redis缓存击穿 穿透
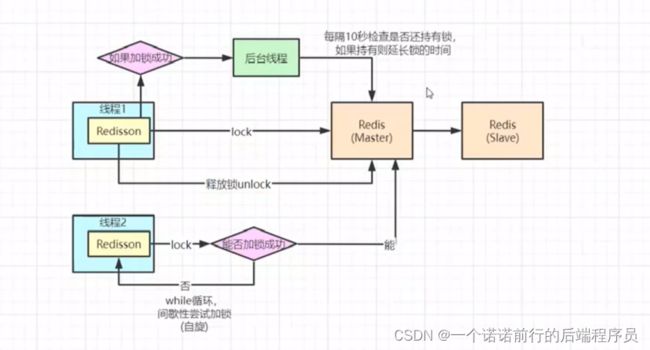
我们之前写了一把分布式锁 并且用redis写的,
redis内部实现是比较完善的,但是我们公司用的时候 redis 至少都是主从,哨兵,cluster
很少有单机的
呢么我们分布式锁基于集群问题下会有什么问题
比如说当第一个线程设置一个key过来进行加锁,加锁成功后,就执行业务了,redis从主节点到从节点的
同步默认是异步的,如果说我主节点刚写成功,准备吧key同步给从节点,这个时候主节点挂了
此时从节点变成新的主节点,或者说他多个从节点会过来进行选举,来选举一个新的master,新的主节点中是没有key的,它也可以加锁成功,这种情况下又超卖了
redis 主从或者集群,会有这么个问题,他的锁有一种情况下会失效
zk也是集群架构,比如说3个节点组成的集群架构,也可使实现分布式锁,他也有leader和follow节点
对于zk实现分布式锁,他是有一些区别的,如果是redis集群的话,从CAP角度来说
redis满足的更多的是ap,也就是他满足的是可用性,他满足的是多一些
zk满足的是cp,他对数据的一致性要求高一些
怎么体现的?
比方说我要基于zk实现分布式锁,我也要实现key value
他也是leader节点才可以写数据,假设这个分布式锁的key 写在了leader节点 他并不会马上给你返回
加锁成功,他会进行数据同步,如果同步成功(他会进行过半机制的校验) 比如说3个节点同步2个
才算成功,有半数以上的节点写入key 成功,我们这个zk才算是加锁成功,才会返回给主线程是加锁成功的
主从切换的 过程中导致锁key丢失的问题,呢我到底使用redis还是zk实现分布式锁
zk性能肯定不如redis,如果你对性能有要求的话 就用redis,
主从节点切换锁失效
可以使用redLock

redLock 我们要加一把锁的话 一般来说我们要搞多个redis节点,一般来说搞基数个redis节点 比方说此时搞3个我们要加锁的话,我们set key会发到3个节点上,我客户端至少要收到整个集群节点的半数以上返回OK,也就是说设置分布式锁成功的节点我才会认为你加锁成功
因为这个半数机制存在,再来一个客户端的话 任何一种情况下都不会加锁成功,和zk差不多 也就是我要保证数据一致的话 我可以牺牲一点可用性,我要在多个节点中写锁的话 实际上是对我的可用性有影响的
相对来说可用性上面有一点点延迟 但是这么来说 他的好处,数据一致性会高一些
红锁不推荐用的,如果说都给redis加个从节点 为了高可用,因为红锁的三个redis是互不相干的
比如说redis1万一挂了没有关系,从节点会顶上去变成主节点,这个时候从节点是没有Key信息的
此时还是会有锁失效的问题产生的
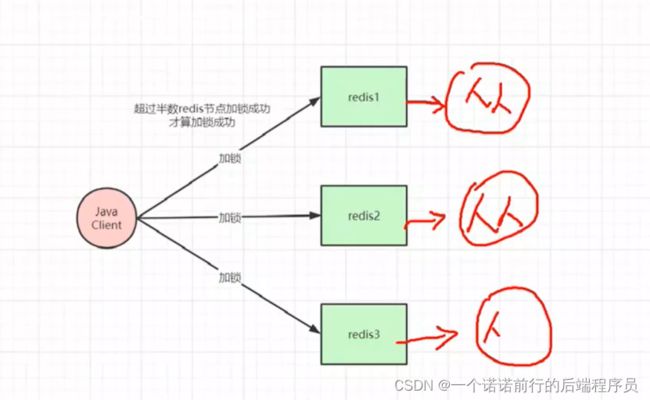
如果不搞从节点就不会出现问题,红锁的话 如果挂了半数以上节点 此时这个锁就会加不成功
红锁或者zk有一个缺点就是我就加一把锁性能就会降低,按照我们刚才说的
如果节点过多的情况下,加一把锁的话就会往更多的节点发送加锁请求,此时性能就会降低吧
红锁不能解决锁丢失的问题
只不过他丢失锁的概率会小一点点 但是他带来的后果就是 他的性能会损失一些
还不如基于zk 来做,所以redLock是有问题的
大促场景下 提升分布式锁性能的问题
分布式锁帮我们解决并发设计的思想是什么,利用redis单线程进行的串行化实现的
我们优化分布式锁比如说 我们要考虑锁的粒度,越小越好,我们加锁的范围肯定是越小越好
第二我们可以利用分段锁类似于currentHashMap来进行分段存储
缓存架构
中小型公司利用redis作为缓存,放到缓存中的,比如说基于缓存做的crud
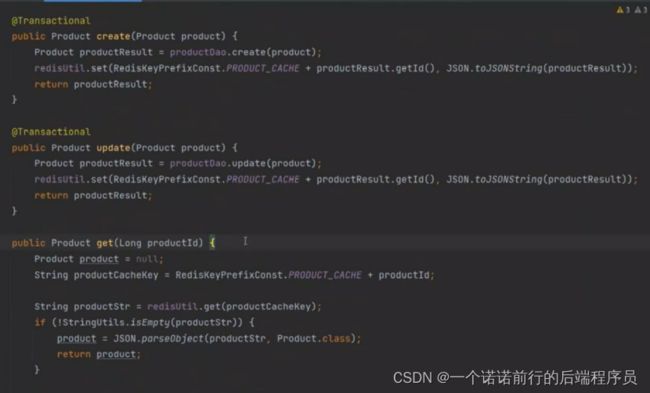
creat 的之后丢到缓存中
新增或者更新商品的时候 都要维护redis的缓存
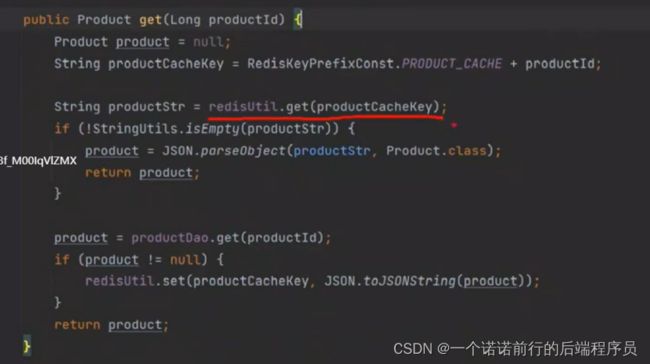
get 的时候先从redis缓存中去取,没有再去从数据库中拿到,之后放到redis缓存
但是如果并发量大的话 就会有redis 缓存问题
如果在高并发情况下有什么问题,例如京东
后台商品很多,我的redis 里面会有很多缓存,呢么我的redis容量要很大
呢对于我们redis,整个线上数据上亿,你丢到redis中对我们redis存储容量是很大的
我们真正的电商网站 真正高频访问的电商不到1%.大量商品都是冷门商品
我没有必要吧很少去访问的商品也丢到缓存浪费我们的资源
其实我们真正用缓存的目的是尽可能吧经常访问的 热点缓存 尽量在缓存中多呆一会
冷门数据 不用一直呆在缓存中,丢缓存的时候 放个时间

