【深入浅出 Yarn 架构与实现】 Yarn 三种调度器
本篇文章将深入介绍 Yarn 三种调度器。Yarn 本身作为资源管理和调度服务,其中的资源调度模块更是重中之重。下面将介绍 Yarn 中实现的调度器功能,以及内部执行逻辑。
一、简介#
Yarn 最主要的功能就是资源管理与分配。本篇文章将对资源分配中最核心的组件调度器(Scheduler)进行介绍。
调度器最理想的目标是有资源请求时,立即满足。然而由于物理资源是有限的,就会存在资源如何分配的问题。针对不同资源需求量、不同优先级、不同资源类型等,很难找到一个完美的策略可以解决所有的应用场景。因此,Yarn提供了多种调度器和可配置的策略供我们选择。
Yarn 资源调度器均实现 ResourceScheduler 接口,是一个插拔式组件,用户可以通过配置参数来使用不同的调度器,也可以自己按照接口规范编写新的资源调度器。在 Yarn 中默认实现了三种调速器:FIFO Scheduler 、Capacity Scheduler、Fair Scheduler。
官方对三种调度器的介绍图。看个大概意思就行,随着调度器的不断更新迭代,这个图不再符合当下的情况。
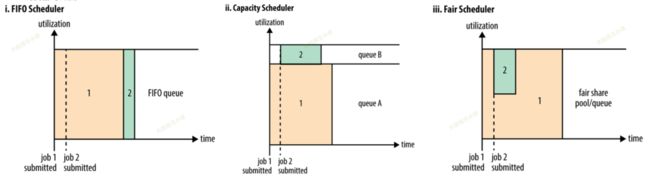
二、FIFO#
最简单的一个策略,仅做测试用。
用一个队列来存储提交等待的任务,先提交的任务就先分资源,有剩余的资源就给后续排队等待的任务,没有资源了后续任务就等着之前的任务释放资源。
优点:
简单,开箱即用,不需要额外的配置。早些版本的 Yarn 用 FIFO 作为默认调度策略,后续改为 CapacityScheduler 作为默认调度策略。
缺点:
除了简单外都是缺点,无法配置你各种想要的调度策略(限制资源量、限制用户、资源抢夺等)。
三、CapacityScheduler#
一)CS 简介#
Capacity Scheduler(后以 CS 简写代替)以队列为单位划分资源。会给每个队列配置最小保证资源和最大可用资源。最小配置资源保证队列一定能拿到这么多资源,有空闲可共享给其他队列使用;最大可用资源限制队列最多能使用的资源,防止过度消耗。
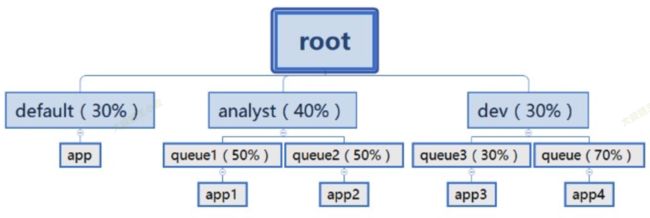
队列内部可以再嵌套,形成层级结构。队列内资源默认采用 FIFO 的方式分配。如下图所示。
优点:
- 队列最低资源保障,防止小应用饿死;
- 空闲容量共享,当队列配置资源有空闲时可共享给其他队列使用
缺点:
- 队列配置繁琐,父队列、子队列都要单独配置优先级、最大资源、最小资源、用户最大资源、用户最小资源、用户权限配置等等。工程中会写个程序,自动生成该配置;
二)CS 特征#
- 分层队列 (Hierarchical Queues):支持队列分层结构,子队列可分配父队列可用资源。
- 容量保证 (Capacity Guarantees):每个队列都会配置最小容量保证,当集群资源紧张时,会保证每个队列至少能分到的资源。
- 弹性 (Elasticity):当队列配置资源有空闲时,可以分配给其他有资源需求的队列。当再次需要这些资源时可以抢夺回这些资源。
- 安全性 (Security):每个队列都有严格的 ACL,用于控制哪些用户可以向哪些队列提交应用程序。
- 多租户 (Multi-tenancy):提供全面的限制以防止单个应用程序、用户和队列从整体上独占队列或集群的资源。
- 优先级调度 (Priority Scheduling):此功能允许以不同的优先级提交和调度应用程序。同时队列间也支持优先级配置(2.9.0 后支持)。
- 绝对资源配置 (Absolute Resource Configuration):管理员可以为队列指定绝对资源,而不是提供基于百分比的值(3.1.0 后支持)。
