标准模板库--STL
这里写目录标题
- STL容器
-
- STL诞生
- STL基本概念
- STL六大组件
- STL中的容器、算法、迭代器
- 容器算法迭代器初识
-
- vector存放内置数据类型
- vector存放自定义数据类型
- vector中嵌套vector
- string容器
-
- 构造函数
- 赋值操作
- 字符串拼接
- 字符串查找与替换
- 字符串比较
- 单字符存取(读写)
- 插入与删除
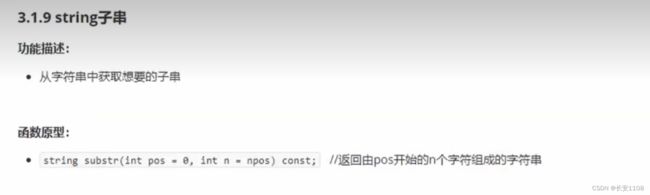
- 获取子串
- vector容器
-
- 简介
- 构造函数
- 赋值操作
- 容量和大小
- 插入和删除
- 数据存取
- 互换容器
-
- 基本操作
- 实际用途
- reserve预留空间
- deque容器(与vector相比 内部是链表)
-
- 简介
- 构造函数
- 赋值操作
- 大小操作
- 插入和删除
- 数据存取
- 排序
- 案例1知识点
-
- 种子
- 随机数
- 随机数种子
- 至于为什么使用deque进行打分
- stack容器
-
- 简介
- queue容器
-
- 简介
- 基本操作
- list容器(链表)
-
- 简介
- 构造函数
- 赋值和交换
- 插入和删除
- 数据存取
- 反转与排序
- set容器
-
- 简介
- 构造和赋值
- 大小和交换
- 插入和删除
- 查找和统计
- set与multiset的区别
- 对组
- 排序
- 自定义数据类型的排序
- map容器
-
- 简介
- 构造和赋值
- 大小与交换
- 插入与删除
- 查找和统计
- 排序
- STL函数对象
-
- 函数对象(仿函数)
- 谓词
-
- 一元谓词
- 二元谓词
- 内建函数对象
-
- 算数仿函数
- 关系仿函数
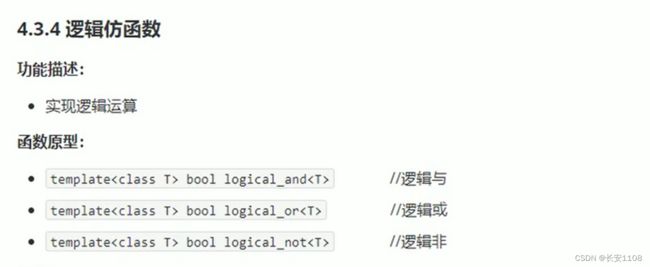
- 逻辑仿函数
- STL常用的算法
-
- 常用遍历算法
-
- for_each
- transform
- 常用查找算法
-
- find
- find_if
- adjacent_find
- binary_search(二分查找)
- count
- count_if
- 常用排序算法
-
- sort
- random_shuffle
- merge
- reverse
- 常用拷贝和替换算法
-
- copy
- replace
- replace_if
- swap
- 常用算数算法
-
- accumulate
- fill
- 常用集合算法
-
- set_intersection
- set_union
- set_defrience
- 演讲比赛项目
-
- while(true)和system(“cls”)
- vector容器赋值
- 随机出小数
- 不同类型运算
- map容器根据key得到value的另一种方法
- 巧用multimap内核进行排序
STL容器
STL诞生

STL基本概念

STL六大组件

STL中的容器、算法、迭代器


容器算法迭代器初识
vector存放内置数据类型

vector是一个系统内置模板类 使用时要包含vector头文件

首先创建一个容器对象 并通过模板参数指定数据类型(当指定类型为int时 就可以认为是一个数组)
之后 调用该容器的成员函数 push_back(数据) 可以将数据以尾插法的形式插入容器中
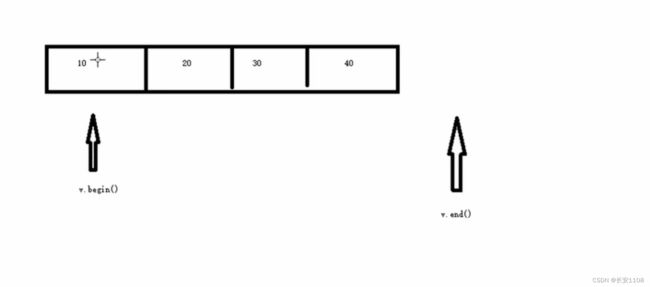
但是想要访问容器中的元素 还需要一个迭代器 每个容器都有自己的迭代器(vector:: 就意为当前容器专属的迭代器),迭代器用来遍历容器中的元素
vector::iterator pBegin = v.begin();
迭代器数据类型 迭代器变量 容器成员函数-用来返回指向容器第一个元素的迭代器
vector::iterator pEnd = v.end();
迭代器数据类型 迭代器变量 容器成员函数-用来返回指向容器最后一个元素的下一位的迭代器
如下图:(可以将迭代器变量视为指针来使用)
接下来是遍历容器中的元素:
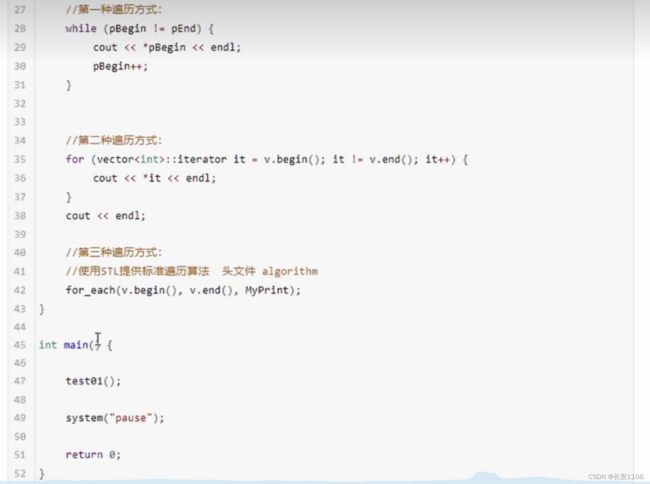
第一种类似于用两个指针来进行遍历 但是只递增一个指针
第二种方式 利用for循环 把创建迭代器与循环结合起来 简化代码
第三种方式 使用STL库里的算法 注意要包含头文件“algorithm”
for_each(首元素迭代器,尾元素后一个元素迭代器,每个元素要经历的函数的函数名(相当于一个函数体 每个元素当做参数))
例如:定义 void MyPrint(int val){
cout<
那么for_each就是一个遍历输出
下面是for_each的源码

vector存放自定义数据类型


it是指向容器元素的指针 所以 *it就是模板参数列表中的参数 如下图 it是Person星 而星it就是Person
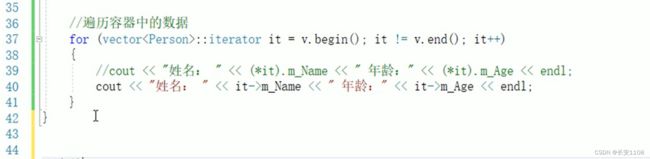

*it就是Person星 因为<>里面是Person星
vector中嵌套vector
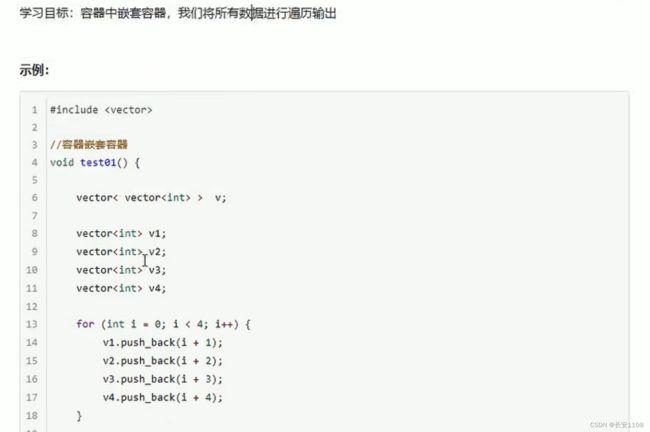
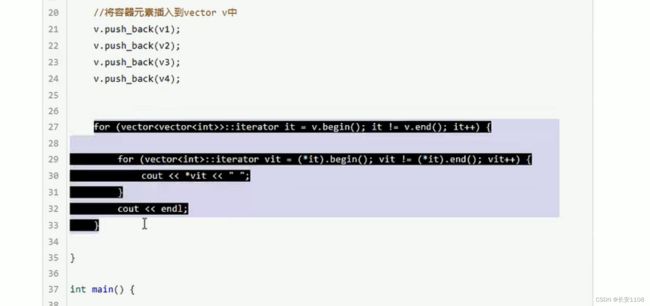
对于循环遍历 外层循环每次都可以获取到一个大元素 该大元素就是vector类型的容器 所以*it也就是vector容器对象 依次指向前面插入的v1,v2,v3,v4。仍然是一个容器对象 并且可以调用其成员函数
所以也就有了内层循环中的变量 以及(*it).begin();
string容器
构造函数

string实际上是一个系统类 其有一个成员属性是char* 所以 string本质上仍然是char * string类中提供了许多成员函数 供我们使用


赋值操作



等号的赋值方法是比较常用的 可以直接字符常量赋值 或者一个字符串赋值给另一个字符串 或者一个字符 也可以赋值给字符串
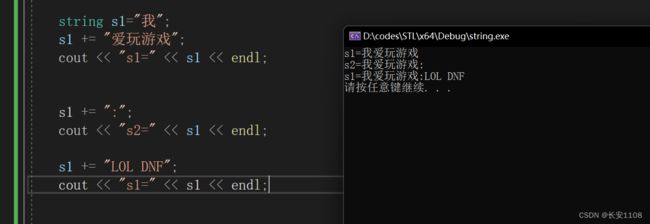
字符串拼接

char* (“helloWorld”)或者string(s) 可以分别称为c形式 与 c++形式 在选择性字符拼接时 c形式只能选前几个 c++形式可以指定从哪个开始 数量几个
注意 函数返回值是引用类型 那么返回的是变量的别名 实际上就是变量 所以s1被拼接后 内容就保存到s1里面了 会跟随者下一次拼接 如下图

字符串查找与替换
里面要注意 替换可以以char* 或者string 可以分别称为c形式 与 c++形式
补充:正常类对象 即“不是常对象” 仍然可以调用成员函数里的常函数

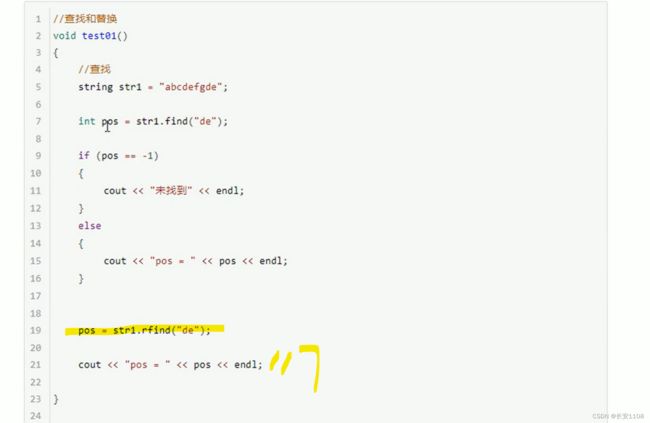
在主串中查找子串 找到了返回子串第一个字符在主串中的位置下标 找不到返回-1
注意 rfind是从右开始查找子串 并返回第一个找到的下标 find是从左开始 返回第一个找到的下标


字符串比较

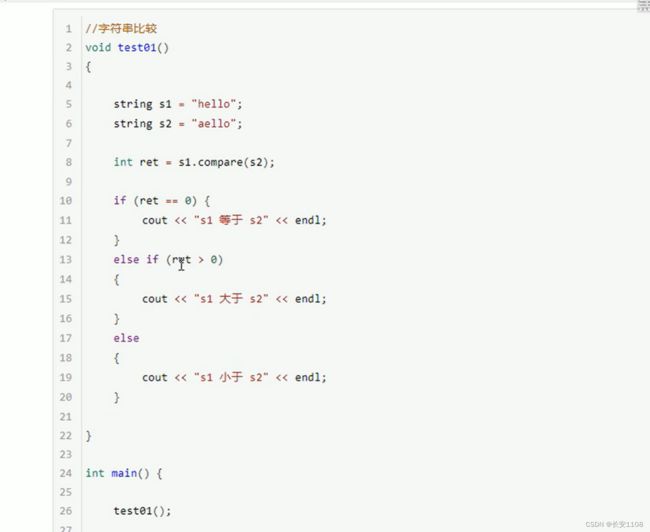
![]()
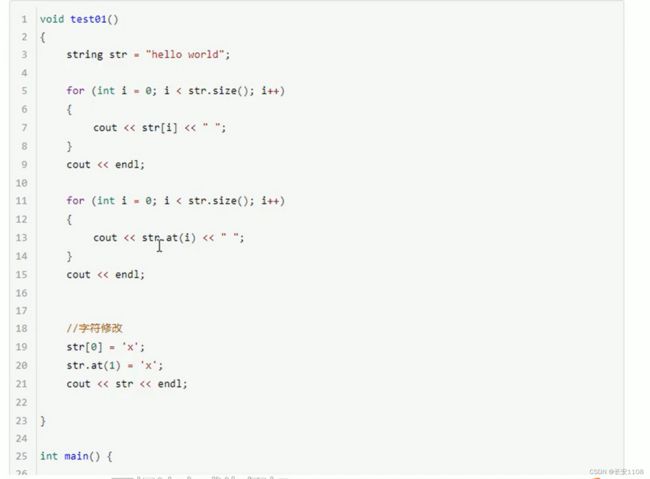
单字符存取(读写)

![]()
读:就是只能获取输出
写:就是可以修改
插入与删除


获取子串
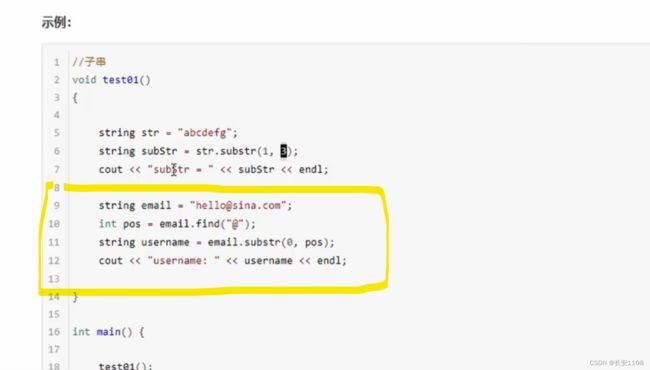
黄框圈起来是一个算法 可以截取@字符之前的字符
首先利用find 返回@字符所在位置下标 因为下标是从0开始 所以下标的值正好是该字符前面的字符数
所以直接带入截取函数中 substr(0,pos);
即可
![]()
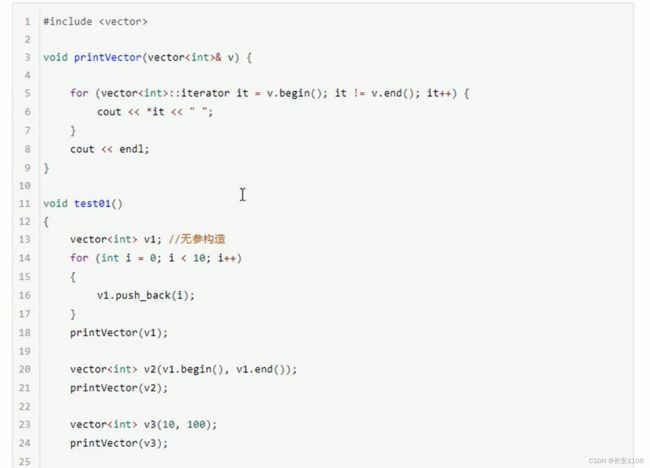
vector容器
简介


v.begin 和 v.end与之前string函数一样 都是返回一个迭代器 功能类似于指针 用于得到容器的单个元素
构造函数

第二个函数参数的作用规则:左闭右开

赋值操作

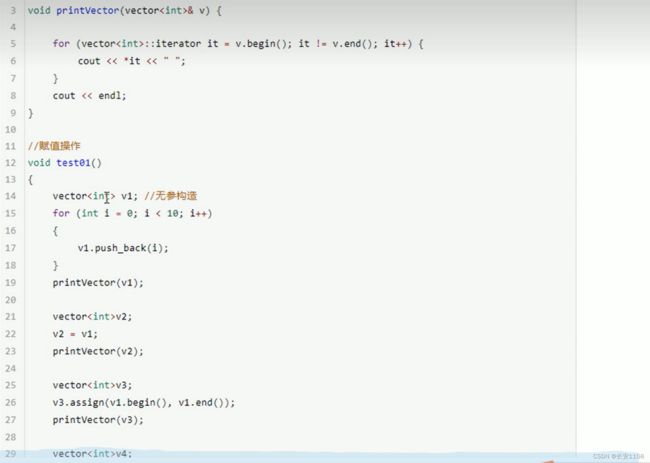
容量和大小

容量:就是该容器一共准备了几个元素的位置
大小:就是该容器中有几个元素
大小小于等于容量 一般大小小于容量 因为编译器会给容量比大小更多的空间 以防万一


若重新设置的大小值 比原来的大 那么超出的部分会用0来占位 (默认)
当然也可以自己指定
注意修改的是size 而不是容量
插入和删除

与string函数不同的是 这里的位置定位要用迭代器
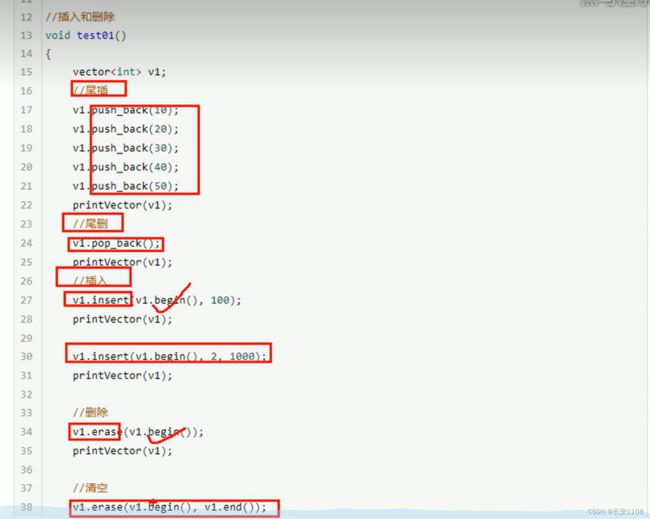

删除时 指定在两个迭代器之间删除元素(如上图) 是左闭右开

数据存取

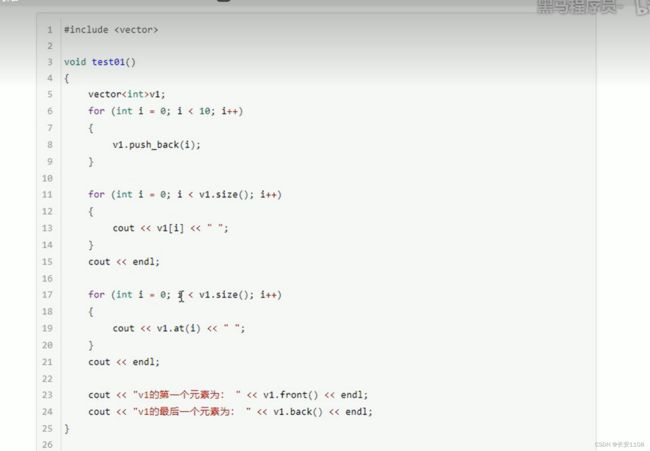

互换容器
基本操作



实际用途

当vector容器的大小被重定义缩小了之后 他的容量并不会变 所以也就造成了内存的浪费
使用swap可以解决这一问题
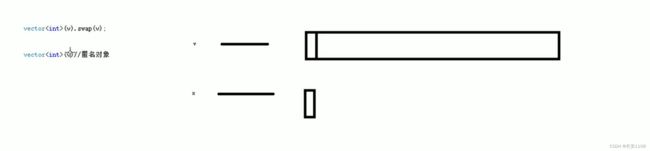
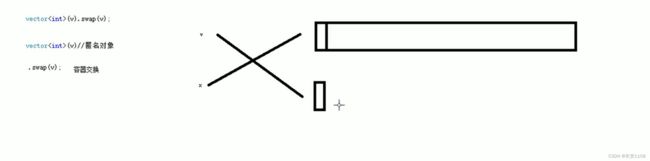
直接vector (v).swap(v) 其中 v是自定义的容器名
因为vector(v) 是一个匿名对象 他调用了拷贝构造 将v拷贝构造了一个新容器 之后调用swap函数 将新容器与旧容器互换
而swap的本质是指针的交换 所以 容器变量v就指向了新的空间 而新空间的匿名对象的指针x 指向了旧空间 又因为x是匿名对象 所以当该行代码执行完之后 匿名对象自动释放
reserve预留空间

当数据量特别大时 编译器会不定时的进行空间的动态扩展 也就是不停的新开辟空间 然后拷贝 之后再新开辟空间 会很耗费时间(尽管我们感受不到)
所以当我们知道了数据的大小之后 就可以先预留这么大的空间 之后编译器就不会一直进行动态拓展了

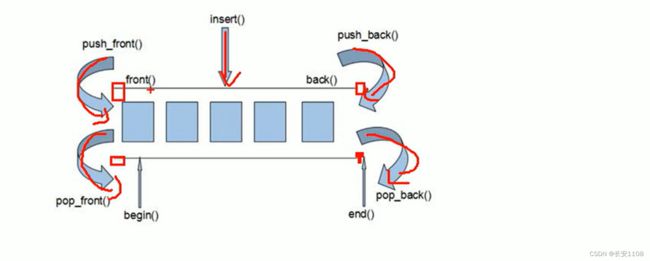
deque容器(与vector相比 内部是链表)
简介

方便头部插入删除
但是不如vector的访问速度快
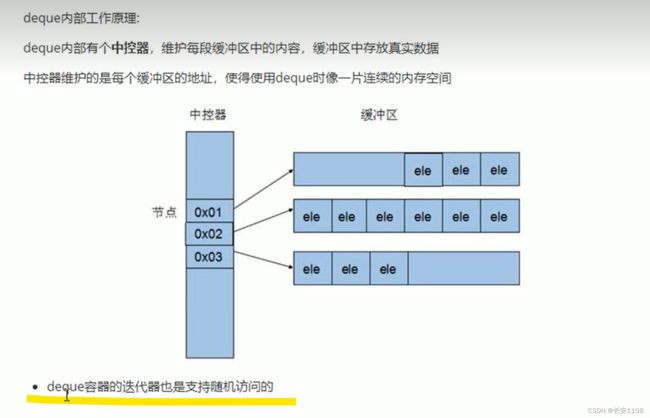
内部类似一个链表
deque的迭代器也是那个最强悍的迭代器 支持随机访问 也就是可以+3 +4 这样访问 不局限于一个一个递增访问
vector迭代器也是这种迭代器
构造函数

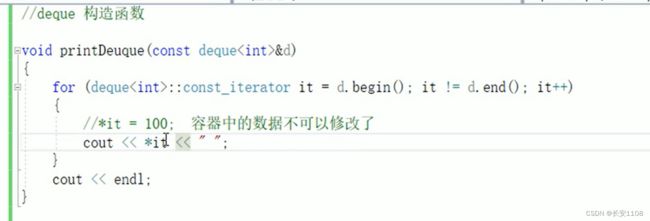
补充:当设置参数的容器只读时 遍历时就不可以使用普通的迭代器了 而是使用只读迭代器 const_iterator 这样该函数体内的容器只有可读权限 不可以被修改


赋值操作


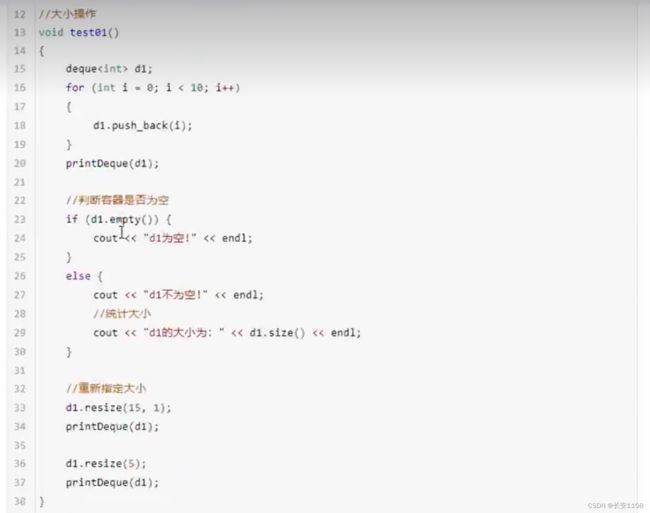
大小操作

因为deque内部是一个链表 所以没有容量的概念 要多少就能给多少

插入和删除

注意上面函数原型中的 pos beg end 都是迭代器 通过begin()函数或者end()函数返回得到




插入和删除的位置都是迭代器提供
数据存取

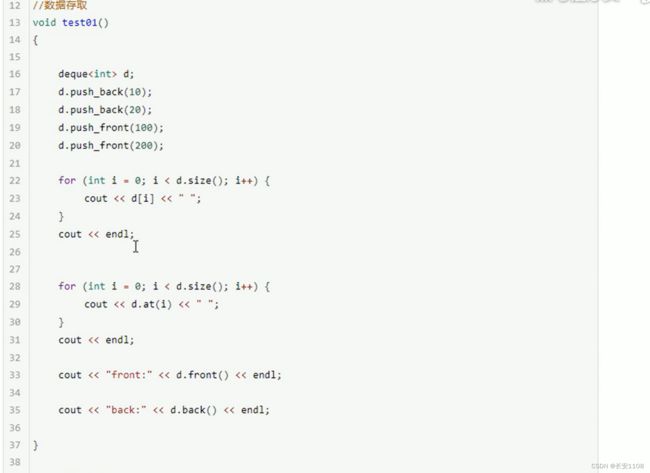

与迭代器的作用相同 都是获取deque容器的元素 但是迭代器的功能更加普适一些 多用于全局函数的设置 比如全局函数的打印 但是【】以及at的方式也可以 多用于函数内部
排序


注意排序函数sort是一个库函数 无需任何对象调用即可使用 参数是某个容器的迭代器

这里说对于支持随机访问的迭代器都可以利用sort算法进行排序 所以vector可以用 但是经过试验 string也可以用
案例1知识点
种子

图中string nameSeed = “ABCDE”
是一个种子 在一个循环里 可以依次拿到他的元素 给一个变量依次赋值 如上图
最终name是 选手+“x”
随机数
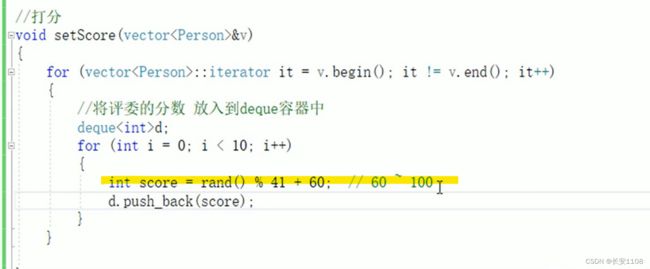
rand()% x + y
首先 rand()%x 的意思是 随机生成0到x-1的随机数 然后 + y 直接根据具体需求使用即可
如上图是 首先生成0到40的随机数
+60之后
最终生成60到100的随机数
随机数种子
问题:
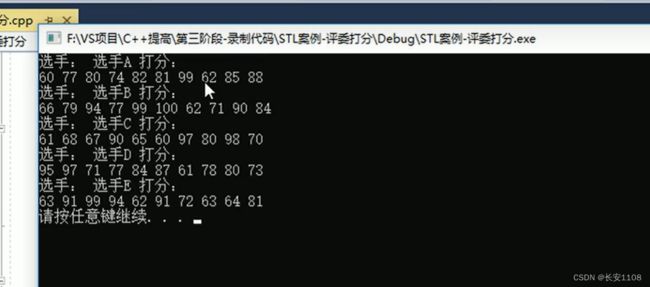
虽然随机数成功生成 但是每次运行 每个选手的随机数都不变 想要真正的实现每次运行也不一样的随机 那么就要加随机数种子
如下:
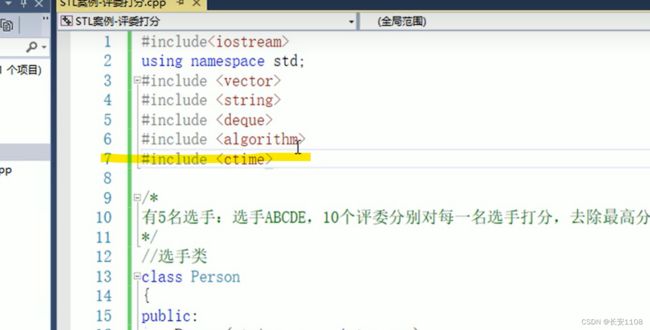
首先包含头文件 ctime

然后在main函数最上面加上这行代码 这就是随机数种子
至于为什么使用deque进行打分

因为deque可以对头部和尾部进行插入和删除 所以方便排序后 删除最大数和最小数
stack容器
简介

这里的栈与数据结构里的栈不同 这里的栈是狭义上的stack容器 在该容器中 系统并没有给他遍历元素函数 他访问元素只有一个函数 就是s.top()可以返回栈顶元素
但是如果输出一个之后就弹出 然后再返回栈顶 虽然可以实现看到所有元素 但是这不叫遍历 因为遍历是不允许动元素 是只读操作 所以移动了元素 就不是遍历 所以不能遍历


注意要弹出栈顶元素 进行循环的终止 不然会陷入死循环

queue容器
简介

基本操作


注意 front返回第一个元素 back返回最后一个元素
!!!注意返回的是元素 大概率是引用类型返回 可以实现链式编程 所以可以“.”出来他的属性进行输出
list容器(链表)
简介
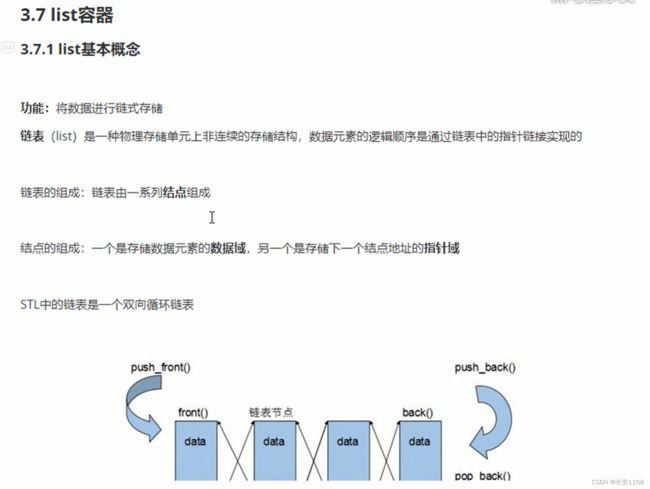
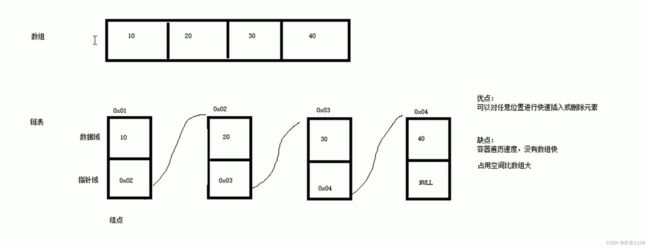
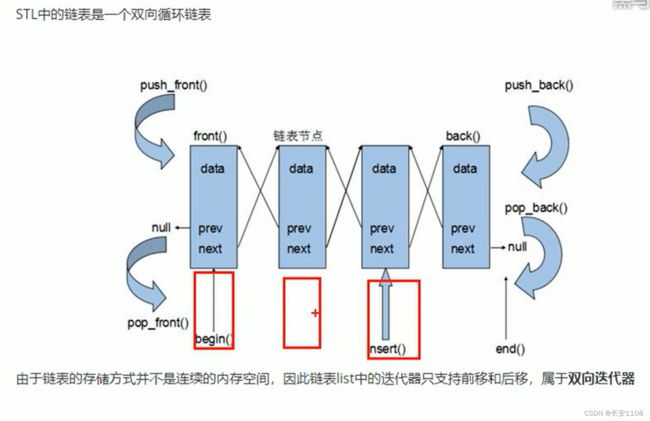
双向循环链表 图中没有体现循环 所以需要将第一个元素的前指针域指向最后一个元素 最后一个元素的指针域指向第一个元素 才是循环链表

具体List的重要性质 如下图解释
在vector容器中 如果容器已满 但是仍然插入元素的话 编译器会重新分配一块更大的空间 所以首地址就变了 所以 迭代器也会跟着变化
(因为迭代器的作用跟指针一样)
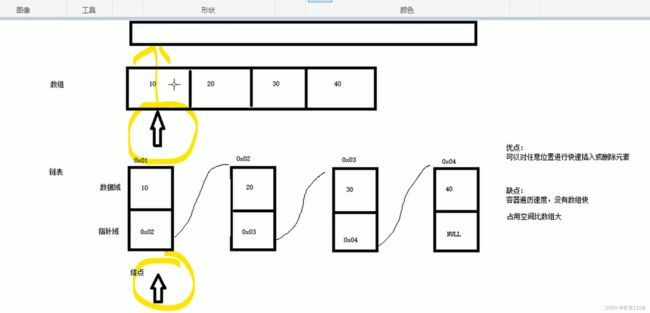
但是在list容器中 因为没有容量的限制 用多少有多少 所以首地址并不会变 那么迭代器也就不会失效
构造函数



赋值和交换



插入和删除

位置定位使用迭代器
注意remove函数 参数是常数 会清除所有与该值匹配的元素
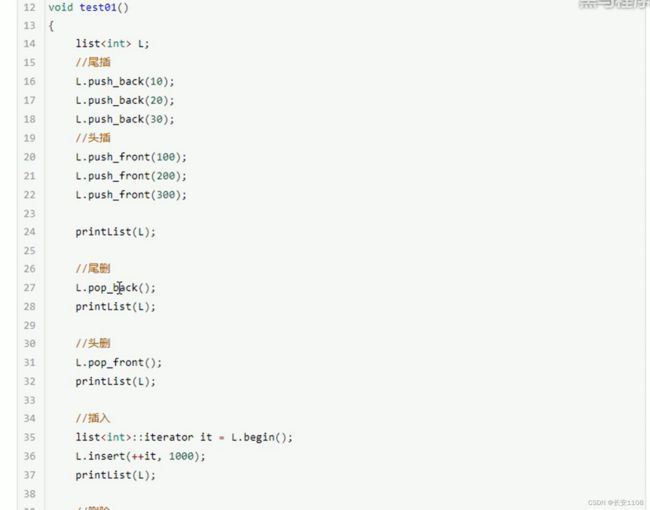

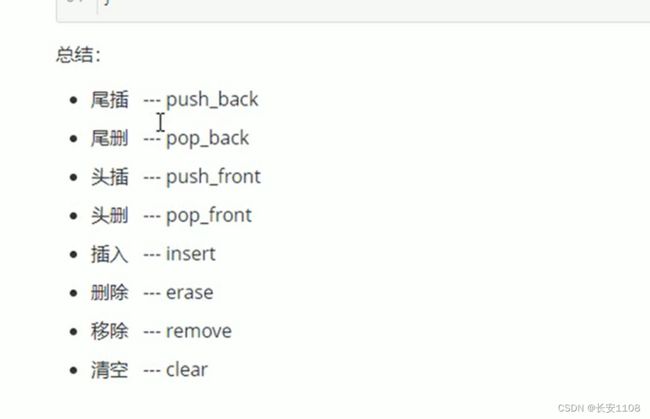
数据存取



由于list是一个链表 而不是连续存储空间 所以 list容器中不可以通过【】或者at来访问元素 只能访问头和尾
补充::


判断迭代器是不是随机访问 :可以+x或者-x就是随机访问(最强迭代器 )x是一个大于0的常数
而单向或者双向迭代器只能++或者–
判断迭代器属于哪种类型可以采用这种方式
反转与排序



注意不支持随机访问迭代器的容器 不可以用标准算法 所以也就不能用sort库函数(或者说系统全局函数)
但是该容器类有一个自己的成员函数 sort 可以使用 从而进行排序

注意 排序默认是升序 但是可以进行重载 传入一个自定义函数 自己定义排序规则 传入两个参数 假设两个参数位置固定 想让其降序 那么直接
v1> v2时 返回真 即可

set容器
简介

实际上set就是一个集合
构造和赋值



set容器没有push_back或者其他的操作 他插入数据只能有insert 同时他插入的数据会自动排序 并且不允许有重复值

大小和交换

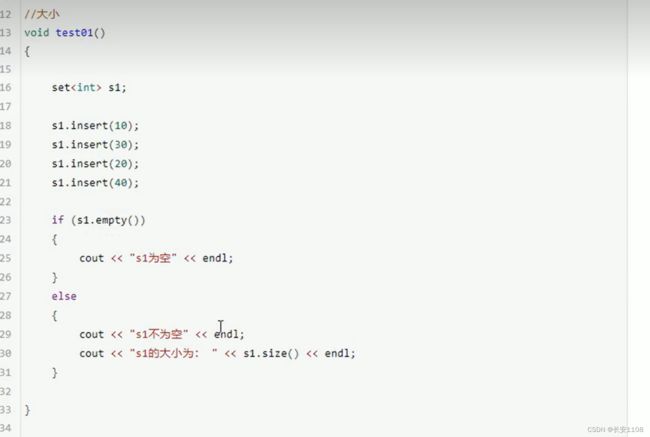


插入和删除


查找和统计

查找的参数是key 也就是传入一个值 就可以返回该值的迭代器
统计也是传入值 但是对于set容器来说 因为不允许重复 所以 返回值不是0 就是 1
不过对于后期的multiset 返回值可能会大于1
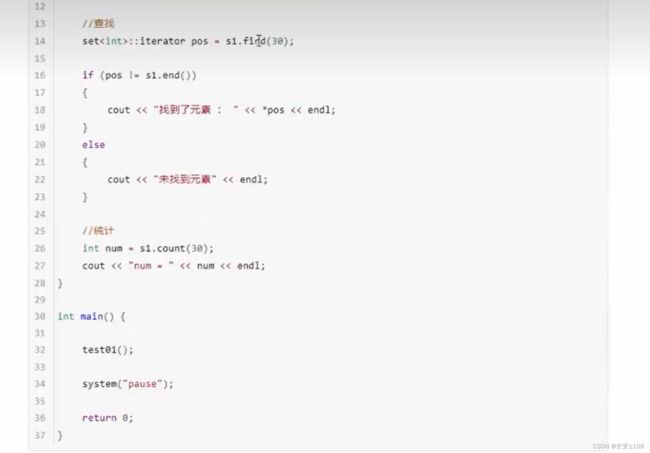

set与multiset的区别

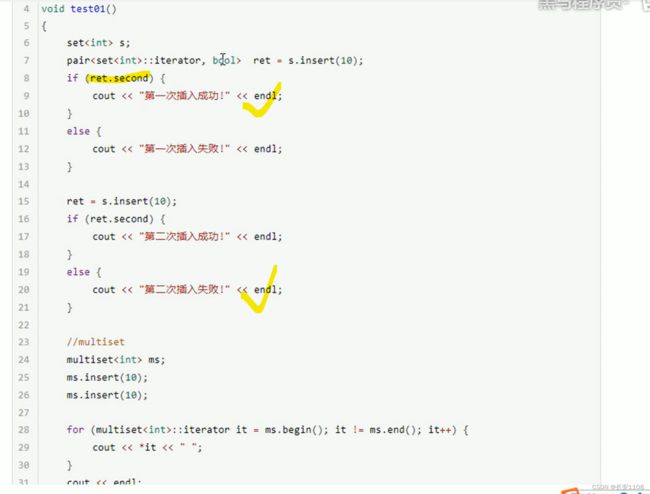
set调用insert会有返回值 返回值是:


返回值是一个pair数对 也就是他返回两个值 一个迭代器 一个bool类型的数
想要查看该数对的其中一个 可以先用一个pair变量接住返回值:pair
然后ret.second 就是获取到了数对的第二个值
如果尝试再次插入已经有的值 会插入失败 bool值为false
对于multiset容器来说 他的返回值只有一个迭代器 因为他只要插入 就会成功 不会出现插入失败的现象 因为他允许重复插入
对组

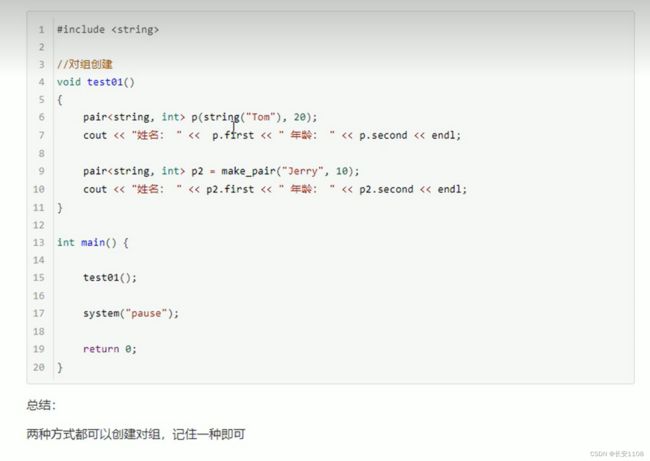
直接创建对组变量 之后调用first 或者 second 成员即可获取
排序

set容器默认会自动按照从小到大的顺序排序 这个排序规则是可修改的
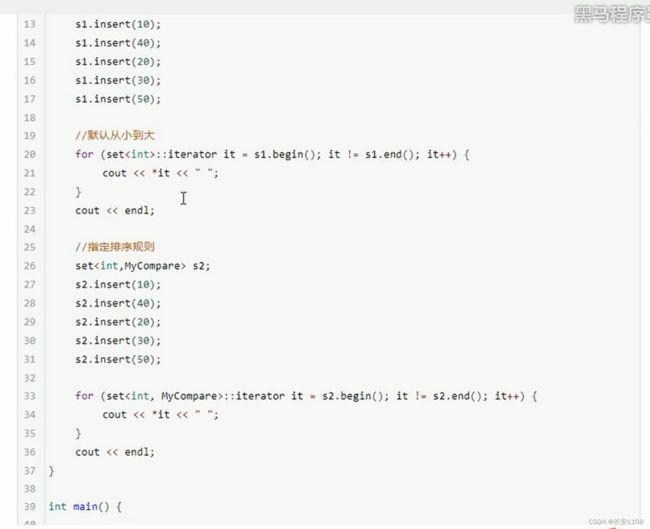
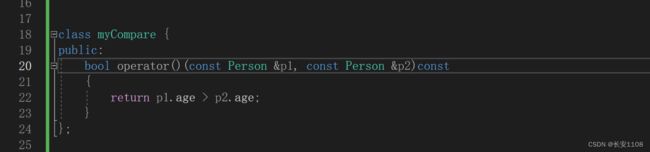
因为在插入时会自动排序 所以 我们要在插入之前就进行排序规则的设定 设定排序规则 要在set容器的参数列表里设置 首先是set的数据类型 在之后跟上自定义的排序规则
因为 模板参数列表中都是填入数据类型 所以 这里不能填入函数名 那么我们可以利用仿函数进行设置 以下是仿函数的例子 直接将类名填入模板参数列表即可

仿函数 就是定义一个类 写上类的成员函数 这样就可以用类名来代指函数
注意 函数写的时候 可以想象v1 v2先后传入 之后返回在你的预期规则下为真值的那个对比模式 如上图

经测试 要想成功运行 要在仿函数后面加上const 使其变成常函数

自定义数据类型的排序
自定义数据类型必须进行排序规则的设定
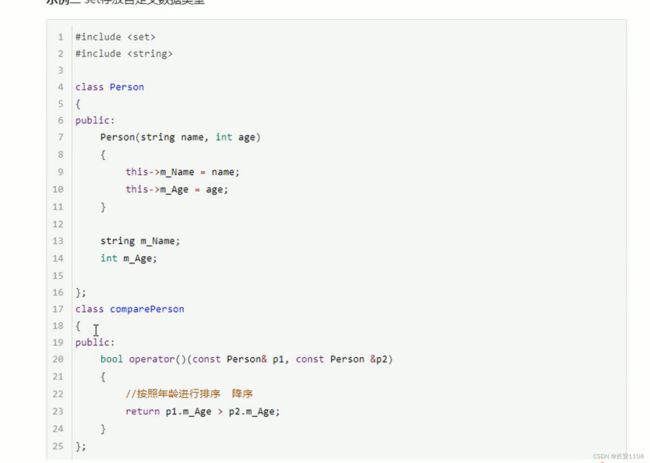
这里的仿函数 首先设置为只读 之后引用传递


经测试 即使参数加了const的仿函数仍然需要变为常函数
map容器
简介

注意是根据key自动排序 以及根据不能有key重复的元素 但是value可以重复
构造和赋值


首先 对于打印函数
*it就是模板参数列表里的内容 但是现在模板参数列表有两个值
其次插入数据的时候 要插入对组元素 但是不必要先创建出对组元素 直接使用其匿名对象就可以 就是没有对象名 直接数据类型+初始化构造参数

大小与交换


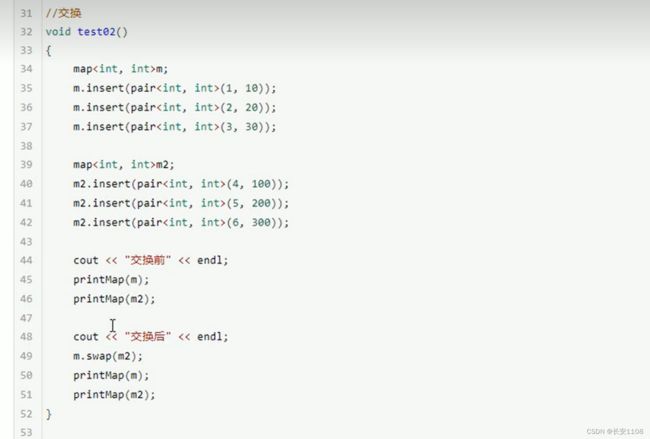

哪怕交换的两个容器元素不对等 那么也不会进行补齐 也不会进行残缺 而是实打实的交换
插入与删除

注意最后一个是根据key的值进行删除 而不是value的值进行删除

四种插入的方式 第一二种都是使用匿名对象的方式 第二种是对组构造函数的第二种形式 直接make_pair(key , value)
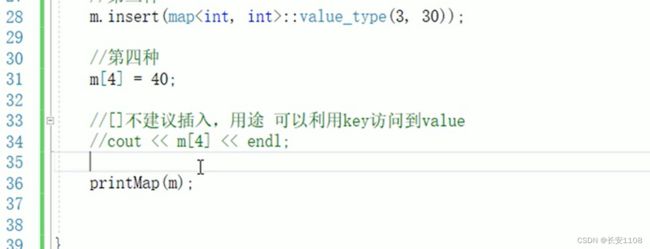
不建议用第四种方式进行插入 因为一旦插入有误 他不会报错 而是帮你创建一个键值对 帮你通过编译 反而会有隐形bug
但是可以采用这种方式进行元素的访问

查找和统计



排序

仍然是利用仿函数 这里还是根据key的值进行排序 仿函数也是根据key值进行操作



STL函数对象
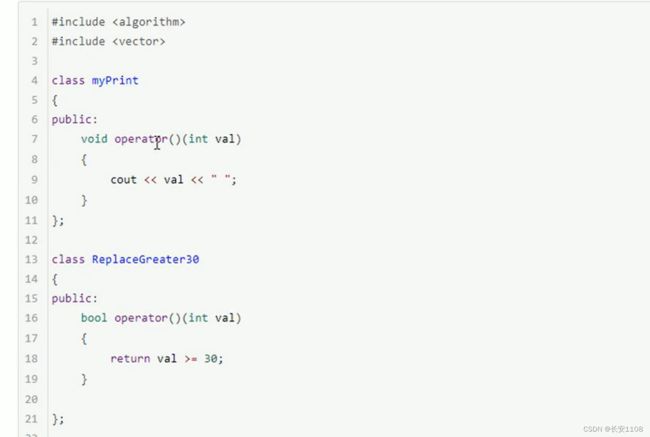
函数对象(仿函数)

函数对象就是一个类的对象 主要使用类中的成员函数 该函数重载()运算符 进行一些函数的重载
实际上就是使用一个提供函数的类 创建一个对象 来使用他的函数
但是由于他的行为非常像一个普通函数的调用 所以又叫做仿函数,如下图

本来是用点 来点出来他的成员函数 但是重载()之后 会有简写形式 就是直接对象加括号 里面传参即可
形式上很像函数的调用


以上是经典例子

由于该函数是在类里面 函数对象有着类的优点 他超越了普通函数 例如 他可以记录自己的状态 比如 调用了多少次

函数对象 实际上就是一个类的对象 他可以当做实参 传入一个以该类为形参的函数中 并进行函数的调用 如上图

用途:
可以用于想要直接输出某些对象时 在类中重载()函数 之后起个函数名 例如printf 可以依次输出对象的信息
谓词
一元谓词


返回值为bool类型
这里用到了一个find if算法 会按照参数一到参数二的区间 按照参数三的算法 进行查找 找到的话 返回当前元素迭代器 未找到 返回end()迭代器
使用时要包含标准算法库 algorithm
二元谓词


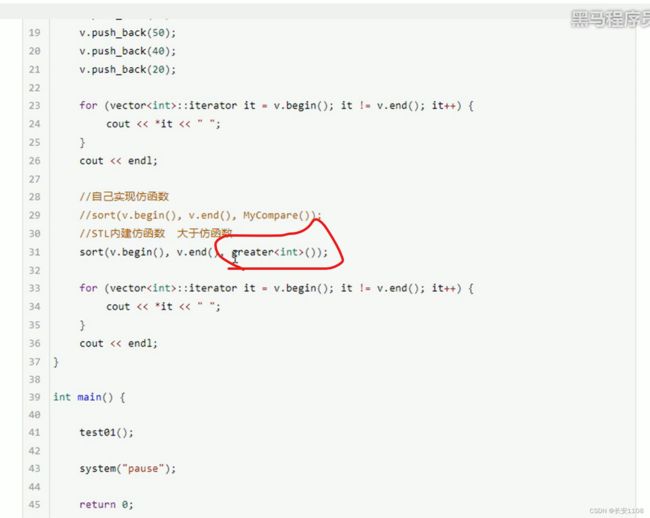
使用sort算法对vector容器排序时 默认是升序 这时 可以传入一个谓词仿函数 来改变他的排序规则 参数可以传入函数对象的匿名对象(匿名对象:类名+(),也就是不起对象名,这里的小括号代表着“对象创建”)
在目前的c++中 已经内置了升序谓词 直接传入greater ()
(其实就是接下来即将要学的内建函数对象)
内建函数对象

系统提供了一些STL 直接包含头文件 创建其对象 调用其成员函数即可 他们的成员函数都是仿函数 重写了小括号 所以直接用小括号调用成员函数
算数仿函数

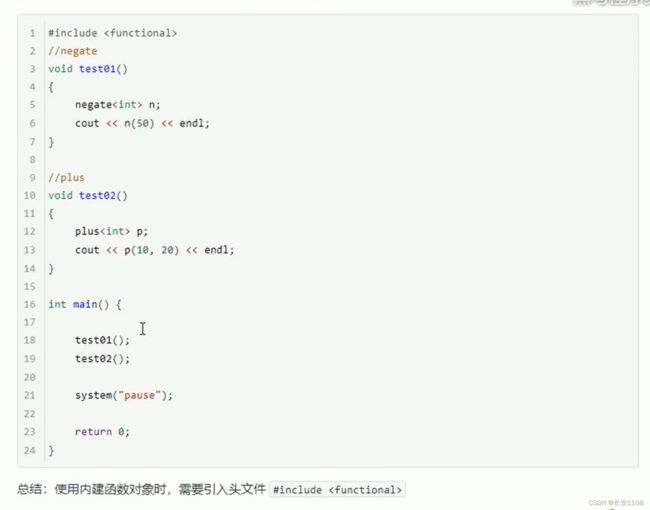
关系仿函数
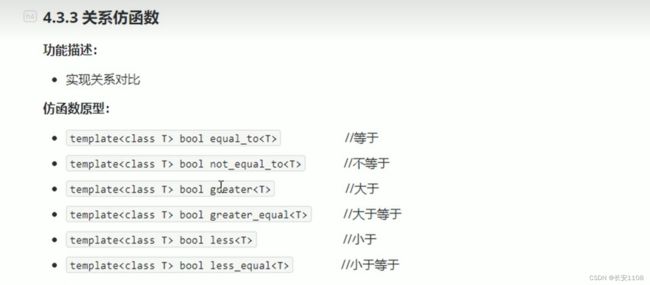
关系仿函数 实际上就是系统内建的谓词 上面提到的greater() 就是内建谓词的一个

逻辑仿函数
STL常用的算法

不同于上面的STL容器 以及内建函数对象 包含头文件后 提供一个标准类
这里 包含算法头文件之后 无需创建类的对象 直接使用函数即可 就是一个库函数文件
常用遍历算法

for_each

第三个参数传入一个函数 或者 一个仿函数 传入普通函数时 直接传函数名 传入函数对象时 传入匿名对象 前者不加小括号 后者加小括号


底层:
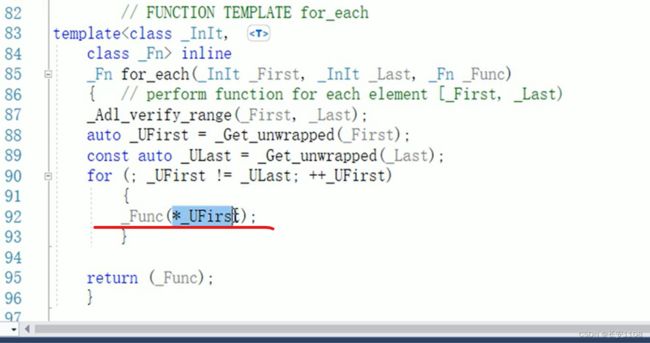
foe_each函数的底层 实际上就是对每一个从起始迭代器到终止迭代器的数 解引用之后 传入第三个参数函数或者仿函数里

transform



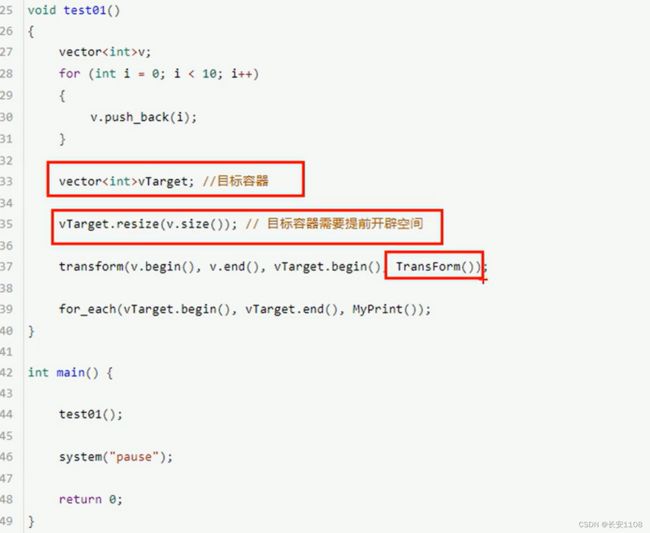
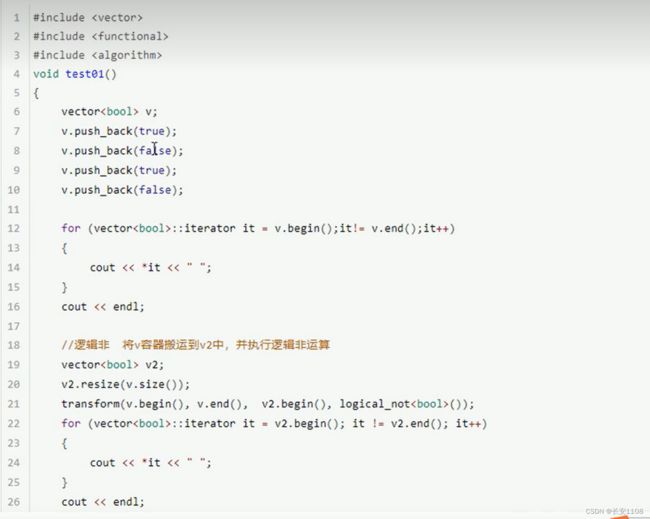
注意 在搬运时 要提前对目标容器resize好大小 可以利用源容器的大小来定义
对于第四个参数:
可以传入函数 也可以传入函数对象 该函数可以什么也不操作 直接返回 也可以进行一些改动 也就是使用transform算法时 系统给了一次遍历修改的机会
注意这里是返回某个值 而不是输出 函数返回值是int


常用查找算法

find

查找内置数据类型

查找自定义数据类型

当使用find()查找自定义数据类型时
要对号进行重载 下面来看一下底层find的底层
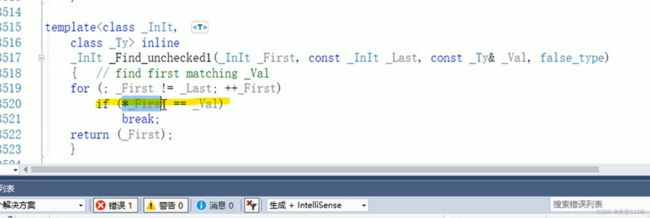
在find里面 实际上是将查找值与迭代器的解引用依次对比 而编译器面对pp时 不知道怎么对比 所以 就需要在类中对==号进行重载 告诉编译器怎么对比 而自己类是自己类的友元 所以 哪怕类中定义成员属性是私有的 在函数设计时 类的内部仍然可以调用某个同类对象的成员属性
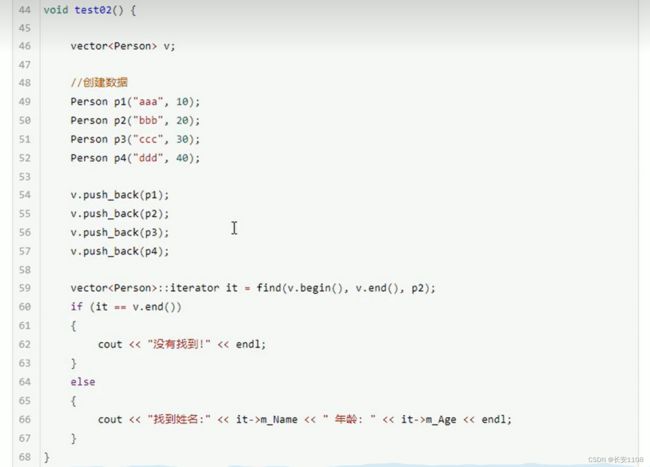

find_if

find_if实际上就是find的第三个参数由一个值改为一个函数对象
内置数据类型

自定义数据类型:
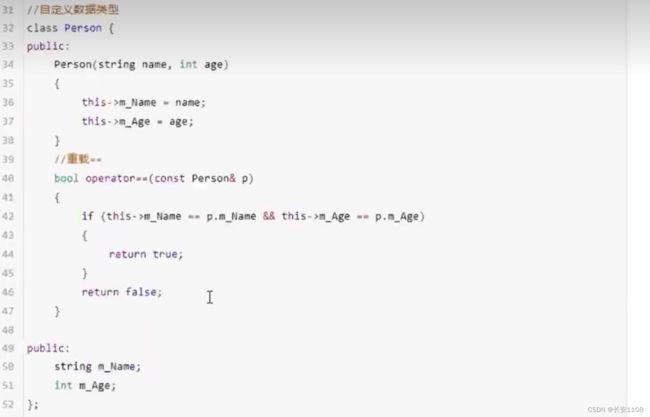
注意 因为传入的是仿函数 仿函数重写小括号之后 会根据要求返回相应规则下的布尔值 如下图 所以 上图中的重载==在find_if里不需要写
因为这里传入的是仿函数 直接看仿函数怎么设置即可 无需重载系统内部的双等号


adjacent_find



binary_search(二分查找)

!!注意 使用二分查找之前 必须保证容器中的元素是有序的
该函数返回值与其他不同 返回的是布尔值


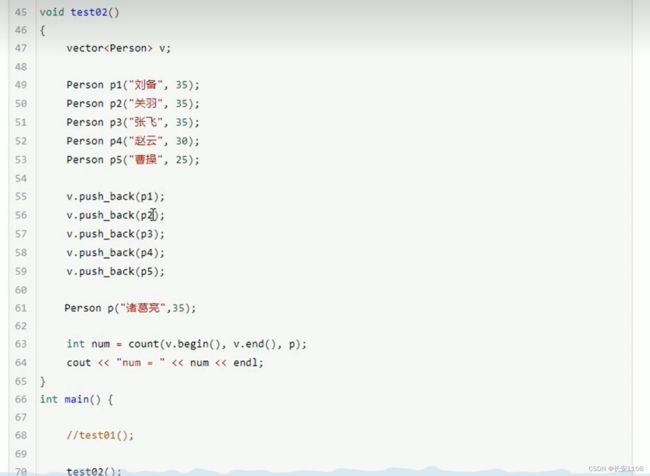
count
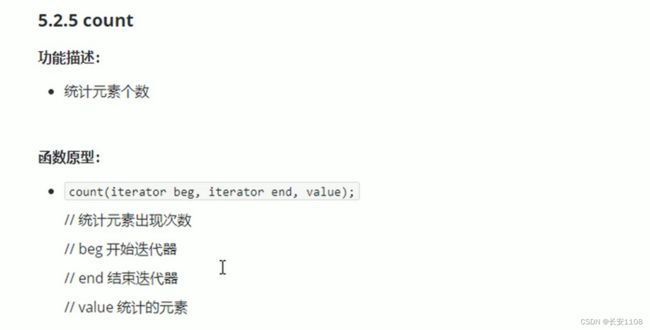
统计某个元素出现的个数
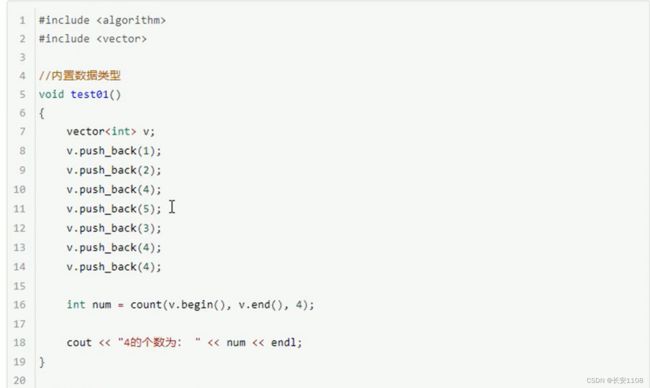

统计自定义类型时 要重载==号 重载双等号的同时 还可以自定义计入统计数的规则
之所以要重载号 是因为cout的底层也是将迭代器解引用之后 与传入的参数对比 相当于pp,如下图:


count_if

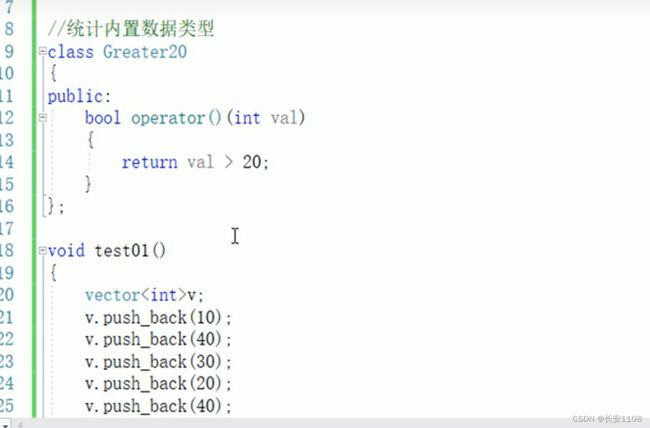

内置数据类型直接传入谓词即可

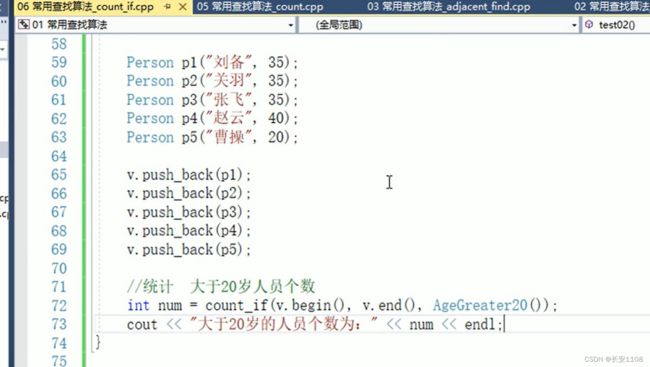
自定义数据类型也是直接传入相应的谓词 自定义数据类型里无需重载任何符号 因为这里参数是传入一个函数对象 或者说仿函数 在仿函数里就把一切都解决了
常用排序算法

sort

第三个参数是一个谓词 或者说返回值为bool的函数对象、内建函数对象 或者 返回值为bool的仿函数
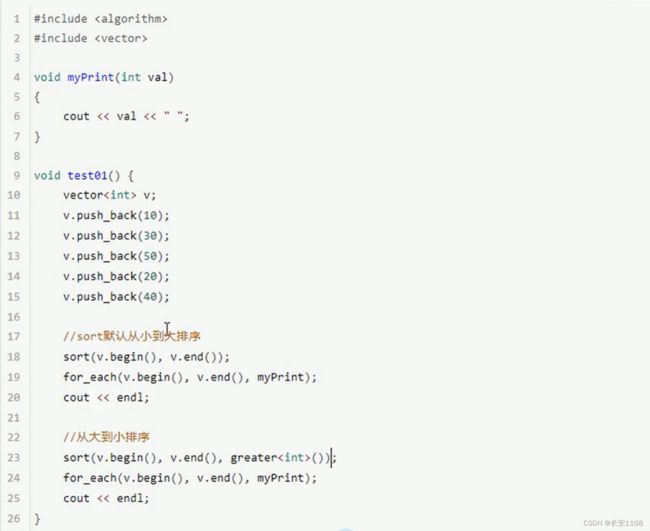
默认升序
降序:使用内建函数对象greater ()
random_shuffle

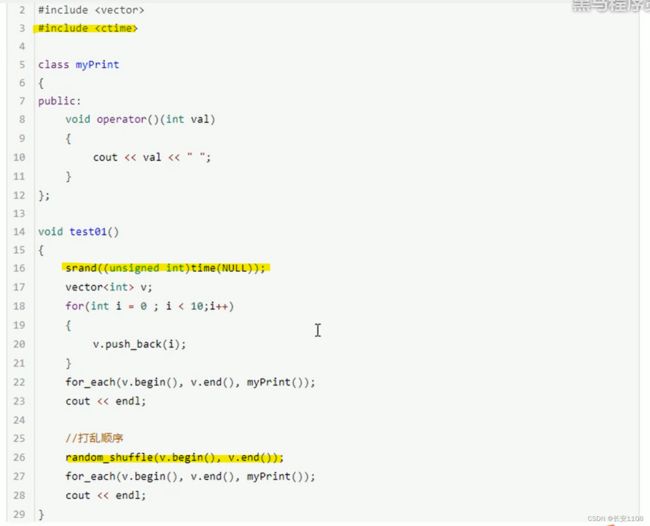
类似于一个洗牌操作 会打乱容器里元素的顺序 但是注意要想真正的实现实时随机 那么就要加随机数种子 如上图标黄的srand
注意要包含ctime头文件
![]()
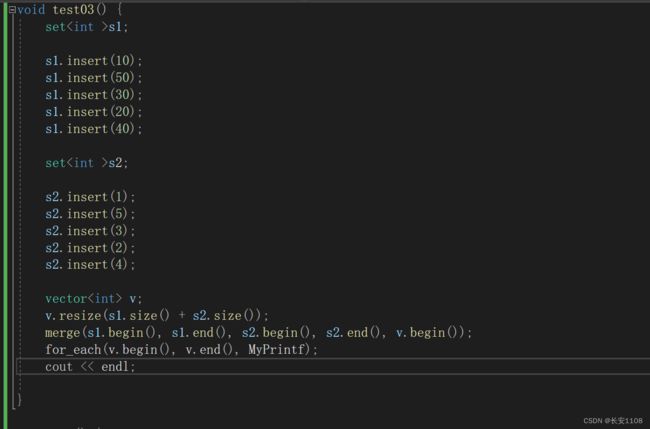
merge
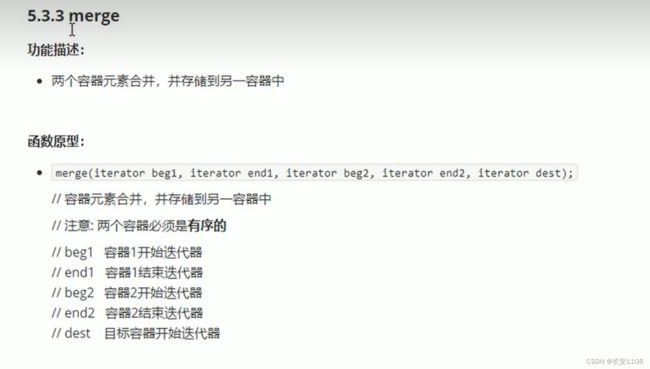
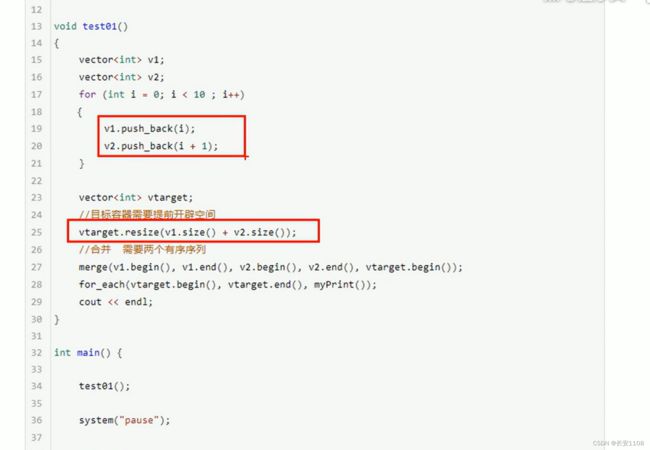
两个源容器必须是有序的
目标容器要提前开辟空间
合并之后的元素也是有序的 升序

