MYSQL基础及性能优化
文章目录
- 一、MYSQL基础
-
- 1.1 MYSQL权限
- 1.2 MYSQL数据类型
-
- 1.2.1 INT类型
- 1.2.2 字符类型
- 1.2.3 时间类型
- 1.2.4 JSON类型
- 二、MYSQL架构与存储引擎
-
- 2.1 MYSQL体系结构
- 2.2 MYSQL逻辑架构
- 2.3 MYSQL物理存储结构
- 2.4 MYSQL存储引擎
- 三、MYSQL业务设计
-
- 3.1 锁
- 3.2 事务
- 3.3 逻辑设计
- 3.4 物理设计
- 四、MYSQL慢查询及索引
-
- 4.1 慢查询
- 4.2 索引
- 4.3 执行计划
- 4.4 SQL优化
一、MYSQL基础
1.1 MYSQL权限
用户权限涉及的表
mysql.user
存放用户账户信息以及全局级别(所有数据库)权限,决定了来自哪些主机的哪些用户可以访问数据库实例,如果有全局权限则意味着对所有数据库都有此权限。
mysql.db
存放数据库级别的权限,决定了来自哪些主机的哪些用户可以访问此数据库。
mysql.table_priv
存放表级别的权限,决定来自哪些主机的哪些用户可以访问数据库的这个表。
mysql.column_priv
存放列级别的权限,决定来自哪些主机的哪些用户可以访问数据库表的这个字段。
msql.procs_priv
存放存储过程和函数级别的权限。
mysql权限的验证过程:
1) 先从user表中判断用户名 + host、密码是否存存在。
2) 再进行权限分配验证,按照user、db、table_priv、column_priv的顺序进行验证。如果user中的权限为Y,则不检查后面的db等的权限。如果为N,则检查db中的权限,以此类推。
赋权
创建用户:
CREATE USER <user>@<host> IDENTIFIED BY <password>
赋权:
GRANT <操作> ON <db>.<表> TO <user>@<host>
操作包含:all、select 、drop、update、insert、delete等。
角色
MSYSQL 8.0之前是没有角色的概念,可以通过用户组功能更实现。
开启用户组功能,实际环境需要配置到my.cnf中
show variables like "%proxy%";
set GLOBAL check_proxy_users =1;
set GLOBAL mysql_native_password_proxy_users = 1;
创建角色
CREATE USER 'admin';
创建用户
CREATE USER 'zhangsan';
CREATE USER 'lisi';
把用户和角色绑定
GRANT PROXY ON 'admin' TO 'zhangsan';
GRANT PROXY ON 'admin' TO 'lisi';
给角色赋权
GRANT sGelect(id,name) ON mall.account TO 'admin';
1.2 MYSQL数据类型
1.2.1 INT类型

无符号/有符号
项目中使用有符号数(默认),无符号可能会导致错误。示例:
create table test(a int unsigned,b int unsigned);
insert into test(1,2);
select a-b from test;//运行出错。
INT(N)
N表示显示宽度,不表示存储数字的长度上限。
ZEROFILL
当存储数字长度小于N时,用数字0填充左边。
1.2.2 字符类型

1.2.3 时间类型
| 类型 | 占用空间 | 表示范围 |
|---|---|---|
| DATETIME | 8 | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| DATE | 3 | 1000-01-01 ~ 9999-12-31 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00 ~ 2038-12-31 23:59:59 |
| YEAR | 1 | YEAR(2) 1970 ~ 2070,YEAR(4) 1901 ~ 2155 |
| TIME | 3 | -838:59:59 ~ 838:59:59 |
1.2.4 JSON类型
创建字段为json的表
create table test(id int ,data json)
插入数据
insert into test values(1,'{"name":"jdiy","age":20}');
JSON函数
json_extract 抽取
select json_extract(data,'$.name') from test;
json_object 将对象转换为json
select json_object("name","mark","age",22);
json_insert 插入数据
update test set data =json_insert(data,"$.address","gansu","$.phone","18000001234");
json_merge 合并数据
select json_merge('{"name":"zhangsan"}','{"age":10}');
其他函数
点击查看更多
JSON 索引
JSON类型数据本身无法直接创建索引,必须将需要索引的JSON数据重新生成虚拟列,对该列进行索引。
create table test_json_idx(id int ,data json ,json_idx varchar(10) generated always as(json_extract(data,'$.name')),index idx_json(json_idx));
二、MYSQL架构与存储引擎
2.1 MYSQL体系结构
连接层
每一个客户端请求,服务端都会新建一个线程处理,每个线程独立拥有各自的内存处理空间。
查看最大连接数:
show variables like '%max_connections%';
SQL处理层
主要完成SQL解析和优化、缓存查询、MYSQL内置实现等。
查看缓存是否开启:
show variables like '%query_cache_type%';//默认关闭
查看缓存大小:
show variables like '%query_cache_size%';//默认1M
SQL解析:
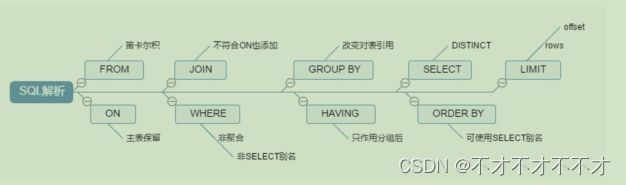
2.2 MYSQL逻辑架构

在mysql中schema 和 database是等价的。
2.3 MYSQL物理存储结构
数据存放地址
show variables like '%datadir%';
数据库
每次创建一个数据库,datadir目录新建一个文件夹。
表文件
存储在数据库文件夹下,frm文件存放表结构,ibd文件存储数据(不同的数据库引擎格式可能不一样)。
2.4 MYSQL存储引擎
查看数据库支持的存储引擎:
show engines;
MyISAM
Mysql5.5之前默认的存储引擎(已停止维护),适用场景:
1) 非事务型应用
2) 只读类应用
3) 空间类应用(空间函数、坐标)
InnoDB
支持事务、行级锁和外键。
CSV
以csv格式进行数据存储,所有列都不能为空,不支持索引,可以对数据文件直接编辑。
ARCHIVE
以zlib形式对表数据进行压缩,磁盘I/O更少,数据存储在.arz文件中。
只支持insert和select操作,只允许在自增ID列加索引。
MEMORY
1) 数据保存在内存中
2) 支持HASH索引和BTREE索引
3) 所有的字段都是固定长度 VARCHAR(10)=CHAR(10)
4) 不支持blog和text等大字段。
查看最大内存大小:
show variables like '%max_heap_table_size%';
FEDERATED
提供了访问远程MYSQL数据库表的方法,本地不存储数据,本地需要保存表结构和远程服务器连接信息。
三、MYSQL业务设计
3.1 锁
锁分类
表级锁
开销小、加锁快。不会出现死锁。锁粒度大,发生锁冲突的概率最高,并发度最低。
行级锁
开销大、加锁慢。会出现死锁。锁粒度最小,发生锁冲突的概率最低,并发度最高。
页面锁(gap锁、间隙锁)
开销介于表锁和行锁之间。会出现死锁。
表锁和行锁的使用场景
表锁适合于以查询为主,只有少量按索引更新数据的应用。如OLAP(联机分析处理)系统。
行锁适合于大量按索引并发更新少量不同数据,同时又有并发查询的应用。如OLTP(联机事务处理)系统。
MyISAM 锁
共享读锁
lock table <表名> read
独占写锁
lock table <表名> write
读锁,当前session只能读本表,其他操作(写本表、或读写其他表)都报错,其他session对本表的写操作会阻塞。
写锁,当前session对其他表的操作报错,其他session对本表的读、写操作会阻塞。
InnoDB 锁
共享读锁
lock in share mode;
其他事务对本行数据加写锁会阻塞。
独占写锁
for update;
其他事务对本行数据加写锁、读锁会阻塞。
两个事务不能锁同一个索引。
写操作在事务中会默认加上独占锁。
行锁必须由索引才能实现,否则会锁全表。
3.2 事务
事务的特性
1) 原子性(Atomicity)
一个事务必须被视为一个不可分割的最小单元,整个事务中的所有操作,要么全部成功,要么全部失败。
2) 一致性(Consistency)
事务将数据库从一个一致性状态转换到另外一种一致性状态,在事务开始之前和事务结束之后,数据库中数据的完整性没有被破坏。
3) 隔离性(Isolation)
一个事务内部的操作及使用的数据对其他事务是隔离的,各个事务之间不能相互干扰。
事务的隔离级别:
未提交读(READ UNCOMMITED)
已提交读(READ COMMITED)
可重复读(REPEATABLE READ) //默认级别
可串行化(SERIALIZABLE)
4) 持久性(Durability)
一旦事务提交,对数据的修改将会永久保存。
其他概念
脏读
事务A读取了事务B更新但未提交的数据。当B回滚,A读到的数据就是脏数据。
不可重复读
事务A多次读取同一数据,事务B在A读取的过程中对数据进行了修改,导致A多次读到的数据不一致。
幻读
事务A多次读取同一个表中的数据,事务B在A读取的过程新增或删除了数据,导致A多次读到的数据记录数不一致。
事务的语法
开启事务:
begin;
satart transcation;
begin work;
事务回滚:
rollback;
事务提交:
commit;
3.3 逻辑设计
数据库范式
第一范式:每一列的属性都是不可再分的属性。
第二范式:表中只具有一个业务主键(每行数据都能被唯一确定)
第三范式:每一个非主属性既不部分依赖、也不传递依赖于业务主键。
