0基础搞工程-基于Chromadb+Chatglm6-2B私有知识库的智能回答系统-1
Part1:前言,吹吹水系列
在准备开新坑之前,我已经很久很久很久没有更新,主要是前段时间太忙,再加上准备跳槽,所以时至今日,才有空洋洋洒洒的再一次回到这里来开始新的项目,最近也面试了货拉拉(过了没去),深度赋智(目前进入二面),目前尚且跳槽到另外一家国企工作。
这是一个全新的系列,在这个工程中,我们将偏向于实战化应用,让大模型落地,主打就是一个应用化(跟风化),并给出实现的全流程精细讲解和避坑指南。
Part2:基本的框架使用和项目设计
最近看到很多基于Langchain+向量数据库+开源语言模型来实现一个私有的智能问答系统,因此本着研究(赶风口,凑热闹)的精神,所以也想来试试做一个前后端分离的框架,基本来说使用Langchian作为集成框架,Chromadb作为本地化知识库的存储,ChatGLM2-6B作为本地的LLM服务模型(并且将跑在CPU上),Gradio作为前端页面框架来实现。
这一个项目将分为如下的几个部分(博客)来进行输出,并且将完全基于Python和少量CSS
| 1.项目的基本架构设计,langchain,chromadb,gradio的项目要求和基本的前端设计 |
| 2.基于web装载的chatglm2-6b的本地CPU部署(实现前后端分离技术) |
| 3.基于chromadb的本地知识库搭建和系统联调,完成整个流程 |
从业务的角度出发,我们可以拆解为如下的几个部分,一个是大模型交互工具,一个是本地化数据库能力,一个是前端调用框架,首先我们将ChatGLM2-6B部署在一台远端服务器上使用httpd服务,暴露一个接口使用post方法来进行访问,并得到输出,并将chromadb改造为使用远端部署的word2vector模型得到的embeddeding来作为向量存储。
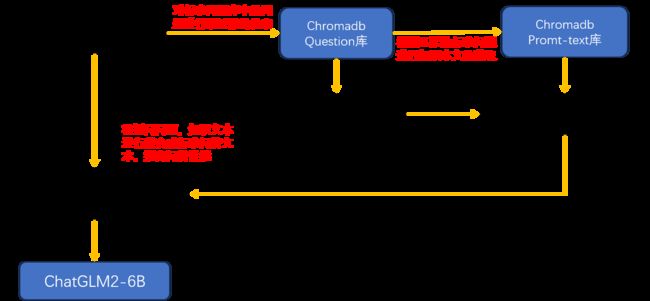
项目中的层级和设计模式如下图:

Part3:基本模式和业务流程
Part4:环境设置部分
| 工具 | 版本 |
|---|---|
| Anaconda | conda 23.7.2 |
| Python | Python 3.9.6(请不要使用低于3.8或者高于3.11版本) |
| Langchain | 0.0.265 |
| Chromadb | 0.4.6(原先用的0.3.4,不过存在意料外的问题) |
| Gradio | 3.40.1(唯一不坑爹的东西) |
先说说环境上的坑,由于langchain和chromadb是大模型的附属产品,因此实际上在此之前他们不存在或者不太出名,因此对于Python版本的要求会稍微比较高,具体的奇葩情况如下:
1.由于Pytorch的缘故,对于Chromadb而言是不支持Python3.11.2版本的
2.对于langchain而言不建议使用低于Python3.8版本的解析器,因为太老的版本只能使用很古早时期的langchain
3.对于chromadb而言建议使用0.4.6,在开发中发现0.3.4版本缺少一个方法,对于0.3.4版本无法及时的从内存写到磁盘,只有结束进程时才会把内存数据lazy到磁盘中
Part5:前端页面和方法部分
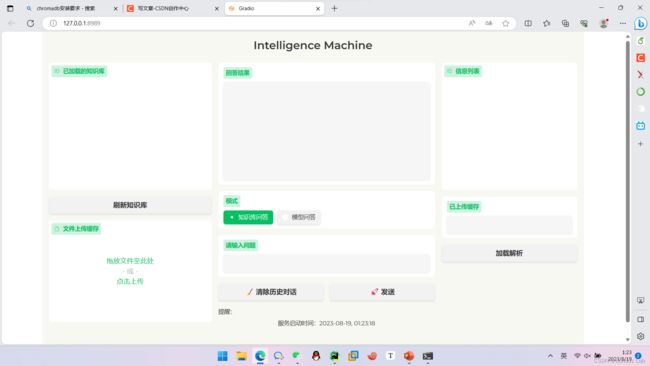
由于装饰部分的代码没啥意义,也没啥好说的,所以我们就把那部分放给大家自行百度云盘获取,我们只放一些重要的python代码,如下是UIinit,py的源代码,它的效果图如下图所示:
所有的源代码如下链接获取:
https://pan.baidu.com/s/1Q5Uz74NjNnCU9PCSOGveGg?pwd=3qu3 https://pan.baidu.com/s/1Q5Uz74NjNnCU9PCSOGveGg?pwd=3qu3 效果如图所示:
https://pan.baidu.com/s/1Q5Uz74NjNnCU9PCSOGveGg?pwd=3qu3 效果如图所示:
UIinit.py 代码如下:
import time
from app_modules.presets import *
import gradio as gr
from application import *
def main(IP,Port):
with open("assets/custom.css", "r", encoding="utf-8") as f:
customCSS = f.read()
with gr.Blocks(css=customCSS, theme=small_and_beautiful_theme) as demo:
gr.Markdown("""Intelligence Machine
""")
state = gr.State()
with gr.Row():
with gr.Column(scale=3):
kg_name = gr.Chatbot(label='已加载的知识库',height=300)
kg_btn = gr.Button("刷新知识库")
