
JavaEE初阶(11)HTTP 协议(发展历程、报文格式、URL、HTTP请求详解、HTTP 响应详解、构造HTTP请求、form 表单构造、AJAX的方式构造)
接上次博客:JavaEE初阶(10)网络原理——TCP/IP协议(再谈协议、应用层、自定义协议、传输层:UDP 协议、 TCP协议、异常、TCP和UDP的对比、网络层重点协议、数据链路层重点协议)-CSDN博客
目录
HTTP 协议概念
HTTP 协议发展历程
适用场景
1. 浏览器打开网站:
2. 手机应用程序访问服务器:
HTTP的报文格式
HTTP协议的不同使用场景
下载并使用抓包工具
HTTP请求报文格式:
HTTP响应报文格式:编辑
URL
认识 "方法" (method)
1、GET 方法
2、POST 方法
GET 和 POST 的区别(面试题)
HTTP其他方法
HTTP请求详解
认识请求 "报头" (header)
前期准备
登陆请求
登录请求头部
登录响应头部
响应主体
访问其他页面
GET请求头部
理解登陆过程
认识请求 "正文" (body)
HTTP 响应详解
200 OK
404 Not Found
403 Forbidden
405 Method Not Allowed
500 Internal Server Error
504 Gateway Timeout
302 Move temporarily
301 Moved Permanently
418 I am a teapot!
状态码小结
认识响应 "报头" (header)
Content-Type
认识响应 "正文" (body)
(1)text/html
(2)text/css
(3) application/javascript
(4)application/json
那么我们如何让客户端构造一个HTTP请求?如何让服务器处理一个HTTP请求?
浏览器构造HTTP请求:
服务器处理HTTP请求(具体的以后介绍):
通过 form 表单构造
form 发送 GET 请求
表单form的重要参数
输入字段 input 的重要参数
体会 form 代码和 HTTP 请求之间的对应关系
form 发送 POST 请求
通过AJAX的方式构造
发送 GET 请求
浏览器和服务器交互过程(引入 ajax 后):
发送 POST 请求
练习:
HTTP 协议概念
HTTP是“超文本传输协议”(Hypertext Transfer Protocol)的缩写,它是一种应用层协议,用于在互联网上传输超文本文档,通常指的是网页。HTTP是Web上最基本的协议之一,它定义了客户端(例如Web浏览器)和服务器之间的通信规则,使我们能够在Web上浏览、搜索和与各种Web资源进行交互。
HTTP的主要功能包括:
-
传输数据:HTTP负责在客户端和服务器之间传输数据,通常是HTML文档、图像、样式表和其他Web资源。这些资源以超文本的形式链接在一起,构成了Web页面。
-
请求-响应模型:客户端通过HTTP请求发送到服务器,并等待服务器的HTTP响应。请求包括所需的资源,以及其他信息如请求方法(GET、POST、PUT、DELETE等),请求头(包含有关请求的元数据),以及请求体(对于某些方法,如POST)。
-
状态代码:HTTP响应包括一个状态代码,指示请求是否成功。例如,200表示成功,404表示未找到请求的资源,302表示重定向等。
-
无状态性:HTTP是一种无状态协议,这意味着每个HTTP请求都是独立的,不依赖于之前的请求。这使得Web服务器可以处理大量的并发请求,但也要求使用会话(如cookies)来跟踪用户状态。
-
可扩展性:HTTP是一个灵活的协议,可以轻松添加新的头部字段和方法,以支持不断发展的Web应用需求。
-
连接管理:HTTP/1.1引入了持久连接,允许多个请求和响应在单个TCP连接上进行,减少了连接的开销。
HTTP的版本有多个,目前最常用的是HTTP/1.1和HTTP/2.0。HTTP/2.0引入了更多的性能优化,如多路复用、头部压缩和服务器推送,以提高Web应用的加载速度和性能。
HTTP是Web的基础之一,负责连接客户端和服务器,使我们能够在浏览器中浏览、搜索和与Web上的各种资源进行交互。无论您是浏览网页、下载文件还是与Web应用程序进行通信,HTTP都在幕后起着至关重要的作用。
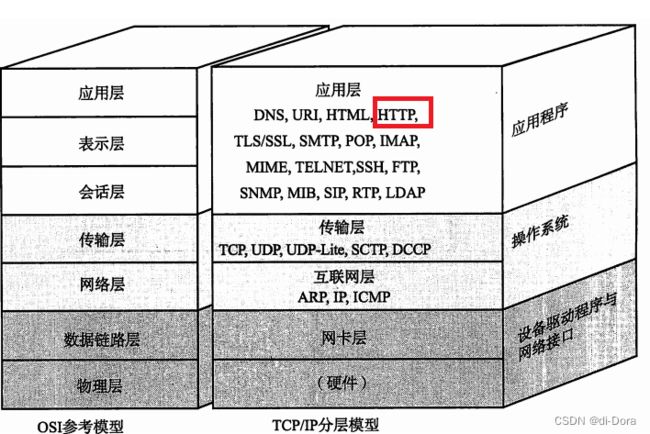
HTTP 协议发展历程
HTTP 诞生与1991年,目前已经发展为最主流使用的一种应用层协议。
HTTP通常是基于传输层的TCP协议实现的,而HTTP/1.0、HTTP/1.1和HTTP/2.0都使用TCP作为其底层传输协议。HTTP/3.0则采用了基于UDP的QUIC(Quick UDP Internet Connections)协议。
HTTP/1.1和HTTP/2.0是当前最常用的HTTP版本:
-
HTTP/1.1:HTTP/1.1是目前广泛采用的HTTP版本,它建立在TCP连接之上,使用一系列请求-响应的模式来传输数据。HTTP/1.1引入了持久连接,允许多个请求和响应在单个TCP连接上复用,以减少连接的开销。然而,它仍然存在一些性能瓶颈,如"队头阻塞",这在HTTP/2.0中得到了改善。
-
HTTP/2.0:HTTP/2.0是HTTP/1.1的进化版本,它引入了多路复用、头部压缩、服务器推送等特性,以提高性能和减少加载时间。HTTP/2.0仍然基于TCP,但通过并行处理多个请求,解决了HTTP/1.1中的队头阻塞问题。
HTTP/3.0采用了UDP上的QUIC协议,以进一步提高性能和安全性。QUIC是由Google开发的协议,它允许多个流(包括HTTP请求和响应)在同一连接上独立传输,降低了延迟。此协议还包括一层加密,从而提高了安全性。然而,HTTP/3.0尚未被广泛采用,而HTTP/1.1和HTTP/2.0仍然是大多数Web应用的主要版本。
总的来说,不同版本的HTTP都在不断发展和改进,以适应不断增长的互联网应用需求。选择使用哪个版本通常取决于你的应用需求和支持的技术。在实际应用中,往往需要综合考虑性能、兼容性和安全性等因素来选择合适的HTTP版本。
适用场景
HTTP协议在许多不同的场景中都得到了广泛的应用,其中包括浏览器打开网站和手机应用程序访问服务器。以下是这两种常见情况的简要说明:
1. 浏览器打开网站:
当我们在Web浏览器中输入网站地址或点击书签时,会发生以下过程:
-
浏览器将发送一个HTTP请求到目标网站的服务器,请求指定的网页或资源。
-
目标服务器接收到请求后,会根据请求的路径和其他信息查找并准备要发送的资源。
-
服务器会构建HTTP响应,其中包括所请求资源的内容以及一些元数据,如响应状态代码、响应头(包含有关响应的元信息)等。
-
服务器将HTTP响应发送回浏览器。
-
浏览器接收响应后,会解析响应内容,渲染页面并显示在用户的屏幕上。
-
用户可以与网页交互,点击链接、填写表单等。
这是典型的HTTP协议用例,其中HTTP用于在浏览器和服务器之间传输网页和相关资源。
2. 手机应用程序访问服务器:
移动应用程序通常需要与服务器通信来获取数据、更新内容、进行用户身份验证等。在这种情况下,HTTP通常用于构建移动应用程序与服务器之间的通信。
-
移动应用程序会使用HTTP请求与服务器交互。这可以包括GET请求来获取数据、POST请求来提交表单数据或执行其他操作,以及其他HTTP方法。
-
服务器将处理这些请求,执行相关操作,然后构建HTTP响应,将所需的数据或响应状态返回给应用程序。
-
移动应用程序将解析HTTP响应,处理数据,然后在用户界面上呈现或执行适当的操作。
这种情况下,HTTP用于支持移动应用程序与服务器之间的数据交换,使应用程序能够实时获取和展示数据。
总的来说,HTTP是一种通用的协议,适用于各种互联网应用。无论是通过浏览器访问网站还是通过移动应用程序与服务器通信,HTTP都是连接客户端和服务器的关键技术之一。
当然,我们要学习HTTP的协议,重点还是学习HTTP的报文格式,接下来就让我们主要来看看HTTP的报文格式。
HTTP的报文格式
HTTP协议的不同使用场景
根据不同的交互需求,HTTP可以被用于不同的模式:
-
一问一答访问网站:这是HTTP最常见的使用方式,通常用于浏览网站。客户端(通常是Web浏览器)向服务器发送HTTP请求,请求网页或资源,服务器返回相应的HTTP响应,包含所请求的内容。这是典型的请求-响应模式,客户端请求一个资源,服务器响应提供该资源。
-
多问一答上传文件:在这种情况下,客户端需要上传文件到服务器。客户端使用HTTP请求,通常是使用HTTP POST方法,将文件数据作为请求体发送到服务器。服务器接收到请求后,可以将文件保存在服务器上,然后返回一个表示上传成功的HTTP响应。
-
一问多答下载文件:这是当客户端需要从服务器下载文件时的模式。客户端向服务器发送HTTP请求,请求服务器提供特定的文件或资源。服务器返回文件内容作为HTTP响应体,客户端可以下载并保存该文件。
-
多问多大串流/远程桌面:这是一种更复杂的应用程序场景,其中HTTP用于建立多个请求和响应的串流通信。这可以是多个请求和响应,以进行复杂的交互,也可以是远程桌面协议,使远程控制和屏幕共享成为可能。
理解HTTP协议的报文格式对于有效地使用和分析HTTP通信至关重要。HTTP协议是一种基于"一问一答"结构模型的协议,它用于在客户端和服务器之间传输超文本文档和其他资源。客户端向服务器发送HTTP请求报文,服务器接收请求并发送HTTP响应报文作为响应。
和我们之前学的TCP和UDP相对比,它的请求和响应在协议格式上有一些差异,主要体现在报文的结构和内容上。
以下是HTTP请求和响应报文的基本格式:
下载并使用抓包工具
如何查看到HTTP请求和响应的格式呢?
