Java代码审计-设计模式-6大设计原则
Java设计模式-6大设计原则
目录
-
单一职责原则(Single Responsibility Principle,SRP)
-
里氏替换原则(Liskov Substitution Principle,LSP)
-
依赖倒置原则(Dependence Inversion Principle ,DIP)
-
接口隔离原则(Interface segregation Principle,IsP)
-
迪米特法则(Low of Demeter,LoD)
-
开闭原则(Open Closed Principle,OCP)
1、单一职责是最基础、也是最重要的设计原则
2、设计原则都在为解耦努力,但要适当解耦
一、单一职责原则(Single Responsibility Principle,SRP)
定义:应该有且仅有同一类原因引起类的变更
理解:类承担的职责要聚焦某一个或者某一类,例如用户管理功能中不应该有订单管理的功能。
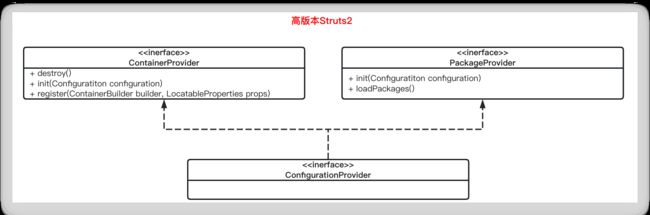
在Struts2中,2.0.8时配置加载的接口为ConfigurationProvider,而到后来的版本变为了ContainerProvider与PackageProvider两个接口,这也是单一职责的转变

来举个例子
业务:要实现一个APP,打车可以选择经济型、快捷性、方便型等
先看第一个版本
public class DiDi {
/**
* 选择乘车类型
* @param type 乘车类型
*/
public void drive(String type){
if (type == "jingji"){
System.out.println("经济型");
}
if (type == "kuaijie"){
System.out.println("快捷型");
}
if (type == "fangbian"){
System.out.println("方便型");
}
}
}
public class Test {
public static void main(String[] args) {
DiDi jingji = new DiDi();
jingji.drive("jingji");
DiDi fangbian = new DiDi();
fangbian.drive("fangbian");
}
}
第一个版本的代码完成了主要的业务功能,但如果产品经理要增加VIP乘车类型来完成对VIP的收费模式,就必须要修改DiDi类,而该类可能已经被十几个类使用,并且经过测试,业务上线运行了。此时修改DiDi类,估计测试部门的同事要疯了。这增加了测试的工作量,也增加了业务的风险。
所以要使用单一职责的设计模式,看一下改进之后的代码
/**
* 车的抽象类,都有行驶的功能
*/
public interface Car {
public void drive();
}
public class Jingji implements Car{
public void drive() {
System.out.println("经济型");
}
}
public class Vip implements Car{
public void drive() {
System.out.println("VIP车型" + ",额外收费10元");
}
}
public class Test {
public static void main(String[] args) {
Jingji jingji = new Jingji();
jingji.drive();
Vip vip = new Vip();
vip.drive();
}
}
代码升级之后,是不是可以灵活的应对需求变更?无论是增加车型,还是修改车型对应的服务,只需要修改对应的类就可以了,也只需要测试该类的相关类,做到了对代码的最小修改。
这里面的Car接口对应现在的需求其实并不是必须的,但对类的抽象是一种“默认的规则”,它在其它设计模式(策略、装饰)中是必须要进行抽象的。
二、里氏替换原则(Liskov Substitution Principle,LSP)
定义:
第一种:所有引用基类的地方必须能够透明地使用其子类的对象
第二种:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有对象o1都替换为o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型
理解:这是两种定义,比较复杂,晦涩难懂,我们来拆开说一下两种定义
第一种:基类是父类、子类通过extends关键字完成继承,从而建立父子类关系,以下面代码为例
/**
* 车的抽象类,都有行驶的功能
*/
public interface Car {
public void drive();
}
public class Jingji implements Car{
public void drive() {
System.out.println("经济型");
}
}
public class Vip implements Car{
public void drive() {
System.out.println("VIP车型" + ",额外收费10元");
}
}
public class Driver {
private Car car;
public void setCar(Car car){
this.car = car;
}
public void drive(){
this.car.drive();
}
}
public class Test {
public static void main(String[] args) {
Car car = new Vip();
Driver driver = new Driver();
driver.setCar(car);
driver.drive();
}
}
在回忆下定义:所有引用基类的地方必须能够透明地使用其子类的对象
父类:Car
