Nerf论文前后介绍以及今后方向(2020年各个方向工作论文分析) NEURAL VOLUME RENDERING:NERF AND BEYOND
你好! 这里是“出门吃三碗饭”本人,
本文章接下来将介绍2020年对Nerf工作的一篇总结论文NEURAL VOLUME RENDERING:NERF AND BEYOND,论文作者是佐治亚理工学院的Frank Dellaert同学和 MIT的Lin Yen-Chen同学,非常感谢两位大佬的总结贡献。
视频解说可以关注B站,即可找到对应视频,另外可以关注《AI知识物语》 公众号获取更多详情信息。
Nerf是一个非常美丽的算法,因为简单,而美丽
本篇文章建议结合视频食用,视频讲解分享将在近几日相应更应于B站
1:神经隐式表面相关研究工作
1.1SDF signed distance function带符号距离函数
参考(1544条消息) SDF(signed distance field)_dx1313113的博客-CSDN博客
一般来说,无论2d或者3d资产都有**隐式(implicit)和显式(explicit)两种存储方式,比如3d模型就可以用mesh直接存储模型数据,也可以用sdf、点云(point cloud)、神经网络(nerual rendering)**来表示,2d资产(这里指贴图)也是如此。
比如贴图一般直接使用rgb、hsv等参数来进行表示,但这样子再放大图片后会出现锯齿,所以 想要获取高清的图像就需要较大的存储空间,这时候就需要矢量表示,在2d贴图中sdf就是为了这种需求产生的。
SDF(Signed Distance Field)在3d和2d中都有对应的应用。在3d中光线追踪对于性能的消耗过大,所以sdf常常被用来作为物体的隐式表达,配合ray marching达到接近光线追踪的效果,也有比如deepSDF这种对于模型的隐式表达方面的应用。在2d中,sdf常常被用来表示字体,原神的面部渲染中阴影部分贴图也是基于sdf生成的。
SDF的本质就是存储每个点到图形的最近距离,即将模型划出一个表面,在模型表面外侧的点数值大于0,在模型表面内侧的点数值小于0
定义:对于任意的给定点,距离函数能够给出其到一个物体上最近点的最小距离(这个距离可能是带符号的)
拓展:
(1)SDF可以被用来做ray marching,来解决光线和SDF的求交问题
(2)SDF能被用于估计大概的percentage of occlusion,即SDF的值一定程度上反应观察者能够看到的“安全”角度
1.2 Occupancy network 占用网络
隐式地将三维曲面表示为深度神经网络分类器的连续决策边界
参考:(1544条消息) Occupancy Networks: Learning 3D Reconstruction in Function Space论文笔记_流木追风的博客-CSDN博客
• 占用函数(occupancy function):每个可能的3D点的占用概率。用神经网络去近似占用函数,同时关注能够隐式表示对象表面的决策边界

Note:输入三维点----》转化为0-1的概率密度 (联想到Nerf中体密度volume density的概念)
• **占用网络(occupancy network):**用神经网络参数化来模拟占用函数,以一对位置p和观测对象x作为输入(p,x),输出占用概率

输入P(三维)× X(观测对象)——>输出 占用概率
1.3 DeepSDF的方法
参考(1544条消息) Deep SDF 、NeuS学习_deepsdf_川河w的博客-CSDN博客
在SDF函数能够表示物体的基础上,用神经网络来拟合这个SDF函数,从而实现用神经网络隐式的表示这个物体,并且由于神经网络的万能拟合性质,原则上来说能够表示任意连续的、任意复杂形状的物体,可以表示一整类形状。
通过连续的体积场表示形状的表面:场中的点的大小表示到表面边界的距离,符号表示该区域是在形状的内部(-)还是外部(+)
下图是传统sdf的公式,X是物体,p为空间中某点,当p点在物体表面内部,距离为负,在表面外面,距离为正。
 论文公式
论文公式

s > 0是外部,s < 0是内部,s = 0是物体表面
训练
用神经网络当做SDF函数的拟合器,训练完(或者说拟合完)之后,输入大量自定义的三维空间采样点,再提取出所有值为0的点组成面,就能够重建整个三维物体了
1.4 PIFU
参考(1544条消息) PIFu笔记_知易行难w的博客-CSDN博客
PIFu: Pixel-Aligned Implicit Function for High-Resolution Clothed Human Digitization
像素对齐隐函数(PIFU),它可以从一幅输入图像(顶行)恢复出高分辨率的人体3D纹理表面。我们的方法可以将服装中错综复杂的变化数字化,比如褶皱的裙子和高跟鞋,包括复杂的发型。形状和纹理可以完全恢复,包括主体背部等基本看不见的区域。PIFU也可以自然地扩展到多视图输入图像(底行)。

摘要:我们介绍了像素对齐隐函数(PIFU),这是一种将2D图像的像素与其对应的3D对象的全局上下文局部对齐的隐式表示。
利用PIFU,我们提出了一种端到端的深度学习方法,用于数字化高细节的衣着人体,该方法可以从一幅图像中推断出3D表面和纹理,也可以根据需要从多幅输入图像中推断出3D表面和纹理。高度复杂的形状,如发型、服装,以及它们的变化和变形,都可以以统一的方式数字化。与用于3D深度学习的现有表示相比,PIFU产生高分辨率的表面,包括基本看不见的区域,如人的背部。具体地说,它与体素表示不同,内存效率高,可以处理任意拓扑,所得表面在空间上与所述输入图像对齐。此外,虽然以前的技术被设计为处理单个图像或多个视图,但是PIFU可以自然地扩展到任意数量的视图。我们从DeepFashion数据集中展示了对真实世界图像的高分辨率和鲁棒重建,其中包含各种具有挑战性的服装类型。我们的方法在公共基准上达到了最先进的性能,并且超过了之前从单个图像进行衣着人体数字化的工作。
我们提出了一种新的三维深度学习的像素对齐隐函数(pixel-aligned implicit function,PIFU)表示方法。而用于2D图像处理的最成功的深度学习方法(例如,语义分割[51]、2D联合检测[57]等)。利用“完全卷积”的网络结构来保持图像和输出之间的空间对齐,这在3D领域尤其具有挑战性。虽然体素表示[59]可以以完全卷积的方式应用,但是表示的存储器密集型特性固有地限制了其产生精细的详细表面的能力。基于全局表示[19,30,1]的推理技术具有更高的内存效率,但不能保证输入图像的细节被保留。类似地,基于隐函数[11,44,38]的方法依赖于图像的全局上下文来推断整体形状,这可能与输入图像不精确对齐。另一方面,PIFu以完全卷积的方式将像素级别的单个局部特征与整个对象的全局上下文对齐,并且不像在基于体素的表示中那样需要很高的内存使用量。这对于衣着对象的3D重建特别相关,其形状可以是任意拓扑、高度变形和高度细节。虽然[26]也利用了局部特征,但由于缺乏3D感知的特征融合机制,他们的方法无法从单一视图推理3D形状。在这项工作中,我们展示了局部特征和3D感知的隐式曲面表示的结合会产生很大的不同,即使从单个视图也可以进行非常详细的重建。
具体地说,我们训练编码器来学习图像的每个像素的单独特征向量,该特征向量考虑了相对于其位置的全局上下文。给定每个像素的特征向量和沿着从该像素传出的相机光线的指定z深度,我们学习了一个隐式函数,该函数可以分类与该z深度相对应的3D点是在表面内部还是外部。特别地,我们的特征向量在空间上将全局3D表面形状与像素对齐,这使得我们可以保留输入图像中存在的局部细节,同时推断出看不见的区域中可能存在的细节。
(有点像一篇论文,其中是引入 隐码,latent code的概念,然后可以加强全局特征,局部细节等等)
Neural Body: Implicit Neural Representations with Structured Latent Codes for Novel View Synthesis of Dynamic Humans
网络上添加相同的隐码,可以增强彼此的联系,也就是神经共享学习,使得生成的图片融合更好。
2: 建立在隐式函数implicit function的一些工作
2.1 BSP-Net
参考(1544条消息) BSP-Net: Generating Compact Meshes via Binary Space Partitioning 详解_夕阳染色的坡道的博客-CSDN博客
研究者提出了 BSP-Net。
该网络学习一个隐式场:给定 n 个点的坐标和一个形状特征向量作为输入,网络输出一些能够指示这些点是在形状内部还是外部的值。其中形状特征向量指的是啥? 论文中是一个表达生成网络,它能生成polygon 形状的网格。和传统的三维网格不一样

生成的网络具有sharp结构。
论文的工作的原理是:通过BSP(Binary Space Partitioning),将空间层次化细分为多个convex 集合。这个网络可以学习一个用convex 集合表示3D 形状。它分为两步骤:
1:通过一组组平面生成一组convex
2:通过一组convex生成一个3D形状
其中因为convex很容易获取polygon的网络。因此整体步骤就是上面两个。
论文贡献
它是第一个用网络直接生成polygonal网格的。且这些网格能很好的被参数化(高质量的网格)。同时它的表达具有新意,用图像生成的平面和它对应的点云作为输入特征,这种表达方式非常新颖。
2.2 Scene Representation Networks
参考(1544条消息) 【NeurIPS 2019】“杰出新方向”荣誉提名奖论文解读:一种场景表征网络模型SRNs_学术头条的博客-CSDN博客
本文提出场景表征网络(Scene Representation Networks,SRNs),这是一种连续的、3D 结构感知的场景表征模型,该模型能够同时编码几何和外观。SRNs 将场景表征为连续函数,将世界坐标(world coordinate)映射为局部场景属性的一个特征表示。通过将成像系统地描述为一个可微的射线行进算法(ray-marching),SRNs 只基于2D图像及其图像的摄像机位便可进行端到端的训练,无需景深或形状信息。这种方法可以在不同场景之间自然泛化,在这个过程中学习强大的几何和外观先验知识。本文通过新视野图的合成、少样本重建、联合形状和外观插值和非刚性面模型的无监督发现来评估SRNs的潜力
贡献:
(1)提出一个连续的、3D结构感知神经场景表征和渲染的模型-SRNs。SRNs能够有效地封装场景的几何和外观信息;
(2)SRNs端到端的训练方式,只需2D空间内的图像,而无需3D空间内的显式监督学习;
(3)证明了SRNs在新视野图合成、形状和外观插值、和少样本重建以及非刚性面部模型的无监督发现任务上显著优于最近的文献基准。
3:Neural Volumes Rendering(一)
参考(1544条消息) Neural Volumes Rendering(一)_深蓝学院的博客-CSDN博客
Neural Volumes(NV)[1] 是 Stephen Lombardzai(Facebook) 在 2019 年SIGGRAPH 发表的工作,虽然 NeRF 的影响力是更大的,但是可以确定的是,NV 是 Volume Rendering 在神经渲染方面上的首次应用,并且 NV 的一些思想在之后的许多工作中都有体现,因此本文将会单独对 NV 进行介绍,希望本文能为大家建立一些 Volume Rendering 的概念。
Neural Volume 主要由两部分组成:
- Encoder-Decoder Network,将观测到的图像转换为一个 3D 的 Vol-ume。
具体的,输入 K 张图片,通过 Encoder 网络,得到一个 256 维的向量 z,我们把这个向量称为场景的状态向量 (State Vector or State Code)。接着将这个状态向量输入到 Decoder 网络得到一个 C × D × D × D 的 Volume,其实就是一个 3D 的立方体,每个顶点的值为一个C 维的向量,NV 中设定 D 为 128,C 为 4(RGBα,α 表示 opacity)。
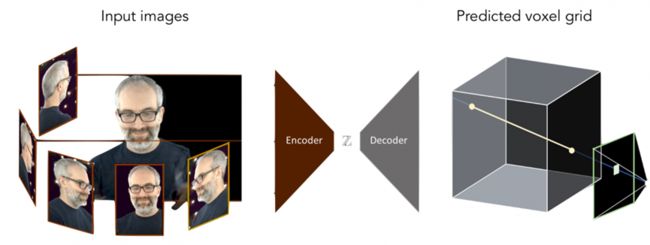
2. Raymarching Step,根据给定的相机参数以及已有的 3D Volume,渲染出对应的图像


上面的公式是 Vol- ume Rendering 的理论部分,因为其与 NeRF 有一些出入,我们暂时不对其进行讲解,在 NeRF 的章节我们进行细致的讲解。但是我们希望读者建立的一个意识是,像素观测到的颜色不止源于表面,而是来源于光线的积分。
4:论文加速方面的工作
4.1 AutoInt (Lindell et al., 2020)
参考(1544条消息) 计算机视觉2020:Automatic Integration 利用自动积分进行体积渲染_AsajuHuishi的博客-CSDN博客
数值积分(Numerical integration)是科学计算的一项基础技术,是许多计算机视觉应用的核心。在这些应用中,隐式神经体积渲染(implicit neural volume rendering)最近被提出作为一种新的视图合成范式,以实现逼真的图像质量。然而,使这些方法实用的一个根本障碍是极端的计算(computational)和内存(memory)需求,这是由于在训练和推理过程中沿着渲染光线所需要的体积积分所引起的。需要数以百万计的射线,每条射线都需要通过神经网络的数百次前向传播,才能用蒙特卡罗采样来近似这些积分。
在这里,我们提出自动积分(automatic integration),这是一个新的框架,使用隐式神经表示网络,学习高效的,闭式解求积分。对于训练,我们实例化与隐式神经表示的导数相对应的计算图。将图形拟合到信号上进行积分。优化后,我们将图重新组合,得到一个表示不定积分的网络。根据微积分基本定理,这使得计算任意定积分在两次计算网络时都是可行的。使用这种方法,我们证明了在计算需求上超过10倍的改进,实现了快速的神经体积渲染。

AutoInt框架:
(1)定义一个完整的网络架构,
(2)AutoInt构建相应的grad网络
(3)优化grad network。
(4)通过计算与grad网络共享参数的积分网络,可以计算出确定的内积分。
4.2Meta-Learning
参考(1544条消息) 元学习概述(Meta-Learning)_meta learning_一只工程狮的博客-CSDN博客
通常在机器学习里,我们会使用某个场景的大量数据来训练模型;然而当场景发生改变,模型就需要重新训练。但是对于人类而言,一个小朋友成长过程中会见过许多物体的照片,某一天,当Ta(第一次)仅仅看了几张狗的照片,就可以很好地对狗和其他物体进行区分。
元学习Meta Learning,含义为学会学习,即learn to learn,就是带着这种对人类这种“学习能力”的期望诞生的。Meta Learning希望使得模型获取一种“学会学习”的能力,使其可以在获取已有“知识”的基础上快速学习新的任务,如:
• 让Alphago迅速学会下象棋
• 让一个猫咪图片分类器,迅速具有分类其他物体的能力
Note:提高泛化性学习
需要注意的是,虽然同样有“预训练”的意思在里面,但是元学习的内核区别于迁移学习(Transfer Learning)
 在机器学习中,训练单位是一条数据,通过数据来对模型进行优化;数据可以分为训练集、测试集和验证集。在元学习中,训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。
在机器学习中,训练单位是一条数据,通过数据来对模型进行优化;数据可以分为训练集、测试集和验证集。在元学习中,训练单位分层级了,第一层训练单位是任务,也就是说,元学习中要准备许多任务来进行学习,第二层训练单位才是每个任务对应的数据。
二者的目的都是找一个Function,只是两个Function的功能不同,要做的事情不一样。
机器学习中的Function直接作用于特征和标签,去寻找特征与标签之间的关联;
而元学习中的Function是用于寻找新的f,新的f才会应用于具体的任务。有种不同阶导数的感觉。又有种老千层饼的感觉,你看到我在第二层,你把我想象成第一层,而其实我在第五层
4.3Nerf++
参考(1544条消息) NeRF神经辐射场学习笔记(六)— NeRF++论文要点解读_右边的口袋的博客-CSDN博客
NeRF++属于是对NeRF的更深理解和延伸,该文章首先讨论了几何-辐射模糊性(shape-radiance ambiguity)这一现象,并且分析了NeRF对于避免该现象的成功之处;接下来,NeRF++提出了一种参数化方法——反球面参数化(inverted sphere parameterization)来应对360度大规模无界3D场景的渲染,并取得了良好的效果。
文章针对360度的无界场景的渲染情况给出了一种反球面参数化的解决方法,即把场景空间划分为两部分——一个内部单位球体(an inner unit sphere)和一个外部反向球体(an outer volume represented by an inverted sphere covering the complement of the inner volume),
其中
内球体包含前景(foreground)和所有摄像机,
外球体包含场景内的其余部分
这两部分是用不同的NeRF独立建模的,内球体的NeRF与传统的NeRF一致,对于外球体的NeRF,我们应用了反球面参数化的解决方法

