Spark系列—spark简介
最近比较空,总结一下spark相关的知识。
一、Spark简介
spark是一种大规模数据处理的统一分析引擎,且基于内存计算的大数据并行计算框架。具有如下特性:
1、高效性
体现在内存存储中间计算结果,基于DAG图执行引擎的优化,减少多次中间结果写HDFS开销。
2、易用性
spark有丰富的API,且支持超过80种不同的Action算子和Transformation算子,如常见的collect、foreach、map、reduce、filter、groupByKey、sortByKey等。
3、通用性
spark以RDD为基础,形成自己的生态圈;集批处理、流计算、交互式SQL查询、图计算GraphX、机器学习于一身。
4、兼容性
spark可以读取多种数据源,如HDFS、Hbase、Mysql等,并且可以使用Hadoop的YARN作为它的资源管理和调度器。
二、Spark架构设计
spark集群是有Driver、Cluster Manager、Worker Node组成。结构如下图:
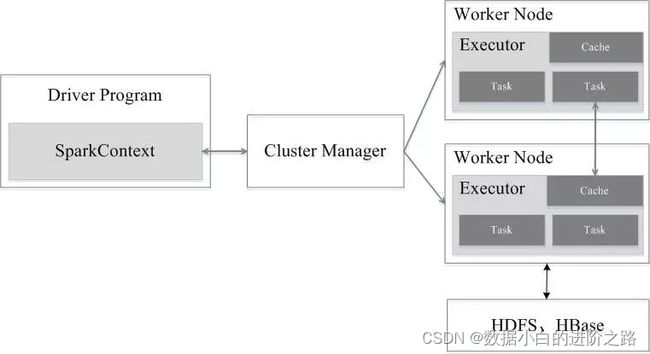
其中:
Driver主要包含如下功能:
- 负责向集群申请资源
- 向master注册信息
- 负责了作业的调度和解析
Cluster Manager是集群资源管理中心,负责给Executor分配计算资源;
Worker Node是工作节点,负责完成具体的计算;
三、运行流程
1、运行环境的搭建
首先Driver会创建一个SparkContext,负责资源的申请(向Cluster Manager)、任务的分配和监控。
2、Cluster Manager启动Executor进程,并且为Executor分配计算资源。
3、Spark Context根据RDD的依赖关系构建DAG图并分解成stage(通过DAGScheduler),然后一批TaskSet提交给底层调度器TaskScheduler处理。
4、Executor向Spark Context申请task,TaskScheduler将task发送到Executor运行,Executor是以stage为单位执行task,期间Driver会监控任务运行状态。
5、Driver收到Executor任务完成的信号后会向Custer Manager发送注销信号;然后Custer Manager向Work Node发送注销信号;Work Node对应的Executor停止运行,并进行资源的释放。

四、Spark基本概念
RDD:
rdd是弹性分布式数据集的简称,是spark中的基本数据抽象,它代表一个不可变、可分区、里面元素可并行计算的集合。
DAG
是Directed Acyclic Graph(有向无环图)的简称,主要反映RDD之间的依赖关系。
Driver Program
控制程序,负责为用户提交的Application构建DAG图。
Cluster Manager
集群资源管理中心,负责为Executor分配计算资源。
Worker Node
工作节点,负责完成具体计算。
Executor
是运行在工作节点(Worker Node)上的一个进程,负责运行Task,并为应用程序Application存储数据。
Application
用户编写的Spark应用程序,其中一个Application包含多个job。
Job
作业,一个Job包含多个RDD及作用于相应RDD上的各种操作
Stage
是作业的基本调度单位,一个job(作业)会分为多组任务,每组任务被称为“阶段”。stage是一个TaskSet,将stage根据分区数可以划分为一个个的Task。
Task
任务,运行在Executor上的工作单元,是Executor中的一个线程。
一句话描述以上名词之间的关系:
用户提交的Application由多个Job组成,Job由多个Stage组成,Stage由多个Task组成。Stage是作业调度的基本单位。