我们需要抓包工具:把网卡上经过的数据获取到并显示出来,它们是分析调试的程序的重要手段。
这些工具可以拦截、捕获和分析经过网络接口的数据流,包括HTTP请求和响应。以下是一些常用的抓包工具:
-
Wireshark:Wireshark是一款流行的开源网络分析工具,可以捕获网络数据包并以易于理解的形式显示它们。我们可以使用Wireshark来查看HTTP请求和响应的详细信息,包括请求报文、响应报文、报文头和报文体,但是不太方便。
-
Fiddler:Fiddler是一个Windows平台上的免费Web调试代理工具,专注于HTTP调试。它可以捕获HTTP请求和响应,以及WebSocket通信。Fiddler还提供了详细的请求和响应的解析、筛选和修改功能。
-
Charles:Charles是一款跨平台的HTTP代理工具,用于查看HTTP请求和响应以及进行调试。它允许我们查看和修改流经代理的数据,从而可以分析和调试HTTP通信。
-
Postman:Postman是一个强大的API测试和调试工具,可以捕获和查看HTTP请求和响应。虽然它主要用于API测试,但也可以用于HTTP请求的查看和调试。
接下来我们就使用 Fiddler 来讲解。
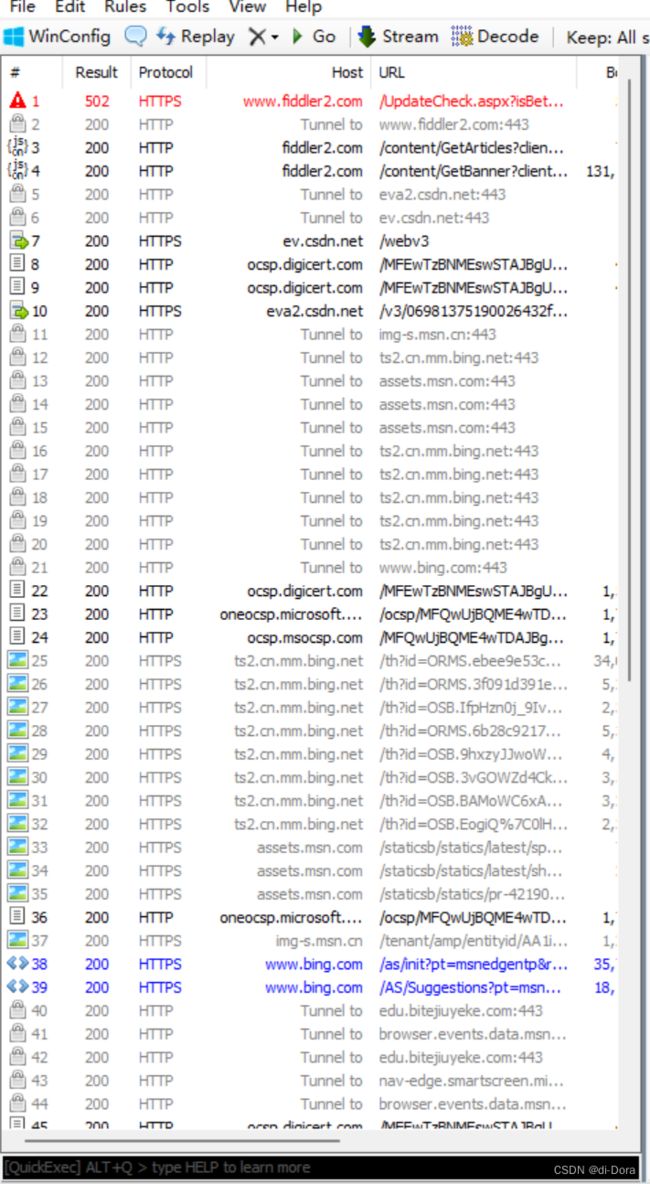
Fiddler是一个强大的网络调试代理工具,它的界面通常分为左侧和右侧两个部分,用于查看捕获的HTTP请求和响应。
左侧部分是一个包含捕获的HTTP请求和响应的列表,我们可以在这里查看所有经过Fiddler代理的数据包,这些数据包按时间顺序排列。
右侧部分通常用于显示选定请求或响应的详细信息,包括请求头、响应头、报文体等。这个部分用于分析特定的请求或响应的内容。
-
启用HTTPS抓包功能:
- 打开Fiddler。
- 在Fiddler的菜单栏中,选择“Tools”(工具) > “Options”(选项)。
- 在选项对话框中,选择“HTTPS”选项卡。
- 在该选项卡下,勾选“Capture HTTPS CONNECTs”和“Decrypt HTTPS traffic”选项。
-
安装Fiddler根证书:
- 一旦你启用了HTTPS抓包功能,Fiddler会充当中间代理,要能够解密HTTPS流量,就需要安装Fiddler根证书。
- 在Fiddler选项对话框的“HTTPS”选项卡下,单击“Actions”(操作)。
- 在下拉菜单中,选择“Trust Root Certificate”(信任根证书)。
- 按照提示,将Fiddler根证书安装到你的操作系统或浏览器中。这将允许Fiddler解密HTTPS流量并进行分析。
-
开始抓包:
- 确保Fiddler已经启动并配置为捕获HTTPS流量。
- 打开任何浏览器或应用程序,执行你希望分析的操作,以触发HTTPS流量。
- 在Fiddler的左侧列表中,你将看到捕获的请求和响应,包括HTTP和HTTPS的内容。
- 单击每个请求或响应,以查看详细信息,包括请求报文和响应报文。
注意,安装Fiddler根证书可能需要管理员权限,并且在某些操作系统和浏览器中,你可能需要额外的配置步骤。一旦配置完成,就可以使用Fiddler来分析HTTPS流量,检查请求和响应的详细信息,以及进行网络调试。
安装的 Fiddler 需要手动开启HTTP功能,并且安装证书,否则只能抓http。
安装根证书,一定要选择“同意”,否则你就只能卸载重装了:
把该勾选的项都勾选上:
这样就正常了:
但是Fiddler 本质上是一个“代理”,可能会和其他的代理软件冲突。
Fiddler在其核心上是一个正向代理服务器,用于HTTP和HTTPS网络调试。它充当客户端(例如Web浏览器)和目标服务器之间的中间人,允许开发人员捕获、查看和修改这两方之间的交互数据。
正向代理和反向代理是两种代理服务器的不同用途:
-
正向代理(Forward Proxy):
- 正向代理是代理服务器,代表客户端发起请求,以隐藏客户端的身份或绕过防火墙等网络安全限制。
- 客户端(例如,浏览器)配置正向代理服务器的地址和端口,然后将请求发送到代理服务器。代理服务器代表客户端发起请求,接收响应,然后将响应返回给客户端。
- 正向代理充当客户端的中介,客户端的请求似乎是来自代理服务器而不是客户端自身。这可用于访问受限制的内容或绕过网络过滤。
-
反向代理(Reverse Proxy):
- 反向代理是代理服务器,代表服务器接收请求,并将请求路由到后端服务器以获取响应,然后将响应返回给客户端。
- 客户端向反向代理服务器发出请求,但客户端不知道或不需要知道响应来自哪个后端服务器。
- 反向代理通常用于负载均衡、安全性和性能优化,将客户端的请求分发给多个后端服务器以提高性能,并隐藏后端服务器的身份以增强安全性。
以下是Fiddler作为正向代理的程序过程:
- 当你启动Fiddler时,它会开始监听指定的端口(默认为8888)。
- 你需要在浏览器或其他需要监视的应用程序中,将Fiddler设置为正向代理。通常,这意味着你将网络设置中的代理指向127.0.0.1(本地主机)的端口8888。
- 当你的浏览器或应用程序发起一个网络请求时,请求首先发送到Fiddler。
- Fiddler捕获请求并在其用户界面中显示详细信息。在此阶段,开发人员可以查看或修改请求内容。一旦完成,Fiddler将请求转发到目标服务器。
- 目标服务器处理请求并将响应发送回Fiddler。
- Fiddler捕获响应并在其用户界面中显示。开发人员可以查看或修改响应内容。一旦完成,Fiddler将响应转发回原始客户端(例如浏览器)。
- 浏览器或应用程序接收到响应,并根据响应数据进行相应的处理。
Fiddler 用于中继HTTP请求和响应,以便分析和调试网络通信。由于它的代理特性,可能与其他代理软件或配置的代理服务产生冲突。
冲突和如何解决它们的方法:
-
冲突的代理设置:如果您的计算机上已经配置了其他代理服务(如VPN代理、代理服务器软件等),它们可能会与Fiddler产生冲突。在这种情况下,你可以考虑暂时禁用其他代理服务,以便Fiddler能够正常工作。
-
端口冲突:Fiddler默认监听的端口是8888,如果其他代理服务或应用程序正在使用相同的端口,可能会导致冲突。你可以在Fiddler选项中更改Fiddler的监听端口,以避免与其他服务冲突。
-
安全软件干预:某些安全软件可能会检测到代理行为,并视其为潜在风险。这可能导致安全软件干预Fiddler的操作。你可以在安全软件中配置允许Fiddler运行,并排除其干预。
-
操作系统代理设置:在某些操作系统中,代理设置可能会全局影响网络连接。如果Fiddler设置为全局代理,它可能会与其他代理设置产生冲突。确保Fiddler的代理设置仅用于需要调试的应用程序。
解决这些冲突通常需要一些配置调整和可能的冲突排除。在使用Fiddler之前,你可以检查你的计算机上是否有其他代理服务或代理设置,并确保它们不会干扰Fiddler的正常运行。
平常我们见过的一些程序,比如:VPN和加速器,这些都是“代理”,它们都会冲突。所以你应该先关闭之前的一些代理软件,也有可能是一个浏览器插件。你还可以尝试使用不同的浏览器,edge通常会有点问题。
为了方便观察,我们先清空一下原先的数据列表:
CTRL+A全选,
选择 "Edit" 菜单中的 "Remove" 选项,或者使用键盘上的 Delete 键。这将删除你选择的HTTP请求数据。
如果你删除了某个请求但后来需要查看或分析它,你可以在 "File" 菜单中找到 "Restore" 选项来恢复已删除的请求。
一个网站打开的时候往往不是只和服务器进行一次操作,大概率是多次操作。
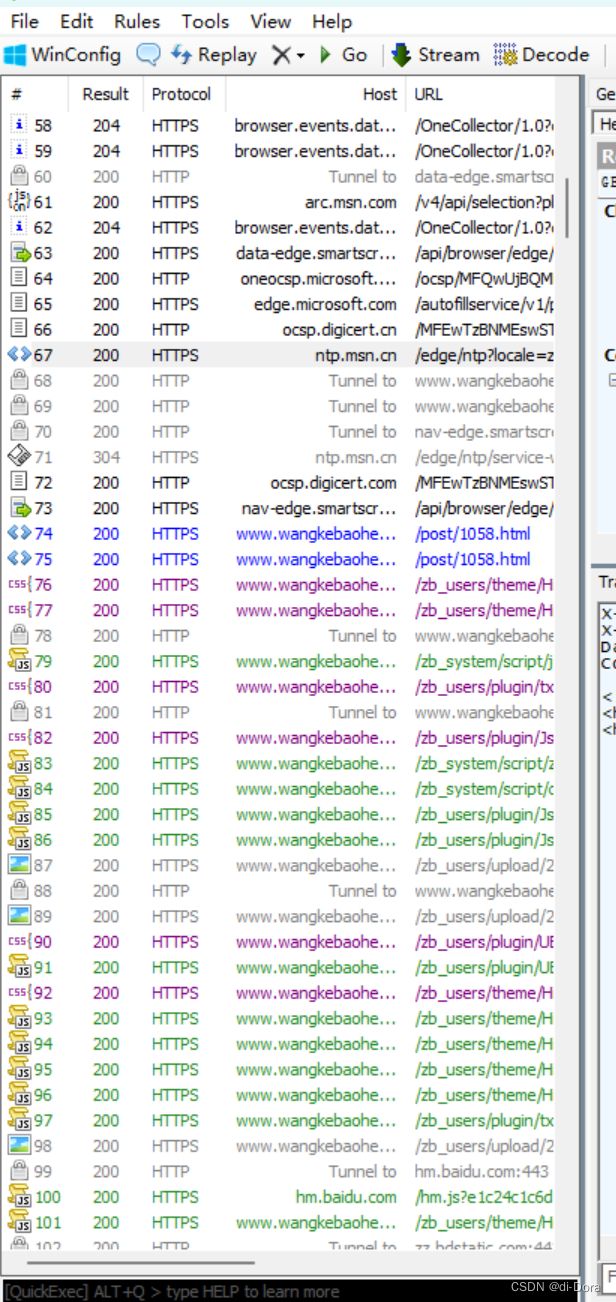
在Fiddler中,HTTP请求和响应的颜色编码通常是用来区分不同类型的请求和响应的状态。
一般情况下,Fiddler的颜色编码如下:
- 蓝色:通常表示返回的是HTML内容,也就是网页的主体部分。HTML通常是由文本、标记和链接组成的,用于呈现网页的结构和内容。
- 黑色:通常表示其他类型的数据,例如JSON、XML、纯文本或二进制数据,这些数据可以用于各种不同的应用,如API通信、文件传输等。
- 绿色:表示成功的HTTP请求。
- 红色:表示HTTP请求失败或返回错误状态码,如404(未找到)或500(服务器内部错误)。
- 黄色:表示重定向的请求,即服务器返回了重定向状态码,如302(临时重定向)。
- 灰色:表示请求是被缓存的。
- 紫色:表示WebSocket通信。
这些颜色编码有助于用户迅速识别HTTP请求和响应的状态和类型。例如,红色的请求和响应通常表示问题或错误,绿色的请求和响应表示成功,黄色表示重定向,等等。这使得Fiddler成为一个强大的网络调试工具,有助于开发人员分析和解决与HTTP通信相关的问题。
HTTP协议是文本格式的协议,我们点开协议里面的HTTP请求部分,会发现内容都是字符串。
我们之前学的TCP和UDP、IP都是二进制。
HTTP响应其实也是文本的,但是直接查看我们看到的是二进制文件,因为这里是压缩后的。
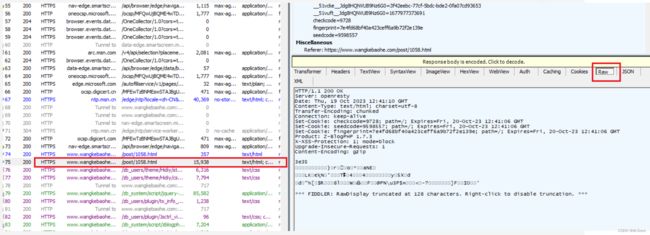
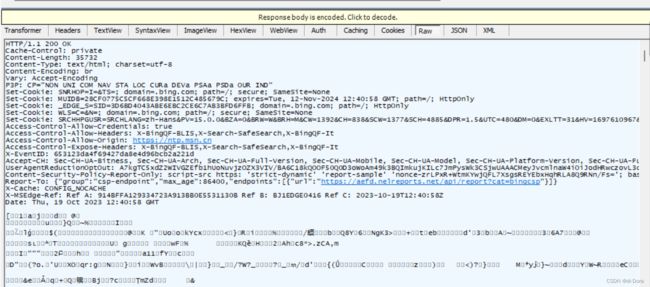
HTTP响应经常会被压缩,压缩之后体积会变小,传输的时候节省网络带宽。
解压缩点这个按钮:

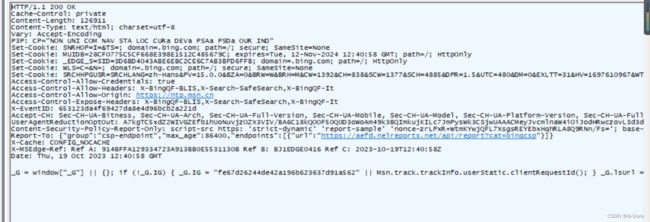
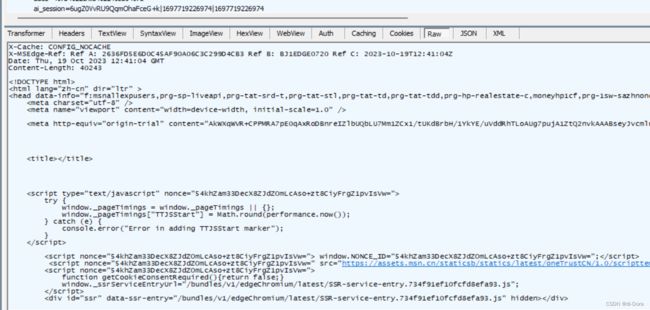
解压缩之后可以看到响应的数据其实是HTML。浏览器显示的网页就是HTML,往往都是浏览器先请求对应的服务器,从服务器那边拿到的页面数据。
HTTP请求报文格式:
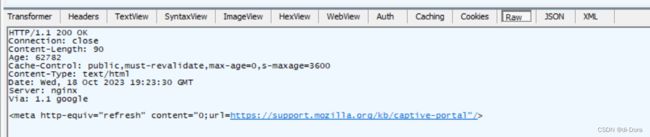
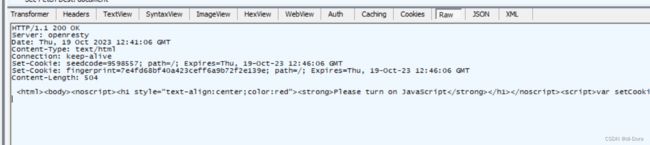
Server: openresty
Date: Thu, 19 Oct 2023 12:41:06 GMT
Content-Type: text/html
Connection: keep-alive
Set-Cookie: seedcode=9598557; path=/; Expires=Thu, 19-Oct-23 12:46:06 GMT
Set-Cookie: fingerprint=7e4fd68bf40a423ceff6a9b72f2e139e; path=/; Expires=Thu, 19-Oct-23 12:46:06 GMT
Content-Length: 504
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, */*;q=0.8
HTTP请求报文由以下几部分组成:
-
请求行:包括HTTP方法(GET、POST、PUT、DELETE等)、请求的URI(Uniform Resource Identifier,即请求的路径),以及HTTP协议版本(通常是HTTP/1.1)。
-
请求头:包含请求的元数据,如User-Agent(客户端的用户代理)、Host(请求的目标主机名)、Accept(客户端可以接受的响应媒体类型)等。
-
空行:用于分隔请求头和请求体。
-
请求体(可选):包含请求的数据,通常在HTTP方法是POST或PUT时使用,例如表单数据或上传的文件。
从行的角度来看:
-
首行:
- 第一部分是HTTP请求的方法(GET、POST、PUT等),它指示了客户端希望执行的操作。
- 第二部分是URL(Uniform Resource Locator),描述了所请求资源在网络上的位置。
- 第三部分是HTTP协议的版本号,例如,HTTP/1.1。
-
请求头(Header):
- 请求头是一系列键值对,每一对键值对都描述了请求的元数据信息。键和值之间使用冒号和空格分隔,如Host: www.example.com。
- 请求头用于传递客户端的信息和需求,如User-Agent、Accept、Cookie等。
-
空行:
- 空行是请求头的结束标记,它表示请求头部分的结束。
-
请求正文(Body):
- 请求正文是可选的,它包含请求的数据,如表单提交的数据或上传的文件内容。
- 并非所有HTTP请求都包含请求正文。
HTTP响应报文格式: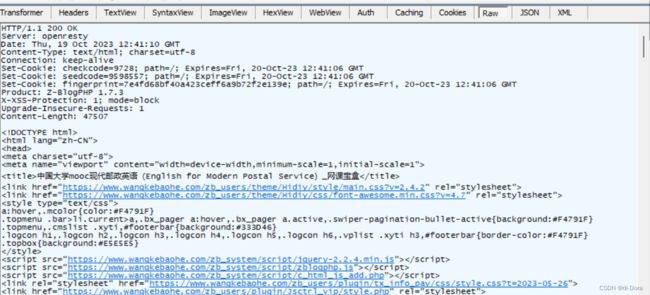
HTTP/1.1 200 OK
Server: openresty
Date: Thu, 19 Oct 2023 12:41:10 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Set-Cookie: checkcode=9728; path=/; Expires=Fri, 20-Oct-23 12:41:06 GMT
Set-Cookie: seedcode=9598557; path=/; Expires=Fri, 20-Oct-23 12:41:06 GMT
Set-Cookie: fingerprint=7e4fd68bf40a423ceff6a9b72f2e139e; path=/; Expires=Fri, 20-Oct-23 12:41:06 GMT
Product: Z-BlogPHP 1.7.3
X-XSS-Protection: 1; mode=block
Upgrade-Insecure-Requests: 1
Content-Length: 47507
中国大学mooc现代邮政英语(English for Modern Postal Service)_网课宝盒
HTTP/1.1 200 OK
Date: Thu, 20 Jan 2022 15:50:23 GMT
Server: Apache/2.4.41 (Ubuntu)
Content-Length: 1234
Content-Type: text/html
Example Page
Hello, World!
