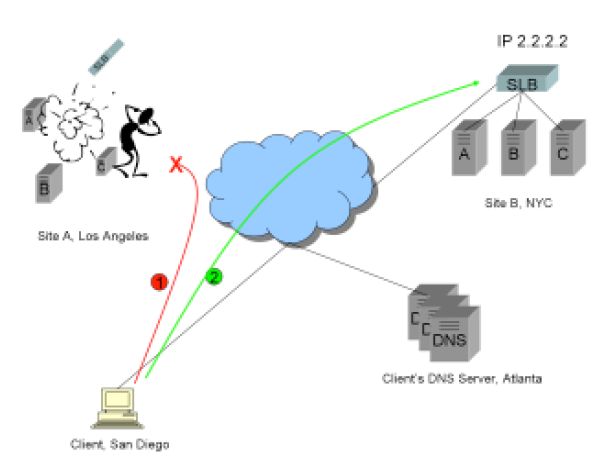
1)当客户端访问站点A顺利的进行商务活动时,一个灾难性的事件导致站点失效。客户端与站点A失去连接。
2)因为第二条A记录2.2.2.2也包含在原始的解析结果中,客户端会平滑的连接到站点B2。注意:这取决于商业应用程序的架构,一些连接状态,比如登录状态、购物车、财务事项等,也许会因为灾难而丢失,然而客户端仍可以在站点B继续进行商务活动。
解析结果中回复多个A记录并不需要GSLB设备,不过大多数GSLB设备支持这一功能。所有重要的DNS服务器都支持回复多个A记录,基本上所有基于B/S的商业站点为了应对浏览器缓存问题,都会在解析结果中返回多个A记录。
An Axiom
对于GSLB,唯一能够实现高可用的方法就是在DNS解析结果中包含多个A记录。
高可用实现有超多的替代的解决方案,但是没有一个能够真正奏效(见下文“替代方案” ),除了修改所有可能访问该站点PC的注册表,在解析结果中回复多个A记录是唯一的方法。
为什么多重A记录会抵消GSLB的负载均衡算法?
就像前文提到的,DNS服务器能够在解析结果中返回多重A记录。GSLB设备同样也可以返回多重A记录。即使互联网站点已经拥有DNS服务器(或购买了DNS解析服务),互联网站点的拥有者仍会采购GSLB设备,通常每台高达$30000,为的是获得那些比普通DNS服务器能提供的更多的特性。
问题来了:
这些特性中,没有一个特性可以同多重A记录配合使用 。
简单的站点Active/Standby算法不行、静态的站点偏好算法不行、基于IANA的站点偏好算法不行、DNS
persistence 算法不行,RTT或步长检测算法不行,基于Geotargeting的重定向也不行…没有任何一个特性可以!下图就来展示为什么:

基于GSLB的DNS解析前面已经阐述过了(为了简便,像健康检查、RTT测量等步骤这节就省略掉了)。
1)我们假设GSLB设备设置站点A为首选站点,IP地址1.1.1.1 ,它在解析响应中按照如下顺序返回解析结果:
- 1.1.1.1
- 2.2.2.2
2)客户端的Local DNS 收到解析结果后,将结果缓存。此时Local DNS将结果返回给客户端,顺序可能是:
- 1.1.1.1
- 2.2.2.2
或者:
- 2.2.2.2
- 1.1.1.1
目前,几乎所有的商用GSLB设备都会返回有顺序的多重A记录,通常被称为“顺序列表”。设想预定的结果顺序会一成不变穿越互联网传递给DNS请求者3,不幸的是,这个设想是错误的。
实践证明:DNS解析结果的地址顺序会被客户端的Local DNS 篡改!
