Spark必读!总有一些Spark知识点你需要知道
作者介绍
周明,去哪网算法开发工程师。2018年加入去哪儿网,主要从事推荐算法相关工作。
这篇文章可以带给你什么
-
不太了解 Spark :可以快速对 Spark 有个简单且清晰的认知,同时知道Spark可以用来做什么,对于经常处理大数据的同学可以思考如何运用到自己的工作中;
-
刚开始写 Spark :一起来回顾 Spark 基础概念和原理,避免新手那些常见的坑,培养性能优化意识,知道如何做性能调优;
-
Spark 老司机 :一起来回顾 Spark 的三三两两,知识点查缺补漏。
一、Spark 的由来

花一些篇幅来讲讲大数据技术的发展史,可以帮助我们更好理解 Spark 诞生的历史背景。
今天我们常说的大数据技术,其实起源于 Google 在 2004 年前后发表的三篇论文,也就是我们经常听到的“三驾马车”,分别是分布式文件系统 GFS 、大数据分布式计算框架 MapReduce 和 NoSQL 数据库系统 BigTable 。
2006年,Lucene 开源项目的创始人 Doug Cutting 基于论文原理开发了 Hadoop ,主要包括 Hadoop 分布式文件系统 HDFS 和大数据计算引擎 MapReduce ,Hadoop 一经发布便引起轰动,Yahoo 、百度和阿里巴巴等知名互联网公司逐渐使用 Hadoop 进行大数据存储与计算。
早期使用 MapReduce 进行大数据编程很复杂,于是Yahoo工程师们开发了一种使用类 SQL 语法的脚本语言 Pig , Pig 脚本经过编译后会生成 MapReduce 程序,然后在 Hadoop 上运行。但毕竟是类 SQL 语法,大量 SQL 数据开发者的迁移学习成本还是很高,于是 Facebook 发布了 Hive ,支持使用 SQL 语法进行大数据计算,Hive 会把 SQL 语句转化成 Map 和 Reduce 的计算程序。
在 Hadoop 早期,MapReduce 既是一个执行引擎,又是一个资源调度框架,MapReduce 维护困难且模块臃肿。于是2012年一个专门负责资源调度的系统Yarn诞生了。同年, UC 伯克利 AMP 实验室开发的基于内存计算的 Spark 开始崭露头角。由于 MapReduce 进行复杂大数据计算的时候需要频繁 I/O 磁盘操作,导致使用 MapReduce 执行效率非常慢,而且在当时内存已经突破了容量和成本限制,所以基于内存计算的 Spark 一经推出,立即受到业界的追捧,并逐步替代 MapReduce 在企业应用中的地位。
以上这些计算框架处理的业务场景都被称作批处理计算,而在大数据领域,还有另外一类应用场景,它们需要对实时产生的大量数据进行即时计算,2014 年三个流计算框架 Storm (毫米级计算响应,但吞吐量低)、 Spark Streaming (秒级响应,但吞吐量高) 和 Flink (毫米级计算响应,同时吞吐量高) 成为 Apache 的顶级项目,开启流计算时代。
二、What is MapReduce?
