链表的创建与使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
目录
文章目录
前言
一、链表是什么?
二、链表的创建与基本操作
1.链表的创建
3.链表的头插
4.链表的尾插
5.链表的销毁
6.链表的查找
7.链表的删除
8.链表的排序
总结
前言
数组作为学习c语言以来,一直使用的一种存储方式,有着查找方便,读取数据快的特点。但是存在数组大小开辟固定,内存使用需要成块,修改插入数据操作繁琐的劣势。链表的学习可以让以上问题得到解决。
一、链表是什么?
链表是由一个又一个结点组成的存储结构,每个结点包含一个指针域和一个数据域,数据域存储数据,指针域存储下一个结点的地址。
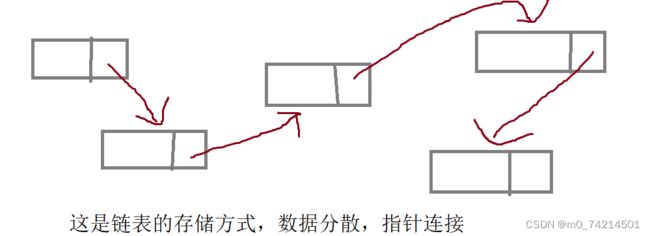
结点的结构
typedef struct Lnode
{
ElemType data;
struct Lnode* next;
}Lnode,*LinkList;注释:
1.头结点:链表的第一个链表,数据域为空,指针指向首元结点,没有存储数据的功能。存在的意义为,操作链表的时候更方便。
2.首元结点:真实意义上的第一个结点,头结点指向的结点。
3.尾结点:链表的最后一个结点,当链表为空的时候,尾结点就是头结点。
4.前驱结点:当前结点的前面一个结点。
链表包括单链表,循环链表与双向链表,三种类型
1.单链表
尾结点指针指向空指针的链表。
2.循环链表
尾结点指针指向头结点的链表,与单链表的主要区别是,在遍历操作时,循环的判断条件有改变。
3.双向链表
在以上结点的基础上,添加一个指向前驱结点的指针,使得操作变得复杂,存储密度变低,但是时间复杂度低,属于拿空间换时间。
二、链表的创建与基本操作
以下操作皆为单链表
1.链表的创建
个人喜欢创建的链表既有头指针又有尾指针,这样的链表可以实现的操作更多,更实用。
size的设计,用来记录结点个数,实现一些操作。
typedef struct S
{
int data;
struct S* next;
}S, * SS;
typedef struct List
{
SS First;
SS End;
int size;
}List, * LList;2.链表的初始化
给链表申请一块地址,即头结点,数据域赋空,指针域置空。
void Initial_List(LList str)
{
str->End = str->First = (SS)malloc(sizeof(S));
assert(str->First != NULL);
str->size = 0;
str->First->data = 0;
str->First->next = NULL;
}
3.链表的头插
在链表的头结点与首元结点之间插入。每次插入后size加一。
void Tou_cha(LList str)
{
SS a;
a = (SS)malloc(sizeof(S));
assert(a != NULL);
scanf("%d", &a->data);
a->next = str->First->next;
str->First->next = a;
str->size++;
}头插的关键在于下面这两行
a->next = str->First->next;
str->First->next = a;
如图所示将新结点的指针域指向首元结点,头结点指针指向新结点,完成头插。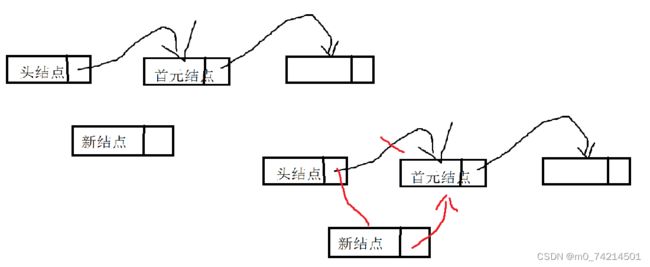
4.链表的尾插
在链表的尾部插入。
void Wei_cha(LList str)
{
SS a = (SS)malloc(sizeof(S));
assert(a != NULL);
scanf("%d", &a->data);
a->next = NULL;
str->End->next = a;
str->End = a;
str->size++;
}关键在
str->End->next = a;
str->End = a;就是让原先的尾结点指针域指向新结点,然后将尾结点更新为新结点
