CentOS 7 搭建 Hadoop3.3.1集群
1. 软件准备
jdk8: 链接: https://pan.baidu.com/s/1zIha0ks8Nokok2cQtO53rA 提取码: jd8x
hadoop3.3.1: 链接: https://pan.baidu.com/s/1Zjjnj05erfVR395yC68tfA 提取码: hd3x
2. 环境准备
集群环境: 网络为桥接模式的两个节点。一个作为 Master 节点,局域网 IP 为 192.168.3.18;另一个作为 Slave 节点,局域网 IP 为 192.168.3.14
因为是实验环境,所有没有新建 hadoop 用户,下文统一使用root用户。
CentOS系统需要关闭防火墙。 CentOS系统默认开启了防火墙,在开启 Hadoop 集群之前,需要关闭集群中每个节点的防火墙。
systemctl status firewalld.service # 查看防火墙状态
systemctl stop firewalld.service # 关闭firewall
systemctl disable firewalld.service # 禁止firewall开机启动
vi /etc/selinux/config
SELINUX=disabled # 最小权限原则关闭
3. 网络配置
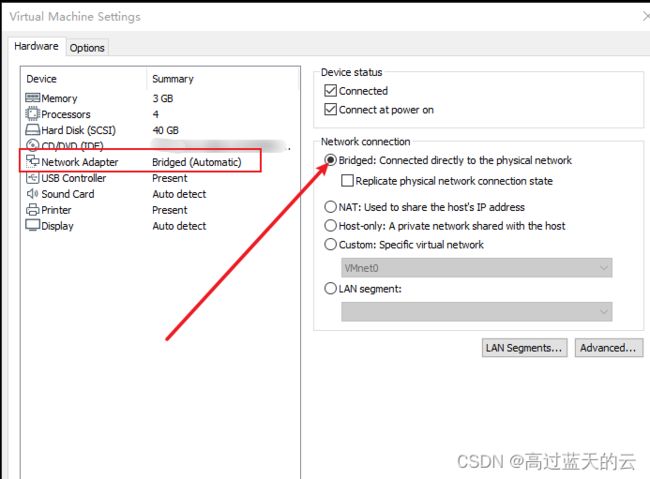
假设集群所用的节点都位于同一个局域网。如果使用的是虚拟机安装的系统,那么需要更改网络连接方式为桥接(Bridge)模式,才能实现多个节点互连。
为了便于区分,我们在 Master 节点上分别执行如下命令修改主机名(即改为 Master,注意是区分大小写的):
vim /etc/hostname

然后执行如下命令修改自己所在集群节点的IP映射:
vim /etc/hosts

修改完成后需要重启一下,重启后在终端中才会看到机器名的变化。
一定要在集群的所有节点上都完成网络配置。如上面讲的是 Master 节点的配置,而在其他的 Slave 节点上,也要对 /etc/hostname(修改为 Slave1、Slave2 等) 和 /etc/hosts(跟 Master 的配置一样)这两个文件进行修改!
配置好后需要在各个节点上执行如下命令,测试是否相互 ping 得通,如果 ping 不通,后面就无法顺利配置成功:
ping Master -c 5
ping Slave -c 5

4. 配置SSH免密登陆
首先需要明白,为什么需要配置ssh免密登录?
1. 配置完免密后,执行scp时不需要输入密码,方便快捷,非主要原因;
2. 集群安装完成后,通常在master节点执行start-all.sh脚本来启动整个集群,脚本会ssh到各个slave节点来执行启动命令。如果没有配置免密登录,那么启停集群时要手动输入很多密码,这是主要原因。
SSH的工作原理:
1. A服务器使用 ssh-key-gen 命令生成密钥对(一对秘钥,公钥和私钥);
2. 将A服务器的公钥copy给B服务器保存起来,这个过程叫做授权;
3. 授权完成后,A服务器再访问B服务器时,会携带着用私钥加密过的数据;
4. B服务器接收到请求数据后,使用公钥解密;
5. B服务器将解密成功的信息通过公钥加密后返回给A服务器;
6. A服务器接收到数据后,使用私钥解密,解密成功后,登录成功。
首先利用 ssh-keygen 生成密钥,并将密钥加入到授权中:
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat id_rsa.pub >> authorized_keys # 加入授权
完成后可执行 ssh Master 验证一下。没问题的话接着在 Master 节点将上公匙传输到 Slave1 节点:
scp ~/.ssh/id_rsa.pub root@Slave:/export/tmp_files/
接着在 Slave 节点上,将 ssh 公匙加入授权:
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat /export/tmp_files/id_rsa.pub >> ~/.ssh/authorized_keys
rm /export/tmp_files/id_rsa.pub # 用完就可以删掉了
如果有其他 Slave 节点,也要执行将 Master 公匙传输到 Slave 节点、在 Slave 节点上加入授权这两步。
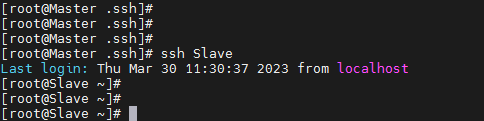
这样,在 Master 节点上就可以无密码 SSH 到各个 Slave 节点了,可在 Master 节点上执行如下命令进行检验,如下图所示:
5. 安装JAVA环境
将上传到服务器的JDK解压到指定目录,自己找个目录,比如 /export/server:
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /export/server
接着需要配置一下 JAVA_HOME 环境变量,我们直接在 /etc/profile 中进行设置并保存:
export JAVA_HOME=/export/server/jdk1.8.0_211 # 添加到文件末尾
export PATH=$PATH:$JAVA_HOME/bin
紧接着执行如下代码,让修改的环境变量生效:
source /etc/profile
查看修改是否生效:

6. 安装Hadoop
将上传到服务器的 hadoop 包解压到指定目录,可以和刚才的 JAVA目录保持一致:
tar -zxvf hadoop-3.3.1.tar.gz -C /export/server
chown -R root:root /export/server/hadoop-3.3.1/ # 修改文件属组
接着需要配置一下 HADOOP_HOME 环境变量,我们还是在 /etc/profile 中进行设置并保存:
export HADOOP_HOME=/export/server/hadoop-3.3.1 # 添加到文件末尾
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
紧接着执行如下代码,让修改的环境变量生效:
source /etc/profile
7. 修改Hadoop集群配置
- 核心配置文件 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://Master:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/server/hadoop-3.3.1/tmpvalue>
property>
configuration>
- HDFS配置文件 hdfs-site.xml
注意:
1. Hadoop 2.x 版本, 访问 HDFS 端口号为 50070;Hadoop 3.x 版本, 访问 HDFS 端口号为 9870
2. dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>Master:9870value>
property>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/export/server/hadoop-3.3.1/data/namenodevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/export/server/hadoop-3.3.1/data/datanodevalue>
property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-checkname>
<value>falsevalue>
property>
<property>
<name>dfs.client.use.datanode.hostnamename>
<value>truevalue>
property>
configuration>
- YARN 配置文件 yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>Mastervalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
- MapReduce 配置文件 mapred-site.xml,同时在里面配置历史服务器
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>Master:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>Master:19888value>
property>
configuration>
- 修改工作机器 workers文件(配置为从节点):有多少个从节点这里就添加多少个
# localhost # 集群数量足够多的话,可以不写这个 localhost,本人是因为只有一个从节点,所以把 Master 本机既当作NameNode又当做DataNode。
Slave
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个 Cluste 节点上。
8. 启动Hadoop
首次启动需要先在 Master 节点执行 NameNode 的格式化:
hdfs namenode -format # 首次运行需要执行初始化,之后不需要
接着可以启动 hadoop 了,启动需要在 Master 节点上进行:
start-all.sh # 开始所有进程
stop-all.sh # 关闭所有进程
正常启动后会有下面几个进程,可通过 jps 命令查看:
当进群数量足够的主节点进程:

本人的主节点(机器数量不够,只能既当 NameNode 又当 DataNode)进程:

从节点进程:

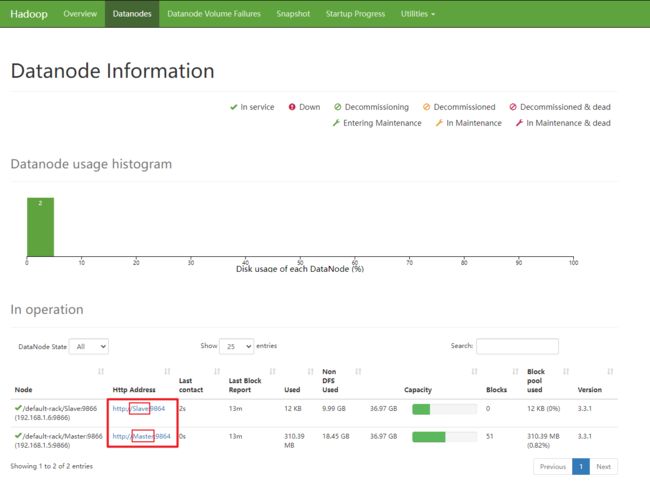
所以,Hadoop起来后,在前端页面看到的DataNode有两个。
安装过程中可能遇到的问题1:

解决:在 /export/server/hadoop-3.3.1/sbin 目录下,在 start-dfs.sh,stop-dfs.sh 这两个文件顶部添加以下参数:
HDFS_DATANODE_USER=root
HDFS_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh,stop-yarn.sh顶部也需添加以下参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
问题2:
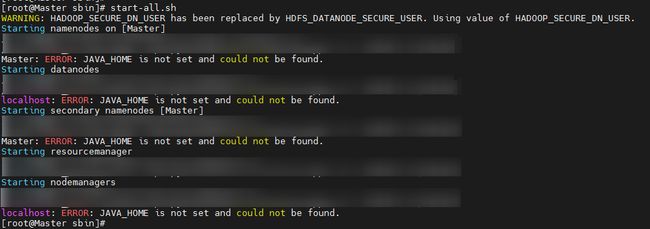
解决:修改配置文件 /export/server/hadoop-3.3.1/etc/hadoop/hadoop-env.sh:
export JAVA_HOME=/export/server/jdk1.8.0_211
解决完这两个问题后,重新执行 start-all.sh 文件即可。
9. 查看web页面
浏览器客户端访问: http://192.168.3.20:9870/

查看hdfs目录:http://192.168.3.20:9870/explorer.html
