Kubernetes Taint(污点) 和 Toleration(容忍)

Author:rab
目录
-
- 前言
- 一、Taint(污点)
-
- 1.1 概述
- 1.2 查看节点 Taint
- 1.3 标记节点 Taint
- 1.4 删除节点 Taint
- 二、Toleration(容忍)
前言
Kubernetes 中的污点(Taint)和容忍(Toleration)是用于调度和管理容器工作负载的重要概念,特别是在多节点集群中。它们允许你指定哪些节点可以承载哪些 Pod,并控制 Pod 在哪些节点上可以运行。
说白了,污点就是故意给某个节点服务器上设置个污点参数,那么你就能让生成 Pod 的时候使用相应的参数去避开有污点参数的 Node 服务器。而容忍则是当资源不够用的时候,即使这个 Node 服务器上有污点,那么只要 Pod 的 yaml 配置文件中写了容忍参数,最终 Pod 还是会容忍的生成在该污点服务器上,Master 节点是默认为 NoSchedule。
一、Taint(污点)
1.1 概述
污点是一种属性,它被赋予一个 Kubernetes 节点,表示该节点有一些特定的限制或条件。节点上的污点可以阻止不具备相应容忍的 Pod 在上面运行。污点可以用于标记节点,以确保只有满足某些条件的 Pod 能够被调度到该节点上。例如,你可以为某个节点设置一个污点,要求只有具备特定标签或硬件要求的 Pod 才能在该节点上运行。
污点的一般格式如下:
key=value:effect
key是污点的名称。value是与污点相关的值,通常为空字符串,表示没有特定值要求。effect可以是NoSchedule、PreferNoSchedule或NoExecute。NoSchedule表示禁止 Pod 被调度到有该污点的节点上(这是 K8s 集群 Master 节点默认的污点效果);PreferNoSchedule表示不鼓励调度到有该污点的节点,但如果没有其他选择,仍然可以调度;NoExecute表示已经在节点上运行的 Pod 在后续不满足污点条件时将被驱逐。
1.2 查看节点 Taint
1、首先获取节点信息
kubectl get node

2、查看某个节点 Taint(污点)
比如我们查看 master 节点的污点情况。
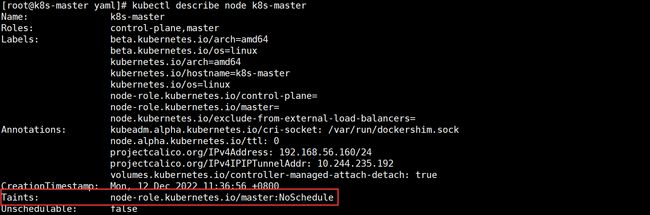
kubectl describe node k8s-master
# 重点关注Taints即可,如图,默认情况下master节点有污点,且为node-role.kubernetes.io/master:NoSchedule
# 这个污点的目的是防止普通的工作负载 Pod 被调度到主节点上
# 以确保主节点仅用于集群管理任务和控制面组件(如etcd、kube-scheduler、kube-controller-manager等)的运行
我们再来看看 worker 节点的污点情况。
kubectl describe node k8s-work1
# 我们会发现,默认情况下,worker节点是没有污点的()

1.3 标记节点 Taint
1、首先给节点打标签
比如将 k8s-work1 节点标签为 GPU 的节点
kubectl label nodes k8s-work1 hardware-type=GPU
查看节点标签
kubectl get node --show-labels

2、添加 GPU 污点
接下来,为带有 GPU 资源的节点添加 GPU 污点,以确保只有具有 GPU 容忍的 Pod 被调度到这个节点上。创建一个 GPU 污点的 YAML 文件如下:
vim nodeTaint.yml
apiVersion: v1
kind: Node
metadata:
name: k8s-work1
spec:
taints:
- key: hardware-type
value: GPU
effect: NoSchedule
# 说明
# key:即节点标签的key
# value:即节点标签的value
# effect:污点效果(NoSchedule或PreferNoSchedule或NoExecute)
或通过命令添加污点也是一样的。
kubectl taint nodes k8s-work1 hardware-type=GPU:NoSchedule
3、创建 GPU 容忍的 Pod
现在,我们可以创建一个需要 GPU 资源的 Pod,并为它添加 GPU 容忍。
vim nodeTaintPod.yml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: nginx
image: nginx
tolerations:
- key: hardware-type
operator: Equal
value: GPU
effect: NoSchedule
这个 YAML 文件定义了一个名为 gpu-pod 的 Pod,它包含一个容器,该容器需要 GPU 资源。然后在 tolerations 部分指定了 GPU 容忍,以匹配节点上的 GPU 污点。
创建 Pod:
kubectl apply -f nodeTaintPod.yml
现在,只有具有 GPU 容忍的 Pod 才能被调度到带有 GPU 污点的节点上,以确保 GPU 资源得到合理的分配。其他普通的 Pod 不会被调度到这个节点上。
验证:
kubectl get pod -owide

这是一个简单的示例,演示了如何使用污点和容忍来满足特定的硬件要求。你可以根据自己的需求创建不同类型的污点和容忍来管理 Pod 的调度。
那如何将 gpu-pod 驱逐出该节点呢?包括在 work1 节点上的所有 Pod
答案:我们只需要将 work1 节点打上 NoExecute 污点即可。
此时,但凡不能容忍的 Pod 都会脱离该节点,并在其他 work 节点新起 Pod。
kubectl taint nodes k8s-work1 hardware-type=GPU:NoExecute
# 如下图,原本work1节点上的Pod已经全部转移到work2节点上了

1.4 删除节点 Taint
删除方法很简单,就是在添加污点指令的末尾加个-号即可:
kubectl taint nodes k8s-work1 hardware-type=GPU:NoExecute-

此时该节点的污点已经被删除,那之前原本在该节点上的运行的 Pod 会恢复回来吗?答案是:不会,但是可以正常的运行其他普通 Pod 了。
二、Toleration(容忍)
容忍其实在上面我们已经提到了,这里在简单说一下。
Toleration 配置方式:
1、方式一
...
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
...
2、方式二
...
tolerations:
- key: "key"
operator: "Exists"
effect: "NoSchedule"
注意以下两种情况:
如果一个 Toleration 的 key 为空且 operator 为 Exists,表示这个 Toleration 与任意的 key、value 和 effect 都匹配,即这个Toleration 能容忍任意的 Taint:
...
tolerations:
- operator: "Exists"
...
如果一个 Toleration 的 effect 为空,则 key 与之相同的相匹配的 Taint 的 effect 可以是任意值:
...
tolerations:
- key: "key"
operator: "Exists"
...
说明:
Kubernetes 会自动给 Pod 添加一个 key 为 node.kubernetes.io/not-ready 的 Toleration 并配置 tolerationSeconds=300,同样也会给 Pod 添加一个 key 为 node.kubernetes.io/unreachable 的 Toleration 并配置 tolerationSeconds=300,除非用户自定义 key,否则会采用这个默认设置。
如果一个使用了很多本地状态的应用程序在网络断开时,仍然希望停留在当前节点上运行一段时间,愿意等待网络恢复以避免被驱逐。在这种情况下,Pod 的 Toleration 可以这样配置:
...
tolerations:
- key: "node.alpha.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
...
此时,这个 Pod 就不会像普通 Pod 那样立即被驱逐,而是再等上 6000 秒才被删除(驱逐)。
—END