Drf框架Django(Elasticsearch,serializers)
目录
1.商业模式介绍
2项目知识点
商业模式介绍
1. B2B–企业对企业
B2B平台是电子商务的一种模式,是英文Business-to-Business的缩写,即商业对商业,或者说是企业间的电子商务,即企业与企业之间通过互联网进行产品、服务及信息的交换。它将企业内部网,通过B2B网站与客户紧密结合起来,通过网络的快速反应,为客户提供更好的服务,从而促进企业的业务发展
案例 阿里巴巴,
2. C2C–个人对个人
通过电子商务网站为买卖用户双方提供一个在线交易平台,使卖方可以在上面发布待出售的物品的信息,而买方可以从中选择进行购买,同时,为便于买卖双方交易,提供交易所需的一系列配套服务。如:协调市场信息汇集、建立信用评价制度、多种付款方式
案例 淘宝,闲鱼,瓜子二手车
3. B2C–企业对个人
B2C是Business to Customer的缩写,而其中文简称为“商对客”。“商对客”是电子商务的一种模式,也就是通常说的直接面向消费者销售产品和服务商业零售模式·这种形式的电子商务一般以网络零售业为主,主要借助于互联网开展在线销售活动·B2C即企业通过互联网为消费者提供一个新型的购物环境
—-网上商店,消费者通过网络在网上购物、网上支付等消费行为。
案例 唯品会,
4.C2B–个人对企业
·C2B(Consumer to Business,即消费者到企业),是互联网经济时代新的商业模式。这一模式改变了原有生产者(企业和机构)和消费者的关系,是一种消费者贡献价值(Create Value),企业和机构消费价值(Consume Value)。C2B模式和我们熟知的供需模式(DSM,Demand Supply Model)恰恰相反,真正的C2B应该先有消费者需求产生而后有企业生产,即先有消费者提出需求,后有生产企业按需求组织生产。通常情况为消费者根据自身需求定制产品和价格,或主动参与产品设计、生产和定价,产品、价格等彰显消费者的个性化需求,生产企业进行定制化生产。
案例 海尔商场,商品宅派
项目知识点
live-server实时简易静态服务器
Live Server:一个具有实时加载功能的小型服务器,可以使用它来破解html/css/javascript,但是不能用于部署最终站点。也就是说我们可以在项目中实时用live-server作为一个实时服务器实时查看开发的网页或项目效果。
安装
npm install -g live-server
在所在项目目录下,打开命令行工具,输入 live-server,回车就可以了(注意这里默认打开的是index.html)。
默认端口 8080 可以指定端口 9000
live-server --port 9000
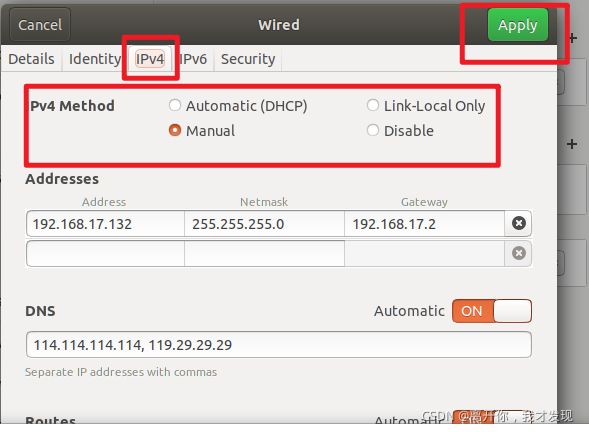
ubuntu 设置默认IP地址
设置 wired
ipv4
手动设置
A类 10.0.0.0--10.255.255.255
B类 172.16.0.0--172.31.255.255
C类 192.168.0.0--192.168.255.255
Address 默认为ubuntu 的ip 用ifconfig 查看
Netmask c类 子网掩码 255.255.255.0
gateway 网关 192.168.17.2
dns 114.114.114.114,119.29.29.29
详情请到这里面
Django自定义文件存储类
注意
- 必须重写的
_open方法,_save方法 url方法 用来访问文件exists方法用来判断文件名是否重复,
"""
继承Storage必须实现_open()和_save()方法
"""
class FastDFSStorage(Storage):
def __init__(self, client_path=None, base_url=None):
# fastDFS的客户端配置文件路径
self.client_path = client_path or settings.FDFS_CLIENT_CONF
# storage服务器ip:端口
self.base_url = base_url or settings.FDFS_BASE_URL
def _open(self, name, mode='rb'):
"""
用来打开文件的,但是我们自定义文件存储系统的目的是为了实现存储到远程的FastDFS服务器,不需要打开文件,所以此方重写后什么也不做pass
:param name: 要打开的文件名
:param mode: 打开文件的模式 read bytes
:return: None
"""
pass
def _save(self, name, content):
"""
文件存储时什么调用此方法,但是此方法默认是向本地存储,在此方法做实现文件存储到远程的FastDFS服务器
:param name: 要上传的文件名
:param content: 以rb模式打开的文件对象 将来通过content.read() 就可以读取到文件的二进制数据
:return: file_id
"""
# 1.创建FastDFS 客户端
# client = Fdfs_client('meiduo_mall/utils/fastdfs/client.conf')
# client = Fdfs_client(settings.FDFS_CLIENT_CONF)
client = Fdfs_client(self.client_path)
# 2.通过客户端调用上传文件的方法上传文件到fastDFS服务器
# client.upload_by_filename('要写上传文件的绝对路径') 只能通过文件绝对路径进行上传 此方式上传的文件会有后缀
# upload_by_buffer 可以通过文件二进制数据进行上传 上传后的文件没有后缀
ret = client.upload_by_buffer(content.read())
# 3.判断文件是否上传成功
if ret.get('Status') != 'Upload successed.':
raise Exception('Upload file failed')
# 3.1 获取file_id
file_id = ret.get('Remote file_id')
# 4.返回file_id
return file_id
