2019独角兽企业重金招聘Python工程师标准>>> 
这几天笔者阅读了一下Spring In Action 4,感觉还是有一定的收获的。在之前的项目上,只会简单地使用Spring MVC,对于很多概念并不理解。现在看看Spring的一些概念,如DI和AOP,以及Spring的各个模块,对于Spring这一整体框架可以有较深的了解。
这篇文章将主要以翻译的形式来讲解Spring,中间夹杂对于原文的理解,以及代码实现,相信对于读者会带来一定的帮助,也是对自己阅读的一个总结。如果读者有不同的见解,还望可以共同探讨一下。顺带推荐一下Manning的In Action系列,笔者此前读了《机器学习实战》,外加上现在看的《Spring实战》,感觉真心不错,国外的许多书籍,相比国内简直是良心之作。但是,中文译本的更新永远无法赶上英文原本的进度,就拿Spring来说,第三版的中文译本还停留在Spring 3,然而Spring已经升级到了4版本,而英文原本紧跟技术进度,相比之下,第四版的中文译本,还不知要到何年何月。当然,文章的翻译除了要花费长时间的努力,还需要译者对技术有较为深入的了解,在此,还是要感谢那些辛勤的贡献者。笔者翻译此书的目的,是为了在读书的同时,能够总结到一些有用的知识,并期望能给读者带来一定的收获。
(题外话:由于开通了邮箱通知功能,近期Windows10任务栏右边总是会显示邮件提示。有一些问题,由于笔者也没有去深度地探究Spring MVC这个框架,也无法做出具体的回答,但相信前面几篇文章对于入门开发还是存在一定的帮助的。真正的项目开发肯定会比教程中更加复杂,因为除了业务逻辑,还有许多重要的问题,如高并发、多线程,以及至关重要的安全问题,是需要考虑进来的。)
接下来,进入正题。。。(转载请说明出处:Gaussic,AI研究生)
Part 1 Spring 核心(Core Spring )
Spring能做很多事情。但是对于Spring的所有的奇妙功能,它们的主要特征是依赖注入(dependency indection, DI)和面向方面编程(aspect-oriented programming, AOP,也可以译为面向切面编程)。
第一章,付诸行动(Springing into action),我将带给你一个Spring 框架的快速概览,包括Spring中的DI和AOP的快速概览,并展示它们是如何帮助降低应用组件(components)的耦合度的。
第二章,装配Bean(Wiring Beans),我们将更为深入地探讨如何将应用的各个组件拼凑在一起。我们将着眼于自动配置(automatic configuration)、基于Java的配置,和XML配置,这三种Spring提供的配置方法。
第三章,高级装配(Advanced Wiring),将展示一些小把戏和手段,它们将帮助你深度挖掘Spring的强大能力,包括有条件的配置(conditional configuration),用以处理自动装配(autowiring)、范围控制(scoping)以及Spring表达式语言(Spring Expression Language, Spring EL)。
第四章,面向方面的Spring(Aspect-oriented Spring),探究如何使用Spring的AOP特征来解除系统级的服务(例如安全和审计(auditing))以及它们所服务的对象之间的耦合度。这一章为之后的章节搭建了一个起始平台,例如第9、13和14章,它们讲解了如何在声明式安全(declarative security)和缓存。
第一章 付诸行动(Springing into action)
对于Java开发者来说,现在是一个很好的时期。
在20年的历史中,Java经历过一些好的时期以及不好的时期。尽管存在着一些粗糙点(rough spots),例如applets, Enterprise JavaBeans(EJB), Java Data Objects(JDO),以及数不尽的日志框架,Java仍然拥有着一个丰富的多样化的历史,作为许多企业级软件的平台而言。而且,Spring在这一段历史上占有很重要的一笔。
在早期,Spring作为更加重量级的Java技术(特别是EJB)的替代品被创造出来。相比EJB,Spring提供了一个更轻量更简洁的的编程模型。它给予了普通Java对象(POJO)更加强大的能力,而这些能力是EJB和一些其他Java规格才拥有的。
随着时间的过去,EJB和J2EE得到了发展。EJB开始自身提供简单的面向POJO的变成模型。现在EJB利用了诸如依赖注入和面向方面变成的思想,可以说其灵感来自于Spring的成功。
虽然J2EE(现在被称为JEE)可以赶上Spring,但是Spring从未停止前进的脚步。Spring持续的发展各个领域。而这些领域,即使是现在,JEE才刚刚开始开始探索,甚至还未引入。移动开发,社交API集成,NoSQL数据库,云计算,以及大数据只是Spring引入的一小部分领域。而且,未来的Spring依然一片光明。
正如我所说,对于开发者来说,现在是一个很好的时期。
这本书是对Spring的一个探索。在这一章节,我们将在高层次测试Spring,让你品尝一下Spring到底是什么。这一章将让你明白Spring到底解决了各种什么样的问题,并且未这本书的其余部分做好准备。
1.1 简化Java开发
Spring是由Rod Johnson创造的一个开源框架。Spring被创造出来以解决企业级应用开发的复杂问题,并且让普通的JavaBeans(plain-vanilla JavaBeans)能够完成此前只有EJB才可能完成的任务。但是Spring的用处并不仅仅局限于服务器端开发。而且Java应用可以从Spring中获益,例如间接性、可测试性以及松耦合。
另一种意义的bean...虽然在表示应用组件时,Spring大方地使用了bean和JavaBean这两个词,但这并不表示一个Spring组件必须严格地遵从JavaBean的规格。一个Spring组件可以是任何形式的POJO。在本书中,我假设JavaBean是一个宽松的定义,与POJO同义。
通过本书你将了解到,Spring做了许多事情。但是Spring提供的几乎每一个功能的根基,是一些非常基础的想法,全部专注于Spring的基本任务:Spring简化Java开发。
这里是粗体!大量的框架说要简化某一些事物。但是Spring旨在简化Java开发这一广泛主题。这还需要更多的解释。Spring是如何简化Java开发的呢?
为了支持对Java复杂度的攻击,Spring利用了4个关键策略:
利用POJO的轻量级与最小侵入式开发(Lightweight and minimally invasive development with POJOs)
通过DI和面向接口实现松耦合(Loose coupling through DI and interface orientation)
通过方面和普通惯例实现声明式编程(Declarative programming through aspects and common conventions)
利用方面和模板消除陈词滥调的代码(Eliminating boilerplate code with aspects and templates)
基本上Spring做的每一件事都可以追溯到这四条策略中的一条或几条上。在这一章节的其他部分,我将扩展到这些想法的每一个中去,展示具体的例子以解释Spring是如何完成其简化Java开发的目标的。让我们从Spring如何通过鼓励面向POJO的开发来保持最小化侵入式的(minimally invasive,这点不好翻译,大致意思是不怎么需要修改POJO的代码)。
1.1.1 释放POJOs的力量
如果你做过很长时间的Java开发工作,你可能会发现某些框架会牢牢地困住你,它们强制你去继承某一个类或实现某一个接口。侵略式编程模型一个简单目标例子(easy-target example)是EJB 2-era stateless session beans(不详,在此不做翻译)。但是即使早期的EJBs是这样一个简单目标,侵入式编程编程仍然能在早期版本的Struts, WebWork, Tapestry,以及无数其他的Java规格与框架中找到。
Spring(尽可能地)避免其API污染你的应用代码。Spring几乎从来不强迫你去实现一个Spring接口,或集成一个Spring类。反而,一个基于Spring的应用中的类通常并没有指示它们为Spring所用。最坏情况,一个类可能被Spring的一个注解标注,但是它另一方面是一个POJO。
为了说明,考虑HelloWorldBean类。
如你所见,这很简单,就是一个普通的Java类,一个POJO。它并没有什么特殊的东西以表明它是一个Spring组件。Spring的非侵入式编程模型表示,这个类在Spring中同样可以很好的工作,就像它能在其他非Spring应用中一样。
尽管样式非常简单,POJOs依然可以很强大。Spring使得POJOs更强大的一个方法是利用DI装配(assembling)它们。让我们看看DI是如何帮助解除应用对象之间的耦合度的。
1.1.2 注入依赖
依赖注入这个词听起来可能有点高大上,让人联想出一些复杂的编程技术或设计模式的概念。但是结果证明,DI并没有听起来那么复杂。通过在你的项目中利用DI,你将发现你的代码将得到极大地简化,更容易理解,更容易测试。
DI是如何工作的
任何非平凡的应用(比Hello World要复杂的多)都是有相互协作的多个类组成的,以执行一些业务逻辑。传统地,每一个对象负责获取对它自己的依赖(与他协作的对象)的引用。这将会带来高度耦合和难以测试的代码。
例如,考虑下面的Knight类。
package com.gaussic.knights;
// 一个专门拯救少女的骑士
public class DamselRescuingKnight implements Knight {
private RescueDamselQuest quest; // 拯救少女任务
// 这里出现了与RescueDamselQuest的紧密耦合
public DamselRescuingKnight() {
this.quest = new RescueDamselQuest();
}
// 骑士出征
public void embarkOnQuest() {
quest.embark();
}
} 相信大家都知道骑士与龙的故事,一个勇敢的骑士,除了能够打败巨龙之外,还需要拯救被囚禁的少女。但是在上面的DamselRescuingKnight中,我们发现他在构造器中创建了他自己的任务,一个RescueDamselQuest(也就是说,这个骑士构造出来时心里就只有一个任务,就是拯救少女,注意这个任务是发自内心的)。这导致了DamselRescuingKnight与RescueDamselQuest的高度耦合,这严重限制了骑士的行动。如果有一位少女需要拯救,那么这个骑士将会出现。但是如果需要屠龙呢,或者需要开个圆桌会议呢,那这个骑士将被一脚踹开。
此外,给DamselRescuingKnight写一个单元测试是非常困难的。在这个测试中,你需要能够保证,在骑士的embarkOnQuest()方法被调用时,quest的embark()方法也被调用。但是在这里并没有明确的方法来完成它。不幸的是,DamselRescuingKnight将保持未测试状态。
耦合是一个双头猛兽。一方面,紧密耦合的代码难以测试,难以重用,且难以理解,并且经常表现出“打地鼠”的bug行为(修复了一个bug,又产生了一个或多个新的bug)。另一方面,一定数量的耦合还是有必要的,完全不耦合的代码做不了任何事情。为了做一些有用的事情,类之间应该互相具有一定的认识。耦合是必需的,但是需要仔细管理。
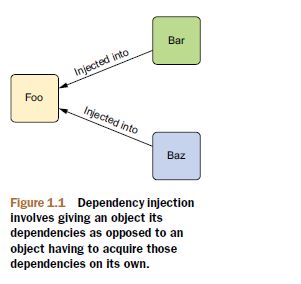
利用DI,对象在构建时被给予它们的依赖,这通过一些定位系统中的每一个对象的三方来实现。对象不需要创建或获得它们的依赖。如图所示,依赖被注入到需要它们的对象中。
为了说明这一点,让我么看看BraveKnight类:一个骑士不仅仅要勇敢,还应该可以完成任何到来的任务。
package com.gaussic.knights;
// 一个勇敢的骑士,应该能完成任何到来的任务
public class BraveKnight implements Knight {
private Quest quest; // 任务,这是一个接口
// 构造器,注入Quest
public BraveKnight(Quest quest) {
this.quest = quest;
}
// 骑士出征
public void embarkOnQuest() {
quest.embark();
}
private BraveKnight() {}
} 如你所见,BraveKnight不像DamselRescuingKnight一样创建自己的任务,而是在构造的时候被传入了一个任务作为构造参数(也就是说,这个骑士构造出来时,有人给了他一个任务,他的目标是完成这个任务,想雇佣兵一样)。这种类型的注入被称为构造注入(constructor injection)。
此外,勇敢的骑士所赋予的任务是一个Quest类型,它是一个接口,所有的具体quest都要实现这个接口。因而BraveKnight可以挑战RescueDamselQuest,SlayDragonQuest,MakeRoundTableRounderQuest,或者任何其他的Quest。
这里的关键点是,BraveKnight并不与任何一个特定的Quest的实现耦合。对于给予了什么任务,他并不介意,只要它实现了Quest接口。这就是DI的一个关键益处-松耦合。如果一个对象仅仅通过依赖的接口(而不是它们的实现或者实例化)来了解这些依赖,那么这个依赖就可以自由地更换为不同的实现,而一方(在此为BraveKnight)不需要知道有任何的不同。
换出依赖的一个最普遍的方法是在测试时利用一个mock实现(one of the most common ways a dependency is swapped out is with a mock implementation during test)。由于紧耦合,你无法适合地测试DamselRescuingKnight,但是你可以轻松地测试BraveKnight,通过给它一个Quest的mock实现(其实就是构建了一个虚拟的Quest),如下所示:
(注意:运行以下测试需要引入junit包和mockito-core包)
package com.gaussic.knights.test;
import com.gaussic.knights.BraveKnight;
import com.gaussic.knights.Quest;
import org.junit.Test;
import org.mockito.Mockito;
// 一个勇敢的骑士,需要经历mock测试的考验
public class BraveKnightTest {
@Test
public void knightShouldEmbarkOnQuest() {
Quest mockQuest = Mockito.mock(Quest.class); // 构建 mock Quest,其实就是虚拟的Quest
BraveKnight knight = new BraveKnight(mockQuest); // 注入mockQuest
knight.embarkOnQuest();
Mockito.verify(mockQuest, Mockito.times(1)).embark();
}
} 在此使用了一个mock对象框架(Mockito)来创建一个Quest接口的虚拟实现。利用虚拟对象,我们可以创建一个新的BraveKnight实例,并通过构造器注入这一虚拟Quest。在调用embarkOnQuest()方法后,利用Mockito来验证虚拟Quest的embark()方法仅仅被调用一次。
将一个Quest注入到一个Knight中
现在,BraveKnight被写成了这样的形式,你可以将任何一个任务交给骑士,那么你应该如何指定给他什么Quest呢?假设,例如,你想要BraveKnight去完成一项屠龙的任务。可能是SlayDragonQuest,如下所示。
package com.gaussic.knights;
import java.io.PrintStream;
// 任务目标:屠杀巨龙
public class SlayDragonQuest implements Quest {
private PrintStream stream; // 允许自定义打印流
public SlayDragonQuest(PrintStream stream) {
this.stream = stream;
}
public SlayDragonQuest() {}
// 任务说明
public void embark() {
stream.println("Embark on quest to slay the dragon!");
}
} 如你所见,SlayDragonQuest实现了Quest接口,让其能很好的适应BraveKnight。你也可能注意到,SlayDragonQuest在构造时请求了一个普通的PrintStream,而不像其他的简单Java示例一样依靠System.out.println()。这里有一个大问题,怎样才能把SlayDragonQuest交给BraveKnight呢?还有怎样才能把PrintStream交给SlayDragonQuest呢?