所以我们set的时候在里面放个缓存失效时间,如果get的时候 能get到的话 我们就给他续时间
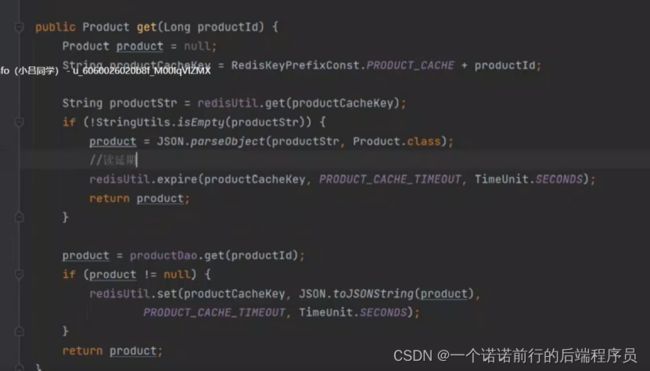
这样的话,不怎么访问的冷门商品在缓存中存储1天就失效了
对于我们一直在访问的商品,尽可能的一直呆在缓存中 这样会对我们数据库的请求会大大减少
呢所以在查询缓存,做一个读取延期,如果我这么来做的话,对于每天都来访问的商品会一直在我们缓存中
那些不怎么访问的商品可能也就上架完毕就不在缓存中,实际上我就实现了数据的冷热分离,热点数据我尽可能的留在缓存中.对于冷门的数据,不会在缓存中简单方案的冷热数据分离,大规模数据我们要做一些数据的冷热分离,让热数据尽可能丢到缓存,而且要常驻缓存,冷数据可能要查数据库的,呢么数据库就可以给其他模块用了
比如说大V带货这种场景,冷门突然被发现
冷门商品几万个请求来调用这里直接打到db了,冷门数据突发变为热点数据,大量请求对我们突发性的数据重建缓存,我们可以加锁进行重建 比如说有一个线程进行放缓存的操作
呢么多个节点的web应用集群这么再每一个web服务器上都要重建一次
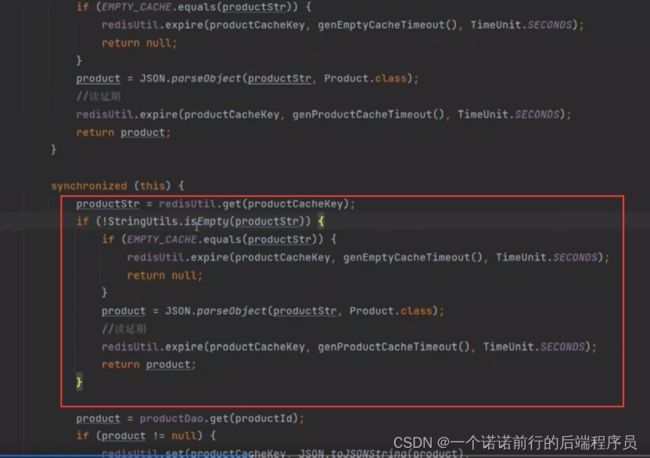

我们这个时候可以利用redis分布式锁进行重建 基于什么商品加的锁啊

https://blog.csdn.net/qq_44377709/article/details/123411590
redis中实现mq的三种方式
Lru算法 lua
redis中数据删除的策略