计算文本相似度,输出相似度最高的n个
目录
- 配置
-
- 创建虚拟环境
- 下载
- TFidf
-
- 概念
- 代码
- word2vec
-
- 概念
- 模型
- 代码
- 结果
- SpaCy
-
- 概念
- 模型
- 代码
- 结果
- Bert
-
- 概念
- 模型
- 代码
- 结果
- 对比
配置
创建虚拟环境
python3.9
conda create -n py39 python=3.9
conda activate py39
下载
pip install -r D:\myfile\jpy\py\000rec\install\requirements.txt
cx-Oracle==8.3.0
pandas==2.1.1
jieba==0.42.1
joblib==1.2.0
gensim==4.3.0
scikit-learn==1.3.0
tqdm==4.65.0
sqlalchemy==2.0.21
spacy==3.5.3
zeep==4.2.1
transformers==4.32.1
pytorch==2.0.1
widgetsnbextension==4.0.9
ipywidgets==8.1.1
ipykernel==6.25.0
python -m spacy download zh_core_web_sm
或者
pip install D:\myfile\jpy\py\000rec\install\zh_core_web_sm-3.5.0.tar.gz
https://github.com/explosion/spacy-models/releases?q=zh_core_web_sm&expanded=true
python -m ipykernel install --user --name py39
TFidf
概念
TF-IDF是用于文本数据分析和信息检索的常见技术,它的全称是 “Term Frequency-Inverse Document Frequency”。它采用统计方法来评估文本中每个词语的重要性,主要应用在以下两个领域:
-
文本检索:TF-IDF用于确定给定查询条件下文档的相关性,从而协助搜索引擎对搜索结果进行排名。它分析查询中词语在文档中的重要性,以提高相关文档的排名。
-
文本挖掘:TF-IDF还可用于文本挖掘任务,如文档分类、聚类和关键词提取。它帮助识别文档中最重要的词语,有助于理解文档内容和主题。
TF-IDF的计算涉及两个核心概念:
-
词频(Term Frequency,TF):衡量一个词语在文档中的出现频率。出现次数多的词语具有较高的TF值。
-
逆文档频率(Inverse Document Frequency,IDF):考虑词语在整个文档集合中的分布情况,对常见词语降低权重,对罕见词语提高权重。
TF-IDF的计算方式是将一个词语的TF值与其IDF值相乘,以得出该词语在文档集合中的重要性分数。通常,TF-IDF分数越高,表示该词语在文档中的重要性越大。TF-IDF的公式如下:
T F i d f = T F ∗ I D F TFidf = TF * IDF TFidf=TF∗IDF
TF-IDF通常用于文本预处理和特征工程,以便机器学习算法能够更好地处理文本数据。它是文本分析和信息检索中非常有用的工具之一。
为什么计算了TF(Term Frequency,词频)之后,还要计算IDF(Inverse Document Frequency,逆文档频率)?
-
强调重要性:TF衡量了词语在单个文档中的频率,但它不足以准确评估词语在整个文档集合中的重要性。常见词语可能在单个文档中频繁出现,但它们在整个文档集合中并不具有特殊的重要性。IDF通过考虑词语在文档集合中的分布情况,增加了罕见词语的权重,减少了常见词语的权重,从而更好地反映了词语的重要性。
-
降低噪声:文本数据中通常包含大量的噪声,如停用词(如 “and”、“the” 等)和常见词语,它们在大多数文档中都出现。TF-IDF可以减少这些噪声的影响,因为它们通常具有低的IDF值,因此在TF-IDF计算中的权重较低。
-
适应不同文档集合:TF-IDF的灵活性使其能够适应不同领域或主题的文档集合。不同领域可能会有不同的常见词语和重要词语,IDF可以根据文档集合的特点调整词语的权重,使其更适应特定领域或主题。
-
特征选择:在文本分析任务中,TF-IDF可用于选择最具代表性的特征词语。高TF-IDF值的词语通常更适合用作特征,因为它们更可能与文档的主题或类别相关,有助于提高文本分类、聚类和信息检索的性能。
综合而言,TF和IDF的结合使得TF-IDF能够更准确地衡量词语的重要性,强调关键词语,降低噪声干扰,适应不同文档集合,以及用于特征选择,提高文本数据分析的质量和效果。
代码
import jieba
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# 句子
df = pd.DataFrame({'id': ['a', 'b', 'c', 'd', 'e'],
'Sentences':["今天天气真好,阳光明媚。",
"关键字匹配是一种常见的文本处理任务。",
"计算机不认识人类语言,要转成词向量。",
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。",
"中文分词工具对文本处理很有帮助。",]})
# 输入的查询句子
query_sentence = "关键字匹配和文本处理任务"
# 分词并建立TF-IDF特征向量
def preprocess(text):
words = jieba.lcut(text)
return " ".join(words)
df["Preprocessed_Sentence"] = df["Sentences"].apply(preprocess)
query_sentence = preprocess(query_sentence)
# 计算相似度
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(list(df["Preprocessed_Sentence"]) + [query_sentence])
similarities = cosine_similarity(tfidf_matrix)
query_similarity = similarities[-1, :-1] # 最后一行是查询句子
# 获取相似度最高的n个句子
n = 10 # 想要获取的相似句子数量
result_df = df.copy()
result_df.set_index('id', inplace=True)
result_df['Similarity_Score'] = query_similarity
result_df = result_df.sort_values(by='Similarity_Score', ascending=False)#.reset_index(drop=True)
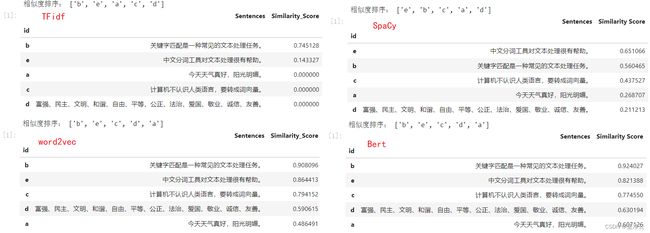
print('相似度排序:', result_df.index.to_list())
result_df[['Sentences', 'Similarity_Score']][:n]
结果

word2vec
概念
Word2Vec 是一种词嵌入(Word Embedding)模型,其核心原理是将单词映射到一个连续的实数向量空间中,以便能够在向量空间中捕捉单词的语义信息。Word2Vec模型有两个主要变种:Continuous Bag of Words (CBOW) 和 Skip-gram。下面将介绍这两个变种的基本原理:
-
Continuous Bag of Words (CBOW):
- 在CBOW模型中,给定一个目标单词,模型试图从其周围的上下文单词中预测目标单词。
- CBOW的输入是一个上下文窗口内的上下文单词的词嵌入向量的平均值。
- 模型的输出是目标单词的词嵌入向量。
- 训练过程中,模型通过最大化预测目标单词的条件概率来学习单词的词嵌入,使得上下文单词给出目标单词的条件下的条件概率最大化。
-
Skip-gram:
- 在Skip-gram模型中,与CBOW相反,给定一个目标单词,模型试图预测它周围的上下文单词。
- Skip-gram的输入是目标单词的词嵌入向量。
- 模型的输出是目标单词周围上下文单词的词嵌入向量。
- 训练过程中,模型通过最大化预测目标单词周围上下文单词的条件概率来学习单词的词嵌入。
Word2Vec的训练过程通常使用大量的文本数据。在训练时,模型调整单词的词嵌入向量,使得能够更好地预测上下文单词或目标单词。这些词嵌入向量在训练完成后可以用于多种自然语言处理任务,如文本分类、情感分析、文档相似度计算等。
Word2Vec的主要思想是通过单词在向量空间中的分布来捕捉单词的语义信息,即语义相近的单词在向量空间中的距离更接近。这种连续向量表示的方式使得模型能够更好地理解单词之间的语义关系,而不仅仅是简单的词频统计。 Word2Vec 已经成为自然语言处理领域中非常有用的工具,用于提高各种NLP任务的性能。
模型
https://ai.tencent.com/ailab/nlp/en/download.html
tencent-ailab-embedding-zh-d100-v0.2.0-s 是腾讯(Tencent)发布的一个中文词嵌入(Word Embedding)模型。这个模型的名称中包含了一些关键信息:
-
“tencent” 表示这是由腾讯公司开发或提供的。
-
“ailab” 表示这个模型可能与腾讯的人工智能实验室(AI Lab)相关。
-
“embedding” 意味着这是一个词嵌入模型,用于将单词映射到实数向量空间中。
-
“zh” 表示这是一个中文语言模型。
-
“d100” 表示每个单词的词嵌入向量的维度为100,即每个单词在向量空间中用一个包含100个实数值的向量表示。
-
“v0.2.0-s” 可能是模型的版本号或标识,指明模型的版本。
这个模型的主要用途是将中文单词映射到100维的向量空间中,以便在自然语言处理任务中使用。这种词嵌入向量通常用于文本分析、文本分类、文本相似度计算、命名实体识别、情感分析和其他自然语言处理任务。
代码
import pandas as pd
import numpy as np
import gensim
from gensim.models import KeyedVectors
import jieba
# 加载预训练的中文Word2Vec模型
model_path = "model/tencent-ailab-embedding-zh-d100-v0.2.0-s/tencent-ailab-embedding-zh-d100-v0.2.0-s.txt"