上节我们知道 Spark 带着比 MapReduce 更快更高更强的使命诞生,我们有必要了解什么是 MapReduce 。
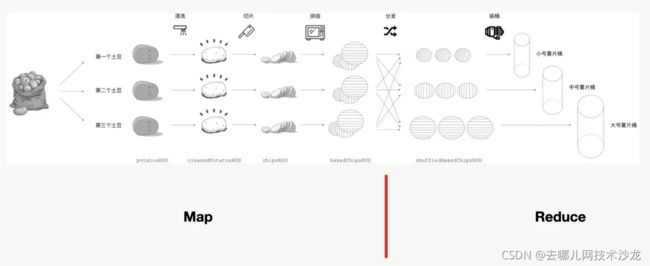
我们从薯片的加工流程来介绍一个MapReduce是如何运作的:
首先,有 3 颗土豆作为原始素材被送上流水线。流水线的第一道工序是清洗。第二道工序是切片,土豆经过切片操作后,变成了一枚枚大小不一、薄薄的薯片。第三道工序就是烘焙。
到此为止我们可以把以上三道不同工序看作是Map阶段的不同算子,通过Map阶段生产出了尺寸参差不齐的薯片。
随后进行分发环节( Reduce ),分发操作先把不同尺寸的薯片区分开,然后分发到指定流水线上完成装桶。
整个加工流程就是一次 MapReduce 。
三、MapReduce 的历史局限性
尽管 MapReduce 在当时提出来的时候轰动一时,但由于历史局限性,它还是存在以下弊端:
- 仅支持 Map 和 Reduce 两种操作。
- 复杂应用场景下,存在大量的磁盘 I/O 操作(当时内存还很贵)和排序合并操作,处理效率极低。我们知道一个逻辑复杂的计算,会转换成多个
- MapReduce 作业,而每个 MapReduce 作业都反复对磁盘进行读写。
不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘) 和流计算(点击日志分析)。 - MapReduce 编程不够灵活。
于是,留给 Spark 需要解决的问题是:
- 可否支持多种表达丰富的算子?
- 可否避免反复的磁盘读写和排序合并?
- 能否一站式支持?
- 能否从复杂的 MapReduce 编程中抽离出来,支持多种编程语言 api ?
四、Why Spark?
在历史长河中,时代选择了 Spark。我们来看看它是如何解决了历史问题,并且它的主要优势是什么?
首先是快,快是 Spark 的立命之本,随着大数据应用场景越发复杂,大家需要更快的大数据框架。Spark 官网测试,Spark 运行速率比 Hadoop 快 100 倍,主要是由于 Spark 基于 RDD 和 DAG 的内存计算减少反复的 I/O 操作,同时通过不断优化的 shuffle 机制改进 shuffle 过程中的排序合并,并且 Spark SQL 做到了可以自动优化;
其次是易于使用,MapReduce 仅支持 Map 和 Reduce 两种操作,而 Spark 具有丰富的算子库,满足大数据开发需求,同时支持多种语言 api ,包括 Java、Scala、Python、R 和 SQL ,进一步扩大了 Spark 的影响力;
然后是一站式,在 Spark 生态系统中支持一站式构建应用,先后推出了友好支持 sql 的 Spark SQL,流计算框架 Spark Streaming ,机器学习算法库 Spark MLib 以及支持图计算的Spark GraphX,由此可见,Spark 野心很大;
最后是Runs Everywhere,从 Hadoop 上可以简单迁移到 Spark,同时支持 Hadoop YARN ,并支持多种数据源:HDFS、HBase、Hive 等。
也许到这里,善于总结的你会得出一个结论:Spark 之所以比 MapReduce 快,主要是因为基于内存计算的 Spark 要优于需要大量 I/O 磁盘操作的 MapReduce ,这是一个大家刚开始接触 Spark 的常见的误解,内存计算并不是 Spark 的独特之处,因为 Spark 和 MapReduce 的计算都发生在内存中,它们之间的区别是,在复杂计算中需要多个 MapReduce 操作的时候,Spark 不需要将中间结果写入磁盘,进而减少 I/O 操作,比这更重要的是, Spark 是如何做到这一点的呢?这主要是得益于 Spark 的 DAG 和 RDD,DAG 记录了 Job 的 Stage 以及在 Job 的执行过程中父 RDD 和子 RDD 之间的依赖关系(这些概念不熟没关系,后面会介绍),而正是基于这种架构设计,使得计算的中间结果能够以 RDD 的形式存放在内存中,并且能够从 DAG 中恢复,从而大大减少了磁盘 I/O ,而 MapReduce 提出的历史环境下,内存比磁盘更为昂贵,所以从一定角度上,是时代造就了 Spark。
五、Spark 的一些基础概念
我们先来介绍一些 Spark 的基础概念:
- RDD,弹性分布式数据集,可以认为是 Spark 在执行分布式计算时的一批来源相同、结构相同、用途相同的数据集。
- DAG,RDD 的有向无环图,DAG记录了 Job 的 Stage 以及在 Job 执行过程中父 RDD 和子 RDD 之间的依赖关系。
- Job,在一个 Application 中,以 Action 为划分 Job 边界,一个 Job 包含N个Transformation 算子和1个 Action 算子。
- Stage,用户提交的计算任务本质上是一个由 RDD 构成的 DAG,如果 RDD 在转换的时候需要做Shuffle(宽依赖),那么这个Shuffle的过程就将这个DAG分为了不同的阶段(即Stage)。由于Shuffle的存在,不同的Stage是不能并行计算的,因为后面Stage的计算需要前面Stage的Shuffle的结果。
- Task,对一个Stage之内的RDD进行串行操作的计算任务。每个Stage由一组并发的Task组成,这些Task的执行逻辑完全相同,只是作用于不同的Partition。一个Stage的总Task的个数由Stage中最后的一个RDD的Partition的个数决定。
六、Spark 提交过程
了解完一些基础概念后,我们来看看当我们提交一个Spark任务后,系统都执行了哪些步骤?