Local DNS服务器篡改解析结果中的地址顺序是为了平衡去不同站点的流量,这是大多数提供商DNS服务器的默认动作4。曾经有想法是将DNS响应结果的TTL设置为0,来避免Local DNS篡改顺序。但是非常不幸,解析结果的顺序仍会被篡改,完全不受GSLB或权威名字解析服务器的控制,这种情况下,确定性的控制客户端优先访问某一站点是不可能的。
网站Cookies:猜怎么着?依然不能奏效!
大多数多地部署的网站都要求会话的持续。换句话说,如何一个客户端连接到了站点A,那么必须要保证在整个会话期间,客户端一直连接在站点A。即便是站点已经很好的同步以适应某种级别的会话持续,然后实时同步是不可能做到的。
浏览器DNS缓存是解决会话持续的一线希望。客户端解析了www.trapster.net 之后,得到结果是站点A,IP 1.1.1.1,客户端会持续连接到站点A直到浏览器缓存过期。前面提到过,IE的过期时间是30分钟,Netscape是15分钟。很明显,单独使用这个方法不能满足超过30分钟(或15分钟)的会话的持续性,因为超时后浏览器会重新解析域名,这时客户端可能会连接到错误的站点。同时,不论30分钟或15分钟,都是固定的时间段,不是客户端停止使用的等待时间。例如,一个用户访问了www.trapster.net,然后接了29分钟电话,挂断了电话后,继续浏览www.trapster.net 开始订购某些商品,浏览器会在一分钟后重新解析,很可能将用户引导到错误的站点。
DNS缓存时间超时问题是众所周知的,因此基本上所有的SLB(服务器负载均衡)都会去解决这一问题。使用一种被称为”站点 cookie”的方法,通常只为HTTP协议部署(也有一些厂商为流媒体协议实现了该方法)。
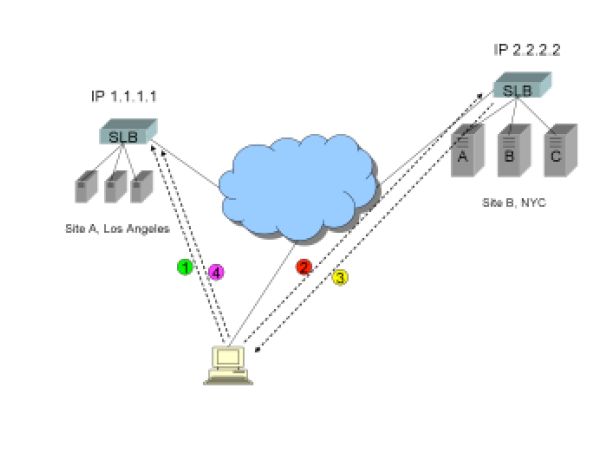
1)客户端解析www.trapster.net的结果——站点A,IP地址1.1.1.1。客户端连接到站点A,开始商务事务。在连接到站点A的同时,站点A的SLB设备植入了HTTP cookie,该cookie 指明了客户端需要持续连接哪个站点(甚至是具体的服务器)。
2)经过一段时间,客户端浏览器的DNS缓存过期后,客户端会重新解析,这次的解析结果是Site B,IP 地址2.2.2.2,该地址将会在客户端浏览器中缓存30分钟(或15分钟),客户端现在向站点B建立连接,当客户端连接到站点B,其发送的站点cookie 表明客户端的当前会话需要连接站点A。
3)站点B的SLB设备读取这个cookie后,发送了一个条HTTP重定向。HTTP重定向中的FQDN部分不能是www.trapster.net,因为该域名对应的解析结果2.2.2.2 仍然缓存在客户端的浏览器中。同时,也不能使用地址1.1.1.1重定向,因为如果不使用DNS域名做重定向,服务器软件和SSL认证通常不能正常的工作。因为这个原因,通常使用一个站点独立的FQDN。在这个例子中,HTTP重定向的域名可能是www-a.trapster.net(或 site-a.www.trapster.net)。
4)客户端现在用www-a.trapster.net 重新连接原来的站点继续商务事务。
如下图展示:
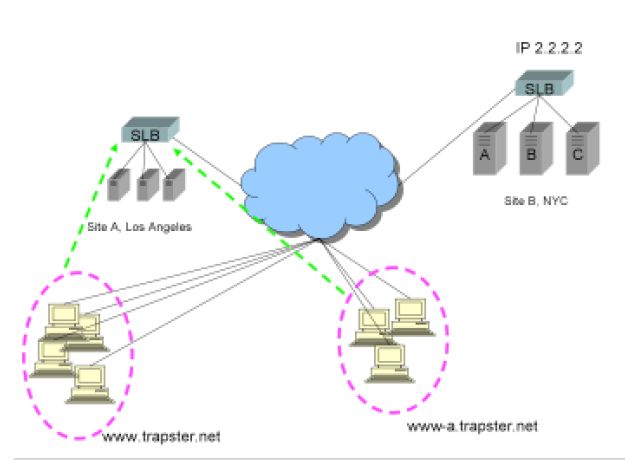
经过一段时间,尤其是站点经历了很长的会话时间(比如股票交易或财经站点),很大比例的用户会通过站点独立的FQDN连接到网站。即使经过短暂的
会话时间,有些用户也会使用到站点独立的FQDN www-a.trapster.net。
因为有用户已经使用了www-a.trapster.net,为了高可靠性考虑,不仅仅需要为www.trapster.net 使用多重A记录,而且还要为www-a.trapster.net 使用多重A记录。如果IP 1.1.1.1 和 IP 2.2.2.2 都包含在www-a.trapster.net 的解析结果中,如前文所述,客户端可能会连接站点A,也可能是站点B!
站点cookie 不能很好的与多重A记录一起工作,同GSLB不能很好的与多重A记录一起工作的原因一样!
GSLB站点健康检查有用吗?
我们已经证明了多重A记录是有必要的,但是剩下的问题是“他们能胜任基于B/S架构的站点吗?”,当收到包含多重A记录的解析结果后,基于浏览器的客户端使用它们自己的“健康检测”方法,这就是为什么多重A记录会设计在DNS协议中。也许有这样的情形,要求GSLB在解析结果中不返回已经检测到失效站点的A记录,但是也有很多情形要求返回失效站点的A记录,即使明确检测该站点失效。这一节就展示这样一个情形,许多种类的故障是很短暂的,换句话说,同样的问题可能会在不同站点间次序的或同时的出现。例如:
1)电力故障也许会影响一个区域的数据中心,并且当电缆网络调整期间,也许会影响其他地区的数据中心。
2)拒绝服务器攻击(DoS)通常攻击指定的IP地址。一次DoS攻击也许会先攻击IP地址1.1.1.1,然后再攻击IP地址2.2.2.2。
3)电脑病毒也许会先影响数据中心A,也许会花半小时来人工的杀除病毒,在这期间,该病毒也许会在数据中心B爆发。
4)ISP内部网络出现问题,一个路由器问题会同时影响一个国家不同区域的网络。
根据前面的例子,站点A使用IP地址1.1.1.1,站点B使用IP地址2.2.2.2,如果一台SLB或GSLB设备(或者是绑定的某个健康检测脚本),发现站点A失效了,应该在解析结果中只返回单一的A记录2.2.2.2吗?如果站点B使用IP地址2.2.2.2随后也发生了故障,但是站点A在半小时的窗口中,从故障恢复
,这种情况下最好还是一直返回两个站点的A记录,即使健康检测进程检测到了失败。记住,返回多重记录很少是适得其反的,因为客户端会自动地连接A记录列表中健康的站点,不需要人工干预。
替代方法
还有一种不太严重的故障会发生。一个站点的所有服务器故障,然而站点的电力、互联网连接和SLB设备都工作正常。此类问题有许多商业上可用的解决方案,包括backup redirection, triangulation,proxying, 或NATing。为了完整性这里会讨论一下这些解决方案,但是这节会说明,这些解决方案虽然可以解决不太严重的服务器故障,但是并不能解决更重要的站点故障问题。
Triangulation
Triangulation 是一种连接恢复方法,对所有的IP 协议都适用。
1)客户端已经连接到站点A,正常的浏览网站。
2)站点A的所有服务器故障(但是在这个例子中,SLB、互联网连接、交换机、路由器、电力等设备都正常)。运行在站点A SLB上的软件检测到了服务器故障,当然所有的存在的TCP连接都会丢失,但是客户端会尝试重连。在站点A的SLB与站点B事先有预建立的TCP隧道,站点A的SLB将客户端的新连接请求通过TCP隧道转发给站点B。
3)站点B的SLB设备选择一个新服务器为该客户端提供服务,并且使用冒名的地址1.1.1.1将数据包直接返回给客户端。
Backup redirection
Backup redirection 只对应用层支持重定向的协议有效(比如 HTTP、HTTPS、一些流媒体协议等)。
1)客户端向站点A发起请求,请求的URL是FQDN www.trapster.net,已经解析为IP地址1.1.1.1。
2)站点A的SLB发现所有的服务器都故障了,于是发出一个HTTP重定向引导用户去连接站点B。这里的重定向必须使用一个不同的FQDN,可以是www-b.trapster.net。如果HTTP重定向使用www.trapster.net,客户端的会使用已经缓存的地址(1.1.1.1)重新连回站点A。并且HTTP重定向可能不可以使用IP地址,因为大多数的服务器、SSL认证等,需要客户端通过FQDN访问站点,而不能是IP地址。
3)客户端现在访问站点B。
IP proxy 和 NAT
IP proxy(和NAT)对所有的IP协议都有效,这里不详细介绍他们了。这两个方法,在发现站点A的所有服务器故障后,会将客户端的连接负载均衡到站点B的VIP(2.2.2.2)上,就像将客户端连接负载均衡到本地服务器一样。
