复杂任务也不怕!上海AI Lab提出增强型LLM框架—ControlLLM,大模型可操控多模态工具
多模态交互的一个新兴的实现方式是工具增强语言模型,这些模型将大型语言模型(LLM)作为主要控制器,并将具有不同功能的工具作为插件进行整合。这有助于解决各种多模态任务,并为多模态交互中的创新应用打开了大门。
尽管 LLM 的性能令人瞩目,但由于用户提示的歧义、工具选择和参数化的不准确性以及工具调度的低效性,它们仍然面临工具调用的困难。目前一些方法基于的假设是每个子任务最多只有一个前置任务,这对于现实世界的应用来说不够,特别是对于通常需要多个输入的多模态任务。
为了克服这些挑战,这篇文章主要探讨了一种新颖框架 ControlLLM,该框架使 LLM 能利用多模态工具来解决复杂的现实世界任务。ControlLLM 在涉及图像、音频和视频处理的各种任务上的评估证明了其相比现有方法具有更高的准确性、效率和多功能性。
论文题目:
ControlLLM: Augment Language Models with Tools by Searching on Graphs
论文链接:
https://arxiv.org/abs/2310.17796
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):(https://gpt4test.com)
文章速览
框架包括三个关键组成部分:任务分解器、Thoughts-on-Graph(ToG)范式和执行引擎。
-
任务分解器:将复杂任务分解为具有明确定义的输入和输出的清晰子任务。
-
ToG 范式:在预构建的工具图上搜索最优解路径,该图指定了不同工具之间的参数和依赖关系。
-
执行引擎:有丰富的工具箱,解释解决路径并在不同的计算设备上高效运行工具。

▲图1 不同任务规划范式的比较
ControlLLM 框架旨在帮助大型语言模型 LLM 准确高效地控制多模态工具,并为涉及多模态输入的复杂现实世界任务提供全面的解决方案。该框架特别强调任务分解、任务规划和解决方案执行三个方面。
-
任务分解:将复杂的任务分解为可管理的子任务
-
任务规划:处理工具选择和工具参数分配
-
解决方案:执行部分则负责执行解决方案并将输出返回给用户
ControlLLM
如图 2 所示,该框架包括四个连续的阶段:任务分解、任务规划、解决方案执行和回复生成。
-
第一阶段是任务分解,将用户输入解析成几个子任务。
-
第二阶段,ToG利用深度优先搜索算法为每个子任务找到最佳解决方案。
-
最后阶段的执行引擎执行解决方案并将输出返回给用户。
