C++入门讲解第一篇

大家好,我是Dark Fire,终于进入了C++的学习,我知道面对我的将是什么,就算变成秃头佬,也要把C++学好,今天是C++入门第一篇,我会尽全力将知识以清晰易懂的方式表达出,希望我们一起加油!
文章目录
-
- 一,C++中的关键字
-
- C++输入与输出
- 命名空间
-
- 命名空间的定义
- 使用命名空间
- auto关键字
一,C++中的关键字
首先,和C语言不同的是,C++又增加了一些关键字,相对于C语言32个关键字,C++63个关键字象征着C++语言会更加灵活多变。由于C++是本贾尼博士在C语言的基础上改进而来,所以C++的关键字大部分还是C语言里的。
红色为C语言已经存在的,黑色为C++扩展的。
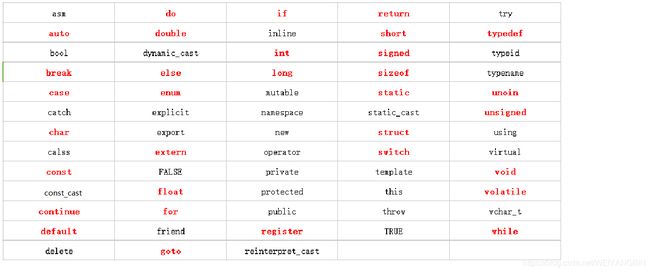
由于这里关键字太多,用例讲解反而记忆不会深刻,所以在之后的章节里会结合一些例子帮助大家来理解和掌握这些关键字的使用场景和注意事项。
C++输入与输出
在C语言中,我们常常用printf和scanf进行读和写的功能,在C++中更换了输入和输出的方法,在C语言中只能对特定种类的数据进行输入和输出功能,而在C++中可以实现类变量的输入和输出(具体会在后边进行讲解)。
在C++中,包含头文件以及ing名空间的使用方法std。iostream就是i,o流的意思,数据从哪里流向哪里。cout和cin是在命名空间中所定义的,所以在使用时要打开命名空间(下边会讲到)。
使用cout(标准输出对象(控制台))和cin(默认输入对象(键盘))进行输入和输出。
cout用例如下

这里<<是流插入运算符,至于>>是流提取运算符,endl是打印后换行的意思,和C语言中的\n作用相同。
这段代码的意思是将i变量的值流入标准输出对象即控制台。
cin用例如下
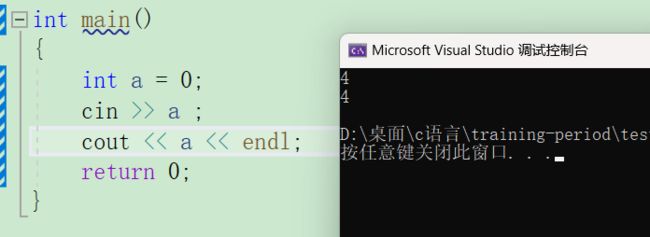
默认a的值为0,输入4后将a的值更改为4。
你一定会有疑问,那么这些变量是如何被识别他们是什么类型的呢?
- 实际上C++的输入和输出可以自动识别变量类型。(交给编译器,让他自己识别)
用例如下
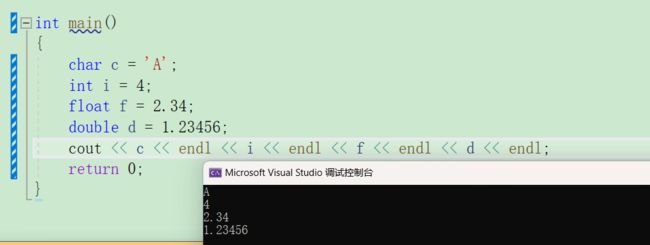
是不是超级方便。
在后边的学习中你才会意识到什么是真正的方便。
关于cout和cin还有很多复杂的用法,比如控制浮点数输出精度,控制整形输出格式等,后续如果需要用到我们在进行讲解,而且C++是兼容C语言的,这些问题也可以由C语言的转义字符进行操作,就不展开讨论。
命名空间
当我们在用C语言进行编程时,常常会出现这样的问题。
#include 当我们包含了头文件time.h时,创建全局变量time,打印time发现报错如下。
![]()
和头文件中的同名变量产生冲突,我们就不得不改变我们创建的变量名。
这种情况经常发生,而且我们命名过一个变量一个名字之后,在该作用域中这个变量名就不能再重复使用了,而且在后边函数,变量,以及创造出来的类是大量存在的,如果将这些变量都存于全局作用域中,势必会出现很多错误,如何避免呢?
