【嵌入式学习-STM32F103-SPI】
SPI目录
- 爱上半导体篇
-
- 1、SS
- 2、SCK
- 3、MOSI(master output, slave Input)
- 4、MISO
- SPI读写93C46(验证4根线实现SPI通讯)
- 给存储器写入数据
- 读数据
- 总结
- 江科大篇
-
- 前言
- 实验现象
- SPI通信
- SPI的硬件规定、SP的软件规定
- 移位示意图(SPI核心)
-
- 模式0(常用)
- 模式1(对应移位模型)
- SPI完整的时序波形(基于W25Q64)
-
- 指定地址写·
- 指定地址读
- W25Q64
-
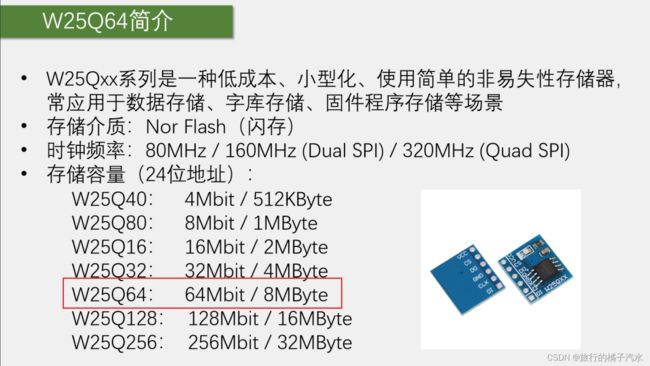
- W25Q64简介
- W25Q64硬件电路
- W25Q64的框图
-
- 划分空间
- 框图总结
- Flash操作注意事项
-
- 写入操作时
- 读取操作时
- W25Q64芯片手册
-
- 1、控制及状态寄存器
- 2、指令集
- 软件SPI读写W25Q64(代码)
-
- 程序的整体框架
- W25Q64
-
- 指令集
- 状态寄存器
- 页编程(page program)
- read data
- 1、验证掉电不丢失
- 2、验证flash擦除之后变为FF的特性
- 3、验证flash只能1写0,不能0写1的特性
- 4、验证写入数据不能跨页的现象
- main.c
- 添加通信层代码
- MySPI.c
- MySPI.h
- 添加驱动层代码
- W25Q64.c
- W25Q64.h
- W25Q64_Ins.h
- 跨页连续写入(可参考野火)
- 硬件SPI读写W25Q64(代码)
- SPI外设简介
-
- 野火SPI框图
-
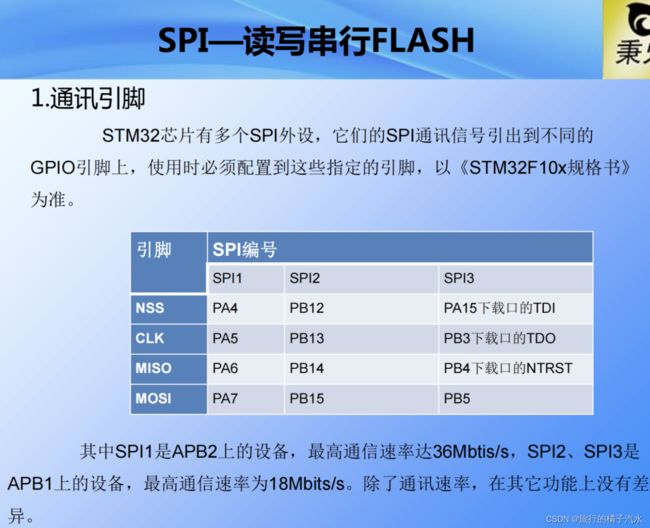
- 1、通讯引脚
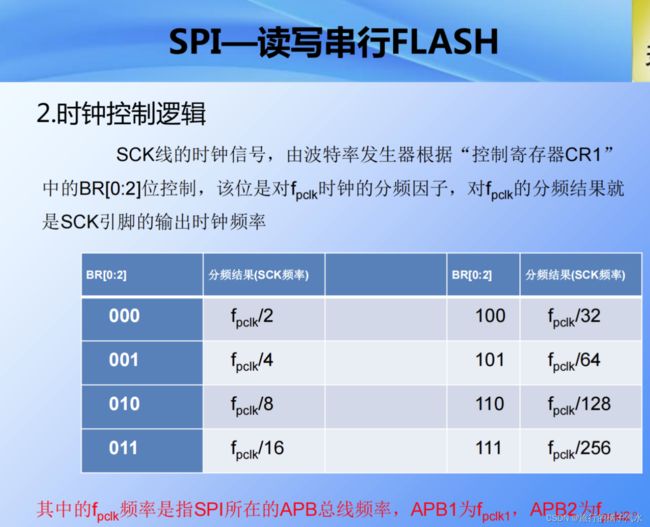
- 2、 时钟控制逻辑
- 3、 数据控制逻辑
- 4、整体控制逻辑
- SPI框图
- SPI简洁框图
- 运行控制部分
-
- 主模式全双工连续传输
-
- 整体流程:
-
- 发送流程
- 接收流程
- 非连续传输
-
- 不同SCK的频率,间隙的影响(拖后腿情况)
- 软件/硬件波形对比
- 手册
- 代码
-
- 初始化流程:
- 运行控制部分:产生交换字节的时序
- SPI相关的库函数:
- 实验效果
- MySPI.c
爱上半导体篇
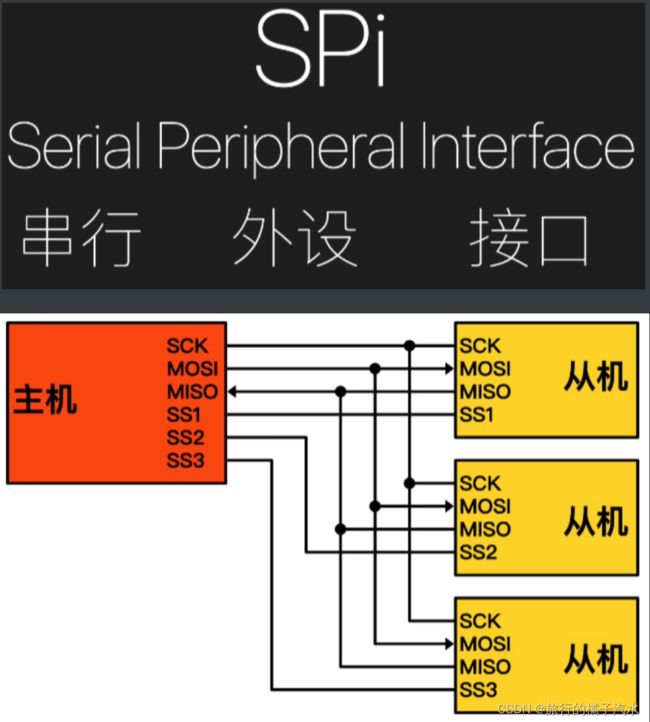
SPI由4根通讯线组成,SS、SCK、MOSI、MISO
1、SS
单片机通过给片选信号线高低电平来确定哪一个从机通讯,一般当这根线为低电平时,片选才有效。

2、SCK
时钟信号线,它的信号是这样的,由主设备产生。


3、MOSI(master output, slave Input)
发送信号线,主设备从这条线上输出数据,从设备通过这条线接收数据
4、MISO
接收信号线,主设备通过这根线接收数据