- 资源池配置:可将 NodeManager 分割到不同的资源池中,资源池中配置队列,进行资源隔离。同时资源池有共享和独立两种模式。在共享情况下,多余的资源会共享给 default 资源池。
三)CS 配置#
假设队列层级如下:
root
├── prod
└── dev
├── eng
└── science
可以通过配置 capacity-scheduler.xml 来实现:
yarn.scheduler.capacity.root.queues
prod,dev
yarn.scheduler.capacity.root.dev.queues
eng,science
yarn.scheduler.capacity.root.prod.capacity
40
yarn.scheduler.capacity.root.dev.capacity
60
yarn.scheduler.capacity.root.dev.eng.capacity
50
yarn.scheduler.capacity.root.dev.science.capacity
50
除了容量配置外,还可以配置单个用户或者程序能够使用的最大资源数,同时可以运行几个应用,权限ACL控制等,不是本篇重点,不再展开。可参考:cloudera - Capacity Scheduler、Hadoop doc - Capacity Scheduler、Hadoop: Capacity Scheduler yarn容量调度配置。
四)CS 实现#
这里仅关注 CS 资源分配的过程。
CS 分配的是各 NM 节点上的空闲资源,NM 资源汇报请到之前的文章《4-3 RM 管理 NodeManager》中了解。
1、资源请求描述#
AM 通过心跳汇报资源请求,包含的信息如下。
message ResourceRequestProto {
optional PriorityProto priority = 1; // 优先级
optional string resource_name = 2; // 期望资源所在节点或机架
optional ResourceProto capability = 3; // 资源量
optional int32 num_containers = 4; // Container 数目
optional bool relax_locality = 5 [default = true]; // 是否松弛本地性
optional string node_label_expression = 6; // 所在资源池
}
2、资源更新入口#
NM 发送心跳给 RM 后,RM 会发送 NODE_UPDATE 事件,这个事件会由 CapacityScheduler 进行处理。
case NODE_UPDATE:
{
NodeUpdateSchedulerEvent nodeUpdatedEvent = (NodeUpdateSchedulerEvent)event;
RMNode node = nodeUpdatedEvent.getRMNode();
setLastNodeUpdateTime(Time.now());
nodeUpdate(node);
if (!scheduleAsynchronously) {
// 重点
allocateContainersToNode(getNode(node.getNodeID()));
}
}
重点在 allocateContainersToNode(),内部逻辑如下:
- 从根队列往下找,找到 most 'under-served' 队列(即 已分配资源/配置资源 最小的);
- 先满足已经预留资源(RESERVED)的容器
- 再处理未预留的资源请求,如果资源不够,则进行 RESERVE,等待下次分配
