正则表达式从理论到实战
正则表达式从理论到实战
- 一、概述
-
- 1. 初识
- 2. 工具
- 二、基本语法
-
- 1. 简单模式匹配
- 2. 量词
- 3. 边界
- 4. 转义字符
- 5. 字符集
- 6. 选择、分组和后向引用
- 7. 贪婪、懒惰和占有
- 8. 零宽断言
- 9. 注释
- 10. 选项
- 三、应用
-
- 安全日志分析
- 四、参考及资源
一、概述
1. 初识
正则表达式(regular expression,简称regex,或RE), Unix 之父Ken Thompson对其的定义为:正则表达式是描述一组字符串特征的模式,用来匹配特定的字符串。
简单的说,正则表达式就是简洁表达一组字符串的一种表达式。比如我们想表达如一下组固话:
023-52410789
0755-54782173
010-62782051
0991-8585671
...
这个例子如果用文字描述将是:区号(以数字0开始,并跟随2-3个数字) + 分隔符(以’-‘代替,便于书面的理解) + 具体的号码(大部分地区的号码是7-8位数字组成)。
试想一下,如果有一篇100页的文档,想要找出所有这种形式的号码,你将如何着手,在不会正则表达式之前,除了肉眼搜索,可能就是一堆的if…else…。
再看看正则表达式:
0\d{2,3}-\d{7,8}
此处应该有掌声!!!
2. 工具
孔子曰:”工欲善其事,必先利其器“,要想学习正则表达式,我们要知道学习工具,边学习,边实践,边应用,如果只是死记语法,那个你已经可以停下来了,正所谓:从入门到放弃。
这里给出三类工具,请结合自身情况妥善选择:
(1)在线工具
-
https/tool.oschina.net/regex/
-
http://tool.chinaz.com/regex/
-
https://c.runoob.com/front-end/854
-
…
(2)离线工具
-
windows文本工具:notepad3、vscode、UltraEdit、Sublime…
-
类Unix相关命令:grep、vi(vim)、sed、…
-
其他:RegExTester、…
(3)编程语言
-
Python
-
Java
-
JavaScript
-
C/C++
-
PHP
-
…
本文以Notepad3和Python两种工具进行示例演示
二、基本语法
正则表达式是一种表达式,该表达式的语法由书面字符和元字符组成。所谓书面字符,即符号是啥就是啥;元字符呢,它代表的是这种写背后的含义比如:0**\d{2,3}-\d{7,8}**, 0和-为书面字符,而\d代表的是数字字符,{2,3}是量词,表示前面的字符出现2至3次。
接下来我们将按如下顺序进行讲解:
简单模式匹配 => 量词 => 边界 => 转义符 => 字符集 => 选择、分组和后向引用 => 贪婪、懒惰、占有 => 零宽断言 => 注释 => 选项
整体难度也在缓缓增加,如果你还没接触过正则表达式,可能心理上已经开始想放弃了,请记住"天下无难事,只怕有心人"。跟着我的节奏,一不小心你就学会了_。
1. 简单模式匹配
这一节你将学会如何用简单的元字符表达某一类字符,下面列出常用的匹配方式:
| 正则表达式 | 匹配字符 | 备注 |
|---|---|---|
| \d | 数字 | digit首字母,表示一个数字 |
| \D | 非数字 | |
| \w | 单词字符 | word首字母, 表示一单词字符,可以是:26个英文字母的大小写或数字 |
| \W | 非单词字符 | |
| \s | 空白字符 | space首字母,表示一个空白字符,可以是:空格、换行(\n)、回车(\r)、制表符(\t) |
| \S | 非空白字符 | |
| . | 任意字符 | 默认情况下不匹配换行符,可设置dotall选项 |
打开notepad3或者其他工具,输入
123
abc
输入Ctrl + F打开查找对话框,进行如下查找,看看查到了什么

输入Ctrl+h打开替换对话框架,进行如下替换,看结果如何?