w2v_model = KeyedVectors.load_word2vec_format(model_path, binary=False)
# 目标句子
target_sentence = "关键字匹配和文本处理任务"
# 对目标句子进行分词并计算句子向量
def target_sentence_to_vector(sentence, model):
words = list(jieba.cut(sentence))
vector = np.zeros(model.vector_size)
word_count = 0
for word in words:
if word in model:
vector += model[word]
word_count += 1
if word_count > 0:
vector /= word_count
return vector
target_vector = target_sentence_to_vector(target_sentence, w2v_model)
# 句子
df = pd.DataFrame({'id': ['a', 'b', 'c', 'd', 'e'],
'Sentences':["今天天气真好,阳光明媚。",
"关键字匹配是一种常见的文本处理任务。",
"计算机不认识人类语言,要转成词向量。",
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。",
"中文分词工具对文本处理很有帮助。",]})
# 对句子进行分词并计算句子向量
def sentence_to_vector(sentence, model):
words = list(jieba.cut(sentence))
vector = np.zeros(model.vector_size)
word_count = 0
for word in words:
if word in model:
vector += model[word]
word_count += 1
if word_count > 0:
vector /= word_count
return vector
df['vector'] = df['Sentences'].apply(lambda x: sentence_to_vector(x, w2v_model))
# 计算"target_sentence"与DataFrame中句子的相似度
def calculate_similarity(target_vector, sentence_vector):
similarity = np.dot(target_vector, sentence_vector) / (np.linalg.norm(target_vector) * np.linalg.norm(sentence_vector))
return similarity
df['Similarity_Score'] = df['vector'].apply(lambda x: calculate_similarity(target_vector, x))
# 按"Similarity_Score"从高到低排序DataFrame
df = df.sort_values(by='Similarity_Score', ascending=False)#.reset_index(drop=True)
df.set_index('id', inplace=True)
print('相似度排序:', df.index.to_list())
n = 10 # 选择前n个最相似的句子
# 输出包含"id"、"sentence"和"Similarity_Score"的DataFrame
df[['Sentences', 'Similarity_Score']][:n]
结果

SpaCy
概念
SpaCy(发音为"spacey")是一种开源自然语言处理(NLP)库和工具包,旨在处理和分析文本数据。它提供了各种功能和算法,用于文本处理、词法分析、句法分析、命名实体识别、词性标注、依存关系分析和文本向量化等自然语言处理任务。SpaCy 的设计注重性能和效率,因此在处理大规模文本数据时非常快速。
以下是 SpaCy 提供的一些主要功能和特点:
-
词法分析:SpaCy 可以将文本分割成句子和单词,进行标记化处理,并提供有关每个单词的详细信息,如词干、词性标记和词语的词义。
-
句法分析:SpaCy 可以识别句子中的依存关系,即单词之间的语法关系。这有助于理解句子结构和单词之间的连接。
-
命名实体识别(NER):SpaCy 可以识别文本中的命名实体,如人名、地名、组织名等,并将其分类为不同的类别,如人名、地名、日期等。
-
词性标注:SpaCy 可以为每个单词分配词性标签,帮助用户了解文本中不同单词的语法角色。
-
文本向量化:SpaCy 提供了预训练的词嵌入模型,可以将文本转换成向量表示,这有助于进行文本分类、聚类和相似度分析等任务。
-
支持多种语言:SpaCy 支持多种自然语言,包括英语、德语、法语、西班牙语、荷兰语等,因此可以用于处理不同语言的文本数据。
-
高性能:SpaCy 的实现被优化,以便处理大规模文本数据,因此在性能方面表现出色。
SpaCy 在自然语言处理和文本分析领域广泛用于各种应用,包括信息检索、文本分类、实体识别、情感分析、机器翻译等。由于其性能和功能的优势,SpaCy 成为了研究人员和工程师在处理文本数据时的有力工具。