namespace关键字就是针对这一问题存在的。
使用命名空间可以对标识符的名称进行本地化,以避免命名冲突或名字污染。
命名空间的定义
关键字namespace后边跟命名空间的名字,然后接一对大括号即可,{}内部便是命名空间中的成员。
用例如下
namespace Dark
{
int time = 0;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
}
命名空间中不仅可以有变量还可以有函数,自定义类型等。
当然,命名空间还可以嵌套
namespace Dark
{
int time = 0;
int Add(int x, int y)
{
return x + y;
}
struct Node
{
struct Node* next;
int val;
};
namespace Fire
{
int rand = 0;
int Sub(int x, int y)
{
return x - y;
}
}
}
一个命名空间就限制了一个新的作用域,命名空间内的所有内容都局限于此命名空间内。
使用命名空间
命名空间内部元素使用有以下三种方法:
1,命名空间及其作用域限定符
int main()
{
cout << Dark::time << endl;
return 0;
}
2,使用using将命名空间中的某个元素引入
int main()
{
using Dark::time;
cout << time << endl;
return 0;
}
3,使用using space 加命名空间名称将命名空间引入就像前边所说std命名空间的引入一样。
int main()
{
using namespace Dark;
cout << Fire::rand << endl;
return 0;
}
引入后就可以直接访问内部的命名空间啦。
访问嵌套的命名空间可以用上边的方法深度挖掘。
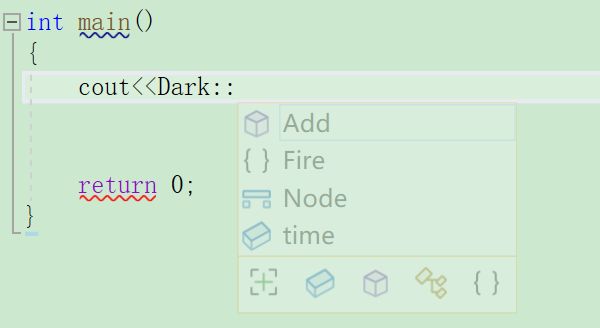
就像这样
int main()
{
cout << Dark::Fire::rand << endl;
return 0;
}
是不是已经十分了解啦。
auto关键字
在C++中,随着程序越来越复杂,程序中用到的类型也越来越复杂,一层一层的嵌套,让类型难于拼写,含义不明确就容易拼写错误。auto就是来解决这一问题的。
比如这个例子(举例说明,细节后边会讲)
#include 有些数据类型很长,很多聪明的友友会考虑用typedef取别名。
#include 然而在某些情况下,typedef不能解决这些问题。
例如
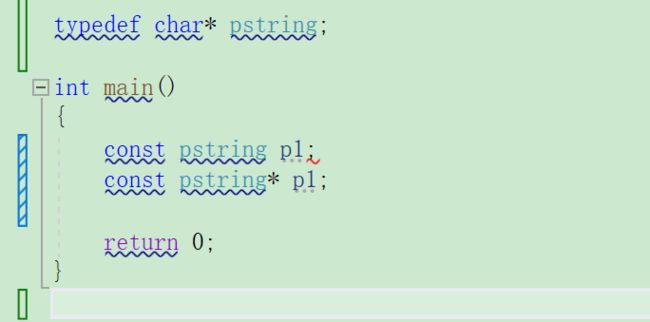
在C++11中,标准委员会赋予了auto全新的含义,auto不再是一个存储类型指示符,而是作为一个新的类型来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
auto可以自动推导数据的类型。
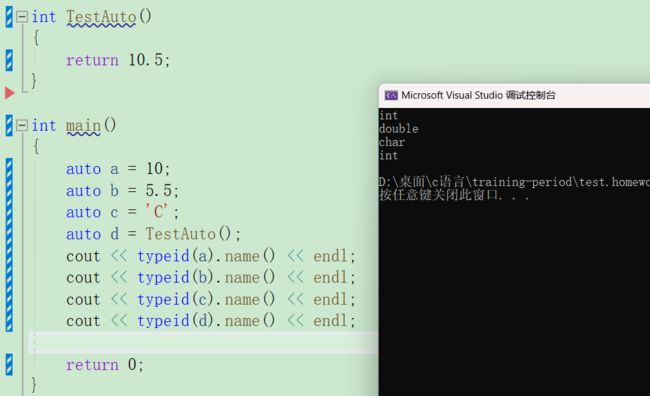
typeid函数可以知道变量的类型。