4.4Neural Sparse Voxel Fields
参考(1544条消息) 9、Neural Sparse Voxel Fields_C–G的博客-CSDN博客
该论文解决的是原始NeRF训练过程收敛速度慢的问题。原始NeRF是使用MLP网络的参数对整个空间进行建模,即原始NeRF的MLP网络的输入只有采样点的坐标和方向,输出就是该采样点的颜色和密度,因此我们可以理解为所有的信息都保存在MLP网络中。而NSVF是使用一个稀疏的体素八叉树(Sparse Voxel Octree)来辅助对空间建模,具体说来就是NSVF通过稀疏的体素八叉树保存了空间中各个节点位置的Feature,然后根据采样点的位置对Feature进行插值,最终输入MLP网络的是采样点的Feature和方向,因此空间中的信息一部分保存在了MLP网络中,另一部分则保存在稀疏的体素八叉树的Feature中
• 提出了由一组体素有界隐式字段组成的 NSVF,其中对于每个体素,体素嵌入被学习以编码局部属性以实现高质量渲染
• NSVF 利用稀疏体素结构实现高效渲染
• 引入了一种渐进式训练策略,该策略以端到端的方式从一组有姿势的 2D 图像中通过可微分的光线行进操作有效地学习底层稀疏体素结构
5:Nerf由静态(static)扩展到动态场景(Dynamic)
5.1Nerfies:
参考(1544条消息) Nerfies: Deformable Neural Radiance Fields[论文笔记]_进击的小老虎丶的博客-CSDN博客
本文提出了一种方法,能够使用从手机中随意捕获的照片真实地重建可变场景。可以观察到这些类NeRF变形场容易出现局部极小值,本文提出了一种基于坐标的模型从粗到细的优化方法,该方法可以带来更稳定的优化。通过把几何处理和物理模拟的原理应用于类神经网络模型,我们提出了变形场的弹性正则化,进一步提高了鲁棒性。
5.2可变性神经辐射场
在这里,我们描述了在给定一组随意捕捉的场景图像的情况下,对非刚性变形场景进行建模的方法。我们将非刚性变形场景分解为神经辐射场(NeRF)的模板体和将观察坐标中的点与模板上的点关联的逐观察变形场。变形场是我们对NeRF的关键扩展,允许我们表示移动的物体。联合优化能量传递函数和变形场会导致欠约束优化问题。因此,我们引入了变形的弹性正则化、背景正则化和连续的、从粗到细的处理技术,以避免糟糕的局部极小值

本文将潜在变形码(ω)和外观码(ψ)关联到每个图像。我们在观察帧中跟踪相机光线,并使用以变形码 ω 为条件的编码为 MLP 的变形场将样本沿着光线变换到正则帧。我们使用变换后的样本 ( x ′ , y ′ , z ′ ) (x’,y’,z’)(x′,y′,z′)、观察方向(θ,φ)和外观码 ψ \psiψ 作为 MLP 的输入来查询模板 NeRF ,并沿光线跟随NeRF积分样本。
5.3Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes
参考:(1544条消息) 25、Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes_C–G的博客-CSDN博客
可以从一个动态场景的单目视频在空间和时间上合成新的观点。模型输入包含坐标、方向、时间,输出包含了空间密度,反射颜色,时域双向流,以及遮挡权重。
创新点
• 用于动态场景的时空视图合成的神经表示,称之为神经场景流场,具有对3D场景动力学建模的能力
• 通过利用刚性和非刚性区域中的多视图约束来优化单目视频上的神经场景流场的方法, 允许同时合成和插值视图和时间


6:Nerf在“baking in light”方面的改进工作
6.1NeRV: Neural Representations for Videos
参考(1544条消息) (论文笔记)NeRV: Neural Representations for Videos_3hoo的博客-CSDN博客
简要介绍
提出了一种新的视频神经表示,在神经网络中编码视频,将视频表示为以帧索引作为输入的神经网络,编码过程是神经网络拟合视频帧,解码过程是简单的前馈操作。

