【采用】大数据风控---风险量化和风险定价
前言
金融的本质从宏观上讲,第一:为有钱人理财,为缺钱人融资;第二:信用,杠杆、风险;第三:为实体经济服务,不然就是泡沫,微观上讲就是经营风险。在经营风险的过程中,风险定价是核心,指对风险资产价格的确定,它所反映的是资本资产所带来的未来收益与风险的一种关系,将风险偏好不同的资金供给方和资金需求方匹配起来,一般来说,两者成正向关系,风险越大,溢价越大,收益越高。而信贷的核心是风险管理,反映在风险定价上就是让优质借款人以较低的利率借款,质量较差的借款人以风险溢价作为补充,借款利率相应提高。通过对不同风险的客群实现差异化的定价、差异化的利率服务,以实现最优的资产配置。金融最大的问题不是炒作,不是脱实就虚,简而言之就是是风险定价不准确。失败的风险定价足以导致一家公司倒闭,甚至会引发连锁效应殃及行业。
以银行为代表的传统金融风险定价系统,主要考虑客户风险、经营情况、目标利润率、自身成本、资金供求关系、市场利率情况及基准利率等。银行评估客户的风险,虽然有一套相对固定的流程,然而除了查央行征信,查流水等,很多情况下还是要依靠线下操作。在确定客户情况的基础上,还要考虑银行放贷成本(包括边际成本、经营成本、人力成本及其他费用)和基准利差。 近年来,利率市场化加速,商业银行传统贷款业务萎缩,为了维持足够的利润水平,银行相继扩大资产管理、托管等表外业务,转向小微企业贷、小额信贷、校园贷等利润率更高的新型贷款业务,这对商业银行的风险定价能力提出了更高要求,如何实施规范而灵活的定价策略,如何推行高效快速的差别定价,成为了商业银行亟待解决的问题。
将前沿高科技与风险定价结合,让风险定价智能化的呼声愈加强烈,实际上,在互联网金融和金融科技领域,智能风险定价已经成为现实。互联网金融企业的核心就是利用大量的网络数据变量,对传统金融无法触及的用户进行风险定价并提供金融服务,即互联网金融平台在运营过程中使质量好的客户能以较优惠的价格获得服务,质量差的客户需要以风险溢价作为补充。消金、互金等基本都是小额分散,做银行不愿意做的高风险客群,即次级贷;差异化的风险定价在实际线上实时放贷场景下,通过用户数据和交易数据可以搭建出核心的风险定价模型。众多的消金和互金生存的核心就是低成本和精准的风险定价策略,而低成本和风险定价的核心是就是大数据风控在贷前贷中贷后的实践运用,新生的互联网金融机构优势正在于拥有海量的数据源、高效的数据处理技术,对更为庞大的新增用户群体给予更为精准的风险定价,数据的获取方式和处理能力决定了企业对于风险定价的精准度和覆盖率。
一、风险定价的重要性和必要性
风险定价有两个关键点:第一,降低成本,包括获客成本、运营成本、资金成本和风险成本等,是基础定价的基础;第二,认识用户,将客群分级,给客群更加匹配的风险定价,关键是有客户足够的表现时间数据,包括不限于客户基本信息数据、征信数据、外部第三方数据、失信信息数据和贷后还款数据等。但国内网贷行业普遍回避风险定价等问题,原因主要有四个为:
1.不想定价,传统金融机构的运作模式是利用高利差覆盖风险,只要能够兜住底,就没有必要做风险定价;
2.不同定价,不少平台是采用信用定价的方式,长期累积的风险极大;
3.不用定价,以e租宝为代表的平台,设资金池、立虚假标,这类平台的运营根本不涉及风控;
4.不能定价,很多平台没有能力完成风险定价。受各重因素困扰,风险定价迟迟未被推出。
事实上,迟迟未能推出的风险定价是大部分规范化运营网贷平台崩盘的根源:由于网贷平台借钱利率高,资产端就会存在逆向选择问题,真正优质的资产不愿高成本的去网贷平台上借钱,愿意花高成本借钱的很大一部分是借不到钱的劣质资产。劣质资产和高利率之间形成了一个负循环,最终网贷平台必将崩盘。
1.风险定价成为金融机构核心竞争力
