大数据_数据中台_数据汇聚联通
目录
一、数据采集、汇聚的方法和工具
1、线上行为采集
2、线下行为采集
3、互联网数据采集
4、内部数据汇聚
二、数据交换产品
1、数据源管理
2、离线数据交换
3、实时数据交换
三、数据存储的选择
1、在线与离线
2、OLTP与OLAP
3、存储技术
构建企业级的数据中台第一步就是要实现各个业务系统的数据的互联互通,从物理上打破数据孤岛。主要通过数据汇聚和交换的能力来实现。在面对不同场景,根据数据类型、数据存储要求等进行不同方案的选择。
一、数据采集、汇聚的方法和工具
1、线上行为采集
①客户端埋点
全埋点:在终端设备上记录用户所有的操作行为,一般在内嵌SDK做一些初始化配置就可以实现全部收集行为的目的。也叫无痕埋点、无埋点等。优点:不用频繁升级,可获取全量数据 缺点:存储、传输成本高
可视化埋点:在终端设备上记录用户的一部分操作,一般通过服务端配置的方式有选择性的记录与保存。优点:不用频繁发布,成本比全埋点低,比较灵活;缺点:可能未收集到想要的数据,需要重新配置等
代码埋点:根据需求定制每次的手机内容,需要对相应终端模块进行升级。优点:灵活性强、可以单独设计方案,对对存储、带宽等可以做较多优化;缺点:成本高,维护难度大,升级周期长。
②服务端埋点
服务端埋点常见的形态有HTTP服务器中的access_log,即所有web服务的日志数据。优点:降低客户端的复杂度、提高信息安全;缺点:无法采集客户端不与服务端交互的信息。
2、线下行为采集
线下数据一般通过硬件采集,如Wifi探测针、摄像头、传感器等。
3、互联网数据采集
这种数据采集方式一般采用网络爬虫,使用一种按照既定规则自动抓取互联网信息的程序或脚本,常用来做网站的自动化测试和行为模拟。常见的网络爬虫框架:Apache Nutch 2、WebMagic、Scrapy、PhpCrawl等,互联网数据采集要遵守相应的安全规范、协议等
4、内部数据汇聚
①数据组织形式分类
结构化数据:规则、完整,能够用二维表来表现的数据,常见数据库、excel中的数据。
半机构化数据:数据规则、完整,但不能通过二维表来表现的数据,比如JSON、XML等复杂结构
非机构化数据:数据不规则、不完整,也不能通过二维表来表现,需要复杂的逻辑才能从中提取,如图片、图像、音频等。
②数据时效和应用场景分
离线:主要用于用户大批量数据的周期性迁移,对时效性要求不高,一般采用分布式批量数据同步的方式,通过连接读取数据,读取数据过程中可以有全量、增量的方式,通过统一处理后写入到目标存储。
实时:主要面向低延时的数据应用场景,一般通过增量日志或通知消息的方式实现,业界有canal,flink等方式来实现。
③ETL和ELT
ETL(Extract-Transform-Load,抽取-转换-存储),抽取过程中加工,优点:节省存储,简化后续处理 缺点:数据不全或丢失,处理效率低
ELT(Extract-Load-Transform,抽取-存储-转换),抽取完成后进行加工,优点:数据齐全,利用大数据等分布式后期处理效果更高 缺点:存储占用较大,无用数据太多可能会造成效率低
④常见数据汇聚工具
Canal:一种通过伪装自己为Mysql等slave,通过监控日志变动的数据推动工具。常作为mysql数据变动的数据收集工具,但其不适合多消费和数据分发场景。
Sqoop:通用的大数据解决方案,在结构化数据和HDFS之间进行数据迁移的工具,基于Hadoop的MapReduce实现。优势:特定场景,数据交换效率高。缺点:定制程度高,不易操作,并且依赖MapReduce,功能扩展性方面受到约束和限制。
