【GEE】5、遥感影像预处理【GEE栅格预处理】
1简介
在本模块中,我们将讨论以下概念:
- 了解常用于遥感影像的数据校正类型。
- 如何直观地比较同一数据集中不同预处理级别的空间数据。
- 如何在 Google Earth Engine for Landsat 8 表面反射率图像中执行云遮蔽和云遮蔽评估。
2背景
什么是预处理?
您将在 Google 地球引擎 (GEE) 中找到的大部分数据都经过了一定程度的预处理。这涉及几种不同的质量控制方法,以确保栅格集合内的最高准确性和一致性。根据收集的不同,可能有各种可用的预处理级别,了解差异以将遥感数据成功整合到生态研究中非常重要。在 GEE 中提供数据之前,出版商一致解决了图像产品的三个常见错误来源:大气(即空气化学)、地形(即高程)和几何(即像素一致性)。
大气校正
随着太阳能从地球表面反弹并返回到我们在太空中的传感器,大气在挡路方面做得很好。这以散射和吸收的形式发生(更多信息,请参见模块 3)。识别和校正这些影响对于准确表示和解释真实的表面条件非常重要,例如树种叶子色素或城市和农业像素之间的差异。
地形和地形校正
坡度、坡向和高程的照明效应对收集和处理遥感数据提出了额外的挑战。已经开发了多种校正方法,包括使用数字高程模型来预测有问题的地形。如果您的研究是在高海拔地区或地形陡峭的地区进行的,您会很欣慰地知道,地形效果的预处理已由专家负责(尽管出于谨慎和谨慎的考虑,确实存在手动方法)。
几何校正
此过程确保光栅图像的对齐是系统的,并且随着时间的推移以及相对于其他图像的对齐。对于 Landsat,地理配准和正射校正过程是通过独立的地面控制点和先前创建的数字高程模型完成的。对于像 Landsat 这样的档案数据集,确保像素一次又一次、年复一年地排列是最重要的。否则,遥感科学家和生态学家将几乎没有能力进行多时相分析。
重要的是要记住,这些质量保证方法都不是 100% 万无一失的!遵循“了解您的数据”的座右铭,并从质量和数量上仔细检查您的图像。我们将在模块后面展示几个例子。
3使用 Landsat 8 在 Google Earth Engine 中进行预处理
在 Google 地球引擎中提供数据之前拥有(免费!)专门支持和幕后工作,这是一个令人难以置信的优势。但是,您可能仍然发现有必要操作您感兴趣的数据集以促进特定的研究应用。在本模块中,我们将使用 Landsat 8 数据,下图详细介绍了不同处理级别的几个用例。
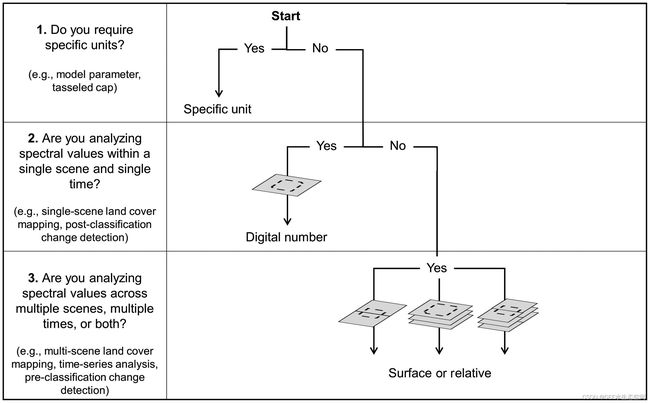
Young et al, 2017 的决策工作流程显示了不同级别 Landsat 数据预处理的建议用例。
的决策工作流程显示了不同级别 Landsat 数据预处理的建议用例。
3.1预处理级别示例。
为了定性地了解不同预处理级别之间的差异,我们可以查看 2018 年夏末美国俄勒冈州南部的几张真彩色图像。在此时间范围内,我们的标准大气干扰因来自加利福尼亚北部的卡尔大火。为了评估我们的初始图像,我们将加载“原始”Landsat 8 集合。原始数据(也称为“传感器辐射”)尚未针对任何形式的潜在影响进行校正,并且通常不用于生态研究。然而,为即将到来的水平建立基线是有帮助的。运行下面的脚本以生成类似于下面的图像。
注意:除了以下预处理级别外,Landsat 数据还分为两个质量级别,第 1 层和第 2 层。第 1 层是更高质量的选项。单击此处了解有关层级之间差异的更多信息。
// Define simple cloud mask, based in values from the 'pixel_qa' band.
// Essentially, values of 322 = land and 324 = water.
var qa = sr.select('pixel_qa');
var mask = qa.eq(322).or(qa.eq(324));
var sr_cm = sr.updateMask(mask);
// Add your new map for comparison to the cloudy image.