子类:Jingji、Vip
引用基类的地方:Driver
引用基类的地方必须透明的使用其子类对象,在代码中我们可以使用Car的Jingji、Vip两个子类,只需要修改类名,而无需修改其它代码。
再看第二种定义:如果对每一个类型为S的对象o1,都有类型为T的对象o2,使得以T定义的所有程序P在所有对象o1都替换为o2时,程序P的行为没有发生变化,那么类型S是类型T的子类型
S类型对象o1:Vip
T类型对象o2:Car
程序P:Driver
当对象o1替换为o2:就是Vip变为Car
程序P的行为没有发生变化:都在调用drive方法,不需要修改代码
那么此时VIP是Car的子类
通过拆解发现,上面的代码是使用了里氏替换原则,使用extends、implements实现父子关系
里氏替换原则的优缺点,具有继承的所有优缺点:
优点:
- 提高代码重用性
- 子类可扩展自我特性
缺点:
- 具有侵入性,必须具有父类的所有属性和方法
- 降低灵活性,必须拥有父类的属性和方法,让子类多了约束
- 增强耦合性,如果修改父类的属性和方法,会对所有的子类产生影响
里氏替换原则为继承定义的规范,包含4层含义:
- 子类必须完全实现父类的方法
- 子类可以有自己个性
- 重载或者实现父类的方法时,输入参数可以放大
- 重写或者实现父类的方法时,输出结果可以被缩小
下面我们详细分解下以上四层含义
(一)子类必须完全实现父类的方法
代码还是使用上面Car的代码,类关系图如下

现在增加了玩具车类,继承Car接口,实现drive方法。但玩具车没有驾驶功能,所以不能直接继承Car接口,因为不能完整的实现父类的方法。
需要增加ToyCar类,继承Car,类关系图如下

代码如下
public class ToyCar implements Car {
public void drive() {
}
}
public class Toy119Car extends ToyCar{
@Override
public void drive() {
System.out.println("玩具消防车");
}
}
public class Test {
public static void main(String[] args) {
Car car = new Vip();
Driver driver = new Driver();
driver.setCar(car);
driver.drive();
Car toy119Car = new Toy119Car();
Driver children = new Driver();
children.setCar(toy119Car);
children.drive();
}
}
(二)子类可以有自己的个性
子类继承父类,如同孩子与父亲,孩子会有属于自己的特点,可以自己增加属性和方法,也可以重写、重载父类方法,例如
public class Jingji implements Car{
public void youhui(){
System.out.println("经济型车专属优惠券10元");
}
public void drive() {
youhui();
System.out.println("经济型");
}
}
(三)重载或者实现父类的方法时,输入参数可以放大
在讲该规则之前,先回忆下前置知识,就是方法的重写与重载
方法重写的规则:
- 参数列表与被重写方法的参数列表必须完全相同。
- 返回类型与被重写方法的返回类型可以不相同,但是必须是父类返回值的派生类(java5 及更早版本返回类型要一样,java7 及更高版本可以不同)。
- 访问权限不能比父类中被重写的方法的访问权限更低。例如:如果父类的一个方法被声明为 public,那么在子类中重写该方法就不能声明为 protected。
方法重载的规则:
- 被重载的方法必须改变参数列表(参数个数或类型不一样);
- 被重载的方法可以改变返回类型;
- 被重载的方法可以改变访问修饰符;
重载或者实现父类的方法时,输入参数可以放大。这句话的含义针对的是重载,因为重写不能修改参数。为什么覆盖或者实现父类的方法时,输入参数不能被缩小?我们先看一个例子
package org.principle.SRP.version4;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
/**
* 里氏替换原则代码
*/
public class Test {
public static void main(String[] args) {
Father f = new Father();
HashMap<String, String> hashMap = new HashMap<String, String>();
f.doSomething(hashMap);
System.out.println("里氏替换----------------父类存在的地方子类应该也可以存在-----------");
Son s = new Son();
s.doSomething(hashMap);
}
}
/**
* 定义一个父类,实现将map集合转换成Collection集合
* @author admin
*
*/
class Father{
public Collection doSomething(Map<String,String> map){
System.out.println(".......父类方法被执行...");
return map.values();
}
}
/**
* 子类重载父类的方法
* @author admin
*
*/
class Son extends Father{
/**
* 注意此处是重载,返回值类型,方法名相同,传入参数不同。
*/
public Collection doSomething(HashMap<String, String> map) {
System.out.println(".......子类方法被执行...");
return map.values();
}
}
.......父类方法被执行...