def exists(self, name):
"""
当要进行上传时都调用此方法判断文件是否已上传,如果没有上传才会调用save方法进行上传
:param name: 要上传的文件名
:return: True(表示文件已存在,不需要上传) False(文件不存在,需要上传)
"""
return False
def url(self, name):
"""
当要访问图片时,就会调用此方法获取图片文件的绝对路径
:param name: 要访问图片的file_id
:return: 完整的图片访问路径: storage_server IP:8888 + file_id
"""
# return 'http://xxx.xxx.xxx.xx:8888/' + name
# return settings.FDFS_BASE_URL + name
return self.base_url + name
-
在Django中setting文件设置三个变量
# 指定Django使用的文件存储类 ,上面编写的py文件的路径 DEFAULT_FILE_STORAGE = 'utils.fdfs.storage.FastDFSStorage' # 设置fdfs使用的client.conf文件路径 ,变量名自己取,与上面的py文件一致 FDFS_CLIENT_CONF = './utils/fdfs/client.conf' # 设置fdfs存储服务器ngibx的ip和端口号,变量名自己取,与上面的py文件一致 FDFS_URL = 'http://xxx.xxx.xxx.xx:8888/' -
具体见官方文档 https://docs.djangoproject.com/zh-hans/2.2/howto/custom-file-storage/
CKEditor 富文本编辑器
-
安装
pip install django-ckeditor -
注册应用
INSTALLED_APPS = [ ...... 'ckeditor', # 富⽂文本编辑器器 'ckeditor_uploader', # 富⽂文本编辑器器上传图⽚片模块 ...... ] -
加载配置
# 富⽂文本编辑器器ckeditor配置 CKEDITOR_CONFIGS = { 'default': { 'toolbar': 'full', # ⼯工具条功能 'height': 300, # 编辑器器⾼高度 'width': 300, # 编辑器器宽 }, } CKEDITOR_UPLOAD_PATH = '' # 上传图⽚片保存路路径,使⽤用了了FastDFS,所以此处设为'' -
注册总路由
re_path(r'^ckeditor/', include('ckeditor_uploader.urls')), -
模型类补充富⽂文本字段
desc_detail = RichTextUploadingField(default='', verbose_name='详细介绍') desc_pack = RichTextField(default='', verbose_name='包装信息') desc_service = RichTextUploadingField(default='', verbose_name='售后服务') -
修复bug适配FastDFS
if len(str(saved_path).split('.')) > 1: if(str(saved_path).split('.')[1].lower() != 'gif'): self._create_thumbnail_if_needed(backend, saved_path)
搜索引擎(全文检索方案Elasticsearch)
实现全文检索的搜索引擎,首选的是
Elasticsearch。
- Elasticsearch是用 Java 实现的,开源的搜索引擎。
- 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github等都采用它。
- Elasticsearch 的底层是开源库Lucene 。但是,没法直接使用 Lucene,必须自己写代码去调用它的接口。
分词说明
-
搜索引擎在对数据构建索引时,需要进行分词处理。
-
分词是指将一句话拆解成多个单字或词,这些字或词便是这句话的关键词。
-
比如:
我是中国人- 分词后:
我、是、中、国、人、中国等等都可以是这句话的关键字。
- 分词后:
-
Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展
elasticsearch-analysis-ik来实现中文分词处理。
-
使用Docker安装Elasticsearch
1.获取Elasticsearch-ik镜像
# 从仓库拉取镜像 $ sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0 # 本地镜像 $ sudo docker load -i elasticsearch-ik-2.4.6_docker.tar2.配置Elasticsearch-ik
-
elasticsearc-2.4.6目录拷贝到home目录下 -
修改
/home/ubuntu/Desktop/elasticsearc-2.4.6/config/elasticsearch.yml第54行。 -
更改ip地址为本机真实ip地址。
3.使用Docker运行Elasticsearch-ik
sudo docker run -dti --name=elasticsearch --network=host -v /home/ubuntu/Desktop/elasticsearch-2.4.6/config:/us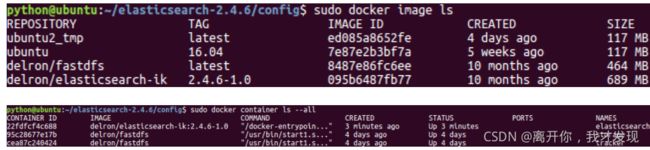
-
-
Haystack介绍和安装配置
1.Haystack介绍
-
Haystack
是在Django中对接搜索引擎的框架,搭建了用户和搜索引擎之间的沟通桥梁。
- 我们在Django中可以通过使用 Haystack 来调用 Elasticsearch 搜索引擎。
-
Haystack 可以在不修改代码的情况下使用不同的搜索后端(比如
Elasticsearch、Whoosh、Solr等等)。
