Java线程池
文章目录
-
-
-
- 线程池主要作用
- 自定义线程池
- 线程执行流程
- 线程池实践建议
- 动态配置线程数
- 线程池监控
-
-
线程池主要作用
- 提供了较好的性能,创建和销毁线程是需要的开销的,线程池的线程是可以复用的
- 线程池提供了一种资源限制和管理的手段
自定义线程池
线程池核心类ThreadPoolExecutor,构造方法如下:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
corePoolSize: 核心线程数,定义最小可以同时运行的线程数量。maximumPoolSize:运行的最大线程数目,当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,任务就会被存放在队列中。常用的队列ArrayBlockingQueueLinkedBlockingQueuekeepAliveTime:当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁。unit:keepAliveTime参数的时间单位。threadFactory:executor创建新线程的时候会用到。handler(RejectedExecutionHandler):拒接策略,如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,需要如何处理的问题。ThreadPoolExecutor.AbortPolicy: 抛出RejectedExecutionException来拒接新任务的处理。ThreadPoolExecutor.CallerRunsPolicy:用调用者所在的线程来执行任务,这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。ThreadPoolExecutor.DiscardPolicy: 不处理新任务,直接丢弃掉。ThreadPoolExecutor.DiscardOldestPolicy: 此策略将丢弃最早的未处理的任务请求。
@Configuration
public class ThreadPoolConfig {
/**
* CPU密集型
*/
public static int CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() + 1;
/**
* IO密集型
*/
public static int IO_CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2;
/**
* 工作队列长度
*/
public static int MAX_QUEUE_SIZE = 1000;
@Bean(name = "qmqWorkerExecutor")
public ThreadPoolExecutor qmqWorkerExecutor() {
// 初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
ThreadFactory factory = new ThreadFactoryBuilder()
.setNameFormat("qmq-worker-%d").build();
return new ThreadPoolExecutor(CORE_POOL_SIZE, 20,
1, TimeUnit.MINUTES,
new LinkedBlockingQueue<>(MAX_QUEUE_SIZE), factory,
new ThreadPoolExecutor.CallerRunsPolicy());
}
}
线程执行流程
整体的流程
- 核心线程池
- 等待队列
- 最大线程池
- 按照饱和策略处理
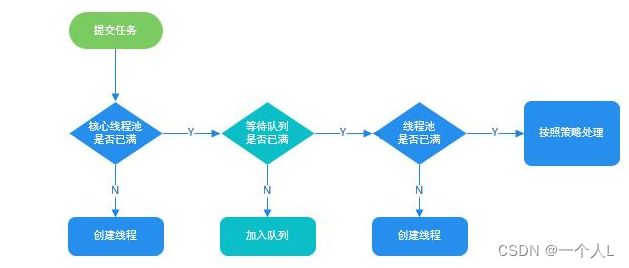
线程池实践建议
- 线程大小定义
- CPU 密集型任务(N+1): 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- I/O 密集型任务(2N): 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
- 建议不同类别的业务用不同的线程池
一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重新优化系统性能瓶颈相关的业务。 - 给线程池的线程命名
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
动态配置线程数
借助nacos的配置中心可以简易实现线程池参数的动态配置。
- 引入nacos-config模块,实现配置动态刷新,此外还需要借助第三方jar包,对动态配置进行监听
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-configartifactId>
dependency>
<dependency>
<groupId>com.purgeteamgroupId>
<artifactId>dynamic-config-spring-boot-starterartifactId>
<version>0.1.0.RELEASEversion>
dependency>
- 线程池参数作为配置,ThreadPoolExecutor提供公有set方法
public void setCorePoolSize(int corePoolSize) {
...
}
public void setMaximumPoolSize(int maximumPoolSize) {
...
}
- 简易实现代码
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import com.purgeteam.dynamic.config.starter.event.ActionConfigEvent;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.ApplicationListener;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
@Component
public class DynamicExecutorFactory implements ApplicationListener<ActionConfigEvent> {
private static final Logger log = LoggerFactory.getLogger(DynamicExecutorFactory.class);
private static ThreadPoolExecutor executor;
@Value("${task.coreSize}")
private String coreSize;
@Value("${task.maxSize}")
private String maxSize;
public DynamicExecutorFactory() {
if (coreSize == null) {
coreSize = "2";
}
if (maxSize == null) {
maxSize = "2";
}
init(Integer.parseInt(coreSize), Integer.parseInt(maxSize));
}
private void init(int corePoolSize, int maximumPoolSize) {
log.info("init core:{},max:{}", corePoolSize, maximumPoolSize);
if (executor == null) {
synchronized (DynamicExecutorFactory.class) {
executor = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, 60L, TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(50),
new ThreadFactoryBuilder().setNameFormat("my-thread-%d").build(),
new ThreadPoolExecutor.CallerRunsPolicy());
}
}
}
public ThreadPoolExecutor getExecutor() {
return executor;
}
@Override
public void onApplicationEvent(ActionConfigEvent event) {
log.info("接收事件");
log.info(event.getPropertyMap().toString());
for (Map.Entry<String, HashMap> entry : event.getPropertyMap().entrySet()) {
if ("task.coreSize".equals(entry.getKey())) {
HashMap value = entry.getValue();
String after = value.get("after").toString();
String before = value.get("before").toString();
executor.setCorePoolSize(Integer.parseInt(after));
log.info("修改核心线程数 before={},after={}", before, after);
}
if ("task.maxSize".equals(entry.getKey())) {
HashMap value = entry.getValue();
String after = value.get("after").toString();
String before = value.get("before").toString();
executor.setMaximumPoolSize(Integer.parseInt(after));
log.info("修改最大线程数 before={},after={}", before, after);
}
}
}
}
线程池监控
…