里氏替换----------------父类存在的地方子类应该也可以存在-----------
.......子类方法被执行...
上面代码的运行结果是什么?其实根据重载的语法要求就知道会调用Son的doSomething方法
因为Java会调用参数更小更精确的方法
如果子类参数范围小于父类就会违背:父类存在的地方子类也存在。
例如子类参数为HashMap,父类参数Map,Map的范围要比HashMap大,相当于子类缩小了范围。
代码运行起来没问题,但却会带来逻辑混乱,开发人员用的是Son类,因为Son类中有他想使用的方法A,Father类也有想用的方法B,这两个方法他都要调用,所以实例化Son类,但Son类却违反了基本规则,重写了Father的A方法(doSomething),导致开发人员并不知道(因为这是“君子约定”,所以不会看Son的源码,如果每调用一个子类方法都要比对有没有修改父类方法,这工作量太大),此时就会导致开发人员的代码执行结果和预想结果不一样,从而产生意向不到的错误。来看一个更加具体的例子
package org.principle.SRP.version5;
class A{
public int func1(int a, int b){
return a-b;
}
}
class B extends A{
public int func1(int a, int b){
return a+b;
}
public int func2(int a, int b){
return func1(a,b)+100;
}
}
public class Test{
public static void main(String[] args){
B b = new B();
System.out.println("100-50="+b.func1(100, 50));
System.out.println("100-80="+b.func1(100, 80));
System.out.println("100+20+100="+b.func2(100, 20));
}
}
100-50=150
100-80=180
100+20+100=220
奇怪吗?执行的结果竟然是100-50=150,这就是意料之外的错误,程序员擅自将func1的执行逻辑修改了!这就是父类存在的地方子类应该也存在,重写以及重载的参数范围变小都是变相的修改父类方法。
所以子类重载父类方法时,必须要保证子类传入参数的范围大于父类
(四)重写或者实现父类的方法时,输出结果可以被缩小
首先如果不遵守该规则,Java会报语法错误
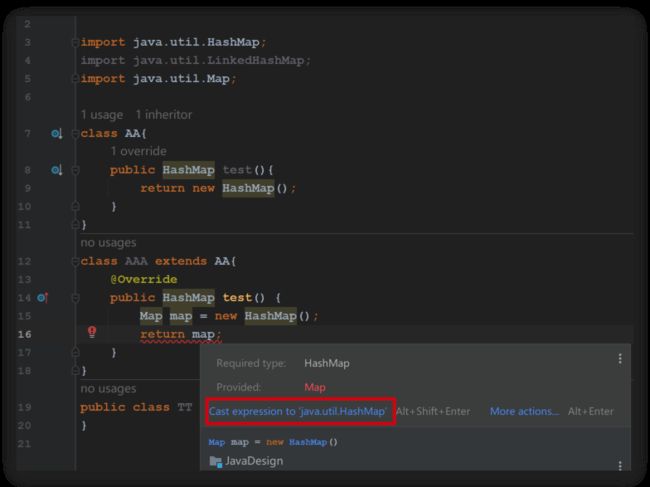
总结来说:如果父类的方法返回值类型时T,子类重写或实现父类方法的返回值类型是S,那么要求S必须小于等于T。里氏替换原则的目的就是增强程序的健壮性,在版本升级时也可以保持非常好的兼容性,即使增加子类,原有的子类还可以继续运行(参考上面Father、Son的例子)。在实际项目中每个子类代表不同的细分业务,父类作为业务的抽象类,父类作为参数时,无论子类如何变更都不会引起代码的修改。
三、依赖倒置原则(Dependence Inversion Principle ,DIP)
我们先来看一个例子,某天项目经理要求写一个羊了个羊游戏,在线养羊,于是程序员一天就写完了
package org.principle.DIP;
class Sheep{
// 宠物的名字
String name = "HappyShepp";
// 无参构造
public Sheep(){
}
// 构造方法传递名字
public Sheep(String name){
this.name = name;
}
public void eat(String food){
System.out.println(name + "在吃" + food);
}
}
/**
*饲养员
*/
class Breeder{
Sheep sheep;
public void setSheep(Sheep sheep){
this.sheep = sheep;
}
public void feed(String food){
System.out.println("饲养员在喂HappyShepp食物:" + food);
}
}
public class Test {
public static void main(String[] args) {
Sheep sheep = new Sheep();
Breeder breeder = new Breeder();
breeder.setSheep(sheep);
breeder.feed("青草");
}
}
// 运行结果
饲养员在喂HappyShepp食物:青草
但是后来游戏火爆,有客户反应想养哈士奇,这时候怎么办?