2.Haystack安装
$ pip install django-haystack $ pip install elasticsearch==2.4.13.Haystack注册应用和路由
INSTALLED_APPS = [ 'haystack', # 全文检索 ]4.在setting中配置Haystack
# Haystack HAYSTACK_CONNECTIONS = { 'default': { 'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine', 'URL': 'http://192.168.17.132:9200/', # Elasticsearch服务器ip地址,端口号固定为9200 'INDEX_NAME': 'meiduo_mall', # Elasticsearch建立的索引库的名称 }, } # 当添加、修改、删除数据时,自动生成索引 # HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor' -
页面静态化
- 为了,提升响应速度,提高用户体验,将页面做成静态化,放到静态服务器上运行,
- 与用户相关的不能做静态化处理,用局部刷新来获取 用户信息,购物车信息,
- 首页index_html, 用crontab 来定时生成
- 静态商品详情页面
购物车
- 购物车存储方法
- 用户选择 2个
huaweip40添加到购物车中,状态为勾选
- 用户选择 2个
- 一条完整的购物车记录包括了
用户,商品,数量,勾选状态 - 存储数据 :
user_id,sku_id,count,selected
存储 说明
- 购物车数据量小, 结构简单,但是更新频繁,所以我们选择内存型数据库Redis
这里,允许用户不登录,也能添加到购物车,利用浏览器的cookie 存储
-
密文存储
- 解决方案:
pickle模块和base64模块
pickle模块使用:
pickle.dumps()将Python数据序列化为bytes类型数据。pickle.loads()将bytes类型数据反序列化为python数据。
>>> import pickle >>> dict = {'1': {'count': 10, 'selected': True}, '2': {'count': 20, 'selected': False}} >>> ret = pickle.dumps(dict) >>> ret b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.' >>> pickle.loads(ret) {'1': {'count': 10, 'selected': True}, '2': {'count': 20, 'selected': False}}- base64模块是Python的标准模块,可以对bytes类型数据进行编码,并得到bytes类型的密文数据。
- base64模块使用:
base64.b64encode()将bytes类型数据进行base64编码,返回编码后的bytes类型数据。base64.b64deocde()将base64编码后的bytes类型数据进行解码,返回解码后的bytes类型数据。
>>> import base64 >>> ret b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.' >>> b = base64.b64encode(ret) >>> b b'gAN9cQAoWAEAAAAxcQF9cQIoWAUAAABjb3VudHEDSwpYCAAAAHNlbGVjdGVkcQSIdVgBAAAAMnEFfXEGKGgDSxRoBIl1dS4=' >>> base64.b64decode(b) b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.' - 解决方案:
ubuntu 网卡,有时缺少 ens33
解决方法
让他自动寻址,分别输入,就可以ping通了:
xx@ubuntu:~/Desktop$ sudo ifconfig ens33 up
xx@ubuntu:~/Desktop$ sudo dhclient ens33
xx@ubuntu:~/Desktop$ sudo ifconfig ens33
参考 Ubuntu18.04解决网卡失效的问题
解决 Win10 与 Ubuntu16.04 之间实现粘贴复制
Ctrl+C,Ctrl+Shift+V
sudo apt install open-vm-tools
sudo apt install open-vm-tools-desktop
# 重启
reboot
ubuntu安装 网络相关的包 apt install netscript
非幂等&幂等
-
概念
- 非幂等
- 如果后端处理理结果对于这些请求的最终结果不不同,跟
请求次数相关,则称接⼝口⾮非幂等
- 如果后端处理理结果对于这些请求的最终结果不不同,跟
- 幂等
- 对于同⼀一个接⼝口,进⾏行行多次相同的请求,如果后端处理理结果对于这些请求都是相同的,则称接⼝口是幂等的
- 非幂等
-
场景
PUT/cart/ count 商品数量 原始值 10 方式1 count 表示 商品数量 +1 -->后端执行加1操作,===>非幂等 PUT /cart/ count=1 --> 11 PUT /cart/ count=1 --> 12 PUT /cart/ count=1 --> 13 方式1 count 表示 修改之后的结果 -->后端执行覆盖原有值,===>幂等 PUT /cart/ count=1 --> 1 PUT /cart/ count=1 --> 1 PUT /cart/ count=13 --> 13
Django 事务的使用
1.Django中事务的使用方案
- 在Django中可以通过
django.db.transaction模块提供的atomic来定义一个事务。
atomic提供两种方案实现事务:
装饰器用法:
-
from django.db import transaction @transaction.atomic def viewfunc(request): # 这些代码会在一个事务中执行 ......