图2:
(a)以像素坐标为输入,使用简单MLP输出像素RGB值的逐像隐式表示
(b) NeRV:以帧索引为输入,使用MLP + ConvNets输出整幅图像的逐像隐式表示。
© NeRV块结构,将特征映射在这里以S进行高档化。
MLP直接输出所有像素值会产生巨大的参数,尤其是当分辨率很大时。因此NeRV在MLP后堆叠多个NeRV块,以便不同位置的像素可以共享卷积核,从而形成有效的网络。NeRV块由卷积层、激活层和一个上采样层(通过实验证明采用PixelShuffle 技术效果最好)组成。
6.2Nerf-W
参考(1544条消息) NeRF神经辐射场学习笔记(七)— NeRF-W论文翻译及原理解读_右边的口袋的博客-CSDN博客
NeRF-W(NeRF in the wild)针对于传统NeRF有关光照变换(variable illumination)和瞬时遮挡(transient occluders)的局限,提出了改进方案。文章引入了一些新的观点使得能够利用非结构化图像集合(instructured image collections)进行场景重建;
首先,在一个学习过的低维潜在空间(learned low-dimensional latent space)中建模每个图像的外观变化,如曝光、光照、天气和后期处理。 遵循生成性潜在优化(Generative Latent Optimization)的框架,我们对每个输入图像的外观嵌入(appearance embedding)进行优化,从而通过学习整个图片集合中的共享外观表示(shared appearance representation),使NeRF-W具有灵活性来解释图像之间的光度和环境变化(photometricand environmental variations)。
其次,文章利用了一个融合有数据相关不确定场的次级体素辐射场(a secondary volumetric radiance field combined with a data-dependent uncertainty field),其中不确定场的提出捕获了可变的观测噪声,并进一步降低了瞬态对象对静态场景表示的影响。通过优化能够识别和消除瞬时图像内容,我们可以通过只渲染静态部分来合成新视图的真实感渲染。
![]()

7:NeRF 推广到其他场景下的工作
7.1PixelNerf
参考(1544条消息) 泛化nerf系列:pixelNeRF 一种基于NeRF的多视角三维重建网络_pixel-nerf_略略略06的博客-CSDN博客
文中提出了一种新的学习框架PixelNeRF,针对的是原本NeRF的不足。即现有的构建神经辐射场的方法往往需要大量的已知观察视角的图片作为输入并且需要花费大量的训练时间。PixelNeRF为了克服这些不足,允许网络跨多个场景被训练以学习先前的场景(获取场景先验知识),使其能够以前馈的方式从稀疏(sparse)的视图集(如一个)执行新的视图合成。利用NERF的体绘制方法,文中的模型可以在没有显式3D监督的情况下直接从图像训练。
论文进行了大量实验,实验结果表明,在所有情况下,PixelNeRF在新颖的视图合成和单幅图像3D重建方面的表现都优于当前最先进的基线方法。
以下是对其效果的展示:

与NeRF不使用任何图像特征不同,PixelNeRF将与每个像素对齐的空间图像特征作为输入,先利用卷积网络获得图像的底特征,将提取到的底特征加入到NeRF网络的输入中,以学习到场景的先验知识,这个过程可以由如下公式表示:
F ( x , d , f ) = ( σ , c )
优化之后的模型可以有效学习场景的先验知识,从而在一次训练之后,对于未知场景,仅通过少量输入即可得到新视点的图片。
单张图像的PixelNeRF
对于沿观察方向d的目标相机光线的查询点x,通过投影和内插法从特征体W中提取出对应的图像特征。然后将该特征与空间坐标(包含x和d)一起传递到NeRF网络f中,利用输出的颜色值和体密度进行体渲染,并将结果与目标像素值进行比较,计算渲染损失(Rendering Loss)。这个过程可以由以下公式表示:
f(γ(x),d;W(π(x)))=(σ,c)