- 增加一个哈士奇类
- 给饲养员类增加setHashiqi方法
有人会说这还不简单,但不要忘了,我们现在写的功能及其简单,而且修改原本代码后,要重新测试Breeder与Sheep,这显然是重复工作,是绝对不允许的。
这就是典型的依赖正置,说白了这就是典型的面向实现编程,你要什么,我实现什么,不考虑事情的本质和扩展性,如果从依赖倒置的角度去写,应该将Sheep抽象化,将Breeder也抽象化,抽象化是依赖倒置的基础条件。
看下面代码
package org.principle.DIP;
/**
* 动物的抽象类,因为饲养员饲养的不只是羊,后续可能还有很多动物
*/
abstract class Animal{
String name = "Animal";
// 无参构造
public Animal(){
}
// 构造方法传递名字
public Animal(String name){
this.name = name;
}
public abstract void eat(String food);
}
class Hashiqi extends Animal{
public Hashiqi(String name){
super(name);
}
public void eat(String food) {
System.out.println(name + "在吃" + food);
}
}
/**
* 饲养员的抽象类,后面所有的饲养员都是People的子类
* 哪怕后面饲养员变为驯兽员都没问题
*/
abstract class People{
String name = "快乐饲养员";
Animal animal;
public People(String name){
this.name = name;
}
public void setAnimal(Animal animal){
this.animal = animal;
}
}
class HappyBreeder extends People{
public HappyBreeder(String name) {
super(name);
}
public void feed(String food){
System.out.println(name + "在喂" + this.animal.name +"食物:" + food);
}
}
public class Test2 {
public static void main(String[] args) {
Hashiqi hashiqi = new Hashiqi("哈士奇");
HappyBreeder breeder = new HappyBreeder("快乐饲养员");
breeder.setAnimal(hashiqi);
breeder.feed("青草");
}
}
// 运行结果
快乐饲养员在喂哈士奇食物:青草
上面的代码用到了典型的依赖倒置,他将最终实现的功能进行抽象为Animal与People,而且setAnimal、setPeople参数也都是父类,这就保证了该类的稳定性,无论传什么子类,我都可以接受,这是不是就是里氏替换原则?
所以,依赖倒置的定义就是:
- 高级模块不应该依赖于低级模块。两者都应该依赖抽象。
- 抽象不应该依赖细节。
- 细节应该依赖于抽象。
低级模块:不可分割的原子实现类
高级模块:原子实现类的组合
抽象:抽象类、接口都是抽象的手段,不能被实例化
细节:实现类
面向实现编程就是面向细节、面向实现类编程,这是狭隘的,完全没有考虑程序的可扩展性。而依赖倒置就是面向接口接口编程,充分考虑可能的实现类的共同特点,使用抽象类、接口来建立实现类的依赖关系。对于依赖倒置应该遵循下面规则:
- 每个类都尽量有接口或者抽象类,或者两者都具备
- 变量的表面类型尽量是接口或者抽象类
- 任何类都不应该从具体类派生
- 尽量不要重写父类的方法,以及特殊的重载(例如违反里氏替换原则)
四、接口隔离原则(Interface segregation Principle,IsP)
什么是接口?
- 实例接口(Object Interface):Person zhangsan = new Person,Person类就是zhangSan的接口,Java中类也是一种接口
- 类接口(Class Interface):Java中经常用interface定义接口
什么是接口隔离?