with语句用法:
from django.db import transaction
def viewfunc(request):
# 这部分代码不在事务中,会被Django自动提交
......
with transaction.atomic():
# 这部分代码会在事务中执行
......
2.事务方案的选择:
- 装饰器用法: 整个视图中所有MySQL数据库的操作都看做一个事务,范围太大,不够灵活。而且无法直接作用于类视图。
- with语句用法: 可以灵活的有选择性的把某些MySQL数据库的操作看做一个事务。而且不用关心视图的类型。
- 具体情况具体分析
3.事务中的保存点:
- 在Django中,还提供了保存点的支持,可以在事务中创建保存点来记录数据的特定状态,数据库出现错误时,可以回滚到数据保存点的状态。
from django.db import transaction
# 创建保存点
save_id = transaction.savepoint()
# 回滚到保存点
transaction.savepoint_rollback(save_id)
# 提交从保存点到当前状态的所有数据库事务操作
transaction.savepoint_commit(save_id)
使用乐观锁并发下单
原因
- 在多个用户同时发起对同一个商品的下单请求时,先查询商品库存,再修改商品库存,会出现资源竞争问题,导致库存的最终结果出现异常。
注意 使用乐观锁的时候,如果一个事务修改了库存并提交了事务,那其他的事务应该可以读取到修改后的数据值,所以不能使用可重复读的隔离级别,应该修改为读取已提交(Read committed)
MySQL事务隔离级别
- 事务隔离级别指的是在处理同一个数据的多个事务中,一个事务修改数据后,其他事务何时能看到修改后的结果。
- MySQL数据库事务隔离级别主要有四种:
Serializable:串行化,一个事务一个事务的执行。Repeatable read:可重复读,无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响。Read committed:读取已提交,其他事务提交了对数据的修改后,本事务就能读取到修改后的数据值。Read uncommitted:读取未提交,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。- MySQL数据库默认使用可重复读( Repeatable read)。
- 使用乐观锁的时候,如果一个事务修改了库存并提交了事务,那其他的事务应该可以读取到修改后的数据值,所以不能使用可重复读的隔离级别,应该修改为读取已提交(Read committed)。
- 修改方式:
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
修改完成之后重启
sudo service mysql restart
transaction-isolation=READ-COMMITTED
Django 接入 支付(支付宝为例)
支付宝开放平台入口
- https://open.alipay.com/platform/home.htm
登录 账号
控制台
创建应用

开发服务-测试
沙箱环境
沙箱环境
支付宝提供给开发者的模拟支付的环境。跟真实环境是分开的。
- 沙箱应用:https://openhome.alipay.com/platform/appDaily.htm?tab=info

支付宝开发文档
-
文档主页: https://openhome.alipay.com/developmentDocument.htm
-
电脑网站支付产品介绍: https://docs.open.alipay.com/270
-
电脑网站支付快速接入: https://docs.open.alipay.com/270/105899/
-
API列表: https://docs.open.alipay.com/270/105900/
-
SDK文档: https://docs.open.alipay.com/270/106291/
-
Python支付宝SDK: 这里使用第三方编写,调用简洁
https://github.com/fzlee/alipay/blob/master/README.zh-hans.md
- SDK安装:
pip install python-alipay-sdk --upgrade
- SDK安装:
配置RSA2公私钥
生成项目公钥
$ openssl
$ OpenSSL> genrsa -out app_private_key.pem 2048 # 制作私钥RSA2
$ OpenSSL> rsa -in app_private_key.pem -pubout -out app_public_key.pem # 导出公钥
$ OpenSSL> exit
调用时注意
notify_url=" ", 此参数一定要写,Str类型
# 生成登录支付宝连接
order_string = alipay.api_alipay_trade_page_pay(
out_trade_no=order_id,
total_amount=str(order.total_amount),
subject="美多商城%s" % order_id,
return_url=settings.ALIPAY_RETURN_URL,
notify_url=" ",
app_private_key_string = open(settings.APP_PRIVATE_KEY_PATH).read()
alipay_public_key_string = open(settings.ALIPAY_PUBLIC_KEY_PATH).read()
# 创建支付宝对象
alipay = AliPay(
appid=settings.ALIPAY_APPID,