SPI读写93C46(验证4根线实现SPI通讯)

93C64是一个EEPROM存储器,等同于电脑的固态硬盘

它有1024位存储空间,等于124字节
怎么读写片内的1024位数据呢?
最直接的方法是,给每一位都外接一根线,显然不现实

因此,我们采用SPI的方式来读写片内1024位数据
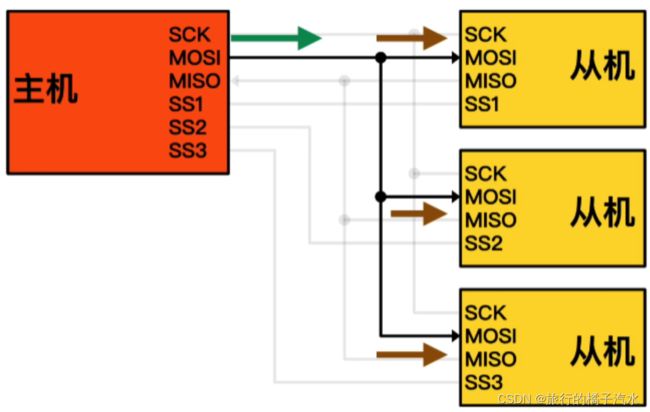
主设备先通过片选方式选择从设备
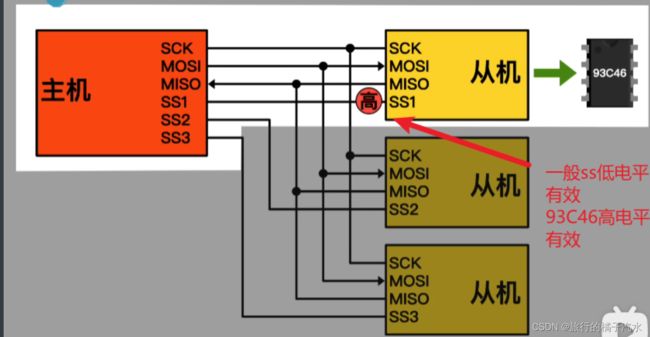
主机选择93C46作为从设备后
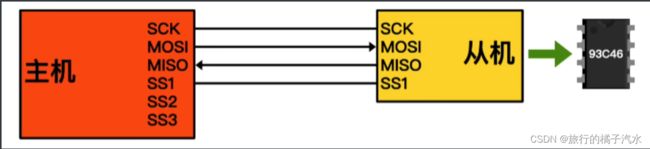
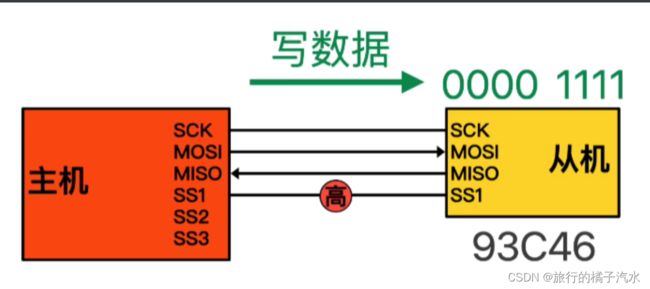
给存储器写入数据

此时需要参考存储器的数据手册指令表

首先发送起始位1,然后发送操作码01,再发送地址0000 0001,最后发送数据0000 1111
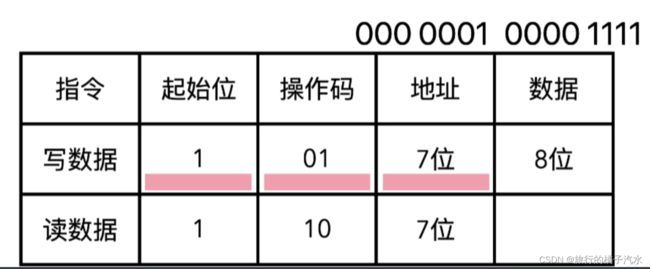
是不是只要把这些高低电平通过MOSI引脚发出去,数据就能成功写入呢?不是的。因为SPI是串行同步通讯
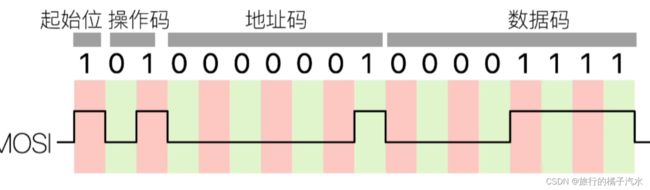
因此这个数据线要和时钟线两根线配合
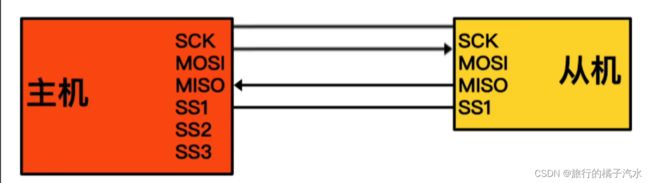
采用SPI的其中一种模式
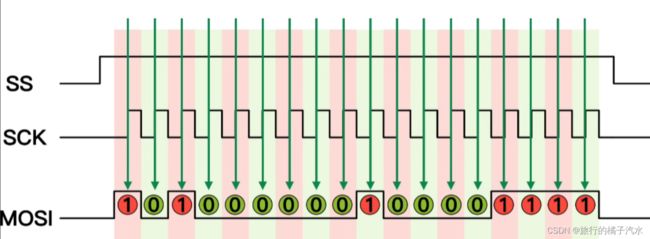
SPI总共有4种模式
时钟空闲为低电平
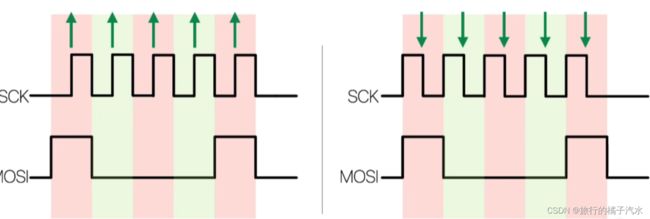
时钟空闲为高电平
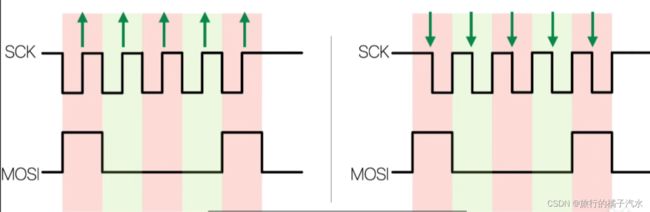
读数据

在读数据的时候也要给它先写数据(只针对这个存储器)

接收数据用的是时钟线和数据输入线

即使只接收不发送数据,主机也得继续给他提供时钟信号

总结

江科大篇
前言
W25Q64是一个Flash存储器芯片,它内部可以存储8M字节的数据,并且掉电不丢失。
I2C的缺点:
由于I2C开漏外加上拉电阻的电路结构,使得通信线高电平的驱动能力比较弱,这就会导致通信线由低电平变到高电平的时候,这个上升沿耗时比较长,这会限制IIC的最大通信速度。

SPI相对于I2C的优缺点:
1、SPI传输更快,它并没有严格规定最大传输速度,最大传输速度取决于芯片厂商的设计需求,如W25Q64存储器芯片,它的SPI时钟频率最大可达80MHz
2、简单粗暴,实现功能没I2C多,SPI比I2C简单
3、SPI的硬件开销比较大,通信线的个数比较多,并且通信过程中,经常会有资源浪费的现象。
实验现象

