实验——神经网络手写字符识别
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、实验目的及原理
- 实验目的
- 实验原理
- 二、实验内容
前言
一、实验目的及原理
(一)实验目的
1.深入理解卷积神经网络中的核心基础,认识卷积层、池化层、全连接层在卷积神经 网络中扮演的角色、实现的具体功能和工作原理。
2.熟悉简单的 CNN 模型,能搭建简单卷积神经网络模型,并能用卷积神经网络架构 对输入的数据进行处理特征提取,训练,从而能对数据输入的数据进行预测分类。
3.掌握 pytorch 的核心库 torch 和 torchvision 的常用的函数、方法和类的使用。
4. 深入理解手写字符识别代码,进一步掌握神经网络正向、反向传播训练流程。
(二)实验原理
1. 卷积神经网络的核心基础涉及卷积层、池化层和全连接层;
卷积层:主要作用是对输入的数据进行特征提取,完成改功能的是卷积层中的卷积核;
池化层:为了控制数据体的大小,通常,在连续的卷积层之间会周期性地插入一个池化 层。这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。 池化层使用 MAX 操作(不一定非要 MAX Pooling 也可以 mean 等等,你喜欢),对输入数 据体的每一个深度切片独立进行操作,改变它的空间尺寸。 全连接层:主要作用是将输入图像在经过卷积和池化操作后提取的特征进行压缩,并且 根据压缩特征完成模型的分类功能。
2. Torchvision 包的主要功能是实现数据的处理、导入和预览等,如果需要对计算机视觉 的相关问题进行处理,可以借用在 torchvisio 包中提供的大量的类来完成相应的工作。
二、实验内容:
import torch
import torchvision
from torchvision import datasets, transforms
from torch.autograd import Variable
import matplotlib.pyplot as plt
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5],std=[0.5])])
data_train = datasets.MNIST(root = "./data/",
transform=transform,train = True,
download=True)
data_test = datasets.MNIST(root="./data",
transform=transform,
train = False)
data_loader_train = torch.utils.data.DataLoader(dataset=data_train,
batch_size=64,
shuffle = True)
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size = 64,
shuffle = True)
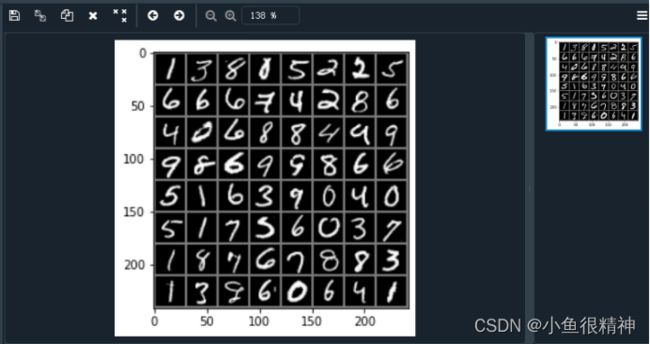
images, labels = next(iter(data_loader_train))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5]
mean = [0.5]
img = img*std+mean
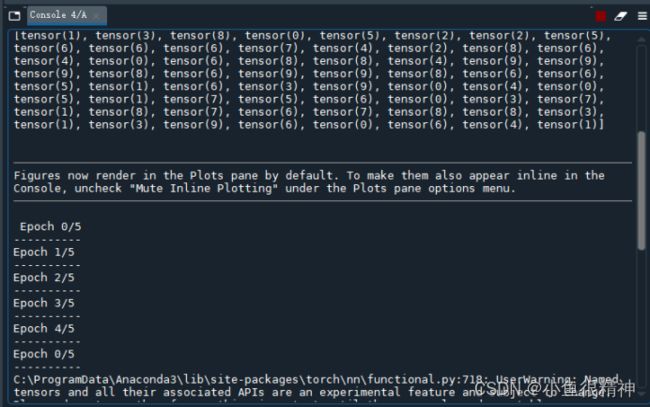
print([labels[i] for i in range(64)])
plt.imshow(img)
plt.show()
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.convl=torch.nn.Sequential(
torch.nn.Conv2d(1,64,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.Conv2d(64,128,kernel_size=3,stride=1,padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(stride=2,kernel_size=2))
self.dense=torch.nn.Sequential(
torch.nn.Linear(14*14*128,1024),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(1024, 10))
def forward(self,x):
x = self.convl(x)
x = x.view(-1, 14*14*128)
x = self.dense(x)
return x
model = Model()
cost = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
n_epochs = 5
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0
print("Epoch {}/{}".format(epoch, n_epochs))
print("-"*10)
for epoch in range(n_epochs):
running_loss = 0.0
running_correct = 0
print("Epoch {}/{}".format(epoch, n_epochs))
print("-"*10)
for data in data_loader_train:
X_train, y_train = data
X_train, y_train = Variable(X_train),Variable(y_train)
outputs = model(X_train)
_, pred = torch.max(outputs.data, 1)
optimizer.zero_grad()
loss = cost(outputs, y_train)
loss.backward()
optimizer.step()
running_loss += loss.data
running_correct += torch.sum(pred == y_train.data)
testing_correct = 0
for data in data_loader_test:
X_test, y_test = data
X_test, y_test = Variable(X_test),Variable(y_test)
outputs = model(X_test)
_, pred = torch.max(outputs.data, 1)
testing_correct += torch.sum(pred == y_test.data)
print("Loss is:{:,4f},Train Accuracy is:{:.4f}%, Test Accuracy is:{:.4f}".format(running_loss/len(data_train),100*running_correct/len(data_train),100*testing_correct/len(data_test)))
data_loader_test = torch.utils.data.DataLoader(dataset=data_test,
batch_size = 4,
shuffle = True)
X_test,y_test = next(iter(data_loader_test))
inputs = Variable(X_test)
pred = model(inputs)
_,pred = torch.max(pred,1)
print("predict Label is:", [i for i in pred.data])
print("Real Label is:",[i for i in y_test])
img = torchvision.utils.make_grid(X_test)
img = img.numpy().transpose(1,2,0)
std = [0.5,0.5,0.5]
mean = [0.5,0.5,0.5]
img = img*std+mean
plt.imshow(img)结果: