六、OpenCV-python 之图像处理(Ⅳ)——模板匹配/分水岭/GrabCut
一、模板匹配
1、单目标
单目标模板匹配的原理:模板图像在输入图像上做滑动操作(类似于 2D 卷积),模板图像与所在原图 patch 做比较,最终返回一个灰度图,每个像素代表该像素的邻域与模板的相似度。当输入图像尺寸为 ( W , H ) (W, H) (W,H)、模板图像尺寸为 ( w , h ) (w,h) (w,h) 时,输出图像尺寸为 ( W − w + 1 , H − h + 1 ) (W-w+1, H-h+1) (W−w+1,H−h+1)。 一旦得到结果,就可以使用cv.minMaxLoc() 函数来查找最大值/最小值的位置,取它为矩形的左上角,取 ( w , h ) (w,h) (w,h) 为矩形的宽和高,这个矩形就是找到的模板区域。
cv.matchTemplate(
image, # 原始图像,可以是灰度图,也可以是BGR图
templ, # 模板图,尺寸不能大于原始图像
method, # 模板匹配方式
result,
mask # 掩码
)
import cv2 as cv
import numpy as np
from matplotlib import pyplot as plt
img = cv.imread('messi5.jpg',0)
img2 = img.copy()
template = cv.imread('template.jpg',0)
w, h = template.shape[::-1]
# 六种不同的模板匹配方式,
methods = ['cv.TM_CCOEFF', 'cv.TM_CCOEFF_NORMED', 'cv.TM_CCORR',
'cv.TM_CCORR_NORMED', 'cv.TM_SQDIFF', 'cv.TM_SQDIFF_NORMED']
for meth in methods:
img = img2.copy()
method = eval(meth)
# 模板匹配
res = cv.matchTemplate(img,template,method)
min_val, max_val, min_loc, max_loc = cv.minMaxLoc(res)
# 获取左上角位置,不同匹配模式获取的方式不相同
if method in [cv.TM_SQDIFF, cv.TM_SQDIFF_NORMED]:
top_left = min_loc
else:
top_left = max_loc
# 计算右下角位置
bottom_right = (top_left[0] + w, top_left[1] + h)
cv.rectangle(img, top_left, bottom_right, 255, 2)
cv.imshow(meth, img)
cv.waitKey(0)
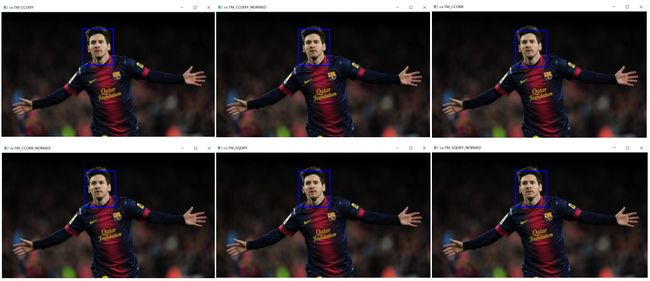
推荐使用 cv.TM_SQDIFF,不推荐 cv.TM_CCORR!
2、多目标
使用 cv.minMaxLoc() 找的是最值,只能有一个返回,如果图像中有多个目标区域呢?这时可以用阈值函数来筛选匹配度较高的位置。因为,模板匹配返回值给出的是每个像素点是模板左上角的概率,只要设置一个概率阈值,就能找到所需位置。
import cv2 as cv
import numpy as np
img_rgb = cv.imread('./images/Mario.png')
img_gray = cv.cvtColor(img_rgb, cv.COLOR_BGR2GRAY)
template = cv.imread('./images/mario_c.png', 0)
w, h = template.shape[::-1]
res = cv.matchTemplate(img_gray, template, cv.TM_CCOEFF_NORMED)
threshold = 0.7
loc = np.where(res >= threshold)
for pt in zip(*loc[::-1]):
cv.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0, 0, 255), 1)
cv.imshow('res.png', img_rgb)
cv.waitKey(0)

在具体使用时,可能会出现的一些问题:
- 匹配模式不同,得到的结果可能也不一样,需要根据实际情况选择最优的模式
- 模板图像的像素值很重要,也就是它的大小、范围会影响最终的匹配结果
- 同一个目标区域返回的左上角的位置可能是多个相邻的点,比如上面第二排硬币的框,线宽之所以如此宽是因为多个点都接受作为左上角,此时可以适当增加阈值
二、霍夫线检测
详见《OpenCV常用检测算法》
三、霍夫圆检测
详见《OpenCV常用检测算法》
四、分水岭算法
任何一张灰度图都可以被视作是一个“地形图”,高强度位置是山峰,低强度位置是山谷。现在假设你在往不同的山谷里面注入不同颜色的水,当山谷被注满时水会溢出来,相邻山谷的水会汇合产生颜色的变化,为了阻止这种颜色的交融,你在汇合处建立屏障;继续注水和建屏障的操作,知道所有的山谷都被淹没。最后,你所建立的屏障就能完成对图像的分割。这就是分水岭算法的原理所在,具体可以访问CMM查看动画。
但是由于图像中存在噪声或其他不规则现象,传统的分水岭算法会导致分割过度。所以,OpenCV 实现了一个基于标记的分水岭算法,在某些被标记的区域内做分水岭,这其中最关键的内容就是计算这个标记 mark!推荐方法是使用 cv.findContours 来标记,也可以用基于距离的方法来获取标记。
1、基于距离
基本算法步骤:
- 预处理:BGR图像变成灰度图,做自适应二值化操作,形态学开操作去除白色噪点
- 计算背景:形态学膨胀,得到确定的背景区域
- 计算前景:
cv.distanceTransform做距离变换,根据距离变换结果做阈值处理,得到确定的前景区域 - 计算未知区域:确定的背景减去确定的前景,得到的就是未知区域,未知区域就包含边界区域
- 计算 mark:对前景区域做基本标记,再融合未知区域作进一步标记
- 分水岭算法:输入是原始图像、mark,输出是标记边界
img = cv.imread('images/coins.png')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# noise removal
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# sure background area
sure_bg = cv.dilate(opening, kernel, iterations=3)