此处用4根SPI通信线,把W25Q64和stm32连接在一起,STM32操作引脚电平,实现SPI通信的时序,进而实现读写存储器芯片的目的。
OLED可看见测试程序的现象,第一行,显示的是ID号,MID是厂商ID,读出来是0xEF,DID是设备ID,读出来是0x4017,ID号均为固定数值。如果读取ID号和手册里一样,说明SPI通信基本没问题。
对于存储器类型芯片:写数据,读数据,对比是否正确。
第二行为写数据,4个字节
第三行为读数据,4个字节
若读出来和写入一样,说明读写存储器芯片没问题
更多类型测试:读写更多的数据、写入数据是否掉电不丢失
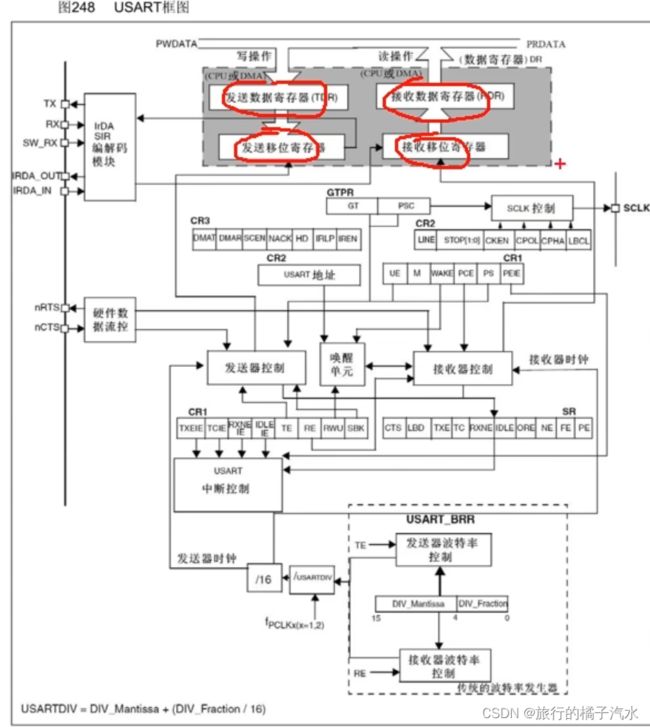
SPI通信
同步,肯定有时钟,因此,SCK引脚就是用来提供时钟信号的。数据位的输出和输入都是SCK的上升沿和下降沿进行的。这样数据位的收发时刻就可以明确的确定。
全双工:数据发送和数据接收单独各占一条线。MOSI和MISO就是分别用于发送和接收的两条线路。MOSI是主机输出从机输入,主机向从机发送数据的线路。MISO就是主机从从机接收数据的线路。
SPI:仅支持一主多从,不支持多主机。I2C太麻烦,直接开辟一条通讯线,专门用来指定我要跟哪个从机进行通信,即SS从机选择线。
I2C:实现一主多从的方式是在其实条件下,主机必须先发送一个字节进行寻址,用来指定我要跟哪个从机进行通信。所以I2C要涉及分配地址和寻址的问题。
SPI的硬件规定、SP的软件规定
主机:stm32
从机:存储器、显示屏、通信模块、传感器等

SPI所有通信线都是单端信号,它们的高低电平都是相对GND的电压差,所以单端信号,所有设备还需要共地。
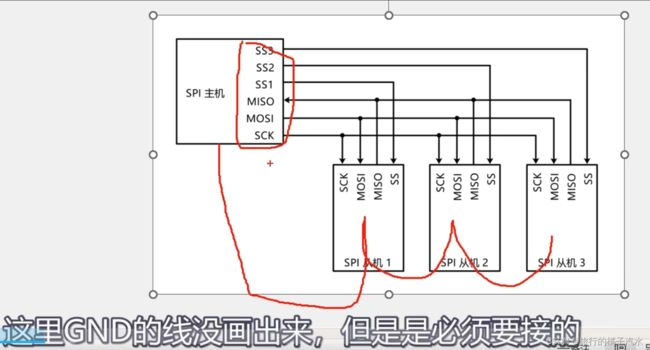
如果从机没有独立供电,主机需要额外引出电源正极VCC给从机供电。
SCK:时钟线完全由主机掌控,所以对于主机来说,时钟线为输出,对于所有从机来说,时钟线为输入。这样主机的同步时钟,就能送到各个从机。

MOSI:主机输出,从机输入
MISO:主机输入,从机输出
SS:低电平有效,主机想指定谁,就把对应的SS输出线置低电平。比如,主机初始化,所有SS线都置高电平(谁也不指定)
输出引脚:推挽输出,高低电平均有很强的驱动能力,这将使得SPI引脚信号的下降沿和上升沿非常迅速,不像I2C下降沿非常迅速,但是下降沿就非常缓慢。SPI信号变化快,自然它就能达到更高的传输速度。一般SPI信号都能轻松达到MHz的速度级别。I2C并不是不想使用更快的推挽输出,而是I2C要实现半双工,经常要切换输入输出,而且I2C又要实现多主机的时钟同步和总线仲裁,这些功能都不允许I2C使用推挽输出。(否则容易导致电源短路,I2C选择更多的功能,自然放弃更强的性能)
输入引脚:浮空或上拉输入
SPI有个缺点:如果三个从机始终都是推挽输出,主机一个是输入,势必会导致冲突。规定:当从机的SS引脚为高电平时,也就是从机未被选中,它的MISO引脚必须切换为高阻态,高阻态就相当于引脚断开,不输出任何电平。这样就可以防止一条线有多个输出,而导致的电平冲突的问题。在SS为低电平时,MISO才允许变为推挽输出。

移位示意图(SPI核心)

左边是SPI主机,里面有一个8位的移位寄存器,右边是SPI从机,里面也有一个8位的移位寄存器。移位寄存器有一个时钟输入端,因为SPI一般是高位先行,因此,每来一个时钟,移位寄存器都会向左进行移位。移位寄存器的时钟源是由主机提供的(这里叫做波特率发生器),它产生的时钟驱动主机的移位寄存器进行移位。同时这个时钟也通过SCK引脚进行输出,接到从机的移位寄存器里。
组成一个圈
主机移位寄存器左边移出去的数据,通过MOSI引脚输入到从机移位寄存器的右边。
从机移位寄存器左边移出去的数据,通过MISO引脚输入到主机移位寄存器的右边。

波特率发生器时钟的上升沿,所有移位寄存器向左移动一位,移出去的位放到引脚上,波特率发生器的下降沿,引脚上的位,采样输入到一位寄存器的最低位。
假设主机有数据10101010要发送到从机。同时从机有个数据01010101要发送到主机。那我们可以驱动时钟, 先产生一个上升沿,此时所有的位向左移动一位。那移出去的数据就被放到通信线上,相当于放到了输出数据寄存器。MOSI数据是1,所以MOSI的电平就是高电平,MISO数据是0,所以MISO的电平就是低电平。这是第一个时钟上升沿执行的结果。把主机和从机中移位寄存器的最高位,分别放到MOSI和MISO的通信线上,这就是数据的输出。


之后,时钟继续运行,上升沿之后,下一个边沿就是下降沿,在下降沿时,主机和从机都会进入数据采样输入,也就是MOSI的1会采样输入到从机的最低位,MISO的0,会采样输入到主机的最低位。以下是第一个时钟结束后的现象。

