剑指offer刷题全纪录
目录
技巧总结:
1.找出数组中重复的数字
不修改数组找出重复的数字(*)
2.二维数组中查找
3.替换空格
4.从尾到头打印链表
5.前序中序遍历建树
6.中序遍历下一个节点
7.两个栈来实现一个队列
8.斐波那契数列
跳台阶
变态跳台阶
矩形覆盖
9.旋转数组的最小数字(***)
下面两题为DFS的应用
10.矩阵中的路径(*)
11.机器人的运动范围
12.割绳子(*)
位运算
11.二进制中1的个数(*)
延伸:判断一个数是不是2的整数次方
延伸:判断两数二进制位有多少位不同(*)
12.数值的整数次方计算
13.打印1到最大n位数(*)
14.O(1)时间删除链表节点
删除链表中重复的节点
15.正则表达式(*)
13.调整数组顺序使得奇数位于偶数前面(***)
14.链表中倒数第k个结点
15.链表中环的入口结点(*)
16.反转链表
17.合并两个排序链表
18.树的子结构(***)
19.二叉树的镜像
对称的二叉树
20.顺时针打印矩阵(****)
21.包含min函数的栈
22.栈的压入、弹出序列(**)
23.二叉树层次遍历
按之字形顺序打印二叉树
24.二叉搜索树的后序遍历序列(***)
25.二叉树中和为某一值的路径(***)
26.复杂链表的复制(*)
27.二叉搜索树与双向链表(*)
28.序列化二叉树(****)
29.有重复的字符串的全排列(*)
有重复的字符串的组合(子集合)(**)
第五章 优化时间和空间效率
30.数组中出现次数超过一半的数字
31.最小k个数
32.数据流中的中位数(****)
33.连续子数组的最大和(*)
34.整数中1出现的次数(从1到n整数中1出现的次数)(*)
数字序列中某一位的数字(*)
45.把数组排成最小的数
46.把数字翻译成字符串(*)
47.礼物的最大价值
48.最长不含重复字符的子字符串
49.丑数(*)
50.第一个只出现一次的字符
从第一个字符串中删除在第二个字符串中出现的字符
字符流中第一个不重复的字符
51.数组中的逆序对(***)
52.两个链表的第一个公共结点
第六章
53.数字在排序数组中出现的次数
0到n-1中缺失的数字(*)
数组中数值和下标相等的元素
54.二叉搜索树的第k个节点
55.二叉树深度
平衡二叉树 ( *** )
56.数组中只出现一次的数字(**)
数组中其他数字均出现3次,有1个数字只出现1次,找出该数(**)
57.和为S的两个数字
和为S的连续正数序列(**)
58.左旋转字符串
翻转单词顺序列(**)
59.滑动窗口的最大值(*)
60.n个骰子的点数(**)
61.扑克牌中顺子
65.不用加减乘除做加法
66.构建乘积数组
64.求1+2+…+n
数组中重复的数字
表示数值的字符串(*)
删除链表中重复的结点
最低公共祖先
普通二叉树
非递归写法
有指向父节点的二叉树
二叉搜索树
技巧总结:
问清楚问题的条件,比如是否是二叉树,还是二叉搜索树
考虑清楚边界条件,一定要记得判断
考虑清楚数据类型,比如 int 和 long long
传参尽量用引用或指针传递,提高效率
复杂大问题尽量化成小问题分析
1.找出数组中重复的数字
给定一个长度为 nn 的整数数组 nums,数组中所有的数字都在 0∼n−10∼n−1 的范围内。
数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。
请找出数组中任意一个重复的数字。
注意:如果某些数字不在 0∼n−10∼n−1 的范围内,或数组中不包含重复数字,则返回 -1;
样例
给定 nums = [2, 3, 5, 4, 3, 2, 6, 7]。
返回 2 或 3。思路:
修改数组的话,O(n)时间,O(1)空间即可实现
利用下标的性质
class Solution {
public:
int duplicateInArray(vector& nums) {
int n = nums.size(), i = 0, res = -1;
if(n < 2) return res;
while(i < n){
if(nums[i] > n-1 || nums[i] < 0) return -1;
if(nums[i] != i){
if(nums[nums[i]] != nums[i]){
swap(nums[i],nums[nums[i]]);
}
else{
res = nums[i];
i++;
}
}
else i++;
}
return res;
}
}; 不修改数组找出重复的数字(*)
二分查找,这题的秘诀是如果 i-m 的区间有重复,这个区间的数字计数会大于 (m-i+1)
时间复杂度:O(nlogn)
空间复杂度:O(1)
class Solution {
public:
int duplicateInArray(vector& nums) {
int n = nums.size();
if(n < 2) return 0;
int i = 1,j = n-1,cnt1 = 0,cnt2 = 0,mid;
while(i < j){
mid = (i+j)/2;
for(int k = 0;k < n;k++){
if(nums[k] >= i && nums[k] <= mid) cnt1++;
else if(nums[k] <= j && nums[k] > mid) cnt2++;
}
// 注意这里必须跳出,因为i和j的赋值是mid,没有+1,-1,不判断会进死循环
if(i+1 == j) return cnt1>cnt2? i:j;
if(cnt1 > mid-i+1) j = mid;
else i = mid;
cnt1 = 0;
cnt2 = 0;
}
return i;
}
}; 2.二维数组中查找
在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
思路:这题可以从右上角或者左下角开始遍历,因为这样的位置,两个方向上呈现递增和递减
class Solution {
public:
bool Find(int target, vector > array) {
// 边界
if(array.empty() || array[0].empty()) return false;
int row = array.size(),col = array[0].size();
// 右上角开始
int i = 0,j = col-1;
while(i < row && j >= 0){
if(array[i][j] == target) return true;
if(array[i][j] > target) j--;
else if(array[i][j] < target) i++;
}
return false;
}
}; 3.替换空格
请实现一个函数,将一个字符串中的每个空格替换成“%20”。例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy。
思路:
(1)字符串结束为‘\0’
(2)直接暴力做,时间复杂度为O(N*N),因为每次遇到空格,后面所有的都要移动
下面的时间复杂度为O(N),看书上讲解
1、遍历一次,获得字符串长度
2、计算新字符串长度,把空格替换为20%,此时长度增加blank_num*2,而不是3*!!!
二刷:char *str是使用下标访问的,这里是一个char数组?
class Solution {
public:
void replaceSpace(char *str,int length) {
if(!str || length <= 0) return;
int blank_num = 0,ori_idx = 0;
// 遍历一次,获得字符串长度
for(;str[ori_idx] != '\0';ori_idx++){
if(str[ori_idx] == ' ') blank_num++;
}
// 计算新字符串长度,把空格替换为20%,此时长度增加blank_num*2,而不是3*!!!
int new_idx = ori_idx + blank_num*2;
for(;ori_idx >= 0;ori_idx--){
if(str[ori_idx] != ' '){
str[new_idx--] = str[ori_idx];
}else{
str[new_idx--] = '0';
str[new_idx--] = '2';
str[new_idx--] = '%';
}
}
}
};没有长度时,使用resize
class Solution {
public:
string replaceSpaces(string &str) {
int ori_len = 0,len = 0;
for(int i = 0;i < str.size();i++){
if(str[i] == '\0') break;
if(str[i] == ' ') len += 3;
else len++;
ori_len++;
}
// 这里有个resize的过程!!!
str.resize(len);
len--;ori_len--;
for(int i = ori_len;i >= 0;i--){
if(str[i] == ' '){
str[len--] = '0';
str[len--] = '2';
str[len--] = '%';
}else{
str[len--] = str[i];
}
}
return str;
}
};相同思路:
合并两个有序数组,AB,使其成为一个有序数组,合并到A上
(1)如果从前往后合并,每次都要移动好多
(2)从后往前,从len(A)+len(B)的位置,开始放入
4.从尾到头打印链表
输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。
思路:用栈实现
/**
* struct ListNode {
* int val;
* struct ListNode *next;
* ListNode(int x) :
* val(x), next(NULL) {
* }
* };
*/
class Solution {
public:
vector printListFromTailToHead(ListNode* head) {
vector res;
stack s;
ListNode* cur = head;
while(cur){
s.push(cur->val);
cur = cur->next;
}
while(!s.empty()){
res.push_back(s.top());
s.pop();
}
return res;
}
}; 5.前序中序遍历建树
输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
思路:
递归,找到根节点后,不断左右递归划分建树
把构建二叉树这个大问题,分解成构建左右子树的两个小问题
注意这里左子树为l1+1,l1+i-l2,而不是l1+1到i-1,后面分割时,这个下标不一定是对起来的!!!
/**
* Definition for binary tree
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* reConstructBinaryTree(vector pre,vector vin) {
return helper(pre,0,pre.size()-1,vin,0,vin.size()-1);
}
TreeNode* helper(vector pre,int l1,int r1,vector vin,int l2,int r2){
if(l1 > r1 || l2 > r2) return NULL;
TreeNode *root = new TreeNode(pre[l1]);
int i = l2;
for(;i <= r2;i++){
if(vin[i] == pre[l1]) break;
}
// 注意这里左子树为l1+1,l1+i-l2,而不是l1+1到i-1,后面分割时,这个下标不一定是对起来的!!!
root->left = helper(pre,l1+1,l1+i-l2,vin,l2,i-1);
root->right = helper(pre,l1+i-l2+1,r1,vin,i+1,r2);
return root;
}
}; 6.中序遍历下一个节点
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode *father;
* TreeNode(int x) : val(x), left(NULL), right(NULL), father(NULL) {}
* };
*/
class Solution {
public:
TreeNode* inorderSuccessor(TreeNode* p) {
TreeNode* cur,*pre;
// 右子树存在,则为右子树最左节点
if(p->right){
cur = p->right;
while(cur->left){
cur = cur->left;
}
return cur;
}
else{
cur = p->father;
// p为根节点
if(!cur) return NULL;
// p为父节点左子节点
else if(p == cur->left) return cur;
// p为父节点右子节点
else{
pre = cur->father;
while(pre && cur == pre->right){
cur = pre;
pre = cur->father;
}
return pre;
}
}
}
};7.两个栈来实现一个队列
用两个栈来实现一个队列,完成队列的Push和Pop操作。 队列中的元素为int类型。
思路:
入队就入栈s1
出队,如果s2空,就把s1中的值,出栈进入s2,否则直接出栈s2即可
class Solution
{
public:
void push(int node) {
s1.push(node);
}
int pop() {
if(s2.empty()){
while(!s1.empty()){
s2.push(s1.top());
s1.pop();
}
}
int res = s2.top();
s2.pop();
return res;
}
private:
stack s1;
stack s2;
}; 8.斐波那契数列
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。
n<=39
class Solution {
public:
int Fibonacci(int n) {
int first = 0,second = 1;
int result = n;
for(int i = 2;i <= n;i++){
result = first+second;
first = second;
second = result;
}
return result;
}
};跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级。求该青蛙跳上一个n级的台阶总共有多少种跳法(先后次序不同算不同的结果)。
递归:
class Solution {
public:
int jumpFloor(int number) {
if(number == 1) return 1;
if(number == 2) return 2;
return jumpFloor(number-1)+jumpFloor(number-2);
}
};非递归:斐波那契
class Solution {
public:
int jumpFloor(int number) {
int first = 1,second = 2;
int result = number;
for(int i = 3;i <= number;i++){
result = first+second;
first = second;
second = result;
}
return result;
}
};变态跳台阶
一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
思路:
每次相当于可以在上一次的基础上,最开始加上1,或者最末尾加上一,所以这样产生的个数f(n) = 2*f(n-1)-1,当全部为1时,前后加一不变,所以要减去1
然后再加上1,加上的为一次跳n阶的方法,故最后为f(n) = 2*f(n-1)
class Solution {
public:
int jumpFloorII(int number) {
int res = 1;
for(int i = 2;i <= number;i++) res *= 2;
return res;
}
};矩形覆盖
我们可以用2*1的小矩形横着或者竖着去覆盖更大的矩形。请问用n个2*1的小矩形无重叠地覆盖一个2*n的大矩形,总共有多少种方法?