Triangulation、backup redirection、IP proxy和NAT的问题
这些方法确实会对站点故障快速恢复有所帮助,但只能是在互联网连接、网络设备、电力和本地SLB设备都工作正常的情况下起作用,换句话说,仅当服务器故障时有效。如果这些方法同多重A记录一同使用,这些方法的能否起作用是值得怀疑的。如果单独使用这些方法,而不使用多重A记录,等于是“丢了西瓜拣芝麻”。如果不将站点的灾难性故障考虑在内,那也没有什么强有力的论据去使用GSLB。看来最好是完全忘掉GSLB,丢弃那些花费和复杂性,将所有的服务器聚集在一个数据中心,而不是两个,使用冗余的电力、网络连接、网络设备、和SLB设备。
这就是说,即使在灾难情况下的高可用是对GSLB最基本的需求,GSLB也只能在特定情况下满足,因此:
对于高可用的需求,Triangulation、backup redirection、IP proxy和NAT,这些方法都不能满足,或者说不需要。基于浏览器的客户端仍需要使用多重A记录。5
BGP主机路由注入
还有一个解决方案,通常被叫做BGP主机路由注入(HRI),同时,至少有两家厂商也叫做“Global IP”。他并不是简单与GSLB配合的备选方案,而是一种用来替换基于DNS的GSLB的解决方案。下面是其原理的概述:

0)(客户端发起DNS解析,www.trapster.net 的解析结果中只有一个IP地址——1.1.1.1。)
1)站点A和站点B的SLB设备(或路由器)都向互联网宣告了地址1.1.1.1。互联网路由器将1.1.1.1的路由信息通过BGP传播,同时交换度量值,最终将路由信息传播给距离客户端最近的互联网路由器,该路由器选择度量值最小的路径,将1.1.1.1的路由加入路由表。
2)客户端此时连接拓扑上最近的站点。
此时发生了服务器(全部)故障,或互联网连接故障、电力故障、SLB设备故障、网络设备故障等灾难性故障。

1)站点A的SLB设备发现了服务器故障,停止通过BGP向互联网宣告IP地址1.1.1.1(或 SLB、互连网连接被破坏,这种情况下宣告显然会停止)。
2)路由在互连网设备间收敛,前往站点A的路由条目最终会被删除。
3)客户端重新建立连接,仍连接IP 1.1.1.1,但这次连接的是站点B。
虽然在理论层次上,这个方案实现的功能像是GSLB梦寐以求的,但是它很少真正部署实现,下面阐述了为什么:
- 互联网的路由相当复杂,在不同地区宣告同一个IP地址的实践,工作的并不可靠。在客户端的会话期间,如果发生路由变动,数据包会在站点A和站点B之间断断续续的传输,此时,即使两个站点都可以正常工作,客户端依然不能正常访问。
- 路由收敛的时间会相当的长。当站点发生故障后,客户端的浏览器会超时,会跳转访问失败的页面。如果用户手动的持续尝试访问,最终连接会恢复,但是故障恢复时间超过5分钟也是有可能的,这么长时间的故障对于商业站点来说是不能接受的。
- BGP宣告的单个IP地址(主机地址)通常会被互联网路由器忽略。一个可能的解决方式是宣告整个网络地址段,然而仅仅为了GSLB这么做,等同于浪费昂贵的公网IP地址资源(因为仅仅一个地址,或一小部分地址会被实际使用到)。
-为了安全考虑,路由器上会配置源地址过滤(有时叫做“bogon”过滤),源地址过滤会防止从不同的地域宣告同一IP地址。这个问题通常可以通过与ISP协商解决。尽管如此,即使与ISP协商去掉了源地址过滤,通常还会有人疏忽的重新加上去,这通常会造成站点失去互联网连接,需要故障报修处理等。
BGP HRI在站点分布在较小地域范围的网络中算是个健全的解决方案,也许可以用于一些互联网应用,但是部署相当的少见,因为它在实践中的表现远远不如理论分析的好。
结论
实现B/S架构的GSLB高可用,唯一的方法就是在解析响应中返回多重A记录,但是返回多重A记录,会破坏目前任何站点选择算法的作用。因为这些特性,比如基本的active-standby算法、DNS persistence算法、基于RTT或步长或BGP跳数的站点选择算法、基于IP地址geotargeting或基于IANA的站点选择都不能奏效。