Map.addLayer(sr_cm, srvis, 'single_scene_masked');
来自俄勒冈州南部的原始 Landsat 8 图像。我们的图像以 Mt McLoughlin (2,893 m) 为中心,东面是 Upper Klamath Lake。如果缩小图像,则可以看到梅德福(西)和克拉马斯福尔斯(东)这两个城市。
3.2大气层顶(TOA)
下一级预处理采用我们的“原始”数据,并对太阳活动的影响进行校正,包括太阳辐照度、地球-太阳距离和太阳仰角。对于研究人员来说,大气层顶 (TOA) 通常适用于评估单一日期、单一场景的影像(即相对较小研究区域内的土地覆盖分类)。这是由于不同程度的太阳效应取决于收集的日期、时间和纬度。将以下代码附加到您的脚本中,生成的图像将与下图类似。
// Define how your cloudMask function should work.
var cloudMask = function(image) {
// var mask = image.select('pixel_qa').eq(322).or(image.select('pixel_qa').eq(324));
var mask = image.select('pixel_qa').eq(322);
return image.mask(mask);
};
// This time we'll look at a more ecologically-focused example, using NDVI.
var collection = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR")
.filterDate('2018-06-01','2018-09-30')
.filter(ee.Filter.calendarRange(140, 270)) // roughly, our potential growing season
.filterMetadata('WRS_PATH', 'equals', 27)
.filterMetadata('WRS_ROW', 'equals', 26)
.map(cloudMask)
.map(function NDVI(i){
return i.addBands(i.normalizedDifference(['B5','B4']).rename('NDVI')) // generates NDVI band
});
var median = collection.median();
// Red = lower values and darker green = higher values
var collectionVis = {bands: 'NDVI', min: 0.5, max: 0.95, palette: ['red','yellow','green','003300']};
Map.addLayer(median, collectionVis, 'NDVI');
加载 TOA 集合后,由于对太阳效应的影响进行了一些校正,部分图像看起来更清晰。但是,似乎还有工作要做!
3.3表面反射率 (SR)
这些数据已经接受了最高级别的预处理,以试图最好地代表地面上的实际情况,其中一定量的太阳能反弹(反射)到空中和星载传感器。然而,即使是表面反射率产品也会受到低太阳角度、过多云层以及北纬 65 度以上的覆盖位置的不利影响(Young 等人,2017 年)。尽管如此,还是建议对多个日期(例如变化检测)或大地理范围(例如算法预测)的分析使用 Landsat 表面反射率数据。将最后一段代码添加到您的脚本中,以在您的地图查看器窗格中查看下面的图像。
// Finally, source an image from Tier 1 Landsat 8 surface reflection.
var sr = ee.Image('LANDSAT/LC08/C01/T1_SR/LC08_045031_20180811');
// Define the true-color vis params.
var srvis = {bands: ['B4','B3','B2'], min: 0, max: 3000, gamma: 1.4};
// Add the surface reflectance image to your map.
Map.addLayer(sr, srvis, 'sr');
应用大气校正似乎大大提高了我们的图像清晰度,尤其是在上克拉马斯湖和 Mt McGloughlin 以西的农业区。
3.4 Landsat 影像对比的完整代码
这些示例的代码来自一个特定的 Landsat 图像,但您现在拥有一个框架来调查任何感兴趣的区域(即您的研究区域)以比较不同级别的预处理。
// Center our map on southern Oregon, USA.
Map.setCenter(-122.3158, 42.4494, 12);
// Import Tier 1 Raw Landsat 8 scene.
var raw = ee.Image('LANDSAT/LC08/C01/T1/LC08_045031_20180811');
// Define the true-color vis params.
var rawvis = {bands: ['B4','B3','B2'], min: 0.0, max: 30000.0, gamma: 1};
// Add the raw image to your map.
Map.addLayer(raw, rawvis, 'raw');
// To begin your comparison, bring in an image from Tier 1 Landsat 8 Top of Atmosphere.
var toa = ee.Image('LANDSAT/LC08/C01/T1_TOA/LC08_045031_20180811');
// Define the true-color vis params.
var toavis = {bands: ['B4','B3','B2'], min: 0.0, max: 0.4};
// Add the TOA image to your map.
Map.addLayer(toa, toavis, 'toa');
// Finally, source an image from Tier 1 Landsat 8 surface reflection.
var sr = ee.Image('LANDSAT/LC08/C01/T1_SR/LC08_045031_20180811');
// Define the true-color vis params.
var srvis = {bands: ['B4','B3','B2'], min: 0, max: 3000, gamma: 1.4};
// Add the TOA image to your map.