使用正则是不是完成了你以前很难完成的问题,现在你应该会完成如下需求:
- 使用替换,将
123和abc变成一行,使用逗号隔开,即要求变成123,abc
【注意】
- 符号 . 表示任意字符,默认情况下不匹配换行符,这在多行数据的匹配中要注意,在后面讲选项的时候会仔细讲。
2. 量词
上面我们学会的是单个字符的匹配,如果要表达多个类似的字符,只能通过复制多次的方式,比如我们要查找5个连在一起的数字,要写成\d\d\d\d\d,按程序员的思维,显然不合理,比如我们要表示1000个数字、任意多个数字、…
接下来介绍如何通过量词来表示上面的情形,下面列出了几种量词的写法:
| 量词 | 含义 | 备注 |
|---|---|---|
| ? | 出现0次或1次 | a\d?:表示a后面跟0个或者1个数字 |
| + | 出现至少1次 | py+:表示p后面跟了至少一个y的字符串 |
| * | 出现任意多次 | .*:正则表达式里常见写法,表示任意字符串(不考虑换行符的情况下) |
| {n} | 出现n次 | \d{5}:表示5个数字的字符串 |
| {n,} | 出现至少n次 | \d{5,}:表示至少5个数字的字符串 |
| {n,m} | 出现至少n至m次 | 0\d{2,3}: 表示数字0后跟有2至3个数字 |
有了量词,一些简单正则表达式已经可以完成,比如在notepad3中输入如下文本:
1234
56789
1549
123456789
使用正则表达式的方式查找:
- 5个以上数字的字符串
- 以1开始,以9结尾的任意数字字符串
此外,量词?、+、*都可以用{}的方式表示,试着写出来。
【注意】
- 这些元字符都是英文状态下的字符(半角),切记不要写成中文状态下的字符(全角)
3. 边界
如何表示一个字符串的起始位置和结束位置呢,这便是我们要讲的边界,这里先给几个简单的边界表示
| 边界 | 含义 | 备注 |
|---|---|---|
| ^ | 表示字符串的起始位置 | ^hi.* 以hi开始的字符串 |
| $ | 表示字符串的结束位置 | .*xls$ 以xls结尾的字符串 |
| \b | 单词边界 | \be\b 匹配不出现在单词中的单个字符e |
| \B | 非单词边界 | \Be\b 匹配单词末尾的e |
| \<、 \> | \<表示单词的开始位置,\>表示单词的结束位置 | 部分应用支持 |
对下方的内容,如何为每一行字符串前面加
, 每一行字符串的后面加
abc
def
ghi
以在前面在
为例

这里只讲了字符串开始和结束以及单词的(非)边界,显然我们有更多的要求,比如下面的文本,我们想在数字与后面的名字之间加入空格,这时就需要更丰富的边界表示,会在零宽断言部分进行详细讲解
1张三
2李四
3王五
11赵四
4. 转义字符
我们已经学了部分元字符,比如.?+*等,那如果我们想要查找元字符本身,比如要查找. 或者 * ,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时你就得使用 \ 来取消这些字符的特殊意义,从而表示字符字面量,比如要表示.,需要写成.