这里有个预留的概念(之后会有文章专门介绍 reserve 机制):
- RESERVED 是为了防止容器饿死;
- 传统调度:比如一堆 1G 和 2G 的容器请求,当前集群全被 1G 的占满了,当一个 1G 的容器完成后,下一个还是会调度 1G,因为 2G 资源不够;
- RESERVED 就是为了防止这种情况发生,所以先把这个资源预留出来,谁也别用,等下次有资源了再补上,直到满足这个容器资源请求。
四、FairScheduler#
一、Fair 简介#
同 Capacity Seheduler 类似,Fair Scheduler 也是一个多用户调度器,它同样添加了多层级别的资源限制条件以更好地让多用户共享一个 Hadoop 集群,比如队列资源限制、用户应用程序数目限制等。
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。如下图所示,当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
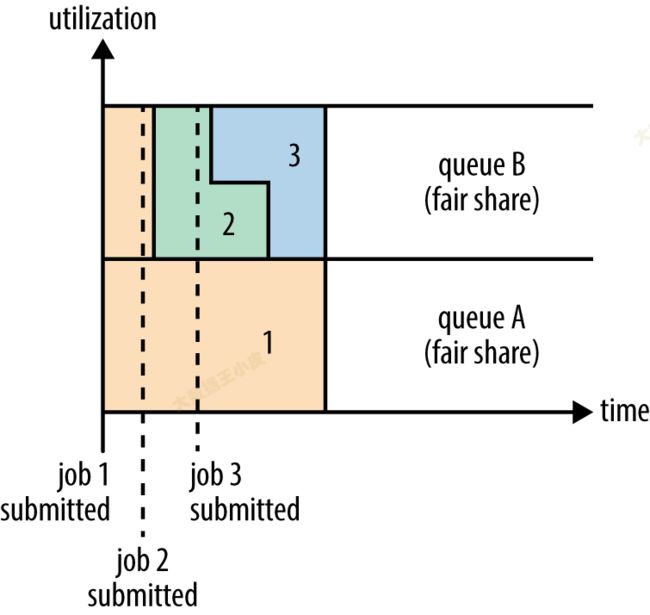
Fair 调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。
优点:
- 分配给每个应用程序的资源取决于其优先级;
- 它可以限制特定池或队列中的并发运行任务。
二)Fair 特征#
- 公平调度器,就是能够共享整个集群的资源
- 不用预先占用资源,每一个作业都是共享的
- 每当提交一个作业的时候,就会占用整个资源。如果再提交一个作业,那么第一个作业就会分给第二个作业一部分资源,第一个作业也就释放一部分资源。再提交其他的作业时,也同理。也就是说每一个作业进来,都有机会获取资源。
- 权重属性,并把这个属性作为公平调度的依据。如把两个队列权重设为 2 和 3,当调度器分配集群 40:60 资源给两个队列时便视作公平。
- 每个队列内部仍可以有不同的调度策略。队列的默认调度策略可以通过顶级元素 进行配置,如果没有配置,默认采用公平调度。
三)Fair 配置#
在 FairScheduler 中是通过在 fair-scheduler.xml 中配置队列权重,来实现「公平」的。
计算时是看(当前队列权重 / 总权重)得到当前队列能分得资源的百分比。
更详细参数配置,可参考:Yarn 调度器Scheduler详解
512mb, 4vcores
30720nb, 30vcores
100
fair
2.0
512mb, 4vcores
30720nb, 30vcores
100
fair
1.0
五、Fair Scheduler与Capacity Scheduler区别#

相同点
- 都支持多用户多队列,即:适用于多用户共享集群的应用环境
- 都支持层级队列
- 支持配置动态修改,更好的保证了集群的稳定运行。
- 均支持资源共享,即某个队列中的资源有剩余时,可共享给其他缺资源的队列
- 单个队列均支持优先级和FIFO调度方式
不同点
- Capacity Scheduler的调度策略是,可以先选择资源利用率低的队列,然后在队列中通过FIFO或DRF进行调度。
- Fair Scheduler的调度策略是,可以使用公平排序算法选择队列,然后再队列中通过Fair(默认)、FIFO或DRF的方式进行调度。
六、小结#
本篇介绍了 Yarn 中组重要的资源调度模块 ResourceScheduler,作为一个可插拔组件,默认有三种实现方式 Fifo、CapacityScheduler、FairScheduler。
文中对三个调度器的功能、特征、配置、实现进行了较为详细的分析。各位同学若对其中实现细节有兴趣可深入源码,进一步探究。