ElasticSearch(搜索引擎)
文章目录
- ElasticSearch
-
- 一、ElasticSearch简介
-
- 1.1、ES的由来
- 1.2、ES的优点
- 二、ElasticSearch功能
-
- 2.1、搜索
- 2.2、全文检索
- 2.3、倒排索引
-
- 2.3.1、概念
- 2.3.2、举例
-
- 2.3.2.1、原始数据分词
- 2.3.2.2、建立索引
- 2.3.2.3、搜索
- 三、ElasticSearch 部署
-
- 3.1、ElasticSearch 安装
- 3.2、安装 Kibana
- 3.3、安装 IK 分词器
-
- 3.3.1、IK分词器简介
- 3.3.2、IK分词器的安装
- 四、ElasticSearch 核心概念
- 五、elasticsearch基本操作
-
- 5.1、index(数据库)
- 5.2、document(行)/(ES的CURD操作)
-
- 5.2.1、 创建文档
- 5.2.2、 查看文档
- 5.2.3、修改文档
- 5.2.4、修改局部属性
- 5.2.5、删除文档
- 5.2.6、批量操作
- 5.3、mapping(映射)/表结构
-
- 5.3.1、查看映射
- 5.3.2、创建 mapping
- 六、DSL高级查询
-
- 6.1、DSL概述
- 6.2、查询全部
- 6.3、匹配查询
- 6.4、多字段匹配 [业务]
- 6.5、前缀匹配
- 6.6、关键字不分词
- 6.7、多个不分词的关键字
- 6.8、范围查询 [业务]
- 6.9、bool查询 [业务]
- 七、进阶查询
-
- 7.1、聚合
-
- 7.1.1、概念
- 7.1.2、测试数据
- 7.1.3、Hello World
- 7.1.4、并列的聚合
- 7.1.5、嵌套的聚合
- 7.1.6、其它聚合方式
- 7.2、指定查询结果字段
- 7.3、高亮效果
- 7.4、分页
-
- 7.4.1、常规分页
- 7.4.2、滚动分页
- 7.5、排序
- 7.6、模糊查询
- 八、Java api 操作 ElasticSearch
-
- 8.1 High Level client
-
- 8.1.1 搭建环境
-
- 8.1.1.1 Maven 配置 POM
-
- 8.1.1.1.1 父工程
- 8.1.1.1.2 依赖
- 8.1.1.1.3 构建插件可选
- 8.1.1.2 SpringBoot
-
- 8.1.1.2.1 配置文件
- 8.1.1.2.2 主启动类
- 8.1.1.2.3 配置类
- 8.1.1.2.4 测试类
- 8.1.2 索引相关操作
-
- 8.1.2.1 创建索引
- 8.1.2.2 查看索引
- 8.1.2.3 删除索引
- 8.1.3 文档相关操作
-
- 8.1.3.1 创建文档
- 8.1.3.2 更新文档
- 8.1.3.3 根据 id 查询文档
- 8.1.3.4 批量操作
- 8.1.3.4 删除文档
- 8.1.4 DSL查询
-
- 8.1.4.1 关键词匹配
- 8.1.4.2 高亮查询
- 8.1.4.3 聚合查询
- 8.2 SpringData ElasticSearch
-
- 8.2.1 搭建环境
-
- 8.2.1.1 Maven 配置 POM
-
- 8.2.1.1.1 父工程
- 8.2.1.1.2 依赖
- 8.2.1.2 SpringBoot
-
- 8.2.1.2.1 配置文件
- 8.2.1.2.2 配置类
- 8.2.1.3 主启动类
- 8.2.2 数据建模
-
- 8.2.2.1 实体类
- 8.2.2.2 Dao
- 8.2.2.3 测试类
- 8.2.3 数据操作
-
- 8.2.3.1 保存文档
- 8.2.3.2 根据 id 查询文档
- 8.2.3.3 查询全部并排序
- 8.2.4 自定义方法
-
- 8.2.4.1 概述
- 8.2.4.2 声明自定义方法
- 8.2.4.3 测试自定义方法
- 九、ElasticSearch 集群
-
- 9.1、需求
- 9.2、概述
-
- 9.2.1、空集群
- 9.2.2、拥有一个索引的单节点集群
- 9.2.3、拥有两个节点的集群
- 9.2.4、拥有三个节点的集群
- 9.2.5、将参数 number_of_replicas 调大到 2
- 9.2.6、关闭了一个节点后的集群
- 9.3、核心概念
-
- 9.3.1、集群 Cluster
- 9.3.2、节点 Node
- 9.3.3、分片 Shards
- 9.3.4、副本 Replicas
- 9.3.5、分配 Allocation
- 9.3.6、节点类型
-
- 9.3.6.1、master
- 9.3.6.2、DataNode
- 9.3.7、总结
- 9.4、搭建
-
- 9.4.1、创建目录
- 9.4.2、复制`ES`目录
- 9.4.3、修改配置文件
-
- 9.4.3.1、实例 9301
- 9.4.3.2、实例 9302
- 9.4.3.3、实例 9303
- 9.4.4、修改 Kibana 配置
- 9.4.5、启动测试
- 9.4.6、查看集群信息的图形化界面工具
- 9.4.7、数据测试
- 9.5、内部机制
-
- 9.5.1、写流程
- 9.5.2、读流程
ElasticSearch
一、ElasticSearch简介
ElasticSearch:智能搜索,分布式的搜索引擎
Elaticsearch,简称为 ES, 是一个开源的高扩展的分布式全文检索引擎,特点:
近乎实时的存储、检索数据;
扩展性好,可以扩展到上百台服务器,处理PB级别的数据;
使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能;
通过简单的
RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。Lucene就是一个jar包,里面包含了各种建立倒排索引的方法,java开发的时候只需要导入这个jar包就可以开发了。
Lucene不是分布式的。
ES的底层就是Lucene,ES是分布式的。(Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎)
1.1、ES的由来
因为Lucene有两个难以解决的问题,
数据越大,存不下来,那我就需要多台服务器存数据,那么我的Lucene不支持分布式的,那就需要安装多个Lucene然后通过代码来合并搜索结果。这样很不好
数据要考虑安全性,一台服务器挂了,那么上面的数据不就消失了。
ES就是分布式的集群,每一个节点其实就是Lucene,当用户搜索的时候,会随机挑一台,然后这台机器自己知道数据在哪,不用我们管这些底层、
1.2、ES的优点
- 分布式的功能
- 数据高可用,集群高可用
- API更简单
- API更高级。
- 支持的语言很多
- 支持PB级别的数据
- 完成搜索的功能和分析功能
二、ElasticSearch功能
2.1、搜索
- 百度,谷歌。我们可以通过他们去搜索我们需要的东西。但是我们的搜索不只是包含这些。
- 互联网的搜索:电商网站。招聘网站。新闻网站。各种APP(百度外卖,美团等等)
- windows系统的搜索,OA软件,淘宝SSM网站,前后台的搜索功能
总结:搜索无处不在。通过一些关键字,给我们查询出来跟这些关键字相关的信息
2.2、全文检索
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
2.3、倒排索引
2.3.1、概念
全文搜索引擎目前主流的索引技术就是倒排索引的方式。
- 传统查询:根据 id 查询数据
- 倒排索引:根据关键词匹配分词结果,然后找到 id
2.3.2、举例
2.3.2.1、原始数据分词
| 文档 ID | 文档内容 |
|---|---|
| 1 | 谷歌地图之父跳槽Facebook |
| 2 | 谷歌地图之父加盟Facebook |
| 3 | 谷歌地图创始人拉斯离开谷歌加盟Facebook |
| 4 | 谷歌地图之父跳槽Facebook,与Wave项目取消有关 |
| 5 | 谷歌地图之父拉斯加盟社交网站Facebook |
| 文档 ID | 文档内容 |
|---|---|
| 1 | [谷歌] [地图] [之父] [跳槽] [Facebook] |
| 2 | [谷歌] [地图] [之父] [加盟] [Facebook] |
| 3 | [谷歌] [地图] [创始] [创始人] [拉斯] [离开] [加盟] [Facebook] |
| 4 | [谷歌] [地图] [之父] [跳槽] [Facebook] [与] [Wave] [项目] [取消] [有关] |
| 5 | [谷歌] [地图] [之父] [拉斯] [加盟] [社交] [网站] [Facebook] |
2.3.2.2、建立索引
| 单词 ID | 单词 | 关联文档的 ID |
|---|---|---|
| 1 | 谷歌 | 1 2 3 4 5 |
| 2 | 地图 | 1 2 3 4 5 |
| 3 | 之父 | 1 2 4 5 |
| 4 | 跳槽 | 1 4 |
| 5 | 1 2 3 4 5 | |
| 6 | 加盟 | 2 3 5 |
| 7 | 创始 | 3 |
| 8 | 创始人 | 3 |
| 9 | 拉斯 | 3 5 |
| 10 | 离开 | 3 |
| 11 | 与 | 4 |
| 12 | Wave | 4 |
| 13 | 项目 | 4 |
| 14 | 取消 | 4 |
| 15 | 有关 | 4 |
| 16 | 社交 | 5 |
| 17 | 网站 | 5 |
2.3.2.3、搜索
用户搜索关键词:拉斯
到索引记录中查询,得知“拉斯”这个词曾出现在id为3和id为5的文档中。
然后就可以根据3和5查询文档本身的数据。
另外,全文索引还会根据匹配程度进行打分,匹配程度高的记录得分高,得分高的记录在搜索结果中靠前。
比如搜索“拉斯离开谷歌”那么3号记录得分就会高。
随笔:综上所诉,ElasticSearch主要是用于将搜索内容进行分词,然后对分词后的结果查询。
三、ElasticSearch 部署
3.1、ElasticSearch 安装
下载地址