互联网金融的主力是网络借贷平台(P2P),P2P从欧美进入中国后,就由纯线上模式变成了线上线下结合的模式,另一方面,与银行相比,网络借贷的资产相对质量较差,加之国内没有成熟的社会信用体系,导致P2P发展初期行业的风险定价成本很高,不少平台因此采取回避态度。当时,一部分平台采用高利差覆盖风险的方式,将没有风险定价导致的高成本转嫁给借款者,更有甚者直接弃风险定价而不顾,任由风险长期积累,最终坑害投资者,一些号称有风控的平台,也仅仅将重心放在了简单的反欺诈和贷后催收上。 由于网贷平台没有或者枉顾风险定价,导致借款利率失衡,真正优质的资产就会避开网络借贷,愿意来P2P借贷的都是一些还款意愿和还款能力极差的劣质资产。于是次级债和高利息之间形成负循环,这也是行业发展前期鱼龙混杂,野蛮发展凸显的一个问题。在监管层面,对刚性兑付的禁止,实质上关闭了风险准备、质保金赔付的大门,有业内人士分析,网贷行业想要合规健康发展,必须满足四个标准,分别是存管、信披、备案和风控,风险定价的重要性和急迫性愈加凸显。甚至可以说,在存管、信披、备案成为合规平台标配的情况下,风险定价将会成为平台的核心竞争力。
对于投资人来说,风险定价是保障自身权益和本息安全与否的关键。对于借款人来说,如果一家平台因为没有风险定价或者风控不成熟,造成借款成本过高,融资成本高于融资收益,会直接导致资产质量下降,违约逾期率上升,反之,如果一家平台的风险定价成熟,优质诚信借款客户能以更低的成本获得借款,质量差的资产则需要付出更多的风险溢价。
2.风险定价的作用
我觉得有以下几个方面的考量优势:
第一:对于信贷资信优质的客户可以降低费率,对于信贷资信差的客户,可以提高费率,做到资金有效分配,利于资源优化配置;
第二:针对于原先银行只做20%的用户,导致更多信贷资质一般的用户得不到现代金融服务,通过差异化定价的方式,可以让更多人得到金融服务,达到真正的普惠金融;
第三:通过借款表现数据反馈的形式,也可以更有利于贷款人约束规范自己的借款行为,珍惜自己的信贷表现,为产品降低更多的逆选择用户。
对大数据的运用和分析能力可以说决定了一个互金平台的实际运营和抗风险能力。事实上,在金融交易的环节中,数据从前、中、后台能够产生或者变换出非常多的模式,全面提升整体效能,包含提升前台营销能力,实现精准营销;提升中台投资能力和运营能力,实现精准预计投资风险和建立更完成的客户服务系统;提升后台的风控能力和研发能力,实现建立投资风险模型和定制化金融产品。
二、大数据风险定价基础
2.1 数据收集
2.1.1 传统银行系数据采集归纳包括:
个人/公司的基本信息,包括个人资历、个人/公司的信用信息、公司财务指标、家庭结构关系、家庭社会地位关系、个人社交关系、工商注册信息等
个人/公司商务信息,包括线上零售交易信息、专利信息、个人/公司资质、土地出让/转让信息、质押抵押信息等
个人/公司社会公众信息,包括涉诉信息、专利信息、被执行人信息等
个人/公司社会关联方信息,包括自媒体、证券社区、行政监管/许可、行业背景、商标、招中标、行政处罚、抵押担保等
2.1.2 互联网数据采集简要归纳包括:
用户运营数据(日常发生的单据、会计凭证、交易流水等)
用户行为数据(精准广告投放、内容推荐、行为习惯和喜好分析、产品优化等)
用户消费数据(精准营销、信用记录分析、活动促销、理财等)
用户地理位置数据(O2O推广,商家推荐,交友推荐等)
互联网金融数据(P2P,小额贷款,支付,信用,供应链金融等)
用户社交等UGC数据(趋势分析、流行元素分析、受欢迎程度分析、舆论监控分析、社会问题分析等)
第三方征信数据(包括:人行征信PBOC数据、同盾、百融、聚信立等第三方数据)
失信违约数据(法院执行和被执行信息、网贷黑名单等)
信贷表现数据(M2+、M3+还款记录数据等)
2.2 常使用的模型
无监督模型: K-means算法模型, K-medoids算法模型、CLARANS算法模型、BIRCH算法模型、DBSCAN算法模型和CURE算法模型等