\. \*
\? \\
\( \)
此外,还有另外一种使用元字符的方法,有部分应用支持:
\Q.\E \Q*\E \Q?\E
5. 字符集
在前面的简单模式匹配中,我们使用了\d、\w等表示一组字符,使用应用中会有更多的需求,比如想表示元音字母,想表示以02468结尾的数字等。这就需要字符集(或者叫字符组),字符集的写法是使用方括号将需要的字符括起来,比如元音字母表示为[aeiou]。
字符集的表示中注意以下两个符号的用法:
-
减号(-):在字符集中,如果想表示某一个范围的字符,可以使用减号来表示一个范围,比如想表示a,b,c,d这四个字符,可以写成
[a-d] -
脱字符():如果我们想对字符集取反,可以在字符组的最前面加入脱字符(),它相当于在说:“我不想匹配这些字符”,但一定要注意^必须出现在字符组的最前面 。
对下面的文本,如果想找出所有的偶数:
124 156 111 1337
92 20 999 666
可以将正则表达式写成
\b\d*[02468]\b
此外,POSIX(Portable Operating System Interface, 可移植操作系统接口)字符组,提供一套命名的字符组,其形式为:[[:xxxxxx:]],取反: [[:^xxxxxx:]]
| 命名字符组 | 含义 |
|---|---|
| [[:alnum:]] | 匹配字母及数字 |
| [[:alpha:]] | 匹配字母 |
| [[:ascii:]] | 匹配ASCII字符 |
| [[:blank:]] | 匹配空白字符 |
| [[:ctrl:]] | 匹配控制字符 |
| [[:digit:]] | 匹配数字 |
| [[:graph:]] | 匹配图形字符 |
| [[:lower:]] | 匹配小写字母 |
| [[:print:]] | 匹配可打印字符 |
| [[:punct:]] | 匹配标点符号 |
| [[:space:]] | 匹配空格字符 |
| [[:upper:]] | 匹配大写字母 |
| [[:word:]] | 匹配单词字符 |
| [[:xdigit:]] | 匹配十六进制数字 |
【注意】
脱字符(^)在正则表达式中的两个用法,如果出现在正则表达式的最前面,表示开始位置;如果出现在字符集的最前面,表示字符集取反。
学习一定要注意总结,不然新知识会扰乱你的认知。
6. 选择、分组和后向引用
- 选择(或分枝)
正则表达式里的选择条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用 | 把不同的规则分隔开。多个选择的时候,将从左到右测试条件。
比如要识别如下两种固话号码,
0991-8585671
023-58102054
(0991)8585671
(023)58102054
则可以写成
\(0\d{2,3}\)\d{7,8}|0\d{2,3}-?\d{7,8}
- 分组
前面讲了如何使用量词重复单个字符,那如何去重复多个字符呢?可以使用小括号 ( ) 来指定一个子表达式(也叫分组),然后对子表达式进行重复,比如(py)+表示至少重复一次py的字符串。还记得刚写的两种固话的匹配吗,这时你可以写成
(\(0\d{2,3}\)|0\d{2,3}-?)\d{7,8}
- 后向引用
使用小括号指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。
默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
后向引用用于重复搜索前面某个分组匹配的文本。例如,\1代表分组1匹配的文本。
如果有点晕乎乎的,这是正常现象,千万别气馁,很多人到这里就放弃,你坚持了,也就成功了。
Linux 的创始人 Linus Torvalds 说过一句话:“Talk is cheap. Show me the code.”, 正则表达式的功效便是一言胜万语,请看下面这个正则表达式:
\b(\w+)\b\s+\1\b
它将匹配重复单词的字符串,你在Notepad3上输入以下内容,试试上面正则表达式的查看效果。
go go
