Golang 关键字使用方法
1. return
***:与其他语言相比,Go函数支持返回多个值
func 函数名 (形参列表) (返回值类型列表){
语句
return 返回值列表
}
func 函数名 (形参列表) (返回值类型列表){
语句
return 返回值列表
}1)如果返回多个值,在接收时,希望忽略某个返回值,则可以使用_符号表示占位忽略
2)如果返回值只有一个, 建议返回值类型列表 不写()
2.递归调用
一个函数在函数体内调用了本身,称为递归调用
package main
import "fmt"
func test(n int){
if n>2{
n--//递归必须向退出递归条件逼近,否则就是无限循环
test(n)
}
fmt.Println("n=",n)
}
func main(){
test(4) // 结果 2 2 3
}
递归使用的原则:
1)执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
2)函数的局部变量是独立的,不会相互影响
3)递归必须向退出递归条件逼近,否则就是无限循环
4)当一个函数执行完毕,或者遇到return,就会执行返回,遵守谁调用就将结果返回给谁,同时当函数执行完毕或者返回时,该函数本身也会被系统销毁(临时占用空间)。
3.函数
func 函数名 (形参列表) (返回值类型列表){
语句
return 返回值列表
}函数注意事项和细节处讨论:
1)函数的形参列表可以是多个,返回值列表也可以是多个
2)形参列表和返回值列表的数据类型可以是值类型和引用类型
3)函数的命名遵循标识符命名规范,首字母不能是数字,首字母大写该函数可以被本包文件和其他包文件使用,类似java中的public,首字母小写,则只能被本包文件使用,其它包文件不能使用,类似private
4)函数中的变量是局部变量,函数外不生效
5)基本数据类型和数组默认都是值传递,即进行值拷贝。在函数内修改,不会影响到原来的值
6)若希望在函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。
7)Go函数不支持重载(函数名相同,形参不一样)
8) 在Golang中,函数也是一种数据类型,可以赋值给一个变量,则该变量就是一个函数类型的变量。通过该变量可以对函数调用
package main
import "fmt"
func getSum(n1, n2 int) int {
return n1 + n2
}
func main() {
a := getSum
fmt.Printf("a的类型是%T,getSum的类型是%T\n", a, getSum)
res := a(10, 6)
fmt.Println("res=", res)
}

9)函数既然是一种数据类型,则函数可以作为形参使用
package main
import "fmt"
func getSum(n1, n2 int) int {
return n1 + n2
}
//函数作为形参使用
func myFunc(fbb func(int, int) int, n1 int, n2 int) int {
return fbb(n1, n2)
}
func main() {
a := getSum
fmt.Printf("a的类型是%T,getSum的类型是%T\n", a, getSum)
res := a(10, 6)
fmt.Println("res=", res)
res1 := myFunc(a, 10, 20) //myFunc(getSum, 10, 20)
fmt.Println("res1=", res1)
}10)为了简化数据类型定义,Go支持自定义数据类型
基本语法: type 自定义数据类型名 数据类型 //相当于一个别名
案例:1. type myInt int //此时 myInt就等价于 int
2. type mySum func(int,int)int //此时,mySum 就等价于一个函数类型 func(int,int)int
注意:在go中虽然 myInt 和 int 都是int类型,但go认为myInt和int是两个类型
01 // 给int取了别名 在go中虽然 myInt 和 int 都是int类型,但go认为myInt和int是两个类型
type myInt int
var num1 myInt = 40
var num2 int
num2 = int(num1)
//02
package main
import "fmt"
func getSum(n1, n2 int) int {
return n1 + n2
}
// 给函数类型取别名
type myFbb func(int, int) int
func myFunc(fbb myFbb, n1 int, n2 int) int {
return fbb(n1, n2)
}
func main() {
a := getSum
fmt.Printf("a的类型是%T,getSum的类型是%T\n", a, getSum)
res := a(10, 6)
fmt.Println("res=", res)
res1 := myFunc(a, 10, 20) //myFunc(getSum, 10, 20)
fmt.Println("res1=", res1)
// 给int取了别名 在go中虽然 myInt 和 int 都是int类型,但go认为myInt和int是两个类型
type myInt int
var num1 myInt = 40
var num2 int
num2 = int(num1)
fmt.Println("num1=", num1, "num2=", num2)
}11) 支持对返回值命名
func cal(n1 int, n2 int) (sum int, sub int) {
sub = n1 - n2 // 不需要再创建变量了,在上面命名时就创建了相应的变量,故此处使用=而非:=
sum = n1 + n2
return
}
func main() {
a1, b1 := cal(10, 5)
fmt.Println("a1=", a1, "b1=", b1)
}
12)使用_标识符,占位忽略返回值
a1, _ := cal(10, 5)
13) Go支持可变参数
//0到多个参数 //支持1到多个参数
func sum(args... int) sum int {func sum(n1 int, args... int) sum int{
} }
说明:
1.args是slice切片,可以通过arge[index]访问到各个值(args名字可以自定义,推荐使用args)
2.如果一个函数的形参列表中海油可变参数,则可变参数需要放到形参列表的最后3.函数
func sum(n1 int, args ...int) (sum int) {
sum = n1
for i := 0; i < len(args); i++ {
sum += args[i]
}
return
}
func main() {
fmt.Println(sum(10, 0, 20, 30, -40))
}3.init函数
基本介绍:
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go语言框架调用;即init会在main函数前被调用
案例:
package main
import "fmt"
//init 函数,通常可以在init函数中完成初始化工作
func init() {
fmt.Println("init() ...")