思路:
(1)第一个矩形竖着放,则剩下可放的方法为:f(n-1)
(2)第一个矩形横着放,则剩下可放的方法为:f(n-2)
故f(n) = f(n-1)+f(n-2)
class Solution {
public:
int rectCover(int number) {
int first = 1,second = 2;
int result = number;
for(int i = 3;i <= number;i++){
result = first+second;
first = second;
second = result;
}
return result;
}
};9.旋转数组的最小数字(***)
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。 输入一个非减排序的数组的一个旋转,输出旋转数组的最小元素。 例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。 NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
思路:二分法
进循环前判断 l 和 r 的大小,若 l 小于 r 说明是顺序的,无旋转
(1)注意:如果中间数字等于左边,等于右边,此时无法判断,只能顺序查找最小值
(2)否则中点与左边比较,如果中点数字大于等于左边,说明从l到mid是顺序的,让l=mid,继续循环
否则r=mid
class Solution {
public:
int minNumberInRotateArray(vector rotateArray) {
if(rotateArray.empty()) return 0;
int l = 0, r = rotateArray.size()-1,mid;
// 不满足下面条件,则未旋转
while(rotateArray[l] >= rotateArray[r]){
// l和r只相差1时,r指向的就是最小点,直接返回
if(l+1 == r) return rotateArray[r];
mid = (l+r)/2;
// l,r和mid的值相同时,只能顺序查找,注意!!!
if(rotateArray[l] == rotateArray[r] && rotateArray[l] == rotateArray[mid]){
return get_min(rotateArray);
}
// 这里的等于:l和mid相同情况,2222111
if(rotateArray[mid] >= rotateArray[l]) l = mid;
else r = mid;
}
// 未旋转直接返回最开始的值
return rotateArray[l];
}
// 顺序查找最小值
int get_min(vector rotateArray){
int min_num = rotateArray[0];
for(auto &num:rotateArray){
if(num < min_num) min_num = num;
}
return min_num;
}
}; 下面是更加精简的写法:
主要核心点就是判断是否是顺序的
class Solution {
public:
int minNumberInRotateArray(vector rotateArray) {
if(rotateArray.empty()) return 0;
int l = 0, r = rotateArray.size()-1,mid;
while(l < r){
// 顺序,直接返回最小一个数
if(rotateArray[l] < rotateArray[r]) return rotateArray[l];
mid = (l+r)/2;
// 注意,下面需要l = mid+1,因为最后返回的是l上的值,所以23412这种情况,需要mid+1
if(rotateArray[l] < rotateArray[mid]) l = mid+1;
else if(rotateArray[r] > rotateArray[mid]) r = mid;
// 左右中相等的情况,通过l++,来缩小范围,这样就不需要直接顺序找了
else l++;
}
return rotateArray[l];
}
}; 下面两题为DFS的应用
10.矩阵中的路径(*)
请设计一个函数,用来判断在一个矩阵中是否存在一条包含某字符串所有字符的路径。
路径可以从矩阵中的任意一个格子开始,每一步可以在矩阵中向左,向右,向上,向下移动一个格子。
如果一条路径经过了矩阵中的某一个格子,则之后不能再次进入这个格子。
注意:
- 输入的路径不为空;
- 所有出现的字符均为大写英文字母;
样例
matrix=
[
["A","B","C","E"],
["S","F","C","S"],
["A","D","E","E"]
]
str="BCCE" , return "true"
str="ASAE" , return "false"思路:
回溯法
(1)注意还原visited数组
(2)visited需要传地址符
class Solution {
public:
bool hasPath(vector>& matrix, string str) {
if(str.empty()) return true;
if(matrix.empty() || matrix[0].empty()) return false;
int m = matrix.size(), n = matrix[0].size();
vector> visited(m,vector(n,false));
for(int i = 0;i < m;i++){
for(int j = 0;j < n;j++){
if(find(matrix,visited,i,j,str,0)) return true;
}
}
return false;
}
bool find(vector>& matrix,vector>& visited,int i,int j, string str,int start){
if(start >= str.size()) return true;
if(i < 0 || j < 0 || i >= matrix.size() || j >= matrix[0].size() || visited[i][j] || matrix[i][j] !=str[start]) return false;
visited[i][j] = true;
if(find(matrix,visited,i-1,j,str,start+1) || find(matrix,visited,i+1,j,str,start+1) || find(matrix,visited,i,j-1,str,start+1) ||find(matrix,visited,i,j+1,str,start+1)){
return true;
}
// 注意这里要还原!!!否则会影响结果
else{
visited[i][j] = false;
return false;
}
}
}; 11.机器人的运动范围
地上有一个 mm 行和 nn 列的方格,横纵坐标范围分别是 0∼m−10∼m−1 和 0∼n−10∼n−1。
一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格。
但是不能进入行坐标和列坐标的数位之和大于 kk 的格子。
请问该机器人能够达到多少个格子?
样例1
输入:k=7, m=4, n=5
输出:20
样例2
输入:k=18, m=40, n=40
输出:1484
解释:当k为18时,机器人能够进入方格(35,37),因为3+5+3+7 = 18。
但是,它不能进入方格(35,38),因为3+5+3+8 = 19。class Solution {
public:
int cnt = 0;
int movingCount(int threshold, int rows, int cols){
if(threshold < 0 || rows <= 0 || cols <= 0) return 0;
vector> visited(rows,vector(cols,false));
move(visited,0,0,threshold);
return cnt;
}
// 注意这里visited需要传地址符!!!
void move(vector> &visited,int i,int j,int threshold){
if(i < 0 || j < 0 || i >= int(visited.size()) || j >= int(visited[0].size()) || visited[i][j]) return;
if(getSum(i)+getSum(j) <= threshold){
cnt++;
visited[i][j] = true;
move(visited,i+1,j,threshold);
move(visited,i-1,j,threshold);
move(visited,i,j+1,threshold);
move(visited,i,j-1,threshold);
}
}
int getSum(int n){
int sum = 0;
while(n){
sum += n%10;
n /= 10;
}
return sum;
}
}; 12.割绳子(*)
题目要求:
- 给你一根长度为n的绳子,请把绳子剪成m段(m , n )都是正整数,(n>1&m>1)
- 每段绳子的长度为k[0],k[1],k[2],...,k[m]。请问k[0]k[1]k[2]...k[m]的最大值。
- 例如绳子是长度为8,我们把它剪成的长度分别为2,3,3的三段,此时得到的最大的乘积是18。
思路一:动态规划
剪第一刀时,有n-1种剪的可能,剪出来第一段绳子可能长尾1,2,...,n-1 。因此f(n) = max(f[i] * f[n-i])
先从最低处开始计算乘积并将每个数可以剪切后得到的成绩最大值进行存储。当计算后面的值的时候利用已经存储好的最大值,计算所有可能的结果并保留最大的。时间复杂度O(n*n)空间复杂度O(n)
dp[i]:长度为i时的最长乘积
class Solution {
public:
int getMax(int length){
if(length < 2) return 0;
if(length == 2) return 1;
if(length == 3) return 2;
int max_res[length+1];
max_res[0] = 0;
max_res[1] = 1;
// 对于2和3,最大乘积为1和2,故这里使用他们自身,因为要被后面的作为基础使用
// 3之后,最大乘积都大于它本身,只需要记录最大乘积即可
max_res[2] = 2;
max_res[3] = 3;
for(int i = 4;i <= length;i++){
int res = 0;
for(int j = 0;j <= i/2;j++){
res = max(res,max_res[j]*max_res[i-j]);
}
max_res[i] = res;
}
return max_res[length];
}
};
int main(){
Solution s = Solution();
int res = s.getMax(8);
cout << res << endl;
}思路2:从原理出发
当(n>=5)时,存在(2(n-2))>n和(3(n-3))>n
当n>=5 时有 3(n-3)>=2(n-2)
我们应该尽量剪出3来得到最大值。
但是要注意当长度为4时,2*2最大
时间复杂度与空间复杂度都是O(1)
class Solution {
public:
int getMax(int length){
if(length < 2) return 0;
if(length == 2) return 1;
if(length == 3) return 2;
int count_3 = length/3;
if(length - count_3*3 == 1) count_3--;
int count_2 = (length-3*count_3)/2;
return pow(3,count_3)*pow(2,count_2);
}
};位运算
位运算注意:
1.n = n << 1,需要用n去接,这个不是直接改变n
2.1不断的左移,最后会把1移出,使其全部为0
11.二进制中1的个数(*)
输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
思路:
(1)只有正数时,可以通过右移该数 & 1,来逐个比较各个位置是否为1
class Solution {
public:
int NumberOf1(int n) {
int flag = 1,count = 0;
while(n){
if(n & flag) count++;
n = n >> 1;
}
return count;
}
};(2)当存在负数时
右移该数,左边补的是符号位,故左边一直补1,会陷入死循环
通过将该数 & 1不断左移,来计数
class Solution {
public:
int NumberOf1(int n) {
int flag = 1,count = 0;
while(flag){
if(n & flag) count++;
flag = flag << 1;
}
return count;
}
};上述的时间复杂度为:O(n)
改进:有一种时间复杂度为数字中1的个数的
每次n & (n-1)
n & (n-1)得到结果是,改二进制数最右边1变为0,很多题都可以用这个思路
如:0011001
0011001 & 0011000 = 0011000
0011000 & 0010111 = 0010000
0010000 & 0001111 = 0000000
刚好3次
class Solution {
public:
int NumberOf1(int n) {
int count = 0;
while(n){
count++;
n = n & (n-1);
}
return count;
}
};延伸:判断一个数是不是2的整数次方
思路:
2:10
4:100
8:1000
故2的整数次方的数字,二进制只有1个1
只需要一次n & (n-1)即可
class Solution {
public:
bool judge(int n) {
return n & (n-1);
}
};延伸:判断两数二进制位有多少位不同(*)
输入两个整数m和n,计算需要改变m的二进制表示中的多少位,才能得到n
思路:如1010和1101,区别的共3位
故先做异或,然后统计异或的结果中有多少个1
class Solution {
public:
int diff(int m,int n){
// 异或结果去计算1的个数
return number_of_1(m^n);
}
int number_of_1(int n){
int count = 0;
while(n){
count++;
n = n & (n-1);
}
return count;
}
};12.数值的整数次方计算
给定一个double类型的浮点数base和int类型的整数exponent。求base的exponent次方。
注意:
(1)对于边界情况的处理:
exponent为负数和为0的情况
0的负数次方非法(注意!!!),也要注意(下面代码里没有体现)
(2)浮点数的比较
c++中除了可以表示为2的幂次以及整数数乘的浮点数可以准确表示外,其余的数的值都是近似值。
例如,1.5可以精确表示,因为1.5 = 3*2^(-1);然而3.6却不能精确表示,因为它并不满足这一规则。
所以在比较的时候需要用一个很小的数值来进行比较。(二分法的思想)当二者之差小于这个很小的数时,就认为二者是相等的了,而不能直接用== 或!=比较。这个很小的数,称为精度。
精度由计算过程中需求而定。比如一个常用的精度为1e-6.也就是0.000001.