解压elasticsearch-7.8.0-windows-x86_64.zip,目录结构:
| 目录 | 说明 |
|---|---|
| bin | 可执行脚本目录 |
| config | 配置目录 |
| jdk | 内置jdk目录 |
| lib | 类库 |
| logs | 日志目录 |
| modules | 模块目录 |
| plugins | 插件目录 |
解压完成后进入bin目录,双击运行elasticsearch.bat
测试访问: http://localhost:9200/
-
注意事项一:
- ElasticSearch是使用java开发的,且本版本的ES需要JDK版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败。
-
注意事项二:
- 出现闪退,通过路径访问发现“空间不足”
-
修改config/jvm.options文件的22行23行,把2改成1,让Elasticsearch启动的时候占用1个G的内存。
-
-Xmx512m:设置JVM最大可用内存为512M。
-
-Xms512m:设置JVM初始内存为512m。此值可以设置与-Xmx相同,以避免每次垃圾回收完成后JVM重新分配内存。
-
3.2、安装 Kibana
ElasticSearch 对外都是基于 RESTFul 风格提供 HTTP 服务,所以可以使用 Postman 来操作 ES。 另外,还可以使用 Kibana 这样的图形化界面客户端使操作更简单。下载地址: 下载后解压。
进入到config目录,修改kibana.yml文件(解开注释):
server.port: 5601
elasticsearch.hosts: [“http://localhost:9200”]
i18n.locale: “zh-CN”
运行kibana-7.8.0-windows-x86_64\bin\kibana.bat文件。再通过浏览器访问:

开始访问:http://127.0.0.1:5601
3.3、安装 IK 分词器
3.3.1、IK分词器简介
IKAnalyzer是一个开源的,基于Java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK分词器3.0的特性如下:
-
采用了特有的“正向迭代最细粒度切分算法“,具有60万字/秒的高速处理能力。
-
采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
-
对中英联合支持不是很好,在这方面的处理比较麻烦.需再做一次查询,同时是支持个人词条的优化的词典存储,更小的内存占用。
-
支持用户词典扩展定义。
-
针对Lucene全文检索优化的查询分析器IKQueryParser;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。
3.3.2、IK分词器的安装
- 下载:
GitHub仓库地址
下载地址

- 解压安装IK插件
直接解压到plugins下,注意目录结构,解压后的zip不要放在plugins目录下

-
重新启动ElasticSearch
-
测试
在kibana中测试:
测试分词器:
l ik_max_word:会将文本做最细粒度的拆分
ik_smart:会做最粗粒度的拆分,智能拆分
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}