kg_btn.click(menberload,inputs=[], outputs=kg_name)
file = gr.File(label="文件上传缓存",visible=True,file_types=['.txt'],file_count="multiple")
with gr.Column(scale=4):
with gr.Row():
search = gr.Textbox(label='回答结果',lines=10)
with gr.Row():
use_pattern = gr.Radio(['知识库问答', '模型问答'], label="模式", value='知识库问答', interactive=True, every=1.0)
with gr.Row():
message = gr.Textbox(label='请输入问题')
with gr.Row():
clear_history = gr.Button(" 清除历史对话")
send = gr.Button(" 发送")
with gr.Row():
gr.Markdown(f"""提醒:
{"服务启动时间:"+str(time.strftime("%Y-%m-%d, %H:%M:%S"))}
""")
with gr.Column(scale=2):
chatbot = gr.Chatbot(label="信息列表",height=300)
huancun_name = gr.Textbox(label="已上传缓存")
set_kg_btn = gr.Button("加载解析")
set_kg_btn.click(dataloaddb, inputs=[], outputs=chatbot)
# ============= 触发动作=============
file.upload(upload_file,inputs=file,outputs=huancun_name)
# set_kg_btn.click(chat, show_progress=True, inputs=[message,use_pattern], outputs=chatbot)
# 发送按钮 提交
send.click(chat,inputs=[message,use_pattern], outputs=search)
# 清空历史对话按钮 提交
clear_history.click(fn=clear_session,inputs=[],outputs=[chatbot, state],queue=False)
# 输入框 回车
message.submit(chat,inputs=[message,use_pattern],outputs=search)
demo.queue(concurrency_count=2)
demo.launch(server_name=IP,server_port=Port,share=False,show_error=True,debug=True,enable_queue=True,inbrowser=True)
if __name__=="__main__":
#file_list = get_file_list()
IP="127.0.0.1"
Port=8989
main(IP,Port)
Part6:前端页面对应的功能组件
在这里将主要展示的是,UIinit.py中对应的函数,不过application中的部分函数调用涉及到了Chromadb的一些操作,因此数据库函数会在下一期中集中讲解,今天是第一天主要过一遍Gradio的用法,和对项目整体框架的预览 。
下图中我们给出了所有按钮的功能解释和函数的调用,并给出了分析和结果,application.py的源代码也如下所示: 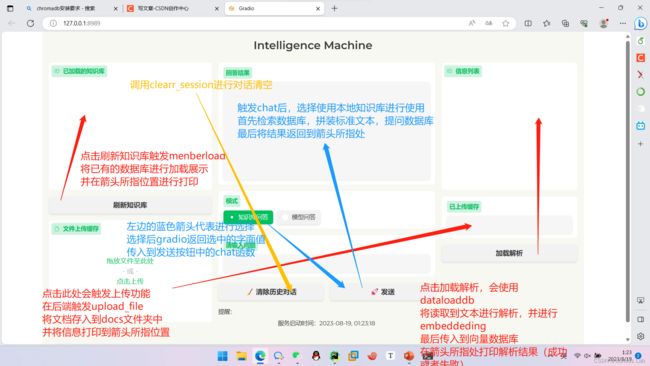
application.py的源代码也如下所示,请注意大模型的对话httpd服务地址要你自己给哦,不过后期我也会出一期,cpu部署LLM的方法,生成速度较慢,但也不是完全不能离开卡。
from NewChatGlm import newChatGLM
from dbSolve import *
import os
import shutil
class LangChain:
def connectLLM(selfs,url):
try:
llm = newChatGLM(endpoint_url=url)
return llm
except Exception as e:
print(e)
def TalkWithLLM(self,text,llm):
try:
#result = llm.post({"messages": [{"content": text}],"stream": True})
result = llm.post({"messages": [{"content": text}]})
return result
except Exception as e:
print(e)
def onefileload(file):
filename = os.path.basename(file.name)