反范式设计
为了性能和读取效率考虑,适当对数据库范式进行违反。例如:允许少量的冗余。
3.4 物理设计
命名规范
遵守可读性原则
遵守表意性原则
遵守长名原则
数据类型选择
当一个数据可以有多种类型选择时:
1) 优先选择数字类型
2) 其次是日期、时间类型
3) 最后是字符类型
4) 对于相同级别的数据类型,优先选择占用空间较小的数据类型
四、MYSQL慢查询及索引
4.1 慢查询
MYSQL会将执行时间超过long_query_time的SQL语句记录在慢查询日志中。默认慢查询日志是关闭的。
慢查询配置
慢查询日志开启状态
show variables like "%slow_query_log%";
慢查询日志文件地址
show variables like "%slow_query_log_file%";
慢查询执行时间阈值
show variables like "%long_query_time%";
是否记录未使用索引的SQL
show variables like "%log_queries_not_using_indexes%";
查看日志存放方式
show variables like "%log_output%";//可选值table、file 、table,file
4.2 索引
索引是帮助mysql高效获取数据的数据结构。
索引的分类
普通索引:一个索引只包含单个列
唯一索引:索引列的值必须唯一,但允许为空。
复合索引:一个索引包含多个列。
基本语法
查看索引:
show index from table_name;
创建索引:
create [unique]index idx_name on table_name(col_name);
删除索引:
`drop index [index_name] on table_name;
4.3 执行计划
执行计划语法
EXPLAIN <sql>
执行计划详解
id列
描述查询语句的序列号,包含一组数字,表示查询中子句或操作表的顺序。
id数值结果可以分为三类:
1) id相同
执行顺序由上至下
2) id不同
id值越大,优先级越高。
3) id相同和不同并存
select_type
查询类型,分为以下类型:
1) SIMPLE
简单查询,不包含子查询或UNION。
2) PRIMARY
包含子查询等复杂查询的最外层查询(主要查询)。
3) SUBQUERY
子查询部分。
4) DERIVED
派生表的SELECT(FROM子句的子查询)
5) UNION
UNION中第二个及后面的查询。
6) UNION RESULT
从UNION中获取的结果。
table
显示当前行数据是关于哪张表
type
显示访问类型
system>const>eq_ref>ref>range>index>ALL
一般来说,保证查询至少达到range级别,最好是ref。
system:表中只有一行记录(系统表)。
const:通过索引一次找到。
eq_ref:对于每个索引,表中只有一行数据匹配。常见主键或唯一索引。
ref:非唯一索引扫描。
range:范围扫描,一般出现在between、<、>、in等查询。
index:查询结果为索引列,只查询索引库,不查询真实数据。
ALL:全表扫描。
possible_key 与 key
possible_key:可能的索引。
key:真实使用的索引,如果为null,则没有使用索引。
key_len
表示索引中使用的字节数,根据这个值可以判断索引的使用情况,特别是组合索引的时候,判断所有的索引字段是否被使用到。
latin1 占用 1 个字节,gbk 占用 2 个字节,utf8 占用 3 个字节。(不同字符编码占用的存储空间不同)
char类型,不可空时:key_len = char长度* 编码
char类型,可空时:key_len = char长度 *编码 + 1
varchar,不可空时:key_len = 长度编码 + 2
varchar,可空时:key_len = 长度编码 + 2 + 1
ref
显示索引的哪一列被使用了。
rows
大致估算需要读取的行数。
Extra
额外需要显示的信息。
Using filesort:无法利用索引进行排序。
Using temporary:使用了临时表保存结果。
Using where:使用了where过滤。
Using index:使用了覆盖索引。
Impossible where:where后的条件语句不成立。
4.4 SQL优化
SQL优化的策略
1) 尽量全值匹配
能在where条件中使用索引尽量使用。
2) 最佳靠前原则
如果索引包含了多列,where条件从最左列开始,不跳过索引中的列。
3) 不在索引列上做任何操作
包含计算、函数、自动或手动类型转换。
4) 范围条件方最后
如果范围放前面,可能导致后面的索引失效
5) 覆盖索引尽量用
6) 不等于要慎用
使用不等于(!=或<>)时,无法使用索引,会导致全表扫描。如果一定要使用,请使用覆盖索引。
7) null/not null 有影响
字段定义为not null(不可为空)时,使用 is null或is not null会导致索引失效。
字段定义为null(可为空)时,is not null会导致索引失效。
解决办法:使用覆盖索引。
8) like查询要当心
like以通配符%开头,会导致索引失效。
解决办法:使用覆盖索引。
9) 字符类型加引号
10) OR改UNION效率高
解决办法:使用覆盖索引