DataX:阿里的一套插件式离线数据交换工具,它是基于进程内读写直连的方式。
二、数据交换产品
前面介绍的工具一般都只能满足一些单一的场景或者过程。为了满足复杂的企业数据交换场景,我们需要一个完整的数据交换产品,包含数据源管理、离线数据处理、实时数据处理等等。
1、数据源管理
数据源的管理主要是管理数据所用的存储,用于平台在做数据交换时,可以方便地对外部存储进行相应的管理。
数据源的分类:
关系型数据库:如Oracle、Mysql、SQL Server、Creenplum等
NoSQL存储:如HBase、Redis、Elasticsearch、Cassandra、MongoDB、Neo4j等
网络及MQ:如Kafka、HTTP等
文件系统:如HDFS、FTP、OSS、CSV、TXT、EXCEL等。
大数据相关:如HIVE、Impala、Kudu、MaxCompute等
2、离线数据交换
离线数据交换时针对数据时效要求低、吞吐量大的场景,解决大规模数据的批量迁移问题。
离线数据同步技术的亮点:
①前置稽核
②数据转换
③跨集群数据同步
④全量同步
⑤增量同步
3、实时数据交换
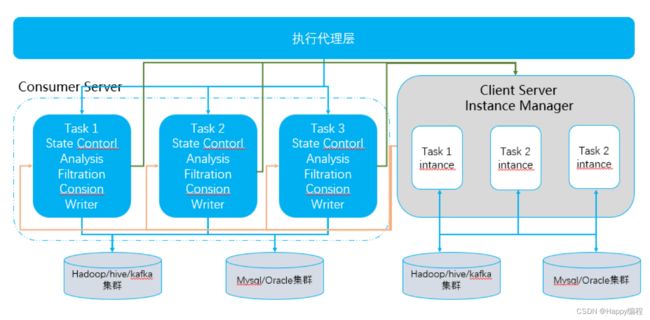
实时数据交换主要负责把数据库、日志爬虫等数据实时接入Kafka、Hive、Oracle等存储中。其两个核心服务为:数据订阅服务(Client Server)、数据消费服务(Consumer Server)。
实时交换架构图示例:
三、数据存储的选择
数据的存储我们一般要考虑数据的规模、数据生产方式以及数据的应用方式,通过方面综合考虑。
1、在线与离线
在线存储是指存储设备和所存储的数据时刻保持“在线状态”,可供用户随意读取,满足计算平台对数据访问的速度要求。在线存储一般为磁盘、磁盘阵列、云存储等。
离线存储是为了对在线存储的数据进行备份,已防可能发生的数据灾难。离线存储的数据不会经常被调用。常见的典型产品是硬盘、磁带和光盘等。
2、OLTP与OLAP
OLTP和OLAP他们并不是竞争或互斥关系,而是相互协作,合作共赢。
| OLTP |
OLAP |
|
| 用户 |
面向操作人员,支持日常操作 |
面向决策人员,支持管理需求 |
| 功能 |
日常操作处理 |
面向分析 |
| DB设计 |
面向应用,事务驱动 |
面向主题,分析驱动 |
| 数据 |
当前的、最新的、细节的、二维的、分立的 |
历史的、聚集的、多维的、集成的、统一的 |
| 存取 |
可更新,读/写数十条记录 |
不可更新的,但周期性刷新,读上百万条记录 |
| 工作单位 |
简单的事务 |
复杂的查询 |
| DB大小 |
100MB到GB级 |
100GB到TB级别 |
3、存储技术
1、分布式系统
分布式系统常见包括分布式文件系统(存储系统需要多种技术的协同工作,其中文件系统为其提供最底层存储能力的支持)和分布式键值系统(用户存储关系简单的半结构化数据)
2、NoSQL数据库
NoSQL的优势,可以支持超大规模数据存储,灵活的数据模型很好支持web2.0应用,具有强大的横向扩展能力等,典型的有:键值数据库、列族数据库、文档数据库和图数据库等,如:HBASE、MongoDB等。
3、云数据库
云数据库是基于云计算技术的一种共享基础架构方法,是部署和虚拟化在云计算环境中的数据库。