}
func main() {
fmt.Println("main()...")
}

细节讨论:
1) 如果一个文件同时包含全局变量,init函数和main函数,则执行流程是:
变量定义->init函数->main函数
package main
import "fmt"
var a = test()
//为直观看到全局变量是先被初始化的,在这儿编写一个函数
func test() int {
fmt.Println("test()...") //第一个输出
return 10
}
//init 函数,通常可以在init函数中完成初始化工作
func init() {
fmt.Println("init() ...") //第二个输出
}
func main() {
fmt.Println("main()...") //第三个输出
}
2) init函数最主要的作用就是完成一些初始化的工作
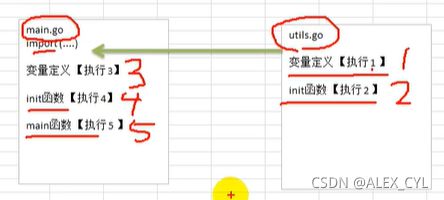
3)如果main.go 文件和引用包文件utils.go文件里都有全局变量定义,init函数,执行流程:
4. 匿名函数
Go支持匿名函数,若某函数只希望被调用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用。
使用方式
1.定义匿名函数时直接调用,这种方式匿名函数只能调用一次
2.将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
3.全局匿名函数:将匿名函数赋给一个全局变量,那么这个匿名函数就成为了一个全局匿名函数,可以在程序需有效。
package main
import "fmt"
// fun1 就是一个全局匿名函数
var (
Fun1 = func(n1, n2 int) int {
return n1 * n2
}
)
func main() {
//在定义匿名函数时直接调用,这种方式匿名函数只调用一次
res1 := func(n1, n2 int) int { // 没有函数名
return n1 + n2
}(10, 20)
fmt.Println("res1=", res1)
//匿名函数赋值给一个变量
a := func(n1, n2 int) int { // 没有函数名
return n1 - n2
}
res2 := a(40, 20)
fmt.Println("res2=", res2)
res3 := a(90, 20)
fmt.Println("res3=", res3)
//全局匿名函数的使用
res4 := Fun1(4, 6)
fmt.Println("res4=", res4)
}
5.闭包
闭包就是一个函数与其相关的引用环境组合的一个整体(实体)
案例:累计计算
代码:
package main
import (
"fmt"
_ "strconv"
)
//累计
// 变量i 与函数 func(int)int {}组成一个整体,即闭包概念
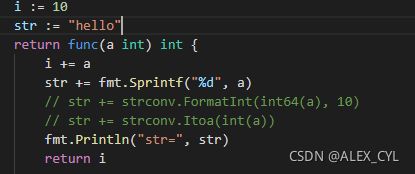
func AddUpper() func(a int) int {
i := 10
str := "hello"
return func(a int) int {
i += a
str += fmt.Sprintf("%d", a)
// str += strconv.FormatInt(int64(a), 10)
// str += strconv.Itoa(int(a))
fmt.Println("str=", str)
return i
}
}
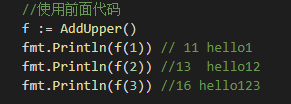
func main() {
//使用前面代码
f := AddUpper()
fmt.Println(f(1)) // 11 hello1
fmt.Println(f(2)) //13 hello12
fmt.Println(f(3)) //16 hello123
}
案例分析:
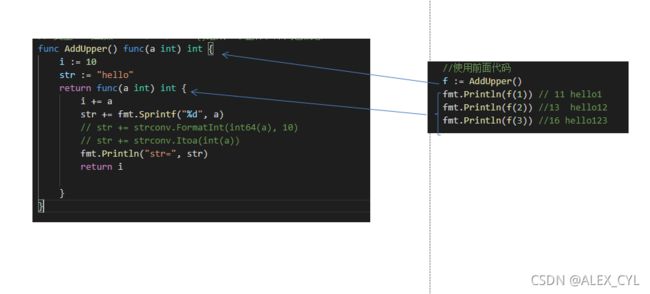
1) AddUpper 定义的一个函数,返回数据类型是 func (int) int{} (匿名函数)
2)闭包的说明
返回的一个匿名函数,这个匿名函数引用到函数外的变量i,str,因此这个匿名函数和变量i,str形成一个整体,构成闭包
亦可以理解成:闭包是类,函数是操作,变量i是字段。函数和他它使用到的函数外的变量i,str构成闭包
3)当反复调用f函数时,因为变量i和str只初始化一次。因此,后续每调用一次就进行累计。
当f := AddUpper() 等价于变量i和str初始化后的匿名函数:
f := func (a int) int { func(a int) int { i += a // i == 10 str += fmt.Sprintf("%d", a) // str == "hello" fmt.Println("str=", str) return i }变量i和str定义在AddUpper包内,所以后续每一次调用f函数都无法对i和str进行初始化
marking:闭包分析的关键:分析出返回的函数和它所使用到哪些函数外的变量,因为函数和它引用到的变量共同构成闭包。
闭包的优势 :
相较普通函数,调用一次变量需要重新分配一定的空间,进行多次操作需要重复多次输入。 闭包可以保留上次引用的某个值,所以传入一次就可以反复使用。
案例: //使用闭包写一个判断文件后缀是否指定后缀,否则添加指定后缀的函数
package main
import (
"fmt"
"strings"
)
//使用闭包写一个判断文件后缀是否指定后缀,否添加指定后缀的函数
func makeSuffix(suffix string) func(string) string {
return func(name string) string {
if strings.HasSuffix(name, suffix) {
return name
}
return name + suffix
}
}
// 传统的函数方法:
func makeSuffix1(suffix, name string) string {
if strings.HasSuffix(name, suffix) {
return name
}
return name + suffix
}
func main() {
// 测试 makeSuffix
//返回一个闭包
f1 := makeSuffix(".png")
fmt.Println(f1("spring"))
fmt.Println(f1("summer.png"))
fmt.Println(f1("autumn.jpg"))
//传统方法
f2 := makeSuffix1
fmt.Println(f2(".jpg", "spring~"))
fmt.Println(f2(".jpg", "autumn.png"))
fmt.Println(f2(".jpg", "winter.jpg"))
}案例说明:
传统方法需要每次都输入判定的后缀文件名,当处理一批相同条件的文件时,闭包的优势就显示出了,输入更少的语句,执行相同的效果。
6.函数的defer
为什么需要defer:
在函数中,经常需要创建资源(例如:数据连接、文件句柄、锁等),为了在函数执行完毕后,及时释放资源,Golang提供了defer(延时机制)
案例说明:
package main
import (
"fmt"
)
func sum(n1, n2 int) int {
//当执行到defer语句时,暂时不执行,会将defer后的语句压入到独立的栈中(defer栈)
//当defer所在函数执行完毕后,再从defer栈中,按照先入后出的方式出栈,执行相关语句
//在defer将语句放入到栈时,也会将相关的值拷贝同时入栈
defer fmt.Println("ok1 n1=", n1) // 输出第三条语句. ok1 n1= 10
defer fmt.Println("ok2 n2=", n2) // 输出第二条语句. ok2 n2= 10
n1++ //11
n2++ //21
res := n1 + n2 // res = 32
fmt.Println("ok3 res=", res) // 输出第一条语句. ok3 res= 32
return res
}
func main() {
res1 := sum(10, 20)
fmt.Println("res1=", res1) // 输出第四条语句 res1= 32
}
运行结果:

defer细节说明:
1.当执行当执行到defer语句时,暂时不执行,会将defer后的语句压入到独立的栈中(defer栈)
2.当defer所在函数执行完毕后,再从defer栈中,按照先入后出的方式出栈,执行相关语句
3.在defer将语句放入到栈时,也会将相关的值拷贝同时入栈。
defer的最佳实践
defer最主要的价值是在函数执行完毕后,可以及时的释放函数创建的资源。
1.在Golang编程中的通常做法是,创建资源后(例如打开了一个文件,获取了数据库的链接,或者是锁等资源),可以执行defer file.Close() defer connect.Close()
2.在 defer 语句后, 可以继续使用创建资源
3.当函数执行完毕后,系统会依次从defer栈中,取出语句,关闭资源
4.这种机制,非常简洁,不必再为什么时机关闭资源而烦心。