所以对于两个浮点数a,b,如果要比较大小,那么常常会设置一个精度
如果fabs(a-b)<=1e-6,那么就是相等了。 fabs是求浮点数绝对值的函数。
类似的 判断大于的时候,就是if(a>b && fabs(a-b)>1e-6)。
判断小于的时候,就是if(a
思路1:
幂运算是非常常见的一种运算,求取a^n,最容易想到的方法便是通过循环逐个累乘,其复杂度为O(n)
class Solution {
public:
double Power(double base, int exponent) {
if(equal(base,0.0)) return 0;
if(exponent == 0) return 1;
double res = 1;
for(int i = 1;i <= abs(exponent);i++){
res *= base;
}
return exponent > 0? res:1.0/res;
}
// 判断浮点数是否相等
bool equal(double a,double b){
if(abs(a-b) <= 0.0000001) return true;
else return false;
}
};思路2:
这在很多时候是不够的,所以我们需要一种算法来优化幂运算的过程。
快速幂——反复平方法
该怎样去加速幂运算的过程呢?既然我们觉得将幂运算分为n步进行太慢,那我们就要想办法减少步骤,把其中的某一部分合成一步来进行。
(1)如果n能被2整除
那我们可以先计算一半,得到a^(n/2)的值,再把这个值平方得出结果。这样做虽然有优化,但优化的程度很小,仍是线性的复杂度。
(2)如果我们能找到2^k == n
那我们就能把原来的运算优化成((((a^2)^2)^2)...),只需要k次运算就可以完成,效率大大提升。可惜的是,这种条件显然太苛刻了,适用范围很小。
不过这给了我们一种思路,虽然我们很难找到2^k == n,但我们能够找到2^k1 + 2^k2 + 2^k3 +......+ 2^km == n。这样,我们可以通过层层递推,在很短的时间内求出各个项的值。可是又有新的问题出现了,我们并不清楚k1、k2...km具体的值是多少,对于不同的n,有不同分法,有没有一种规则能把这些分法统一起来。
我们都学习过进制与进制的转换,知道一个b进制数的值可以表示为各个数位的值与权值之积的总和。比如,2进制数1001,它的值可以表示为10进制的1*2^3 + 0*2^2 + 0*2^1 + 1*2^0,即9。这完美地符合了上面的要求。可以通过2进制来把n转化成2^km的序列之和,而2进制中第i位(从右边开始计数,值为1或是0)则标记了对应的2^(i - 1)是否存在于序列之中。譬如,13为二进制的1101,他可以表示为2^3 + 2^2 + 2^0,其中由于第二位为0,2^1项被舍去。
如此一来,我们只需要计算a、a^2、a^4、a^8......a^(2^km)的值(这个序列中的项不一定都存在)并把它们乘起来即可完成整个幂运算。借助位运算的操作,可以很方便地实现这一算法,其复杂度为O(logn)。
举例:
3的13次
13的二进制为1101
cur 3
cur 3的2次
cur 3的4次
cur 3的8次
为1的位置乘起来,故最后为3 * 3的4次 * 3的8次 = 3的13次
class Solution {
public:
double Power(double base, int exponent) {
if(equal(base,0.0)) return 0;
if(exponent == 0) return 1;
double res = 1,cur = base;
// 将负数的exponent转成正数
int pos_exponent = exponent;
if(exponent < 0) pos_exponent = -exponent;
// 下面就是快速幂的代码
while(pos_exponent){
// 该位为1时
if(pos_exponent & 1){
res *= cur;
}
cur *= cur;
pos_exponent >>= 1;
}
return exponent > 0? res:1.0/res;
}
// 判断浮点数是否相等
bool equal(double a,double b){
if(abs(a-b) <= 0.0000001) return true;
else return false;
}
};13.打印1到最大n位数(*)
思路:
注意大数问题,这里用dfs生成string大数,然后打印
#include
#include
using namespace std;
// 前面0的部分不打印
void print(string num){
int i = 0;
while(i < num.size() && num[i] == '0') i++;
for(;i < num.size();i++){
cout << num[i];
}
cout << endl;
}
// 使用dfs组合可能的大数排列
void dfs(int n,string num){
if(n == 0){
print(num);
return;
}
for(int i = 0;i < 10;i++){
dfs(n-1,num+to_string(i));
}
}
void printNumbers(int n){
if(n <= 0){
return;
}
dfs(n,"");
}
int main(){
printNumbers(3);
} 14.O(1)时间删除链表节点
下面没有考虑尾结点情况,如果有尾结点,需要O(n)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
void deleteNode(ListNode* node) {
ListNode* p = node->next;
node->val = p->val;
node->next = p->next;
delete p;
}
};删除链表中重复的节点
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留。
样例1
输入:1->2->3->3->4->4->5
输出:1->2->5
样例2
输入:1->1->1->2->3
输出:2->3思路:
注意删除头结点和删除尾结点情况
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* head) {
if(!head || !head->next) return head;
ListNode* dummy_head = new ListNode(-1),*pre = dummy_head,*cur;
dummy_head->next = head;
while(pre->next){
cur = pre->next;
// 有重复
if(cur->next && cur->next->val == cur->val){
while(cur->next && cur->next->val == cur->val){
cur = cur->next;
}
pre->next = cur->next;
}else{
// 无重复
pre = cur;
}
}
return dummy_head->next;
}
};15.正则表达式(*)
请实现一个函数用来匹配包括'.'和'*'的正则表达式。
模式中的字符'.'表示任意一个字符,而'*'表示它前面的字符可以出现任意次(含0次)。
在本题中,匹配是指字符串的所有字符匹配整个模式。
例如,字符串"aaa"与模式"a.a"和"ab*ac*a"匹配,但是与"aa.a"和"ab*a"均不匹配。
样例
输入:
s="aa"
p="a*"
输出:true
class Solution {
public:
bool isMatch(string s, string p) {
// cout << s << ' ' << p << endl;
// p为空
if(p.empty()) return s.empty();
// s为空
if(s.empty()){
if(p.size()%2 != 0 || p[1] != '*') return false;
else return isMatch(s,p.substr(2,p.size()-2));
}
// 下一个不是‘*’
if(p.size() == 1 || p[1] != '*'){
if(p[0] == '.' || s[0] == p[0]){
return isMatch(s.substr(1,s.size()-1),p.substr(1,p.size()-1));
}
else return false;
}
// 下一个是‘*’
else{
if(p[0] == '.' || s[0] == p[0]){
return isMatch(s,p.substr(2,p.size()-2)) || isMatch(s.substr(1,s.size()-1),p);
}
else return isMatch(s,p.substr(2,p.size()-2));
}
}
};13.调整数组顺序使得奇数位于偶数前面(***)
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的位置可以改变。
class Solution {
public:
void reOrderArray(vector &array) {
if(array.size() < 2) return;
int l = 0,r = array.size()-1;
while(l < r){
while(l < r && array[l]&1) l++;
while(l < r && !(array[r]&1)) r--;
swap(array[l],array[r]);
l++;r--;
}
}
}; 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
思路:参考冒泡法
只要前偶后奇,就把奇数与偶数交换位置
举例:
i = 0时,一次j的遍历:
22232
22322
23222
32222
i = 1,继续...
时间复杂度:O(N*N)
class Solution {
public:
void reOrderArray(vector &array) {
// 类似冒泡排序,每次把一个奇数交换到最前面
for(int i = 0;i < array.size();i++){
for(int j = array.size()-1;j > i;j--){
// 前偶后奇,就交换位置,这样一次可以把一个奇数交换到最前面
if(!(array[j-1]&1) && (array[j]&1)){
swap(array[j-1],array[j]);
}
}
}
}
}; 14.链表中倒数第k个结点
输入一个链表,输出该链表中倒数第k个结点。
注意:
(1)传入指针为空指针(链表题都要注意这个判断)
(2)k为0的时候返回NULL,不要遗漏。因为正常的倒数,都是从倒数第一开始
(3)当k长度大于链表长度时,返回NULL
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* head, unsigned int k) {
// 解决k=0和传入为空指针的问题
if(k == 0 || !head) return NULL;
ListNode *cur = head,*k_next_node = head;
for(int i = 1;i < k && k_next_node;i++){
k_next_node = k_next_node->next;
}
// k大于链表长度的判断
if(!k_next_node) return NULL;
while(k_next_node->next){
k_next_node = k_next_node->next;
cur = cur->next;
}
return cur;
}
};相似题目:
找到链表中点
15.链表中环的入口结点(*)
给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
思路:
找到环的起始点
首先我们看下面这张图:
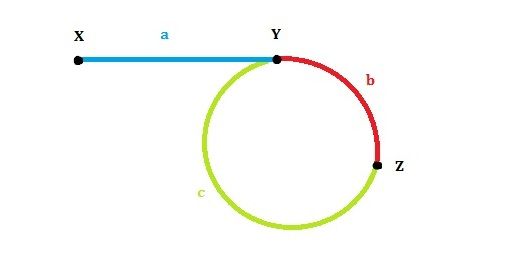
设:链表头是X,环的第一个节点是Y,slow和fast第一次的交点是Z。各段的长度分别是a,b,c
第一次相遇时slow走过的距离:a+b
fast走过的距离:a+b+n(b+c)(第一次相遇之前,fast可能已经绕了好几圈)
因为fast的速度是slow的两倍,所以fast走的距离是slow的两倍,有 2(a + b) = a + b + n(b+c) ==> a = (n-1)(b+c) + c , where n>=1(这个结论很重要!)。
那么让两个指针分别从X和Z开始走,每次走一步,那么正好会在Y相遇!也就是环的第一个节点。
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* EntryNodeOfLoop(ListNode* pHead){
// 边界:肯定没有环
if(!pHead || !pHead->next|| !pHead->next->next) return NULL;
ListNode *slow = pHead,*fast = pHead;
while(slow && fast->next){
slow = slow->next;
fast = fast->next->next;
if(slow == fast) break;
}
// 没有环
if(!slow) return NULL;
slow = pHead;
while(slow != fast){
slow = slow->next;
fast = fast->next;
}
return slow;
}
};16.反转链表
输入一个链表,反转链表后,输出新链表的表头。
思想:
注意边界条件(输入为NULL或者只有一个节点)
使用虚拟头节点,这样写起来比较轻松
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* ReverseList(ListNode* phead) {
// 边界
if(!phead || !phead->next) return phead;
ListNode* dummy_head = new ListNode(-1);
ListNode* cur = phead,*temp;
dummy_head->next = phead;
while(cur->next){
temp = cur->next;
cur->next = cur->next->next;
temp->next = dummy_head->next;
dummy_head->next = temp;
}
return dummy_head->next;
}
};17.合并两个排序链表
输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。
思路:
用一个虚拟新头结点
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* Merge(ListNode* phead1, ListNode* phead2){
ListNode* cur1 = phead1,* cur2 = phead2,*temp;
ListNode* dummy_head = new ListNode(-1);
ListNode* dummy_cur = dummy_head;
while(cur1 && cur2){
if(cur1->val <= cur2 ->val){
temp = cur1;
cur1 = cur1->next;
}else{
temp = cur2;
cur2 = cur2->next;
}
dummy_cur->next = temp;
dummy_cur = dummy_cur->next;
}
// 注意下面是if,不是while
if(cur1) dummy_cur->next = cur1;
if(cur2) dummy_cur->next = cur2;
return dummy_head->next;
}
};18.树的子结构(***)
输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)
注意边界条件!
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
bool HasSubtree(TreeNode* pRoot1, TreeNode* pRoot2){
if(!pRoot1 || !pRoot2) return false;
// 这个必须写在这里,而不是下面,这里每一次pRoot2保证是一棵完整的树
return does_tree1_has_tree2(pRoot1,pRoot2) || HasSubtree(pRoot1->left,pRoot2)|| HasSubtree(pRoot1->right,pRoot2);
}
bool does_tree1_has_tree2(TreeNode* pRoot1, TreeNode* pRoot2){
//边界不要遗漏
if(!pRoot2) return true;
if(!pRoot1) return false;
// 直接返回false,然后从上面重新开始,如果在这里调用递归,pRoot2不是一课完整的树了
if(pRoot1->val != pRoot2->val) return false;
else return does_tree1_has_tree2(pRoot1->left,pRoot2->left) && does_tree1_has_tree2(pRoot1->right,pRoot2->right);
}
};19.二叉树的镜像
操作给定的二叉树,将其变换为源二叉树的镜像。
二叉树的镜像定义:源二叉树
8
/ \
6 10
/ \ / \
5 7 9 11
镜像二叉树
8
/ \
10 6
/ \ / \
11 9 7 5思路:递归
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
void Mirror(TreeNode *pRoot) {
// 边界
if(!pRoot || (!pRoot->right && !pRoot->left)) return;
// 交换左右子树
TreeNode *temp;
temp = pRoot->right;
pRoot->right = pRoot->left;
pRoot->left = temp;
// 递归
Mirror(pRoot->left);
Mirror(pRoot->right);
}
};可以直接swap
class Solution {
public:
void Mirror(TreeNode *pRoot) {
if(!pRoot || (!pRoot->right && !pRoot->left)) return;
swap(pRoot->right,pRoot->left);
Mirror(pRoot->left);
Mirror(pRoot->right);
}
};对称的二叉树
请实现一个函数,用来判断一颗二叉树是不是对称的。注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的。
思路:
递归判断左右子树是否对称
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
class Solution {
public:
bool isSymmetrical(TreeNode* pRoot){
if(!pRoot) return true;
return isSym(pRoot->left,pRoot->right);
}
bool isSym(TreeNode* p1,TreeNode* p2){
if(!p1 && !p2) return true;
// 注意!p1 || !p2 的判断,不然会出现非法情况!!!!!!
if(!p1 || !p2 || p1->val != p2->val) return false;
return isSym(p1->left,p2->right) && isSym(p1->right,p2->left);
}
};20.顺时针打印矩阵(****)
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字,例如,如果输入如下4 X 4矩阵: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 则依次打印出数字1,2,3,4,8,12,16,15,14,13,9,5,6,7,11,10.