Map.addLayer(sr, srvis, 'sr');
3.5云遮蔽
正如我们所发现的,当我们得到表面反射率产品时,大气、地形和几何校正的预处理工作已经完成。在 Google Earth Engine 中可用之前,Landsat 数据处理中未包括的一个非常重要的步骤是消除近地天气现象。这通常以云的形式出现。云在热带(即茂密的雨林)和水体上尤其普遍。在本节中,我们将看看后者位于明尼苏达州东北部和安大略省西南部的 Quetico-Superior 地区,由于大面积的云层覆盖,部分地由数百个小到中型湖泊。

夏天的云层聚集在克蒂科省立公园的让湖上空。图片来源:泰伊舒尔克。
3.5.1单图像掩蔽:第 1 部分
让我们从加载我们知道是多云的图像开始。在世界的这个地区有很多选择,但这张八月下旬的图片向我们展示了多种形式的云。还有一点需要考虑的是,云层会在下面的土地上投下阴影,这进一步扩大了我们最终必须移除的地理范围。启动一个新脚本,运行下面的代码以生成如下图所示的图像。
// Load an initial image to test view a cloudy image.
var sr = ee.Image('LANDSAT/LC08/C01/T1_SR/LC08_027026_20180829');
// Define visparams for true-color image.
var srvis = {bands: ['B4', 'B3', 'B2'], min: 0, max: 3000, gamma: 1.4};
// Add your cloudy image to the map.
Map.addLayer(sr, srvis, 'single_scene');
Map.setCenter(-91.8859, 48.8936, 8.81);
Quetico-Superior 国家上空多云的图像。
3.5.2单图像掩蔽:第 2 部分
现在来处理我们的云问题。Landsat 提供了一个 pixel_qa 波段,简而言之,它根据先前量化的特征(例如云和雾霾的可能性)分配不同的值。您会发现构建云遮罩的代码更复杂,但这是一种从图像中删除那些讨厌的白色斑点的简单、保守的方法。将以下代码附加到现有脚本并重新运行以查看类似于下图的图像。请记住取消选中图层控件中的“single_scene”!
// Define simple cloud mask, based in values from the 'pixel_qa' band.
// Essentially, values of 322 = land and 324 = water.
var qa = sr.select('pixel_qa');
var mask = qa.eq(322).or(qa.eq(324));
var sr_cm = sr.updateMask(mask);
// Add your new map for comparison to the cloudy image.
Map.addLayer(sr_cm, srvis, 'single_scene_masked');
成功移除云和云阴影,但生成的图像不会留下很多可用像素。
3.5.3跨多个日期屏蔽
在带有云层的单个 Landsat 场景中,我们失去了相当多的地理覆盖范围。但是还有另一种方法!我们还可以在多个日期范围内应用掩码。为此,我们需要创建一个函数,我们将在模块 9中详细介绍。现在,使用下面的函数(和其余代码)继续您的脚本。将代码附加到现有脚本中。
虽然 Google Earth Engine 中确实有来自 Landsat 的预制 NDVI 图像集合,但这些数据集仅在 2017 年之前可用。因此,我们还将计算 NDVI 并将其添加到我们的图像集合中。这将使我们能够为 2018 年整个生长季节的每个像素生成一个中值,从而测量研究区域的植被健康状况。重新运行您的代码,生成的图像应如下所示。
// Define how your cloudMask function should work.
var cloudMask = function(image) {
// var mask = image.select('pixel_qa').eq(322).or(image.select('pixel_qa').eq(324));
var mask = image.select('pixel_qa').eq(322);
return image.mask(mask);
};
// This time we'll look at a more ecologically-focused example, using NDVI.
var collection = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR")
.filterDate('2018-06-01','2018-09-30')
.filter(ee.Filter.calendarRange(140, 270)) // roughly, our potential growing season
.filterMetadata('WRS_PATH', 'equals', 27)
.filterMetadata('WRS_ROW', 'equals', 26)
.map(cloudMask)
.map(function NDVI(i){
return i.addBands(i.normalizedDifference(['B5','B4']).rename('NDVI')) // generates NDVI band
});
var median = collection.median();
// Red = lower values and darker green = higher values
var collectionVis = {bands: 'NDVI', min: 0.5, max: 0.95, palette: ['red','yellow','green','003300']};
Map.addLayer(median, collectionVis, 'NDVI');
可视化 2018 年整个生长季节的 NDVI 中值。随意切换不同的背景层。您的图像可能与此处显示的图像不完全相同。
3.5.4可视化图像计数
我们的 NDVI 图像看起来不错。但我们对这些价值观有多大信心?具体来说,重要的是评估实际上有多少图像构成了我们的中值。我们可以通过可视化在每个像素位置使用多少图像的总和来快速检查我们得到的 NDVI 中值是否在整个研究区域具有代表性。将以下代码附加到您的脚本中,然后单击“运行”。您应该会看到类似于下图的图像。
对于计数层,如果我们在 NDVI 值中发现空间异常,则有多种选择。我们可以扩大我们的季节性日期范围或选择包含多年的数据。最终,我们可能会接受失败,并认为天气太阴天无用,并决定探索不同的数据集——这是完全可以接受的!