后面如此类推

下面一步到位。最终8个时钟之后,原来主机的10101010到从机,从机的01010101到主机。实现了主机和从机一个字节的数据交换

SPI的数据收发都是基于字节交换(基本单元)进行的。当主机需要发送一个字节,并且同时需要接收一个字节的时候,就可以执行字节交换的时序。完成发送同时接受的目的。
我们一般接收的时候,会同一发送0x00或0xFF去跟从机换数据。
SPI通信的基础是交换一个字节,从而可以实现①发送一个字节,②接收一个字节和③发送同时接收一个字节三种功能。
SPI时序基本单元

CPOL(Clock Polarity)时钟极性
CPHA(Clock Phase)时钟相位
以上两位组合后可有4种模式,功能一样
模式0(常用)
模式0的数据移出移入的时机会相位提前(上升沿读取数据,下降沿移出数据)

我们可以称作在第0个边沿移出数据,在第1个边沿移入数据(采样数据)

首先,SS下降沿开始通信,此刻SCK还没有变化,但是SCK一旦开始变化,就要移入数据,此时,趁SCK还没有变化,SS下降沿时就要立刻触发移位输出,所以MISO和MOSI的输出是对齐ss的下降沿的。

CPHA决定是第几个边沿采样,并不能单独决定是上升沿或者下降沿。
模式0和模式3都是SCK上升沿采样
模式1和模式2都是SCK下降沿采样
模式1(对应移位模型)

SS,从机选择,在通信开始时,SS为高电平,在通信过程中,SS始终保持低电平,通信结束,SS恢复高电平。
以下是主机输入,从机输出(此处MISO用中间的线表示高阻态)
SS下降沿后,从机的MISO被允许开启输出,SS上升沿后,从机MISO必须置回高阻态。

以下是移位传输的操作
因为CPHA=1,SCK第一个边沿移出数据,主机和从机同时移出数据,主机通过MOSI移出最高位,此时MOSI的电平表示主机要发送数据的B7,从机通过MISO移出最高位,此时MISO表示从机要发送数据的B7。
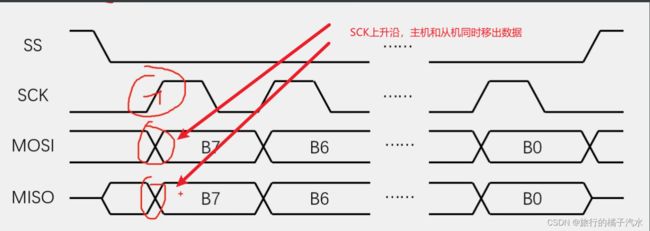
然后时钟运行,产生下降沿,此时主机和从机同时移入数据,也就是进行数据采样,这里主机移出的B7进入从机移位寄存器的最低位,从机移出的B7进入主机移位寄存器的最低位。这样一个时钟脉冲产生完毕,一个数据位传输完毕。

上升沿,主机和从机同时输出当前移位寄存器的最高位,第二次的最高位就是原始数据的B6,然后下降沿,主机和从机移入数据,B6传输完成。之后时钟继续运行,数据依次移出,移入,移出,移入…最后一个下降沿,数据B0传输完成。自此,主机和从机就完成了一个字节的数据交换。如果主机只想交换一个字节,这时SS可置高电平,结束通信。在SS的上升沿,MOSI还可以再变化一次,将MOSI置一个默认的高电平或低电平,(也可以不管)SPI没有硬性规定MOSI的默认电平,然后MISO,从机必须置回高阻态。此时主机的MISO为上拉输入,那MISO引脚的电平就是默认的高电平,如果主机MISO为浮空输入,那MISO电平不确定。
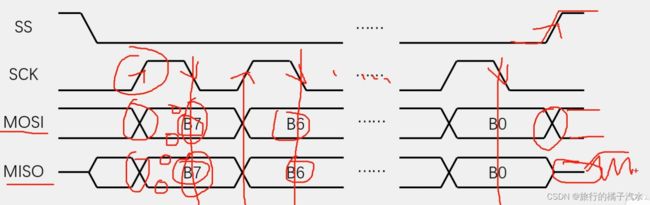
如果主机还想继续交换字节呢
此时,主机不必把SS置回高电平,直接重复交换一个字节的时序。

SPI完整的时序波形(基于W25Q64)
I2C中,有效数据流第一个字节是寄存器地址,之后依次是读写的数据,使用的是读写寄存器的模型。
SPI中,通常采用的是指令码加读写数据的模型。
SPI起始后,第一个交换发送给从机的数据,一般叫做指令码,在从机中,对应会定义一个指令集,当我们需要发送什么时,就可以在起始后第一个字节发送指令集里面的数据。
在W25Q64里,0X06代表的是写使能,在这里使用SPI模式0,在空闲状态,SS为高电平,SCK为低电平,MOSI和MISO电平没有严格规定。然后,SS产生下降沿,时序开始,在这个下降沿时刻,MOSI和MISO就要开始变换数据。
SCK低电平是数据变化的时期,高电平是读取数据的时期
以下:主机用0x06换来从机0xFF,但是实际上从机并没有输出,0XFF是默认高电平。 那整个时序的功能就是发送指令,指令码是0x06,从机比对后事先定义好的指令集,发现0x06是写使能的指令,那从机就会控制硬件进行写使能。这样一个指令从发送到执行就完成了。
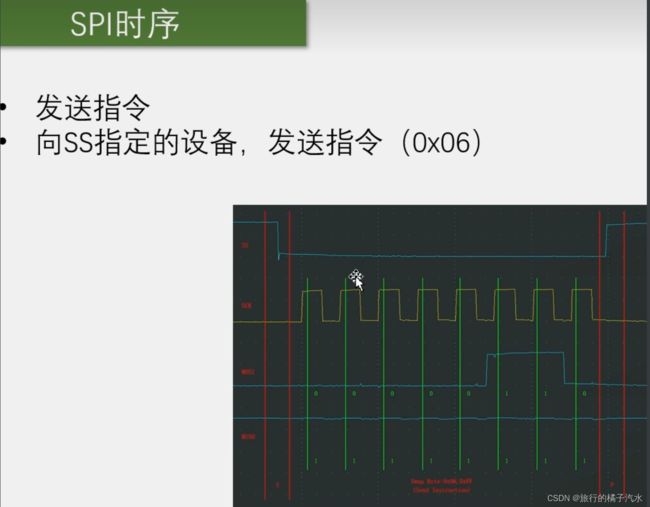
发送单字节指令时序

指定地址写·
在0x123456地址下,写入0x55这个数据。最后如果只想写入一个数据,就可以SS置高电平,结束通信。
由于SPI没有应答机制,交换一个字节后就立刻交换下一个字节即可。
W25Q64有8M字节的存储空间,因此指定地址是24位,分三个字节传输。
过程
首先,SS下降沿开始时序,这里MOSI空闲时是高电平,在下降沿后,SCK第一个时钟之前,可以看到MOSI变换数据,由高电平变为低电平,然后SCK上升沿,数据采样输入,对于SCK来说,下降沿变换数据,上升沿采样数据,8个时钟之后,一个字节交换完成,此处用0x02换来了0xFF,其中发送的0x02是一条指令,代表这是一个写数据的时序,不需要看0xFF,由于后续还要继续交换字节,接着是第二个字节,因此在第一个字节最后的一个下降沿,把下一个字节的最高位放到MOSI上,同样一个流程,第二个字节用0x12换来了0xFF。
根据W25Q64芯片规定,写指令之后的字节定义为地址高位,所以0x12表示发送地址的23~16位。依次类推发送24位地址完毕,从机收到的24位地址是0x123456。3位地址结束后,就要发送写入指定地址的内容,继续调用交换一个字节,发送数据0x55.这表示在0x123456地址下,写入0x55这个数据。