有监督模型:支持向量机(Support Vector Machines)、线性回归(linear regression)、逻辑回归(logistic regression)、朴素贝叶斯(naive Bayes)、决策树(decision trees)、K-近邻(k-nearest neighbor algorithm)、随机森林(Random forest),神经网络(neural networks),主要的用途比如我们根据已经识别的有风险和无风险的行为,去预测现在正在发生的行为或者进行二分类或者多分类
离群点检测:比如登录行为,当同ip登录大量登录失败,这种行为可能是暴力破解,当同ip登录基本全部成功,这种行为可能是机器登录,采用离群点检测发现这两类行为并处理等,常用于反欺诈
2.3 数据画像
企业利用寻找到的目标用户群,挖掘每一个用户的人口属性、行为属性、社交网络、心理特征、兴趣爱好等数据,经过不断叠加、更新,抽象出完整的信息标签,组合并搭建出一个立体的用户虚拟模型,即用户画像。给用户“打标签”是用户画像最核心的部分。所谓“标签”,就是浓缩精炼的、带有特定含义的一系列词语,用于描述真实的用户自身带有的属性特征,方便企业做数据的统计分析。出于不同的受众群体、不同的企业、不同的目的,给用户打的标签往往各有侧重点,应该具体问题具体看待。
企业必须在开发和营销中解决好用户需求问题,明确回答“用户是谁——用户需要/喜欢什么——哪些渠道可以接触到用户——哪些是企业的种子用户”。更了解你,是为了更好的服务你;用户画像的重要的几个目的:
指导产品研发以及优化用户体验
实现精准化营销
可以做相关的分类统计
便于做相关的数据挖掘
差异化产品和利率设计
用户画像是风险定价的基础,其底层是机器学习,那么无论是要做客户分群还是精准营销,都先要将用户数据进行规整处理,转化为相同维度的特征向量,诸多华丽的算法才可以有用武之地,像是聚类,回归,关联,各种分类器等等。对于结构化数据而言,特征提取工作往往都是从给数据打标签开始的。比如购买渠道,消费频率,年龄性别,家庭状况等等。好的特征标签的选择可以使对用户刻画变得更丰富,也能提升机器学习算法的效果(准确度,收敛速度等)。对于半结构化和非结构化的数据我们就需要进行清洗,详细可以参照数据清洗的相关文章和知识,不再赘述。
参见文章:用户画像的流程、方法(https://blog.csdn.net/zw0Pi8G5C1x/article/details/83964888)
三、风险定价
量化风险管理的一个核心是风险定价,根据银行自身的风险偏好来对资产进行定价,高风险资产定价较高,低风险产品定价较低,根据风险高低来制定资产收益,RBP(基于风险定价)已经成为主流。主流的贷款定价方法包括:
1. 成本加成定价法
这种方法以银行自身为核心,贷款利率=资金的边际成本+银行的经营成本+预期违约的补偿费用+预期利润
2. 价格领导定价法
贷款利率=基准利率+信用风险溢价+流动风险溢价+其他风险溢价
这种方法应用较为广泛
3. 客户盈利分析法
综合考虑一笔贷款带来的总收入、借款人实际占用的资金金额、贷款的收益与银行的目标利润、资金成本和其他经营费用的对比情况,以客户为导向的定价方法。
4. 基于RAROC的定价方法
贷款的RAROC超过IRR的一定门槛值后,才予以通过。
目前国内工商银行、招商银行等大型银行有采用RAROC定价方法,一些国际先进银行积极应用RAROC方法。
(一)、风险定价基础篇
风险定价的核心思路,主要有以下几点:
第一人群的划分,精准、准确的用户画像和分级,正所谓物以类聚、人以群分;
第二风险评估预测,不同客群在不同场景下,逾期率、损失率是多少,会产生多少的M3+的坏账资产;
第三成本分摊,将获客成本、资金成本、催收成本等涉及到信贷环节的支出分摊到每个客群上。
具体的常用定价方法有两种:基准利率定价法和客户盈利分析法
基准利率定价法=基准利率 + 违约风险溢价 + 期限风险溢价;
客户盈利分析法,从某一客户的身上获得的整体收益,是否能满足整体的利润要求,也就是根据成本和收益核算,对应的公式是:贷款成本 = 资金成本 + 风险成本 + 运营成本 + 预期收益金额;
对于互联网消费金融来说,合适的定价方式是采用客户盈利分析法,定价费率(预期利润) = 综合成本 + 风险溢价 + 预期收益,这就是最终的数学目标公式,非常简单。
综合风险成本=预计未来一年的贷款余额 * 贷款的信用风险利差
(二)、风险定价量化篇
信用风险分为两部分,一部分为违约风险,另外一部分为价差风险。违约风险是指债务人不能或者不愿意及时归还利息及本金;信用价差风险是指债务人因为信用下降而导致能够还款的金额下降的风险。反过来理解,也就是一个是违约时间到达风险,另外一个就是违约大小,违约多少的风险。因此如果从上述观点思考的话,我们在考虑风险因素的时候,应该着重从以下几个点来思考产品因素的整体风险:
违约敞口,违约时候造成资损的随机变量,对于放贷金额的最大损失评估,风险计提
转移概率,是指由于各种因素,例如工作变动,人生变故等等原因,借款人信用变化的概率,也称为信用转移,目前查看的视角有两种,一种是评级随着时间的变化而变化,例如上年评级在AAA,本年度下调到AA,在目前的现金贷产品中,此类方式更多的被实时申请技术取代,第二种是从产品风险的角度更多的是以贷款人在不同MOB的变化情况,来预估整体的转移概率表现。
逾期率滚动---计算风险计提
违约概率,借款人不归还借款的概率,主要通过借款人贷前的数据表现来评估放贷之后的贷款违约表现情况
回收率,是指借款人发生违约后,仍然可以获得的资金所占比例,通常可以借鉴LOSSCAL的方式预测回收率模型,因为本身是动态的方法,因此需要建立多因子的模型,并具有统计学意义的显著性才能入选模型,一般的整体框架包含了以下的几个步骤:
a.转化:由于回收率分布是高度不对称的,峰度左偏,斜度右偏,可以用Beta分布函数来近似表示,重要确定中心和形状参数即可。不同类型的分级处理由不同的Beta分布来进行刻画,将Beta分布从Beta空间转化到正态空间变为对称的正态分布可以更加方便的处理,但是正态分布变量的概率和相应Beta空间的概率相同
b.建模,建模分为两步,即建立最小模型和真实模型,通过指标进行计算得到权重,确定合理权重,最小模型如下:
w = w0 + w1x1 + w2x2+...... + wkxk,其中x1是转化值,w是正态化的回收率
c.映射:由于w是正态空间,需要将Beta分布转换你应用与不同的分级处理,使用数学统计方法校验数据,验证模型有效性
d.将结果作为基准,与其他回收率模型进行比较,计算测算误差以及实际回收率的相关性
(三)、风险定价模型篇
依托于互联网金融的定价体系发展阶段大概经历了四个阶段,分别为如下展示:
一口价模式,简单粗暴,劣币驱逐良币,针对所有的用户群体都按照统一的费率标准进行展示
精算定价,解释方便,定价偏差大,以历史逾期率作为唯一的定价因子
数据定价,预测校准,解释性差,以30+的因子统计建模
大数据定价,难于解释,百万ID特征,实时的特征学习方法,具有实时审批,逾期率的实时预测,以及实时的差异化定价。
下面将以精算定价在实际场景中的应用方式来阐述如何将理论转化到具体的应用场景中,以及模型在提高风险的分割能力,提高定价的精度及准确性,确保策略的可调整性方面是怎么完成的。
a:一般模型的介入思维可以从改造现有,增加新进因子这两个方面来进行,优化现有定价因子,如果当前的定价因子并不是由多变量预测模型生成,或者当前的定价因子已经沿用多时,需要进行更新;添加复合层级定价因子,复合层级变量是由一组定价因子建立,并能形成对应的评分分组,好处:可以平滑因定价因子改变而造成的对整体费率的扰动,同时可以在增加新的定价因子时候,合理的处理可以进一步增加整体的费率区分度。
b:搭建的精算模型将引入广义线性模型,为什么选择这样的模型?这个模型有什么应用上的好处?广义线性模型(generalized linear model, GLM)是简单最小二乘回归(OLS)的扩展,在OLS的假设中,响应变量是连续数值数据且服从正态分布,而且响应变量期望值与预测变量之间的关系是线性关系。而广义线性模型则放宽其假设,首先响应变量可以是正整数或分类数据,其分布为某指数分布族。其次响应变量期望值的函数(连接函数)与预测变量之间的关系为线性关系。因此在进行GLM建模时,需要指定分布类型和连接函数。其中分布参数包括了binomaial(两项分布)、gaussian(正态分布)、gamma(伽马分布)、poisson(泊松分布)等。和lm函数类似,glm的建模结果可以通过下述的泛型函数进行二次处理,如summary()、coef()、confint()、residuals()、anova()、plot()、predict()
c.建模的整体步骤:
1.数据准备,确定数据结构,目标变量,选择建模的定价变量,风险暴露的调整,损失调整,生成交互变量,因为选择的是纯风险损失模型,因此目标变量的选取是预估即将发生的损失金额,纯风险损失=已发生损失/风险暴露
2.建模,广义线性模型结构和相应的模型设计,对模型输出的解释,模型调整
3.增添复合层级变量的主要步骤,复合层级变量的模型设计,选择复合层级因子变量(Tier Element),生成复合层级分数并进行复合层级分组
4.建立模型,生成模型参数,选择逾期分布和连接函数,生成GLM赔付率模型
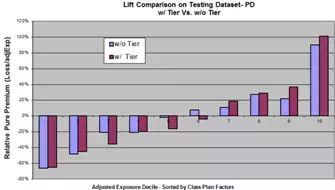
5.模型验证,不同定价区间的模型Lift提升度收益图
四、风险定价实践案例
1.钱来网
钱来网风险定价体系核心是评分卡模型和风险定价器。基于风险定价模式和评分卡模型,钱来网开发了H5版本的风险定价器,类似平安的车险定价器,嵌入在微信公众号“易借”中。“易借”接入了由全国各地优秀的房地产评估机构共同建设运营的专业性房地产信息数据服务的估价平台,根据云数据对十几个城市上万份案例做了分析,结合多年来在行业积累的经验,采用科技手段,并经过多轮的实践验证,能对房屋进行初步估价,这为钱来网的房产抵押借款准确估价提供了基础,同时提高了借款业务的贷前审核效率,加快了放款速度,并率先在行业内独创大数据风控模型---“白匣子”评分卡模型。钱来网的创新评分卡系统是一个房押借款的信用评级系统,基于数据的建模回归和传统的“5C”审核技术相结合产生的,既有大数据的基因,同时兼顾了经验的认知和判断。评分卡系统以基础信用评分和抵押率为两个主要维度,对客户的信用等级进行了3个等级的划分,以反映对逾期率的预测,分别为AAA、A、BB,信用等级越高,抵押率越低,利率越低,反之则抵押率越高,利率越高。针对不同风险等级的借款人,平台计提不同的风险保障金,并对于投资人制定不同的风险保障措施。通过风险定价,可以更精细化管理资产风险,评分卡模型一方面大大降低了人为主观因素对于审批的误判,同时调动客户的诚信积极性。
2.人寿保险
人寿保险统计的结果是数据量。在保险公司里,数据量主要包括这样几部分:
保单数据及保单维持数据。这部分数据基本上都在业务系统中。
核赔理赔数据。这部分数据大部分也在业务系统中,同时部门内部也有对应的数据库。
投资理财数据。因为寿险经营时间长,保费投资是寿险经营的重要方面,所以这部分数据在寿险公司中体现最为明显,导致大量的金融市场数据集中在投资部门。这部分数据通常和业务系统是分离的。
定价数据。这部分数据是精算部门用来定价和利润测试,以及用来向保监会报送各类报表运算的时候需要的,有相当一部分来自于业务系统。
风险管理数据。这部分数据相当零散,且涉及以上各类数据,同时还包括公司的财务乃至宏观管理数据。以及一些行业公共数据和监管数据。
2.1 寿险产品精算定价的“再精算”
通常,寿险产品定价是基于寿险精算模型进行纯保费(精算现值)的计算,然后使用“资产份额”和“宏观定价法”来确定实际保费。这个过程中,涉及的数据量实际上仅仅包括传统的生命表(保监会规定)以及部分抽样数据,这部分数据仅仅占可利用数据的5%左右。
