MySQL数据库(二)
数据库 —— 基础
-
-
- 6. 聚合
-
- 6.1 GROUP BY 分组
-
-
- 6.1.1 单字段分组
- 6.1.2 多字段分组
- 6.1.3 分组聚合排序
- 6.2 HAVING子句
- 6.3 DISTINCT去重
-
- 7. 子查询
- 8. 多表查询
-
-
- 8.1 关联查询
- 8.2 连接查询
-
- 8.2.1 内连接
- 8.2.2 外连接
- 8.2.3 自连接
-
- 9. MySQL函数
-
MySQL数据库(一)
6. 聚合
| 聚合操作:在数据查询的基础上对数据进行统计和计算的过程,聚合操作属于数据的查询筛选(总和、平均值、最大值、最小值,分组和排序等) |
聚合函数
MIN、MAX、SUM、AVG是对值的统计,COUNT是对记录数(条数)的统计
聚合函数忽略NULL值
| 函数 | 功能 |
|---|---|
| COUNT(column) | 计算某列的非空值的数量 |
| SUM(column) | 计算某列的数值总和 |
| AVG(column) | 计算某列的平均值 |
| MIN(column) | 返回某列的最小值 |
| MAX(column) | 返回某列的最大值 |
| STD(column) | 计算某个字段的标准差(样本标准差) |
| VARIANCE(column) | 计算某个字段的方差(样本方差) |
| ROUND(column) | 对某个字段进行四舍五入 |
| VAR_POP(column) | 计算某个字段的方差(总体方差) |
| STDDEV_POP(column) | 计算某个字段的标准差(总体标准差) |
- 实例应用
sql建表语句及数据: sql文件 – 提取码:x2o9
- 需求:查看老师的最高工资,最低工资,平均工资和工资总和
- SQL语句 ——
聚合函数-- 查看老师的最高工资,最低工资,平均工资和工资总和 select max(salary), min(salary), avg(salary), sum(salary) from teacher;
- 结果

- 需求:负责课程编号3的老师的平均工资
- SQL语句 ——
s聚合函数条件查询-- 负责课程编号3的老师的平均工资 select avg(salary) from teacher where subject_id = 3;-- 查看助教的信息(名字,工资,年龄) select name,salary,age from teacher where title = '助教';
- 结果

- 需求:统计学生人数
- SQL语句 ——
select...where...基础语句查询-- 统计学生人数 select count(*) from student;
- 结果

6.1 GROUP BY 分组
GROUP BY子句可以将结果集按照指定字段值相同的记录进行分组,配合聚合函数可以实现组内统计
在SELECT子句中出现聚合函数时,不在聚合函数中的字段都要出现在GROUP BY子句中
GROUP BY子句是配合聚合函数使用的(一般SELECT子句中没有聚合函数,通常不写GROUP BY)
SELECT 字段名,聚合函数 FROM 表名 WHERE 过滤条件 GROUP BY 字段 ORDER BY 字段 LIMIT m,n;
6.1.1 单字段分组
- 需求:查看每种职位的老师平均工资
- SQL语句 ——
GROUP BY单字段分组-- 查看每种职位的老师平均工资 select title, avg(salary) from teacher group by title;
- 结果

- 需求:每个班级的人数
- SQL语句 ——
GROUP BY单字段分组-- 每个班级的人数 select class_id, count(*) from student group by class_id;
- 结果