app_notify_url=None, # 默认回调url
app_private_key_string=app_private_key_string,
# 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,
alipay_public_key_string=alipay_public_key_string,
sign_type='RSA2',
debug=True
)
print("打印参数》》》》》")
print(type(settings.ALIPAY_RETURN_URL))
print("执行》》》》》》》")
# 生成登录支付宝连接
order_string = alipay.api_alipay_trade_page_pay(
out_trade_no=order_id,
total_amount=str(order.total_amount),
subject="美多商城%s" % order_id,
return_url=settings.ALIPAY_RETURN_URL,
notify_url=" ",
)
# 生成登录支付宝连接
# 3.0 接口方法
order_string = alipay.client_api(
"alipay.trade.page.pay",
biz_content={
"subject": "美多商城%s" % order_id,
"out_trade_no": order_id,
"total_amount": str(order.total_amount),
"product_code": "FAST_INSTANT_TRADE_PAY",
},
return_url=settings.ALIPAY_RETURN_URL,
)
# 响应登录支付宝连接
# 真实环境电脑网站支付网关:https://openapi.alipay.com/gateway.do? + order_string
# 沙箱环境电脑网站支付网关:https://openapi.alipaydev.com/gateway.do? + order_string
alipay_url = settings.ALIPAY_URL + "?" + order_string
# print("alipay_url")
# print(alipay_url)
return JsonResponse({'code': 0, 'errmsg': 'OK', 'alipay_url': alipay_url})
后台部署
弃用Django自带的admin,使用扩展 xadmin
安装 ubuntu18.04 pip install https://github.com/sshwsfc/xadmin/tarball/
win10 解决 https://blog.csdn.net/teavamc/article/details/75400755
注册应用
# xadmin 配置
'xadmin',
'crispy_forms',
'reversion',
迁移Xadmin数据库
python manage.py makemigrations
mysql 数据库主从
作用
-
通过增加从服务器来提⾼数据库的性能,在主服务器上执⾏写⼊和更新,在从服务器器上向外提供读功能,可以动态地调整从服务器器的数量,从⽽调整整个数据库的性能。
-
提⾼数据安全,因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份⽽不破坏主服务器相应数据
-
在主服务器上生成实时数据,而在从服务器器上分析这些数据,从而提高主服务器的性能
热备份 主机不停机,实时将数据备份给从机
冷备份 主机需要停机,再将数据备份给从机
同步机制
1.先执行冷备份
2.再执行热备份

注意: mysql 主从机的版本,不要相差太大
-
修改从机配置文件
# 修改端口 port = 8306 # 是否生成日志文件 0 不生成 1生成 general_log_file = /var/log/mysql/mysql.log general_log = 0 # 主机 为1 # 修改从机 server-id = 2 -
主机配置
server-id = 1 # log日志文件 log_bin = /var/log/mysql/mysql-bin.log重启主机的mysql
-

-
创建从机账号
mysql –uroot –pmysql GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' identified by 'slave'; FLUSH PRIVILEGES; -
获取mysql主机的二进制日志信息
在主机上
SHOW MASTER STATUS;
说明
file >> 从机热备份时读取数据的文件
Position >> 从机热备份时读取数据的位置,节点

在从机上
SHOW MASTER STATUS;
序列化器
1. 安装
-
pip install djangorestframework
2. 注册序列化器
-
INSTALLED_APPS = [ ... 'rest_framework', ]
3. 创建序列化器
-
模型类
