PyTorch实现基于LSTM的多变量输入多变量输出的Seq2Seq预测(进阶版)
我在几个月前接触深度学习,学习LSTM,后来写了一篇文章《基于pytorch的LSTM预测实现(入门级别)https://blog.csdn.net/m0_68676807/article/details/131033853》。
距离现在已经过去了好几个月,作为一个已经入门的学习者来说,我觉得有必要去说明几点。
1.对于现在市面上的这种滑动窗口的代码,这种真的只适合入门级别,写写水刊论文。没法实现需要的一些功能,在此基础上改进也非常困难! 如果有幸运者看到我这篇文章,恭喜你少走许多弯路,我之前没有师兄领路,一步步自己走过来,花了许多冤枉钱,浪费了许多时间与精力。
def sliding_windows(data, seq_length):
'''
Output:The data form we can feed GRU
'''
x = []
y = []
for i in range(len(data)-seq_length-1):
_x = data[i:(i+seq_length),:]
_y = data[i+seq_length,-1]
# _y = data[i + seq_length-1, -1]
x.append(_x)
y.append(_y)
2.市面上的代码,真正有用的很少,许多还有错误,我也不保证我的代码没有错误(深度学习就是盲盒)。这也是我最批判的地方,所谓的知识付费,无非又是为学习增加一道道门槛,过去的三年,口罩带来的线上学习,打破了纸质书带来的知识屏障,现在也带来了新的障碍!
3.对于TF2和PyTorch两种框架,我主要使用PyTorch,后来也去学习过TF2,还是建议学习PyTorch,他的条理非常清晰,下限高上限制也高!
进入正题,怎么搭建一个多输入,多输出或者是单输出的LSTM模型呢?
1.首先是编程理念,要跳出入门的时候的那种编程思路,如果你跳不出来,就是你还是不够深刻,这个时候就要多读优秀论文及他们的开源代码! 这里我也是非常幸运,在一开始接触时间序列预测,我就知道了Informer,当时不理解他的代码和论文,但是我始终没有放弃他,我一遍遍的看,每次都有收货,做学术这个东西,还是得看TOP学校和企业。Informer的代码地址我也给出了。
GitHub - zhouhaoyi/Informer2020: The GitHub repository for the paper "Informer" accepted by AAAI 2021.
“就好比有的人看起来什么都会一点,但实际上根本没有付出实际努力,总是想要走捷径。”
“不用担心,真正优秀的人不需要走捷径,因为只要他走起路来,脚下都是捷径。”
在过去的半年里面,我遇到了许许多多的学习上的难题,我就是把他放在一边,因为我坚信自己未来的某一刻可以攻克他,只需要我再努力一点点,积累一点点,事实证明也确实是这样!与君共勉!
2.我整个代码框架是参考Informer的,我就是学习他,写出了Seq2Seq 的LSTM预测模型,在Informer论文里面,作者也提到了LSTM模型,只是他们没有开源这部分代码!我觉得他们也可能也是这样实现的LSTM。
3.先自定义一个数据集,而不是想所有市面上的那样去创建输入数据集。代码我在这里给出,我不做过多解释,我也不会给出所有源码,因为这是我项目需要用到的代码,需要的人可以加我进行学术交流!(qq:1632401994)
这是用于训练的数据集Dataset_Custom(Dataset),在实现预测的时候会再创建一个数据集。在这里就不给出了。
class Dataset_Custom(Dataset):
def __init__(self,
file_path='./ETTm1.csv', split_rate=0.75, flag='train', target='OT',
seq_len=32,pred_len = 12,inverse=False,freq='15min',features='M'):
'''自定义参数设置'''
self.file_path = file_path
self.split_rate = split_rate
self.target = target
self.seq_len = seq_len