- 客户端不需要依赖它不需要的接口
- 类的依赖关系应该建立在最小的接口上
总结来说:建立单一的接口,不要建立臃肿庞大的接口,因为实现类中可能只需要其中的某几个方法,不需要的方法,我不要实现。
说到这里,很多人会觉的接口隔离原则跟之前的单一职责原则很相似,其实不然。其一,单一职责原则原注重的是职责;而接口隔离原则注重对接口依赖的隔离。其二,单一职责原则主要是约束类,其次才是接口和方法,它针对的是程序中的实现和细节;而接口隔离原则主要约束接口,主要针对抽象,针对程序整体框架的构建。
例如一个接口的职责包含十个方法,各个模块按照规定的权限来访问,在单一职责原则中是允许的,因为这十个方法都属于同一种职责,无法拆分了。但接口隔离原则不允许,因为它要求”尽可能多的专门接口“,就是指给各个模块都应该是单一接口,多个模块就是多个接口,而不是都集成在一块,容纳所有需求。
例如对于汽车的描述,汽车有座椅加热、涡轮增压、自动驾驶这些功能,代码可以这样实现
package org.principle.ISP;
interface Car{
public void seatHeating();
public void autoPilot();
public void turbo();
}
/**
* 奔驰比较牛,三个功能都有
*/
class Benz implements Car {
public void seatHeating() {
System.out.println("座椅加热");
}
public void autoPilot() {
System.out.println("自动驾驶");
}
public void turbo() {
System.out.println("涡轮增压");
}
}
/**
* 三菱价格低,没有座椅加热
*/
class SanLing implements Car {
public void seatHeating() {
}
public void autoPilot() {
System.out.println("自动驾驶");
}
public void turbo() {
System.out.println("涡轮增压");
}
}
Car的三个功能奔驰都有,但三菱只有两个,但受限于语法问题,三个方法都得实现,只不过SeatHeating是个空方法,是不是很奇怪?太多余了!不优雅
所以应当拆分Car接口,例如下面代码
package org.principle.ISP;
interface SeatHeating{
public void seatHeating();
}
interface AutoPilot{
public void autoPilot();
}
interface Turbo{
public void turbo();
}
class BenzX implements SeatHeating,AutoPilot,Turbo{
public void seatHeating() {
System.out.println("座椅加热");
}
public void autoPilot() {
System.out.println("自动驾驶");
}
public void turbo() {
System.out.println("涡轮增压");
}
}
class SanLingX implements SeatHeating,AutoPilot{
public void seatHeating() {
System.out.println("座椅加热");
}
public void autoPilot() {
System.out.println("自动驾驶");
}
}
现在就变的非常优雅,非常清晰,没有多余,但并不是所有接口都只有一个方法,一个接口可以多个方法,这里只是演示使用。
那接口的隔离做的粒度越小越好吗?当然不是。虽然增加了灵活度,但降低了维护性,所以接口的设计要因项目而已,把握好”度“是关键。
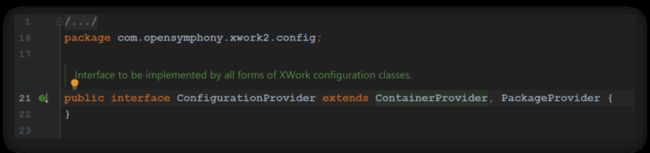
在Struts2中,对于配置的抽象类ConfigurationProvider低版本只是这一个接口,高版本的ConfigurationProvider拆分为了ContainerProvider、PackageProvider,这就是接口隔离的典型应用

五、迪米特法则(Low of Demeter,LoD)
也称为最少知识原则(Least Knowledge Principle , LKP),对于初学者来说,这样的定义实在是太晦涩了。
- 一个类对自己耦合的类或者调用的类知道的越少越好,你内部如何复杂和我没关系
- 只和直接朋友交流(直接朋友是:耦合关系、组合、聚合、依赖)
朋友的定义是这样的:出现在成员变量、方法的输入输出参数中的类称为朋友类,而方法内部的类不属于朋友类,迪米特法则认为,一个对象或方法,只能调用以下对象:
- 该对象本身
- 方法的参数对象
当A类的方法调用了B类,B类调用C类完成业务,如果A类中也出现了C类,那么三者之间的耦合性将大大增加,例如C类出现代码变更,那么可能会影响A类和B类的代码,这无疑是增加了代码风险。
模拟一个超时购物的场景
package org.principle.LOD;
// 钱包
class Wallet {
// 钱包里装的钱
private Float value;
// 构造器
public Wallet(Float value) {
this.value = value;
}
// 获得钱包里的钱的金额
public Float getMoney(){
return this.value;
}
// 付账时 减钱
public void reduceMoney(Float money){
this.value -= money;
}
}
// 顾客
class Customer {
private Wallet wallet = new Wallet(50f);
public Wallet getWallet() {
return wallet;
}
}
// 收银员
class PaperBoy {
// 收银员收钱
public void charge(Customer customer,Float money){
Wallet wallet = customer.getWallet();
if (wallet.getMoney() >= money){
System.out.println("顾客付账:" + money +"元");