7.2GRAF
参考(1545条消息) [论文精读]GRAF: Generative Radiance Fields for 3D-Aware Image Synthesis_大头蘑菇汤的博客-CSDN博客
尽管2D生成的对抗网络已经实现了高分辨率图像的合成,但它们在很大程度上缺乏对3D世界和图像形成过程的理解。因此,它们不能提供对相机视点或对象姿势的精确控制。
为了解决这个问题,最近的几种方法利用基于中间体素的表示与可区分的渲染结合使用。但是,现有方法要么产生低图像分辨率,要么缺乏摄像头和场景属性,例如,对象标识可能会随着视点而变化。
在本文中,我们提出了一个针对辐射场的生成模型,该模型最近证明是成功的单个场景合成的新型视图。与基于体素的表示形式相反,辐射场不仅限于3D空间的粗离散化,而是允许在存在重建歧义的情况下优雅地降低相机和场景属性。通过引入一个基于多尺度斑块的鉴别器,我们在单独从未经未受的2D图像中训练我们的模型时展示了高分辨率图像的合成。我们系统地分析了几个具有挑战性的合成和现实数据集的方法。我们的实验表明,辐射场是生成图像合成的强大表示,导致3D一致的模型以高保真性能.
在本文中,我们证明可以使用条件辐射场来解决粗糙输出和难缠的潜伏期之间的困境,这是新型视图合成的最近提出的连续表示(NeRF)的条件变体。更具体地说,我们做出以下贡献:
i: 我们提出了GRAF,这是一种用于从未介绍的图像中的高分辨率3D感知图像合成的辐射场的生成模型。除了观点操作外,我们的方法还允许修改生成对象的形状和外观。
ii: 我们引入了一个基于斑块的鉴别器,该鉴别器在多个尺度上采样图像,这是有效学习高分辨率生成辐射场的关键。
iii: 我们会系统地评估合成和真实数据集的方法。我们的方法在视觉保真度和3D一致性方面与最先进的方法相比,同时推广到高空间分辨率。
7.3pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis
参考(1545条消息) 【论文笔记】pi-GAN: Periodic Implicit Generative Adversarial Networks for 3D-Aware Image Synthesis_blurrrrrrrr的博客-CSDN博客
本文首先提出了目前3D视觉领域已有的两大问题:
没有底层的3D表示,或者依赖于“视图不一致”的表示,因此合成的图片在各个视角上不一致;
1网络结构不够好,2得到的图片质量不高。
因此,作者提出了周期性隐式生成的对抗性网络*(Periodic Implicit Generative Adversarial Networks)*,简称为pi-GAN. pi-GAN利用具有周期激活函数和体积渲染的神经表示,将场景表示为与视图一致的辐射场,能够得到SOTA的效果
总的来说,本文和GRAF的架构较为相似,但相较于GRAF效果有较好的提升。
本文中的trick主要体现在:
- 使用了SIREN作为激活函数,得到了很好的效果;
- 使用了FiLM作为条件网络层和逐步增长的判别器,得到了很好的效果;
8:iNerf
参考(1545条消息) 【论文精读】iNeRF_YuhsiHu的博客-CSDN博客
提出了 iNeRF,这是一个通过“反转”NeRF来执行姿态估计的框架,并且这个过程不需要mesh。 我们研究是否可以通过 NeRF 应用综合分析进行无mesh、仅 RGB 的 6DoF 姿态估计,也就是,给定图像,找到相机相对于 3D 对象或场景的平移和旋转。我们的方法假设在训练或测试期间是无法得到mesh的。从初始姿态估计开始,我们使用梯度下降来最小化从 NeRF 渲染的像素和观察图像中的像素之间的残差。
在我们的实验中,我们首先研究 1)如何在 iNeRF 的姿势细化过程中对光线进行采样以收集信息梯度,以及 2)不同批次大小的光线如何影响合成数据集上的 iNeRF。然后,我们展示了对于来自 LLFF 数据集的复杂现实世界场景,iNeRF 可以通过估计新图像的相机位姿并将这些图像用作 NeRF 的额外训练数据来改进 NeRF。最后,我们展示了 iNeRF 可以通过反转从单个视图推断的 NeRF 模型,使用 RGB 图像执行类别级别的对象姿态估计,包括训练期间未看到的对象实例
本文主要贡献如下:
(i) 我们表明 iNeRF 可以使用 NeRF 模型来估计具有复杂几何形状的场景和对象的 6 D o F 姿势,而无需使用 3D 网格模型或深度传感。
(ii) 我们对射线采样和梯度优化的批量大小进行了彻底的调查,以表征 iNeRF 的鲁棒性和局限性。
(iii) 我们证明 iNeRF 可以通过预测额外图像的相机姿势来改进 NeRF,然后可以将其添加到 NeRF 的训练集中。
(iv) 我们展示了类别级别的姿势估计结果,对于看不见的物体,并包括真实世界的演示。
Limited
光照和遮挡会严重影响iNeRF,一个潜在的解决方案是使用transient latent codes建模appearance variation,就像NeRF-W当中训练NeRF时候做的那样,并且在iNeRF当中对这些外观编码和相机位姿一起进行联合优化。并且,现在iNeRF使用大概20秒来运行100 100100次迭代优化,还不能实时,可以结合新的NeRF来做提升。