在应用组件之间建立联系的行为,通常被称之为装配(wiring)。在Spring中,有很多将组件装配在一起的方法,但是通常的方法总是通过XML的。下面展示了一个简单的Spring配置文件,knight.xml,它将BraveKnight, SlayDragonQuest和PrintStream装配在了一起。
在此,BraveKnight和SlayDragonQuest在Spring中都被定义为bean。在BraveKnight bean中,它在构造是传入了一个SlayDragonQuest的引用,作为构造参数。同时,SlayDragonQuest bean中使用了Spring表达式语言来传递 System.out(这是一个PrintStream)给SlayDragonQuest的构造器。
如果说XML配置不符合你的口味,Spring还提供了基于Java的配置方法。如下所示。
package com.gaussic.knights;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
// @Configuration注解,声明这是一个配置类
@Configuration
public class KnightConfig {
// 与XML中的bean目的相同,声明一个SlayDragonQuest bean,传入System.out
@Bean
public Quest quest() {
return new SlayDragonQuest(System.out);
}
// 与XML中的bean目的相同,声明一个BraveKnight bean,传入quest
@Bean
public Knight knight() {
return new BraveKnight(quest());
}
} 无论是使用基于XML还是基于Java的配置,DI的益处都是相同的。虽然BraveKnight依赖于Quest,但它并不知道将被给予什么样的Quest,或者这个Quest是从哪里来的。同样的,SlayDragonQuest依赖于PrintStream,但是它并不需要了解那个PrintStream是什么。只有Spring,通过它的配置,知道所有的组件是如何组织到一起的。这样,我们就可以在不修改当前类的情况下,去修改它的依赖。
这个例子展示了Spring中装配bean的一个简单方法。先不要在意太多的细节,我们将会在第二章深入探讨Spring配置。我们也将探讨Spring中装配bean的一些其他办法,包括一种让Spring自动发现bean和创建它们之间关系的方法。
现在你已经生命了BraveKnight和Quest之间的关系,你需要载入XML配置文件并且打开应用。
看它工作
在Spring应用中,一个应用上下文(application context)载入bean的定义并将它们装配在一起。Spring应用上下文完全负责创建并装配所有构成应用的对象。Spring提供了多种应用上下文的实现,每一个主要的不同在于它们如何载入配置。
当bean被声明在xml文件中时,一个合适的方法是ClassPathXmlApplicationContext。这个Spring上下文实现从一个或多个(在应用的classpath目录的)XML文件载入Spring上下文。下面的main()方法使用了ClassPathXmlApplicationContext来载入knight.xml,并且获得对Knight对象的一个引用。
package com.gaussic.knights;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class KnightMain {
public static void main(String[] args) throws Exception {
// 从应用的classpath目录载入Spring配置文件
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("META-INF/spring/knight.xml");
// 获取bean,并执行
Knight knight = context.getBean(Knight.class);
knight.embarkOnQuest();
context.close();
}
} 此处,main()方法基于knight.xml文件创建了Spring上下文。然后它利用这个上下文作为一个工厂来检索ID为knight的bean。利用对Knight对象的一个引用,它调用了embarkOnQuest()方法来使knight执行给予他的任务。注意这个类并不知道骑士被赋予了什么样的任务。这样,它也不知道这个任务是交给BraveKnight做的。只有knight.xml知道具体的实现是什么。
运行KnightMain的main()方法,将得到下列结果:
利用这个例子,你应该对依赖注入有了一定的了解。在这本书中你将看到更多的DI。现在让我们来看看Spring的另一个Java简化策略:基于方面(aspects)的声明式编程。
1.1.3 方面(Aspects)的运用
虽然DI可以松散的绑定软件的各个组件,面向方面编程(AOP)还可以让你更够捕捉那些在整个应用中可重用的组件。
AOP经常被定义为一项提升软件系统分离性(separation of concerns)的技术。系统往往由多个组件构成,每一个组件负责一个特定的功能。但是通常这些组件还需要承担其核心功能以外的附加功能。一些系统服务,例如日志、事务管理和安全,往往会进入一些其他的组件中,而这些组件往往负责其他的核心功能。这些系统服务通常被称为交叉相关(cross-cutting concerns),因为它们在系统中往往交叉在多个组件内。
由于将这些相关性传播到了多个组件中,你向你的代码引入了两种层次的复杂度:
实现系统级相关性的代码在多个组件中存在重复。这表明如果你需要改变这些相关性的工作方式,你需要访问多个组件。即使你将这个相关性抽象为一个独立的模块,这样其他的组件可以通过模块调用来使用它,这个方法调用依然在多个组件里面重复。
你的组件被与核心功能无关的代码污染了。一个向地址簿添加一个地址的方法,应该仅仅关心如何去添加这个地址,而不是还得去关心它的安全性和事务性。
下图展示了这一复杂度。左边的业务对象太过亲密地与右边的系统服务相联系。每个对象不仅仅知道自己被日志记录、安全检查,以及涉及到事务中,而且还需要负责自己去执行这些服务。
AOP可以模块化这些服务,然后声明式地将它们运用到需要它们的组件中。这样可以使得其他组件更加紧密地专注于负责它们自己的功能,完全无视任何系统服务的存在。简单的说,方面(aspects)使得POJOs保持普通(plain)。
把方面想象成一个覆盖多个组件和应用的毯子可以帮助理解,如下图所示。在其核心部分,一个包含多个模块的应用实现了业务功能。利用AOP,你可以利用一层层的其他功能将你的核心应用覆盖。这些层可以声明式地运用到你的应用中,以一种更为灵活的方式,而不需要让你的核心应用知道他们的存在。这是一个很强大的概念,因为它保证安全、事务管理和日志不去污染你的应用的核心业务逻辑。
为了说明方面在Spring中是如何运用的,让我们再来看看骑士的例子,向其中添加一个基本的Spring方面。
AOP实战
勇敢的骑士在屠杀巨龙和拯救少女归来之后,我们这些百姓要如何才能知道他的丰功伟绩呢?吟游诗人(minstrel)会将勇士的故事编成歌谣在民间传颂(有网络红人就必然要有网络推手啊)。我们假设你需要通过吟游诗人的服务来记录骑士出征和归来的整个过程。下面展示了这个Minstrel类:
package com.gaussic.knights;
import java.io.PrintStream;
// 吟游诗人
public class Minstrel {
private PrintStream stream;
public Minstrel(PrintStream stream) {
this.stream = stream;
}
// 骑士出发前,颂唱
public void singBeforeQuest() {
stream.println("Fa la la, the knight is so brave!");
}
// 骑士归来,颂场
public void singAfterQuest() {
stream.println("Tee hee hee, the brave knight did embark on a quest!");
}
} 如你所见,Minstrel是一个有两个方法的简单类。singBeforeQuest()旨在骑士出发前调用,singAfrterQuest()旨在骑士完成任务归来调用。在这两种情况下,Minstrel都通过注入其构造器的PrintStrem来颂唱。
把这个Minstrel运用到你的代码中其实非常简单----你可以把它直接注入到BraveKnight中,对吗?让我们对BraveKnight做一点适当的调整,以使用Minstrel。下面的代码展示了将BraveKnight和Minstrel运用到一起的第一次尝试:
package com.gaussic.knights;
public class BraveKnight2 {
private Quest quest;
private Minstrel minstrel;
public BraveKnight2(Quest quest, Minstrel minstrel) {
this.quest = quest;
this.minstrel = minstrel;
}
// 一个骑士应该管理自己的吟游诗人吗???
public void embarkOnQuest() throws Exception {
minstrel.singBeforeQuest();
quest.embark();
minstrel.singAfterQuest();
}
} 上面的代码可以完成任务。现在你只需要回到Spring配置文件中去定义Minstrel bean,并将其注入到BraveKnight bean的构造器中。但是等等。。。。
好像有什么不对劲。。。一个骑士难道应该去管理他自己的吟游诗人吗?一个伟大的骑士是不会自己去传扬自身的功绩的,有节操的吟游诗人应该主动的去传颂伟大骑士的功绩,而不接受他人的收买。那么,为什么这里的骑士他时时地去提醒吟游诗人呢?
此外,由于这个骑士需要知道这个吟游诗人,你被强制将Minstrel注入到BraveKnight中。这不仅仅复杂化了BraveKnight的代码,还让我想到,如果你需要一个没有吟游诗人的骑士要怎么办?如果Minstrel是null那怎么办(骑士所处的地区,压根没有吟游诗人的存在)?那你是不是还要引入一些非空检查逻辑到你的代码里面呢?
你的简单的BraveKnight类开始变得越来越复杂(而骑士只想做一个纯粹的骑士)。但是,使用AOP,你可以声明,吟游诗人应该主动地去颂唱骑士的功绩,而骑士只需要做好本职工作。
为了把Minstrel转变为一个方面,你要做的仅仅是在Spring配置文件中声明它。这是一个更新版的knight.xml,加入了Minstrel方面的声明:
这里你使用了Spring的 aop configuration 命名空间来声明Minstrel bean是一个方面。首先你声明Minstrel是一个bean。然后在
在以上两种情况中,pointcut-ref属性都引用了一个名为embark的pointcut(切入点)。这个pointcut定义在了之前的
如果你不了解AspectJ,或者AspectJ pointcut表达式是如何编写的,不用担心。我们将在第4章对Spring AOP做更多的讲解。现在,知道你要请求Spring在BraveKnight在出征前后,调用Minstrel的singBeforeQuest()和singAfterQuest()方法足矣。
现在,不改动KnightMain的任何地方,运行main()方法,结果如下:
这就是它的全部了!只需要一点点的XML,你就将Minstrel转换为了一个Spring方面。如果它现在还没完全说明白,不用担心,你将在第4章中看到更多的Spring AOP示例,它们将给你更明确的概念。现在,这个例子有两个重点需要强调。
第一,Minstrel仍然是一个POJO,没有任何代码表明它将被作为一个方面。Minstrel只在你在Spring context中声明时,才是一个方面。
第二,也是最重要的,Minstrel可以运用到BraveKnight中,而BraveKnight不需要明确地调用它。实际上,BraveKnight甚至一直不知道还有Minstrel的存在。
我还应该指出,虽然你使用了一些Spring的魔法来将Minstrel转化为一个方面,你还是需要将它先声明为一个bean。重点是,你可以用Spring aspects做任何的事情,像其他的Spring beans一样,例如将依赖注入给它们。
使用aspects来颂唱骑士的功绩是很好玩的。但是Spring的AOP可以用在更多实用的地方。在后面你将看到,Spring AOP可以用来提供服务,例如声明式事务、安全,将在第9章和14章介绍。
在这之前,我们来看看Spring简化Java开发的另一个方法。
1.1.4 利用模板消除重复代码
你是否写过一些看似之前写过的代码?这不是“似曾相似“,朋友。那是重复代码(boilerplate code)---为了执行常见或简单的任务需要一遍一遍的写相似的代码。
不幸的是,Java API的许多地方都含有重复的代码。使用JDBC做数据库查询就是一个明显的例子。如果你在使用JDBC,你可能需要写一些如下所示的代码:
public Employee getEmployeeById(long id) {
Connection conn = null;
PreparedStatement stmt = null;
ResultSet rs = null;
try {
conn = dataSource.getConnection(); // 建立连接
// 选择 employee
stmt = conn.prepareStatement("select id, firstname, lastname, salary from employee where id=?");
stmt.setLong(1, id);
rs = stmt.executeQuery();
Employee employee = null;
if (rs.next()) {
employee = new Employee(); // 创建对象
employee.setId(rs.getLong("id"));
employee.setFirstName(rs.getString("firstname"));
employee.setLastName(rs.getString("lastname"));
employee.setSalary(rs.getBigDecimal("salary"));
}
return employee;
} catch (SQLException e) { // 错误处理
} finally {
if (rs != null) { // 收拾残局
try {
rs.close();
} catch (SQLException e) {
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {
}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
}
}
}
return null;
} 如你所见,这个JDBC代码的目的是查询一个员工的名字和工资情况。由于这项特定的查询任务被埋藏在一堆的JDBC仪式中,你首先必须创建一个连接,然后创建一个陈述(statement),最后在查询结果。而且,为了安抚JDBC的脾气,你必须catch SQLException,其实就算它抛出了错误,你也没什么能够做的。
最后,在所有的事情都做完了,你还得收拾残局,关闭连接(connection)、陈述(statement)、结果集(result set)。这还是有可能出发JDBC的脾气,因而你还得catch SQLException。
上面代码最显著的问题是,如果你要做更多的JDBC查询,你将会写大量重复的代码。但是只有很少一部分是真正跟查询相关的,而JDBC重复代码要多得多。
在重复代码业务中,JDBC并不孤独。许多的工作都包含相似的重复代码。JMS、JNDI和大量的REST服务通常涉及到大量完全重复的代码。
Spring通过将重复代码封装在模板中来消除它们。Spring的JdbcTemplate可以在不需要所有传统JDBC仪式的情况下执行数据库操作。
例如,使用Spring的SimpleJdbcTemplate(JdbcTemplate的一个特定形式,利用了Java 5的优点),getEmployeeById()方法可以重写,使得它仅关注于检索员工数据的任务,而不需要考虑JDBC API的需求。下面的代码展示了更新后的getEmployeeById()的样子:
public Employee getEmployeeById(long id) {
return jdbcTemplate.queryForObject(
"select id, firstname, lastname, salary from employee where id=?", // SQL查询
new RowMapper() {
// 映射结果到对象
public Employee mapRow(ResultSet rs, int rowNum) throws SQLException {
Employee employee = new Employee();
employee.setId(rs.getLong("id"));
employee.setFirstName(rs.getString("firstname"));
employee.setLastName(rs.getString("lastname"));
employee.setSalary(rs.getBigDecimal("salary"));
return employee;
}
}, id);
} 如你所见,新版本的getEmployeeById()更加简洁且专注于从数据库中查询员工。模板的queryForObject()方法被给予一个SQL查询,一个RowMapper(为了将结果集数据映射到领域对象),以及0个或多个查询参数。你无法在getEmployeeById()中找到任何的JDBC重复代码。这一切都交给了模板来处理。
我已经想你展示了Spring是如何使用面向POJO的开发来降低Java开发复杂性的,DI, aspects 和 templates。同时,还展示了如何在XML配置文件中配置bean和aspect。但是如何载入这些文件呢?让我们看看Spring容器(container),存放应用的bean的地方。
1.2 盛装你的bean
在Spring应用中,你的应用对象住在Spring容器中。如图1.4所示,容器创建对象,然后将它们装配在一起,配置它们,然后管理它们的生命周期,从襁褓到坟墓。
在下一章节,你将了解如何配置Spring,使得它知道它需要创建、配置和装配什么对象。首先,知道对象什么时候hang out(闲逛?不好翻译)是很重要的。了解容器将帮助你了解对象是如何被管理的。
容器是Spring框架的核心。Spring的容器使用DI来管理组成一个应用的组件。这包括建立协调组件之间的联系。本身,这些组件更简洁切更易理解,它们支持重用,且易于单元测试。
没有单独的Spring容器。Spring包括多种的容器实现方法,可以分为两种独立的类型。Bean工厂(bean factory,由org.springframework.beans.factory.BeanFactory接口定义)是最简单的容器,提供DI的基本支持。应用上下文(application context,由org.springframework.context.ApplicationContext接口定义)建立与bean工厂的概念之上,提供应用框架服务,例如从配置文件中读取文本消息的能力和向感兴趣的事件监听器发送应用时间的能力。
虽然使用bean factory和application都可以,bean factory对于大部分应用来说还是太低级了。因此,相比bean factory,application context更受青睐。我们将专注于使用application context,而不花更多的时间在bean factory上。
1.2.1 使用应用上下文
Spring包含多种口味的应用上下文。以下是一部分你最有可能遇上的:
AnnotationConfigApplicationContext --- 从一个Java配置类中载入Spring应用上下文
AnnotationConfigWebApplicationContext --- 从一个Java配置类中载入Spring web应用上下文
ClassPathXmlApplicationContext --- 从一个或多个在classpath下的XML文件中载入Spring上下文,将上下文定义文件作为一个classpath资源文件
FileSystemXmlApplicationContext --- 从文件系统中的XML文件中载入上下文定义
XmlWebApplicationContext --- 从包含在一个web应用中的一个或多的XML文件中载入上下文定义
我们将在第八章讲解基于web的Spring应用时更加详细的说明AnnotationConfigWebApplicationContext和XmlWebApplicationContext。现在,让我们用FileSystemXmlApplicationContext从文件系统载入Spring上下文,或用ClassPathXmlApplicationContext从classpath载入Spring上下文。
从文件系统或classpath载入应用上下文与从bean factory中载入bean相类似。例如,下面是如何载入FileSystemXmlApplicationContext的:
ApplicationContext context = new FileSystemXmlApplicationContext("c:/knight.xml"); 类似地,可以使用ClassPathXmlApplicationContext从应用的classpath载入应用上下文:
ApplicationContext context = new ClassPathXmlApplicationContext("knight.xml"); FileSystemXmlApplicationContext和ClassPathXmlApplicationContext的不同之处在于,前者在文件系统的特定的位置寻找knight.xml,而后者在应用的classpath中寻找knight.xml。
另外,如果你更偏向从Java配置中载入你的应用上下文的话,可以使用AnnotationConfigApplicationContext:
ApplicationContext context = new AnnotationConfigApplicationContext(KnightConfig.class); 取代指定一个载入Spring应用上下文的XML文件外,AnnotationConfigApplicationContext被给以一个配置类来载入bean。
现在手头上有了一个应用上下文,你可以利用上下文的getBean()方法,从Spring容器中检索bean了。
现在你知道了如何创建Spring容器的基本方法,让我们更进一步的看看在Bean容器中一个bean的生命周期。
1.2.2 一个bean的一生
在传统的Java应用中,bean的生命周期非常简单。Java的关键词被用来实例化bean,然后这个bean就可以使用了。一旦这个bean不再使用,将会被垃圾收集器处理。
相比之下,在Spring容器中的bean的生命周期更加复杂。理解Spring bean的生命周期是非常重要的,因为你可能需要利用Spring提供的一些有点来定制一个bean什么时候被创建。图1.5展示了一个典型的bean在载入到应用上下文时的生命周期。
如你所见,一个bean工厂在bean可以被使用前,执行了一系列的设置操作。让我们来探讨一些细节:
Spring实例化bean。
Spring将值和bean引用注入到bean的属性中。
如果一个bean实现了BeanNameAware,Spring将这个bean的id传递给setBeanName()方法。
如果一个bean实习了BeanFactoryAware,Spring调用setBeanFactory()方法,将一个引用传入一个附入(enclosing)的应用上下文。
如果一个bean实现了BeanPostProcessor接口,Spring调用其postProcessBeforeInitialization()方法。
如果一个bean实现了InitializingBean接口,Spring调用其afterPropertiesSet()方法。类似的,如果这个bean使用了init-method进行声明,那么特定的初始化方法将被调用。
如果一个bean实现了BeanPostProcessor,Spring调用其postProcessAfterInitialization()方法。
在这点,bean就可以被应用使用了,并且一直保持在应用上下文中,直到应用上下文被销毁。
如果一个bean实现了DisposableBean接口,Spring调用其destroy()方法。同样,如果这个bean被声明了destroy-method,将会调用特定的方法。
现在你已经知道了如何创建并载入一个Spring容器。但是一个空的容器本身并没有什么好处,它不含任何东西,除非你将什么放进去。为了实现Spring DI的好处,你必须将Spring容器中的应用对象装配起来。我们将在第二章节更加详细的讲解bean的装配。
首先,我们来调查一下现代Spring的蓝图(landscape),来看看Spring框架是由什么构成的,以及后面版本的Spring提供了什么新的特性。
1.3 Spring版图概览
如你所见,Spring框架专注于通过DI、AOP和减少重复来简化企业Java开发。即使那是Spring的全部,那也是值得一用的。但是对于Spring来说,还有很多令你难以置信的东西。
在Spring框架中,你将发现许多Spring简化Java开发的方法。但是,在Spring框架之上,是一个更大的建立在核心框架之上的项目生态系统,将Spring扩展到更多的领域,例如web services, REST, mobile和NoSQL。
让我们先来分解一下核心Spring框架,来看看它给我们带来了什么。然后我们再扩展我们的视野来看看Spring包的更多成员。
Spring模块
当你下载了Spring distriution之后,查看它的libs目录,你将发现多个JAR文件。在Spring 4.0中,有20个独立的模块,每个模块有3个JAR文件(binary class, source, JavaDoc)。完整的library JAR文件如图1.6所示。
这些模块可以被排成6个功能的类,如图1.7所示。
总的来说,这些模块给了你任何你需要的东西,来开发企业级应用。但是你不需要让你的应用完全基于Spring框架。你可以自由地选择适合你的应用的模块,并且在Spring无法满足你的需求时,选择其他的模块。Spring甚至提供了与许多其他框架和库的集成点,因而你不用去自己写它们。
让我们一个一个的来看看Spring的每一个模块,来了解一下每一个模块是如何拼凑整个Spring的版图的。
核心Spring容器
Spring框架的中心是一个容器,它负责管理Spring应用中的bean是如何创建、配置与管理的。这个模块的内部是Spring bean工厂,是Spring提供DI的一部分。建立在bean工厂之上,你将发现Spring应用上下文的多个实现,每一个都提供了配置Spring的不同方式。
除了bean工厂和应用上下文之外,这个模块还提供了许多企业级服务,例如邮件、JNDI访问、EJB集成,和调度。
Spring的所有模块都都是建立在核心容器之上的。你将在配置你的应用是隐式的使用这些类。我们将通篇讨论核心模块,从第二章开始,我们将更深入的挖掘Spring DI。
Spring AOP 模块
Spring在AOP模块中提供了面向方面编程的丰富支持。这个模块的作用服务于------为你自己的Spring应用开发你自己的aspects。与DI类似,AOP支持应用对象的松散耦合。但是利用AOP,应用级的相关性(例如事务和安全)解除了它们与其他对象的耦合。
我们将在第4章更加深入的讲解Spring AOP支持。
数据访问和集成
使用JDBC时总是会造成大量的重复代码(获取连接,创建statement,处理结果集合,然后关闭连接)。Spring的JDBC和数据访问对象(DAO)模块将这些重复代码抽象化,因而你可以保持你的数据库代码干净和简单,并且阻止了由数据库资源访问失败导致的错误。这个模块也在多种数据库服务器返回的错误消息之上构建了一层非常有意义的exception。你并不需要去破解神秘而专用的SQL错误消息。
对于那些更喜欢使用对象关系映射(object-relational mapping, ORM)工具的人来说,Spring提供了ORM模块。Spring的ORM支持建立在DAO支持之上,以多种ORM方法提供了建立DAO的方便方法。Spring并没有试图去实现它自己的ORM方法,但是它提供了连接多个流行ORM框架的钩子(hook),包括Hibernate,Java Persistemce APUI,Java Data Objects,以及iBATIS SQL Maps。Spring的事务管理像支持JDBC一样支持这些ORM框架。