// 减去 应付的钱
wallet.reduceMoney(money);
System.out.println("钱包里还剩:"+wallet.getMoney()+"元");
} else {
System.out.println("钱包里的金额不够......");
}
}
}
public class Test {
public static void main(String[] args) {
PaperBoy paperBoy = new PaperBoy();
Customer customer = new Customer();
paperBoy.charge(customer,20f);
}
}
在PaperBoy中的charge方法中出现了Wallet类,在Customer中也出现了Wallet类,而且观察PaperBoy.charge方法,PaperBoy竟然调用了wallet.reduceMoney(money);也就是拿着客户的钱包付钱,这反常态,你怎么可以动我钱包呢。所以他们之间的关系太乱,需要修改
// 顾客
class Customer {
private Wallet wallet = new Wallet(50f);
// 顾客自己付钱
public void pay(Float money){
if (wallet.getMoney() >= money){
System.out.println("顾客付账:" + money +"元");
// 减去 应付的钱
wallet.reduceMoney(money);
System.out.println("钱包里还剩:"+wallet.getMoney()+"元");
} else {
System.out.println("钱包里的金额不够......");
}
}
}
// 收银员
class PaperBoy {
// 收银员收钱
public void charge(Customer customer,Float money){
customer.pay(money);
}
}
这样PaperBoy只是提出收费的要求,但具体客户怎么付,是刷卡还是现金,这都与我没有关系。通过分析:
- 顾客
Customer和钱包Wallet是朋友 - 顾客
Customer和收银员PaperBoy是朋友 - 钱包
Wallet和收银员PaperBoy是陌生人
这就符合了迪米特法则:只和朋友交流,不和陌生人说话。该法则的观念就是类之间的解耦,只有解耦了,类的复用率才高,但也会导致与单一职责、依赖倒置、接口隔离相同的问题:产生大量的类,提高了系统的复杂性,所以在使用时也需要因项目而异,反复斟酌。
六、开闭原则(Open Closed Principle,OCP)
在前面讲到过:编程语言的所有设计都在为解耦努力,解耦的目的是让模块之间的依赖变小,例如迪米特原则(只和朋友交流,减少对外公开方法),例如单一职责、接口隔离等等都在实现解耦,这叫【低耦合】,对应的还有个词语叫做【高内聚】,这就是经典的高内聚、低耦合。
内聚,从字面上来看有聚精会神、聚在一起的意思,那么 高内聚也就是尽可能的使一个模块或一个类再或者是一个方法只专注做好一件事。
我们在设计软件的时候一定要采取【多聚合、少继承】的基本原则,因为使用 “聚合” 的这种方式能够使业务逻辑更加清晰,更有利于我们后期的扩展和维护。
耦合,从字面上来看有藕断丝连的意思。那么低耦合也就是尽可能的使每个模块之间或者每个类之间再或者是每个方法之间的关联关系减少,这样可以使各自尽可能的独立,一个地方出错,不会影响全部,更能提高代码的重用性。
我们在设计软件的时候也一定要注意各模块之间一定尽可能的减少联系,防止一个模块出现的问题影响到其他模块。
而开闭原则同样也是高内聚、低耦合的表现,它的定义是
一个软件实体如类、模块和函数应该对扩展开放,对修改关闭
通俗来讲就是一个软件实体应该通过扩展来实现变化,而不是通过修改已有的代码来实现变化。软件实体指的就是代码,例如一个模块、类、方法。
一个软件的开发周期总是坎坷的,伴随着多种多样的变化,但同样的也有不变的地方,一般会这样去做
不变的地方:进行抽象,使代码稳定,当代码实现后尽可能的不去修改
变的地方:通过实现类实现,通过抽象类和接口建立类与类之间的耦合关系
用例子说明开闭原则,需求是销售饮料
package org.principle.OCP.version1;
public interface Water {
public String getName();
public String getColor();
public int getPrice();
}
package org.principle.OCP.version1;
public class Cola implements Water{
private String name = "可口可乐";
private String color = "黑色";
private int price = 4;
public Cola(String name, String color, int price){
this.name = name;
this.color = color;
this.price = price;
}
public String getName() {
return name;
}
public String getColor() {
return color;
}
public int getPrice() {
return price;
}
@Override
public String toString() {
return "【" + getName() + "】是【" + getColor() + "】颜色的,价格为【" + getPrice() + "】元";
}
}
public class Customer {
public static void main(String[] args) {
Water cola = new Cola("可口可乐","黑色",4);
System.out.println(cola.toString());
Water baishi = new Cola("百事可乐","黑色",5);
System.out.println(baishi.toString());
}
}
上述代码是Customer类创建可乐对象,从而获得价格,这是一个很简单的代码。但需求变了,需要打8折销售,请问如何实现?