from django.db import models # Create your models here. # 准备书籍列表信息的模型类 class BookInfo(models.Model): # 创建字段,字段类型... name = models.CharField(max_length=20, verbose_name='名称') pub_date = models.DateField(verbose_name='发布日期',null=True) breadcount = models.IntegerField(default=0, verbose_name='阅读量') bcommentcount = models.IntegerField(default=0, verbose_name='评论量') is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') image = models.ImageField(upload_to='book', null=True, verbose_name='图片') class Meta: db_table = 'bookinfo' # 指明数据库表名 verbose_name = '图书' # 在admin站点中显示的名称 def __str__(self): """定义每个数据对象的显示信息""" return self.name # 准备人物列表信息的模型类 class HeroInfo(models.Model): hname = models.CharField(max_length=20, verbose_name='名称') hgender = models.IntegerField(max_length=20,verbose_name='密码') hdesc = models.CharField(max_length=200, null=True, verbose_name='描述信息') hbook = models.ForeignKey(BookInfo,related_name='people', on_delete=models.CASCADE, verbose_name='图书') # 外键 is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta: db_table = 'heroinfo' verbose_name = '人物信息' def __str__(self): return self.hname -
创建
serializers.py文件- 写序列化器
from rest_framework import serializers from book.models import BookInfo class PeopleInfoSerializer(serializers.Serializer): """英雄数据序列化器""" id = serializers.IntegerField(label='ID') hname = serializers.CharField(label='名字') hgender = serializers.IntegerField(label="性别") hdesc = serializers.CharField(label="描述信息") """定义序列化器""" class BookInfoSerializer(serializers.Serializer): """图书数据序列化器""" id = serializers.IntegerField(label='ID') name = serializers.CharField(label='名称') pub_date = serializers.DateField(label='发布日期') breadcount = serializers.IntegerField(label='阅读量') bcommentcount = serializers.IntegerField(label='评论量') # 一对多的序列化器 people = PeopleInfoSerializer(many=True) class PeopleSerializer(serializers.Serializer): """英雄数据序列化器""" id = serializers.IntegerField(label='ID') hname = serializers.CharField(label='名字') hgender = serializers.IntegerField(label="性别") hdesc = serializers.CharField(label="描述信息") # hbook_id = serializers.IntegerField(label="图书id") # hbook = serializers.PrimaryKeyRelatedField(label='图书',read_only=True) # 不能被反序列化 # hbook = serializers.PrimaryKeyRelatedField(label='图书',queryset=BookInfo.objects.all()) # # 此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值) # hbook = serializers.StringRelatedField(label="图书") # # 图书的序列化信息 hbook = BookInfoSerializer()序列化输出
from book.models import BookInfo,HeroInfo hero = HeroInfo.objects.get(id=3) from book.serializers import PeopleSerializer hero_ser = PeopleSerializer(hero) hero_ser.data -
反序列化器
-
写一个 字典
-
创建 序列化器对象 serializer
-
验证
-
保存
代码