四、ElasticSearch 核心概念
Elasticsearch是面向文档型数据库,一条数据在这里就是一个文档,用JSON作为文档序列化的格式,比如下面这条用户数据:
{ "name" : "John", "sex" : "Male", "age" : 25, "birthDate": "1990/05/01", "about" : "I love to go rock climbing", "interests": [ "sports", "music" ] }用Mysql这样的数据库存储就会容易想到建立一张User表,有各个字段等,在ElasticSearch里这就是一个文档,当然这个文档会属于一个User的类型,各种各样的类型存在于一个索引当中。这里有一份简易的将Elasticsearch和关系型数据术语对照表:
| ElasticSearch | MySQL |
|---|---|
| index(索引库) | Database(数据库) |
| mapping(映射) | 表结构 |
| Table(表) | |
| document(文档) | Row(行) |
| field(字段) | Column(列) |
ElasticSearch较高的版本已经废除了type这个概念。
ElasticSearch 中字符串有两种类型:
- text:分词,不能用来排序和聚合
- keyword:不分词,可以被用来检索过滤、排序和聚合
五、elasticsearch基本操作
5.1、index(数据库)
PUT /aura_index增加一个aura_index的index库GET _cat/indices命令查询ES中所有的index索引库GET /my_index命令查看my_index索引DELETE /aura_index删除一个aura_index的index库
5.2、document(行)/(ES的CURD操作)
| 数据 | 对应的类型 |
|---|---|
| null | 不添加字段 |
| true 或 false | boolean |
| 字符串 | text |
| 数值 | long |
| 小数 | float |
| 日期 | date |
| 类型 | 说明 |
|---|---|
| PUT | 类似于SQL中的增 |
| DELETE | 类似于SQL中的删 |
| POST | 类似于SQL中的改 |
| GET | 类似于SQL中的查 |
5.2.1、 创建文档
PUT /索引名称/_doc/文档id
{
json 格式数据
}
注意:我们插入数据的时候,如果我们的语句中指明了index和type,如果ES里面不存在,默认帮我们自动创建
操作举例:
PUT /my_index/_doc/1
{
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
5.2.2、 查看文档
语法:GET /{索引名称}/{类型}/{id} / 语法:GET /{数据库}/{表}/{id}
GET /my_index/_doc/1
5.2.3、修改文档
使用POST来修改数据,其实使用PUT也可以实现修改数据
POST的方式进行修改数据,POST是局部更新数据,别的数据不动。PUT是全局更新
PUT /my_index/_doc/1
{
"title": "小米手机",
"category": "小米",
"images": "http://www.gulixueyuan.com/xm.jpg",
"price": 3999
}
注意:下面这种操作也是成功的,会丢数据,是全局的修改
PUT /my_index/_doc/1
{
"category": "小米"
}
5.2.4、修改局部属性
语法:POST /{索引名称}/_update/{docId} { “doc”: { “属性”: “值” } }
注意:这种更新只能使用post方式。
POST /my_index/_update/1
{
"doc": {
"price": 4500
}
}
5.2.5、删除文档
语法: DELETE /{索引名称}/{类型}/{id}
操作举例:DELETE /my_index/_doc/1
5.2.6、批量操作
批量操作通常分成三部分:
- 请求方式部分:POST _bulk
- 元数据部分:
- 指定 bulk 动作
- 指定执行批量操作的 index、type、文档 id 等信息
- 数据部分:执行批量操作用到的数据
POST _bulk { action: { metadata }} { request body } { action: { metadata }} { request body }
总的语法规则:
- 每个 JSON 串都不能换行,只能放在同一行。
- 各个 JSON 串之间通过换行分隔,而不是逗号
- 多个操作不会因为某个操作失败而终止,返回结果会显示失败的详细原因
批量操作类型:
- create:批量创建文档。如果文档存在则返回错误
- index:如果文档不存在就创建,如果文档存在就更新
- update:更新一个文档,如果文档不存在就返回错误
- delete:删除一个文档,如果要删除的文档id不存在,就返回错误
批量保存
POST _bulk {"create": {"_index":"my_index", "_id":1}} {"emp_id":5,"emp_name":"name01","emp_age":20} {"create": {"_index":"my_index", "_id":2}} {"emp_id":6,"emp_name":"name02","emp_age":21} {"create": {"_index":"my_index", "_id":3}} {"emp_id":7,"emp_name":"name03","emp_age":22}批量删除
POST _bulk {"delete": {"_index":"my_index", "_id":2}} {"delete": {"_index":"my_index", "_id":3}}
5.3、mapping(映射)/表结构
有了索引库,等于有了数据库中的database。
接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
5.3.1、查看映射
语法格式:GET /索引名称/_mapping,
结果示例:
{ "my_index" : { "mappings" : { "properties" : { "category" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "id" : { "type" : "long" }, "images" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } }, "price" : { "type" : "long" }, "title" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } } }
5.3.2、创建 mapping
| 数据 | 对应的类型 |
|---|---|
| null | 字段不添加 |
| true | flase |
| 字符串 | text |
| 数值 | long |
| 小数 | float |
| 日期 | date |
注意:我们通常不会单独创建 mapping,mapping 也无法脱离 index 单独存在。 所以创建 mapping 也都是在创建 index 的时候同时进行
语法格式:PUT /索引名称
{ "mappings":{ "properties":{ "字段名":{ "type":"当前字段的数据类型", "index":布尔值,表示是否为当前字段建立索引, "store":布尔值,表示当前字段是否存储, "analyzer":"当前字段使用的分词器名称", "search_analyzer":"搜索关键词使用的分词器" }, "字段名":{ …… } } } }操作举例:
PUT /index_song { "mappings": { "properties": { "song_id":{ "type": "long", "index": true, "store": true }, "song_name":{ "type": "text", "index": true, "store": true, "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "singer":{ "type": "keyword", "index": true, "store": true }, "song_album":{ "type": "text", "index": true, "store": true, "analyzer": "ik_max_word" }, "song_lyric":{ "type": "text", "index": true, "store": false, "analyzer": "ik_max_word" }, "song_img":{ "type": "keyword", "index": false, "store": true } } } }字段属性说明
是否分词
- 需要分词的情况:分词之后,分词结果是有意义的、会被搜索的。例如:歌曲名称
- 不分词的情况:分词之后,分词结果没有意义,不会被搜索。例如:歌曲图片地址、地名、人名
是否索引
- 需要索引的情况:要搜索这个字段,就基于它建立索引。例如:歌曲名称
- 不需要索引的情况:不会被搜索的字段,不必建立索引。例如:歌曲图片地址
是否存储
是否存储是指:该字段是否在 _source 之外再做一个额外的存储。这样对于做了存储的字段可以通过 stored_fields 方式获取。 这一点我们作为初学者不必深究,我们只需要知道:即使我们设置了 store 为 false,查询结果中 _source 这里也仍然能够显示该字段。 所以通常是没有影响的。
六、DSL高级查询
6.1、DSL概述
Query DSL概述: Domain Specific Language(领域专用语言),Elasticsearch提供了基于JSON的DSL来定义查询。
测试数据:
POST db_song/_doc { "song_name":"give me an apple", "song_singer":"tom", "song_album":"apple pie", "song_lyrics":"i want to give you an apple", "song_price":10 } POST db_song/_doc { "song_name":"happy tears", "song_singer":"jerry", "song_album":"apple farmer", "song_lyrics":"i will go to London", "song_price":20 } POST db_song/_doc { "song_name":"tears of happy", "song_singer":"jerry", "song_album":"apple farmer", "song_lyrics":"i will go to NewYork", "song_price":30 } POST db_song/_doc { "song_name":"fly me", "song_singer":"bigger one", "song_album":"two star", "song_lyrics":"i put an apple on your table", "song_price":40 }
6.2、查询全部
query下match_all
# DSL:查询全部
# 从DSL语法角度来说,第一行是请求方式和请求地址,第一行下面是一个JSON格式的请求体
GET /db_song/_search
{
"query": {
"match_all": {}
}
}
6.3、匹配查询
query下match
# DSL:关键词匹配一个字段查询
GET /db_song/_search
{
"query": {
"match": {
"song_name": "apple"
}
}
}
# 补充条件删除
POST /db_song/_delete_by_query
{
"query": {
"match": {
"song_name": "apple"
}
}
}
6.4、多字段匹配 [业务]
query下multi_match
# DSL:关键词匹配多个字段
# 被命中的document的字段中,和关键词匹配的越多,在搜索结果中得分越高,说明匹配度越高
GET /db_song/_search
{
"query": {
"multi_match": {
"query": "apple",
"fields": [
"song_name",
"song_album",
"song_singer",
"song_lyrics"
]
}
}
}
6.5、前缀匹配
query下prefix
# DSL查询:前缀匹配
# 分词结果以指定字符串开头的能匹配上
GET /db_song/_search
{
"query": {
"prefix": {
"song_name": {
"value": "app"
}
}
}
}
6.6、关键字不分词
query下term
# DSL查询:关键词不分词
# 原始数据:happy tears
# 原始数据分词结果:[happy][tears]
# 匹配方式:用happy tears和分词结果匹配,发现它和happy、tears都匹配不上
GET /db_song/_search
{
"query": {
"term": {
"song_name": {
"value": "happy tears"
}
}
}
}
6.7、多个不分词的关键字
query下terms
# DSL查询:多个不分词的关键词
GET /db_song/_search
{
"query": {
"terms": {
"song_name": [
"happy",
"tears"
]
}
}
}
6.8、范围查询 [业务]
query下range
# DSL查询:范围查询
# gte: 大于等于,greater than equal
# lte: 小于等于,less than equal
# gt: 大于,greater than
# lt: 小于,less than
GET /db_song/_search
{
"query": {