指定地址读
指定地址读:向SS指定的设备,先发送读指令,这里芯片定义,0x03为读指令。
主机发送指令0x03,代表我要读取数据,然后主机依次交换3个字节,分别是0x12、0x34、0x56组合到一起就是0x123456,代表24位地址。指定地址后,我们要开始接收数据。

指定地址下的数据是0x55,主机实现指定地址读一个字节的目的。如果继续接收,那么从机内部地址指针自动加1,从机就会继续把指定地址下一个位置的数据发送到主机。这样依次进行就可以实现指定地址接收多个字节的目的。最后,数据传输完毕,SS置回高电平,时序结束。

细节:由于MISO是硬件控制的波形,所以它的数据变化,都可以紧贴时钟下降沿。MISO数据的最高位,实际上是在上一个字节,最后一个下降沿提前发生的,因为这是SPI模式0,所以数据变化都要提前半个周期变化。

W25Q64
W25Q64简介
存储器分为易失性存储器和非易失性存储器(存储的数据是否是掉电不丢失)
易失性存储器一般包括SRAM、DRAM等
非易失性存储器一般包括E2PROM、Flash等
数据存储:STM32有些参数或采集的数据想要掉电不丢失保存
字库存储:OLED显示屏或者LCD液晶屏
固件程序存储:直接把程序下载到外挂芯片里,需要执行程序时,直接读取外挂芯片的程序文件来执行
本节只是用最简单的数据存储功能
24位地址最多能分配多少个字节呢?

相当于16M,因此24位地址的最大寻址空间是16MB
W25Q64硬件电路

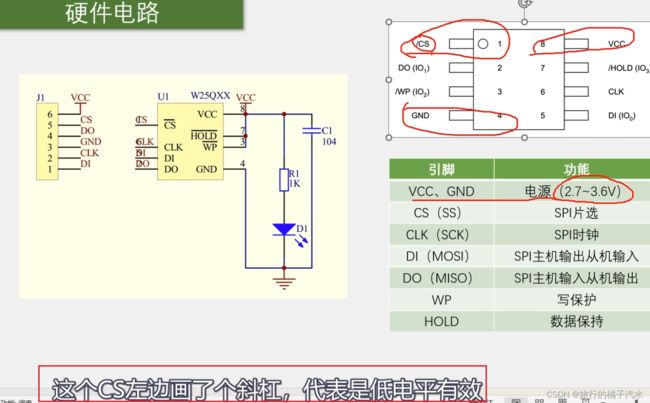
HOLD,数据保持,低电平有效
WP,写保护 ,配合内部的寄存器配置,可以实现硬件的写保护,写保护低电平有效,WP接低电平,保护住,不让写,WP接高电平,不保护,可以写。
接线表示
HOLD和WP接到VCC,由于它们低电平有效,因此我们都不用。C1直接接到VCC和GND,显然是一个电源滤波,R1和D1直接接到VCC和GND,显然是一个电源指示灯,通电就亮。
总体:VCC和GND接3.3V电源,SPI通信线直接接到STM32的SPI通信引脚。HOLD和WP需要用的话,就接到STM32的GPIO,不需要用就直接接VCC。
J1,就是一个6脚的排针

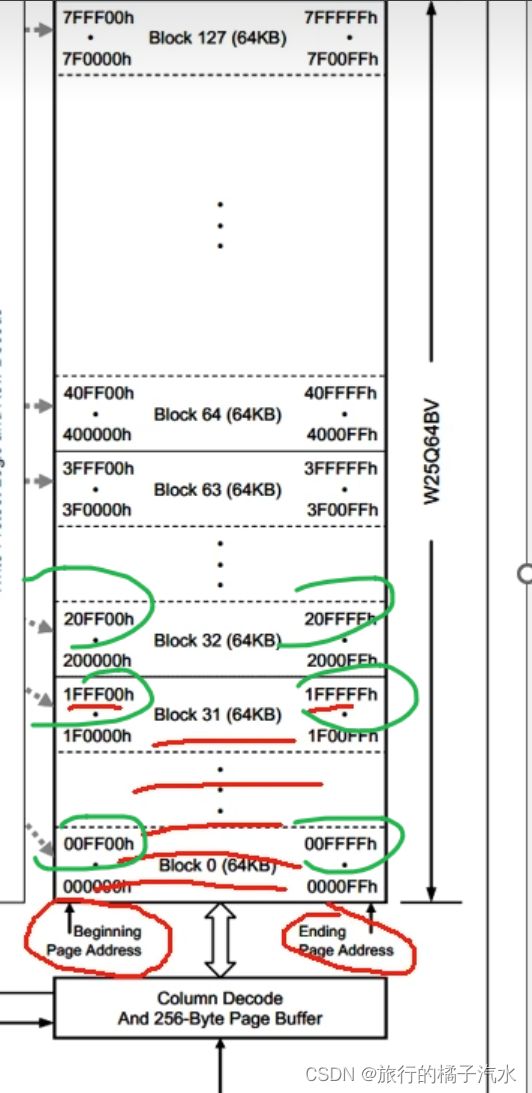
W25Q64的框图

划分空间
首先,整个矩形空间里,是所有的存储器,存储器以字节为单位,每个字节都有唯一的地址,W25Q64的地址宽度是24位,3个字节,所以看到左下角,它的地址是00 00 00h,h代表16进制。之后的空间地址依次自增,指导最后的一个字节地址是7F FF FF h。为什么不是FF开头,因为24位地址,最大寻址范围是16MB。W25Q64只有8MB,只用到一半空间。

在整个空间里,我们以64kb为一个基本单元,把它划分为若干的块,有block1,2,3…

分的块数:8Mb / 64kb =( 8Mb / 1024 )/ 64kb = 128块
块内地址变化规律:在每一块内,它的地址变化范围就是低位的2个字节,每个块的起始地址是xx 00 00 结束是xx FF FF
块内地址:
起始:00 00 00 结束:00 FF FF
起始:1F 00 00 结束:1F FF FF
….
起始:7F 00 00 结束:7F FF FF
对每一块进行更细的划分,分为多个扇区Sector,在每个扇区以4kb为一个单元进行划分,16份
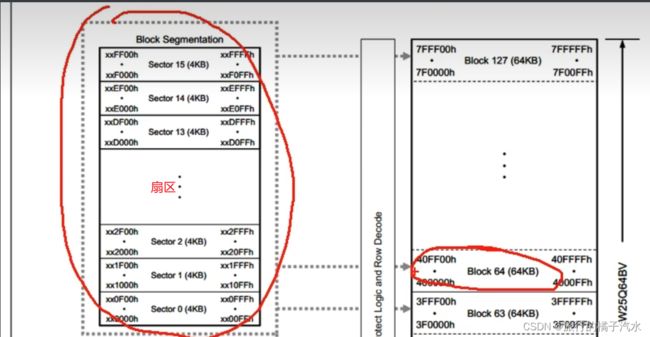
页是直接对整个存储空间划分的,也可以看作在扇区里再进行划分,其大小是256个字节,一个Sector可分得16页 4KB=4096bite

