3 函数的升级-上
常量与宏回顾
C++中的const常量可以替代常数定义,如:
"Const int a = 8; --> 等价于 #define a 8 " 宏在预编译阶段处理,而c++ const常量则在编译阶段处理,比宏 更为安全。
C中,我们可以用宏代码片段去实现某个函数,容易出现副作用。在C++中,是否有解决方案替代代码宏,消除宏的副作用?
- C++ 推荐使用内联函数替代宏代码片段,关键字 inline
- 内联函数声明时 inline 关键字必须和函数定义结合在一起,否则编译器会直接忽略内联请求。
inline int func(int a, int b)
{
return a < b ? a : b;
}
//----------------------------
//下面这段代码内联请求会被编译器忽略
inline int func(int a, int b);
int func(int a, int b)
{
return a < b ? a : b;
}
内联函数在最终生成的可执行文件中,是没有定义的,因为C++编译器直接将函数体插入函数调用的地方。故内联函数没有普通函数调用时的额外开销(压栈、跳转、返回)。
既然内联函数这么好用,那么是否可以将每个函数都定义为内联函数呢?答案时否定的。因为C++编译器不一定准许函数的内联请求。如果请求失败,C++编译器会将内联函数变成普通函数处理。
内联函数与宏区别
宏:宏代码片段由预编译器处理,只是进行简单的文本替换,没有任何编译过程。
内联函数:内联函数是一种特殊的函数,具有普通函数的特征,如参数检查,返回类型等。内联函数是对编译器的一种请求,编译器可能会拒绝这种请求。内联函数由编译器处理,直接将编译后的函数体插入调用的地方。
下面用比较大小的范例来说明宏的副作用
#include 函数本意是想比较两个数的大小,但是由于宏的简单文本替换的逻辑,FUNC(++a, b); ->(++a) < (b) ? (++a) : (b),如果调用宏FUNC,则最终a被自加了两次。但是如果是用inline func函数,则可以很好的消除这种文本替换带来的副作用。
现代C++编译器会对编译进行优化,因此一些函数即使没有inline声明,也可能被编译器内联编译。现代C++编译器也提供了扩展语法,能够对函数进行强制内联。
gnu g++: attribute((always_inline)) 属性.
写法:
inline int func __attribute__((always_inline)) (int a, int b) {
}
接下来我们看下编译器对内联函数的处理行为。
#include 利用g++编译器进行汇编,g++ -S 3-2.c, 生成.s文件。我们查询.s文件,发现发现inline_func 和 on_inline_func都被处理成了普通函数。
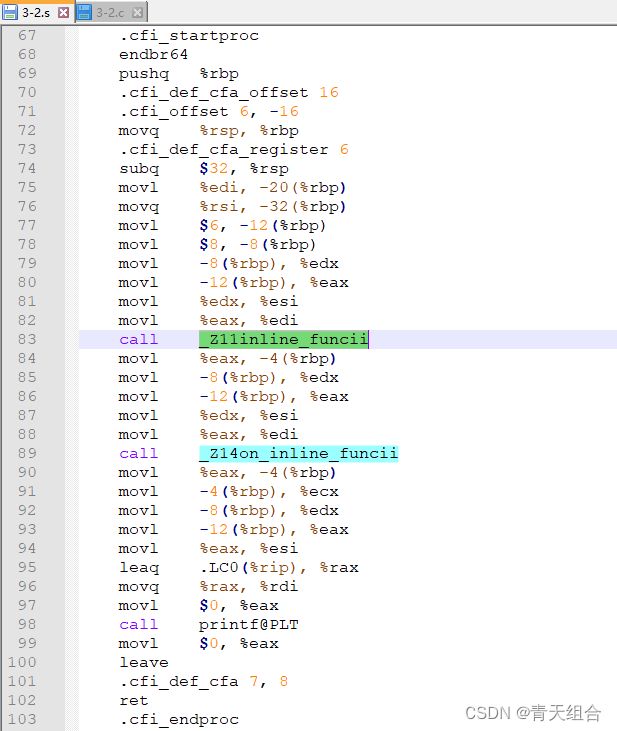
如果是处理成内联函数,那么代码段会直接插入到main中,并没有call的动作,此时,如果我们这样写
inline int inline_func __attribute__((always_inline))(int a, int b) {
return a < b ? a : b;
}
再用反汇编,发现.s文件中没有了inline_func 字符。说明已经插入到了main函数中。
对于g++扩展关键字,一般情况下不使用。但是如果是对算法速度要求比较严格的地方,可以使用扩展关键字强制内联,用于加速算法执行速度。
C++内联编译的限制:
- 不能存在任何形式的循环语句
- 不能存在过多的条件判断语句
- 函数体不能过于庞大
- 不能对函数进行取地址操作(如果对一个内联函数进行取地址操作,那么编译器会对拒绝内联的请求。)
- 函数内联声明必须在调用语句之前
编译器对于内联函数的限制并不是绝对的,内联函数相对于普通函数的优势只是省去了函数调用时压栈、跳转和返回的开销。因此当函数执行开销远大于这些开销时,内联将变得无意义。
c++中内联函数的实现机制

符号表:C++在编译程序过程当中,生成的一张表,存放文件里面出现的一些名字。不会生成在程序当中。
函数默认参数
C++可以在函数声明时为参数提供一个默认值,当函数调用时没有指定这个参数的值,编译器会自动用默认值替代。
#include 
函数默认参数规则
只有参数列表后面部分的参数才可以提供默认参数值,一旦在一个函数调用中开始使用默认参数值,那么这个参数后的所有参数都必须提供默认参数值;如果不提供,则会报错。–编译器规则
//函数声明与定义,b提供了默认参数,b之后都要提供,假如c不提供默认参数,则会报错。
int add(int a, int b = 2, int c = 3)
{
return a + b + c;
}
//-------------------
//函数使用
printf("add(2) = %d\n", add(2));
printf("add(2) = %d\n", add(2, ,1));//编译报错。
函数占位参数
占位参数:只有参数类型声明,而没有参数名声明
int func(int a, int b, int)//最后一个int 就是占位参数
{
return a + b;
}
一般情况下,在函数体内部无法使用占位参数,因为没有名字,所以无法使用占位参数。
那么c++支持这样的函数占位参数有什么意义呢
- 可以将占位参数与默认参数结合起来使用,为以后程序的扩展留下线索
//当程序员看到这种定义时,应该知道作者要提醒你,函数可能会被改动,项目如果要扩展参数,那么占位参数此时就可以变成正在的参数。
int func(int a, int b, int = 0)
{
return a + b;
}
- 兼容c程序中可能出现的不规范写法
//定义一个无参的函数
int func() {
return 1;
}
//在c中调用地方,传参数可以不受限制,
func();
//在c中可以编译通过,在c++中强类型检查会报错。
func(1, 2 ,3);
///-----------
//此时,如果将定义改成func(1, 2 ,3);能编译通过。
int func(int = 0, int = 0, int = 0) {
return 1;
}
func(1, 2 ,3);
总结
- c++中可以通过inline关键字声明内联函数
- inline关键字只是一种请求,编译器不一定运行这种请求
- 内联函数省去了普通函数调用时压栈、跳转、返回的操作
- c++中在声明函数的时候指定参数的默认值
- c++可以声明占位符参数,占位符参数一般用于程序扩展和兼容c语言函数调用的不规范写法