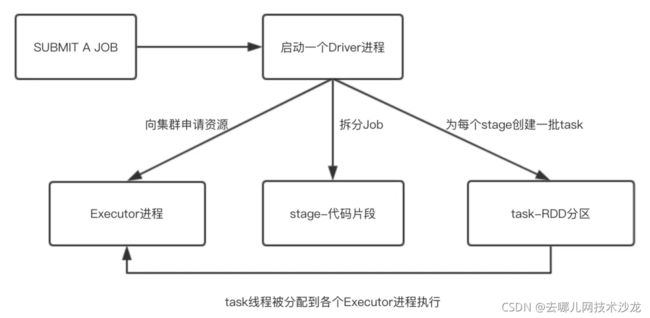
首先,每个Spark任务会对应启动一个 Driver 进程, Driver 进程启动模式由 Spark 任务提交类型不同而不同,主要区别如下:
- local(本地模式):Driver进程直接运行在本地
- yarn-client:Driver运行在本地
- yarn-cluster:Driver运行在集群(NodeManager)
其次,Driver进程为Spark任务申请资源:向集群管理器Resource Manager申请运行Spark作业需要使用的资源,主要的资源是Executor进程及其所需的CPU core,进程数和CPU core数均可通过Spark任务设置的资源参数来指定;
第三,Driver进程会将Spark任务代码按照宽依赖算子分拆为多个Stage;
第四,Driver进程为每个Stage创建一批Task;
最后,将这些Task分配到各个Executor进程中执行。
七、Spark Web UI
我们可以通过 Spark 的 Web UI 来查看 Spark 任务进展,以及 DAG 图、Job 划分、Stage 划分、Executor 和 Task 进程执行情况等,Web UI 也是我们性能调优的起点和重要观测工具。
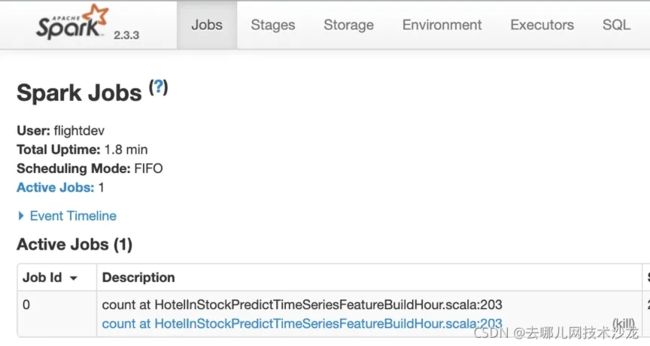
八、Spark 性能优化
我们在实际 Spark 开发中不免遇到图中所示的这些问题,大部分这些问题都是由于数据量太大或编写的 Spark 代码性能差导致各种内存溢出、栈溢出。这里提供几个 Spark 性能优化的思路。