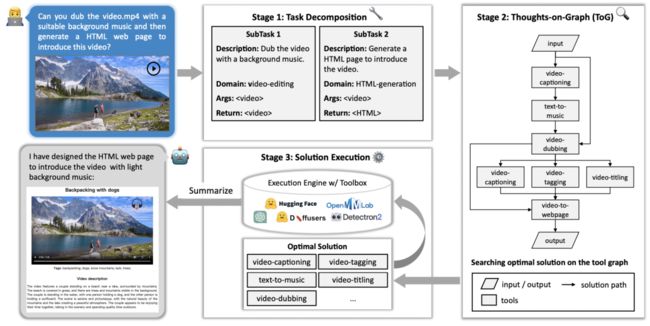
▲图2 ControlLLM 的系统设计
任务分解
ControlLLM 从任务分解开始,这是将用户提问分解成一系列并行子任务的阶段,可以利用语言模型来自动分解用户提问。任务分解的结果以 JSON 格式呈现,如表 1 所示。

▲表1 详细说明任务分解输出协议中的每个字段
这个阶段的目标是实现三个目标:
-
将用户提问分成更小、更易处理的单元,即子任务,从而加速任务规划。
-
它寻求确定与给定问题最相关和适当的搜索域,从而进一步缩小搜索空间。
-
努力从指令的上下文中推断出输入和输出资源类型,以确定 ToG 搜索的起始和结束节点。
使用 Thoughts-on-Graph 进行任务规划
这个阶段构成了整个系统的核心。作者根据任务分解的结果,设计了 Thoughts-on-Graph(ToG)范式,以启发式地在图上找到解决方案。
构建工具图
作者观察到,不同工具的输入和输出之间存在明显的拓扑结构,因此作者提出基于邻接矩阵构建工具图,作为分析和优化工具与资源之间相互作用的基本模块。
在工具图中,资源节点和工具节点是两种主要的元素。
-
资源节点:定义为一个元组,其中“类型”表示资源的具体类型。
-
工具节点:表示为一个三元组,包含描述、参数和返回值,这些元素都对理解工具的功能有重要意义。工具图中的边复杂地连接节点,突出不同工具之间的关系。
-
在图中定义了两种类型的边,分别是工具-资源边和资源-工具边。
通过建立这个图表,可以使用多样的搜索策略来做出关于工具选择、输入资源分配和工作流优化的明智决策。
在图上搜索
如算法 1 所示,在图上的解决方案搜索算法是建立在深度优先搜索(DFS)算法之上的。搜索到的解决方案是一系列工具,它们将输入资源作为输入并返回输出资源以完成用户提问。

为了在时间和空间复杂度之间找到一个折衷方案,研究者开发了一个工具评估模块,其中语言模型被利用来对每个搜索步骤中的工具进行评分,然后过滤掉一些不相关的工具。
通过这个评估模块,作者设计了四种搜索策略(贪婪策略、束搜索策略、自适应策略、穷尽策略),来确定在图上搜索时,在所有相邻节点中访问哪些“任务域”内的工具节点。
解决方案专家
解决方案专家能够简化从所有可能的候选方案中评估和选择最佳解决方案的过程。通过将每个解决方案系统地转化为格式化的字符串描述,并利用提示工程的能力,使我们能够根据评估分数做出明智的决策。
资源专家
在算法 1 中,作者遇到了一个挑战,即可用资源列表中可能存在多个相同资源类型的情况。为了解决这个复杂性,研究者设计了一个资源专家。这个模块将完成缺失参数的任务转化为填空练习。为实现这一目标,资源专家制定提示,不仅包括任务描述,还包括可用资源列表。