边界考虑清楚
class Solution {
public:
vector printMatrix(vector > matrix) {
vector res;
if(matrix.empty() || matrix[0].empty()) return res;
int m = matrix.size(),n = matrix[0].size();
// 注意i需要满足两个条件:i <= (m-1)/2 && i <= (n-1)/2,不要遗漏
for(int i = 0;i <= (m-1)/2 && i <= (n-1)/2;i++){
for(int j = i;j <= n-1-i;j++){
res.push_back(matrix[i][j]);
}
// 必须有两行
if(m-1-i > i){
for(int j = i+1;j <= m-1-i;j++){
res.push_back(matrix[j][n-1-i]);
}
}
// 必须有两行两列
if(m-1-i > i && n-1-i > i){
for(int j = n-2-i;j >= i;j--){
res.push_back(matrix[m-1-i][j]);
}
}
// 必须有三行两列
if(m-1-i > i+1 && n-1-i > i){
for(int j = m-2-i;j >= i+1;j--){
res.push_back(matrix[j][i]);
}
}
}
return res;
}
}; 21.包含min函数的栈
定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1))。
思路:
这题很巧妙,建立一个辅助栈min_s
每次push一个数的时候,如果比辅助栈的栈顶小,则push这个数
否则,push辅助栈的栈顶
这个栈用来记录当前栈内的最小值
class Solution {
public:
void push(int value) {
if(min_s.empty() || value < min_s.top()) min_s.push(value);
else min_s.push(s.top());
s.push(value);
}
void pop() {
s.pop();
min_s.pop();
}
int top() {
return s.top();
}
int min() {
return min_s.top();
}
private:
stack s,min_s;
}; 22.栈的压入、弹出序列(**)
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
思路:
用一个栈模拟这个过程,写的时候注意边界判断
如果下一个pop刚好为栈顶,pop栈顶即可
不为栈顶,则不断push,知道为栈顶
如果push完了仍然不是栈顶,则非法
class Solution {
public:
bool isPopOrder(vector pushV,vector popV) {
if(pushV.empty()) return popV.empty();
stack s;
int i = 0,j = 0;
for(;i < popV.size();i++){
// 与栈顶不同,入栈
while(j < popV.size() && (s.empty() || s.top() != popV[i])){
s.push(pushV[j++]);
}
// 仍然与栈顶不同,则为非法
if(s.top() != popV[i]) return false;
s.pop();
}
return true;
}
}; 大神的写法,更加清晰:
class Solution {
public:
bool IsPopOrder(vector pushV,vector popV) {
if(pushV.empty()) return true;
stack s;
for(int i = 0,j = 0;i < pushV.size();){
s.push(pushV[i++]);
// 这里是while,相同时连续的出栈
while(j < popV.size() && s.top() == popV[j]){
s.pop();
j++;
}
}
return s.empty();
}
}; 23.二叉树层次遍历
从上往下打印出二叉树的每个节点,同层节点从左至右打印。
思路:用一个队列即可
扩展:层次遍历二叉树其实相当于图的广度优先搜索,使用队列来做
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector PrintFromTopToBottom(TreeNode* root) {
vector res;
if(!root) return res;
queue q;
TreeNode* cur = root;
q.push(cur);
while(!q.empty()){
int len = q.size();
for(int i = 0;i < len;i++){
cur = q.front();
q.pop();
res.push_back(cur->val);
if(cur->left) q.push(cur->left);
if(cur->right) q.push(cur->right);
}
}
return res;
}
}; 按之字形顺序打印二叉树
请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
思路:
思路一:
直接按照规律层次遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector> printFromTopToBottom(TreeNode* root) {
vector> res;
if(!root) return res;
int level = 1,q_size;
queue q;
q.push(root);
TreeNode* cur;
// 层次遍历
while(!q.empty()){
q_size = q.size();
vector out;
for(int i = 0;i < q_size;i++){
cur = q.front();q.pop();
out.push_back(cur->val);
// 先右后左
if(cur->right) q.push(cur->right);
if(cur->left) q.push(cur->left);
}
// 奇数层逆置
if(level&1) reverse(out.begin(),out.end());
res.push_back(out);
level++;
}
return res;
}
}; 思路二:使用栈
打印第2层,把节点1的左子节点2和右子节点3存放到容器里,此时需要从右往左打印,先打印3,后打印2,故使用栈实现
打印第3层,先打印节点3,再打印节点2,并把它们的子节点都存在容器里,打印第3层时是从左往右打印,先打印节点2的子节点4,5,再打印节点3的子节点6,7,故我们仍然用栈来实现,注意第二层孩子节点进栈时,应该先右后左
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
class Solution {
public:
vector > Print(TreeNode* pRoot) {
vector > res;
if(!pRoot) return res;
stack s1,s2;
TreeNode* cur;
s1.push(pRoot);
while(!s1.empty() || !s2.empty()){
vector out;
// 奇数层
if(!s1.empty()){
while(!s1.empty()){
cur = s1.top();s1.pop();
out.push_back(cur->val);
if(cur->left) s2.push(cur->left);
if(cur->right) s2.push(cur->right);
}
}else{
// 偶数层
while(!s2.empty()){
cur = s2.top();s2.pop();
out.push_back(cur->val);
// 先右后左
if(cur->right) s1.push(cur->right);
if(cur->left) s1.push(cur->left);
}
}
res.push_back(out);
}
return res;
}
}; 24.二叉搜索树的后序遍历序列(***)
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
二叉搜索树:
若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
思路:
后序遍历:最后一个节点为根节点
在二叉搜索树中,左子树全部小于根节点值,根据这个可以确定左右子树
如
正确后序:5,7,6(左),9,11,10(右),8(根节点)
错误后序:7(右),4(矛盾),6,5(根)
拓展:
这类给了二叉树遍历序列的题,一般都先找到根节点,然后根据根节点划分左右子树,递归去做
class Solution {
public:
bool verifySequenceOfBST(vector sequence) {
if(sequence.empty()) return true;
isBST(sequence,0,sequence.size()-1);
}
bool isBST(vector &seq,int l,int r){
if(l >= r) return true;
int root = seq[r],i = l;
// 左子树
while(seq[i] < root) i++;
// 判断右子树情况
for(int j = i;j < r;j++){
if(seq[j] < root){
return false;
}
}
return isBST(seq,l,i-1) && isBST(seq,i,r-1);
}
}; 25.二叉树中和为某一值的路径(***)
输入一颗二叉树的跟节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)
思路:
经典dfs递归写法:
注意一定是:
if(!root->left && !root->right && expectNumber == 0){
res.push_back(out);
}
写成
if(!root && expectNumber == 0){
res.push_back(out);
}
会有问题,会重复加入两次,因为左右孩子均为空,会递归两次,从而加入两次
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector> res;
vector> findPath(TreeNode* root, int sum) {
if(!root) return res;
vector out;
dfs(root,out,sum);
return res;
}
void dfs(TreeNode* root, vector out,int sum){
if(!root) return;
out.push_back(root->val);
sum -= root->val;
// 这里注意!不要再递归下去,否则左右子树为空,会入栈两次!!!
if(sum == 0 && (!root->left && !root->right)){
res.push_back(out);
return;
}
dfs(root->left,out,sum);
dfs(root->right,out,sum);
}
}; 非递归写法:
这个非递归写法参考别人的,我没写出来,因为太繁琐了,卡住了。。。
关键在于得有个last记录被访问的节点,不然只用先序遍历非递归会有问题,根节点还没算右子树,就被出栈了,导致路径不全(是不是用后序遍历就好了???)
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
vector > FindPath(TreeNode *root, int expectNumber){
vector > res;
if (root == NULL) return res;
stack s;
int sum = 0; //当前和
vector curPath; //当前路径
TreeNode *cur = root; //当前节点
TreeNode *last = NULL; //保存上一个节点
while (!s.empty() || cur){
if (cur == NULL){
TreeNode *temp = s.top();
// 根节点在访问右子树时还没出栈,因为计算路径要用,故这里有个last记录上一个遍历节点,每次右子节点访问完,last就会变成这个右子节点,不断往上退,防止重复遍历
if (temp->right != NULL && temp->right != last){
cur = temp->right; //转向未遍历过的右子树
}else{
last = temp; //保存上一个已遍历的节点
s.pop();
curPath.pop_back(); //从当前路径删除
sum -= temp->val;
} }
else{
s.push(cur);
sum += cur->val;
curPath.push_back(cur->val);
if (cur->left == NULL && cur->right == NULL && sum == expectNumber){
res.push_back(curPath);
}
cur = cur->left; //先序遍历,左子树先于右子树
}
}
return res;
}
}; 26.复杂链表的复制(*)
输入一个复杂链表(每个节点中有节点值,以及两个指针,一个指向下一个节点,另一个特殊指针指向任意一个节点),返回结果为复制后复杂链表的head。(注意,输出结果中请不要返回参数中的节点引用,否则判题程序会直接返回空)
难点:
(1) 如果先根据next创建链表,然后对每个节点依次查找random,这样时间复杂度是O(N*N)
(2) 如果对每个节点和它复制后的节点创建字典对应,这样时间复杂度是O(N),但是空间复杂度也是O(N),属于空间换时间
思路:
下面这种方法可以空间O(1),时间O(N)

/*
struct RandomListNode {
int label;
struct RandomListNode *next, *random;
RandomListNode(int x) :
label(x), next(NULL), random(NULL) {
}
};
*/
class Solution {
public:
RandomListNode* Clone(RandomListNode* pHead){
if(!pHead) return NULL;
RandomListNode* cur = pHead;
RandomListNode* dummy_head = new RandomListNode(-1);
// 第一步,生成新节点,接在原节点后面
while(cur){
RandomListNode* tmp = new RandomListNode(cur->label);
tmp->next = cur->next;
cur->next = tmp;
cur = tmp->next;
}
cur = pHead;
// 第二步,连接random
while(cur){
// 注意这里需要判断!!!!不要遗漏
if(cur->random) cur->next->random = cur->random->next;
cur = cur->next->next;
}
cur = pHead;
// 第三步,分开链表,借助虚拟头结点
RandomListNode* dummy_cur = dummy_head;
while(cur){
dummy_cur->next = cur->next;
cur->next = cur->next->next;
cur = cur->next;
dummy_cur = dummy_cur->next;
}
return dummy_head->next;
}
};27.二叉搜索树与双向链表(*)
输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的双向链表。要求不能创建任何新的结点,只能调整树中结点指针的指向。
思路:
这题我有点被绕晕了,着重看一下
目标:
1. 递归解法(***):
分析清楚问题,把复杂的问题逐步分解
解题思路:
1.将左子树构造成双链表,并返回链表头节点。
2.定位至左子树双链表最后一个节点。
3.如果左子树链表不为空的话,将当前root追加到左子树链表。
4.将右子树构造成双链表,并返回链表头节点。
5.如果右子树链表不为空的话,将该链表追加到root节点之后。
6.根据左子树链表是否为空确定返回的节点。(这个注意,因为这里想要的是双向链表头结点,而不是直接返回根节点)
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
TreeNode* Convert(TreeNode* pRootOfTree){
if(!pRootOfTree) return NULL;
if(!pRootOfTree->left && !pRootOfTree->right) return pRootOfTree;
// 递归左子树,返回左子树双向链表的头
TreeNode* left = Convert(pRootOfTree->left);
// 将左子树双向链表尾接到根节点
if(left){
TreeNode* cur = left;
while(cur->right) cur = cur->right;
cur->right = pRootOfTree;
pRootOfTree->left = cur;
}
// 递归右子树
// 将右子树双向链表头接到根节点(注意这里是头)
if(pRootOfTree->right){
TreeNode* right = Convert(pRootOfTree->right);
right->left = pRootOfTree;
pRootOfTree->right = right;
}
// 左子树存在,左子树的链表头才是真的链表头
return left != NULL? left:pRootOfTree;
}
};2.非递归解法
中序遍历非递归基础上,增加pre,用来保存上一次走过的节点,然后把pre右子树指向当前节点,当前节点左子树指向pre
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* convert(TreeNode* root) {
if(!root) return NULL;
stack s;
TreeNode* cur = root,*pre = NULL,*new_head;
bool first = true;
while(!s.empty() || cur){
// 中序遍历
while(cur){
s.push(cur);
cur = cur->left;
}
cur = s.top();s.pop();
// 首节点判断
if(first){
new_head = cur;
first = false;
}
// 加入双向链表的前后连接
if(pre){
pre->right = cur;
cur->left = pre;
}
pre = cur;
// 中序遍历常规操作
cur = cur->right;
}
return new_head;
}
}; 28.序列化二叉树(****)
思路:这里我使用先序遍历dfs,比较好写,层次相对难一些
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
string res;
dfs(root,res);
return res;
}
void dfs(TreeNode* root,string &res){
if(!root){
res += "null ";
return;
}
res += to_string(root->val)+' ';
dfs(root->left,res);
dfs(root->right,res);
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
vector data_s = split(data);
int idx = 0;
return dfs_de(data_s,idx);
}
TreeNode* dfs_de(vector data_s,int &idx) {
if(idx >= int(data_s.size())) return NULL;
TreeNode* root = getTreeNode(data_s[idx++]);
if(!root) return root;
root->left = dfs_de(data_s,idx);
root->right = dfs_de(data_s,idx);
return root;
}
// 实现字符串split功能
vector split(string data){
vector res;
int begin = 0,i = 0;
string val;
while(i < int(data.size())){
while(i < int(data.size()) && data[i] != ' ') i++;
val = data.substr(begin,i-begin);
res.push_back(val);
i++;
begin = i;
}
return res;
}
// 通过一个string值返回生成的二叉树节点
TreeNode* getTreeNode(string val){
if(val == "null") return NULL;
else{
TreeNode* node = new TreeNode(stoi(val));
return node;
}
}
};
29.有重复的字符串的全排列(*)
输入一个字符串,按字典序打印出该字符串中字符的所有排列。例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串abc,acb,bac,bca,cab和cba。
思路:dfs来排列,注意防止重复
1)保证不重复使用数字:使用visit数组
由于递归的for都是从0开始,难免会重复遍历到数字,而全排列不能重复使用数字,意思是每个nums中的数字在全排列中只能使用一次(当然这并不妨碍nums中存在重复数字)。不能重复使用数字就靠visited数组来保证,这就是第一个if剪枝的意义所在。
if(visit[i]) continue;
(2)去重
关键来看第二个if剪枝的意义,这里说当前数字和前一个数字相同,且前一个数字的visited值为0的时候,必须跳过。这里的前一个数visited值为0,并不代表前一个数字没有被处理过,而是递归结束后恢复状态时将visited值重置为0了
if(i > 0 && nums[i]==nums[i-1] && !visit[i-1]) continue;

class Solution {
public:
vector res;
vector Permutation(string str) {
if(str.empty()) return res;
vector visited(str.size(),false);
string out;
sort(str.begin(),str.end());
dfs(str,visited,out);
return res;
}
void dfs(string &str,vector &visited,string &out){
if(out.size() == str.size()) {res.push_back(out); return;}
for(int i = 0;i < str.size();i++){
if(visited[i]) continue;
// 防止重复!!!