好消息是,现在消费者可以将原本花GSLB上的每单元$30000,用在购置更多的服务器和提升站点内部同步能力上!
Watering it down
冒着混淆前文理论的风险6,写了下文:
至少在理论上,GSLB设备可以以某种“最佳选择+轮询”的模式运转,例如如果一个FQDN在欧洲有两个站点,在美国有两个站点,对于欧洲的客户端,为了更好的服务,GSLB只返回位于欧洲的两个站点的A记录给客户端的Local DNS服务器。客户端的Local DNS服务器会在两个站点间轮询负载。见下图:
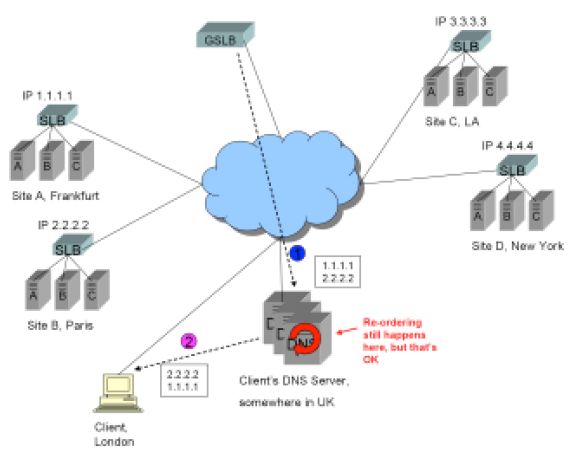
0)在这之前(没有在图上显示),客户端请求解析FQDN www.trapster.net,最终解析请求迭代到了www.trapster.net的权威服务器,也就是GSLB设备。GSLB执行站点选择算法,为客户选择法兰克福和巴黎站点,排除洛杉矶和纽约。
1)GSLB返回两个站点的IP 1.1.1.1 和2.2.2.2。
2)解析结果中的A记录顺序会被客户端Local DNS服务器打乱,但是在这个例子中,该行为是可接受的。客户端会连接法兰克福或巴黎站点。
为了更好的说明,我随便选择一个术语“区域”,来描述这个GSLB拓扑结构。
上文提到的站点A和站点B被划分为“欧洲GSLB区域”,站点C和站点D划在“美国区域”。这个方法,只有在网站的站点分布在全球,且划分为不同的区域,每个区域至少包含两个数据中心互为备份,这种情况下,才能被全局负载均衡。如果www.trapster.net的数据中心分布在伦敦、纽约、东京,那么“最佳选择+轮询”的模式就不会奏效了。某一客户端在伦敦,GSLB需要返回伦敦站点的A记录(地理位置最近的站点),同时它必须至少返回另一个站点的IP(纽约或东京,两个站点与伦敦的距离都不近)。客户端会连接伦敦的站点或者连接其他的站点。很明显,这明显违背了GSLB站点选择算法的初衷。同时,一些站点选择算法(例如步长计算)不能在“最佳选择+轮询”模式下工作(留给读者来思考),DNS persistence 算法也不能同“最佳选择+轮询”协同。即使这个复杂的实现可以为超大的全球站点服务,对于本文讨论的案例来说该方法并不是一个通用的解决方案。
原文地址:http://www.tenereillo.com/GSLBPageOfShame.htm
- This paper discusses Internet behavior in the sense of the larger Internet. Certainly custom solutions can be created. For
example, there is the possibility of distribution of special software to run on client computers. Such solutions are almost
never practical for Internet sites, and are therefore not discussed here. Also, exceptions can be found in noncustom
solutions, such as browsers or DNS servers that are configured to behave differently than described here. Again, those are
very rare. Finally, there are applications that are not required to serve browser based clients. This paper does not apply to
those applications. ↩ - The timeliness of the connection attempt to the second site is application dependent, but essentially all browser based
