【机器学习】—SVM中拉格朗日算法和SMO算法
阅读之前看这里:博主是一名正在学习数据类知识的学生,在每个领域我们都应当是学生的心态,也不应该拥有身份标签来限制自己学习的范围,所以博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。
博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。
目录
- 1.SVM的约束最优化问题
- 2.有约束求解问题(拉格朗日乘子法)
-
- 2.1各类最优化问题
- 2.2 如何利用拉格朗日乘子法求解
-
- (1)无约束条件的时候
- (2)有等式约束条件的时候
- (3)约束条件是多个等式的时候
- (4)约束条件是等式和不等式,且有多个的时候
- 2.3 SVM拉格朗日乘子法的求解
- 3.SMO高效优化算法
-
- 3.1 SMO干了什么?
- 3.2 为什么SMO跑的那么快?
- 3.3 乘子选择问题
- 3.4 SMO算法的原理
- 3.5 SMO算法的特点和优势
- 4. 源代码及代码注释:
1.SVM的约束最优化问题
SVM的具体原理很多博客和书籍都有介绍,我这里就不再详细介绍了,可以参考博客:SVM支持向量机算法介绍
通过间隔最大化,得到SVM的约束最优化问题:
m i n ω , β 1 2 ∥ ω ∥ 2 s . t . y i ( w ⋅ x i + b ) − 1 ≥ 0 , i = 1 , 2 , . . . , m \mathop{min}\limits_{\omega,\beta} \frac{1}{2}\left \| \omega \right \|^2 \\ s.t. y_i(w\cdot x_i +b)-1\ge0, \qquad i = 1,2,...,m ω,βmin21∥ω∥2s.t.yi(w⋅xi+b)−1≥0,i=1,2,...,m
2.有约束求解问题(拉格朗日乘子法)
对于上述带有不等式约束的最优化问题,可以使用拉格朗日乘子法(Lagrange Multiplier)对其进行求解。
2.1各类最优化问题
首先先了解一下最优化问题的分类,最优化问题可以分为一下三类:
- 无约束的优化问题,可以写成: m i n x f ( x ) \mathop{min}\limits_{x}f(x) xminf(x)对于这类的优化问题,常常使用的方法就是Fermat定理,即使用求取f(x)的导数,然后令其为零,可以求得候选最优值,再在这些候选值中验证;如果是凸函数,可以保证是最优解。
- 有等式约束的优化问题,可以写成: m i n x f ( x ) s . t . h i ( x ) = 0 , i = 1 , 2 , . . . , m \mathop{min}\limits_{x}f(x) \\ s.t. h_i(x)=0, \qquad i = 1,2,...,m xminf(x)s.t.hi(x)=0,i=1,2,...,m对于这类的优化问题,常常使用的方法就是拉格朗日乘子法(Lagrange Multiplier) ,即把等式约束 用一个系数与目标函数 f ( x ) f(x) f(x)写为一个式子,称为拉格朗日函数,而系数称为拉格朗日乘子。拉格朗日函数的形式如下, μ \mu μ即拉格朗日乘子:
L ( x , μ ) = f ( x ) − μ h ( x ) L(x,\mu)=f(x)-\mu h(x) L(x,μ)=f(x)−μh(x)通过拉格朗日函数对各个变量求导,令其为零,可以求得候选值集合,然后验证求得最优值。 - 不等式约束的优化问题,可以写成: m i n x f ( x ) \mathop{min}\limits_{x}f(x) xminf(x)
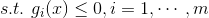
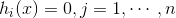
对于这类的优化问题,常常使用的方法就是KKT条件。同样地,我们把所有的等式、不等式约束与 f ( x ) f(x) f(x)写为一个式子,也叫拉格朗日函数,系数也称拉格朗日乘子,通过一些条件,可以求出最优值的必要条件,这个条件称为KKT条件。
2.2 如何利用拉格朗日乘子法求解
拉格朗日乘子法可以应用于有等式约束的优化问题和有不等式约束的优化问题
对于有等式约束的优化问题:
m i n x f ( x ) s . t . h i ( x ) = 0 , i = 1 , 2 , . . . , m \mathop{min}\limits_{x}f(x) \\ s.t. h_i(x)=0, \qquad i = 1,2,...,m xminf(x)s.t.hi(x)=0,i=1,2,...,m其中 f ( x ) f(x) f(x)被称为目标函数。
(1)无约束条件的时候
当没有约束条件的时候,我们通过求导的方法,来寻找最优点,设 x ∗ x^* x∗是这个最优点,即此时有
![]()
此外,如果 f ( x ) f(x) f(x)是一个实值函数, x ⃗ \vec{x} x是一个 n n n维向量的话,那么 f ( x ) f(x) f(x)对向量 x ⃗ \vec{x} x的导数被定义为
![]()
(2)有等式约束条件的时候
当有一个等式约束条件 ![]()
举例设
m i n x f ( x 1 , x 2 , x 3 ) \mathop{min}\limits_{x}f( x_1,x_2,x_3) xminf(x1,x2,x3)
![]()
从几何的角度看,可以看成是在一个曲面 Ω { x 1 , x 2 , x 3 ∣ h ( x 1 , x 2 , x 3 ) = 0 } \Omega\{ x_1,x_2,x_3|_{h(x_1,x_2,x_3)=0}\} Ω{ x1,x2,x3∣h(x1,x2,x3)=0}上寻找函数 f ( x 1 , x 2 , x 3 ) f(x_1,x_2,x_3) f(x1,x2,x3)的最小值。
设目标函数 z = f ( x 1 , x 2 , x 3 ) z=f(x_1,x_2,x_3) z=f(x1,x2,x3),当 z 取不同的值的时候,相当于可以投影在曲面 Ω { x 1 , x 2 , x 3 ∣ h ( x 1 , x 2 , x 3 )