cv.imshow('3-background', sure_bg)
# Finding sure foreground area
dist_transform = cv.distanceTransform(opening, cv.DIST_L2, 5)
ret, sure_fg = cv.threshold(dist_transform, 0.7 * dist_transform.max(), 255, 0)
# Finding unknown region
sure_fg = np.uint8(sure_fg)
unknown = cv.subtract(sure_bg, sure_fg)
# Marker labelling
ret, markers = cv.connectedComponents(sure_fg)
# Add one to all labels so that sure background is not 0, but 1
markers = markers + 1
# Now, mark the region of unknown with zero
markers[unknown == 255] = 0
markers = cv.watershed(img, markers)
img[markers == -1] = [255, 0, 0]
2、基于轮廓
img = cv.imread('images/coins.png')
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
ret, thresh = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# 形态学开操作去白色噪点
kernel = np.ones((3, 3), np.uint8)
opening = cv.morphologyEx(thresh, cv.MORPH_OPEN, kernel, iterations=2)
# 膨胀操作,让轮廓往外扩展一些(不加的话可能效果不佳)
opening = cv.dilate(opening, kernel, iterations=3)
# 计算轮廓
contours, hierarchy = cv.findContours(opening, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
# 绘制轮廓,作为 mark
h, w, _ = img.shape
marks = np.zeros((h, w))
for i in range(len(contours)):
cv.drawContours(marks, contours, i, i+1) # 不同的轮廓使用不同的标记值
marks = marks.astype(np.int32)
# 分水岭算法
marks = cv.watershed(img, marks)
img[marks == -1] = (255, 0, 0)
五、GrabCut 算法
GrabCut 算法论文《“GrabCut”: interactive foreground extraction using iterated graph cuts》,它提出了一种利用最少的交互完成前景提取的算法。算法的基本思路:先人工在图像中用矩形框选取目标前景所在区域,然后 GrabCut 通过迭代分割找到最优解;如果最优解还是不够完美,用户再使用画笔在图像上进一步标注哪些地方是背景、哪些地方是前景,算法再一次给出最优解。具体来说:
- 画矩形框:算法认为矩形框以外的全是背景,矩形框以内的是“未知”
- 编码:对矩形框以内的像素点进行前景和背景编码,其依据就是每个像素点跟矩形框外面的背景相似度
- GMM 建模:使用高斯混合模型对前景和背景进行建模
- GMM 重编码:GMM 对象素进行重新标记,原理类似于聚类
- 图的建立:根据 GMM 的像素分布建立一个图,以像素作为节点,再另外添加两个节点:源点,汇点。每个前景像素连接到源点,每个背景像素连接到汇点
- 计算权重:像素到源点和汇点的权重由各自是前景/背景的概率来定义,像素到像素之间的权重由像素颜色相似度来定义(差距较大则权重较低)
- 分割:采用 mincut 算法对图进行分割,分割的原则是如果相邻像素点分别属于前景和背景,则它们之间的连边被切断,该边的权重计入代价函数,切割方式须保证代价函数最小。剪切后,所有连接到源节点的像素都成为前景,连接到汇聚节点的像素都成为背景。
- 迭代:反复迭代,直到得到最优解。迭代的操作就是人为指定哪些地方分错了。
# 函数解析:
cv.grabCut(
img, # 8位3通道图像
mask, # 掩码,大小跟原始图像一致,像素值有0/1/2/3,分别表示背景、前景、可能是背景、可能是前景
rect, # ROI,表示其外围的像素都是背景
bgdModel, # 算法内部使用的数组,只需要创建一个(1,65)的float64数组就行
fgdModel, # 算法内部使用的数组,只需要创建一个(1,65)的float64数组就行
iterCount, # 迭代次数
mode # 选择初始化是使用上面的mask还是rect,cv.GC_INIT_WITH_RECT,cv.GC_INIT_WITH_MASK
)
看一个实例:先用一个矩形框给出我们目标物体的大概位置,然后用 GrabOut 做分割。
import numpy as np
import cv2 as cv
from matplotlib import pyplot as plt
img = cv.imread('images/messi.png')
mask = np.zeros(img.shape[:2], np.uint8) # 其实这里没用到它
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
rect = (50, 50, 700, 450) # 初始化用的是它
cv.grabCut(img, mask, rect, bgdModel, fgdModel, 5, cv.GC_INIT_WITH_RECT) # 结果直接存在 mask 中
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8')
img = img * mask2[:, :, np.newaxis]
plt.imshow(img[:, :, ::-1]), plt.colorbar(), plt.show()
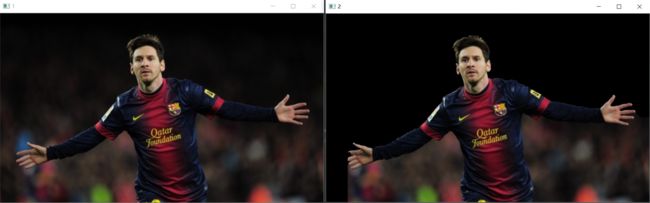
图像上半部分基本都分割为背景了,但是手臂以下的部分处理却不好。而且GrabCut的耗时比较长,上述 743*435 的图片,耗时在6s左右。所以,实际上GrabCut在速度和精度上效果都不理想!