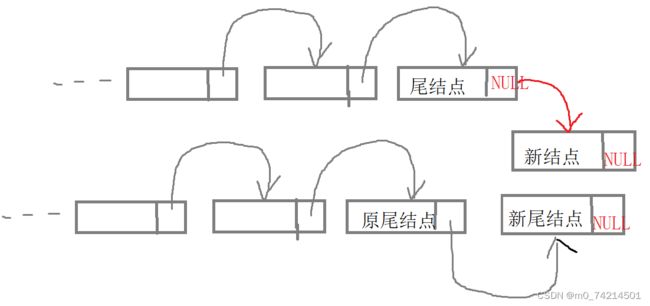
5.链表的销毁
将链表销毁,只保留头结点
void Xiao_hui(LList str)
{
while (str->First->next != NULL)
{
SS A = str->First->next;
str->First->next = A->next;
free(A);
A = NULL;
str->size--;
}
str->End = str->First;
}这个思路是从首元结点依次释放掉,在释放过程中要注意下一结点的保留,确保数据不丢失。
所以我们就创建一个量临变量指针,存储首元结点,同时将首元结点的指针域赋值给头指针的指针域。之后将临时变量释放掉,就实现了一个结点的销毁也就是删除。如此循环到尾结点,就实现链表的销毁,最后将尾指针赋值为头指针。
6.链表的查找
这个比较简单,两个循环判断条件,如果是a为空指针了,那么说明直到最后一个结点,都没有找到。反之则是找到了
void Find(LList str)
{
int b;
scanf("请输入查找的数:%d", &b);
SS a = str->First->next;
while (a != NULL && a->data != b)
{
a = a->next;
}
if (a == NULL)
{
printf("没有找到\n");
return;
}
else
{
printf("找到了\n");
return;
}
}7.链表的删除
删除有头删,尾删两种方式。主要思路就是,将要删除的结点的前驱结点指向该结点的后面一个结点,然后将该结点释放掉。
头删:创建一个指针A,赋值为首元结点的指针域,释放掉首元结点,将头指针的指针域赋为A
void Tou_shan(LList str)
{
SS a;
a = str->First->next->next;
free(str->First->next);
str->First->next = a;
str->size--;
}尾删:创建一个指针,通过递推,得到尾结点的前驱结点。将该结点的指针域置空,释放尾结点,将该结点赋为新尾结点。
void Wei_shan(LList str)
{
SS a;
a = str->First;
while (a->next != str->End)
a = a->next;
a->next = NULL;
free(str->End);
str->End = a;
str->size--;
}8.链表的排序
链表的排序,操作相较以上操作要复杂一点。思路是将原链表断开。断点是首元结点与它后面一个结点中间。然后将后面一个链表的结点逐一插入到前面一个链表里面。
void Pai_xu(LList str)
{
SS b = str->First->next->next;
SS a = str->First->next;
a->next = NULL;
while (b != NULL)
{
SS c = str->First;
SS d = b;
b = b->next;
while (c->next!= NULL && c->next->data < d->data)//这一步判断条件的设定特别重要。在比较的时候一定要注意拿该结点的后面一个结点去比较。不然在某些情况下,头结点会参与排序。
{
c = c->next;
}
if (c->next == NULL)
{
a->next = d;
d->next = NULL;
a = d;
}
else
{
d->next = c->next;
c->next = d;
}
}
printf("排序成功\n");
str->End = a;
}总结
初识链表,可能觉得链表的使用复杂,不实用。但是随着知识的深入,你会发现链表有这许多优点,比如:插入修改数据的低空间复杂度,存储空间的灵活性......
最后,链表的基础操作并不是很难,但对一些基础知识要求比较高。如果很大困难的,可以先去复习一下,指针的使用、动态内存的开辟。
新人,有错误,多多指导,谢谢观看。