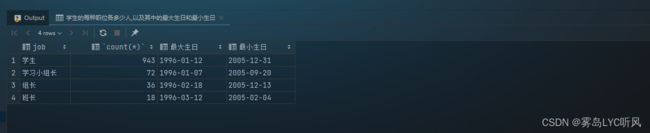
- 需求:学生的每种职位各多少人,以及其中的最大生日和最小生日
- SQL语句 ——
GROUP BY单字段分组-- 学生的每种职位各多少人,以及其中的最大生日和最小生日 select job, count(*), min(birth) 最大生日, max(birth) 最小生日 from student group by job;
- 结果
6.1.2 多字段分组
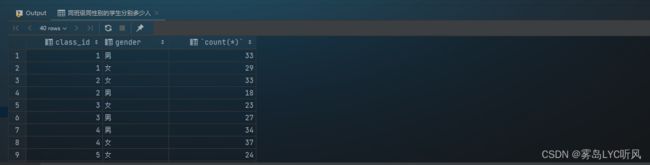
- 需求:同班级同性别的学生分别多少人
- SQL语句 ——
GROUP BY多字段分组select class_id, gender, count(*) from student group by class_id, gender;
- 结果
- 需求:每个班每种班务人员及学生各多少人
- SQL语句 ——
GROUP BY多字段分组-- 每个班每种班务人员及学生各多少人 select class_id, job, count(*) from student group by class_id, job;
- 结果

6.1.3 分组聚合排序
- 需求:每个科目老师的平均工资排名
- SQL语句 ——
GROUP BY分组聚合排序-- 每个科目老师的平均工资排名 select subject_id, avg(salary) as avgs from teacher group by subject_id order by avgs desc;
- 结果

6.2 HAVING子句
HAVING子句:分组中的过滤条件
- 应用:HAVING子句是紧跟在GOURP BY子句之后,用于对分组进行过滤的子句
HAVING和WHERE的区别
WHERE在第一次检索表数据时用于添加过滤条件,确定结果集
HAVING在GROUP BY之后(将结果集分组之后)添加过滤条件的,用于确定分组
- 需求:每个科目老师的平均工资(平均工资低于8000)
- SQL语句 ——
HAVING子句-- 每个科目老师的平均工资(平均工资低于8000) select subject_id, avg(salary) as avgs from teacher group by subject_id having avgs < 8000;
- 结果

- 需求:各科目女老师的平均工资(平均工资低于8000)
- SQL语句 ——
HAVING子句-- 各科目女老师的平均工资(平均工资低于8000) select subject_id,avg(salary) as avgs from teacher where gender='女' group by subject_id having avgs < 8000;
- 结果

6.3 DISTINCT去重
DISTINCT可以将结果集按照指定的字段去除重复行
DISTINCT必须紧跟在SELECT关键字之后
- 需求:老师的职称都有哪些
- SQL语句 ——
DISTINCT去重-- 老师的职称都有哪些 select distinct title from teacher;
- 结果

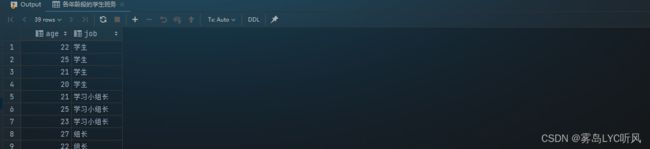
- 需求:各年龄段的学生班务
- SQL语句 ——
DISTINCT去重-- 各年龄段的学生班务 select distinct age,job from student;
- 结果
7. 子查询
| 子查询:嵌套在一个SQL语句中的DQL语句(该DQL被称为子查询) 分类:单行单列子查询,该子查询的结果集只有一个值 多行单列子查询,该子查询结果集是多个值 应用场景 :单行单列子查询,该子查询的结果集只有一个值 DQL中使用子查询 在SELECT子句中,将当前子查询结果作为一个字段展示 在WHERE子句中,将当前子查询结果作为过滤条件使用(最常用的场景) DML中使用 将一个查询结果集用于增删改操作 |
- 需求:每个老师任教的科目
- SQL语句 ——
子查询select teacher.name, subject.name from teacher, subject where teacher.id = subject.id;
- 结果