// Create counts band.
var counts = collection.select('NDVI').count();
// Find our potential maximum count by getting the size of the initial image collection.
print(collection.size());
// In this palette, red = lower values and blue = higher values.
var countVis = {min: 0, max: 6, palette: ['b2182b','ef8a62','fddbc7',
'd1e5f0','67a9cf','2166ac']};
Map.addLayer(counts, countVis, 'counts');
可视化用于计算每个像素中值的图像数量。较深的红色值较低,较深的蓝色值较高。
3.5.5生成和导出直方图
要了解计数值的定量分布,我们可以构建计数数据的直方图。如果我们的研究区域如此多云以至于平均值仅代表一两个值,我们可能需要重新考虑我们的源数据或收集年份。将此最终代码块添加到脚本中,您将能够在控制台选项卡中看到直方图。您将制作自己的几何形状(如果您需要复习如何执行此操作,请参阅模块 1 )。您的直方图可能会根据您的形状略有不同,但它足以包含图像,它应该类似于下图中的分布。
// Draw your own rectangle and try to cover most of the Landsat scene and
// then we'll make a histogram of the distribution. Because the scene area
// is so large GEE requires us to perform some aggregating. But this will
// give us a general sense of our distribution.
var histogram = ui.Chart.image.histogram(counts, geometry, 120);
// Display the histogram.
print(histogram);

使用直方图函数量化来自计数层的值分布的数量。
4结论
在本单元中,我们回顾了应用于遥感图像的一些常见校正,这些校正有助于生产您将在 Google 地球引擎中找到的高质量产品。我们还介绍了一个用于可视化这些差异的简单框架,并了解了处理水平的变化如何影响俄勒冈州南部烟雾缭绕的夏季所产生的图像。最后,我们构建了一个工作流脚本,使用 Google Earth Engine 从生长季节图像中去除云层,生成平均植被指数值,并评估使用图像的分布。
5完整的云屏蔽代码
// Load an initial image to test view a cloudy image.
var sr = ee.Image('LANDSAT/LC08/C01/T1_SR/LC08_027026_20180829');
// Define visparams for true-color image.
var srvis = {bands: ['B4', 'B3', 'B2'], min: 0, max: 3000, gamma: 1.4};
// Add your cloudy image to the map.
Map.addLayer(sr, srvis, 'single_scene')
Map.setCenter(-91.8859, 48.8936, 8.81);
// Define simple cloud mask, based in values from the 'pixel_qa' band.
// Essentially, values of 322 = land and 324 = water.
var qa = sr.select('pixel_qa');
var mask = qa.eq(322).or(qa.eq(324));
var sr_cm = sr.updateMask(mask);
// Add your new map for comparison to the cloudy image.
Map.addLayer(sr_cm, srvis, 'single_scene_masked');
// Define how your cloudMask function should work.
var cloudMask = function(image) {
// var mask = image.select('pixel_qa').eq(322).or(image.select('pixel_qa').eq(324));
var mask = image.select('pixel_qa').eq(322);
return image.mask(mask);
};
// This time we'll look at a more ecologically-focused example, using NDVI.
var collection = ee.ImageCollection("LANDSAT/LC08/C01/T1_SR")
.filterDate('2018-06-01','2018-09-30')
.filter(ee.Filter.calendarRange(140, 270)) // roughly, our potential growing season
.filterMetadata('WRS_PATH', 'equals', 27)
.filterMetadata('WRS_ROW', 'equals', 26)
.map(cloudMask)
.map(function NDVI(i){
return i.addBands(i.normalizedDifference(['B5','B4']).rename('NDVI')) // generates NDVI band
});
var median = collection.median();
// Red = lower values and darker green = higher values.
var collectionVis = {bands: 'NDVI', min: 0.5, max: 0.95, palette: ['red','yellow','green','003300']};
Map.addLayer(median, collectionVis, 'NDVI');
// Create counts band.
var counts = collection.select('NDVI').count();
// Find our potential maximum count by getting the size of the initial image collection.
print(collection.size());
// In this palette, red = lower values and blue = higher values.
var countVis = {min: 0, max: 6, palette: ['b2182b','ef8a62','fddbc7',
'd1e5f0','67a9cf','2166ac']};
Map.addLayer(counts, countVis, 'counts');
// Draw your own rectangle and try to cover most of the Landsat scene and
// then we'll make a histogram of the distribution. Because the scene area
// is so large GEE requires us to perform some aggregating. But this will
// give us a general sense of our distribution.
var histogram = ui.Chart.image.histogram(counts, geometry, 120);
// Display the histogram.
print(histogram);