在第10章节,我们将讲解Spring数据访问,你将看到Spring的基于模板的JDBC抽象是如何能够大大地简化JDBC代码的。
这个模块还包括了一个对于Java Message Service(JMS)的Spring抽象,以通过消息机制进行与其他应用的异步集成。此外,对于Spring 3.0,这个模块包含了object-to-XML映射特性,它们是Spring Web Services项目的根本部分。
此外,这个模块使用了Spring的AOP模块来提供Spring应用中对象的事务管理服务。
Web和远程
模型-视图-控制器(MVC)样式已经非常广泛地被接受,以用来构建web应用,使得用户接口与应用逻辑向分离。Java在MVC框架中并无缺陷,Apache Struts, JSF, WebWork和Tapestry已经成为了非常流行的MVC选择。
即使Spring可以集成多种流行MVC框架,它的web和远程模块来自于一个可靠的MVC模块,它在应用web层充分运用了Spring的松散耦合技术。我们将在第5-7章讲解Spring mvc框架。
除了面向用户的web应用以外,为了建立可以与其他应用交互的应用,这个模块还提供了多个远程选项。Spring的远程能力包括远程方法调用(Remote Method Invocation, RMI), Hessian, Burlap, JAX-WS,以及Spring自己的HTTP invoker。Spring还提供了使用REST API的一级支持。
在地第15章,我将讲解Spring远程。并且你将在第16章学习到如何创建与使用REST API。
仪器(INSTRUMENTATION)
Spring的仪器(instrumentation,是这么翻吗)模块包括了向JVM添加助理(agent)的支持。特别地,它向Tomcat提供了一个迂回助理以转换类文件,就像它们是被类加载器加载一样。
如果这听起来难以理解,不要太担心。这个模块提供的仪器用途非常窄,我们将不会在这本书中讲解。
测试
意识到了开发者写的测试的重要性,Spring提供了一个模块以测试Spring应用。
在这个模块中,你将发现许多的mock对象实现,为了撰写作用于JNDI,servlet,和portlet的单元测试代码。对于集成级的测试,这个模块提供了载入Spring上下文的bean和操作bean的支持。
在本书中,大多数例子将用测试来表示,利用Spring提供的测试方法。
1.3.2 Spring组合(Spring portfolio)
Spring总比你能看到的要多得多。事实上,Spring的模块比下载下来的要多得多。如果你仅仅停留在核心的Spring框架,你将错过Spring组合带来的一笔巨大从潜力。整个Spring组合包包括了多个建立在核心Spring框架上的框架和库。 总体上,整个Spring组合包带来了基本覆盖Java开发每一面的Spring编程模型。
要覆盖Spring组合包提供的全部内容,需要大量的篇幅,而且很多都超出了本书的范围。但是我们将了解一下Spring组合包的一些元素;这里是基于核心Spring框架的一个品尝。
Spring Web Flow 网络流
Spring Web Flow建立在核心Spring框架之上,提供了将Spring bean发布为web服务的声明式方法,这些服务基于一个可论证的架构上下级的协议最后(contract-last)模型。服务的协议是由Bean的接口决定的。Spring Web Services提供了协优先(contract-first) web服务模型,其中服务实现是为满足服务协议而编写的。
Spring Security 安全
安全是许多应用的关键方面。使用Spring AOP实现,Spring安全为Spring应用提供了声明式的安全机制。你将在第9章了解如何向web层添加Spring安全的。我们将在第14章重新回到Spring安全来检验如何保证方法调用安全性的。
Spring Integration 集成
许多的企业级应用必须与其他的企业级应用进行交互。Spring集成提供了多种常用交互模式的实现,以Spring声明式的形式。本书将不做讲解。
Spring Batch 批处理
当需要在数据上执行大量的操作时,没有什么能比得上批处理。如果你将去开发一个批处理应用,你可以利用Spring Batch, 来使用Spring的鲁棒、面向POJO的开发方法完成它。Spring Batch超出了本书的范围。
Spring Data 数据
Spring Data使得操作各种数据库变得非常简单。虽然关系型数据库多年来一直用于企业应用中,现代的应用越来越意识到不是所有的数据都可以用表中的行和列来表示的。一种新产生的数据库,通常被称之为NoSQL数据库,提供了新的方法来操作新型数据库,而非传统关系型数据库。
不管你是在使用文档数据库如MongoDB,图形数据库如Neo4j,或者甚至传统关系型数据库,Spring Data为persistence提供了简化的编程模型。这包括,为多种数据类型,一个自动仓库(repository)机制来为你创建仓库实现。
我们将在第11章中讲解如何用Spring Data来简化Java Persistence API(JPA)开发,然后在第12章时扩展性地讨论一些NoSQL数据库。
Spring Social 社交
社交网络在互联网上升趋势,越来越多的应用开始集成社交网站的接口,例如Facebook和Twitter。如果你对这方面感兴趣,你可以了解一下Spring Social,Spring的一个社交网络扩展。
但是Spring Social并不仅仅是微博和朋友。尽管这样命名,Spring Social相比社交(social)这一词更加偏向于连接(connect)。它帮助你利用REST API连接你的Spring应用,其中还包括很多没有任何社交目的的应用。
由于空间的限制,我们将不在本书中讲解Spring Social。
Spring Mobile 移动
移动应用是软件开发另一个热门点。智能手机以及平板已经逐渐成为备受用户青睐的客户端。Spring Mobile是Spring MVC的一个新的扩展,以支持移动web应用的开发。
Spring For Android 安卓
与Spring Mobile相关的是Spring Android项目。这个项目旨在利用Spring框架为一些安卓设备上的本地应用的开发带来一定的便利。初始地,这个项目提供了一个版本的Spring RestTemplate,它可以运用在Android应用中。它还可以操作Spring Social来使得本地安卓app可以与REST API相连接。本书将不讨论Spring for Andoid。
Spring BOOT 快速启动
Spring大大简化了许多编程任务,减少甚至消除了大量你可能通常非常需要的重复代码。Spring Boot是一个非常激动人心的新项目,它的目的是在Spring开发时简化Spring本身。
Spring Boot大量地利用了自动配置技术,以消除大量的(在多种情况下,可以说是所有的)Spring配置。它还提供了许多的启动器(starter)项目来帮助来减少你的Spring项目构建文件,在你使用Maven或Gradle时。我们将在第21章讲解Spring Boot。
1.4 Spring的新功能
当这本书的第三版出版时,最晚的Spring版本是3.0.5。这大概是3年前,并且Spring自那起发生了许多的改变。Spring框架迎来了3个重大的发布---3.1,3.2,以及现在的4.0---每一次发布都带来了许多新的特性与改善,以减轻应用开发。并且多个模块成员经历了巨大的改变。