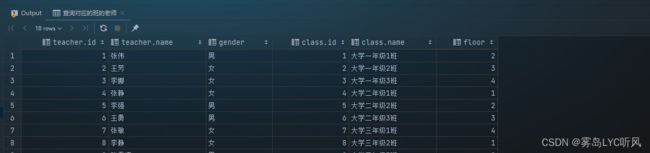
- 需求:查询对应的班的老师
- SQL语句 ——
子查询-- 查询对应的班的老师 select teacher.id, teacher.name, teacher.gender, class.id, class.name, class.floor from teacher, class where teacher.id = class.teacher_id;
- 结果
8. 多表查询
8.1 关联查询
| 关联查询:通过指定关联条件来连接两个或多个表,根据这些关联条件,数据库会自动找出相关联的行并组合起来 连接查询:连接查询是关联查询的一种具体类型;使用连接操作符(如INNER JOIN、LEFT JOIN、RIGHT JOIN等)来将表连接在一起,并返回匹配的行 关联查询是一种概念,描述了表之间的关系;连接查询是关联查询的具体实现方式,使用连接操作符将表连接在一起,返回满足条件的结果集 |
- 关联关系分类
一对一
- A表的一条记录仅唯一对应B表中的一条记录,反过来B表中的一条记录也仅唯一对应A表中的一条
记录
一对多- A表中的一条记录对应B表中的多条记录,但是反过来B表中的一条记录仅能唯一对应A表中的一条
记录
多对多
A表中的一条记录能够对应B表中的多条记录;同时B表中的一条记录也能对应A表中的多条记录
- 语法
SELECT 字段,... FROM 表A,表B[,表C,...] WHERE A表与B表的连接条件 AND [其他表的连接条件] AND 过滤条件关联查询中连接条件通常不可以忽略或缺失,否则会产生笛卡尔积
- 需求:查询大一新生的居住地址
- SQL语句 ——
多表关联-- 查询大一新生的居住地址 select s.name, s.age, s.gender, s.job, s.birth, s.class_id, l.name from student s, location l where l.id = s.location_id;
- 结果
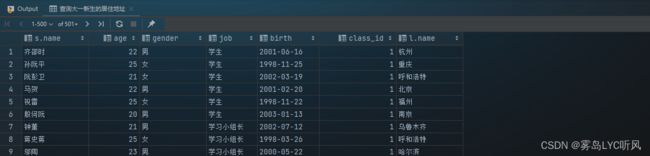
- 需求:查询陈泽宇老师所属班级的学生
- SQL语句 ——
多表关联-- 查询陈泽宇老师所属班级的学生 select s.name, c.name, s.gender, s.job from teacher t, class c, student s where t.id = c.teacher_id and c.id = s.class_id and t.name = '陈泽宇';
- 结果
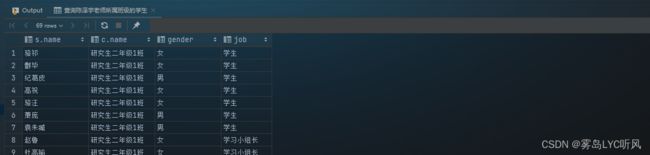
- 需求:任教大学英语的老师,且班级为大学(即不包含研究生)
- SQL语句 ——
多表关联-- 任教大学英语的老师,且班级为大学(即不包含研究生) select t.name, t.gender, t.title, t.salary, s.name, c.name from teacher t, class c, subject s where t.id = c.teacher_id and s.id = t.subject_id and s.name = '大学英语' and c.name like '大学%';
- 结果

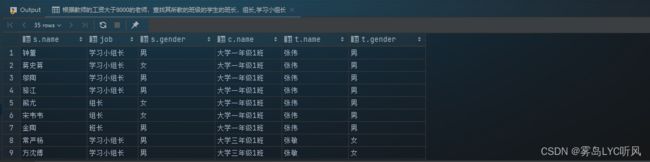
- 需求:根据教师的工资大于8000的老师,查找其所教的班级的学生的班长,组长,学习小组长
- SQL语句 ——
多表关联-- 根据教师的工资大于8000的老师,查找其所教的班级的学生的班长,组长,学习小组长 select s.name, s.job, s.gender, c.name, t.name, t.gender from teacher t, class c, student s where t.id = c.teacher_id and c.id = s.class_id and s.job in ('班长', '组长', '学习小组长') and t.salary > 8000;
- 结果
- 需求:各科老师的平均工资降序排序
- SQL语句 ——
多表关联:分组聚合排序查询-- 分组聚合排序查询:各科老师的平均工资降序排序 select s.name, avg(salary) as avgs from teacher t, subject s where t.subject_id = s.id group by s.name order by avgs desc;
- 结果