解决方案执行
在生成任务解决方案之后,它们会被传递给一个工具引擎进行执行。在这个阶段,执行引擎首先将解决方案解析为一系列动作。每个动作都与特定的工具服务相关联,这些工具服务可以通过手工制作的映射表或基于某些策略的自动调度器来实现。
解析动作是由解释器执行的,该解释器能够自动将动作分派到本地、远程或混合端点。参考HuggingGPT的设计,多个独立的子任务将并行执行以提高效率。解释器维护一个状态内存,用于存储所有中间结果,包括它们的值和类型。这种设计使得动作参数能够在运行时自动纠正。
在所有执行结果完成后,可以对用户的提问做出回复。为了提高回复的全面性和清晰度,作者引入了一个额外的阶段来汇总所有的执行结果并生成用户友好的回复。这是通过向 LLM 提示用户提问、操作列表和执行结果,并要求它们智能地总结答案来实现的。
语言模型的选择
作者设计了一系列精心设计的提示,通过上下文学习进行任务分解、工具评估、解决方案专家和资源专家。
在语言模型的选择上,可以选择使用现成的 LLM,如 ChatGPT 和 Llama 2。
-
优点:它们具有强大的 zero-shot 能力,并且不需要从头开始训练语言模型。
-
缺点:它们可能会导致性能较低,因为它们没有针对我们的要求进行训练。
另一种选择是通过使用 Self-Instruct 方法来微调语言模型,例如 LLaMA。
-
优点:可以通过适应数据和任务来实现高性能。
-
缺点:需要计算资源来训练模型,并且可能会遇到过拟合或数据稀缺的问题。
实验
在实验部分,作者设计了一套基准测试,涵盖了问题回答、图像生成、图像编辑、图像感知、视觉问题回答等多个任务领域。这个基准测试中,这些任务涉及了超过20种不同模态的工具。
采用众包评估方法,通过一个简单的协议与三位注释专家合作。这个协议将评估分解为三个主要方面:工具选择、论证推理和整体评估。
作者还对 ControlLLM 进行了全面的分析,如表 2 显示,ControlLLM 框架支持更多的功能,有助于提高多模式交互的用户体验,这证明该框架具有很高的可扩展性。
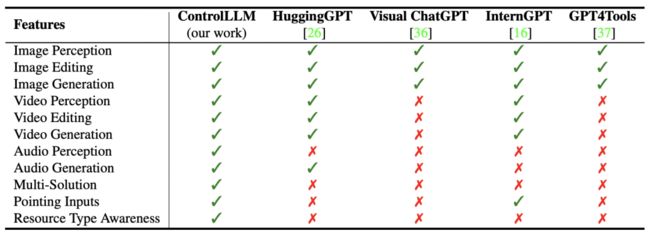
▲表2 不同方法之间功能的比较
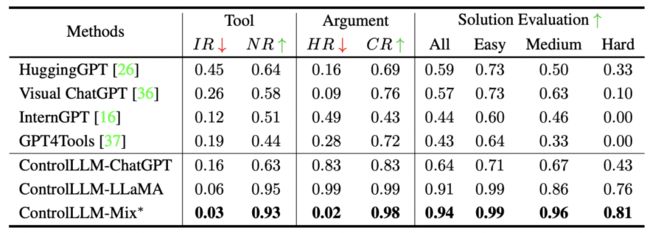
▲表3 与其他最先进的方法相比
总结起来,ControlLLM 在工具选择、论证推理和整体解决方案的有效性方面表现出色。
消融实验