在一页中,地址变化范围是 xx xx 00 到xx xx FF
左下角是SPI控制逻辑,也是芯片内部进行地址锁存、数据读写等操作,都可以由控制逻辑来自动完成。控制逻辑就是整个芯片的管理员。而控制逻辑的左边就是通信引脚,这些引脚和主控芯片相连。

主控芯片通过SPI协议,把指令和数据发给控制逻辑,控制逻辑就会自动去操作内部电路,来完成我们想要的功能。
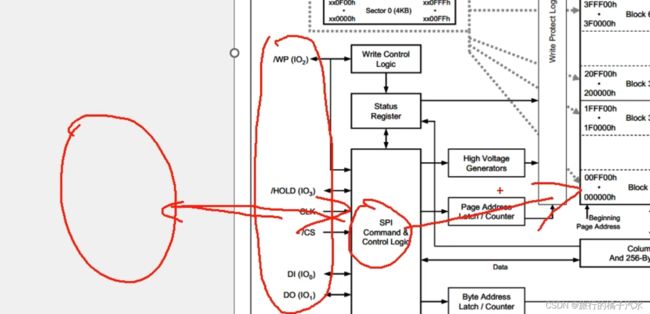
控制逻辑上有状态寄存器,状态寄存器(status Register)比较重要,比如芯片是否处于忙状态,是否写使能,是否写保护。
写控制逻辑(Write Control Logic)与WP配合引脚实现硬件写保护。
掉电不丢失的存储器,一般都需要一个高压源。 ,刻骨铭心的变化
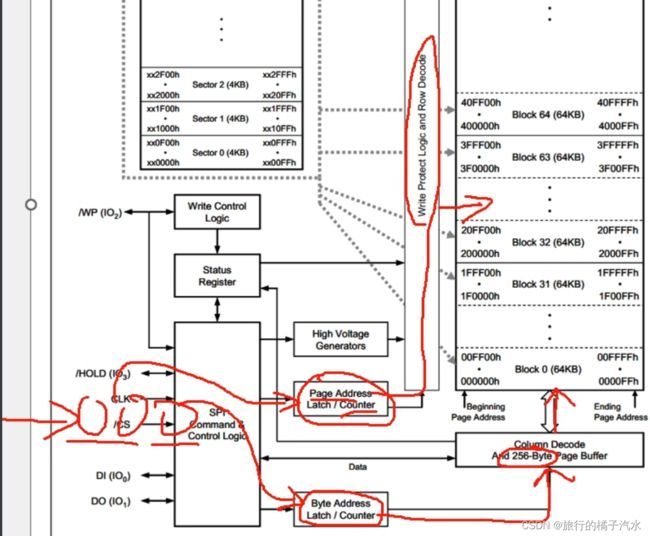
页地址锁存/计数器和字节地址锁存/计数器来指定地址的。
通过SPI总共发过来三个字节的地址,我们发的3个字节地址,前两个字节会进到页地址锁存计数器里,最后一个字节,会进到这个字节地址锁存计数器里。

然后页地址通过写保护和行解码来选择我们需要操作哪一页。字节地址,通过这个列解码和256字节页缓存来进行指定字节的读写操作。又因为地址锁存都是有一个计数器,所以地址指针,在读写之后,可以自动加1.这样 就可以很容易实现,从指定地址开始,连续读写多个字节的目的。
我们写入数据会先放到==缓存区(RAM,速度快)==里,然后在时序结束后,芯片再将缓存区的数据复制到对应的Flash里,进行永久保存.

为什么要用缓存区而不直接发送到Flash里呢
因为SPI写入的频率非常高,而Flash写入,由于需要掉电不丢失,留下刻骨铭心的印象,它就比较慢。
所以这个芯片的设计思路是,你写入的数据,我先放在页缓存区里存着,因为缓存区是RAM,所以它的速度非常快,可以更上SPI总线的速度。但缓存区只有256个字节,所以写入时序有限制条件。(写入的一个时序,连续写入的数据量,不能超过256个字节),等你写完后,芯片再慢慢从缓存区转移到Flash存储器里。
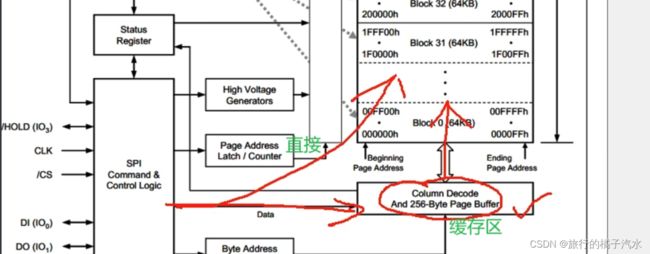
而从缓存区转到Flash里,需要一定的时间。
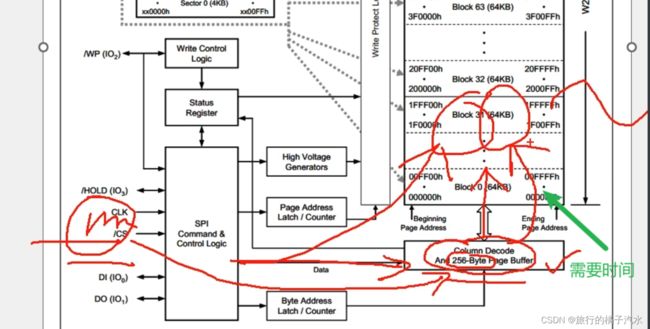
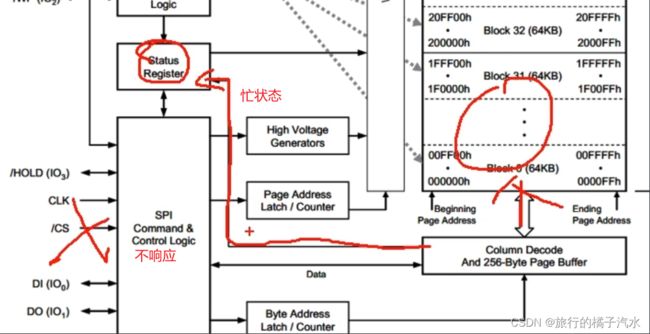
所以在写入时序结束后,芯片会进入一段忙的状态,他这里就会有一条线,通往状态寄存器,给状态寄存器的BUSY位置1.此时,在忙的时候,芯片就不会响应新的读写时序了。
框图总结
一、整个Flash的空间划分,会划分为块、扇区和页(block->sector->page)
二、SPI控制逻辑,它就是整个芯片的管理员,执行指令、读写数据都靠它
三、状态寄存器,它和忙状态、写使能、写保护等功能有关
四、256字节的页缓存,它会对一次性写入的数据量产生限制
Flash操作注意事项