from book.models import BookInfo,HeroInfo from book.serializers import PeopleSerializer, BookInfoSerializer data = { 'name':'Python高级', 'pub_date':'2020-1-1', 'breadcount':100, 'bcommentcount':200, } # 创建序列化对象 book = BookInfoSerializer(data=data) # 验证 返回 True False book.is_valid() # 查看报错信息 book.errors # 返回 {}is_valid()方法还可以在验证失败时抛出异常serializers.ValidationError,可以通过传递raise_exception=True参数开启,REST framework接收到此异常,会向前端返回HTTP 400 Bad Request响应。
-
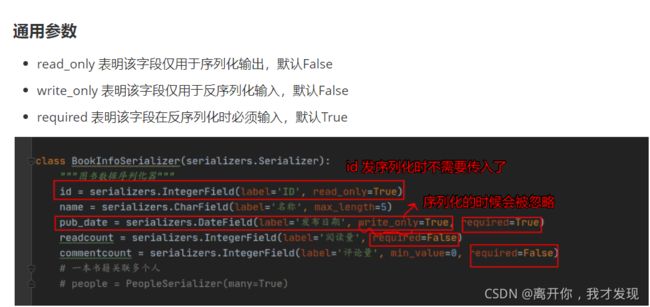
read__only和write__only 不能同时出现
**验证字段方法validate_filedname **
可以 进行正则判断,
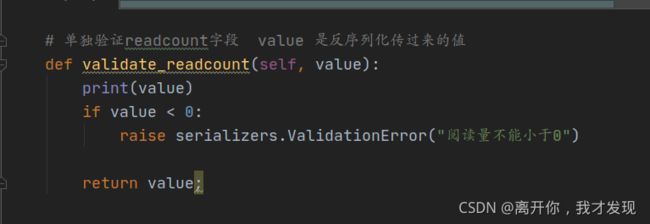
validate
在序列化器中需要同时对多个字段进行比较验证时,可以定义validate方法来验证,如
def validate(self, attrs):
readcount = attrs['readcount']
commentcount = attrs['commentcount']
if commentcount > readcount:
raise serializers.ValidationError('评论量不能大于阅读量')
return attrs
保存
保存到数据库,
# 序列化器类,定义create 方法
def create(self, validated_data):
"""新建"""
return BookInfo.objects.create(**validated_data)
代码
**注意: 如果创建序列化器对象的时候,没有传递instance实例,则调用save()方法的时候,create()被调用。 **
>>> from book.serializers import BookInfoSerializer
>>>
>>> data = {
... 'name':'Python高级',
... 'pub_date':'2020-01-01',
... 'readcount':100,
... 'commentcount':20
... }
>>>
>>> serializer = BookInfoSerializer(data=data)
>>>
>>> serializer.is_valid(raise_exception=True)
True
>>>
>>> serializer.save()
更新
def update(self, instance, validated_data):
"""更新,instance为要更新的对象实例"""
instance.name = validated_data.get('name', instance.name)
instance.pub_date = validated_data.get('pub_date', instance.pub_date)
instance.readcount = validated_data.get('readcount', instance.readcount)
instance.commentcount = validated_data.get('commentcount', instance.commentcount)
instance.save()
return instance
**注意: 如果创建序列化器对象的时候,如果传递了instance实例,则调用save()方法的时候,update()被调用。**
测试
>>> from book.serializers import BookInfoSerializer
>>> from book.models import BookInfo
>>>
>>> book = BookInfo.objects.get(id=5)
>>>
>>> data = {
... 'name':'Django高级',
... 'pub_date':'2020-01-01',
... 'readcount':100,
... 'commentcount':20
... }
>>>
>>> serializer = BookInfoSerializer(instance=book,data=data)
>>>
>>> serializer.is_valid(raise_exception=True)
True
>>>
>>> serializer.save()
>>>
小结
- 如果没有传入
instance则 是保存 到数据库,自动调用create方法 - 传入
instance则 是更新 到数据库,自动调用update方法
两点说明:
1) 在对序列化器进行save()保存时,可以额外传递数据,这些数据可以在create()和update()中的validated_data参数获取到
serializer.save(user=request.user)
2)默认序列化器必须传递所有required的字段,否则会抛出验证异常。但是我们可以使用partial参数来允许部分字段更新
serializer = BookInfoSerializer(instance=book, data={'pub_date': '2999-1-1'}, partial=True)
模型类序列化器ModelSerializer
ModelSerializer与常规的Serializer相同,但提供了:
- 基于模型类自动生成一系列字段
- 包含默认的create()和update()的实现
代码
from rest_framework import serializers
from book.models import BookInfo