思路一:从实际业务和代码规范角度,从根源上避免数据冗余
这里举减少数据冗余几个例子:
- 如果我们是使用 Spark SQL 从 HDFS 中读取数据并进行数据计算,那么这时候可以先基于实际业务场景检查 where 条件,尽量减少无效数据,比如在做国内业务的时候,就把国际数据剔除;
- 在左 join 的时候检查右表的 join key 是否唯一,避免 join 后数据爆炸;
- cache 的使用,当需要对一个 RDD 进行多次算子操作时,应该使用 RDD 的持久化策略并复用同一个 RDD;
下图我们展示了 RDD 的几种持久化策略。
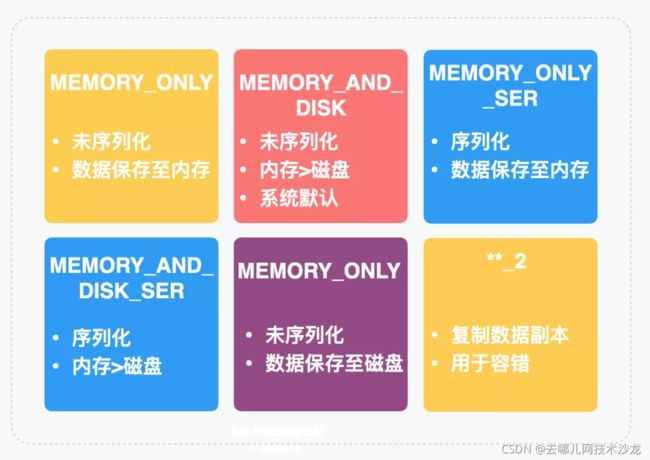
那么如何选择持久化策略呢?
- 性能最高的是 MEMORY_ONLY ,但前提是你的内存必须足够足够大,否则容易内存溢出
- 如果发生了内存溢出,使用 MEMORYONLYSER 级别,序列化降低内存占用,减少频繁 GC ,但多了序列化与反序列化的开销,同时无法根本上避免内存溢出
- 如果纯内存级别都无法使用,那么可以使用 MEMORYANDDISKSER 策略或 MEMORYAND_DISK 策略
- 通常不建议使用 DISKONLY (完全基于磁盘文件进行数据的读写)和后缀为 2 的级别,后缀为 _2 的持久化策略会为数据创建一份副本并保存到其他节点,数据复制和副本传输导致的网络开销会导致性能下降,但优点是高可用。
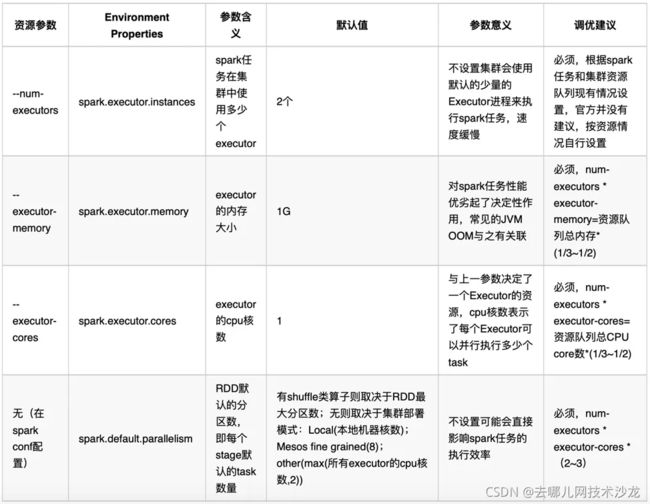
思路二:常用 Spark 参数优化
这里总结了几个常见的优化参数:
思路三:导致Spark任务慢的主要原因 — 数据倾斜
什么是数据倾斜?