kitty kitty
- 命名分组
在后向引用中,我们使用了自动分组号的引用,这会带来一些不便:
- 如果引用的分组前面增加了一个分组,这时对应的分组号变了,后面的引用也需要全部修改;
- 如果表达式过长,后面很难记住每个分组号的意义,这就像我们在访问一个网站时,通常是输入网址,而不是IP地址。正则表达式里面的做法是采用分组命名的方式,下面列出了几种命名分组的方式:
\b(?\w+)\b\s+\k'name'\b
\b(?\w+)\b\s+\k\b
\b(?\w+)\b\s+\g{name}\b
#在python中,使用如下的命名分组方式
\b(?P\w+)\b\s+\(?P=name)\b
针对上面的例子,我们将分组命名为word,在Notepad3中可以写成如下的形式:
\b(?\w+)\b\s+\k'word'\b
- 非捕获分组
前面讲的分组都是捕获分组,如果不想捕获(就是想表达一个子表达式,不会在后面利用这个子表达式的内容),我们可以采用非捕获分组,它的写法是在分组的前面加 ?:
(?:py)+
7. 贪婪、懒惰和占有
先来看个例子:
123abc123456abc
如果想找出123abc和123456abc两个字符串,你兴奋的写下了.*abc,结果发现只匹配了一次,把整个字符串匹配了。这便是我们要讲的匹配模式。
- 贪婪
当正则表达式中包含能接受重复的限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符。这被称为贪婪匹配
示例:a.*b,它将会匹配最长的以a开始,以b结束的字符串。如果用它来搜索 aabab的话,它会匹配整个字符串aabab。
- 懒惰
如果想要匹配尽可能少的字符呢,这就是懒惰匹配模式。怎么做呢?只要**在量词后面加上一个问号?**就可以了。
比如前面的示例,你只需要将正则表达式写为如下形式即可:
.*?abc
懒惰匹配总是出现在有量词的地方,有如下懒惰量词:
| 语法 | 描述 |
|---|---|
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
| {m,n}? | 重复m到n次,但尽可能少重复 |
- 占有
此外,还有一种匹配模式就占有匹配,这种匹配很像贪心式匹配,它会选定尽可能多的内容。但与贪心式匹配不同的是它不进行回溯。它不会放弃所找到的内容,它很自私,这也是把它称为占有式(possessive)的原因,优点是速度快,因为不回溯。
比如 000000,如果你写成 .*+0,这是不能匹配的,因为.*会匹配整个字符串,又因为是占有模式,将不会进行回溯,这时就没办法继续匹配0。
同样,占有匹配同样总是出现在有量词的地方,有如下占有量词:
| 语法 | 描述 |
|---|---|
| *+ | 占有式匹配任意次 |
| ++ | 占有式匹配1次或更多次 |
| ?+ | 占有式匹配0次或1次 |
| {n,}+ | 占有式匹配重复n次以上 |
| {m,n}+ | 占有式匹配重复m到n次 |
【注意】
- 问号(?):问号有两种场景,一是以量词方式使用,表示
?前面的子表达式或者字符出现1次或者0次;二是出现在量词后面,表示懒惰匹配。 - 加号(+):加号有两种场景,一是以量词方式使用,表示
+前面的子表达式或者字符出现至少1次;二是出现在量词后面,表示占有匹配。
8. 零宽断言
在边界部分,我们讲了^$\b\B等边界表示,但是我们说它不够灵活,比如前面的示例,想通过替换操作在数字后面加空格,这就需要我们这一节的零宽断言。
1张三
2李四
3王五
11赵四
什么叫零宽断言呢?某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),因此它们也被称为零宽断言。
- 零宽度正预测先行断言
(?=exp)也叫零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp,说人话,就是找满足表达式exp前面的位置。
试试使用正则表达式\b\w+(?=ing\b)查找以下内容时,查到了什么
I'm singing while you're dancing.