HTTP响应报文由以下几部分组成:
-
状态行:包括HTTP协议版本(通常是HTTP/1.1)、状态码(指示请求的处理结果,如200表示成功,404表示未找到,302表示重定向等)和状态短语(与状态码相关的短描述)。
-
响应头:包含响应的元数据,如Server(响应的服务器软件)、Content-Type(响应的媒体类型)、Content-Length(响应的内容长度)等。
-
空行:用于分隔响应头和响应体。
-
响应体:包含响应的数据,通常是网页内容、文件内容或其他资源的数据。
从行的角度来看:
-
首行:
- 第一部分是HTTP协议的版本号,例如,HTTP/1.1。
- 第二部分是状态码,它描述了请求的处理结果,如200表示成功、404表示未找到、302表示重定向等。
- 第三部分是状态码的描述,通常是一个短的文本说明,例如"OK"表示成功。
-
响应头(Header):
- 响应头也是一系列键值对,描述了响应的元数据信息,如Server、Content-Type、Content-Length等。
- 响应头传递了服务器的信息以及响应的属性。
-
空行:
- 空行标志着响应头的结束。
-
响应正文(Body):
- 响应正文包含了响应的具体内容,这可能是HTML、CSS、JavaScript、JSON、XML等各种格式,也可以被压缩以减小传输大小。
- 不一定要有,也可以为空。
URL
计算机中非常重要的概念。表述了某个资源在网络上的所属位置。数据库也算是一种资源。
https://user:[email protected]:8080/directory/file.html?query=value#fragment
现在,让我们逐个拆解这个URL:
![]()
- 协议方案名(Scheme): https: 这指明了用于访问资源的协议类型。常见的协议有http(超文本传输协议)、https(安全的HTTP,通过SSL/TLS加密)、ftp(文件传输协议)等。
- 登陆信息认证:这个东西现在基本上不会用了,尤其是针对用户的产品。
- 服务器地址【可以是IP地址,也可以是域名(Host)】: www.example.com: 这是服务器的域名,它指向了资源所在的服务器的位置。域名通常解析为一个IP地址。
- 服务器端口: 8080: 这是服务器上的特定端口,用于访问服务器上的特定服务。如果没有明确指定,大多数协议都有默认端口,例如HTTP的默认端口是80,而HTTPS的默认端口是443。
- 带层次的文件路径(Path): /directory/file.html: 这指定了服务器上资源的特定位置。路径通常对应服务器文件系统中的文件或目录结构,但这取决于服务器如何配置。
- 查询参数(Query): query=value: 这是发送给服务器的参数,通常用于请求特定资源或信息。查询参数以?开始,多个参数之间用&分隔。
- 片段(Fragment)标识符: #fragment: 这是URL中的一个锚点,它引用资源中的一个特定部分,例如HTML页面中的一个特定段落或标题。片段部分在浏览器中处理,并且通常不发送到服务器。
综上,URL提供了一个标准方法来描述互联网上资源的位置,并为客户端提供了所需的所有信息来定位和检索这些资源。
对于Query String来说,当查询参数的值(value)包含特殊字符、空格、或者非标准ASCII字符时,通常需要进行URL编码(URL encoding)以确保它们在URL中传输和解析正确。这些特殊符号可能会使浏览器/HTT[服务器对于URL的解析出错。所以我们需要进行转义。URL encode本质就是一种“转义字符”。
URL编码将特殊字符和非标准字符转换为URL安全的形式,通常是使用百分号编码(Percent Encoding)来表示。
URL编码的一般规则是将字符转换为"%XX"的形式,其中XX是字符的十六进制ASCII码。例如,空格字符会被编码为"%20",而问号字符?会被编码为"%3F"。这确保了URL中的字符不会与URL的语法和解析发生冲突。
例如,如果你想在查询参数中包含一个特殊字符,比如问号?,你应该将它编码为%3F,如下所示:
原始URL:https://www.example.com/search?q=some?query
编码后的URL:https://www.example.com/search?q=some%3Fquery
在不同的编程语言和框架中,都提供了URL编码和解码的函数或方法来处理这些情况。例如,Python中的urllib.parse库提供了quote()函数用于URL编码,以及unquote()函数用于解码。在JavaScript中,encodeURIComponent()函数用于URL编码,而decodeURIComponent()函数用于解码。
认识 "方法" (method)
1、GET 方法
定义与用途:
- GET是HTTP中的一种方法,主要用于从服务器获取资源。
- 在浏览器地址栏直接输入URL时,浏览器会发送一个GET请求。
- 在HTML中,link、img、script 等标签也会触发GET请求。
- 使用JavaScript的Ajax技术,我们可以构造GET请求进行异步数据交互。(Python爬虫常用)

请求特点:
- 请求行的首部包含“GET”关键字。
- URL的查询字符串可以有内容,也可以为空。
- 请求头部分包含一系列的键值对结构。
- GET请求的主体部分通常为空。
关于GET请求的URL长度问题:
- 一些流传的信息认为GET请求的URL长度限制为1024kb,但这是不准确的。
- HTTP协议的RFC 2616标准并未规定URL的最大长度。
- URL的实际长度限制取决于浏览器和服务器的实现。
- 浏览器端:不同浏览器对URL的长度限制不同。但现代浏览器通常都支持非常长的URL。
- 服务器端:URL长度通常是可配置的,取决于服务器的设置和实现。
总之,尽管HTTP协议本身没有限制URL的长度,但在实际应用中,浏览器和服务器的具体实现可能会设置一些限制。在设计Web应用时,考虑到跨浏览器和跨平台的兼容性,通常建议不要使用过长的URL。
2、POST 方法
定义与用途:
- POST是HTTP中的一种方法,通常用于将用户输入的数据提交给服务器,例如登录表单。
- 通过HTML的 form 标签,或使用JavaScript的Ajax技术,都可以构造POST请求。

这里我其实最开始没能抓到返回页面的请求,原因是命中了浏览器缓存。
浏览器显示的页面其实都是从服务器这边下载的HTML,它的内容可能比较多,体积比较大,通过网络加载消耗的时间也会比较多。
所以浏览器一般都会自己带有缓存,就把之前加载过的页面保存在本地硬盘上,下次访问可以直接读取本地硬盘的数据。
请求特点:
- 请求行的首部包含“POST”关键字。
- URL的查询字符串通常为空,但也可以包含数据。
- 请求头部分包含一系列的键值对结构。
- POST请求的主体部分通常不为空,主体内的数据格式由请求头中的 Content-Type 指定。
- 主体的长度由请求头中的 Content-Length 指定。
POST方法主要用于将数据传输到服务器,这些数据通常包含在请求主体中。与GET请求不同,POST请求通常用于非幂等操作,例如在服务器上创建新资源,因此具有状态更改的潜力。在POST请求中,主体的数据格式通常由 Content-Type 头部字段指定,可以是表单数据、JSON、XML等格式。
你会发现我上传了一张图片,这里的body非常长,因为此处把图片放到HTTP请求中,往往要进行mb4转码

在HTTP请求中上传一张图片,这可能导致请求主体(body)非常大,因为图像文件通常具有较大的文件大小。如果将图像文件作为HTTP请求的一部分上传,可能需要将二进制数据进行编码,以便在HTTP请求中传输。
常用的图像编码格式包括Base64编码,这将二进制数据编码为文本字符串,使其可以包含在HTTP请求中。具体的编码方法和格式可能因不同的编程语言和HTTP库而异。通常,编码后的图像数据会放在请求的主体中,而请求头会包含有关数据类型(例如Content-Type)和数据长度(例如Content-Length)的信息。
在服务器端,我们需要解码请求主体,以还原图像文件的二进制数据。这可以通过编程语言的库和工具来完成。
注意,虽然可以将图像文件包含在HTTP请求中,但对于大型文件或多个文件的上传,通常更常见的做法是使用多部分表单(multipart/form-data),这样可以更有效地处理文件上传。此外,HTTP服务器通常有文件上传限制,需要根据服务器配置来确定最大请求主体的大小。
GET 和 POST 的区别(面试题)
GET和POST其实并没有本质的区别!!!双方可以替换对方的场景。
但是虽然没有本质区别,但是在使用习惯上还是存在一些差异。
- GET请求通常会把要传给服务器的数据加到URL的 query、string 里面。
- POST请求,经常把要传给服务器的数据加到body里面。
这是习惯上最大的差别。当时上述情况并非绝对,GET也可以使用body,POST也可以使用 query、string ,使用的前提是客户端/服务器都得按照一样的方式来处理代码。 所以一般还是建议大家按照约定俗成的习惯,不要太特立独行~~~
语义不同:
- GET一般用于获取数据,而POST一般用于提交数据。GET请求通常用于从服务器请求资源,而POST请求通常用于将数据提交到服务器,一般都是登录和上传。
- 相比之下,PUT和POST等,语义就比较混乱了。
数据传递方式:
- GET请求的主体通常为空,需要传递的数据通过查询字符串(query string)传递,附加在URL上。
- POST请求的查询字符串通常为空,需要传递的数据通过请求主体(body)传递,通常使用Content-Type头部指定数据格式。
幂等性:
- 幂等是数学概念,即输入相同的内容,输出是稳定的。
- GET请求一般是幂等的,即多次相同的GET请求应该返回相同的结果。
- POST请求一般是不幂等的,如果多次相同的POST请求得到的结果一样,通常不视为请求是幂等的。
- 但是需要注意,这种说法不够准确,但也不是完全出错。GET是否幂等不绝对,RFC上建议GET请求实现为幂等的。一个GET不幂等的情况:搜狗的广告搜索,这背后涉及到一系列复杂的逻辑操作。
缓存:
- GET请求可以被缓存,因为它是幂等的,多次获取相同资源不会对服务器状态产生影响。
- POST请求通常不被缓存,因为它通常用于对服务器状态进行更改。
- 当然,这个说法也和上述幂等有关,是幂等性的延续,如果请求是幂等的,自然就可以缓存。
其他补充说明:
- 关于语义:虽然GET和POST有常见的用途,但实际上,GET也可以用于提交数据,而POST也可以用于获取数据,因为HTTP本身并未强制这些语义。
- 关于安全性:GET和POST在安全性方面并无绝对的不同,安全性主要取决于数据加密和其他安全措施的实施。
- 关于传输数据量:HTTP标准未规定GET的URL或POST的主体的长度限制,因此传输数据量取决于浏览器和服务器的实现。
- 关于传输数据类型:GET虽然不直接传输二进制数据,但可以对二进制数据进行URL编码以传输。
这里我们需要具体解释一下。
网络上经常有一些说法,需要注意:
1、GET请求能传递的数据量有上,POST没有。这个说法是一个历史遗留问题,早期版本的浏览器硬件资源非常匮乏,针对GET请求的URL长度做出了限制。但是实际上RFC标准文档中并没有明确规定URL能有多长,目前的浏览器和服务器的实现过程中,URL可以是非常长的,甚至可以使用URL传递一些图片这样的数据;
2、GET传递数据不安全,POST请求传递数据更安全。依据是:如果使用GET请求进行实现登陆,点击登陆的时候就会把用户名和密码放到URL中,进一步的显示到浏览器的地址栏里,相比之下POST则是在body中,不会在界面上显示出来,所以更安全。但是我们通常说的“安全”指的是传递的数据不容易被黑客获取,或者被获取到之后不容易被破解。所以此处的密码是加密的,即使拿到了也不容易破解。
3、GET只能给服务器传输文本数据,POST可以给服务器传输文本和二进制数据。
- GET也不是不可以使用body,body中是可以直接放二进制的。
- GET也可以把二进制数据进行base转码放到URL中的query和string中。
4、GET请求可以被浏览器收藏夹收藏,POST不能,因为收藏的时候可能会丢失body。这个说法目前是正确的,但是可能和技术关系不大,主要还是看你怎么提需求。
我虽然提供了GET和POST方法之间的主要区别,但是具体的实现和应用还是得取决于浏览器和服务器的配置和要求。
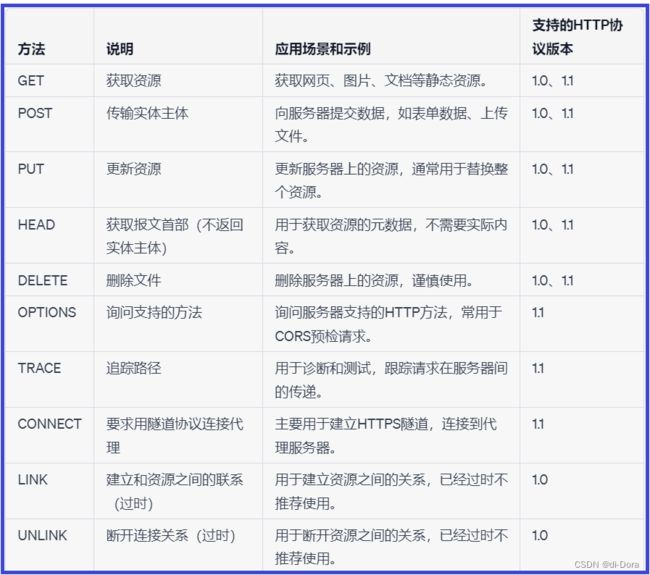
HTTP其他方法
-
PUT:
- PUT方法用于向服务器上传、更新资源。与POST相似,但具有幂等特性,多次执行相同的PUT请求应该产生相同的结果。
- 一般用于替换服务器上的资源。
-
DELETE:
- DELETE方法用于删除服务器上的指定资源。对服务器的状态产生更改。
-
OPTIONS:
- OPTIONS方法请求服务器返回所支持的HTTP请求方法,通常用于跨域请求中的预检请求(CORS预检请求)。
-
HEAD:
- HEAD方法类似于GET,但响应中不包含实体主体,只返回响应头信息。通常用于检索资源的元数据而不需要实际内容。
-
TRACE:
- TRACE方法用于回显服务器端接收到的请求,通常用于诊断和测试。对于安全性考虑,应该谨慎使用。
-
CONNECT:
- CONNECT方法是预留的,目前很少使用。通常用于建立代理服务器隧道,通常在HTTPS连接时使用。
我们提到这些HTTP方法可以使用Ajax或网络编程语言来构造,任何能进行网络编程的语言都可以构造HTTP请求,实质上就是通过TCP socket发送符合HTTP协议规则的字符串。
这些HTTP的请求最初的初心其实就是未来表示不同的语义。可是在现在的实际使用过程中,这个初心已经被遗忘了。HTTP的各种请求目前来说已经不一定完全遵守自己的规定了,你可以更加随意的使用。
HTTP请求详解
认识请求 "报头" (header)
请求头(header)是HTTP请求中的一部分,用于携带关于请求的元数据和其他信息。
HTTP请求头通常采用键值对的格式,每个键值对占一行,键和值之间使用冒号分隔(而不是分号)。
请求头提供了有关请求的重要信息,包括请求的方法、URL、主机、内容类型、身份验证凭证等等。
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Connection: keep-alive
在上面的示例中,每个键值对表示一个请求头,例如,"Host"头部指定了请求的主机名,"User-Agent"指定了发送请求的用户代理,"Accept"头部指定了接受的内容类型等等。
HTTP请求头是HTTP请求的一部分,它提供了关于请求的元数据信息,它们以键值对的格式表示,而不是使用分号分隔。
报头的种类有很多, 此处我们仅介绍几个常见的。
1、Host:
定义与用途: 指定请求的服务器主机地址和端口。
示例: Host: www.example.com
这个信息在URL中也是存在的。但是在使用代理的情况下,Host的内容可能和URL中的内容不同。
2、Content-Length:
定义与用途: 指定请求主体或响应主体的数据长度,以字节为单位。
示例: Content-Length: 1234
非必须,请求里面有body才会有这个属性。通常情况下,GET请求里面就没有,POST就有。
TCP涉及到粘包问题,HTTP在传输层就是基于TCP的。使用同一个TCP连接,传输多个HTTP数据报,此时就会使多个GTTP数据包在TCP接收缓冲区中挨在一起。接收方解析的时候就需要能够清楚HTTP数据包之间的边界。
对于GET这种没有body的请求,直接使用空行作为分隔符;
对于POST这种有body的请求,就需要结合空行和Content-Length。
3、Content-Type:
- 定义与用途: 指定请求或响应主体的数据格式,即body中数据的格式。
- 常见选项和格式:
- application/x-www-form-urlencoded:
- 表单提交的标准数据格式。
- 例如:key1=value1&key2=value2
- multipart/form-data:
- 通常用于表单提交,尤其是涉及到文件或图片上传。
- 数据以边界(boundary)分隔。
- 例如:
Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="text" title ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png ... content of chrome.png ... ------WebKitFormBoundaryrGKCBY7qhFd3TrwA-- - application/json:
- 用于传输JSON格式的数据。
- 例如:{"username":"123456789","password":"xxxx"}
- application/x-www-form-urlencoded:
非必须,请求里面有body才会有这个属性。通常情况下,GET请求里面就没有,POST就有。
请求头部提供了关于请求内容和其他元数据的关键信息,帮助服务器正确解析和响应请求。
HTTP请求和响应的body中的格式可以有多种选择,取决于数据的类型和需求。以下是一些常见的HTTP请求和响应body中的格式:
HTTP请求body中的格式:
- JSON:常用于向服务器发送结构化的数据,如API请求。
- from表单的格式(相当于是把query string给搬到body中):通过application/x-www-form-urlencoded格式,通常用于HTML表单提交。
- 多部分表单数据,from=data的格式(上传文件的时候会涉及到,当然也不一定,也有可能是from表单,之前的上传图片就是,只是一个key一个value,但是这个value作为图片,非常大):通过multipart/form-data格式,常用于文件上传。
- XML:用于传输和接收XML格式的数据。
- 文本:纯文本数据,无格式。
HTTP响应body中的格式:
- HTML:通常用于呈现网页内容。


- JSON:用于API响应,传输结构化数据。

- 图像:如JPEG、PNG、GIF等,用于传输图像文件。
- CSS:用于定义页面样式。


- JavaScript:用于客户端执行脚本。


- XML:用于传输和接收XML格式的数据。
- 文本:纯文本数据,无格式。


后续给服务器提交给请求不同的 Content-Type ,服务器处理数据的逻辑也是不同的。服务器返回数据给浏览器们也需要设置合适的 Content-Type,浏览器也会根据不同的 Content-Type做出不同的处理。
其中响应中的HTML、CSS、JavaScript构成网页的主体,HTML表示页面的骨架,CSS表示页面的样式,JavaScript 表示页面的行为。
4、User-Agent(简称 UA)
定义与用途:表示发送请求的用户代理的属性,通常是浏览器或其他客户端应用。描述里你使用什么设备上网。
格式与内容:
UA字符串通常包含操作系统、硬件类型、浏览器以及浏览器的渲染引擎等信息。
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36
Windows NT 10.0; Win64; x64 表示操作系统版本信息。
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 表示浏览器版本和其使用的渲染引擎信息。
背景与历史:
-
User-Agent(UA)字符串的格式和内容常常受到历史遗留问题的影响。在互联网的早期,网站的内容相对简单,而浏览器之间的差异也很大。为了提供最佳的用户体验,网站开发者需要考虑到多个浏览器版本的兼容性。
-
随着时间的推移,网页的内容变得越来越丰富,浏览器更新和升级的速度也加快了。这导致了新旧版本浏览器的并存,因此,开发者既要考虑到老版本浏览器的兼容性,又要确保新版本浏览器用户的体验得到保障。为了解决这个问题,开发者开始使用UA来识别并区分不同的浏览器。UA中记录了浏览器的版本、所支持的特性等信息,这为开发者提供了巨大的帮助。
-
然而,随着各大浏览器厂商争夺市场份额,为了确保网站能够在其浏览器上正确显示,浏览器开始在UA字符串中包含其他浏览器的标识。这导致了UA字符串变得越来越复杂和冗长。
- 现代互联网的发展已经使得大多数浏览器之间的差异变得很小。现在的前端开发技术,如“响应式网页”编程,使得同一个HTML页面能够很好地适应不同的设备和浏览器。因此,UA的重要性已经大大降低,现在它主要被用来识别是PC端还是移动端。
- 由于这种标识的历史原因,现代浏览器的 User-Agent 字符串包含了大量的信息,这有时会导致隐私和安全问题。因此,有一些提议和措施正在考虑修改或简化 User-Agent 字段的内容,以提高用户隐私。
- 现在浏览器的差异已经很小了,此时UA的作用也就没有那么关键了。现在UA主要是用来区分是PC端还是移动端。这样的区分一般只是为了进行统计,而不会返回不同版本的页面。现在前端开发有“响应式网页”编程技术,同一个HTML很好的兼容不同的设备。
总之,User-Agent 请求头部字段提供了关于请求来源的用户代理的详细信息,这有助于服务器为不同的设备、操作系统或浏览器提供适当的响应。
5、Referer
定义与用途:
- Referer表示当前请求的来源页面(是从哪里跳转来的),即引导用户前往当前页面的页面的URL。
- 它用于记录用户从哪个页面跳转到当前页面,以帮助网站分析流量和用户导航。
- 当用户直接在浏览器地址栏中输入URL或者通过点击书签/收藏夹中的链接来访问网页时,通常不会发送Referer头部字段。这是因为Referer字段是由上一个页面传递给当前页面的,但在这种情况下,没有上一个页面。因此,浏览器不会发送Referer信息。
Referer字段通常用于标识从哪个页面跳转过来,以便网站或服务器了解用户的访问来源。但在直接输入URL或使用书签的情况下,没有上一个页面可供标识,因此没有Referer信息发送到目标网页。
-
用户点击广告之后,广告平台每次跳转之前都会先跳转到一个计费服务器,再跳转到广告主的页面。广告主通过记录日志就知道点击情况了。
-
广告主也可能会在很多不同的平台投放广告,广告主的服务器就需要区分出哪些请求是来自A,哪些请求又是来自B?我们通过Referer就可以进行区分(域名不同)
-
是否会存在一种情况?有人把Referer给改了,本来是“搜狗”的广告,结果跳转到了别的广告平台?在早期的互联网中,确实存在运营商或中间人劫持的情况,其中修改HTTP请求或响应中的信息,如Referer,是其中的一种手法。这种行为通常是为了注入广告或跟踪用户活动,甚至可能用于监视和搜集用户的数据。因为网络数据都是通过运营商的设备(路由器/交换机)转发的,运营商通过在路由器上部署一些特定的程序,就很容易能够获取到,也就很容易篡改。所以后面就使用HTTTPS来替代HTTP,HTTP最大的问题在于“明文传输”,这就容易被第三方获取并篡改。而HTTPS对HTTP的数据进行了加密,第三方想要获取并篡改就没那么容易了,通过这个手段就可以有效地遏制运营商劫持。
-
HTTPS的广泛采用是一个重要的改进,因为它通过加密通信来保护数据的完整性和隐私,使运营商或其他恶意第三方更难以篡改用户的数据。HTTPS的加密机制通过使用SSL/TLS协议来实现,确保了数据在传输过程中的保密性。
运营商劫持等恶意行为在HTTPS广泛采用后变得更加困难,因为HTTPS通信中的数据在客户端和服务器之间进行端到端的加密,防止了中间人的干预。此外,Web浏览器和网站也会检测证书,以确保与服务器建立安全的HTTPS连接。
尽管HTTPS提供了更高的安全性,但仍然可能存在一些其他安全漏洞和攻击,例如钓鱼攻击、恶意证书颁发等。因此,大家都需要保持警惕,并确保采取适当的安全措施,以降低潜在威胁的风险。同时,不断更新和改进网络协议和安全措施也是网络安全的一部分。
示例:
- Referer: https://www.example.com/previous-page
注意:
- 如果用户直接在浏览器中输入URL、使用收藏夹访问页面,或者通过其他方式访问页面而没有从其他页面跳转过来,
Referer字段可能为空或缺失。
6、 Cookie
定义与用途:
- Cookie 字段用于在HTTP请求和响应之间存储和传递数据,可以被认为是浏览器在本地存储数据的一种机制。
- 浏览器的数据来自于服务器,浏览器后续的操作也是要提交给服务器的。服务器这边管理了一个网站的核心数据。但程序运行过程中也会有一些数据需要在浏览器这里储存,并且在后续请求的时候数据可能需要再发给服务器,比如上次登录的时间、上次访问的时间、用户的身份信息、累积的访问次数……这些临时性的数据存储在浏览器中是比较合适的。
- 实际上我们更容易想到的方法是把这样的数据直接存储到本地文件中。但是实际上是不可行的。浏览器为了考虑安全性,禁止网页直接访问你的电脑的文件系统(病毒杀毒),网页代码也就无法直接生成一个硬盘的文件来存储数据了。
- 为了保证安全性,又能进行存储数据,于是就引入了Cookie,也是按照硬盘文件的方式保存的,但是浏览器把操作文件给封装了,网页只能往Cookie里面存储键值对,也就是一些简单的字符串。
- Cookie是一种用于在客户端(通常是浏览器)和服务器之间存储小段数据的机制。这些数据以键值对的形式存储,通常是程序员自己定义的。这些键值对可以包含一些简单的字符串,通常用于存储用户会话信息、首选项、身份验证令牌等。
- 数据通常以键值对的形式存储在Cookie中的,这里的键值对是程序猿自己定义的(和 query string 类似)
- Cookie往往是从服务器返回的数据,可以由服务器返回给客户端,也可以由页面的JavaScript代码自己生成并存储在客户端。服务器通常在HTTP响应头中设置Cookie,而浏览器会将它们存储在客户端的硬盘上。客户端的JavaScript代码可以通过浏览器的Document对象来创建、读取和修改Cookie。