- 需求:各个老师的学生人数
- SQL语句 ——
分组聚合,limit分页查询-- 分组聚合,limit分页查询:各个老师的学生人数 select t.name, count(*) from teacher t, class c, student s where t.id = c.teacher_id and c.id = s.class_id group by t.name limit 5;
- 结果

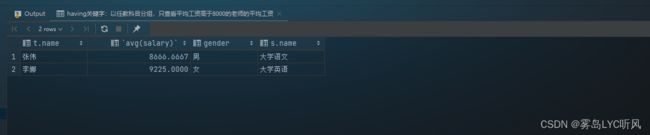
- 需求:以任教科目分组,只查看平均工资高于8000的老师的平均工资
- SQL语句 ——
having关键字-- having关键字:以任教科目分组,只查看平均工资高于8000的老师的平均工资 select t.name, avg(salary), t.gender, s.name from teacher t, subject s where t.subject_id = s.id group by s.name having avg(t.salary) > 8000;
- 结果
8.2 连接查询
8.2.1 内连接
- 内连接是关联查询的另一种写法;
- 内连接查询只会查找到符合条件的记录,结果和表关联查询是一样的
语法
SELECT 子句 FROM 表A JOIN 表B ON A与B的连接条件 [JOIN 表C ON A与C或B与C的连接条件 ... ] WHERE 过滤条件
- 需求:大学一年级的学生信息(名字,年龄,班级)
- SQL语句 ——
内连接查询-- 大学一年级的学生信息(名字,年龄,班级) select s.name, s.age, c.name from class c join student s on c.id = s.class_id where c.name like '大学一年级%';
- 结果

- 需求:查询英语老师
- SQL语句 ——
内连接查询-- 查询英语老师 select t.name, t.age, t.salary, t.gender, s.name from teacher t join subject s on s.id = t.subject_id where s.name = '大学英语';
- 结果

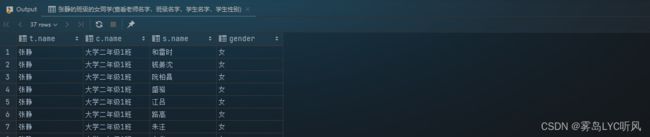
- 需求:张静的班级的女同学(查看老师名字,班级名字,学生名字,学生性别)
- SQL语句 ——
内连接查询-- 张静的班级的女同学(查看老师名字,班级名字,学生名字,学生性别) select t.name, c.name, s.name, s.gender from teacher t join class c on t.id = c.teacher_id join student s on c.id = s.class_id where t.name = '张静' and s.gender = '女';
- 结果
8.2.2 外连接
- 外连接也用于关联查询,特点:可以将不满足连接条件的记录也查询出来
- 用于同时返回两个或多个表中的所有记录,无论是否存在匹配的行
- 左外连接(LEFT JOIN):
以JOIN左侧表为驱动表,该表中所有记录都要体现在结果集中,右侧表不满足连接条件的记录对应
的字段全部为NULL- 右外连接(RIGHT JOIN):
以JOIN右侧表作为驱动表,该表中的记录都要体现在结果集中,左侧表不满足连接条件的字段都补
NULL
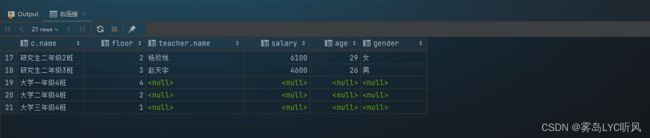
- 需求:查看所有班级信息和对应的老师信息(可以为空,即该老师没有教任何班级,也要显示)
- SQL语句 ——
左连接和右连接-- 查看所有班级信息和对应的老师信息(可以为空,即该老师没有教任何班级,也要显示)-- 左连接 select c.name, c.floor, teacher.name, teacher.salary, teacher.age, teacher.gender from teacher left join class c on teacher.id = c.teacher_id; -- 右连接 select c.name, c.floor, teacher.name, teacher.salary, teacher.age, teacher.gender from teacher right join class c on teacher.id = c.teacher_id;
- 结果