在保险公司持续经营的情况下,新开发的一种保险产品,它在传统数据依赖上可能只需要一些精算部门的经验数据,以及传统的已经做好的模型,只需要修改一些基本假设和预订费率、预订利率以及预订死亡率即可。 在大数据背景下,与此保险产品有关的数据范围扩展到了整个业务部门乃至核保核赔部门,这些部门的数据经过多年的积累能够进行有效连接,形成一个庞大的后台数据记录。以某一家普通保险公司为例,该数据连接后形成了一个900M数据记录池,这些客户的记录无疑能够对传统定价有很大的帮助,能够将精算定价的结果进行“再精算”过程。
寿险产品中最重要的就是死亡率。在传统定价方法中,使用的是2000—2003年生命表。该生命表已经使用多年,反映了当时的死亡状况。对于一款推向市场的寿险产品,它所面临的人群实际上是未来的客户,他们的死亡率状况与2000—2003年生命表已经有很大差异。 利用大数据平台,可以构造庞大的分年龄和分时间死亡率表。
2.2 寿险产品的细化分类与创新
保险本质上是“大数定律”,对于任何一个群体来说,只要投保的数量足够多,就可以应用“大数定律”。保险产品的定价本质上就是对“风险”的度量,只要风险能够度量,就能够给出一个合适的价格,以此价格出售产品就能够保证收支平衡。这正是保险产品运作的方式。
但对于风险的度量和精确测算并不是一件容易的事情。所以传统的保险产品都人为限定为“标准体”;其他的“非标准体”都被保险例外条款而排除在外。这个过程实际上浪费了大量的数据和信息。
大数据修正了大数定律,拓展了风险覆盖的程度,保险公司可以基于数据优势,进行群体的细化处理,针对不同群体开发不同的保险产品,从而启动新的赢利增长点,开发出新的业务模式。
以寿险为例,以上述900M数据加上该公司健康险5年的数据以及合作医院的跟踪数据为基础(总数据基础大约在1.5G左右),开发针对重疾患者的定期寿险产品。对于该产品定价来说,很重要的因素有两个:第一个就是首年发病率,它实际上衡量了新产品与传统产品的“偏差”——意味着健康体从健康状态转移到了疾病状态,进入了“意向购买人群”;第二个就是病死率,即疾病人群的死亡率,作用与传统寿险的死亡率相同。具体测算步骤如下:
第一步,从该公司的承保理赔库中筛选出重大疾病保险的承保理赔记录,筛选出所需字段,添加需要计算的字段,如年龄段、疾病种类、理赔数、暴露数、保单周年日等。
第二步,1999—2011年13年中具体某一年的测算方法为:假设保单周年日与被保险人生日是重合的,以保单周年日为分界点,将该年度一分为二,分别记有保单年度1、年龄段1、理赔数1、暴露数1和保单年度2、年龄段2、理赔数2、暴露数2。对保单记录做出调整(如失效日期调整、满期日调整、多次索赔合并调整等)后,按照矩估计精算法为每条保单记录分别计算出其在该年度前后两部分的理赔数1、暴露数1和理赔数2、暴露数2。按照年龄段对上述数据进行分类汇总,即可得到该年度内不同年龄段的理赔数和暴露数,二者相比即为该年龄段在该年内的重疾发病率。
第三步,13年中的每一年均重复上述处理过程,共计算13次。结果可得到13年中每一年不同年龄段的理赔数、暴露数和重疾发病率。将13年的理赔数、暴露数再次按照年龄段分类汇总,即可得到不同年龄段总的理赔数和暴露数,二者相比即得到该年龄段的总重疾发病率。
第四步,上述步骤所得结果是所有重疾的一个疾病总发病率情况,也可分疾病种类测算出每一种具体疾病不同年龄段的发病率情况,测算方法与上述步骤相同。
以癌症患者与糖尿病患者为例,发病率和病死率测算结果分别如表4和表5所示。
实际上,中国糖尿病患者有9000多万,其他重疾且可保群体数量在3亿左右,相当于美国人口数量。这部分群体因为本身处于高风险状态,所以对保险的需求比正常人更加强烈。但在传统保险框架内,他们却因为“非标准体”的原因而被拒保,这是一个巨大的矛盾。基于大数据,保险公司可以对该群体进行细分,并精确测定其风险水平,推出适合的保险产品。
具体可以查阅:大数据背景下的寿险产品定价与创新(https://www.xzbu.com/3/view-4858489.htm)
4.招商银行