写入操作时
1、写入操作前,必须先进行写使能–>手机先解锁再使用,防止误触
2、每个数据位只能由1改写为0,不能由0改写为1->Flash并没有像RAM那样,直接完全覆盖改写的能力,比如在某个字节的存储单元里,存储了0XAA数据,对应的二进制位就是1010 1010,如果我直接再次在这个存储单元写入一个新的数据,比如我再次写入一个0x55,那写完后,这个从存储单元里存的是0x55吗?不是,因为0x55的二进制 0101 0101,当它要覆盖原来的1010 1010时,就会收到该条规定的约束,每个数据位只能由1改写为0,不能由0改写为1
写入0x55,实际存储的新数据实际为0x00
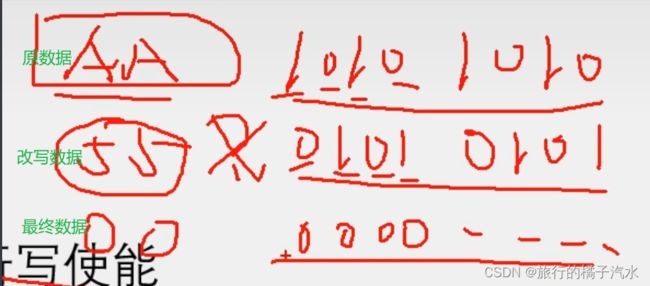
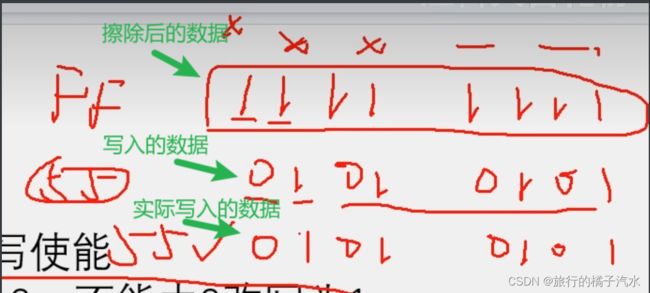
3、为了弥补2,需要再写入数据前必须先擦除,擦除后,所有数据位变为1->1111 1111
FLASH中1的数据拥有单向改为0的权利,一旦改写为0后,就不能反悔改写成1,要想反悔,就必须得先擦除,所有的位先统一都变成1,然后再重新来过。
如果有时候你读取Flash会发现数据全是FF,那说明这一段有可能是擦除之后还没有写入数据的空白空间在Flash中,FF代表的是空白,而不是00
4、(写入前要进行擦除) 擦除必须按最小擦除单元进行(可选择整个芯片擦除或按块擦除或按扇区擦除)——>成本
要想不丢失数据,需要把数据先读出来,再把原本数据扇区擦掉,改写完读出来的数据后,在把数据全部写回去。

5、连续写入多个字节时,最多写入一页的数据,超过页尾位置的数据,会回到页首覆盖写入
页缓存区只有256字节,为什么有缓存区呢,因为Flash写入太慢,跟不上SPI的频率,所以写入的数据会先放在RAM暂存,等时序结束后,芯片再慢慢把数据写入到Flash。页缓存区是与flash的页对应的。
6、写入操作结束后,芯片进入忙状态,不响应新的读写操作
写入操作都是对缓存区进行的,等时序结束后,芯片还要搬砖一段时间

所以每次写入操作后,都有一段时间的忙状态,在这个状态下,我们不要进行读写操作,否则芯片不会响应。要想知道芯片什么时候结束忙状态,我们可以使用读取状态寄存器的指令,看一下状态寄存器的BUSY位是否为1.Busy为0时我们就可以对芯片进行操作。

读取操作时
直接调用读取时序,无需使能,无需额外操作,没有页的限制,读取操作结束后不会进入忙状态,但不能在忙状态时读取。
W25Q64芯片手册
1、控制及状态寄存器
状态寄存器1和2,1比较重要,而1有两位比较重要,包括BUSY和Write Enable Latch(WEL)

2、指令集


第一个时写使能,指令码是06,要想发送写使能指令,利用SPI来操作。首先,起始,然后,交换一个字节,第一个字节是发送方向,发送0x06指令,该指令后续无需跟数据,因此直接停止。
第二个读状态寄存器1,首先起始,交换字节发送指令码05,这是读指令,所以后面有数据,需要继续交换字节,通过交换读取一个字节,为(S7-S0),其中S0是busy位,s1是wel位。主要用来查看忙状态
第三个页编程,写数据,只是它有256字节页大小的限制。操作流程是,起始,交换字节发送指令02,然后继续交换发送地址的23-16位、15-8位、7-0位。这三个字节用来指定地址,再之后写入数据(D7-D0),该数据写入到刚才指定的地址下。如果继续交换写入,后续的字节就从起始地址开始依次存储。
第四个扇区擦除, 使用方法是,起始,交换字节发送指令20,之后再交换发送3个字节的地址,终止。发送之后,这个指定地址所在的扇区就会被整个擦除。这个地址是精确到某个字节的,一般会把这个地址对齐到扇区的首地址,这样表示擦除一整个扇区。
第五个读ID指令,JEDEC ID,操作流程是起始,交换发送9F,随后连续交换读取3个字节,终止。其中第一个字节是厂商ID,后两个字节是设备ID。
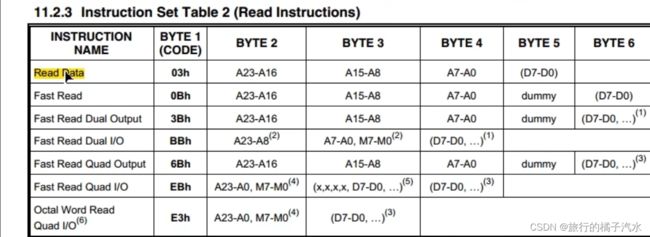
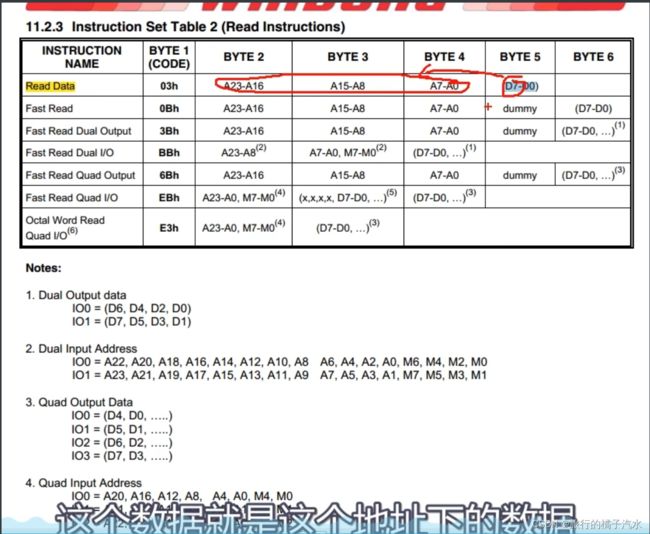
最后一个指令读取数据。操作流程是,起始,交换发送指令03,之后交换发送3个字节的地址,再之后就可以交换读取数据。如果继续交换数据,后面数据就从指定地址开始依次读存储的数据。读取没有页的限制。
软件SPI读写W25Q64(代码)
程序的整体框架