// 当前数字和前一个数字相同,且前一个数字的visited值为0的时候,必须跳过。
// 这里的前一个数visited值为false,并不代表前一个数字没有被处理过
// 而是递归结束后恢复状态时将visited值重置为false了
if(i > 0 && str[i-1] == str[i] && !visited[i-1]) continue;
out.insert(out.end(),str[i]);
visited[i] = true;
dfs(str,visited,out);
// 去掉最后一个!!不是去掉i位置
out.erase(out.end()-1);
visited[i] = false;
}
}
}; 有重复的字符串的组合(子集合)(**)
输入三个字符aab,生成所有组合,包括空集
思路:
这个和上面那题看似一样,其实不同
子集合其实只需要每次在上一次生成的基础上加入当前字符,然后再加入到结果中即可
例如:
‘’
a,aa
b,ab,aab
每次加入一个新字母
(注意,这个顺序就是下面代码的生成顺序)
class Solution {
public:
vector subset(string str) {
vector res;
if(str.empty()) return res;
sort(str.begin(),str.end());
// 这个作为种子
res.push_back("");
for(int i = 0;i < str.size();i++){
int count = 1;
while(str[i+1] == str[i]){
count++;i++;
}
res = build_sub(res,str[i],count);
}
return res;
}
vector build_sub(vector &res,char c,int count){
// 每次对一个新的字符,在所有res的基础上,再加入它,然后重新加入res中
int res_size = res.size();
string cur;
for(int i = 0;i < res_size;i++){
cur = res[i];
// 对于重复的情况,比如有两个a,则第二个a的加入不是在所有res上加入,而是在第个a生成的后面加入
for(int j = 0;j < count;j++){
cur.insert(cur.end(),c);
res.push_back(cur);
}
}
return res;
}
}; 引申:这题挺骚操作的
第五章 优化时间和空间效率
优化时间:
(1)改用更加高效的算法
(2)空间换时间,注意空间消耗,不是次次可行
30.数组中出现次数超过一半的数字
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0。
思路:
O(n)就可以搞定
这里注意第二次再从头计数一次,统计是否超过一半
class Solution {
public:
int MoreThanHalfNum_Solution(vector numbers) {
if(numbers.empty()) return 0;
if(numbers.size() == 1) return numbers[0];
int count = 1,half_num = numbers[0];
for(int i = 1;i < numbers.size();i++){
if(numbers[i] == half_num) count++;
else count--;
if(count == 0){
half_num = numbers[i];
count = 1;
}
}
// check
count = 0;
for(auto &num:numbers){
if(num == half_num) count++;
}
return (count*2 > numbers.size())? half_num:0;
}
}; 31.最小k个数
输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4
解法一:大顶堆
时间复杂度:nlogk,适用于海量数据
思路:前k个构建大顶堆,对于k之后的数,与大顶堆堆顶比较,比堆顶小,就替换堆顶,往下调整
class Solution {
public:
vector GetLeastNumbers_Solution(vector input, int k) {
vector res;
if(k <= 0 || input.size() < k) return res;
// 前k个构建大顶堆
vector heap(input.begin(),input.begin()+k);
build_heap(heap);
// 对于k之后的数,与大顶堆堆顶比较,比堆顶小,就替换堆顶,往下调整
for(int i = k;i < input.size();i++){
if(heap[0] > input[i]){
heap[0] = input[i];
adjust(heap,0);
}
}
return heap;
}
// 建堆
void build_heap(vector &heap){
int len = int(heap.size());
int max_idx;
for(int i = len/2;i >= 0;i--){
adjust(heap,i);
}
}
// 调整
void adjust(vector &heap,int idx){
int max_idx = idx;
if(idx*2+1 < heap.size() && heap[max_idx] < heap[idx*2+1]) max_idx = idx*2+1;
if(idx*2 < heap.size() && heap[max_idx] < heap[idx*2]) max_idx = idx*2;
if(max_idx != idx){
swap(heap[idx],heap[max_idx]);
adjust(heap,max_idx);
}
}
}; 直接使用优先队列
class Solution {
public:
vector GetLeastNumbers_Solution(vector input, int k) {
vector res;
int len = int(input.size());
if(k <= 0 || k > len) return res;
if(k == len) return input;
// 默认从大到小排列
priority_queue q;
// 也可以这么写
// priority_queue ,less > q;
for(int i = 0;i < len;i++){
if(i < k) q.push(input[i]);
// 小于栈顶(即最大值)
else if(input[i] < q.top()){
q.pop();q.push(input[i]);
}
}
while(!q.empty()){
res.push_back(q.top());
q.pop();
}
return res;
}
}; 优先队列使用:c++优先队列(priority_queue)用法详解_c++优先级队列_吕白_的博客-CSDN博客
解法二:快速排序
时间复杂度:O(n),只有当输入数组可修改时可以使用
为什么上述查找方式复杂度为n呢?
- 第一次分区查找,我们需要对大小为n的数组进行操作,比较次数为n
- 第二次分区查找,需对n/2大小的数组进行操作,比较次数为n/2
- 依次类推,我们需要比较的次数为n,n/2,n/4,n/8…1。这是一个等比数列,加起来结果为2n-1,复杂度为n
发现我快排写的仍然非常卡。。。很多边界条件老是忘
class Solution {
public:
vector GetLeastNumbers_Solution(vector input, int k) {
vector res;
if(k <= 0 || k > input.size()) return res;
if(k == input.size()) return input;
int idx = -1,begin = 0,end = input.size()-1;
while(idx != k-1){
idx = partition(input,begin,end);
if(idx > k-1) end = idx-1;
else if(idx < k-1) begin = idx+1;
}
// 这里是push_back注意,没有给res先预设空间!!!
for(int i = 0;i < k;i++) res.push_back(input[i]);
return res;
}
int partition(vector &input,int begin,int end){
int pivot = input[begin];
// 从begin开始,不是begin+1 !!!
int l = begin,r = end;
while(l < r){
// 注意这里有l < r的判断
while(l < r && input[r] >= pivot) r--;
input[l] = input[r];
while(l < r && input[l] <= pivot) l++;
input[r] = input[l];
}
// 最后放到l位置
input[l] = pivot;
return l;
}
}; 解法三:冒泡排序
时间复杂度:k*O(N)
class Solution {
public:
vector GetLeastNumbers_Solution(vector input, int k) {
vector res;
int len = int(input.size());
if(k <= 0 || k > len) return res;
if(k == len) return input;
// 将小的数字沉到最下面
for(int i = 0;i < k;i++){
for(int j = 1;j < len-i;j++){
if(input[j-1] < input[j]) swap(input[j-1],input[j]);
}
}
for(int i = 0;i < k;i++){
res.insert(res.begin(),input[len-1-i]);
}
return res;
}
}; 32.数据流中的中位数(****)
如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。我们使用Insert()方法读取数据流,使用GetMedian()方法获取当前读取数据的中位数。
(1)快排
插入:O(1)
找出中位数O(n)
(2)链表
插入(排序插入):O(n)
找出中位数(可以定义两个指针指向中位数,奇数个时,指向同一个数):O(1)
(3)二叉搜索树
插入:O(logn)
当数据极度不平衡时,时间复杂度仍然为O(N)
使用平衡的二叉搜索树可以解决这个问题,但一般STL没有这个实现
(4)两个堆
为了保证插入新数据和取中位数的时间效率都高效,这里使用大顶堆+小顶堆的容器,并且满足:
1、两个堆中的数据数目差不能超过1,这样可以使中位数只会出现在两个堆的交接处;
2、大顶堆的所有数据都小于小顶堆,这样就满足了排序要求。
总结:
class Solution {
public:
void insert(int num){
// 如果第一个大顶堆为空,或者数小于第一个堆顶
if(first.empty() || first.top() >= num) first.push(num);
else second.push(num);
// 平衡两个堆的数量
if(first.size() == second.size()+2){
second.push(first.top());first.pop();
}
else if(second.size() == first.size()+2){
first.push(second.top());second.pop();
}
}
double getMedian(){
// 偶数:取平均
if(first.size() == second.size()) return (first.top()+second.top())/2.0;
// 奇数
else return first.size()>second.size()? first.top():second.top();
}
private:
priority_queue,less> first;
priority_queue,greater> second;
}; 33.连续子数组的最大和(*)
给定一个数组 array[1, 4, -5, 9, 8, 3, -6],在这个数字中有多个子数组,子数组和最大的应该是:[9, 8, 3],输出20,再比如数组为[1, -2, 3, 10, -4, 7, 2, -5],和最大的子数组为[3, 10, -4, 7, 2],输出18。
思路: 一次遍历,当cur_sum小于0时,令当前值为cur_sum,否则累加当前值,并与max_sum比较是否需要更新
时间复杂度:O(n)
class Solution {
public:
int FindGreatestSumOfSubArray(vector array) {
if(array.empty()) return 0;
int max_sum = INT_MIN,cur_sum = 0;
for(auto &num:array){
// cur_sum小于0,则令当前值为cur_sum
if(cur_sum <= 0) cur_sum = num;
else cur_sum += num;
if(cur_sum > max_sum) max_sum = cur_sum;
}
return max_sum;
}
}; 思路二:也可以用动态规划解,但是需要额外的空间
34.整数中1出现的次数(从1到n整数中1出现的次数)(*)
求出1~13的整数中1出现的次数,并算出100~1300的整数中1出现的次数?为此他特别数了一下1~13中包含1的数字有1、10、11、12、13因此共出现6次
思路:找到规则来做
以2593中5的个数为例:
(1)个位上的5
5,15,25,35...
以10为间隔,10个里面有1个数个位上是5
23:则23/10 = 2
27:则27/10+1 = 3
公式为:n/10+(n%10 >= 5? 1:0)
(2)十位上的5
50-59,150-159,250-259
以100为间隔,100个数里10个十位上是5
n%100 大于 等于60,则额外加10个
n%100在50-60之间,则加上n%100-50+1
n%100小于50,则加上0
公式为:n/100+(n%100)
acwing:不会溢出
时间复杂度:O(logn),一个数n有logn位
class Solution {
public:
int numberOf1Between1AndN_Solution(int n) {
int res = 0,cnt = INT_MAX;
// 以123为例子
// 个位上的1:123/10 + 1(因为123%10 >= 1) = 13
// 十位上的1:123/100 + 10(因为123%100 >= 10) = 20
// 百位上的1:123/1000 + 24 = 24
// 合计57
for(int base = 10;cnt != 0;base *= 10){
cnt = n/base * (base/10);
// 注意这里要与0比较,否则会出现负数
cnt += min(base/10,max(0,n%base-base/10+1));
cout << cnt << endl;
res += cnt;
}
return res;
}
};牛客:大数
class Solution {
public:
int NumberOf1Between1AndN_Solution(int n){
if(n <= 0) return 0;
int count = 0;
long add;
for(long i = 1;i <= n;i *= 10){
long divider = i*10;
// 下面这段因为c++的min只能支持int,所以只能这么写
// 不然可以写成count += (n / diviver) * i + min(max(n % diviver - i + 1, 0), i);
// 非常简洁
count += n/divider*i;
add = 0;
// 小于i,不需要加
if(n % divider- i + 1 > 0){
add = n % divider- i + 1;
// 超过i,加的就是i的个数
if(add > i) add = i;
}
count += add;
}
return count;
}
};数字序列中某一位的数字(*)
数字以0123456789101112131415…的格式序列化到一个字符序列中。
在这个序列中,第5位(从0开始计数)是5,第13位是1,第19位是4,等等。
请写一个函数求任意位对应的数字。
样例
输入:13
输出:1思路:找规律题,参见剑指offer225页
class Solution {
public:
int digitAtIndex(int n) {
if(n < 10) return n;
long long cnt = 0,base = 9,len = 1,cur,bit;
while(cnt+base*len <= n){
cnt += base*len;
base *= 10;
len++;
}
// 获得当前数,当前数第几位
cur = pow(10,len-1)+(n-cnt-1)/len;
bit = (n-cnt-1)%len;
// 直接转字符串输出即可
return to_string(cur)[bit]-'0';
}
};45.把数组排成最小的数
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。例如输入数组{3,32,321},则打印出这三个数字能排成的最小数字为321323。
思路:
这题有两个要注意的点:
(1)我们希望找到一个排序规则,数字根据这个排序规则排序之后能形成排成一个最小数。
故对于两个数3,321,我们应该比较3321和3213哪个比较小,小的那个排在前面
而不是仅仅比较两个数字哪个值大
(2)多个数字组合以后,会溢出,这是一个隐形的大数问题,需要用string去存
class Solution {
public:
// 判断a和b哪个应该排前面,而不是值的大小
// a排前面,则a+b < b+a
// 注意这里必须加static
static bool cmp(int a,int b){
string s1 = to_string(a)+to_string(b);
string s2 = to_string(b)+to_string(a);
return s1 < s2;
}
string PrintMinNumber(vector numbers) {
sort(numbers.begin(),numbers.end(),cmp);
string res = "";
for(auto &s:numbers){
res += to_string(s);
}
return res;
}
}; 46.把数字翻译成字符串(*)
给定一个数字,我们按照如下规则把它翻译为字符串:
0翻译成”a”,1翻译成”b”,……,11翻译成”l”,……,25翻译成”z”。
一个数字可能有多个翻译。例如12258有5种不同的翻译,它们分别是”bccfi”、”bwfi”、”bczi”、”mcfi”和”mzi”。
请编程实现一个函数用来计算一个数字有多少种不同的翻译方法。
样例
输入:"12258"
输出:5本题解法
DP:O(N)
还记得经典的爬楼梯(斐波那契数列)吗?每次可以走1步或者2步,问n个台阶一共有多少种爬楼梯的方法?