招行2013年上线新的零售个贷系统,已针对信贷目标客户群开发三个评分卡模型,分别从申请、行为、催收三个环节设置。以大数据为驱动,创建线上贷款风险管理体制。依据大数据体系,招行“闪电贷”根据不同客户的信用数据给出不同额度的授信,贷款额度门槛最低1000元起,一般个人客户最高额度可达30万-50万。同时,“闪电贷”根据客户的风险等级进行差异化定义贷款利率。授信额度和贷款利率将由系统根据客户过往数据每一个月动态调整一次。贷款期限方面,招行“闪电贷”设置1-24个月不同期限,在授信额度范围内,实现“随借随还,按天计息”。以一位授信额度为12万的客户为例,日利率为0.0348%,年化贷款利率为12.7%。
5.国内通用
可以考察借款人的不同借款维度,包括社交网络数据和平台上行为数据;你我金融的天秤系统,运用机器学习、神经网络等前沿算法及分布式数据存储、人脸识别、OCR扫描等前沿技术,对借款人的多项数据进行分析利用,并归纳出用户的特征向量,为用户匹配精准费率,进行风险定价,完成科学授信。
总结
1.风险定价(Risk based pricing)顾名思义,就是在风险的基础上去做定价,根据违约率不同,把客群进行细分,最后确保每个细分客群里都能有合适的收益率,有逼格一点可以做的比较连续额度区间,简单的话也可以做成几个简单的定价。做的更细致一点的话,可以做一些弹性测试,采用test-and-learning的思想,比如同一批客户分成不同的组给定不同的利率,看看客户的接受度,以及所造成的逆向选择情况以及逾期损失情况。如果客户接受率降低,或者逆向选择现象严重,客户的实际表现会偏离分析分群时看到的客户表现的。
2.金融领域从未来的发展方向来看,将会依托于大数据平台,将个人的互联网数据有效的整合到一起,形成一个风险管理风险控制体系,进而为风险进行更准确更公平的定价,这将会是最终真正的创新。
3.风险定价就是用收益来覆盖风险,300%的利息的产品,哪怕只有50%的用户正常还款,也会大赚特赚,再说了其余50%只要不是欺诈,不是还能催收回来部分嘛,还能正常还几期的,这就是之前‘714高炮’形成的原因。但是风险定价背后还有一个血淋淋的现实就是老实还款的人承担高额利息补贴逃债用户。因为有了风险定价才会有DMP、精准营销解决方案来转卖这些信息。
4.最后
If 10% of the profits,capital will ensure being used everywhere;20% of the profits,capital can active;50% of the profits,capital will rush into danger (如果有10%的利润,资本就会保证到处被使用;有20%的利润,资本就能活跃起来;有50%的利润,资本就会铤而走险)
for 100% of the profits,capital would dare to trample all human laws; there are more than 300% of the profits,capital would dare to commit any crimes,and even go to the first to take the risk of strangulation(为了100%的利润,资本就敢践踏一切人间法律;有300%以上的利润,资本就敢犯任何罪行,甚至去冒绞首的危险。”)
-马克思-《资本论》
为了利润,资本可以不顾一切。
参考文章1:https://zhuanlan.zhihu.com/p/31144345
参考文章2:http://www.jpm.cn/article-36691-1.html
参考文章3:https://zhuanlan.zhihu.com/p/52095801
参考文章4:https://zhuanlan.zhihu.com/p/52095801
————————————————
版权声明:本文为CSDN博主「Bonus_F」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_32123787/article/details/99293718