首先,在任务分解过程中,作者研究了将先前的知识融入子任务描述的影响。如表 4 结果显示,先前的知识确实提高了必要工具的包含率,并降低了使用相同的大型语言模型时选择不相关工具的机会。此外,语言模型的能力在工具选择中起到决定性的作用,语言模型越强大,解决方案评估的得分就越高。
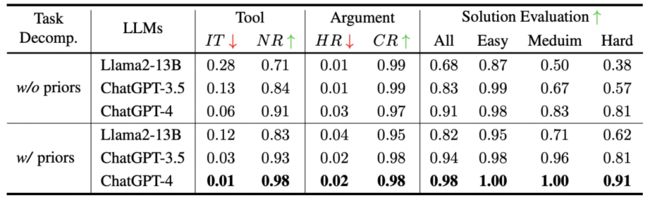
▲表4 关于不同 LLM 的任务分解效果
其次,研究了搜索策略的影响。如表 5 所示,虽然详尽的策略在大多数指标上表现最佳,但自适应策略在效率和效果之间取得了良好的平衡。为了在时间和准确性之间进行权衡,作者选择自适应策略作为默认的搜索策略。
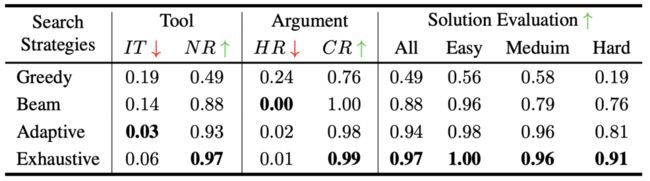
▲表5 不同搜索策略的评估
案例研究
本文方法能够生成更多样化的解决方案,以满足用户的期望,这要归功于所提出的 ToG 范式。在图 3 中,使用两个简单案例来说明任务规划中两种不同方法之间的差异。在这里,每个输出节点都是由不同的解决方案路径生成的。
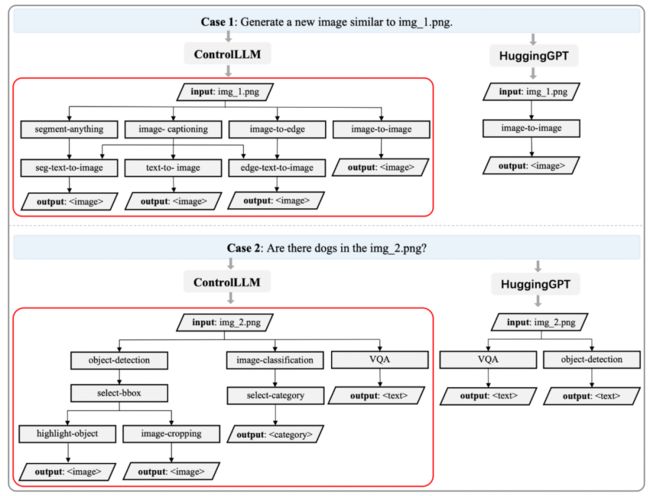
▲图3 任务规划的比较
作者还展示了一些图像感知的案例,这涉及分析和理解图像内容、图像处理和图像编辑、图像问题回答和图像生成,以及在任务规划过程中通过 ToG 搜索的解决方案在复杂场景中的能力等。这些任务需要系统调用工具来处理视觉信息,并从图像中提取相关特征和标签。
▲图4 不同任务领域的案例研究
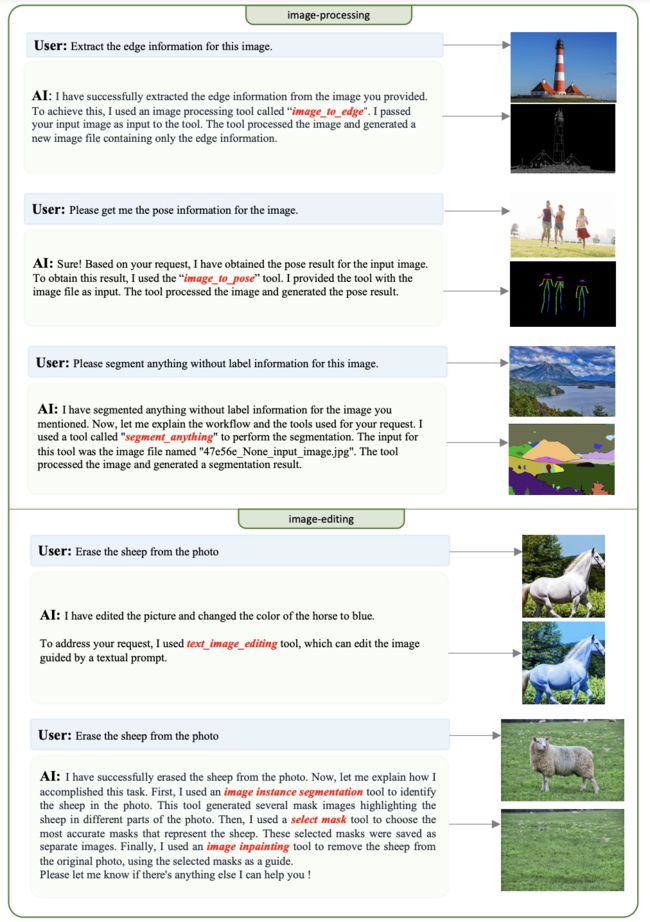




这些图表展示了 ControlLLM 在简单和复杂情景下的任务规划能力,从而实现更好的用户体验。
总结
作者提出了 ControlLLM,这是一个多模态交互框架,可以准确地控制在各个领域中的工具使用,包括文本、图像、音频、视频等。
它具有几个优点:
-
能够准确处理涉及多模态输入和输出的复杂现实任务
-
减少自然语言中的歧义问题的影响
-
克服 LLM 在任务规划过程中的 token 限制
-
工具箱易于扩展。
然而,这项工作仍然存在一些局限性:
-
由于这项工作的目标是提高工具使用的准确性,即使解决方案可行,也不能保证工具的输出能够满足人类的期望。
-
另一方面,由于自然语言中固有的歧义,很难确保所选的最佳解决方案与用户的目标一致。这种情况下,如果最佳解决方案失败,只能为用户提供由 ToG 搜索到的更多备选解决方案供选择。
最后,ControlLLM 为 LLM 能够跨不同模态,使用各种工具来解决现实世界中的复杂任务提供了可能,这项工作为多模态交互领域的研究和发展提供了有价值的贡献。