因为要求源容器是有序的
所以用set也可以
reverse


常用拷贝和替换算法

copy



replace

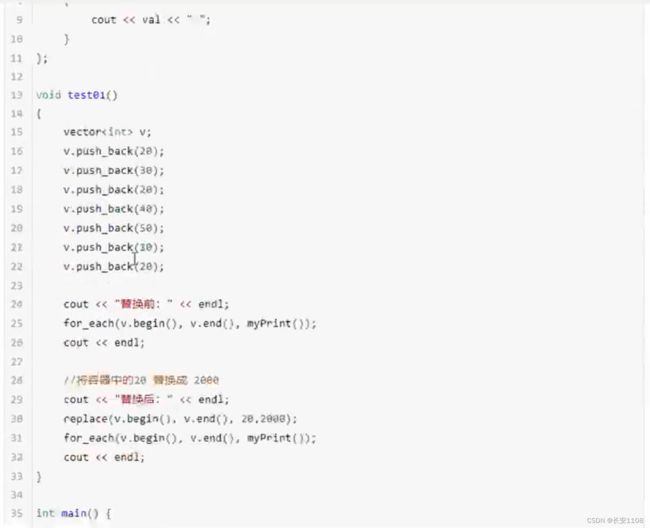

replace_if


![]()
swap


![]()
补充;

交换后 容器的大小也跟着交换
常用算数算法

accumulate

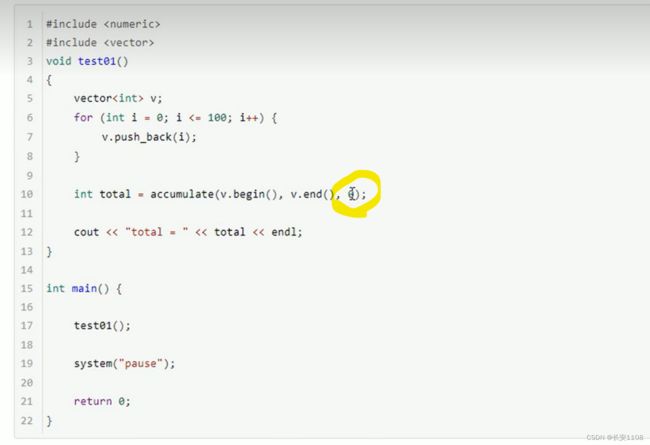
第三个参数是累加起始值 也就是没累加之前已经有的值

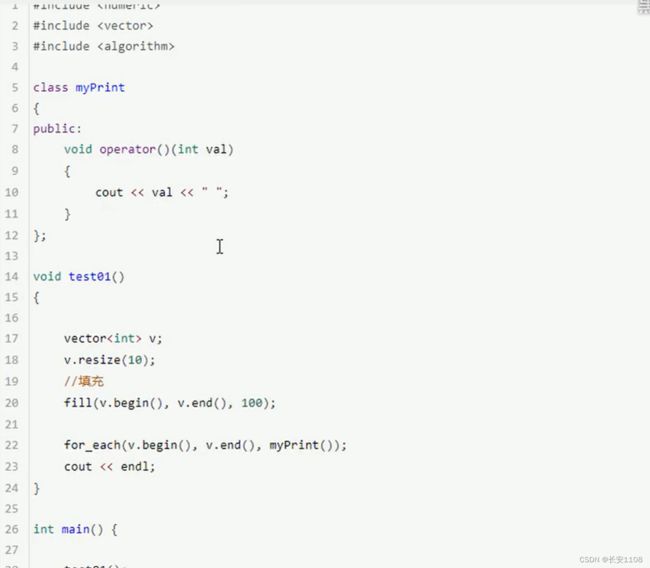
fill

用于在指定了容器大小之后 容器空位置默认是0 后续可以重新指定空位置的数

常用集合算法

set_intersection

函数的返回值为新容器中最后一个交集元素的迭代器
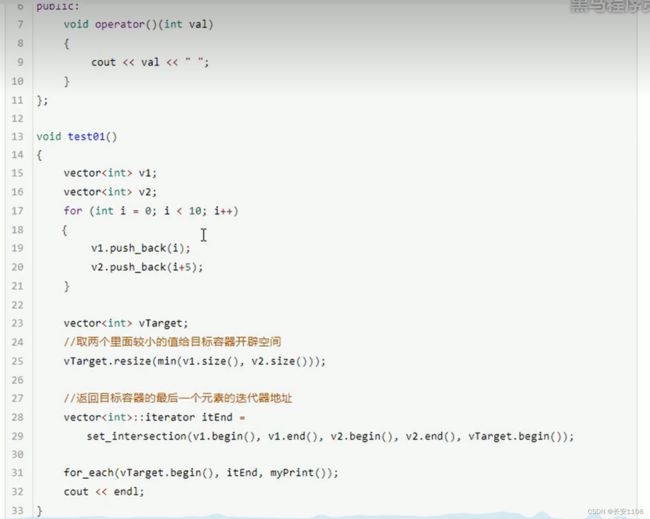
注意点1
要对新容器开辟空间 开辟空间时 最大值就是两个容器的最小size
这里有个算法min(参数1,参数2)
可以返回两个参数的最小值
注意点2
两个源容器必须是有序的
注意点3
遍历时 应该首迭代器是新容器的.begin() 尾迭代器不是end() 而是函数的返回值所返回的迭代器
因为新容器为了照顾特殊情况 迭代器在最大值的位置 所以 有时没有出现特殊情况 后面就全是零 所以 用函数返回值返回的交集集合最后一个元素的迭代器比较合适

set_union

区别于排序算法中的merge合并 这里是求并集 不允许有重复元素 但是merge并不会管你有没有重复元素 而是直接有序合并
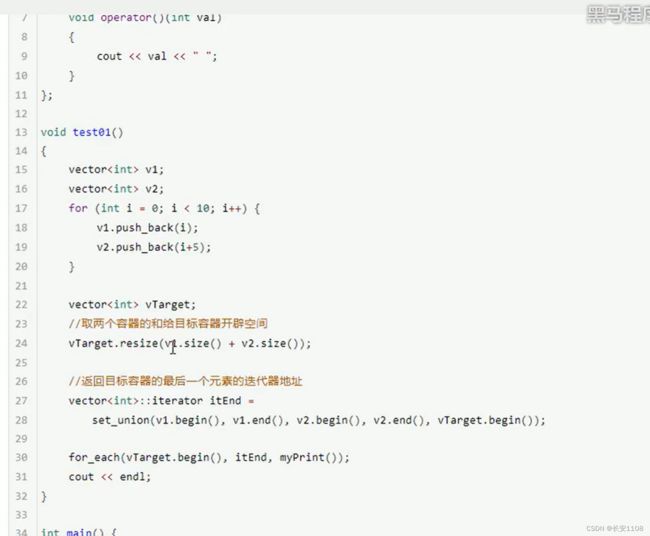

与上面的求交集大同小异
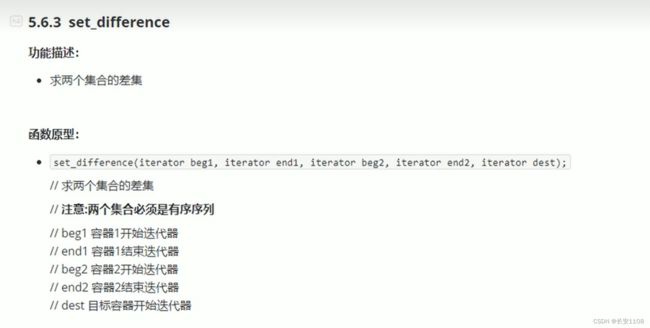
set_defrience
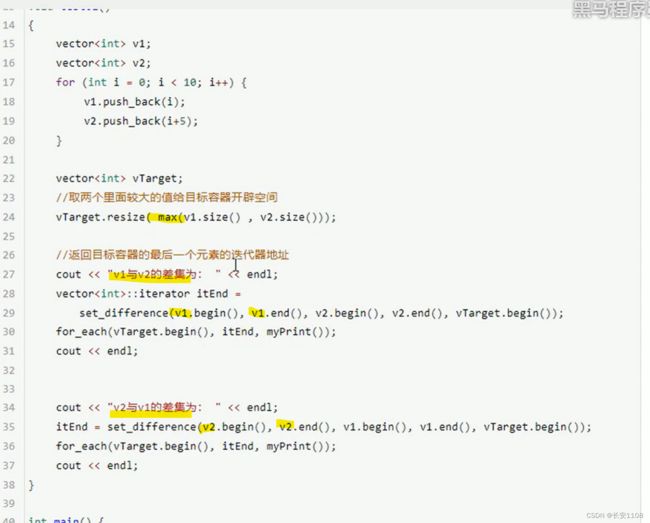
开辟空间用较大的size 使用算法max即可得到
演讲比赛项目
while(true)和system(“cls”)
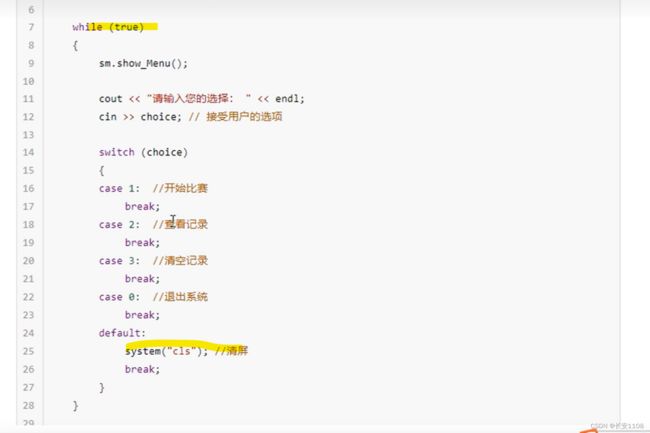
再次回顾 while(1) 可以让程序停留在这个循环 所以 可以一直供用户选择
system(“cls” )是清屏操作 配合着while(1)使用
用户使用完之后 清屏 然后再次循环输出展示菜单 等待用户选择
vector容器赋值

直接容器名赋值即可将vector容器进行一次拷贝
随机出小数

首先随机一个高位数的数 之后除以10 就是小数了(注意要用double类型接) 除以十之后再加一个“.f” 更保险
不同类型运算

当用accumulate算法时 设置初始值的时候 如果是浮点型运算且初始值为0 那么可以设置为0.0f
因为sum是一个浮点型 当浮点型除以一个整形 那么结果就是一个整形 所以 为了保持浮点型 将整形进行强制类型转换
map容器根据key得到value的另一种方法

map【i】 (i是key)
map加索引 可以得到对应的value
巧用multimap内核进行排序
![]()
创建一个临时容器 将分数当作key 因为multimap的key值自动排序 所以 存入该容器之后 自动按照分数进行排序 value值可以获取到选手编号 定位选手