"range": {
"song_price": {
"gte": 20,
"lte": 30
}
}
}
}
6.9、bool查询 [业务]
bool 是 boolean 的缩写。表示布尔值的意思。
多个查询的组合,组合方式包括:
- must: 各个条件都必须满足,所有条件是 and 的关系
- should: 各个条件有一个满足即可,即各条件是 or 的关系
- must_not: 各个条件必须不满足,相当于各条件分别取反之后再 and
- filter: 与 must 效果等同,但是它不计算得分,效率更高点。同时也表示在已有查询结果的基础上再进行过滤
# DSL查询:bool查询
# bool查询中的must
# must的值是一个数组,数组中每一个对象是一个查询条件,各个条件之间是“且”的关系
GET /db_song/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"song_name": "apple"
}
},
{
"match": {
"song_lyrics": "want"
}
}
]
}
}
}
# should的值是一个数组,数组中每一个对象是一个查询条件,各个条件之间是“或”的关系
GET /db_song/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"song_name": "apple"
}
},
{
"match": {
"song_lyrics": "London"
}
}
]
}
}
}
# must_not:各个条件取反,取反之后是“且”的关系
GET /db_song/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"song_name": "apple"
}
},
{
"match": {
"song_lyrics": "London"
}
}
]
}
}
}
# DSL查询:filter相当于不计算得分的must
GET /db_song/_search
{
"query": {
"bool": {
"filter": [
{
"match": {
"song_name":"apple"
}
},
{
"match": {
"song_lyrics":"want"
}
}
]
}
}
}
# 从业务的角度也可以理解为:在前面查询结果的基础上,再进一步过滤
# DSL查询:组合各种语法
GET /db_song/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"song_name": "apple"
}
}
],
"filter": [
{
"range": {
"song_price": {
"gte": 10,
"lte": 50
}
}
}
]
}
}
}
七、进阶查询
7.1、聚合
7.1.1、概念
本质上就是分组,相当于 SQL 中的 group by。
7.1.2、测试数据
注意:只有不分词的字段才能聚合,text类型的字段无法参与聚合!
PUT db_hr
{
"mappings": {
"properties": {
"department":{
"type": "keyword"
},
"subject":{
"type": "keyword"
}
}
}
}
# _bulk 表示批量导入数据
POST db_hr/_bulk
{ "index": {}}
{ "emp_name" : "nicole adler", "emp_age" : 20, "emp_salary":1000.00, "department":"hr","subject":"hr worker","birthday":"1995-10-12"}
{ "index": {}}
{ "emp_name" : "jason alex", "emp_age" : 21, "emp_salary":1100.00, "department":"hr","subject":"hr worker","birthday":"1992-03-07"}
{ "index": {}}
{ "emp_name" : "tom green", "emp_age" : 22, "emp_salary":1200.00, "department":"hr","subject":"hr manager","birthday":"1985-11-17"}
{ "index": {}}
{ "emp_name" : "jeff hare", "emp_age" : 23, "emp_salary":1300.00, "department":"hr","subject":"hr manager","birthday":"1999-10-14"}
{ "index": {}}
{ "emp_name" : "robert hill", "emp_age" : 24, "emp_salary":1400.00, "department":"hr","subject":"hr manager","birthday":"1997-10-11"}
{ "index": {}}
{ "emp_name" : "belinda arge", "emp_age" : 30, "emp_salary":1500.00, "department":"rd","subject":"java","birthday":"1992-05-08"}
{ "index": {}}
{ "emp_name" : "amy", "emp_age" : 31, "emp_salary":2100.00, "department":"rd","subject":"java","birthday":"2014-10-13"}
{ "index": {}}
{ "emp_name" : "hoffman", "emp_age" : 32, "emp_salary":5500.00, "department":"rd","subject":"java","birthday":"1998-02-01"}
{ "index": {}}
{ "emp_name" : "joyce dabney", "emp_age" : 25, "emp_salary":2800.00, "department":"rd","subject":"php","birthday":"1990-01-01"}
{ "index": {}}
{ "emp_name" : "rae de mesa", "emp_age" : 36, "emp_salary":7500.00, "department":"rd","subject":"php","birthday":"1983-07-06"}
{ "index": {}}
{ "emp_name" : "lisa", "emp_age" : 45, "emp_salary":15100.00, "department":"fi","subject":"fi worker","birthday":"1996-06-06"}
{ "index": {}}
{ "emp_name" : "kim deziel", "emp_age" : 55, "emp_salary":25100.00, "department":"fi","subject":"fi worker","birthday":"1991-09-11"}
{ "index": {}}
{ "emp_name" : "tina-louise foster", "emp_age" : 65, "emp_salary":35100.00, "department":"fi","subject":"fi manager","birthday":"1997-07-07"}
{ "index": {}}
{ "emp_name" : "brennan foti", "emp_age" : 75, "emp_salary":45100.00, "department":"fi","subject":"fi manager","birthday":"1998-08-15"}
7.1.3、Hello World
DSL 语句:
GET db_hr/_search
{
"aggs": {
"agg_hello_world": {
"terms": {
"field": "department"
}
}
}
}
节选查询结果中的聚合部分:
"aggregations" : {
"agg_hello_world" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "hr",
"doc_count" : 5
},
{
"key" : "rd",
"doc_count" : 5
},
{
"key" : "fi",
"doc_count" : 4
}
]
}
}
结果说明:
- buckets:聚合执行分组后得到的各个组
- key:聚合字段在当前组内的值
- doc_count:在当前组内包含document的数量
7.1.4、并列的聚合
# 并列的聚合:各聚各的,互不影响
GET /db_hr/_search
{
"aggs": {
"agg_dept": {
"terms": {
"field": "department"
}
},
"agg_subject": {
"terms": {
"field": "subject"
}
}
}
}
7.1.5、嵌套的聚合
# 嵌套的聚合:组内再分组
GET /db_hr/_search
{
"aggs": {
"agg_dept": {
"terms": {
"field": "department"
},
"aggs": {
"agg_subject": {
"terms": {
"field": "subject"
}
}
}
}
}
}
7.1.6、其它聚合方式
- max:组内取最大值
- min:组内取最小值
- avg:组内取平均值
- sum:组内计算总数
- stats:组内汇总各项统计结果,包含上面的每一项
# 计算每个部门平均工资
GET /db_hr/_search
{
"aggs": {
"agg_dept": {
"terms": {
"field": "department"
},
"aggs": {
"avg_salary": {
"avg": {
"field": "emp_salary"
}
}
}
}
}
}
# 按照各种方式统计
GET /db_hr/_search
{
"aggs": {
"agg_dept": {
"terms": {
"field": "department"
},
"aggs": {
"agg_stats": {
"stats": {
"field": "emp_salary"
}
}
}
}
}
}
7.2、指定查询结果字段
# 指定查询结果中显示哪些字段
GET /db_hr/_search
{
"query": {
"match": {
"emp_name": "adler"
}
},
"_source": [
"emp_name",
"emp_age",
"emp_salary"
]
}
7.3、高亮效果
# 高亮效果
# 默认效果:围绕关键词加em标签
GET /db_hr/_search
{
"query": {
"match": {
"emp_name": "adler"
}
},
"highlight": {
"fields": {
"emp_name": {}
}
}
}
# 指定高亮效果
GET /db_hr/_search
{
"query": {
"match": {
"emp_name": "adler"
}
},
"highlight": {
"fields": {
"emp_name": {
"pre_tags": "",
"post_tags": ""
}
}
}
}
7.4、分页
7.4.1、常规分页
使用 from、size 指定分页参数。
计算 from 值的公式:(pageNo-1)*pageSize
适用场景:页面显示分页数据。因为from、size其实是先把所有查询结果取出再根据from、size截取,所以不适合大数据量。
# 分页:from、size 分页
GET /db_hr/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 5
}
7.4.2、滚动分页
m表示分钟,s表示秒,执行滚动分页后,scroll_id会被缓存指定的时间。
适用场景:大数据量分批取出。
GET db_hr/_search?scroll=5m
{
"size": 1
}
GET /_search/scroll
{
"scroll":"5m", "scroll_id":"FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFGMzVEpnNFlCaWd0WVJkT1BoZFloAAAAAAAAIuAWVHpwNVBiaTBUMXFzdlBqQWd5N1lHUQ=="
}
7.5、排序
# 排序
# FIELD 位置:指定排序字段
# order 后面:排序方向
# 多字段排序:先根据第一个字段排序,在第一个字段值重复的范围内再根据第二个字段排序
GET /db_hr/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"emp_salary": {
"order": "desc"
}
},
{
"birthday": {
"order": "asc"
}
}
]
}
7.6、模糊查询
GET /db_hr/_search
{
"query": {
"fuzzy": {
"emp_name": {
"value": "ader",
"fuzziness": "auto:2,5"
}
}
}
}
fuzziness格式的说明:
本次查询允许的最大编辑距离,默认不开启模糊查询,相当于fuzziness=0。
支持的格式:
可以是数字(0、1、2)代表固定的最大编辑距离
自动模式,AUTO:[low],[high]的格式,含义为:
- 查询词长度在[0-low)范围内编辑距离为0(即强匹配)
- [low, high)范围内允许编辑一次
- >high允许编辑2次
- 也可以只写AUTO代表默认的自动模式,相当于AUTO:3,6
八、Java api 操作 ElasticSearch
8.1 High Level client
highlevelclient 是 高级客户端 需要通过它去操作 Elasticsearch , 它底层也是要依赖 rest-client 低级客户端
- 大致流程

