学习笔记 | Ch03 pandas入门和实战2 —— 数据运算、层次化索引
3.3 pandas数据运算
3.3.1 算术运算
pandas的数据对象在进行算数运算时:
- 如果有相同索引对则进行算术运算
- 如果没有则会引入缺失值,这就是
数据对齐。
对于DataFrame数据而言,对齐操作会同时发生在行和列上。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
obj1 = Series([3.2,5.3,-4.4,-3.7],index=['a','c','g','f'])
obj1
a 3.2
c 5.3
g -4.4
f -3.7
dtype: float64
obj2 = Series([5.0,-2,4.4,3.4],index=['a','b','c','d'])
obj2
a 5.0
b -2.0
c 4.4
d 3.4
dtype: float64
obj1+obj2
a 8.2
b NaN
c 9.7
d NaN
f NaN
g NaN
dtype: float64
df1 = DataFrame(np.arange(9).reshape(3,3),columns=['a','b','c'],index=['apple','tea','banana'])
df1

df2 = DataFrame(np.arange(9).reshape(3,3),columns=['a','b','d'],index=['apple','tea','coco'])
df2

df1+df2

s = df1.ix['apple']
s
a 0
b 1
c 2
Name: apple, dtype: int64
df1-s

3.3.2 函数应用和映射
在数据分析时,常常会对数据进行较复杂的数据运算,这时需要定义函数。
定义好的函数可以应用到pandas数据中,其中有三种方法:
map函数,将函数套用到Series的每个元素中;apply函数,将函数套用到DataFrame的行与列上;applymap函数,将函数套用到DataFrame的每个元素上。
lambda为匿名函数,和定义好的函数一样,可以节省代码量。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
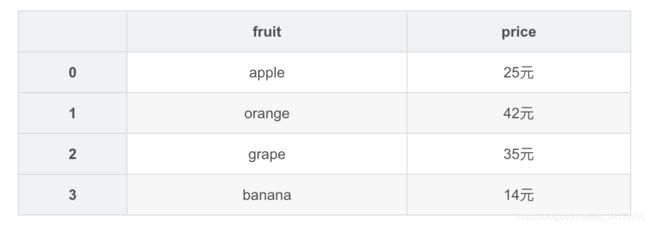
data = {
'fruit':['apple','orange','grape','banana'],
'price':['25元','42元','35元','14元']
}
df1 = DataFrame(data)
df1
def f(x):
return x.split('元')[0]
df1['price']=df1['price'].map(f)
df1

df2 = DataFrame(np.random.randn(3,3),columns=['a','b','c'],index=['app','win','mac'])
df2

f = lambda x:x.max()-x.min()
df2.apply(f)
a 1.853620
b 0.296043
c 1.015907
dtype: float64
df2.applymap(lambda x:'%.2f'%x)

3.3.3 排序
- 通过
sort_index函数可对索引进行排序,默认情况为升序。 - 通过
sort_values方法可对值进行排序。 - 对于
DataFrame数据而言,通过指定轴方向,使用sort_index函数可对行或者列索引进行排序。 - 要根据列进行排序,可以通过
sort_values函数把列名传给by参数即可。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
obj1 = Series([-2,3,2,1],index=['b','a','d','c'])
obj1
b -2
a 3
d 2
c 1
dtype: int64
obj1.sort_index()
a 3
b -2
c 1
d 2
dtype: int64
obj1.sort_index(ascending=False)
d 2
c 1
b -2
a 3
dtype: int64
obj1.sort_values()
b -2
c 1
d 2
a 3
dtype: int64
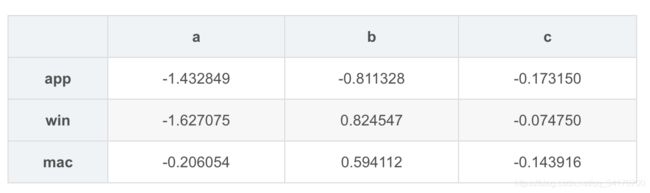
df2 = DataFrame(np.random.randn(3,3),columns=['a','b','c'],index=['app','win','mac'])
df2
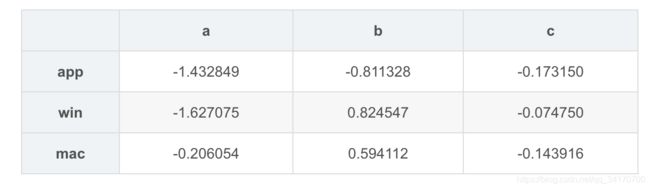
df2.sort_values(by='b')
df2
3.3.4 汇总与统计
- 在
DataFrame数据中,通过sum函数可以对每列进行求和汇总,与Excel中的sum函数类似。 - 指定轴方向,通过
sum函数可按行汇总。 describe方法可对每个数值型列进行统计,经常用于对数据的初步观察时使用。
df = DataFrame(np.random.randn(9).reshape(3,3),columns=['a','b','c'])
df

df.sum()
a 3.214396
b 0.981052
c 1.707930
dtype: float64
df.sum(axis=1)
0 3.951337
1 2.180063
2 -0.228023
dtype: float64
3.3.5 唯一值和值计数
- 在
Series中,通过unique函数可以获取不重复的数组。 - 通过
values_counts方法可统计每个值出现的次数。
- 对于
DataFrame的列而言,unique函数和values_counts方法同样适用,这里不再举例。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
data = {
'name':['张三','李四','王五','小明'],
'sex':['female','female','male','male'],
'year':[2001,2001,2003,2002],
'city':['北京','上海','广州','北京']
}
df = DataFrame(data)
df
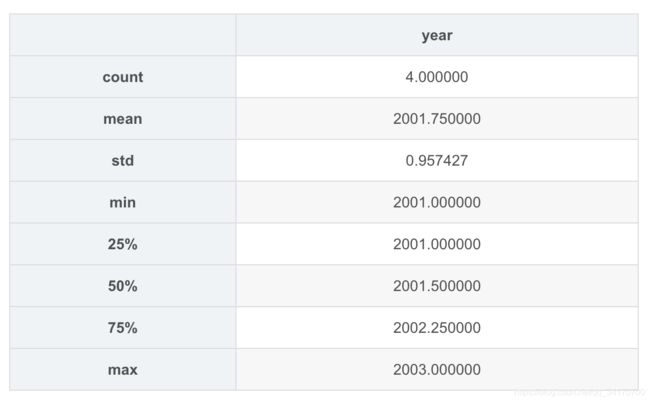
df.describe()
obj = Series(['a','b','a','c','b'])
obj
0 a
1 b
2 a
3 c
4 b
dtype: object
obj.unique()
array(['a', 'b', 'c'], dtype=object)
obj.value_counts()
b 2
a 2
c 1
dtype: int64
3.4 层次化索引
3.4.1 层次化索引简介
- 层次化索引就是轴上有多个级别索引,索引对象为
MultiIndex对象。 - 对于
DataFrame数据而言,行和列索引都可以为层次化索引。
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
obj = Series(np.random.randn(9),index=[['one','one','one','two','two','two','three','three','three'],['a','b','c','a','b','c','a','b','c']])
obj
one a -0.933845
b -0.572607
c 1.159502
two a -1.271014
b -0.819004
c -0.025532
three a 0.289312
b -0.658327
c 1.661820
dtype: float64
obj.index
MultiIndex(levels=[['one', 'three', 'two'], ['a', 'b', 'c']],
labels=[[0, 0, 0, 2, 2, 2, 1, 1, 1], [0, 1, 2, 0, 1, 2, 0, 1, 2]])
obj['two']
a -1.271014
b -0.819004
c -0.025532
dtype: float64
obj[:,'a']
one -0.933845
two -1.271014
three 0.289312
dtype: float64
3.4.2 重排分级顺序
- 通过
swaplevel方法对层次化索引进行重排。
3.4.3 汇总统计
- 在对层次化索引的
pandas数据进行汇总统计时,可以通过level参数指定在某层次上进行汇总统计。
df= DataFrame(np.arange(16).reshape(4,4),
index=[['one','one','two', 'two'], ['a', 'b', 'a','b']],
columns=[['apple','apple','orange','orange'],['red','green','red','green']])
df

df['apple']

df.swaplevel(0,1)
df.sum(level=0)
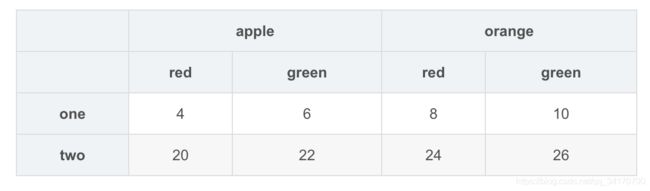
df.sum(level=1,axis=1)

参考资料
- 《从零开始学python数据分析》| 第3章