dp[i]=dp[i-1]+dp[i-2]
这道题相当于加了一些限制条件的爬楼梯,限制条件是i和i+1组成的数字要在10到25之间,注意05这种不是合法的。
class Solution {
public:
int getTranslationCount(string s) {
if(s.empty()) return 1;
auto len = s.size();
vector dp(len+1,1);
for(int i = 2;i <= len;i++){
string num = s.substr(i-2,2);
if(num > "25" || num < "10"){
dp[i] = dp[i-1];
}else{
dp[i] = dp[i-1]+dp[i-2];
}
}
return dp[len];
}
}; 47.礼物的最大价值
在一个m×n的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于0)。
你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格直到到达棋盘的右下角。
给定一个棋盘及其上面的礼物,请计算你最多能拿到多少价值的礼物?
注意:
- m,n>0m,n>0
样例:
输入:
[
[2,3,1],
[1,7,1],
[4,6,1]
]
输出:19
解释:沿着路径 2→3→7→6→1 可以得到拿到最大价值礼物。思路:
经典dp题目
这种移动求最优类的题目,一般第一反应就是dp
空间:O(n*n)解法
class Solution {
public:
int getMaxValue(vector>& grid) {
if(grid.empty() || grid[0].empty()) return 0;
int m = grid.size(),n = grid[0].size();
vector> dp(m+1,vector(n+1,0));
for(int i = 1;i <= m;i++){
for(int j = 1;j <= n;j++){
dp[i][j] = max(dp[i-1][j],dp[i][j-1])+grid[i-1][j-1];
}
}
return dp[m][n];
}
}; 空间:O(n)解法
注意这里第一行就是要从左向右累加,而不是直接赋值成第一行数字
class Solution {
public:
int getMaxValue(vector>& grid) {
if(grid.empty() || grid[0].empty()) return 0;
int m = grid.size(),n = grid[0].size();
vector dp(n,0);
for(int i = 0;i < m;i++){
dp[0] = dp[0]+grid[i][0];
for(int j = 1;j < n;j++){
dp[j] = max(dp[j-1],dp[j])+grid[i][j];
}
}
return dp[n-1];
}
}; 48.最长不含重复字符的子字符串
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
假设字符串中只包含从’a’到’z’的字符。
样例
输入:"abcabc"
输出:3思路:
用一个字典记录出现过的字符所在下标,并且维护一个左边界,如果新遇到的字符重复,且在左边界右侧,则更新左边界
时间复杂度:O(n)
空间复杂度:O(n)
class Solution {
public:
int longestSubstringWithoutDuplication(string s) {
if(s.empty()) return 0;
unordered_map m;
int max_len = 0,left = 0;
for(int i = 0;i < s.size();i++){
char c = s[i];
// 不在字典中,直接扩充右边界
if(!m.count(c)) m[c] = i;
else{
// 在字典中,且在左边界右边,则更新左边界,字典中存放的是每个字母所在下标
if(m[c] >= left) left = m[c]+1;
m[c] = i;
}
max_len = max(max_len,i-left+1);
}
return max_len;
}
}; 49.丑数(*)
解法一:依次判断每个数是不是
逐个判断每个数是不是丑数时间消耗比较大,因为数会越来越大,每次对一个数不断的去除2,3,5,运算量大,不可行
正确解法:空间换时间
从小到大存下生成的丑数,丑数其实是不断的对前面生成的数乘以2,乘以3,或者乘以5
(1)丑数数组: 1
乘以2的队列:2
乘以3的队列:3
乘以5的队列:5
选择三个队列头最小的数2加入丑数数组;
(2)丑数数组:1,2
乘以2的队列:
乘以3的队列:1*3
乘以5的队列:1*5
选择三个队列头最小的数3加入丑数数组;
(3)丑数数组:1,2,3
乘以2的队列:2*2
乘以3的队列:3*2
乘以5的队列:5*1
选择三个队列头里最小的数4加入丑数数组;
(4)丑数数组:1,2,3,4
乘以2的队列:2*3
乘以3的队列:3*2
乘以5的队列:5*1
选择三个队列头里最小的数5加入丑数数组;
(5)丑数数组:1,2,3,4,5...
class Solution {
public:
int getUglyNumber(int n) {
if(n <= 0) return -1;
vector res(n,1);
int t2 = 0,t3 = 0,t5 = 0,n2,n3,n5;
for(int i = 1;i < n;i++){
n2 = res[t2]*2;
n3 = res[t3]*3;
n5 = res[t5]*5;
res[i] = min(n2,min(n3,n5));
// 增加自身,同时去重,比如2*3和3*2的情况
// 所以这里不能用if else
if(res[i] == n2) t2++;
if(res[i] == n3) t3++;
if(res[i] == n5) t5++;
}
return res[n-1];
}
}; 50.第一个只出现一次的字符
在一个字符串(0<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置, 如果没有则返回 -1(需要区分大小写).
我的写法:
这类跟出现次数有关/重复不重复的题,都要考虑用字典做
class Solution {
public:
char firstNotRepeatingChar(string s) {
unordered_map m;
int min_idx = INT_MAX;
char first_char = '#';
for(int i = 0;i < s.size();i++){
if(m.count(s[i])) m[s[i]] = -1;
else m[s[i]] = i;
}
for(auto idx = m.begin();idx != m.end();idx++){
if(idx->second != -1 && idx->second < min_idx){
min_idx = idx->second;
first_char = idx->first;
}
}
return first_char;
}
}; 别人的ascii码写法
class Solution {
public:
int ha[256];
int FirstNotRepeatingChar(string str){
memset(ha, 0, sizeof(ha));
for(int i=0;i扩展:但凡这类涉及到字符串的出现次数的题目,都可以考虑使用哈希表
从第一个字符串中删除在第二个字符串中出现的字符
如:“we are students”和"aeiou",删除后得到“w r stdnts”
思路:对第二个字符串建立哈希表,这样从头开始遍历字符串1的时候,就可以用O(1)的时间复杂度判断该字符是否在s2中
class Solution {
public:
string delete_duplicate(string s1,string s2){
if(s2.empty() || s1.empty()) return s1;
unordered_set s2_set(s2.begin(),s2.end());
for(int i = 0;i < s1.size();i++){
if(s2_set.count(s1[i])){
s1.erase(i,1);
// erase后i还要保持原状!!注意!!!
i--;
}
}
return s1;
}
}; 字符流中第一个不重复的字符
思路:
使用一个字典存每个字符第一次出现的位置,出现第二次,则置为-1
需要输出的时候,遍历字典即可
时间复杂度:O(N)
空间复杂度:O(N)
class Solution{
public:
//Insert one char from stringstream
void Insert(char ch){
if(m.find(ch) == m.end()){
m[ch] = idx;
}else{
m[ch] = -1;
}
idx++;
}
//return the first appearence once char in current stringstream
char FirstAppearingOnce(){
int min_idx = INT_MAX;
char first = '#';
// 注意这里字典的遍历
for(auto c = m.begin();c != m.end();c++){
if(c->second != -1 && c->second < min_idx){
min_idx = c->second;
first = c->first;
}
}
return first;
}
private:
unordered_map m;
int idx = 0;
}; 同理:
删除字符串中重复的数字
判断是否为变位词(Anagram)/兄弟单词
51.数组中的逆序对(***)
在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。
输入一个数组,求出这个数组中的逆序对的总数。
样例
输入:[1,2,3,4,5,6,0]
输出:6思路:
归并排序
过程:
先把数组分割成子数组,先统计出子数组内部的逆序对的数目
然后再统计出两个相邻子数组之间的逆序对的数目。在统计逆序对的过程中,还需要对数组进行排序。如果对排序算法很熟悉,我们不难发现这个过程实际上就是归并排序。
时间复杂度:
O(NlogN)
空间复杂度:
O(N),空间换时间
class Solution {
public:
int cnt = 0;
int inversePairs(vector& nums) {
// 注意这里是nums.size()-1,否则非法访问!!!
merge_sort(nums,0,nums.size()-1);
return cnt;
}
void merge_sort(vector& nums,int l,int r){
if(l >= r) return;
if(l+1==r){
if(nums[l] > nums[r]){
swap(nums[l],nums[r]);
// 加入计数
cnt++;
}
}else{
int mid = (l+r)/2;
merge_sort(nums,l,mid);
merge_sort(nums,mid+1,r);
merge(nums,l,r);
}
}
void merge(vector& nums,int l,int r){
vector res;
int l_end = (l+r)/2,r_begin = l_end+1;
int i = l,j = r_begin;
while(i <= l_end && j <= r){
if(nums[i] > nums[j]) {
res.push_back(nums[j++]);
// 加入计数
cnt += (l_end-i+1);
}
else res.push_back(nums[i++]);
}
// 注意下面是while,不是if,还有这里不需要再加了,因为上面计数已经完成 !!!!