8.1.1 搭建环境
8.1.1.1 Maven 配置 POM
8.1.1.1.1 父工程
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.6.RELEASEversion>
<relativePath/>
parent>
8.1.1.1.2 依赖
<dependencies>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.8.0version>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-clientartifactId>
<version>7.8.0version>
dependency>
<dependency>
<groupId>org.elasticsearchgroupId>
<artifactId>elasticsearchartifactId>
<version>7.8.0version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.9.9version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.76version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>runtimescope>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
8.1.1.1.3 构建插件可选
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
8.1.1.2 SpringBoot
8.1.1.2.1 配置文件
application.properties
elasticsearch.host=localhost
elasticsearch.port=9200
8.1.1.2.2 主启动类
不需要加额外注解,就是一个普通的主启动类
8.1.1.2.3 配置类
package com.song.es.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig {
private String host;
private Integer port;
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public Integer getPort() {
return port;
}
public void setPort(Integer port) {
this.port = port;
}
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient restHighLevelClient =
new RestHighLevelClient(RestClient.builder(new HttpHost(host,port,"http")));
return restHighLevelClient;
}
}
8.1.1.2.4 测试类
package com.song.es.test;
import org.junit.jupiter.api.Test;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class ElasticSearchTest {
@Autowired
private RestHighLevelClient restHighLevelClient;
}
8.1.2 索引相关操作
8.1.2.1 创建索引
CreateIndexRequest导包时使用:org.elasticsearch.client.indices.CreateIndexRequest
@Test
public void createIndex() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest(INDEX_NAME);
// CreateIndexRequest createIndexRequest = new CreateIndexRequest(INDEX_NAME);该方法是创建一个ES中的索引,在mysql中则是创建一个数据库,INDEX_NAME则是名称可设置在外面例如private final String INDEX_NAME = "test_es";注意不可以有大写
String mappingJSON = "{\n" +
" \"properties\": {\n" +
" \"name\": {\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true,\n" +
" \"store\": true\n" +
" },\n" +
" \"age\": {\n" +
" \"type\": \"integer\",\n" +
" \"index\": true,\n" +
" \"store\": true\n" +
" },\n" +
" \"remark\": {\n" +
" \"type\": \"text\",\n" +
" \"index\": true,\n" +
" \"store\": true,\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"search_analyzer\": \"ik_smart\"\n" +
" }\n" +
" }\n" +
" }";
// 现在插件网址里将创建的语句先写好,再转为字符串并在idea中添加转义字符
createIndexRequest.mapping(mappingJSON, XContentType.JSON);
// ES中的映射,在这的意思即将内容映射上去
CreateIndexResponse createIndexResponse =
restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
boolean createIndexResult = createIndexResponse.isAcknowledged();
System.out.println("createIndexResult = " + createIndexResult);
}
8.1.2.2 查看索引
GetIndexRequest导包时使用:
import org.elasticsearch.client.indices.GetIndexRequest;
@Test
public void getIndexTest() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest(INDEX_NAME);
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(getIndexRequest, RequestOptions.DEFAULT);
Map<String, MappingMetadata> mappings = getIndexResponse.getMappings();
Set<String> mappingsKeySet = mappings.keySet();
for (String key : mappingsKeySet) {
MappingMetadata mappingMetadata = mappings.get(key);
System.out.println("key = " + key);
System.out.println("mappingMetadata = " + mappingMetadata.sourceAsMap());
}
Map<String, Settings> settings = getIndexResponse.getSettings();
Set<String> settingsKeySet = settings.keySet();
for (String key : settingsKeySet) {
Settings setting = settings.get(key);
System.out.println("key = " + key);
System.out.println("setting = " + setting);
}
}
8.1.2.3 删除索引
@Test
public void testDelIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest(INDEX_NAME);
AcknowledgedResponse response =
restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
boolean deleteResult = response.isAcknowledged();
System.out.println("deleteResult = " + deleteResult);
}
8.1.3 文档相关操作
8.1.3.1 创建文档
@Test
public void testSaveDoc() throws IOException {
// 获取到索引(数据库)
IndexRequest indexRequest = new IndexRequest(INDEX_NAME);
//设置索引id为1
indexRequest.id("1");
// 传入实体类,即传入要生成的行
User user = new User();
user.setAge(20);
user.setName("tom");
user.setRemark("Good boy");
// 将传入的行,转换为JSON格式发送
indexRequest.source(JSON.toJSONString(user), XContentType.JSON);
// f封装为响应体
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
DocWriteResponse.Result result = indexResponse.getResult();
System.out.println("result = " + result);
}
8.1.3.2 更新文档
@Test
public void testUpdateDoc() throws IOException {
UpdateRequest updateRequest = new UpdateRequest(INDEX_NAME, "1");
User user = new User();
user.setRemark("bab boy");
updateRequest.doc(JSON.toJSONString(user), XContentType.JSON);
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
DocWriteResponse.Result result = updateResponse.getResult();
System.out.println("result = " + result);
}
8.1.3.3 根据 id 查询文档
@Test
public void testGetDoc() throws IOException {
GetRequest getRequest = new GetRequest(INDEX_NAME);
getRequest.id("1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
String sourceAsString = getResponse.getSourceAsString();
System.out.println("sourceAsString = " + sourceAsString);
}
8.1.3.4 批量操作
@Test
public void testBulk() throws IOException {
BulkRequest bulkRequest = new BulkRequest(INDEX_NAME);
for (int i = 0; i < 10; i++) {
User user = new User();
user.setAge(i * 10);
user.setName("name " + i);
user.setRemark("remark " + i);
bulkRequest.add(
new IndexRequest(INDEX_NAME)
.id("10" + i)
.source(JSON.toJSONString(user), XContentType.JSON));
}
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
BulkItemResponse[] items = bulkResponse.getItems();
for (BulkItemResponse item : items) {
System.out.println("item = " + item.isFailed());
}
}
8.1.3.4 删除文档
@Test
public void testDelDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest(INDEX_NAME);
deleteRequest.id("105");
DeleteResponse deleteResponse =
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
DocWriteResponse.Result result = deleteResponse.getResult();
System.out.println("result = " + result);
}
8.1.4 DSL查询
8.1.4.1 关键词匹配
对应DSL语句中的match查询:
GET /db_song/_search
{
"query": {
"match": {
"song_name": "apple"
}
}
}
@Test
public void testDSLQuery() throws IOException {
// SearchRequest对象:代表发送给 ES 的整个请求
SearchRequest searchRequest = new SearchRequest(INDEX_NAME_SONG);
// SearchSourceBuilder对象:代表 DSL 语句