在 Spark 作业运行过程中,一个重要的性能消耗地方是 Shuffle 过程。一个 Shuffle 过程需要将分布在集群中多个节点上的同一个 key ,拉取到同一个节点上,进行聚合或 join 等操作,比如 reduceByKey 、 join 等算子,都会触发 Shuffle 操作。而在 Shuffle 过程中,可能会发生大量的磁盘文件读写的 IO 操作,以及数据的网络传输操作,并且如果数据中 key 的分布极其不均衡(在实际业务场景很常见,比如代理商或爬虫用户行为比普通用户多很多),就容易导致某些 Task 执行时间过长(可以在前面介绍的 Web UI 上查看每个 Task 的执行时长和处理数据大小),甚至可能因为某个 Task 处理的数据量过大导致内存溢出,最终任务失败。
数据倾斜的基础解法
-
遇到数据倾斜怎么办呢?可以按照如下步骤解决大部分问题:
基于前面介绍的 Web UI ,查看哪些 Task 执行较为异常,可以看执行时间以及处理的数据量,进而确定 Task 位于哪个 Stage ,按照 Stage 划分原理以及 Web UI 上指定的代码行数,可以定位数据倾斜发生在哪段代码; -
定位到导致数据倾斜的代码段之后,根据不同算子做具体分析,比如是 groupBy 或 join 导致的 Shuffle ,可以查看 RDD 的 key 分布,统计每个 key 出现次数,按降序排序进行分析;
-
如果发现导致倾斜的 key 就少数几个,而且对业务本身的影响并不大的话,可以考虑直接过滤掉那少数几个 key ,比如计算用户点击行为的时候,发现有user_name=“0”的用户点击次数是普通用户的数十万倍,我们可以直接过滤这种少数导致数据倾斜的 key,这种方式实现简单,可以从根本上解决数据倾斜,但适用场景不多,且可能具有业务风险,如果是构建机器学习模型训练样本,可能会导致线上线下数据分布不一致;
-
提高 Shuffle 操作的并行度(spark.sql.shuffle.partitions),增加shuffle read task的数量,可以让原本分配给一个 Task 的多个 key 分配给多个 Task ,从而让每个 Task 处理比原来更少的数据,但这种方式一般可以解决大部分问题,但无法彻底根除数据倾斜问题,比如如果数据极其不均衡,比如一个 key 对应十万条数据,那么无论你的 Task 数量增加到多少,这个对应着 10万 数据的 key 肯定还是会分配到一个 Task 中去处理。
避免使用Shuffle类算子
避免使用 Shuffle 类算子,比如使用 Map join 替代 Reduce join (普通的join),使用 Broadcast 变量与 Map 类算子实现 join 操作,进而完全规避掉 Shuffle 类的操作,彻底避免数据倾斜的发生和出现。具体操作是将较小 RDD 中的数据可以通过创建 Broadcast 变量将这部分数据广播到每一个 Executor 中,对另外一个 RDD 执行 Map 操作与其中的每一条数据按照 key 进行比对即可。
但这种方式仅适用大表 join 小表,且小表大小在几百 M ,或者一两 G 的情况,适用范围比较小。
数据倾斜优化 — key 散列设计再聚合
key 散列设计再聚合,Spark 的 Shuffle 操作导致的数据倾斜问题在一定意义上可以类比 HBase 的热点问题,因此 HBase 的 RowKey 的散列设计思想可以套用在聚合类的 Shuffle 操作导致的数据倾斜场景,具体怎么做呢?
首先对 key 进行 hash 散列,一般使用随机数,或者针对 key 的具体内容进行 hash ,目的是将原本一个数据量大的 key 先 hash 成 k 个数据量较少的 key ,那么原本必须拉取到一个 Task 上进行 Shuffle 计算的数据可以拉取到 k 个不同的 Task 上计算,在一定程度上缓解了单个 Task 处理过多数据而导致的数据倾斜。
然后再对局部聚合后的 key 去除 hash 后再聚合得到最终聚合结果。这种 key 散列设计思想广泛使用在由 join 类的 Shuffle 算子导致的数据倾斜中。同样, Flink 上的 keyBey 引起的数据倾斜导致 Flink 任务频繁挂掉,也可以使用这种方法。
九、总结
这篇文章主要分享了什么:
-
介绍了Spark的历史背景和历史使命
-
Spark基础概念和Web UI
-
Spark性能优化
期待能给你带来:
-
更全面理解Spark
-
利用Spark解决实际工作问题
-
强化性能优化意识和能力