applications will try the second IP address after a few unanswered TCP SYN packets. ↩ - Some solutions also attempt to achieve site weighting by returning duplicates. For example, to get 75% of traffic on site
one they would return the ordered list {1.1.1.1, 1.1.1.1, 1.1.1.1, 2.2.2.2}. This feature does not work reliably, as most DNS
servers note the duplicates and round robin the list as {1.1.1.1, 2.2.2.2}. ↩ - The order that A records are returned by the most commonly deployed DNS server, BIND, is as follows. The first record
is chosen at random. The remaining records are returned in a cyclic order. For example, if the ordered list is {1.1.1.1, 2.2.2.2,
3.3.3.3} the first response might be {2.2.2.2, 3.3.3.3, 1.1.1.1}, the next response to a subsequent client request, from a client
that shares that name server, would be {3.3.3.3, 1.1.1.1, 2.2.2.2}. Other DNS resolvers and servers reorder the list differently,
for example the Windows XP DNS cache will reorder a response such that any subnetadjacent
IP address is returned first.
This paper does not attempt to provide a canonical list of such issues. It will suffice to say that, for a number of reasons, the
order in an ordered list of A records cannot be expected to be preserved. ↩ - Sites that do not support browser based clients, but do support applications that do not work well with multiple A
records (indeed some custom robot type client applications do not), have no other recourse but to use one of these recover
methods. ↩ - The “Watering it down” section was part of the original paper. I removed it because I thought it complicated the issue.
Reviewers suggested that I put it back in. Done. 5/26/04. ↩