8.2.3 自连接
- 自连接:将表自己连接到自己,用于从单个表中选择匹配记录
语法:
SELECT column1, column2, column3 FROM table1 t1, table1 t2 WHERE t1.key = t2.key;
- 自连接是指当前表中的一条记录可以对应自己的多条记录;具有相同属性的一组数据之间又存在上下级的树状结构数据
- 员工组织结构:同属于员工,且存在上下级关系
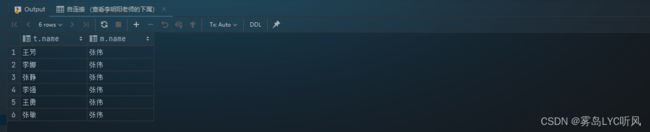
- 需求:查看张伟老师的下属
- SQL语句 ——
自连接-- 自连接 (查看张伟老师的下属) select t.name,m.name from teacher t join teacher m on t.manager = m.id where m.name = '张伟';
- 结果
9. MySQL函数
字符串函数
CONCAT(str1, str2, ...):将多个字符串拼接在一起
UPPER(str):将字符串转换为大写
LOWER(str):将字符串转换为小写
SUBSTRING(str, start, length):返回字符串中指定位置和长度的子串
LENGTH(str):返回字符串的长度
TRIM(str):去除字符串两端的空格
REPLACE():用于替换字符串中的指定字符或字符串
数值函数
ROUND(num, decimal_places):对数字进行四舍五入
FLOOR(num):向下取整
CEILING(num):向上取整
ABS(num):返回数字的绝对值
MOD(num, divisor):返回两个数相除的余数
日期和时间函数
NOW():返回当前日期和时间
DATE_FORMAT(date, format):将日期格式化为指定的格式
YEAR(date):返回日期的年份
MONTH(date):返回日期的月份
DAY(date):返回日期的日
DATEDIFF(date1, date2):计算两个日期之间的天数差
条件函数:CASE WHEN ... THEN ... ELSE ... END(用于根据条件执行不同的操作)
窗口函数(Window Functions)
ROW_NUMBER():为查询结果的每一行分配一个唯一的序号
RANK():为查询结果的每一行分配一个排名,相同的值将得到相同的排名,并且会跳过下一个排名
DENSE_RANK():为查询结果的每一行分配一个密集排名,相同的值将得到相同的密集排名,不会跳过下一个排名
LEAD():获取当前行的后续行中指定列的值
LAG():获取当前行的前面行中指定列的值
FIRST_VALUE():获取分组中的第一个行中指定列的值
LAST_VALUE():获取分组中的最后一个行中指定列的值
MySQL中正则表达式相关主要函数:REGEXP、REGEXP_LIKE、REGEXP_INSTR、REGEXP_REPLACE和REGEXP_SUBSTR
REGEXP:用于进行正则表达式匹配。可以在WHERE子句中使用它来筛选满足某个正则表达式条件的行。例如:
SELECT * FROM table_name WHERE column_name REGEXP 'pattern';
REGEXP_LIKE:类似于REGEXP,但是返回的结果为布尔值(0或1),表示是否匹配成功。它可以在SELECT语句中使用,作为一个条件表达式。例如:
SELECT column_name FROM table_name WHERE REGEXP_LIKE(column_name, 'pattern');
REGEXP_INSTR:用于返回正则表达式第一次匹配的位置索引。如果匹配不成功,则返回0。它接受两个参数:待匹配的字符串和正则表达式。例如:
SELECT REGEXP_INSTR('abcdef', 'cd'); -- 返回 3
REGEXP_REPLACE:用于将匹配正则表达式的部分替换为指定的字符串。它接受三个参数:待处理的字符串、正则表达式和替换字符串。例如:
SELECT REGEXP_REPLACE('Hello, World!', 'World', 'Universe');
-- 返回 'Hello, Universe!'