while(i <= l_end) res.push_back(nums[i++]);
while(j <= r) res.push_back(nums[j++]);
for(int i = 0;i < res.size();i++) nums[i+l] = res[i];
}
}; 52.两个链表的第一个公共结点
输入两个链表,找出它们的第一个公共结点。
思路:
思路1:
直接暴力求解,对一个链表中每个节点暴力查找是否在链表2中
时间复杂度:O(m*n)
思路二:
使用栈,先进后出,可以入两个栈,然后分别出栈,直到出栈变得不一样,它的上一个即是公共节点
但是这样需要空间消耗,思路3不需要空间消耗
思路3:
从公共节点的性质出发,从公共节点开始,两个链表公用一个尾部,呈现Y字型
(1)找出2个链表的长度,然后让长的先走两个链表的长度差
(2)然后再一起走,此时遇到两者相同的节点,一定是公共节点
(因为2个链表用公共的尾部)
时间复杂度:O(m+n)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *findFirstCommonNode(ListNode *headA, ListNode *headB) {
if(!headA || !headB) return NULL;
ListNode *cur1 = headA,*cur2 = headB;
int len1 = 0,len2 = 0;
while(cur1){len1++;cur1 = cur1->next;}
while(cur2){len2++;cur2 = cur2->next;}
cur1 = headA;
cur2 = headB;
// 走到等长
while(len1 > len2){len1--;cur1 = cur1->next;}
while(len2 > len1){len2--;cur2 = cur2->next;}
// 不断往后走
while(cur1 != cur2){
cur1 = cur1->next;
cur2 = cur2->next;
}
return cur1;
}
};第六章
53.数字在排序数组中出现的次数
统计一个数字在排序数组中出现的次数。
思路:
由于数组有序,所以使用二分查找方法定位k的第一次出现位置和最后一次出现位置
时间复杂度:
O(logN)
class Solution {
public:
int getNumberOfK(vector& nums , int k) {
if(nums.empty() || k < nums[0] || k > nums[nums.size()-1]) return 0;
int first =get_first(nums,k),second = get_second(nums,k);
// 不存在数字的情况
if(first == second){
return nums[first]==k? 1:0;
}
return second-first+1;
}
int get_first(vector& nums , int k){
int mid=0,i = 0,j = nums.size()-1;
while(i <= j){
mid = (i+j)/2;
if(nums[mid] < k) i = mid+1;
else if(nums[mid] == k && (mid == 0 || nums[mid-1] < k)) break;
// 这里包含了nums[mid] > k 和 nums[mid] == k但是在中间的情况
else j = mid-1;
}
return nums[mid]==k? mid:0;
}
int get_second(vector& nums , int k){
int mid=0,i = 0,j = nums.size()-1;
while(i <= j){
mid = (i+j)/2;
if(nums[mid] > k) j = mid-1;
else if(nums[mid] == k && (mid == nums.size()-1 || nums[mid+1] > k)) break;
// 这里包含了nums[mid] < k 和 nums[mid] == k但是在中间的情况
else i = mid+1;
}
return nums[mid]==k? mid:0;
}
}; 0到n-1中缺失的数字(*)
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0到n-1之内。
在范围0到n-1的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
样例
输入:[0,1,2,4]
输出:3思路:
二分法,这里注意首尾缺失情况
class Solution {
public:
int getMissingNumber(vector& nums) {
if(nums.empty()) return 0;
int i = 0,j = nums.size()-1,mid;
while(i <= j){
mid = (i+j)/2;
if(nums[mid] == mid) i = mid+1;
// [1,2]这种情况
else if(mid == 0 || nums[mid-1] == mid-1) return mid;
else j = mid-1;
}
// [0]这种情况
if(i == nums.size()) return nums.size();
return -1;
}
}; 直接取巧先判断首尾缺失:
class Solution {
public:
int getMissingNumber(vector& nums) {
int n = nums.size();
// 首缺失判断
if(nums.empty()|| nums[0] != 0) return 0;
// 尾缺失判断
if(nums[n-1] == n-1) return n;
// 剩下一定是在内部
int i = 0,j = nums.size()-1,mid;
while(i <= j){
mid = (i+j)/2;
if(nums[mid] == mid) i = mid+1;
else if(nums[mid-1] == mid-1) return mid;
else j = mid-1;
}
return -1;
}
}; 数组中数值和下标相等的元素
假设一个单调递增的数组里的每个元素都是整数并且是唯一的。
请编程实现一个函数找出数组中任意一个数值等于其下标的元素。
例如,在数组[-3, -1, 1, 3, 5]中,数字3和它的下标相等。
样例
输入:[-3, -1, 1, 3, 5]
输出:3
注意:如果不存在,则返回-1。
思路:最简单二分,0 trick
class Solution {
public:
int getNumberSameAsIndex(vector& nums) {
int i = 0,j = nums.size()-1,mid;
while(i <= j){
mid = (i+j)/2;
if(nums[mid] == mid) return mid;
else if (nums[mid] < mid) i = mid+1;
else j = mid-1;
}
return -1;
}
}; 54.二叉搜索树的第k个节点
思路:即中序遍历第k个值
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};
*/
class Solution {
public:
TreeNode* KthNode(TreeNode* pRoot, int k){
if(!pRoot || k < 1) return NULL;
int count = 0;
TreeNode* cur = pRoot;
stack s;
while(cur || !s.empty()){
while(cur){
s.push(cur);
cur = cur->left;
}
cur = s.top(); s.pop();
count++;
if(count == k) return cur;
cur = cur->right;
}
// K超过树内节点数
return NULL;
}
}; 55.二叉树深度
非递归写法:层次遍历
/*
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {
}
};*/
class Solution {
public:
int TreeDepth(TreeNode* pRoot){
if(!pRoot) return 0;
int level = 0,q_size;
TreeNode* p = pRoot;
queue q;
q.push(p);
while(!q.empty()){
level++;
q_size = q.size();
for(int i = 0;i < q_size;i++){
p = q.front(); q.pop();
if(p->left) q.push(p->left);
if(p->right) q.push(p->right);
}
}
return level;
}
}; 递归写法:
class Solution {
public:
int TreeDepth(TreeNode* pRoot){
if(!pRoot) return 0;
return 1+max(TreeDepth(pRoot->left),TreeDepth(pRoot->right));
}
};平衡二叉树 ( *** )
输入一棵二叉树,判断该二叉树是否是平衡二叉树。
平衡二叉树:
平衡二叉树定义:它是一棵空树或(1)它的左右两个子树的高度差的绝对值不超过1,(2)并且左右两个子树都是一棵平衡二叉树
而不是只考虑根节点左右子树高度差绝对值不超过1
思路:
解法1:较为直观
class Solution {
public:
bool IsBalanced_Solution(TreeNode* pRoot) {
if(!pRoot) return true;
// (1)左右两个子树的高度差的绝对值不超过1
if(abs(get_depth(pRoot->left)-get_depth(pRoot->right))>1) return false;
// (2)左右两个子树都是一棵平衡二叉树
return IsBalanced_Solution(pRoot->left)&&IsBalanced_Solution(pRoot->right);
}
int get_depth(TreeNode* pRoot){
if(!pRoot) return 0;
else return 1+max(get_depth(pRoot->left),get_depth(pRoot->right));
}
};解法2:在1基础上进行剪枝,从下往上遍历
解法1有很明显的问题,在判断上层结点的时候,会多次重复遍历下层结点,增加了不必要的开销。如果改为从下往上遍历,如果子树是平衡二叉树,则返回子树的高度;如果发现子树不是平衡二叉树,则直接停止遍历,这样至多只对每个结点访问一次。
class Solution {
public:
bool IsBalanced_Solution(TreeNode* pRoot) {
if(!pRoot) return true;
if(get_depth(pRoot) == -1) return false;
return true;
}
int get_depth(TreeNode* pRoot){
if(!pRoot) return 0;
int left = get_depth(pRoot->left);
if(left == -1) return -1;
int right = get_depth(pRoot->right);
if(right == -1) return -1;
else return abs(left-right)>1? -1:1+max(left,right);
}
};56.数组中只出现一次的数字(**)
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
思路:
解题关键:两个相同数字,异或结果为0
(1)故整个数组异或后,得到两个只出现一次的数字的异或结果。
这题的难点是在最后得到ab异或的结果以后,怎样去将ab分开
(2)我们取出异或结果其中任意一位为‘1’的位,用来后面去区分a,b
就拿 {1,1,2,2,3,5} 来说,如果我们将其全部异或起来,我们知道相同的两个数异或的话为0,那么两个1,两个2,都抵消了,就剩3和5异或起来,那么就是二进制的11和101异或,得到110。
然后我们先初始化diff为1,如果最右端就是1,那么diff与a_xor_b去做与会得到1,否则是0,我们左移diff,用10再去做与,此时得到结果11,找到最右端第一个1了
(3)用diff来和数组中每个数字相与
根据结果的不同,一定可以把3和5区分开来,而其他的数字由于是成对出现,所以区分开来也是成对的,最终都会异或成0,不会3和5产生影响。分别将两个小组中的数字都异或起来,就可以得到最终结果了
class Solution {
public:
void FindNumsAppearOnce(vector data,int* num1,int *num2) {
int flag = data[0],diff = 1;
// 得到目标两数的异或结果
for(int i = 1;i < data.size();i++){
flag ^= data[i];
}
// 寻找第一个1
while(!(diff & flag)){
diff = diff << 1;
}
// 利用得到的1把数组分成两个
*num1 = 0;
*num2 = 0;
for(auto &num:data){
if(num & diff) *num1 ^= num;
else *num2 ^= num;
}
}
}; 引申:
数组中其他数字均出现3次,有1个数字只出现1次,找出该数(**)
思路:
一个int一共32位,统计每一位上1出现的次数,如果能被3整除,则出现1次那个数在该位上为0,否则为1
(1) 写法1:flag左移
class Solution {
public:
int singleNumber(vector& nums) {
int res = 0,flag = 1,count;
// 对每一位,统计该位上1出现次数,如果不能被3整除,这个为就是那个出现1次数的1位
for(int i = 0;i < 32;i++){
count = 0;
for(auto &num:nums){
if(num & flag) count++;
}
res |= (count%3) << i;
// flag左移的话是每次左移一位
flag = flag << 1;
}
return res;
}
}; (2)写法2:数字右移
class Solution {
public:
int singleNumber(vector& nums) {
int res = 0,flag = 1,count;
// 对每一位,统计该位上1出现次数,如果不能被3整除,这个为就是那个出现1次数的1位
for(int i = 0;i < 32;i++){
count = 0;
for(auto &num:nums){
// 数字右移每次移动i
if((num >> i) & flag) count++;
}
cout << count << endl;
res |= (count%3) << i;
}
return res;
}
}; 时间复杂度更小做法:
O(n)时间复杂度:数组A中,除了某一个数字x之外,其他数字都出现了三次,而x出现了一次。请给出最快的方法,找到x_昨日明眸的博客-CSDN博客
57.和为S的两个数字
输入一个递增排序的数组和一个数字S,在数组中查找两个数,使得他们的和正好是S,如果有多对数字的和等于S,输出两个数的乘积最小的
思路:双指针
这里注意:
找到的第一组(相差最大的)就是乘积最小的。
可以这样证明:

class Solution {
public:
vector FindNumbersWithSum(vector array,int sum) {
int low = 0,high = array.size()-1,cur_sum;
vector res;
while(low < high){
cur_sum = array[low]+array[high];
if(cur_sum < sum) low++;
else if(cur_sum > sum) high--;
else {
res.push_back(array[low]);
res.push_back(array[high]);
break;
}
}
return res;
}
}; 和为S的连续正数序列(**)
输出所有和为S的连续正数序列。序列内按照从小至大的顺序,序列间按照开始数字从小到大的顺序
如:连续正数和为100的序列:18-22和9-16
思路:
思路1:暴力解法
固定首个数字,然后暴力求解,这样时间复杂度为O(N*N),过于耗时
思路2:双指针
使用双指针指向连续序列的首尾
如果该序列和小于目标,则右移右指针
如果该序列和大于目标,则右移左指针
直到左指针>右指针
时间复杂度:O(N)
class Solution {
public:
vector > res;
vector > FindContinuousSequence(int sum) {
if(sum < 3) return res;
int low = 1,high = 2,cur_sum = low+high;
while(low < high){
cur_sum = (low+high)*(high-low+1)/2;
if(cur_sum > sum) low++;
else if(cur_sum < sum) high++;
else{
vector out;
for(int i = low;i <= high;i++){
out.push_back(i);
}
res.push_back(out);
low++;
}
}
return res;
}
}; 58.左旋转字符串
对于一个给定的字符序列S,请你把其循环左移K位后的序列输出。例如,字符序列S=”abcXYZdef”,要求输出循环左移3位后的结果,即“XYZdefabc”
思路:
先整体翻转一次,而后再分界点前后各自翻转一次
reverse(beg,end) 会将[beg,end)之内的元素全部逆置
class Solution {
public:
string LeftRotateString(string str, int n) {
if(str.size() < 2) return str;
reverse(str.begin(),str.end());
reverse(str.begin(),str.begin()+str.size()-n);
reverse(str.begin()+str.size()-n,str.end());
return str;
}
};写法2:
class Solution {
public:
string LeftRotateString(string str, int n) {
int len = str.size();
if(len < 2) return str;
// 注意这一步
n = n%len;
for(int i = 0,j = n-1;i < j;i++,j--) swap(str[i],str[j]);
for(int i = n,j = len-1;i < j;i++,j--) swap(str[i],str[j]);
for(int i = 0,j = len-1;i < j;i++,j--) swap(str[i],str[j]);
return str;
}
};翻转单词顺序列(**)
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变,标点符号和普通字母一样处理。
例如“I am a student.”,翻转后变为“student. a am I”
思路:
先翻转整个句子,然后,依次翻转每个单词。
依据空格来确定单词的起始和终止位置,不要忘记最后一个单词单独进行反转!!!