self.pred_len = pred_len
self.inverse = inverse
self.features = features
self.freq = freq
assert flag in ['train', 'test', 'val']
type_map = {'train': 0, 'val': 1, 'test': 2}
self.set_type = type_map[flag]
self.__read_data__()
def __read_data__(self):
df_raw = pd.read_csv(self.file_path)
self.scaler = StandardScaler()
cols = list(df_raw.columns)
cols.remove(self.target)
cols.remove('date')
df_raw = df_raw[['date'] + cols + [self.target]]
num_train = int(len(df_raw) * self.split_rate)
num_vali = int(len(df_raw) * 0.1)
num_test =len(df_raw) - num_train - num_vali
border1s = [0, num_train - self.seq_len, len(df_raw) - num_test - self.seq_len]
border2s = [num_train, num_train + num_vali, len(df_raw)]
border1 = border1s[self.set_type]
border2 = border2s[self.set_type]
cols_data = df_raw.columns[1:]
df_data = df_raw[cols_data]
train_data = df_data[border1s[0]:border2s[0]]
self.scaler.fit(train_data.values)
data = self.scaler.transform(df_data.values)
self.data_x = data[border1:border2]
# print('self.data_x, self.data_x[0])', len(self.data_x), self.data_x[0], self.data_x.shape)
if self.inverse:
self.data_y = df_data.values[border1:border2]
else:
self.data_y = data[border1:border2]
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end
r_end = r_begin + self.pred_len
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
return seq_x, seq_y
def __len__(self):
return len(self.data_x)-self.seq_len-self.pred_len + 1
def inverse_transform(self, data):
return self.scaler.inverse_transform(data)4.搭建模型,如果采用Informer的逻辑架构,这里就非常容易,输入X的shape是(batch,seq,features),经过LSTM输(batch,seq,features)我们不需要再输出的时候去取某一个序列,而是取Pred_len个序列,我目前不知道这一点会不会破坏时序性,我在看LInear模型的时候,作者在seq这个维度上面进行变换,但是他们有位置编码。所以这一点需要待确定,欢迎交流。
class LSTM(nn.Module):
def __init__(self,
input_size=7,
hidden_size=256,
num_layers=2,
output_size=7,
dropout=0.2,
seq_len =32,
pred_len=12,