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// MatchQueryBuilder对象:代表 DSL 语句中query里面的match
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("song_name", "apple");
// SearchSourceBuilder对象的query()方法:代表 DSL 语句中的query
searchSourceBuilder.query(matchQuery);
// 把SearchSourceBuilder对象构造的 DSL 语句填充到请求对象中
searchRequest.source(searchSourceBuilder);
// 发送请求,执行查询,接收响应
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 对照 ES 返回的 JSON 数据格式,解析响应对象
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String searchResult = hit.getSourceAsString();
System.out.println("searchResult = " + searchResult);
}
}
8.1.4.2 高亮查询
@Test
public void testDSLQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest(INDEX_NAME_SONG);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("song_name", "apple");
searchSourceBuilder.query(matchQuery);
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("");
highlightBuilder.postTags("");
highlightBuilder.field("song_name");
searchSourceBuilder.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String searchResult = hit.getSourceAsString();
System.out.println("searchResult = " + searchResult);
Map<String, HighlightField> highMap = hit.getHighlightFields();
Set<Map.Entry<String, HighlightField>> entries = highMap.entrySet();
for (Map.Entry<String, HighlightField> entry : entries) {
String key = entry.getKey();
HighlightField value = entry.getValue();
System.out.println("key = " + key);
System.out.println("value = " + value.getFragments()[0].toString());
}
}
}
8.1.4.3 聚合查询
@Test
public void testAgg() throws IOException {
SearchRequest searchRequest = new SearchRequest(INDEX_NAME_HR);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.terms("dept_agg").field("department"));
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Map<String, Aggregation> aggregationMap = searchResponse.getAggregations().asMap();
Set<String> keySet = aggregationMap.keySet();
for (String key : keySet) {
System.out.println("key = " + key);
ParsedStringTerms parsedStringTerms = (ParsedStringTerms) aggregationMap.get(key);
List<? extends Terms.Bucket> buckets = parsedStringTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
Object bucketKey = bucket.getKey();
System.out.println("bucketKey = " + bucketKey);
long docCount = bucket.getDocCount();
System.out.println("docCount = " + docCount);
}
}
}
8.2 SpringData ElasticSearch
8.2.1 搭建环境
8.2.1.1 Maven 配置 POM
8.2.1.1.1 父工程
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.3.6.RELEASEversion>
<relativePath/>
parent>
8.2.1.1.2 依赖
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
dependencies>
8.2.1.2 SpringBoot
8.2.1.2.1 配置文件
application.properties
# ES 服务地址
elasticsearch.host=127.0.0.1
# ES 服务端口
elasticsearch.port=9200
# 配置日志级别,开启debug日志
logging.level.com.atguigu=debug
8.2.1.2.2 配置类
ElasticsearchRestTemplate是spring-data-elasticsearch项目中的一个类,和其他spring项目中的template类似。
在新版的spring-data-elasticsearch中,ElasticsearhRestTemplate代替了原来的ElasticsearchTemplate。
原因是ElasticsearchTemplate基于TransportClient,TransportClient即将在8.x以后的版本中移除。所以,我们推荐使用ElasticsearchRestTemplate。
ElasticsearchRestTemplate基于RestHighLevelClient客户端的。需要自定义配置类,继承AbstractElasticsearchConfiguration,并实现elasticsearchClient()抽象方法,创建RestHighLevelClient对象。
package com.song.es.config;
import lombok.Data;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.config.AbstractElasticsearchConfiguration;
@Data
@Configuration
@ConfigurationProperties(prefix = "elasticsearch")
public class ElasticSearchConfig extends AbstractElasticsearchConfiguration {
private String host;
private Integer port;
@Override
public RestHighLevelClient elasticsearchClient() {
RestClientBuilder builder = RestClient.builder(new HttpHost(host, port));
RestHighLevelClient restHighLevelClient = new RestHighLevelClient(builder);
return restHighLevelClient;
}
}
8.2.1.3 主启动类
常规无特殊
8.2.2 数据建模
8.2.2.1 实体类
映射 ES 中的 Document
package com.song.es.mapping;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
@Data
@Document(indexName = "product",shards = 1, replicas = 1)
public class Product implements Serializable {
// @Id 注解声明这个字段是 document 的 id
@Id
private Long id;
// 声明普通字段,指定字段类型、分词器
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String productName;
@Field(type = FieldType.Integer)
private Integer store;
@Field(type = FieldType.Double, index = true, store = false)
private double price;
}
8.2.2.2 Dao
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
}
8.2.2.3 测试类
package com.song.es.test;
import com.song.es.dao.ProductRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
@SpringBootTest
public class ElasticSearchTest {
@Autowired
private ProductRepository productRepository;
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Test
public void testInit() {
// IOC 容器初始化的过程中,会根据 Product 实体类创建 index、mapping
}
}
8.2.3 数据操作
8.2.3.1 保存文档
@Test
public void testSave() {
Product product = new Product();
product.setId(505L);
product.setProductName("Hello Goods");
product.setStore(6789);
product.setPrice(3366.77);
productRepository.save(product);
}
8.2.3.2 根据 id 查询文档
@Test
public void testGetById() {
Product product = productRepository.findById(505L).get();
System.out.println("product = " + product);
}
8.2.3.3 查询全部并排序
@Test
public void testSort() {
Iterable<Product> iterable = productRepository.findAll(Sort.by(Sort.Direction.DESC, "price"));
for (Product product : iterable) {
System.out.println("product = " + product);
}
}
8.2.4 自定义方法
8.2.4.1 概述
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。比如你的方法名叫做:findByTitle,那么它就知道你是根据title查询,然后自动帮你完成,无需写实现类。当然,方法名称要符合一定的约定。
虽然基本查询和自定义方法已经很强大了,但是如果是复杂查询(模糊、通配符、词条查询等)就显得力不从心了。此时,我们只能使用原生查询。
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndPrice |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrPrice |
| is | findByFielde | 根据Field获得数据 | findByTitlee |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findByPriceLessThan |
8.2.4.2 声明自定义方法
package com.song.es.dao;
import com.song.es.mapping.Product;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
List<Product> findByPriceBetween(double price1, double price2);
}
8.2.4.3 测试自定义方法
@Test
public void testDIY() {
List<Product> productList =
productRepository.findByPriceBetween(2000, 5000);
for (Product product : productList) {
System.out.println("product = " + product);
}
}
九、ElasticSearch 集群
9.1、需求
单台ElasticSearch服务器往往都有最大的负载能力的限制。超过这个阈值,服务器性能就会大大降低甚至不可用。
所以生产环境中,一般都需要搭建ElasticSearch集群。
除了负载能力,单点服务器也存在其他问题:
- 单节点存储容量有限
- 存在单点故障隐患,无法实现高可用
- 单服务的并发处理能力有限
配置服务器集群时,集群中节点数量没有限制,大于等于2个节点就可以看做是集群了。
一般出于高性能及高可用方面来考虑,集群中节点数量都是3个以上。
9.2、概述
9.2.1、空集群