这一版本的Spring in Action已经进行了更新,覆盖了大多数的这些版本的特性。但是现在,我们简单地来看看Spring更新了什么。
1.4.1 Spring 3.1更新了什么?
Spring 3.1有许多有用的新特性与改进,大多都专注于简化和改进配置方法。此外,Spring 3.1提供了声明式的缓存支持,以及对于Spring MVC的许多改进。这里是Spring 3.1的一些亮点:
为了解决从多种环境(例如开发,测试,与发布)选择独立的配置的问题,Spring 3.1引入了环境资料(profile)。资料使得一些事情成为可能,例如,依赖于应用的环境选择不同的数据源bean。
建立在Spring 3.0的基于Java的配置的基础上,Spring 3.1添加了多个enable注解以允许Spring用一个注解来进行特定特性的切换。
声明式缓存支持被引入了Spring,使得我们可以利用简单的注解来声明缓存边界与规则,这与我们如何声明事务边界相类似。
一个新的c命名空间带来了构造器注入,与Spring 2.0的p命名空间类似(用于属性注入),简化了配置方法。
Spring开始支持Servlet 3.0,包括利用基于Java的配置方法声明servlet和filter,来取代原来的web.xml。
Spring JPA的改进使得我们可以完全的配置JPA,而不需要persistence.xml。
Spring 3.1还包括了多个对Spring MVC的增强:
path variables到model attributes的自动绑定
@RequestMappingproduces和consumes属性,为了匹配请求的Accept和Content-Type头
@RequestPart注解,允许绑定部分的multipart请求到handler 方法参数
flush属性支持(重定向的属性),和一个RedirectAttributes类型来在请求见传递flash属性
与Spring 3.1更新了什么同等重要的是,Spring 3.1中哪些已经不再使用了。特别地,Spring的JpaTemplate和JpaDapSupport类以不被建议使用,取而代之的是EntityManager。即使它们已经不建议使用,它们依然在Spring 3.2中。但是你不应该使用它们,因为它们没有升级到支持JPA 2.0,且在Spring 4中已经被移除。
现在我们来看看Spring 3.2更新了什么。
1.4.2 Spring 3.2更新了什么?
Spring 3.1专注于利用一些其他的改进来改善配置方法,包括Spring MVC的改进。Spring 3.2主要是一个专注于Spring MVC的版本。Spring 3.2有如下的改进:
Spring 3.2 controllers可以充分利用Servlet 3的异步请求,将请求的处理传给多个分离的线程,释放servlet线程以处理更多的请求。
虽然Spring MVC controllers自Spring 2.5起就可以简单地作为POJO进行测试,Spring 3.2包含了一个Spring MVC测试框架,以针对controllers编写更加丰富的测试,作为controller来预警它们的行为,而不需要servler container。
除了改进controller测试,Spring 3.2包含了对测试基于RestTemplate的客户端的支持,而不需要发送请求到真实的REST终端。
一个@ControllerAdvice注解允许普通的@ExceptionHandler,@InitBinder,@ModelAttributes方法可以出现在单一的类中,并且运用到所有的controllers。
在Spring 3.2之前,全内容协议(full content negotiation)仅仅可以通过ContentNegotiationViewResolver来支持。但是在Spring 3.2中,全内容协议在整个Spring MVC中都是可用的,甚至在一个依赖于消息转换的controller方法。
Spring MVC 3.2包含了一个新的@MatrixVariable注解,已绑定一个请求的矩阵变量来处理方法参数。
抽象基类AbstractDispatcherServletInitializer可以用来方便的配置DispatcherServlet,而不使用web.xml。同样,它的子类AbstractAnnotationConfigDispatcherServletInitializer可以在配置基于Java的Spring配置方法时使用。
添加了ResponseEntityExceptionHandler类作为DefaultHandlerExceptionResolver的备用而使用。ResponseEntityExceptionHandler方法返回ResponseEntity
RestTemplate和@RequestBody参数支持通用类型。
RestTemplate和@RequestMapping方法支持HTTP PATCH方法。
映射拦截器支持URL模式,以排除在拦截处理之外。
虽然Spring MVC是Spring 3.2的主要部分,它还加入了一些非MVC的改进。这里是一些最有趣的新特性:
@Autowired,@Value和@Bean注解可以作为meta-annotations使用,以创建定制化注入和bean声明注解。
@DateTimeFormat注解不再依赖于JodaTime。如果出现了JodaTime,它将被使用。否则,使用SimpleDateFormat。
Spring的声明式缓存支持开始初始化支持JCache 0.5。
你可以定义全局formats以转换和处理日期和时间。
集成测试可以配置和载入WebApplicationContext。
集成测试可以测试request和session范围的beans。
你将看到大量的Sping 3.2特性,在本书的多个章节中,特别是在web和REST章节。
1.4.3 Spring 4.0更新了什么?
Spring 4.0是目前最新的Spring版本。在其中有许多的新特性,包含如下:
Spring现在包含了对WebSocket编程的支持,包括JSR-356: Java API for WebSocket。
意识到WebSocket提供了一个低级的API,特别需要高级的抽象。Spring 4.0包含了一个高级的面向消息的编程模型,在WebSocket之上,基于SockJS,并且包含了STOMP子协议支持。
一个来自Spring集成项目的带有多种类型的消息模块。这个消息模块支持Sprig的SockJS/STOMP支持。它还包含发布消息的基于模板的支持。
Spring 4.0是最早支持Java 8特性(包含 lambdas)的框架之一。这使得利用回调接口(例如使用JdbcTemplate的RowMapper)更加的干净易读。
为基于Groovy开发的应用带来了更加平滑的编程体验,最重要的是让Spring应用可以完全用Groovy来轻松开发。利用来自Grails的BeanBuilder,使Spring应用能够使用Groovy来配置。
为有条件的bean的创建提供了更加通用的支持,其中,bean只能在条件允许的情况下被创建。
Spring 4.0还包含了Spring的RestTemplate的异步实现,直接返回,但是在操作完成之后回调。
添加了许多JEE规范的支持,包括JMS 2.0,JTA 1.2,JPA 2.1和Bean Validation 1.1。
如你所见,许多新的成员都在最新的Spring框架中出现。通过本书,我们将了解大多数的新特性,以及长期支持的特性。
1.5 总结
现在你应该知道Spring到底带来了什么吧。Spring旨在使得Java开发更加简单化,且提倡松散耦合的代码。这其中最重要的是依赖注入和面向方面编程。
在本章,你稍微品尝了一下Spring的DI。DI是一种关联应用对象的方法,使得对象不需要知道它们的依赖来自哪里,或者它们是如何实现的。相比它们自己索取依赖,需要依赖的对象被它人给予了其所依赖的对象。因为依赖对象经常知道他们的注入对象(通过接口),使得耦合度很低。
除了DI,你稍微了解了一点Spring的AOP支持。AOP使你能够专注于一个地方----一个方面----逻辑可以从应用中分散开来。当Spring将你的bean装配在一起时,这些方面可以在一个运行时中运行,高效的给予bean以新的行为。
DI和AOP是Spring的一切的中心。因而你必须理解如何使用这些重要功能,以能够使用框架的其他部分。在本章,我们仅仅看到了Spring的DI和AOP的表面。在接下来的几章,我们将深入探讨。
没有其他闲事,让我们移动到第二章,来学习如何利用Spring DI将对象装配在一起。