模型
https://spacy.io/
SpaCy 提供了不止一个中文语言模型,以满足不同应用场景的需求。以下是一些常见的 SpaCy 中文语言模型:
-
zh_core_web_sm:这是 SpaCy 的轻量级中文语言模型,提供基本的中文文本处理功能,包括分词、词性标注、句法分析和命名实体识别。它适用于一般的中文文本处理任务。
-
zh_core_web_md:这个模型比 zh_core_web_sm 更大,包含更多的词汇和语法信息。它适用于需要更复杂分析的任务,如文本挖掘和文本理解。
-
zh_core_web_lg:这是 SpaCy 的大型中文语言模型,包含了大量的词汇和语法信息。它适用于处理大规模文本数据,如文本分类、聚类和信息检索。
这些模型的选择取决于具体的应用需求和文本数据规模。通常来说,如果您只需要进行基本的文本处理和分析,zh_core_web_sm 可能足够了。但如果需要更多的语法和词汇信息,或者处理更大规模的数据,可以考虑使用 zh_core_web_md 或 zh_core_web_lg。 SpaCy 提供这些不同版本的中文语言模型,以便用户根据其具体需求来灵活选择适合的模型。
代码
import warnings
warnings.filterwarnings("ignore")
import spacy
import pandas as pd
# 加载Spacy中文语言模型
nlp = spacy.load("zh_core_web_sm")
# 句子
df = pd.DataFrame({'id': ['a', 'b', 'c', 'd', 'e'],
'Sentences':["今天天气真好,阳光明媚。",
"关键字匹配是一种常见的文本处理任务。",
"计算机不认识人类语言,要转成词向量。",
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。",
"中文分词工具对文本处理很有帮助。",]})
# 选择要比较的目标句子
target_sentence = "关键字匹配和文本处理任务"
# 计算所有句子的相似度
similarity_scores = []
for sentence in df["Sentences"]:
doc1 = nlp(target_sentence)
doc2 = nlp(sentence)
similarity = doc1.similarity(doc2)
similarity_scores.append(similarity)
# 将相似度得分添加到数据框中
df["Similarity Score"] = similarity_scores
# 根据相似度得分降序排序,选择相似度最高的n个句子
n = 10 # 选择前n个最相似的句子
top_n_similar_sentences = df.sort_values(by="Similarity Score", ascending=False).head(n)
top_n_similar_sentences.set_index('id', inplace=True)
print('相似度排序:', top_n_similar_sentences.index.to_list())
# 打印DataFrame
top_n_similar_sentences
结果

Bert
概念
BERT(Bidirectional Encoder Representations from Transformers)是一种自然语言处理(NLP)模型,它是由Google于2018年发布的,基于Transformer架构的深度学习模型。BERT 是一种预训练模型,旨在学习单词和短语的上下文相关性,以便用于各种自然语言处理任务。
BERT 的主要特点包括:
-
双向性:BERT 强调了双向上下文建模,即在训练中同时考虑了一个单词的左侧和右侧上下文。这使得 BERT 能够更好地理解单词在不同上下文中的含义。
-
预训练:BERT 是通过大规模文本语料库的预训练来获得语言理解能力。它在大规模文本数据上进行了"无监督"预训练,学习了单词和句子的语义表示。
-
微调:经过预训练后,BERT 可以通过微调(fine-tuning)来适应特定的自然语言处理任务,如文本分类、命名实体识别、情感分析等。微调过程可以根据具体任务进行监督式训练。
BERT 已经在自然语言处理领域引起了革命性的变化,因为它在多项任务上取得了领先的性能。它的预训练能力使其能够捕捉单词和短语之间的复杂语义关系,从而减少了需要手动设计特征的需求。BERT 的模型结构和预训练权重也可以用于迁移学习,因此在小规模数据集上的任务也能受益于 BERT 的学习。
除了原始的 BERT 模型,还有各种基于 BERT 的变种,如RoBERTa、ALBERT、DistilBERT 等,它们通过不同的训练策略和架构改进来进一步提高性能。BERT 变种已经成为自然语言处理研究和应用的主要工具之一,广泛用于文本理解和分析任务。
模型
https://huggingface.co/
“huggingface” 是一个自然语言处理(NLP)领域的开源平台,提供了许多预训练的深度学习模型和工具,帮助研究人员和开发者在文本处理任务中更容易地使用和部署这些模型。“bert-base-chinese” 是 huggingface 发布的一个中文自然语言处理模型,基于谷歌研究团队开发的 BERT(Bidirectional Encoder Representations from Transformers)模型。
