NeurIPS23|Gold-YOLO:华为诺亚打造YOLO全新巅峰!
作者 | 王云鹤 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/657742732
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【目标检测】技术交流群
本文只做学术分享,如有侵权,联系删文
导读
本文提出了一种全新的信息交互融合机制:信息聚集-分发机制(Gather-and-Distribute Mechanism)。该机制通过在全局上融合不同层次的特征得到全局信息,并将全局信息注入到不同层级的特征中,实现了高效的信息交互和融合。

NeurIPS23论文地址:
https://arxiv.org/abs/2309.11331
PyTorch代码:
https://github.com/huawei-noah/Efficient-Computing/tree/master/Detection/Gold-YOLO
MindSpore 代码:
https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO
引言
YOLO系列模型面世至今已有8年,由于其优异的性能,已成为目标检测领域的标杆。在系列模型经过十多个不同版本的改进发展逐渐稳定完善的今天,研究人员更多关注于单个计算模块内结构的精细调整,或是head部分和训练方法上的改进。但这并不意味着现有模式已是最优解。
当前YOLO系列模型通常采用类FPN方法进行信息融合,而这一结构在融合跨层信息时存在信息损失的问题。针对这一问题,我们提出了全新的信息聚集-分发(Gather-and-Distribute Mechanism)GD机制,通过在全局视野上对不同层级的特征进行统一的聚集融合并分发注入到不同层级中,构建更加充分高效的信息交互融合机制,并基于GD机制构建了Gold-YOLO。在COCO数据集中,我们的Gold-YOLO超越了现有的YOLO系列,实现了精度-速度曲线上的SOTA。
 精度和速度曲线(TensorRT7)
精度和速度曲线(TensorRT7)  精度和速度曲线(TensorRT8)
精度和速度曲线(TensorRT8)
传统YOLO的问题
在检测模型中,通常先经过backbone提取得到一系列不同层级的特征,FPN利用了backbone的这一特点,构建了相应的融合结构:不层级的特征包含着不同大小物体的位置信息,虽然这些特征包含的信息不同,但这些特征在相互融合后能够互相弥补彼此缺失的信息,增强每一层级信息的丰富程度,提升网络性能。
原始的FPN结构由于其层层递进的信息融合模式,使得相邻层的信息能够充分融合,但也导致了跨层信息融合存在问题:当跨层的信息进行交互融合时,由于没有直连的交互通路,只能依靠中间层充当“中介”进行融合,导致了一定的信息损失。之前的许多工作中都关注到了这一问题,而解决方案通常是通过添加shortcut增加更多的路径,以增强信息流动。
然而传统的FPN结构即便改进后,由于网络中路径过多,且交互方式不直接,基于FPN思想的信息融合结构仍然存在跨层信息交互困难和信息损失的问题。
Gold-YOLO:全新的信息融合交互机制
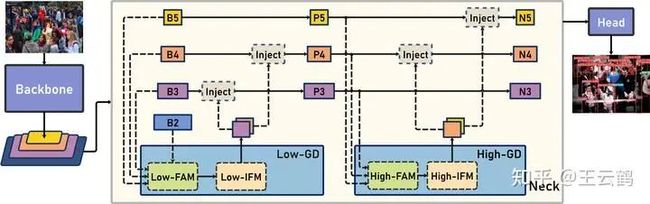 Gold-YOLO架构
Gold-YOLO架构
因此我们提出了一种全新的信息交互融合机制:信息聚集-分发机制(Gather-and-Distribute Mechanism)。该机制通过在全局上融合不同层次的特征得到全局信息,并将全局信息注入到不同层级的特征中,实现了高效的信息交互和融合。在不显著增加延迟的情况下GD机制显著增强了Neck部分的信息融合能力,提高了模型对不同大小物体的检测能力。
GD机制通过三个模块实现:信息对齐模块(FAM)、信息融合模块(IFM)和信息注入模块(Inject)。
信息对齐模块负责收集并对齐不同层级不同大小的特征
信息融合模块通过使用卷积或Transformer算子对对齐后的的特征进行融合,得到全局信息
信息注入模块将全局信息注入到不同层级中
在Gold-YOLO中,针对模型需要检测不同大小的物体的需要,并权衡精度和速度,我们构建了两个GD分支对信息进行融合:低层级信息聚集-分发分支(Low-GD)和高层级信息聚集-分发分支(High-GD),分别基于卷积和transformer提取和融合特征信息。
此外,为了促进局部信息的流动,我们借鉴现有工作,构建了一个轻量级的邻接层融合模块,该模块在局部尺度上结合了邻近层的特征,进一步提升了模型性能。我们还引入并验证了预训练方法对YOLO模型的有效性,通过在ImageNet 1K上使用MAE方法对主干进行预训练,显著提高了模型的收敛速度和精度。
实验结果
我们在COCO数据集上测试了模型的精度,并使用Tesla T4+TensorRT 7测试了模型的速度,结果显示我们的Gold-YOLO在精度-速度曲线上取得了当前的SOTA结果。