注意:
使用auto定义变量时,必须要将其初始化,在编译阶段编译器需要根据其初始化表达式来推导auto的实际类型,因此auto并非是一种类型的声明,而是类型的占位符,编译器在编译期间会将auto替换为变量实际的类型。
可以发现,我们将数据类型的确定让编译器确认了,而不是主动传递%d %f之类的标识符。
auto的使用
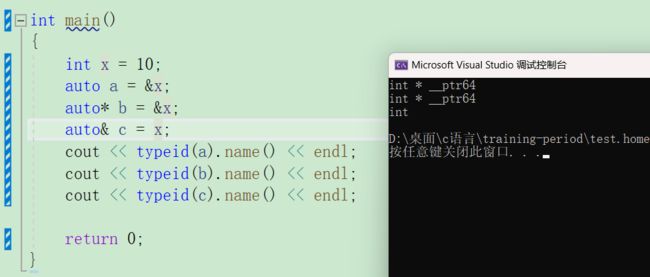
1,auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto没有任何区别,加上后,auto推导的就是指针类型,不加时,推导的就是指针类型加 *。
但是,用auto声明引用时,必须加上&,不然编译器也不知道你是不是引用。
用例如下
2,在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器会报错,因为编译器只会对第一个类型进行推导,然后用推导出的类型定义这行后边的类型。

auto这么厉害,但也有不可推到的场景
1,auto不能作为函数的参数
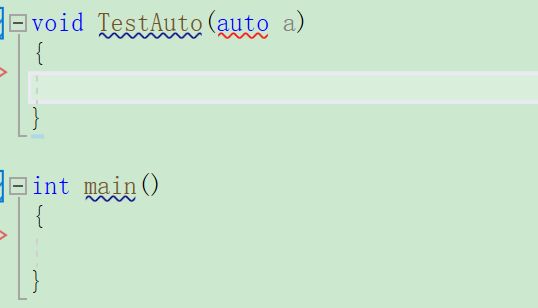
auto不能推导出形参的实际类型,有可能会造成二义性,所以编译失败。
2,auto不能直接声明数组
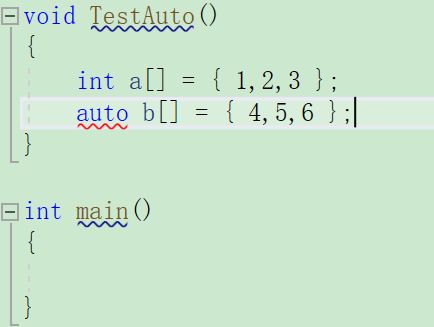
auto常见的用法
最常见的优势用法就是新式for循环,还有lambda表达式进行配合使用(后边会讲)
范围for的用法
在C++98如果想遍历一个数组
void TestFor()
{
int array[] = { 1,2,3,4,5 };
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
{
array[i] *= 2;
}
for (int*p=array; p <array+ sizeof(array) / sizeof(array[0]); p++)
{
cout << *p << endl;
}
}
遍历数组各个元素都乘以2,然后借助下标进行打印。
在C++11中,对于一个有范围的集合,对程序员来说,循环的范围是多余的,这件事我们也可以甩给编译器。
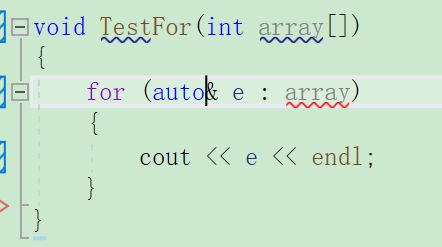
for循环后的括号由“:”分为两部分,第一部分是范围内用于迭代的变量,第二部分则是被迭代的范围。
用例如下
void TestFor()
{
int array[] = { 1,2,3,4,5 };
for (auto& e : array)
{
e *= 2;
}
for (auto e : array)
{
cout << e << " " << endl;
}
}
在这里e是被引用的array里的每个元素,auto可以自动识别变量的类型,与普通循环类型,这里也可以用continue结束某次循环,也可以使用break跳出循环。
for循环迭代的范围必须是确定的,对于数组而言,就是第一个元素到最后一个元素的范围。
今天就介绍到这里啦,如果有问题欢迎友友们指出哦。