hive中的SQL
第一章 查询语句基本语法
1.1 **Select***查询结构基本语法
下面是一个SQL查询语句的基本结构
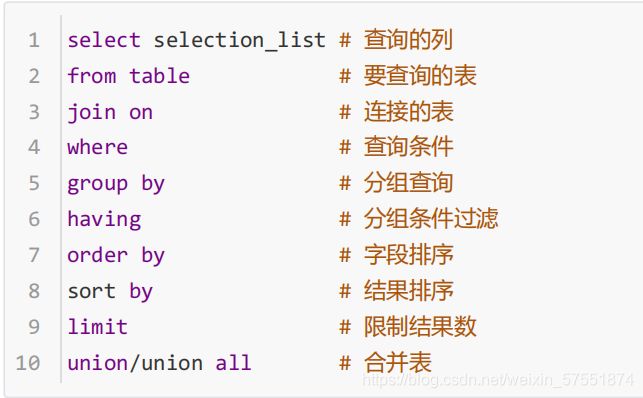
1.2 sql****语句的执行顺序


1.3 查询注意事项

1.4 数据库建模
关系型数据库最难的地方,就是建模(model)。
错综复杂的数据,需要建立模型,才能储存在数据库。所谓"模型"就是两样东西:实体
(entity)+ 关系(relationship)ER图。实体指的是那些实际的对象,带有自己的属性,可以理解成一组相关属性的容器。关系就是实体之间的联系,通常可以分成"一对一"、"一对 多"和"多对多"等类型。

第二章 Join****的语法与特点
2.1 表之间关系



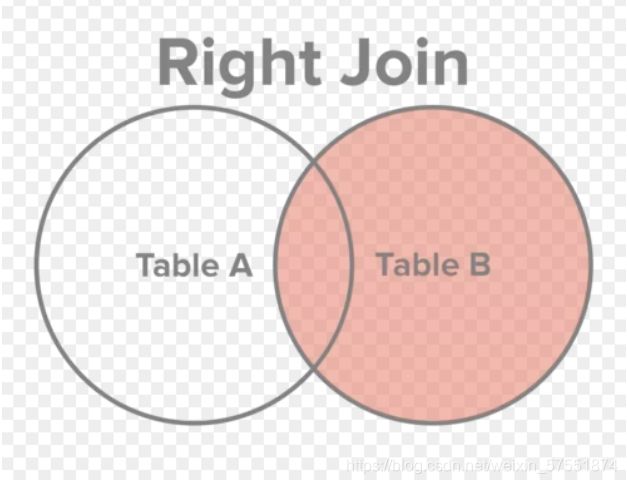





2.2 Join案例-语句特点演示
2.1.1 连接分类
类型:(left join \ left outer join)
right join right outer join inner join
full outer join
特殊类型:
left semi join
准备数据
请参照/data/u1.txt ,/data/u2.txt
2.2.2 建两张表
create table if not exists u1(
id int, name string
)
row format delimited fields terminated by ',';
create table if not exists u2(
id int, name string
)
row format delimited fields terminated by ',';
2.2.3 加载数据
load data local inpath '/opt/data/u1.txt' into table u1;
load data local inpath '/opt/data/u2.txt' into table u2;
2.2.4 内连接
使用关键字join 、 inner join 、 多表用逗号分开

2.1.1 左连接
数据以左表的数据为准,左表存在的数据都查询出,右表的数据关联上就出来,关联不上以
NULL代替

2.1.2 右连接
以右表为准,来匹配左表信息,如果匹配不上,使用NULL来代替。

2.1.3 全连接

2.3 Hive专有Join****特点
2.3.1 left semi join
在hive中,有一种专有的join操作,left semi join,我们称之为半开连接。它是left join的一种优化形式,只能查询左表的信息,主要用于解决hive中左表的数据是否存在的问题。相当于exists关键字的用法。

2.3.2 子查询
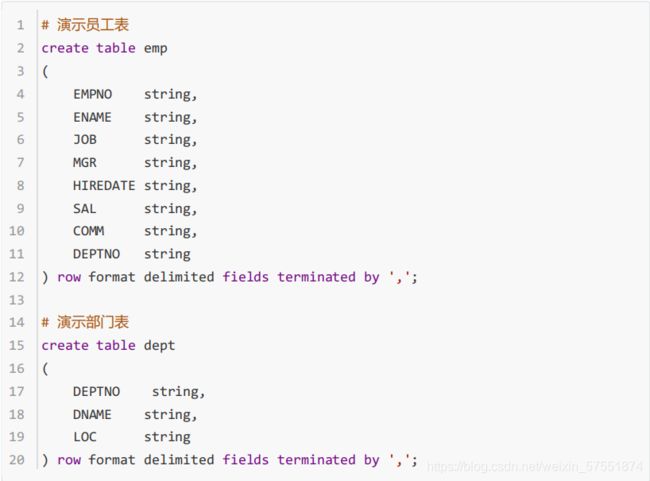
准备数据: 请参照

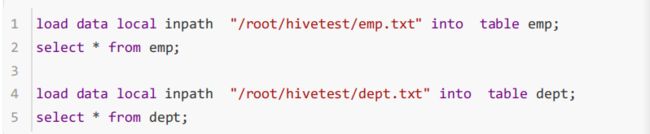
导入数据:


2.1.3 map-side join
如果所用的表中有小表,将会把小表缓存在内存中,然后在map端进行连接查找。hive在 map端 查找时会减小整体查询量,从内存中读取缓存的小表数据,效率较快,还省去大量数据传输和shuffle耗时
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UzUnFiid-1620306415558)(file:///C:\Users\梦却醉~1\AppData\Local\Temp\ksohtml16072\wps89.png)]



2.1.4 表达式别名
对有些表达式来说,查询的结果字段名比较难理解,这时候可以给表达式起一个别名,方便查看结果的表头.使用as把复杂表达式命名为一个容易懂的别名

*第三章 查询子句
3.1 Where****语句特点
where后不能跟聚合函数

3.2 Group By****语句特点
group by:分组,通常和聚合函数搭配使用
查询的字段要么出现在group by 后面,要么出现在聚合函数里面

3.3 Having****语句
Hiving是对分组以后的结果集进行过滤。

3.4 Limit****语句
限制从从结果集中取数据的条数,一般用于分页

3.5 排序
3.5.1 order by
![]()
3.5.2 sort by

3.5.3 distribute by
![]()
3.5.4 cluster by

3.5.5 排序详细区别


第四章 表合并 Union
如果把两张表 结果联合在一起,可以用union,有下面两种用法
union :将多个结果集合并,去重,排序
union all :将多个结果集合并,不去重,不排序。
下面是具体代码演示


第五章 数据类型
前面已经讲过基本数据类型,以下是复杂基本类型:
| 分类 | 类型 | 描述 | 字面量示例 |
|---|---|---|---|
| 复杂类型 | ARRAY | 有序的同类型的集合 | array(1,2) |
| MAP | key-value,key必须为原始类型,value可以任意类型 | map(‘a’:1,’b’:2) | |
| STRUCT | 字段集合,类型可以不同 | struct(‘1’,1,1.0), named_stract(‘col1’,’1’,’col2’,1,’clo3’,1.0) | |
| UNION | 在有限取值范围内的一个值 | create_union(1,’a’,63) |
5.1 特殊基本类型

简单数据类型创表案例***


5.2 复杂的数据类型
复杂类型分为三种,分别是 数组array,键值对map,和结构体struct

5.2.1 array****示例


5.2.1.1 列转行
就是把一列数据转化成多行,如下:

内嵌查询:
explode:展开
列表中的每个元素生成一行
select explode(score) score from arr1;
lateral view : 虚拟表
侧视图的意义是配合explode,一个语句生成把单行数据拆解成多行后的数据结果集。
解释:lateral view 会将explode生成的结果放到一个虚拟表中,然后这个虚拟表会和当前表
join,来达到数据聚合的目的。
结构解析:要进行聚合的虚拟表,lateral view explode(字段) 虚拟表名 as 虚拟表字段名
select name,cj from arr1 lateral view explode(score) score as cj;
统计每个学生的总成绩:
select name,sum(cj) as totalscore from arr1 lateral view explode(score) score as cj group by name;
5.2.1.2 行转列
就是把多行数据转化成一行数据:
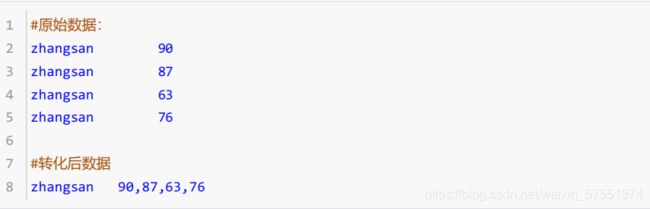
准备数据**:

collect_set****函数:
它们都是将分组中的某列转为一个数组返回

将数据写成array格式:

5.2.2 map****示例
有数据如下:

创建map类型的表

加载数据
load data local inpath '/root/hivetest/map1.txt' into table map1;
Map格式数据查询

5.2.2.1 Map列转行
使 用 上 面 的 数 据
explode展开数据
select explode(score) as (m_class,m_score) from map1;
Lateral view
Lateral View和split,explode等一起使用,它能够将一行数据拆成多行数据,并在此基础上对拆分后的数据进行聚合。

5.2.2.2 Map****行转列
准备数据:

创建临时表,并加载数据

创建要导入数据Map表

导入数据:

5.2.3 struct

5.1.1 复杂数据类型案例

#查询:下属个数大于4个,公积金小于1200,省份在河北的数据
create table if not exists tax
id int,
name string,
belong array,
tax map,
addr struct 9 )
row format delimited fields terminated by ' '
collection items terminated by ','
map keys terminated by ':'
stored as textfile; 14
# 导入数据
load data local inpath '/root/hivetest/tax.txt' into table tax; 18
#查询:下属个数大于4个,公积金小于1200,省份在河北的数据
select id,
name,
belong[0],
belong[1],
tax['wuxian'],
tax['shebao'],
addr.road
from tax
where size(belong) > 4 and
tax['gongjijin'] < 1200 and
addr.province = '河北'; 31
结果:
2 lkq lg lw 2000.0 300.0 河北 石家庄