- 零宽度正回顾后发断言
(?<=exp)也叫零宽度正回顾后发断言,它断言自身出现的位置的前面能匹配表达式exp,简单说,就是找满足表达式exp后面的位置。
尝试使用正则表达式(?<=\bre)\w+\b查询如下内容:
reading a book
- 零宽度负预测先行断言
写法:(?!exp),断言此位置的后面不能匹配表达式exp,相当于零宽度正预测先行断言取反。
试试\d{3}(?!\d)查找字符串123ae4567,看匹配到什么
- 零宽度正回顾后发断言
写法(?, 断言此位置的前面不能匹配表达式exp,相当于零宽度正回顾后发断言取反。
尝试使用正则表达式(?查找字符串8585671abc8585671
【提醒】
整体来说,零宽断言的作用就是查找满足(或者不满足)某个条件的之前(或者之后)的位置,不要被高大上的名字给整晕了。
9. 注释
我们在学任何一门语言的时候,老师肯定都会强调注释的重要性,只是我们在初学的时候一般都没去写注释,原因不是它不重要,而是我们解决的问题或者写出的东西太简单,写注释显得有点…
同样的,在正则表达式当中,当我们在书写一些复杂正则表达式时,注释就显得特别重要。
正则中写注释的语法为:(?#comment),比如下面表示数字0-255的正则表达式的中,我们可以通过注释迅速的知道表达式的目的。
2[0-4]\d(?#200-249)|25[0-5](?#250-255)|[01]?\d\d?(?#0-199)
上面的正则写起来仍然感觉难以阅读,因为我们不能优雅的加空格和换行,为了解决这个问题,可以使用正则表达式的一个选项,叫“忽略模式里的空白符”选项。有了这个选项,在编写正则表达式时能任意的添加空格,Tab,换行,而实际在匹配时会忽略掉这些空白字符。此外,启用这个选项后,在#后面到这一行结束的所有文本都将被当成注释忽略掉。
开启这个选项后,可以写成
2[0-4]\d #200-249
|25[0-5] #250-255
|[01]?\d\d? #0-199
【总结】
这里对小括号的常用方式
| 分类 | 代码**/**语法 | 说明 |
|---|---|---|
| 捕获 | (exp) | 匹配exp,并捕获文本到自动命名的组里 |
| (?exp) | 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name’exp) | |
| (?:exp) | 匹配exp,不捕获匹配的文本,也不给此分组分配组号 | |
| 零宽断言 | (?=exp) | 匹配exp前面的位置 |
| (?<=exp) | 匹配exp后面的位置 | |
| (?!exp) | 匹配后面跟的不是exp的位置 | |
| (? | 匹配前面不是exp的位置 | |
| 注释 | (?#comment) | 这种类型的分组不对正则表达式的处理产生任何影响,用于提供注释让人阅读 |
10. 选项
在前面的部分小节里有提到几个选项的作用,下面列出一些常用的选项
- java中常用的正则选项
| 名称 | 选项 | 说明 |
|---|---|---|
| IgnoreCase(忽略大小写) | (?i) | 匹配时不区分大小写。 |
| Multiline(多行模式) | (?m) | 更改^和 的 含 义 , 使 它 们 分 别 在 任 意 一 行 的 行 首 和 行 尾 匹 配 , 而 不 仅 仅 在 整 个 字 符 串 的 开 头 和 结 尾 匹 配 。 ( 在 此 模 式 下 , 的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下, 的含义,使它们分别在任意一行的行首和行尾匹配,而不仅仅在整个字符串的开头和结尾匹配。(在此模式下,的精确含意是:匹配\n之前的位置以及字符串结束前的位置.) |
| Singleline(单行模式) | {?s} | dotall,更改.的含义,使它与每一个字符匹配(包括换行符\n) |
| IgnorePatternWhitespace(忽略空白) | (?x) | 忽略表达式中的非转义空白并启用由#标记的注释。 |
| Uinx中的行 | (?d) | 只有’\n’才被认作一行的中止,并且与’.‘,’^‘,以及’$'进行匹配 |
| UnicodeCase | (?u) | 对Unicode字符进行大小写不明感的匹配。默认情况下,大小写不明感的匹配只适用于US-ASCII字符集。 |
- Python的re库中常用的正则表达式选项
ASCII = sre_compile.SRE_FLAG_ASCII # assume ascii "locale"
IGNORECASE = sre_compile.SRE_FLAG_IGNORECASE # ignore case
LOCALE = sre_compile.SRE_FLAG_LOCALE # assume current 8-bit locale
UNICODE = sre_compile.SRE_FLAG_UNICODE # assume unicode "locale"
MULTILINE = sre_compile.SRE_FLAG_MULTILINE # make anchors look for newline
DOTALL = sre_compile.SRE_FLAG_DOTALL # make dot match newline
VERBOSE = sre_compile.SRE_FLAG_VERBOSE # ignore whitespace and comments
下面使用Python的re库的几个选项做简单说明
