强化学习之策略迭代和价值迭代(gym)
前言 —— 基于动态规划的强化学习

一、策略迭代
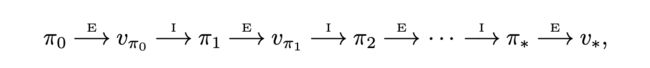
1.1 伪代码

1.2 基于冰湖环境的代码
实验环境及介绍:FrozenLake8x8-v0
import gym
import time
import numpy as np
def policy_evaluation(env, value_table, policy, gamma=0.9, threshold=1e-4):
delta = 2 * threshold
while delta > threshold:
# 1.存储旧的value表
new_value_table = np.zeros(env.nS) # 此处不能用np.copy(value_table),因为更新V(s)用的是+=,所以若不置零则无限加和不收敛
for state in range(env.nS):
# 从当前state提取策略对应的action
action = policy[state] # 可能会由于随机选择的动作不包含奖励=1的动作而得到无更新的new_value_table
# 2.更新V(s)
for prob, next_state, reward, done in env.P[state][action]:
new_value_table[state] += prob * (reward + gamma*value_table[next_state])
delta = sum(np.fabs(new_value_table - value_table))
value_table = new_value_table
return value_table
def policy_improvement(env, value_table, policy, gamma=0.9):
while True:
# 1.存储旧policy
old_policy = np.copy(policy)
for state in range(env.nS):
action_value = np.zeros(env.nA)
for action in range(env.nA):
for prob, next_state, reward, done in env.P[state][action]:
action_value[action] += prob * (reward + gamma*value_table[next_state])
# 2.更新最优policy
policy[state] = np.argmax(action_value)
if np.all(policy == old_policy): break
return policy
def policy_iteration(env, iterations, gamma=0.9):
env.reset()
start = time.time()
# 初始化策略-随机策略 (16个状态下的[0,4)策略)
policy = np.random.randint(low=0, high=env.nA, size=env.nS)
# 初始化value表 (初始化0)
value_table = np.zeros(env.nS)
for step in range(iterations):
old_policy = np.copy(policy)
# 1.Policy Evaluation
value_table = policy_evaluation(env, value_table, policy, gamma)
# 2.Policy Improvement
policy = policy_improvement(env, value_table, policy, gamma)
# 3.判断终止条件
if np.all(policy == old_policy):
print('===== Policy Iteration ======\nTime Consumption: {}s\nIteration: {} steps\nOptimal Policy(gamma={}): {}'.format(time.time()-start, step+1, gamma, policy))
break
return value_table, policy
def play_game(env, policy, episodes=5, timesteps=150):
for episode in range(episodes):
state = env.reset()
for t in range(timesteps):
action = policy[state]
state, reward, done, info = env.step(action)
if done:
print("===== Episode {} finished ====== \n[Reward]: {} [Iteration]: {} steps".format(episode+1, reward, t+1))
env.render()
break
# 创建冰湖环境
env = gym.make('FrozenLake8x8-v0')
# 策略迭代
value_table, policy = policy_iteration(env, iterations=100000, gamma=0.9)
# 使用迭代计算得到的策略打游戏
play_game(env, policy, episodes=3)
env.close()
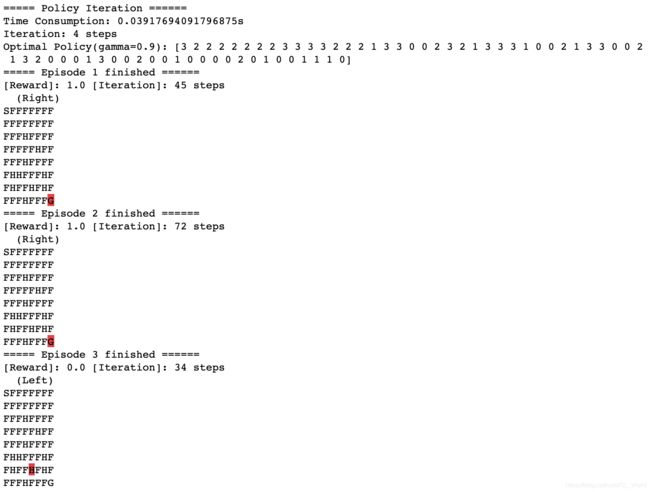
执行结果如下:
1.3 代码debug过程
起初写完代码发现run完policy_evaluation后value表中的值不收敛,越来越大,直至inf。后来发现是new_value_table = np.copy(value_table)的错误,因为更新V(s)用的是+=,所以若不置零(new_value_table = np.zeros(env.nS))则新价值表都是基于旧表再加新值得到,则新旧两表永远不会一致,使得算法不收敛。
二、价值迭代
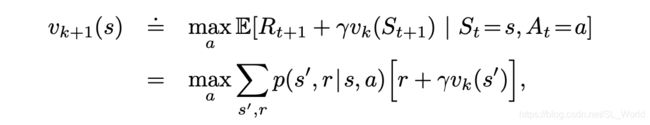
2.1 伪代码

2.2 基于冰湖的代码
实验环境及介绍:FrozenLake8x8-v0
import gym
import time
import numpy as np
def value_iteration(env, threshold=1e-4, gamma=0.9):
env.reset()
start = time.time()
# 初始化策略
policy = np.zeros(env.nS, dtype=int) # 默认为float类型
# 初始化value表 (初始化0)
value_table = np.zeros(env.nS)
new_value_table = np.zeros(env.nS)
delta = 2 * threshold
while delta > threshold:
for state in range(env.nS):
action_value = np.zeros(env.nA)
for action in range(env.nA):
for prob, next_state, reward, done in env.P[state][action]:
action_value[action] += prob * (reward + gamma*value_table[next_state])
# 1.利用max操作更新V(s),区别与Policy Iteration
new_value_table[state] = max(action_value)
# 2.Policy Improvement
policy[state] = np.argmax(action_value)
delta = sum( np.fabs(new_value_table - value_table) )
value_table = np.copy(new_value_table) # 注:需用copy拷贝副本,否则两个变量指向同一位置,则赋值时同时改变
print('===== Value Iteration ======\nTime Consumption: {}s\nIteration: {} steps\nOptimal Policy(gamma={}): {}'.format(time.time()-start, 1, gamma, policy))
return value_table, policy
def play_game(env, policy, episodes=5, timesteps=150):
for episode in range(episodes):
state = env.reset()
for t in range(timesteps):
action = policy[state]
state, reward, done, info = env.step(action)
if done:
print("===== Episode {} finished ====== \n[Reward]: {} [Iteration]: {} steps".format(episode+1, reward, t+1))
env.render()
break
env = gym.make('FrozenLake8x8-v0')
# 价值迭代
value_table, policy = value_iteration(env, gamma=0.9)
# 使用迭代计算得到的策略打游戏
play_game(env, policy, episodes=3)
env.close()
执行结果如下:

【参考文献】
[1] gym-冰湖环境源码.