device=torch.device('cuda:0')
):
super(LSTM,self).__init__()
self.outout_size = output_size
self.hidden_size = hidden_size
self.num_layers = num_layers
self.dropout = dropout
self.input_size = input_size
self.device = device
self.pred_len = pred_len
self.seq_len = seq_len
self.batch_first = True
self.bidirectional = False
self.lstm = nn.LSTM(input_size=self.input_size, hidden_size=self.hidden_size,
num_layers=self.num_layers, dropout=self.dropout,batch_first=self.batch_first, bidirectional=self.bidirectional)
self.reg = nn.Sequential(nn.Linear(self.hidden_size, self.hidden_size),
nn.Tanh(),
nn.Linear(self.hidden_size, self.outout_size),
)
self.Linear = nn.Linear(self.seq_len, self.pred_len)
def initial_hidden_state(self,batch_size):
'''(num_layers * num_directions, batch_size, hidden_size )'''
if self.bidirectional==False:
num_directions = 1
else:
num_directions = 2
h_0 = torch.randn(self.num_layers * num_directions, batch_size, self.hidden_size).to(self.device)
c_0 = torch.randn(self.num_layers * num_directions, batch_size, self.hidden_size).to(self.device)
# print(num_directions)
hidden_state = (h_0, c_0)
return hidden_state
def forward(self,x):
hidden_state = self.initial_hidden_state(x.size(0))
lstm_out, hidden = self.lstm(x, hidden_state)
outputs = self.reg(lstm_out)
# print(outputs.shape)
outputs = self.Linear(outputs.permute(0,2,1)).permute(0,2,1)
return outputs5.目前这个模型,多输入多输出的效果没有多输入单输出的效果好!我也在探索,在改进,到底是哪一步出问题了,目前还是以优化模型为主,加入self_attension。
6.目前我还有一些细节问题还在解决,比如inverse的问题,训练loss过大等!但是整个项目的框架应该没有问题了。
结果展示:
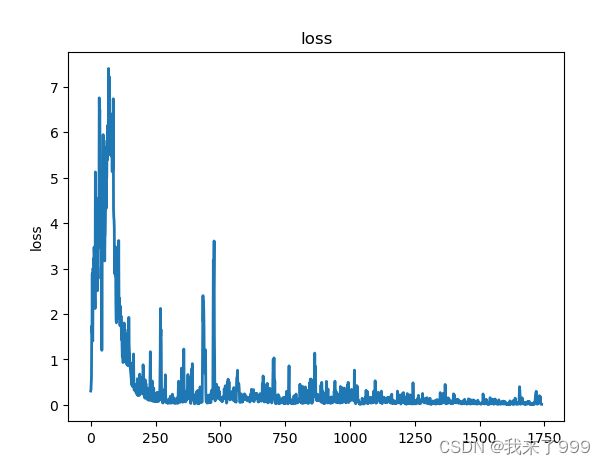
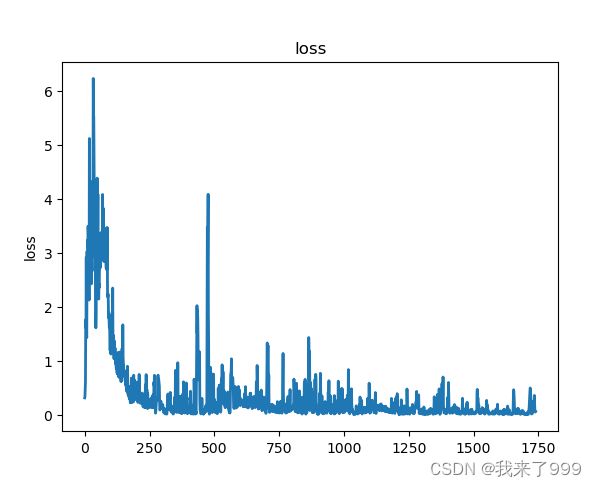
训练集上:左侧为单输出的loss,右侧为多输出的loss,效果都不怎么好!

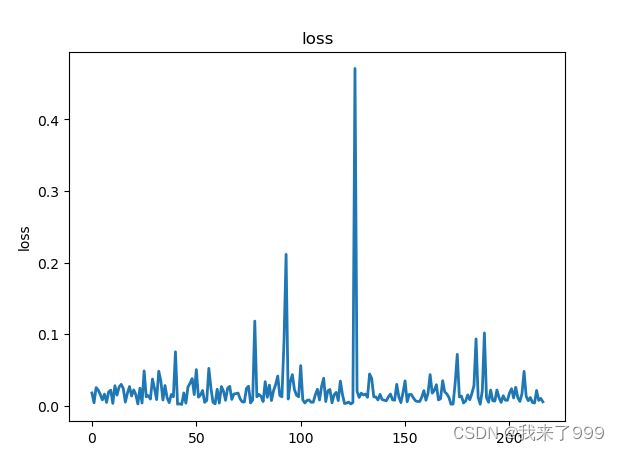
验证集上:左侧为单输出的loss,右侧为多输出的loss,我发现训练的epoch越多,loss也逐渐降低。
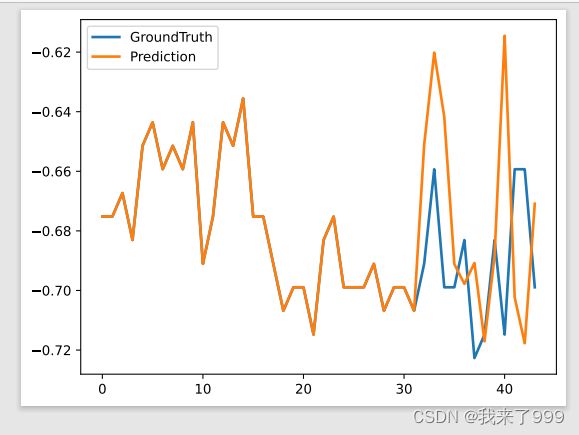
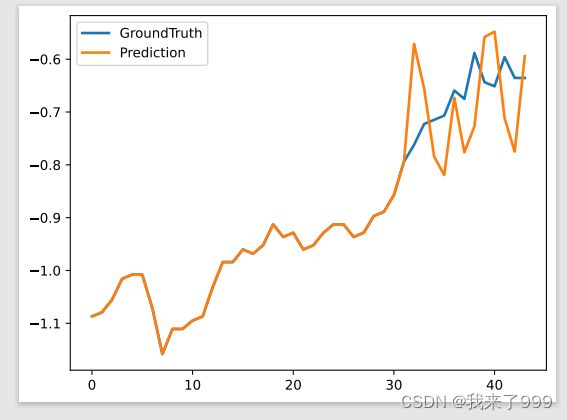
测试集上:测试效果都不好,所以需要改进一些细节地方!