9.2.2、拥有一个索引的单节点集群

9.2.3、拥有两个节点的集群
所有主分片和副本分片都已被分配

9.2.4、拥有三个节点的集群
为了分散负载而对分片进行重新分配

9.2.5、将参数 number_of_replicas 调大到 2
9.2.6、关闭了一个节点后的集群

9.3、核心概念
9.3.1、集群 Cluster
一个集群就是由一个或多个服务器节点组织在一起,共同持有整个数据,并一起提供索引和搜索功能。
一个ElasticSearch集群有一个共同的名称,默认是”elasticsearch”。
名字一样的节点会进入同一个集群;反过来说不同集群就是用不同名称来区分的。
9.3.2、节点 Node
集群中包含很多服务器,一个节点就是其中的一个服务器。作为集群的一部分,它存储数据,参与集群的索引和搜索功能。
一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。
根据这个名字可以确定网络中的哪些服务器对应于ElasticSearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,
这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,
会默认创建并加入一个叫做“elasticsearch”的集群。
9.3.3、分片 Shards
一个索引可以存储超出单个节点硬件限制的大量数据。
比如,一个具有10亿文档数据的索引占据1TB的磁盘空间,而任一节点都可能没有这样大的磁盘空间。
或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,每一份就称之为分片。
当你创建一个索引的时候,你可以指定你想要的分片的数量。
每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许你水平分割 / 扩展你的内容容量。
- 允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由Elasticsearch管理的,对用户透明。
我们可以在建立索引的时候创建分片信息:
#number_of_shards:主分片数量,默认1(6.x版本默认为5)
#number_of_replicas:每个主分片对应的副本数量,默认1
PUT /users
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}

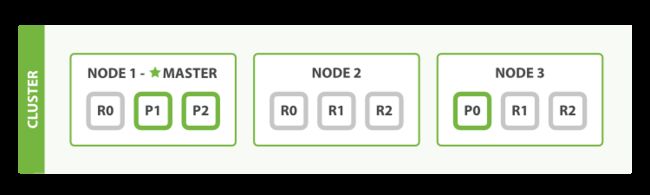
-
★表示master节点
-
●表示DataNode节点
-
粗线框格子为主分片,细线框为副本分片,主分片与副本分片不能同时在同一个节点上。
上述例子中,创建3个主分片,每个主分片配置了2个副本分片,加起来一共9个分片。
分片序号分别为0、1、2代表不同的数据段存储。其中0号分片的主分片在node-3机器上,node-1和node-2是它的备份分片。
注意:主分片数量一旦指定后就不允许更改,否则会影响后续的数据操作(分片位置路由是取模主分片数量)。
虽然主分片数量不可用更改,但是副本数量可以修改:
粗线框格子为主分片,细线框为副本分片,主分片与副本分片不能同时在一台机器上。
9.3.4、副本 Replicas
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,
这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片/节点有可能失败的情况下,提供了高可用性。为了达到这个效果,复制分片不和主分片放在同一个节点上。
- 扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。
一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。
分片和复制的数量可以在索引创建的时候指定。在索引创建之后,可以改变复制分片数量,但不能改变主分片数量。
默认情况下,Elasticsearch中的每个索引被分片1个主分片和1个复制分片,这样的话每个索引总共就有2个分片。
如果此时集群中有两个节点,那么这两个分片分别存放在两个节点上。
9.3.5、分配 Allocation
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。
这个过程是由master节点完成的。 即:Elasticsearch的分片分配和均衡机制。
9.3.6、节点类型
ES 中的节点类型分为:Master、DataNode。
9.3.6.1、master
ElasticSearch启动时,会选举出来一个Master节点。
大致的过程是:当某个节点启动后,使用Zen Discovery机制找到集群中的其他节点,并建立连接。
并从候选节点中选举出一个主节点。
参考配置如下:
discovery.seed_hosts: [“host1”, “host2”, “host3”]
cluster.initial_master_nodes: [“node-1”, “node-2”,“node-3”]
Master节点主要负责:
- 管理索引(创建索引、删除索引)、分配分片
- 维护元数据
- 管理集群节点状态
不负责数据写入和查询,比较轻量级。一个ElasticSearch集群中,只有一个Master节点。在生产环境中,内存可以相对小一点,但要确保机器稳定。
9.3.6.2、DataNode
数据节点可以有多个,负责:数据写入、数据检索,大部分Elasticsearch的压力都在DataNode节点上,在生产环境中,内存最好配置大一些。
9.3.7、总结