- Cookie存储到浏览器所在主机的硬盘上,并且是按照域名的维度来存储的,每个域名可以在客户端存储自己的Cookie数据,这些Cookie是与特定域名关联的。不同域名之间的Cookie通常是相互隔离的,它们不会互相访问或共享数据。
- 当浏览器再次请求同一服务器时,它会自动将相关Cookie包含在HTTP请求的Cookie头中,发给服务器,服务器可以读取这些Cookie,就会通过Cookie的内容做一些逻辑上的处理,例如身份验证或用户会话跟踪。
- 总的来说就是:Cookie保存了一些给程序员使用的数据。
示例:
- Cookie: username=johndoe; sessionid=123456
- 键值对之间使用 ;分割,键和值使用 = 分割。
- 这些内容就是浏览器本地存储的Cookie,都会在后续请求服务器的时候把这些内容自动代入到请求中,发给服务器,服务器就通过Cookie的内容做一些逻辑上的处理。
关于域名和Cookie:
- 每个不同的域名(网站)可以有自己的Cookie,这些Cookie在不同网站之间不会冲突。
- 通过HTTP响应的Set-Cookie头部字段,服务器可以向浏览器设置Cookie数据。
Referer和Cookie是HTTP请求头部字段的一部分,它们提供了在Web应用程序中进行跟踪和标识的功能,用于了解用户行为和提供个性化服务。
前期准备
通过抓包观察网页登录过程是一种常见的方式来了解网络通信和验证身份的过程。以下是一般的步骤,以观察码云登录过程为例:
-
安装抓包工具:
- 首先,你需要安装一个网络抓包工具。一些常见的抓包工具包括Fiddler、Wireshark、Charles等,你可以根据你的需求和操作系统选择一个合适的工具。
-
启动抓包工具:
- 启动你选择的抓包工具,并设置它以侦听本地网络流量。
-
清除浏览器中的Cookie:
- 打开你的浏览器,登录到码云账户(或你要观察的目标网站)。
- 在浏览器中,清除之前存在的Cookie。这通常可以在浏览器的设置或开发者工具中找到。你可以通过清除浏览器的Cookie来模拟"未登录"状态,以便观察登录过程。
-
进行登录:
- 在浏览器中,输入你的用户名和密码并尝试登录到码云(或目标网站)。
-
观察抓包工具:
- 回到抓包工具,你应该能够看到登录请求和响应的细节,包括HTTP头部信息和Cookie。
-
查看登录请求和响应:
- 查看抓包工具中的请求和响应数据。你应该能够看到包含用户名和密码的POST请求,以及来自服务器的响应,可能包括登录凭据的Cookie。
-
分析数据:
- 通过分析这些数据,你可以了解登录过程的细节,包括请求头部、POST数据、响应头部和Cookie的使用。
这个过程允许你深入了解网站登录的内部工作原理,并可以帮助你识别如何实施身份验证和会话管理等功能。请注意,进行网络抓包时,请遵守相关法律和道德规范,不要滥用这些信息。
登陆操作
登陆请求
POST https://gitee.com/login HTTP/1.1
Host: gitee.com
Connection: keep-alive
Content-Length: 394
Cache-Control: max-age=0
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Upgrade-Insecure-Requests: 1
Origin: https://gitee.com
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
Referer: https://gitee.com/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
encrypt_key=password&utf8=%E2%9C%93&authenticity_token=36ZqO9tglSN6EB6pF6f2Gt%2B
dalgkbpTDUsJC5OER7w8%3D&redirect_to_url=%2FHGtz2222&user%5Blogin%5D=HGtz2222&enc
rypt_data%5Buser%5Bpassword%5D%5D=Hy2gjJ60312Ss12jSe21GMLPEb766tAhCygL281FLRMpiz
xJVaWGOPlQF7lZhelab1HS2vBiwfBo5C7BnR5ospoBiK1hR6jNXv1lesaYifv9dP1iRC6ozLLMszo%2F
aRh5j5DeYRyKcE0QJjXRGEDg4emXEK1LHVY4M1uqzFS0W58%3D&user%5Bremember_me%5D=0这是一个示例的登录请求,采用POST方法,发送到https://gitee.com/login。以下是请求头的详细解释,按照你之前提供的格式:
登录请求头部
-
请求方法和URL:
- 请求方法:
POST - URL:
https://gitee.com/login
- 请求方法:
-
Host:
- 表示服务器主机的地址和端口。
- 示例:
Host: gitee.com
-
Connection:
- 指定连接选项,此处为保持连接。
- 示例:
Connection: keep-alive
-
Content-Length:
- 表示请求主体(body)的长度,以字节为单位。
- 示例:
Content-Length: 394
-
Cache-Control:
- 控制缓存行为的指令。
- 示例:
Cache-Control: max-age=0
-
User-Agent:
- 表示用户代理(浏览器和操作系统)的属性。
- 示例:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36
-
Accept:
- 指定客户端可接受的内容类型。
- 示例:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
-
Content-Type:
- 指定请求主体的数据格式,此处为
application/x-www-form-urlencoded,表示表单数据。 - 示例:
Content-Type: application/x-www-form-urlencoded
- 指定请求主体的数据格式,此处为
-
Referer:
- 表示请求的来源页面的URL,通常是登录页面。
- 示例:
Referer: https://gitee.com/login
-
Accept-Encoding:
- 指定客户端可接受的内容编码。
- 示例:
Accept-Encoding: gzip, deflate, br
-
Accept-Language:
- 指定客户端接受的语言。
- 示例:
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
-
请求主体 (Body):
- 请求主体包含用户的登录信息,通常以键值对的形式传递,如
encrypt_key=password、user[login]=HGtz2222等。
- 请求主体包含用户的登录信息,通常以键值对的形式传递,如
这个请求头部用于将登录信息发送到https://gitee.com/login,以进行用户身份验证。服务器将使用请求主体中的数据来验证用户并进行相应的操作。请注意,登录请求通常包含用户名和密码等敏感信息,应该使用安全的HTTPS连接来保护这些数据的传输。
登陆响应
HTTP/1.1 302 Found
Date: Thu, 10 Jun 2021 04:15:58 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Keep-Alive: timeout=60
Server: nginx
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
X-UA-Compatible: chrome=1
Expires: Sun, 1 Jan 2000 01:00:00 GMT
Pragma: must-revalidate, no-cache, private
Location: https://gitee.com/HGtz2222
Cache-Control: no-cache
Set-Cookie: oschina_new_user=false; path=/; expires=Mon, 10 Jun 2041 04:16:00
-0000
Set-Cookie: gitee_user=true; path=/
Set-Cookie: gitee-sessionn=M1Rhbk1QUUxQdWk1VEZVQ1BvZXYybG13ZUJFNGR1V0pSYTZyTllEa21pVHlBUE5QU2Qwdk44NXdEam
11T3FZYXFidGNYaFJxcTVDRE1xU05GUXN0ek1Uc08reXRTay9ueTV3OGl5bTdzVGJjU1lUbTJ4bTUvN1
l3RFl4N2hNQmI1SEZpdmVJWStETlJrdWtyU0lDckhvSGJHc3NEZDFWdHc5cjdHaGVtNThNcEVOeFZlaH
c0WVY5NGUzWjc2cjdOcCtSdVJ0VndzdVNxb3dHK1hPSDBDSFB6WlZDc3prUVZ2RVJyTnpTb1c4aFg1Mm
UxM1YvQTFkb1EwaU4zT3hJcmRrS3dxVFZJNXoxaVJwa1liMlplbWR5QXQxY0lvUDNic1hxN2o0WDg1Wk
E9LS10N0VIYXg4Vm5xdllHVzdxa0VlUEp3PT0%3D-
-2f6a24f8d33929fe88ed19d4dea495fbb40ebed6; domain=.gitee.com; path=/; HttpOnly
X-Request-Id: 77f12d095edc98fab27d040a861f63b1
X-Runtime: 0.166621
Content-Length: 92
You are being redirected.
这是一个示例的登录响应,HTTP响应代码为302 Found,表示重定向。
可以看到, 响应中包含了 3 个 Set-Cookie 属性. 其中我们重点关注第三个. 里面包含了一个 gitee-session-n 这样的属性, 属性值是一串很长的加 密之后的信息。这个信息就是用户当前登陆的身份标识. 也称为 "令牌(token)"
以下是响应头和主体的详细解释:
登录响应头部
-
HTTP版本和状态码:
- HTTP版本:HTTP/1.1
- 状态码:302 Found
-
Date:
- 指定响应的日期和时间。
- 示例:
Date: Thu, 10 Jun 2021 04:15:58 GMT
-
Content-Type:
- 指定响应主体的内容类型。
- 示例:
Content-Type: text/html; charset=utf-8
-
Connection:
- 指定连接选项,此处为保持连接。
- 示例:
Connection: keep-alive
-
Keep-Alive:
- 指定保持连接的超时时间。
- 示例:
Keep-Alive: timeout=60
-
Server:
- 指定服务器名称和版本信息。
- 示例:
Server: nginx
-
X-XSS-Protection:
- 启用或禁用浏览器的跨站脚本攻击保护。
- 示例:
X-XSS-Protection: 1; mode=block
-
X-Content-Type-Options:
- 指定浏览器是否应该嗅探响应中的内容类型。
- 示例:
X-Content-Type-Options: nosniff
-
X-UA-Compatible:
- 指定浏览器的兼容性模式。
- 示例:
X-UA-Compatible: chrome=1
-
Expires:
- 指定响应的过期时间。
- 示例:
Expires: Sun, 1 Jan 2000 01:00:00 GMT
-
Pragma:
- 指定缓存策略,如必须重新验证、不缓存等。
- 示例:
Pragma: must-revalidate, no-cache, private
-
Location:
- 重定向的目标URL,表示登录成功后用户将被重定向到
https://gitee.com/HGtz2222。 - 示例:
Location: https://gitee.com/HGtz2222
- 重定向的目标URL,表示登录成功后用户将被重定向到
-
Cache-Control:
- 控制缓存行为的指令,此处指示不缓存。
- 示例:
Cache-Control: no-cache
-
Set-Cookie:
- 设置Cookie,其中包括
oschina_new_user和gitee_user等Cookie。 - 示例:
Set-Cookie: oschina_new_user=false; path=/; expires=Mon, 10 Jun 2041 04:16:00 -0000 Set-Cookie: gitee_user=true; path=/ Set-Cookie: ...