import re
s = '''
abc123
abc
123
'''
print('不使用DOTALL选项的查找结果:')
print(re.findall('.+?123', s))
print('\n使用DOTALL选项的查找结果:')
print(re.findall('.+?123', s, flags=re.DOTALL))
print('\n不使用使用MULTILINE选项的查找结果:')
print(re.findall('^a.*123', s))
print('\n使用使用MULTILINE选项的查找结果:')
print(re.findall('^a.*123', s,flags=re.MULTILINE))
print('\n不使用使用VERBOSE选项的查找结果:')
print(re.findall('a.* 123#注释测试', s))
print('\n使用使用VERBOSE选项的查找结果:')
print(re.findall('a.* 123#注释测试', s,flags=re.VERBOSE))
能学到这里,你已经掌握了基本的正则表达式的语法,接下来就是需要利用正则表达式解决一些实际问题
三、应用
安全日志分析
这里有一份CentOS的安全日志数据,完整数据下载地址:
链接:https://pan.baidu.com/s/1E2ghQjb8sfE-SVk-MPnDPw
提取码:nuli
日志片段
Jul 3 10:48:15 iZ23qc401m5Z sshd[9935]: Failed password for invalid user ethos from 202.120.38.145 port 37219 ssh2
Jul 3 10:48:15 iZ23qc401m5Z sshd[9936]: Connection closed by 202.120.38.145
Jul 3 10:50:21 iZ23qc401m5Z sshd[10110]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=202.120.38.145 user=root
Jul 3 10:50:23 iZ23qc401m5Z sshd[10110]: Failed password for root from 202.120.38.145 port 42648 ssh2
Jul 3 10:50:23 iZ23qc401m5Z sshd[10111]: Connection closed by 202.120.38.145
Jul 3 10:52:29 iZ23qc401m5Z sshd[10290]: Invalid user user from 202.120.38.145
Jul 3 10:52:29 iZ23qc401m5Z sshd[10291]: input_userauth_request: invalid user user
Jul 3 10:52:29 iZ23qc401m5Z sshd[10290]: pam_unix(sshd:auth): check pass; user unknown
Jul 3 10:52:29 iZ23qc401m5Z sshd[10290]: pam_unix(sshd:auth): authentication failure; logname= uid=0 euid=0 tty=ssh ruser= rhost=202.120.38.145
Jul 3 10:52:29 iZ23qc401m5Z sshd[10290]: pam_succeed_if(sshd:auth): error retrieving information about user user
Jul 3 10:52:31 iZ23qc401m5Z sshd[10290]: Failed password for invalid user user from 202.120.38.145 port 48082 ssh2
这里面有很多错误密码登录的日志,现在想分析出哪些IP在登录这台服务器,并且统计出它的登录次数
可以观察到,错误密码登录的行有一个明显的标识是Failed password,我们需要的是提取出这行数据里的IP地址,这里以Python为例进行代码展示
import re
import pandas as pd
with open(r'secure-20180708') as fp:
result = re.findall(r'.*?Failed\s+password.*?from\s+([\d\.]+)\s+port', fp.read())
print( pd.Series(result).value_counts())
运行后,将看到如下的结果。
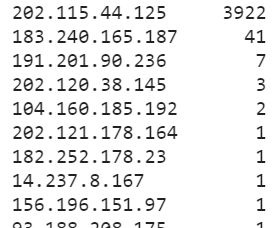
有没有被惊艳到…-,这里使用re库提取信息,使得pandas库完成了ip统计,不可谓不简单。
四、参考及资源
【主要参考】
- 《学习正则表达式》
- 《精通正则表达式》
【资源下载】
-
两个日志工具文件
- notepad3的Portable版,无需安装,解压即可运行
- vscode的Portable版,无需安装,解压即可运行
-
电子书
- 《学习正则表达式》
- 《精通正则表达式》
-
应用中的安全日志文件
- secure-20180708
链接:https://pan.baidu.com/s/1bqVzVDsNAEUw4vND5TB7TQ
提取码:nuli