- 修改Cola的getPrice方法代码,加入打八折功能,这是最直接的,但有问题,我想看原价怎么办?
- 在Cola类中,添加打折方法discountPrice,也可以,但需要修改Water接口,这带来的影响就太大了,如果Water接口被10个类实现,那么就会影响10个类,这显然是不现实的,接口是约束、契约,是稳定的,不能随意修改
- 增加一个DiscountCola类,继承Cola,然后重写getPirce方法,这样无需改动已有代码只需要增加类即可,这就满足了**【扩展开发,对修改关闭】**
看一下代码实现
package org.principle.OCP.version1;
public class DiscountCola extends Cola{
public DiscountCola(String name, String color, int price) {
super(name, color, price);
}
@Override
public int getPrice() {
return (int) (super.getPrice() * 0.8);
}
}
package org.principle.OCP.version1;
public class Customer {
public static void main(String[] args) {
Water cola = new Cola("可口可乐","黑色",4);
System.out.println(cola.toString());
Water baishi = new Cola("百事可乐","黑色",5);
System.out.println(baishi.toString());
// 打八折
Water discountCola = new DiscountCola("百事可乐","黑色",5);
System.out.println(discountCola.toString());
}
}
代码做了2个更改,一个是增加DiscountCola类,二是修改了Customer类,但马上会觉得修改业务需求后,项目代码还是变了。这里不要钻牛角尖,项目的需求是多变的,代码肯定也会随之改动,但我们要把控好“度”,尽可能的封装不变的地方,将经常变化的地方根据设计原则、设计模式改进为扩展性强的代码,功能的增加、需求的变更,肯定会带来代码的改变,但要尽可能的减少对原有代码的修改,这就很考验架构设计。以上的案例,更合理的设计是使用装饰模式,这个后面再讲。
但这次更改是修改的高层次模块,也就是经常变的地方,这部分代码必须在最少修改的情况下适应业务,减少风险。开闭原则并不代表不做任何修改。
变化可以总结为3种类型:
- 逻辑变化:单一逻辑,逻辑内不与其它模块耦合,例如算法a+b*c改为a+b+c,可以修改原类,可能它是一个bug,或者算法优化。但前提是所有依赖该算法的类都可以按照变化后的逻辑进行处理
- 子模块变化:模块变化必然影响其它模块,除非它是完全孤立的。特别是低层次的模块,例如接口、抽象类,前面的案例就是典型
- 可见视图变化:例如Java中可以使用JSP、Swing界面,如果界面与业务逻辑耦合太大,那么更换视图则会伤筋动骨,视图与业务代码都要修改。这就考验我们的设计是否灵活。
使用开闭原则有什么好处呢?
- 对测试友好:上线之后的代码都是有意义的,而且经过了严格的测试,如果因为业务的增加,却修改了低层次模块(接口、抽象类),或者原有代码,就意味着原有的测试代码需要重新写,如果这个代码历史悠久,请问,你敢动吗?
- 提高复用性:代码功能越是单一,越能提高复用性,单一职责、接口隔离都是这样的。这避免了修改A功能时,对B功能产生影响
- 提高维护性:你退出项目组后,接手你工作的同事更喜欢扩展类,而不是修改原类,无论你写的多优秀,让别人读懂都是很痛苦的事情
- 面向对象的开发要求:万物皆对象,每个对象都有变化的特点,而如何应对变化就需要策略,这就需要再设计之初考虑所有变化因素,然后留下接口,等待“可能”变为“现实”