一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成,它们共同承担数据和负载的压力。
当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为主节点时,它将负责管理集群范围内除数据外的所有变更。
例如增加、删除索引,或者增加、删除节点等。作为用户,我们可以将请求发送到集群中的任何节点,包括主节点。
每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。
无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。
Elasticsearch 对这一切的管理都是透明的。
9.4、搭建
9.4.1、创建目录
elasticsearch-cluster
9.4.2、复制ES目录
把原来的 ES 解压目录复制成三份:

注意:复制之后 data 目录要删除。
9.4.3、修改配置文件
config/elasticsearch.yml
9.4.3.1、实例 9301
#集群名称
cluster.name: my-application
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称
node.name: node-1
#配置允许的访问网络
network.host: 0.0.0.0
#http服务端口
http.port: 9201
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9301
#是否允许为主节点,默认true
node.master: true
#是否为数据节点,默认true
node.data: true
#初始配置选举master节点
cluster.initial_master_nodes: ["node-1"]
#节点发现
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#elasticsearch-head 跨域解决
http.cors.allow-origin: "*"
http.cors.enabled: true
9.4.3.2、实例 9302
#集群名称
cluster.name: my-application
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称
node.name: node-2
#配置允许的访问网络
network.host: 0.0.0.0
#http服务端口
http.port: 9202
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9302
#是否允许为主节点,默认true
node.master: true
#是否为数据节点,默认true
node.data: true
#初始配置选举master节点
cluster.initial_master_nodes: ["node-1"]
#节点发现
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#elasticsearch-head 跨域解决
http.cors.allow-origin: "*"
http.cors.enabled: true
9.4.3.3、实例 9303
#集群名称
cluster.name: my-application
#默认为true。设置为false禁用磁盘分配决定器。
cluster.routing.allocation.disk.threshold_enabled: false
#节点名称
node.name: node-3
#配置允许的访问网络
network.host: 0.0.0.0
#http服务端口
http.port: 9203
#集群间通信端口号,在同一机器下必须不一样
transport.tcp.port: 9303
#是否允许为主节点,默认true
node.master: true
#是否为数据节点,默认true
node.data: true
#初始配置选举master节点
cluster.initial_master_nodes: ["node-1"]
#节点发现
discovery.seed_hosts: ["127.0.0.1:9301","127.0.0.1:9302","127.0.0.1:9303"]
#elasticsearch-head 跨域解决
http.cors.allow-origin: "*"
http.cors.enabled: true
9.4.4、修改 Kibana 配置
Kibana 不需要复制,只需要把配置文件修改一下。
配置文件路径:config/kibana.yml
elasticsearch.hosts: ["http://localhost:9200","http://localhost:9201","http://localhost:9202","http://localhost:9203"]
9.4.5、启动测试
查看集群健康度
GET /_cluster/health查看节点信息
GET /_cat/nodes
节点健康度指标说明:
- 绿色:所有的主分片和副本分片都已分配。你的集群是 100% 可用的。
- 黄色:所有的主分片已经分片了,但至少还有一个副本是缺失的。不会有数据丢失,所以搜索结果依然是完整的。不过,你的高可用性在某种程度上被弱化。如果 更多的 分片消失,你就会丢数据了。把 yellow 想象成一个需要及时调查的警告。
- 红色:至少一个主分片(以及它的全部副本)都在缺失中。这意味着你在缺少数据:搜索只能返回部分数据,而分配到这个分片上的写入请求会返回一个异常。
9.4.6、查看集群信息的图形化界面工具
把elasticsearch-head-master.zip解压到非中文无空格目录下。
在命令行下进入解压目录,运行:npm start
9.4.7、数据测试
创建索引:
PUT /shopping
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "2"
}
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "ik_max_word"
},
"subtitle":{
"type": "text",
"analyzer": "ik_max_word"
},
"images":{
"type": "keyword",
"index": false
},
"price":{
"type": "float",
"index": true
}
}
}
}
保存文档:
POST /shopping/_doc/1
{
"title":"小米手机",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}
9.5、内部机制
9.5.1、写流程
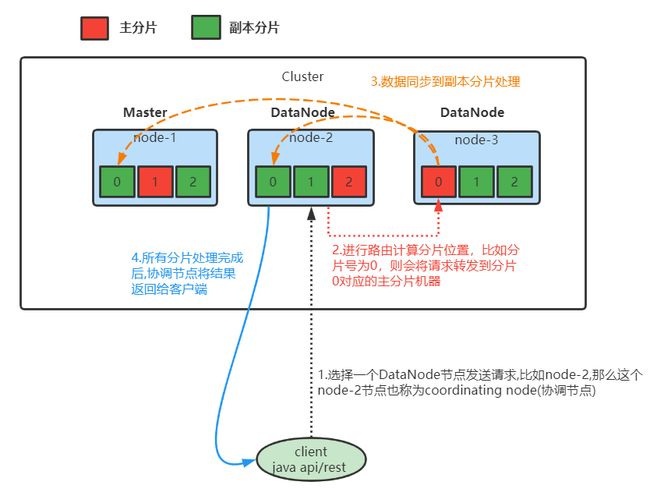
- 第一步: 客户端选择DataNode节点发送请求,如上图架构,假设发送到node-2节点上。此时被选择的node-2节点也称为coordinating node(协调节点)
- 第二步: 协调节点根据路由规则计算分片索引位置。并将请求发送到分片索引对应的主分片机器上(这里假设分片计算后的值为0,那么请求会命中到node-3节点上)。
- 计算分片索引位置: shard = hash(routing) % number_of_primary_shards,routing可以自己设定,一般默认为文档的ID。
- 第三步: 当主分片文档写入完成后,同时将数据推送到与之对应的副本分片进行写入操作
- 第四步: 当分片完成了写入后再由协调节点将操作结果返回给客户端
9.5.2、读流程

- 第一步:客户端选择DataNode节点发送请求,如上图架构,假设发送到node-2节点上。此时被选择的node-2节点也称为coordinating node(协调节点)
- 第二步: 协调节点将从客户端获取到的请求数据转发到其它节点
- 第三步: 轮询其它节点将查询结果文档ID、节点、分片信息返回给协调节点
- 第四步: 协调节点通过文档ID、节点信息等发送get请求给其它节点进行数据获取,最后进行汇总排序将数据返回给客户端
随笔:
ElasticSearch(搜索引擎)主要是进行字段的截取查找功能,对于我来说,则主要是对于如何在idea里整合时需要携带,使用的jar包,方法…
每日金句
花开又期,花期不同。
春日不迟,相逢终有时。