同时我们针对Gold-YOLO中不同分支和结构对模型精度和速度的影响,进行了相应的消融实验。
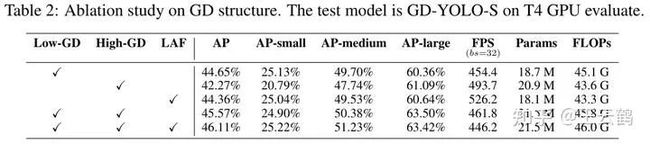
为了验证GD机制在不同模型和任务中的鲁棒性,我们还进行了以下实验
实力分割任务
将Mask R-CNN中的Neck部分替换为GD,并在COCO instance 数据集上进行训练和测试
| model | Neck | FPS | Bbox mAP | Bbox mAP:50 | Segm mAP | Segm mAP:50 |
|---|---|---|---|---|---|---|
| MaskRCNN-ResNet50 | FPN | 21.6 | 38.2 | 58.8 | 34.7 | 55.7 |
| MaskRCNN-ResNet50 | AFPN | 19.1 | 36.0 | 53.6 | 31.8 | 50.7 |
| MaskRCNN-ResNet50 | PAFPN | 20.2 | 37.9 | 58.6 | 34.5 | 55.3 |
| MaskRCNN-ResNet50 | GD | 18.7 | 40.7 | 59.5 | 36.0 | 56.4 |
语义分割任务
将PointRend 中的Neck部分替换为GD,并在Cityscapes 数据集上进行训练和测试
| model | Neck | FPS | mIoU | mAcc | aAcc |
|---|---|---|---|---|---|
| PointRend-ResNet50 | FPN | 11.21 | 76.47 | 84.05 | 95.96 |
| PointRend-ResNet50 | GD | 11.07 | 78.54 | 85.60 | 96.12 |
| pointrend-ResNet101 | FPN | 8.76 | 78.3 | 85.705 | 96.23 |
| PointRend-ResNet101 | GD | 11.07 | 80.01 | 86.15 | 96.34 |
不同的目标检测模型
将 EfficientDet 中的Neck部分替换为GD,并在COCO数据集上进行训练和测试
| model | Neck | FPS | AP |
|---|---|---|---|
| EfficientDet | BiFPN | 6.0 | 34.4 |
| EfficientDet | GD | 5.7 | 38.8 |
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、协同感知、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)
 视频官网:www.zdjszx.com
视频官网:www.zdjszx.com
② 国内首个自动驾驶学习社区
近2000人的交流社区,涉及30+自动驾驶技术栈学习路线,想要了解更多自动驾驶感知(2D检测、分割、2D/3D车道线、BEV感知、3D目标检测、Occupancy、多传感器融合、多传感器标定、目标跟踪、光流估计)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、AI模型部署落地实战、行业动态、岗位发布,欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频,期待交流!

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、点云处理、端到端自动驾驶、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!