class Solution {
public:
string ReverseSentence(string str) {
reverse(str.begin(),str.end());
int begin = 0,end = 0;
while(end < str.size()){
if(str[end] != ' ') end++;
else{
reverse(str.begin()+begin,str.begin()+end);
begin = end+1;
end++;
}
}
// //最后一个单词单独进行反转
reverse(str.begin()+begin,str.begin()+end);
return str;
}
};59.滑动窗口的最大值(*)
给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针对数组{2,3,4,2,6,2,5,1}的滑动窗口有以下6个: {[2,3,4],2,6,2,5,1}, {2,[3,4,2],6,2,5,1}, {2,3,[4,2,6],2,5,1}, {2,3,4,[2,6,2],5,1}, {2,3,4,2,[6,2,5],1}, {2,3,4,2,6,[2,5,1]}。
思路:
我们可以使用一个双端队列deque。
我们可以用STL中的deque来实现,接下来我们以数组{2,3,4,2,6,2,5,1}为例,来细说整体思路。
数组的第一个数字是2,把它存入队列中。第二个数字是3,比2大,所以2不可能是滑动窗口中的最大值,因此把2从队列里删除,再把3存入队列中。第三个数字是4,比3大,同样的删3存4。此时滑动窗口中已经有3个数字,而它的最大值4位于队列的头部。
第四个数字2比4小,但是当4滑出之后它还是有可能成为最大值的,所以我们把2存入队列的尾部。下一个数字是6,比4和2都大,删4和2,存6。就这样依次进行,最大值永远位于队列的头部。
但是我们怎样判断滑动窗口是否包括一个数字?应该在队列里存入数字在数组里的下标,而不是数值。当一个数字的下标与当前处理的数字的下标之差大于或者相等于滑动窗口大小时,这个数字已经从窗口中滑出,可以从队列中删除
class Solution {
public:
vector maxInWindows(const vector& num, unsigned int size){
vector res;
deque q;
for(int i = 0;i < num.size();i++){
// 比当前值小的,都出队
while(q.size() && num[q.back()] <= num[i]) q.pop_back();
// 如果队首最大值的下标,与当前差值超过size,出队
while(q.size() && i-q.front()+1 > size) q.pop_front();
// 入队的是下标
q.push_back(i);
if(size && i+1 >= size) res.push_back(num[q.front()]);
}
return res;
}
}; 60.n个骰子的点数(**)
将一个骰子投掷n次,获得的总点数为s,s的可能范围为n~6n。
掷出某一点数,可能有多种掷法,例如投掷2次,掷出3点,共有[1,2],[2,1]两种掷法。
请求出投掷n次,掷出n~6n点分别有多少种掷法。
样例1
输入:n=1
输出:[1, 1, 1, 1, 1, 1]
解释:投掷1次,可能出现的点数为1-6,共计6种。每种点数都只有1种掷法。所以输出[1, 1, 1, 1, 1, 1]。
样例2
输入:n=2
输出:[1, 2, 3, 4, 5, 6, 5, 4, 3, 2, 1]
解释:投掷2次,可能出现的点数为2-12,共计11种。每种点数可能掷法数目分别为1,2,3,4,5,6,5,4,3,2,1。
所以输出[1, 2, 3, 4, 5, 6, 5, 4, 3, 2, 1]。思路:
i 等于1-6,f[n][sum] = f[n-1][sum-i],不断递推下去
class Solution {
public:
vector numberOfDice(int n) {
vector> f(2,vector(n*6+1,0));
vector res;
for(int i = 1;i <= 6;i++) f[1][i] = 1;
int flag = 1;
for(int i = 2;i <= n;i++){
flag = i & 1;
for(int j = i;j <= 6*i;j++){
// 这里注意要先置零
f[flag][j] = 0;
// 这里要判断j-k >= i-1,不要遗漏,不然越界
for(int k = 1;k <= 6 && j-k >= i-1;k++){
f[flag][j] += f[1-flag][j-k];
}
}
}
// 输出结果
for(int i = n;i <= 6*n;i++) res.push_back(f[flag][i]);
return res;
}
};
61.扑克牌中顺子
从扑克牌中随机抽5张牌,判断是不是一个顺子,即这5张牌是不是连续的。
2~10为数字本身,A为1,J为11,Q为12,K为13,大小王可以看做任意数字。
为了方便,大小王均以0来表示,并且假设这副牌中大小王均有两张。
样例1
输入:[8,9,10,11,12]
输出:true
样例2
输入:[0,8,9,11,12]
输出:true思路:统计里面空缺数目,是否小于等于0的个数
class Solution {
public:
bool isContinuous( vector numbers ) {
if(numbers.size() < 5) return false;
int cnt_0 = 0,i = 0;
sort(numbers.begin(),numbers.end());
while(numbers[i] == 0) {cnt_0++;i++;}
for(;i < numbers.size()-1;i++){
int diff = numbers[i+1]-numbers[i]-1;
if(diff < 0 || diff > cnt_0) return false;
else cnt_0 -= diff;
}
return true;
}
}; 65.不用加减乘除做加法
二进制加法,异或获得不进位加法结果,与操作左移一位获得进位效果,继续循环累加
class Solution {
public:
int add(int num1, int num2){
int sum = num1,carry;
while(num2 != 0){
sum = num1 ^ num2;
carry = (num1 & num2) << 1;
num1 = sum;
num2 = carry;
}
return sum;
}
};66.构建乘积数组
给定一个数组A[0,1,...,n-1],请构建一个数组B[0,1,...,n-1],其中B中的元素B[i]=A[0]*A[1]*...*A[i-1]*A[i+1]*...*A[n-1]。不能使用除法。
思路:
如果每次都直接计算,则时间复杂度是O(n*n)
这里使用中间结果
class Solution {
public:
vector multiply(const vector& A) {
int len = int(A.size());
vector b(len);
// 边界
if(len < 2) return b;
int ret = 1;
// 注意这里的条件
for(int i = 0;i < len;ret *= A[i++]){
b[i] = ret;
}
ret = 1;
for(int i = len-1;i >= 0;ret *= A[i--]){
b[i] *= ret;
}
return b;
}
}; 64.求1+2+…+n
求1+2+…+n,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
样例
输入:10
输出:55class Solution {
public:
int getSum(int n) {
int res = n;
// 短路做
n >= 1 && (res += getSum(n-1));
return res;
}
};数组中重复的数字
在一个长度为n的数组里的所有数字都在0到n-1的范围内。 数组中某些数字是重复的,但不知道有几个数字是重复的。也不知道每个数字重复几次。请找出数组中任意一个重复的数字。 例如,如果输入长度为7的数组{2,3,1,0,2,5,3},那么对应的输出是第一个重复的数字2。
思路:
思路1:直接排序
时间复杂度:O(NlogN)
空间复杂度:O(1)
思路2:使用哈希表存
时间复杂度:O(N)
空间复杂度:O(N)
思路3:使用题目标红的信息,利用下标来做
class Solution {
public:
// Parameters:
// numbers: an array of integers
// length: the length of array numbers
// duplication: (Output) the duplicated number in the array number
// Return value: true if the input is valid, and there are some duplications in the array number
// otherwise false
bool duplicate(int numbers[], int length, int* duplication) {
int idx = 0,cur;
while(idx < length){
// cur的取值范围判断!!
if(numbers[idx] < 0 || numbers[idx] >= length) return false;
// 与下标相等,直接判断下一个
if(numbers[idx] == idx) {idx++;continue;}
// 不等的时候判断,是否对应下标已经有该数
if(numbers[numbers[idx]] == numbers[idx]){
*duplication = numbers[idx];
return true;
}
// 交换
swap(numbers[idx],numbers[numbers[idx]]);
}
return false;
}
};表示数值的字符串(*)
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。
例如,字符串"+100","5e2","-123","3.1416"和"-1E-16"都表示数值。
但是"12e","1a3.14","1.2.3","+-5"和"12e+4.3"都不是。
思路:有限状态自动机

class Solution {
public:
bool isNumeric(char* string){
enum input_type{invalid,
sign,
num,
dot,
exp};
vector> trans_table = {{-1,1,2,3,4},
{-1,-1,2,3,-1},
{-1,-1,2,3,4},
{-1,-1,5,-1,-1},
{-1,6,7,-1,-1},
{-1,-1,5,-1,4},
{-1,-1,7,-1,-1},
{-1,-1,7,-1,-1}};
int state = 0;
input_type type;
while(*string != '\0'){
if(*string == '+' || *string == '-') type = sign;
else if(*string >= '0' && *string <= '9') type = num;
else if(*string == '.') type = dot;
else if(*string == 'e' || *string == 'E') type = exp;
else type = invalid;
state = trans_table[state][type];
if(state == -1) return false;
string++;
}
if(state == 2 || state == 5 || state == 7) return true;
return false;
}
}; 删除链表中重复的结点
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
(1)非递归
注意想清楚,这个写法比较容易出现问题
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead){
if(!pHead || !pHead->next) return pHead;
ListNode *dummy_head = new ListNode(-1);
ListNode *cur = pHead,*dummy_cur = dummy_head;
while(cur){
// 不同时
if(!cur->next || cur->next->val != cur->val){
dummy_cur->next = cur;
dummy_cur = dummy_cur->next;
cur = cur->next;
// 注意这里要置NULL,不然末尾的重复会无法删除
dummy_cur->next = NULL;
}else{
int dup = cur->val;
while(cur && cur->val == dup) cur = cur->next;
}
}
return dummy_head->next;
}
};(2)递归写法
相对不容易出问题
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};
*/
class Solution {
public:
ListNode* deleteDuplication(ListNode* pHead){
if(!pHead || !pHead->next) return pHead;
// 当前节点不重复时
if(pHead->val != pHead->next->val){
pHead->next = deleteDuplication(pHead->next);
return pHead;
}
// 当前节点重复时
else{
int dup = pHead->val;
ListNode* cur = pHead;
while(cur && cur->val == dup) cur = cur->next;
return deleteDuplication(cur);
}
}
};二叉树的下一个结点
思路:
(1)存在右子树,则右子树最左节点就是下一个点
(2)不存在右子树
如果该节点是其父节点的左孩子,则返回父节点;
否则继续向上遍历其父节点的父节点,重复之前的判断,返回结果。
/*
struct TreeLinkNode {
int val;
struct TreeLinkNode *left;
struct TreeLinkNode *right;
struct TreeLinkNode *next;
TreeLinkNode(int x) :val(x), left(NULL), right(NULL), next(NULL) {
}
};
*/
class Solution {
public:
TreeLinkNode* GetNext(TreeLinkNode* pNode){
if(!pNode) return NULL;
// 存在右子树,则为右子树最左节点
if(pNode->right){
TreeLinkNode* cur = pNode->right;
while(cur->left) cur = cur->left;
return cur;
}
// 不存在右子树
else{
TreeLinkNode* father = pNode->next,*cur = pNode;
while(father && father->left != cur){
cur = father;
father = cur->next;
}
return father;
}
return NULL;
}
};中序遍历上一个节点:
我没验证过,感觉写的没问题
class Solution {
public:
TreeLinkNode* GetNext(TreeLinkNode* pNode){
if(!pNode) return NULL;
// 存在左子树,则为左子树最右节点
if(pNode->left){
TreeLinkNode* cur = pNode->left;
while(cur->right) cur = cur->right;
return cur;
}
// 不存在左子树
else{
TreeLinkNode* father = pNode->next,*cur;
while(father && father->right == cur){
cur = father;
father = cur->next;
}
return father;
}
return NULL;
}
};最低公共祖先
普通二叉树
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == NULL || root == p || root == q) return root;
// 递归找左右
TreeNode* left = lowestCommonAncestor(root->left,p,q);
TreeNode* right = lowestCommonAncestor(root->right,p,q);
// 左右都找到,说明当前点就是
if(left && right){
return root;
}
// 左边
if(left) return left;
else return right;
}
};非递归写法
我们找出一条从根到A的路径保存到栈或者数组,相同的方式找到一条从根到B的路径也保存到栈或者数组(参考:查找从根到某结点的路径)。然后开始遍历这两个数组,找到第一次下标相同但是值不同的那么数的下标,这个下标的前一个数就是最近公共祖先。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == p || root == q) return root;
int idx = 0;
// 找到根到p和q的路径
vector path1 = getPath(root,p);
vector path2 = getPath(root,q);
while(idx < path1.size() && idx < path2.size() && path1[idx]->val == path2[idx]->val) idx++;
// 最后一个相同的点就是最近公共祖先
if(idx >= path1.size()) return p;
else if(idx >= path2.size()) return q;
else return path1[idx-1];
}
// 找到你从root到p的路径返回
vector getPath(TreeNode* root, TreeNode* p){
stack s;
TreeNode* cur = root,*pre;
while(cur || !s.empty()){
while(cur){
s.push(cur);
if(cur == p) return convert(s);
cur = cur->left;
}
cur = s.top();
// 没有右子树,或者右子树已经被访问
while(!cur->right || pre && cur->right == pre){
pre = cur;
s.pop();
cur = s.top();
}
cur = cur->right;
}
return convert(s);
}
vector convert(stack s){
vector res;
while(!s.empty()){
res.push_back(s.top());
s.pop();
}
reverse(res.begin(),res.end());
return res;
}
}; 有指向父节点的二叉树
相当于两个链表第一个交点
二叉搜索树
传统的二叉树要找一个节点,需要O(n)时间的深度搜索或者广度搜索,但是BST却只要O(logn)就可以,有了这一层便利,我们的思路就可以很简洁。
(1) 如果给定的节点确定在二叉树中,那么我们只要将这两个节点值(a和b)和根节点(root->val)比较即可,如果root->val 的大小在a和b之间,或者root->val 和a b中的某一个相等,那最低公共祖先就是root了。否则,如果a b 都比(root->val)小,那继续基于 root -> left 重复上述过程即可;如果a b 都比(root->val) 大,root -> right,递归实现。
(2) 如果是给定节点值,并且不能保证这两个值在二叉树中,那么唯一的变化就是:当root->val 的大小在a和b之间,或者root -> val 等于a或b 的情况出现时,我们不能断定最低公共祖先就是root,需要在左(右) 枝继续搜索 a或者b,找到才能断定最低公共祖先就是root。递归过程的root都遵循这个规则。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(p->val == q->val) return p;
if(p->val > q->val) swap(p,q);
TreeNode* cur = root;
while(!((cur->val >= p->val) && (cur->val <= q->val))){
if(cur->val < p->val) cur = cur->right;
else cur = cur->left;
}
return cur;
}
};