shutil.move(file.name, "docs/" + filename)
return filename
def upload_file(file):
if not os.path.exists("docs"):
os.mkdir("docs")
if len(file)==1:
filename=onefileload(file[0])
else:
filename=[]
for i in range(len(file)):
filename.append(onefileload(file[i]))
filename=','.join(filename)
r=filename
return r
def load(name,sets):
node = open("app_modules/"+name+".txt", sets, encoding="utf-8")
result=node.readlines()
result=[result[i] for i in range(len(result))]
return result
def menberload():
r=load("menber",'r')
r = [[None,i.replace('\n','')+"刷新成功"] for i in r]
return r
def clear_session():
return '', None
def chat(message,symbol):
localpath = os.getcwd()
questiondbpath=localpath + r"\vectordb\questiondb"
prompttextpath=localpath + r"\vectordb\promptdb"
questiondbname = "questiondb"
prompttextname ="promptdb"
querytext=[message]
n_results=1
message=PromptSearch(symbol,questiondbpath,questiondbname,prompttextpath,prompttextname,querytext,n_results)
LC=LangChain()
llm=LC.connectLLM("http://xxx.xxx.xxx.xxx:xxxx/glmchat2")
output=LC.TalkWithLLM(message,llm)
output=output["choices"][0]["message"]["content"]
return output
def dataloaddb():
filepath=os.listdir("docs")
localpath=os.getcwd()
questiondbpath = localpath + "/vectordb/questiondb"
prompttextpath = localpath + "/vectordb/promptdb"
questiondbname = "questiondb"
prompttextname = "promptdb"
try:
Sindex = [1 if "question" in filepath[i] else 0 for i in range(len(filepath))]
question_path = "docs/" + filepath[Sindex.index(1)].replace('\n', '')
text_path = "docs/" + filepath[Sindex.index(0)].replace('\n', '')
q,a=Allinchromadb(question_path, text_path, questiondbpath, questiondbname, prompttextpath, prompttextname)
name = question_path.split('-')[1]
nodes = open("app_modules/menber.txt", 'a', encoding="utf-8")
nodes.write(name + '\n')
nodes.close()
result="知识库解析成功"+str(q)
except Exception as e:
pathlist=os.listdir("docs")
for i in range(len(pathlist)):
os.remove("docs/"+pathlist[i])
name="该"
result = "知识库解析失败"
return [[None,name+result]]
Part6:本节节论
这是新坑开坑制作,0基础搞工程这个系列旨在让大家进行项目尝试和学习,并给出自己的一些解决思路和方法,并给出一个相对完整的作品,今天是系列的第一个工作的第一篇博客,主要是对项目设计进行了梳理并给出前端的基本实现和功能函数的写法,剩下的会在后续2篇博客中出现分别是对于chromadb的设计和讨论,一个是对于大模型部署的博客文章,敬请大家期待。