- 设置Cookie,其中包括
-
X-Request-Id:
- 响应中的请求ID。
- 示例:
X-Request-Id: 77f12d095edc98fab27d040a861f63b1
-
X-Runtime:
- 服务器处理请求的运行时间。
- 示例:
X-Runtime: 0.166621
响应主体
响应主体是一个HTML文档,包含了重定向消息,告诉用户他们将被重定向到https://gitee.com/HGtz2222。这是一个常见的登录成功后的操作,用户将被重定向到他们的个人页面或其他受保护的区域。
这个响应表明登录成功,并且用户的身份验证状态已更新,将被重定向到新的URL。登录后,用户的身份将由gitee_user Cookie来维护,这个Cookie将在登录成功后的响应头中设置。
重定向是常见的用户身份验证操作之一,它允许用户成功登录后被自动导航到他们的目标页面,以提供良好的用户体验。
访问其他页面
登陆成功之后, 此时可以看到后续访问码云的其他页面(比如个人主页), 请求中就都会带着刚才获取到的 Cookie 信息
GET https://gitee.com/HGtz2222 HTTP/1.1
Host: gitee.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,imag
e/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: navigate
Sec-Fetch-User: ?1
Sec-Fetch-Dest: document
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
Referer: https://gitee.com/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-
4358-aa73-472762c79dc0; visit-gitee--2021-05-06%2010%3A12%3A24%20%2B0800=1;
sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22726826%22%2C%22first_id%22%3
A%22175869ba5888b6-0ea2311dc53295-303464-2073600-
175869ba5899ac%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E
7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%
9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%2
4latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%22175869ba5888b6-
0ea2311dc53295-303464-2073600-175869ba5899ac%22%7D; remote_way=svn;
tz=Asia%2FShanghai;
Hm_lvt_24f17767262929947cc3631f99bfd274=1622637014,1622712683,1622863899,1623298
442; Hm_lpvt_24f17767262929947cc3631f99bfd274=1623298550; gitee_user=true; giteesessionn=M1Rhbk1QUUxQdWk1VEZVQ1BvZXYybG13ZUJFNGR1V0pSYTZyTllEa21pVHlBUE5QU2Qwdk44NXdEam
11T3FZYXFidGNYaFJxcTVDRE1xU05GUXN0ek1Uc08reXRTay9ueTV3OGl5bTdzVGJjU1lUbTJ4bTUvN1
l3RFl4N2hNQmI1SEZpdmVJWStETlJrdWtyU0lDckhvSGJHc3NEZDFWdHc5cjdHaGVtNThNcEVOeFZlaH
c0WVY5NGUzWjc2cjdOcCtSdVJ0VndzdVNxb3dHK1hPSDBDSFB6WlZDc3prUVZ2RVJyTnpTb1c4aFg1Mm
UxM1YvQTFkb1EwaU4zT3hJcmRrS3dxVFZJNXoxaVJwa1liMlplbWR5QXQxY0lvUDNic1hxN2o0WDg1Wk
E9LS10N0VIYXg4Vm5xdllHVzdxa0VlUEp3PT0%3D-
-2f6a24f8d33929fe88ed19d4dea495fbb40ebed6这是一个示例的GET请求,用于访问 https://gitee.com/HGtz2222 登陆成功之后的页面。以下是请求头的详细解释,:
GET请求头部
-
请求方法和URL:
- 请求方法:
GET - URL:
https://gitee.com/HGtz2222
- 请求方法:
-
Host:
- 表示服务器主机的地址和端口。
- 示例:
Host: gitee.com
-
Connection:
- 表示连接方式,这里是保持连接。
- 示例:
Connection: keep-alive
-
Cache-Control:
- 控制缓存的行为,这里是不使用缓存。
- 示例:
Cache-Control: max-age=0
-
Upgrade-Insecure-Requests:
- 表示是否允许不安全的请求升级为安全的请求。
- 示例:
Upgrade-Insecure-Requests: 1
-
User-Agent:
- 表示浏览器和操作系统的属性,用于标识客户端。
- 示例:
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36
-
Accept:
- 表示客户端可以接受的媒体类型。
- 示例:
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
-
Sec-Fetch-Site:
- 表示请求目标的站点类型,这里是"same-origin",表示同源请求。
- 示例:
Sec-Fetch-Site: same-origin
-
Sec-Fetch-Mode:
- 表示请求模式,这里是"navigate",表示导航请求。
- 示例:
Sec-Fetch-Mode: navigate
-
Sec-Fetch-User:
- 表示请求用户,这里是"?1",表示请求用户已经存在。
- 示例:
Sec-Fetch-User: ?1
-
Sec-Fetch-Dest:
- 表示请求目标的类型,这里是"document",表示文档请求。
- 示例:
Sec-Fetch-Dest: document
-
sec-ch-ua:
- 表示浏览器和操作系统的属性。
- 示例:
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
-
sec-ch-ua-mobile:
- 表示浏览器在移动设备上的属性。
- 示例:
sec-ch-ua-mobile: ?0
-
Referer:
- 表示请求是从哪个页面跳转过来的。
- 示例:
Referer: https://gitee.com/login
-
Accept-Encoding:
- 表示客户端可以接受的编码方式,例如gzip、deflate等。
- 示例:
Accept-Encoding: gzip, deflate, br
-
Accept-Language:
- 表示客户端的语言偏好。
- 示例:
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
-
Cookie:
- 表示之前获取到的Cookie信息,用于在服务器端识别用户。
- 示例:包含多个Cookie键值对,如
Cookie: oschina_new_user=false; user_locale=zh-CN; ...
这个GET请求包含了之前登录成功后获取的Cookie信息,用于访问个人主页
请求你中的 Cookie 字段也包含了一个 gitee-session-n 属性, 里面的值和刚才服务器返回的值相 同。 后续只要访问 gitee 这个网站, 就会一直带着这个令牌, 直到令牌过期/下次重新登陆。
理解登陆过程
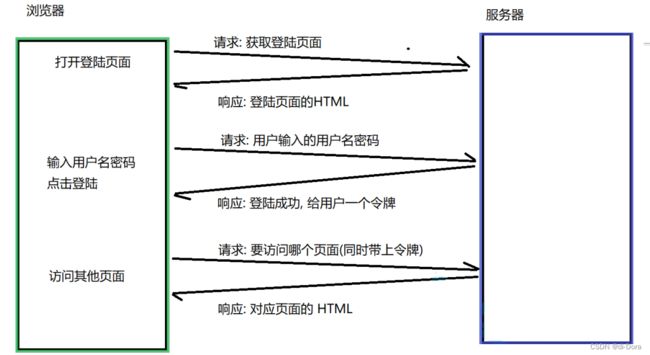
这个过程和去医院看病很相似:
-
到医院挂号:
- 在网站上,这相当于首次访问网站并填写登录信息(如用户名和密码)。
- 提供身份证等于提供你的用户名和密码。
- 得到“就诊卡”相当于从服务器收到一个用于后续识别的令牌或Cookie。
-
后续去各个科室:
- 当你浏览一个登录后才能访问的页面或进行其他操作时,你不需要再次输入用户名和密码。这是因为你的浏览器会自动发送那个令牌或Cookie,告诉服务器你是谁。
- 这就像用就诊卡来证明自己的身份,而不是每次都出示身份证。
-
看完病后注销就诊卡:
- 在网站上,这类似于点击“注销”或“退出登录”按钮。这通常会使当前的令牌或Cookie失效,这样即使其他人得到了它也不能用它来伪装成你。
- 如果你的就诊卡丢了,它不会泄露你的身份证信息,因为它只是一个令牌,不包含敏感信息。
-
再次来医院看病:
- 如果你想再次访问受限制的内容,你需要重新登录,这时服务器会为你生成一个新的令牌或Cookie。
- 这就像每次去医院时都需要重新办理一个新的就诊卡。
通过这个比喻,我们可以更容易地理解身份验证的原理,以及令牌和Cookie在其中的作用。这也强调了为什么在使用完后应该注销令牌或Cookie,以保护自己的账户安全。
认识请求 "正文" (body)
正文中的内容格式和 header 中的 Content-Type 密切相关。 上面也罗列了三种常见的情况。
HTTP请求正文(Request Body)是HTTP请求的一部分,它包含了客户端发送给服务器的数据或内容。请求正文的内容格式通常与请求头中的Content-Type字段密切相关,Content-Type字段指定了请求正文的数据类型和格式。
以下是几种常见的请求正文示例,每种示例与不同的Content-Type相关:
1、application/x-www-form-urlencoded:这是一种常见的请求正文格式,通常用于HTML表单提交。数据以键值对的形式编码,并以application/x-www-form-urlencoded格式发送给服务器。示例:
Content-Type: application/x-www-form-urlencoded
user=username&password=pass123这个请求正文包含了用户的用户名和密码。
2、application/json:JSON格式的请求正文通常用于通过JSON对象发送数据给服务器。示例:
Content-Type: application/json
{
"name": "John",
"age": 30,
"city": "New York"
}这个请求正文包含了一个JSON对象,描述了用户的名称、年龄和所在城市。
3、multipart/form-data:这种格式通常用于文件上传,允许在请求正文中包含文件数据。示例:
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="file"; filename="example.jpg"
Content-Type: image/jpeg
(binary data for the file)这个请求正文包含了一个文件,文件名为"example.jpg"。
HTTP请求正文的内容可以根据应用程序的需求和HTTP请求的目的而有所不同。Content-Type字段用于指定请求正文的数据类型和编码方式,以确保服务器能够正确解释和处理请求的内容。服务器会根据Content-Type的值来解析请求正文,并采取相应的操作,无论是提交表单数据、JSON对象,还是上传文件。
下面可以通过抓包来观察这几种情况:
(1)application/x-www-form-urlencoded,抓取码云上传头像请求
POST https://gitee.com/profile/upload_portrait_with_base64 HTTP/1.1
Host: gitee.com
Connection: keep-alive
Content-Length: 107389
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Accept: */*
X-CSRF-Token: 6ROfZGr4Y7Qx8td1TuKCnrG8gbODLCSUqUBZSw2b+ac=
X-Requested-With: XMLHttpRequest
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Origin: https://gitee.com
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://gitee.com/HGtz2222
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: oschina_new_user=false; user_locale=zh-CN; yp_riddler_id=1ce4a551-a160-
4358-aa73-472762c79dc0; visit-gitee--2021-05-06%2010%3A12%3A24%20%2B0800=1;
sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%22726826%22%2C%22first_id%22%3
A%22175869ba5888b6-0ea2311dc53295-303464-2073600-
175869ba5899ac%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E
7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%
9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%2
4latest_referrer%22%3A%22%22%7D%2C%22%24device_id%22%3A%22175869ba5888b6-
0ea2311dc53295-303464-2073600-175869ba5899ac%22%7D; remote_way=svn;
tz=Asia%2FShanghai;
Hm_lvt_24f17767262929947cc3631f99bfd274=1622637014,1622712683,1622863899,1623298
442; gitee_user=true; Hm_lpvt_24f17767262929947cc3631f99bfd274=1623298560; giteesessionn=c0hXQ0I5SjR1bWg5M01IR3RYS3hLT0RhelN1aFVuMExKdEdSSmRaQWIwRy9QWFUwV0thdzV1alIzYj
RaOU9ZeDdkZEJZK2RtTVRNeTNFRHNYVW9ha2hEcWJyclIwS1NVRG1EL0xxTmJXSGxvSzh3c28zOHBia1
pIOFQrU3RYeWE0bE13S09DTm5MZWZ5WW5WUVFpSzFiMGFWbHRDQ0xRakc1Um5yY21HQllqeUpNLzBvZF
gxbHVhN09uK2h1VVVmRHZkS3BmVGEwcDhyNjJVb1p0RFRLY0VOem5vNEEvd0FuYzJJYlhZcGlyenZQc3
dSbXBNUWI3UUwrRDBrV2N0UHZRdjFBUXF5b0Y0L1Vrd09pQVBKNkdjZmY5cHlDTCtMWG4ya0tIaW5LcE
tBTkw4cGFGVjhUQ0djMWhkOXI0bUFteUY4VW80RHl2T2Q2YmxwR1d3M3Rad1RhZWhhdnNiTTNrcE1RV2
NyZ1dYeDRoR0dpanh4bERNMTBuenB1NkgxLS16QUdJS3NlZG9mTVBtYlVlREppck1BPT0%3D-
-898d1284181ca494918d29ac44f9a3a79d448a9b
avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0Ss
LAAAg......实际的抓包结果比较长, 此处没有全部贴出。
这是一个通过POST请求上传用户头像的示例。让我们来分析一下这个请求:
-
请求方法:这是一个HTTP POST请求。
-
请求目标:请求的URL是https://gitee.com/profile/upload_portrait_with_base64
-
请求头部:
- Host: gitee.com 是请求的主机名。
- Connection: keep-alive 表示要保持长连接。
- Content-Length: 107389 表示请求正文的长度为107389字节。
- sec-ch-ua, Accept, X-CSRF-Token, X-Requested-With, sec-ch-ua-mobile, User-Agent, Content-Type, Origin, Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest, Referer, Accept-Encoding, Accept-Language, Cookie 这些都是请求头的字段,它们包含了与请求相关的各种信息,包括用户代理信息(User-Agent),请求的来源(Referer),Cookie等。
-
请求正文(Body):
- 这是一个表单形式(application/x-www-form-urlencoded)的请求。请求正文中包含了用户头像的数据。
- avatar=data%3Aimage%2Fpng%3Bbase64%2CiVBORw0KGgoAAAANSUhEUgAAAPgAAAD4CAYAAADB0SsLAAAg... 是头像数据的一部分。这部分可能包含了用户头像的图像数据,以Base64编码的方式表示。
这个请求的主要目的是将用户头像数据上传到指定的URL。请求头中包含了一些与请求相关的信息,包括用户代理(User-Agent)、来源(Referer)、Cookie等。请求正文中包含了头像数据,可以由服务器来解析和处理。
(2)multipart/form-data 抓取系统的 "上传简历" 功能:
POST https://v.bitedu.vip/tms/oss/upload/file HTTP/1.1
Host: v.CSDN.vip
Connection: keep-alive
Content-Length: 293252
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
Authorization: Bearer
eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbl91c2VyX2tleSI6IjFiYThjMDM5LWUyN2UtNDdhZS04YTAzLTN
mNWMzY2UwN2YyNSJ9.VQWoqrrgWZpDNc81tYfSvna8A9uZP6QKqucnvGMuY8wbavHF30rx7NG9VxnAo1
78V0nOJBd75QxRvNRgpY6-Iw
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Content-Type: multipart/form-data; boundary=----
WebKitFormBoundary8d5Rp4eJgrUSS3wT
Accept: */*
Origin: https://v.bitedu.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.baidu.vip/personInf/student?userId=634
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=2342412223; AdminToken=eyJhbGciOiJIUzUxMiJ9.eyJsb2dpbleSI6IjFiYThjMDM5LWUyN2UtNDdhZS04Y
TAzLTNmNWMzY2UwN2YyNSJ9.VQWoqrrgWZpDNc81tYfSvna8A9uZP6QKqucnvGMuY8wbavHF30rx7NG9
VxnAo178V0nOJBd75QxRvNRgpY6-Iw
------WebKitFormBoundary8d5Rp4eJgrUSS3wT
Content-Disposition: form-data; name="file"; filename="李星亚 Java开发工程师.pdf"
Content-Type: application/pdf
%PDF-1.7
%³
1 0 obj
<> /Outlines 5 0 R /Pages 2 0 R /Type /Catalog>>
endobj
3 0 obj
<>
endobj
13 0 obj
<>
endobj实际的抓包结果比较长, 此处没有全部贴出。
这是一个通过POST请求上传文件的示例,使用的是multipart/form-data格式。让我来分析这个请求:
-
请求方法:这是一个HTTP POST请求。
-
请求目标:请求的URL是https://v.CSDN.vip/tms/oss/upload/file。
-
请求头部:
- Host: v.CSDN.vip 是请求的主机名。
- Connection: keep-alive 表示要保持长连接。
- Content-Length: 293252 表示请求正文的长度为293252字节。
- sec-ch-ua, Authorization, sec-ch-ua-mobile, User-Agent, Content-Type, Accept, Origin, Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest, Referer, Accept-Encoding, Accept-Language, Cookie 这些都是请求头的字段,它们包含了与请求相关的各种信息,包括用户代理信息(User-Agent)、授权信息(Authorization)、请求的来源(Referer)、Cookie等。
-
请求正文(Body):
- 这是一个multipart/form-data格式的请求。请求正文以------WebKitFormBoundary8d5Rp4eJgrUSS3wT开始,然后包含了文件数据。
- Content-Disposition 字段中的name属性表示字段的名称,filename属性表示上传文件的原始文件名。
- Content-Type 字段表示上传的文件类型为application/pdf,PDF文件。
- 接下来是文件内容,这里显示了PDF文件的一些内容。
这个请求的主要目的是将一个文件上传到指定的URL,文件的名称是"李星亚 Java开发工程师.pdf",文件类型为PDF。请求头中包含了一些与请求相关的信息,包括用户代理(User-Agent)、授权信息(Authorization)、来源(Referer)、Cookie等。请求正文以multipart/form-data格式包含了文件数据。
(3) application/json 抓取系统的 "上传简历" 功能:
POST https://v.bitedu.vip/tms/login HTTP/1.1
Host: v.CSDN.vip
Connection: keep-alive
Content-Length: 105
sec-ch-ua: " Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"
sec-ch-ua-mobile: ?0
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/91.0.4472.101 Safari/537.36
Access-Control-Allow-Methods: PUT,POST,GET,DELETE,OPTIONS
Content-Type: application/json;charset=UTF-8
Access-Control-Allow-Origin: *
Accept: application/json, text/plain, */*
Access-Control-Allow-Headers: Content-Type, Content-Length, Authorization,
Accept, X-Requested-With , yourHeaderFeild
Origin: https://v.CSDN.vip
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Sec-Fetch-Dest: empty
Referer: https://v.CSDN.vip/login
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: rememberMe=true; username=123456789
{"username":"123456789","password":"xxxx","code":"u58u","uuid":"9bd8e09ea27b48cd
acc6a6bc41d9f462"}
这是一个通过POST请求发送JSON数据的示例。下面是对这个请求的分析:
-
请求方法:这是一个HTTP POST请求。
-
请求目标:请求的URL是 https://v.CSDN.vip/tms/login 。
-
请求头部:
- Host: v.bitedu.vip 是请求的主机名。
- Connection: keep-alive 表示要保持长连接。
- Content-Length: 105 表示请求正文的长度为105字节。
- sec-ch-ua, sec-ch-ua-mobile, User-Agent, Access-Control-Allow-Methods, Content-Type, Access-Control-Allow-Origin, Accept, Access-Control-Allow-Headers, Origin, Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest, Referer, Accept-Encoding, Accept-Language, Cookie 这些都是请求头的字段,包含了与请求相关的各种信息,包括用户代理信息(User-Agent)、允许的请求方法(Access-Control-Allow-Methods)、CORS相关信息、来源(Referer)、Cookie等。
-
请求正文(Body):
- 请求正文以JSON格式发送,Content-Type 字段指明了请求的内容类型为application/json;charset=UTF-8,字符编码为UTF-8。
- JSON数据包含在大括号 {} 内,包含了以下字段:
- username: "123456789"
- password: "xxxx"
- code: "u58u"
- uuid: "9bd8e09ea27b48cdacc6a6bc41d9f462"
这个请求的主要目的是向 https://v.CSDN.vip/tms/login 发送一个JSON数据,包含了用户名、密码、验证码等信息。请求头中包含了一些与请求相关的信息,包括用户代理(User-Agent)、CORS设置、来源(Referer)、Cookie等。
HTTP 响应详解
HTTP响应是服务器对客户端请求的回复。每次你在浏览器中输入一个URL、点击一个链接或者通过其他方式进行网络请求,都会收到一个HTTP响应。HTTP响应由三部分组成:状态行、响应头和响应正文。
状态行:这是响应的第一行,包含了HTTP版本、状态码和状态描述。例如:"HTTP/1.1 200 OK"。
认识 "状态码" (status code)
HTTP响应的状态码(Status Code)是用于表示请求处理结果的三位数字代码,表示访问一个页面的结果。每个状态码对应一种不同的响应情况,用于通知客户端发出的请求是否成功,或者出现了什么问题。
状态码:状态码是一个三位数,用于表示请求的处理结果。状态码的第一个数字定义了响应的类别:
1xx:信息响应。表示请求已接收,继续处理。2xx:成功。表示请求已被成功接收、理解和接受。3xx:重定向。要完成请求,需要进一步操作。4xx:客户端错误。请求包含语法错误或无法完成。5xx:服务器错误。服务器在处理请求时发生错误。
以下是一些常见的HTTP状态码:
-
200 OK:这是最常见的状态码,表示请求已成功处理。服务器已返回请求的数据。
-
201 Created:表示请求已经成功,并且服务器创建了一个新的资源,通常在POST请求成功后返回。
-
204 No Content:表示请求已成功处理,但响应不包含实体主体。通常用于DELETE请求。
-
400 Bad Request:客户端请求有语法错误,服务器无法理解。
-
401 Unauthorized:表示需要进行身份验证或者认证信息无效,通常要求用户提供有效的用户名和密码。
-
403 Forbidden:服务器已经理解请求,但拒绝执行它,通常是因为权限不足。
-
404 Not Found:请求的资源未找到。
-
500 Internal Server Error:表示服务器在执行请求时出现了错误,客户端通常无法解决。
-
502 Bad Gateway:服务器作为网关或代理,从上游服务器接收到无效响应。
-
503 Service Unavailable:服务器当前无法处理请求,通常是因为服务器过载或正在维护。
这些状态码帮助客户端理解请求的结果,根据不同的状态码,客户端可以采取相应的行动。HTTP协议还有许多其他状态码,每个状态码都有特定的含义。理解这些状态码有助于开发者和系统管理员更好地诊断和解决HTTP请求和响应的问题。
认识重定向
重定向是一种HTTP响应机制,用于将客户端请求从一个URL(通常是A)重定向到另一个URL(通常是B)。重定向是服务器向客户端发出的指令,告诉客户端重新发起请求,但这次请求的目标是新的URL。
HTTP重定向通常用于以下情况:
-
永久重定向——资源永久移动:HTTP状态码301 Moved Permanently表示资源的位置已永久移动到新的URL,客户端应该将以后的请求直接发送到新的URL。可缓存。
-
临时重定向——资源临时移动:HTTP状态码302 Found表示资源的位置已临时移动到新的URL,客户端应该发送下一个请求到新的URL。这个重定向可能只是暂时的。不可缓存。
-
登录或认证:网站可能要求用户登录或提供身份验证信息才能访问某些资源。如果用户尚未登录或未提供必要的身份验证信息,服务器可能返回一个重定向响应,将用户引导到登录页面。
-
URL重写或规范化:有时,服务器将对URL进行规范化或重写,以确保一致性和遵循最佳实践。这可以通过重定向来实现。
很多时候页面跳转也可以通过重定向来实现,还有的时候某个网站/服务器迁移了(IP/域名改变),就可以给旧的地址一个重定向响应,访问地址就会
重定向在Web开发和网站维护中非常常见,用于多种情况,包括页面跳转和处理服务器迁移。以下是一些常见的应用情景:
-
页面跳转:重定向经常用于实现页面跳转,如从一个URL重定向到另一个URL。这可以用于用户登录后自动跳转到他们的个人资料页面,或者从旧的URL跳转到新的URL以维护网站的结构和导航。
-
服务器迁移:当网站的服务器或IP地址发生变化时,服务器可以向旧的地址发送重定向响应,将访问者引导到新的地址。这有助于确保旧的链接仍然有效,避免了断裂的链接和丢失的访问者。
-
SEO优化:在搜索引擎优化(SEO)方面,重定向是维护网站的排名和搜索引擎索引的关键工具。当网页的URL结构发生变化时,通过使用301永久重定向,可以将搜索引擎引导到新的URL,以确保排名和索引的连续性。
-
身份验证和授权:网站可能会使用重定向来引导用户进行身份验证,例如在用户未登录时将他们重定向到登录页面。一旦登录成功,他们将被重定向回原始请求的页面。
重定向是HTTP协议的一个强大特性,它允许网站管理者以一种用户友好的方式维护网站结构,同时确保访问者能够访问所需的内容。这对于提供良好的用户体验和维护网站的可用性至关重要。
总的来说,重定向是HTTP中的一种重要机制,允许服务器将客户端请求引导到新的URL,以实现资源的移动、登录、规范化等目的。客户端收到重定向响应后,会自动向新的URL重新发送请求。
200 OK
这是一个最常见的状态码, 表示访问成功。
抓包抓到的大部分结果都是 200:
例如访问搜狗主页:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 10 Jun 2021 06:07:27 GMT
Content-Type: text/html; charset=utf-8
Connection: keep-alive
Vary: Accept-Encoding
Set-Cookie: black_passportid=; path=/; expires=Thu, 01 Jan 1970 00:00:00
GMT; domain=.sogou.com
Pragma: No-cache
Cache-Control: max-age=0
Expires: Thu, 10 Jun 2021 06:07:27 GMT
UUID: 80022370-065c-49b0-a970-31bc467ff244
Content-Length: 14805