下面是对 “bert-base-chinese” 的一些重要信息:
-
BERT 模型:BERT 是一种预训练的神经网络模型,它在大规模文本数据上进行了训练,具有深度双向编码器结构。这使得 BERT 能够理解文本上下文和语境,从而在各种自然语言处理任务中表现出色。“bert-base-chinese” 版本是专门针对中文文本进行了预训练的 BERT 模型。
-
中文支持:“bert-base-chinese” 受益于其预训练数据集,可以理解和处理中文文本。这包括中文分词、句法结构、语义等多层次的文本信息。
-
适用性:“bert-base-chinese” 可以用于多种自然语言处理任务,包括文本分类、命名实体识别、情感分析、问答系统等。你可以使用这个模型来完成不同的中文文本处理任务,而不需要从头开始训练一个模型。
-
huggingface Transformers 库:huggingface 提供了 Transformers 库,其中包括了 “bert-base-chinese” 这样的预训练模型,以及用于加载、微调和评估这些模型的工具。这使得开发者可以轻松地集成和使用这些模型,加速他们的自然语言处理项目。
代码
import warnings
warnings.filterwarnings("ignore")
from transformers import AutoTokenizer, AutoModel
import pandas as pd
import torch
from sklearn.metrics.pairwise import cosine_similarity
# 加载BERT模型和分词器
model_name = "model/bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# 句子
df = pd.DataFrame({'id': ['a', 'b', 'c', 'd', 'e'],
'Sentences':["今天天气真好,阳光明媚。",
"关键字匹配是一种常见的文本处理任务。",
"计算机不认识人类语言,要转成词向量。",
"富强、民主、文明、和谐、自由、平等、公正、法治、爱国、敬业、诚信、友善。",
"中文分词工具对文本处理很有帮助。",]})
# 选择要比较的目标句子
target_sentence = "关键字匹配和文本处理任务"
# 矩计算DataFrame中所有句子的 embeddings
sentence_embeddings = []
for sentence in df["Sentences"]:
# 使用tokenizer(分词器)编码句子
sentence_tokens = tokenizer(sentence, return_tensors="pt", padding=True, truncation=True)
# Calculate the sentence embedding
sentence_embedding = model(**sentence_tokens).last_hidden_state.mean(dim=1)
sentence_embeddings.append(sentence_embedding)
# 计算target_embedding的 embedding
target_sentence_tokens = tokenizer(target_sentence, return_tensors="pt", padding=True, truncation=True)
target_embedding = model(**target_sentence_tokens).last_hidden_state.mean(dim=1)
# 计算所有句子的相似度
similarity_scores = []
for sentence_embedding in sentence_embeddings:
# Calculate cosine similarity
similarity = cosine_similarity(target_embedding.detach().numpy(), sentence_embedding.detach().numpy())[0][0]
similarity_scores.append(similarity)
# 将相似度得分添加到 DataFrame
df["Similarity Score"] = similarity_scores
# 根据相似度得分降序排序,选择相似度最高的n个句子
n = 10
top_n_similar_sentences = df.sort_values(by="Similarity Score", ascending=False).head(n)
top_n_similar_sentences.set_index('id', inplace=True)
print('相似度排序:', top_n_similar_sentences.index.to_list())
# Display the DataFrame
top_n_similar_sentences
结果

对比