class BookInfoModelSerializer(serializers.ModelSerializer):
class Meta:
model = BookInfo # 必须指定模型类
fields = '__all__' # 默认生成字段
# 可以自己指定字段
# fields = ["id", "name"]
# 除去列表中的字段
# exclude = ["is_delete"]
演示

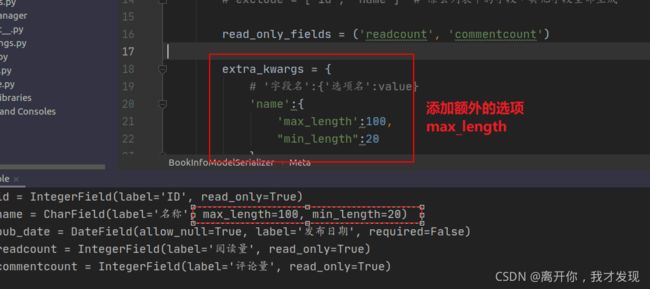
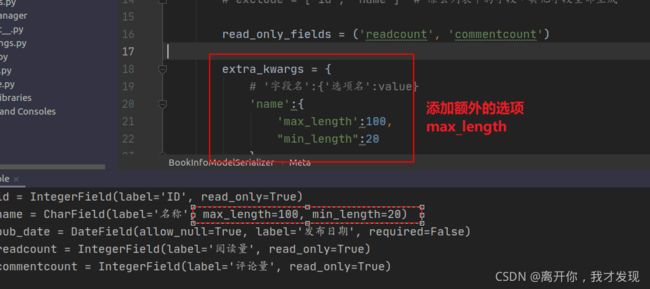
-
设置某些字段为只读

-
额外参数
序列化器关联的外键写法
subs = AreaSerializer(many=True) # subs 是省下面的所有的市区县
# subs = serializers.PrimaryKeyRelatedField() # 只会序列化出 id
# subs = serializers.StringRelatedField() # 序列化的时模型中str方法返回值
视图
-
扩展 Request
# Django自带的 request.GET # 扩展 request.query_params ====================== # Django自带的 request.POST # 扩展 request.data -
扩展 Response
REST framework提供了
Renderer渲染器,用来根据请求头中的Accept(接收数据类型声明)来自动转换响应数据到对应格式。如果前端请求中未进行Accept声明,则会采用默认方式处理响应数据,我们可以通过配置来修改默认响应格式。REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': ( # 默认响应渲染类 'rest_framework.renderers.JSONRenderer', # json渲染器 'rest_framework.renderers.BrowsableAPIRenderer', # 浏览API渲染器 ) }构造方式
Response(data, status=None, template_name=None, headers=None, content_type=None)参数说明:
data: 为响应准备的序列化处理后的数据;status: 状态码,默认200;template_name: 模板名称,如果使用HTMLRenderer时需指明;headers: 用于存放响应头信息的字典;content_type: 响应数据的Content-Type,通常此参数无需传递,REST framework会根据前端所需类型数据来设置该参数。
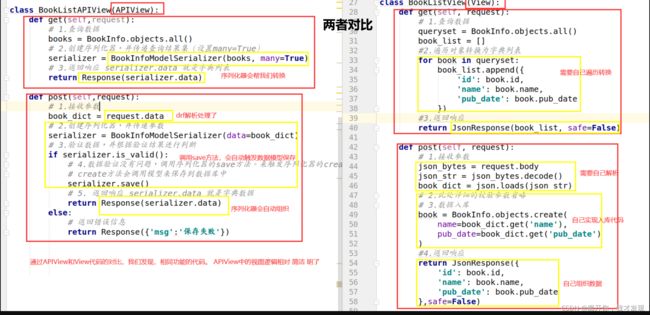
1. APIView(一级)
APIView与View的不同之处在于:
- 传入到视图方法中的是REST framework的
Request对象,而不是Django的HttpRequeset对象; - 视图方法可以返回REST framework的
Response对象,视图会为响应数据设置(render)符合前端要求的格式; - 任何
APIException异常都会被捕获到,并且处理成合适的响应信息; - 在进行dispatch()分发前,会对请求进行身份认证、权限检查、流量控制。
支持定义的属性:
- authentication_classes列表或元祖,身份认证类
- permissoin_classes列表或元祖,权限检查类
- throttle_classes列表或元祖,流量控制类
2. GenericAPIView(二级)
支持定义的属性:
-
列表视图与详情视图通用:
- queryset列表视图的查询集
- serializer_class视图使用的序列化器
-
详情页视图使用:
- lookup_field查询单一数据库对象时使用的条件字段,默认为’
pk’ - lookup_url_kwarg查询单一数据时URL中的参数关键字名称,默认与look_field相同
- lookup_field查询单一数据库对象时使用的条件字段,默认为’
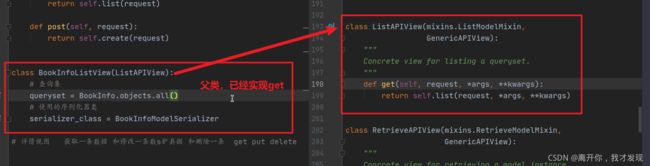
3. Mixin
注意Mixin 配合GenericAPIView
-
1)ListModelMixin
列表视图扩展类,提供
list(request, *args, **kwargs)方法快速实现列表视图,返回200状态码。该Mixin的list方法会对数据进行过滤和分页。
-
2)CreateModelMixin
创建视图扩展类,提供
create(request, *args, **kwargs)方法快速实现创建资源的视图,成功返回201状态码。如果序列化器对前端发送的数据验证失败,返回400错误
-
详情文档
4. 子类视图(三级)
-
ListAPIView
-
添加路由
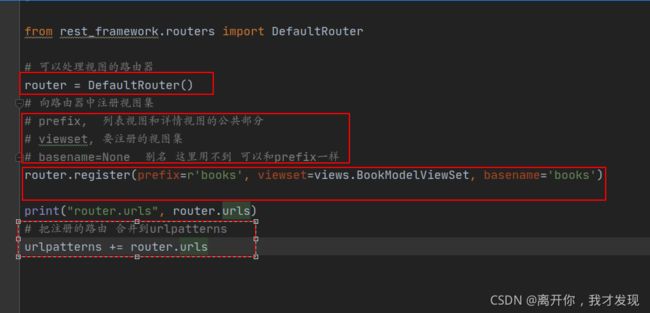
视图集ViewSet
- 实现所有的增,删,改,查,查一个

drf 缓存使用
安装
pip3 install drf-extensions
1.装饰器的方式
-
它可以接收两个参数

-
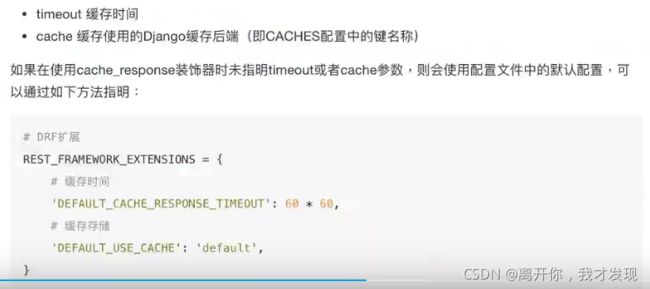
**继承视图 CacheResponseMixin **
-
setting 设置缓存时间
# drf缓存时间 REST_FRAMEWORK_EXTENSIONS = { # 设置为5秒 'DEFAULT_CACHE_RESPONSE_TIMEOUT': 5 } -
官网文档:http://chibisov.github.io/drf-extensions/docs