一、SPI模块(通信层)
该模块主要包含通信引脚封装、初始化以及SPI通信的3个拼图(起始、终止和交换一个字节)
二、W25Q64驱动层(基于SPI层)
在这个模块里,调用底层SPI的拼图,来拼接各种指令和功能的完整时序,比如写使能、擦除、页编程、读数据等。我们称作W25Q64的硬件驱动层
三、在主函数里调用驱动层的函数,来完成我们想要实现的功能。
模式0
SS下降沿和数据移出是同时发生的,包括后面SCK下降沿和数据移出也是同时发生的,但这不代表我们程序上要同时执行两条代码,它们是有顺序的,是先SS下降沿或SCK下降沿,再数据移出,下降沿是数据移出动作的触发条件。对于硬件SPI来说,由于使用了硬件的移位寄存器电路,这两个动作几乎同时发生的,对于软件SPI来说,由于程序是一条条执行的,不可能同时完成两个动作,所以软件SPI,直接看成先后执行的逻辑。
即先SS下降沿,再移出数据,再SCK上升沿,再移入数据,再SCK下降沿,再移出数据。。。
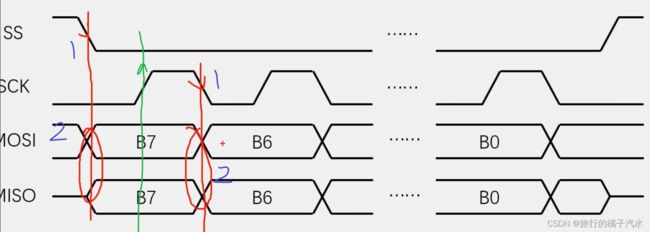
程序中用0x80依次右移一位,取出ByteSend的每一位,或者给ByteReceive的每一位置1
0x80 >> i的作用是用来挑出数据的某一位或者某几位,即用来屏蔽其他无关位,这种类型的数据称为掩码。
W25Q64
主要参考指令集表格
demo1:先把ID号读出来,看看对不对,依次验证底层的SPI协议写的有没有问题
起始,先交换发送指令9F,随后连续交换接收3个字节,停止
厂商ID+设备ID(高8位,存储器类型,低8位,表示容量)
//有两个返回值,我们使用指针来实现多返回值
void W25Q64_ReadID(uint8_t *MID, uint16_t *DID)
{
MySPI_Start();
MySPI_SwapByte(W25Q64_JEDEC_ID); //发送的是读ID号的指令,从机收到读ID号的指令,他就会在下一次交换把ID号返回给主机
//通信过程,不同时间调用相同的函数,它的意义是不一样的
*MID = MySPI_SwapByte(W25Q64_DUMMY_BYTE); //参数我要给从机一个东西,此时我的目的时接收,所以给它抛的东西没有意义,返回值就是厂商ID号
*DID = MySPI_SwapByte(W25Q64_DUMMY_BYTE); //收到设备ID的高8位
*DID <<= 8; //把第一次读到的数据运到DID的高8位
*DID |= MySPI_SwapByte(W25Q64_DUMMY_BYTE); //收到设备ID的低8位(第二次读取需要变为|=,不能写等于,否则高8位就置0)
MySPI_Stop(); //停止时序
}
指令集
实现指令集里面标黄色的指令


状态寄存器
上图:起始之后,先发送指令码,再接收状态寄存器1或2,之后如果时序不停,还要继续接收的话,这个芯片就会把最新的状态寄存器发过来。the status register can be read continuously
如果不忙,函数很快退出,如果忙会卡在函数里面,等不忙了,就会退出。
//等待busy为0
void W25Q64_WaitBusy(void)
{
uint32_t Timeout;
MySPI_Start();
//发送指令码,读状态寄存器1
MySPI_SwapByte(W25Q64_READ_STATUS_REGISTER_1);
Timeout = 100000;
//接收状态寄存器(主要用途是判断芯片是不是忙状态),等待busy为0状态
//发送dumy_byte,接收数据,返回值是状态寄存器1,与上0x01,用掩码取出最低位,如果它==0x01,就是busy为1,此时进入while循环等待,否则为0
//利用连续读出状态寄存器,实现等待BUSY的功能
while ((MySPI_SwapByte(W25Q64_DUMMY_BYTE) & 0x01) == 0x01)
{
Timeout --;
if (Timeout == 0)
{
break;
}
}
//终止时序
MySPI_Stop();
}
页编程(page program)
![]()

总之,dummy表示按规定交换一个无用的数据
read data

流程是,交换发送指令03,再发送3个字节地址,随后转入接收数据,一次接收数据。
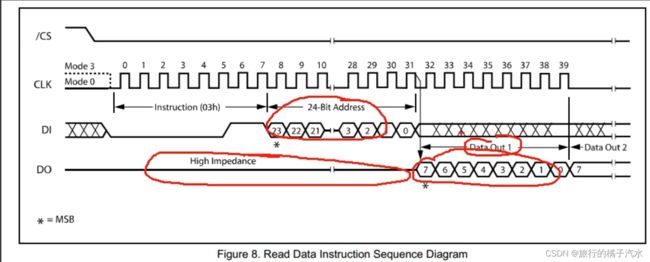
DO一开始一直是高阻态,在发送完3个字节地址后,DO开启输出,此时主机就可以接收有用数据DataOut1了,在接收时,DI的波形是XXX,表示这个数据无所谓(抛砖引玉),之后如果你连续接收多次,那就是DataOut2、DataOut3等,读取没有256字节限制,可以跨页,一直连续读。
//读数据的数组是输出参数,读到的参数通过数组输出
//读取数据没有页限制,所以读取count范围非常大
void W25Q64_ReadData(uint32_t Address, uint8_t *DataArray, uint32_t Count)
{
uint32_t i;
MySPI_Start();
MySPI_SwapByte(W25Q64_READ_DATA);
MySPI_SwapByte(Address >> 16);
MySPI_SwapByte(Address >> 8);
MySPI_SwapByte(Address);
//开始读数据(抛砖引玉)
for (i = 0; i < Count; i ++)
{
//发送FF,置换为有用的数据
//在每次调用交换读取之后,存储器芯片内部地址指针自动自增,依次返回指定地址开始,往后线性区域地址下的数据
DataArray[i] = MySPI_SwapByte(W25Q64_DUMMY_BYTE);
}
//结束
MySPI_Stop();
}
1、验证掉电不丢失
擦除和写入代码注释掉
(断电重启仍未A1 B2 C3 D4)

2、验证flash擦除之后变为FF的特性
只擦除不写入

读取的数据全是FF,说明Flash擦除之后变为FF

3、验证flash只能1写0,不能0写1的特性
有擦除的写入,写入什么读出什么不会出错
而下图为不擦除,直接改写

由下图改写为下下图
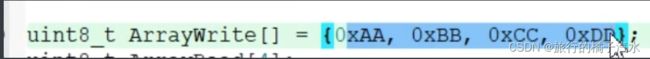
![]()
最终结果是写入 55 66 77 88 读出的数据是 00 22 44 88

AA直接改写为55,为什么编程00呢?
如果不执行擦除来进行写入,那么读出来的数据=原始数据&写入的数据
因此,写入数据前必须擦除,否则,直接覆盖改写的数据,大概率是错的。
4、验证写入数据不能跨页的现象
页地址的范围是xxxx00到xxxxFF,前面四位是页地址,后面两位是页内地址,赋值最后两位FF,即一页的最后一个地址
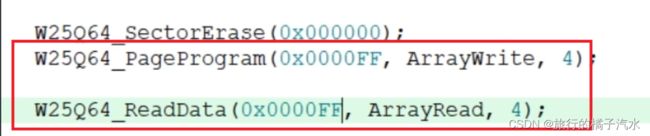
写入 55 66 77 88
读出 55 FF FF FF
55写入地址0FF,后面的66并没有跨页到下一个地址100

而是返回第一页的页首00.存储器不能跨页写入
读取能跨页,第二页是擦除了的,并没有写入,所以默认为FF
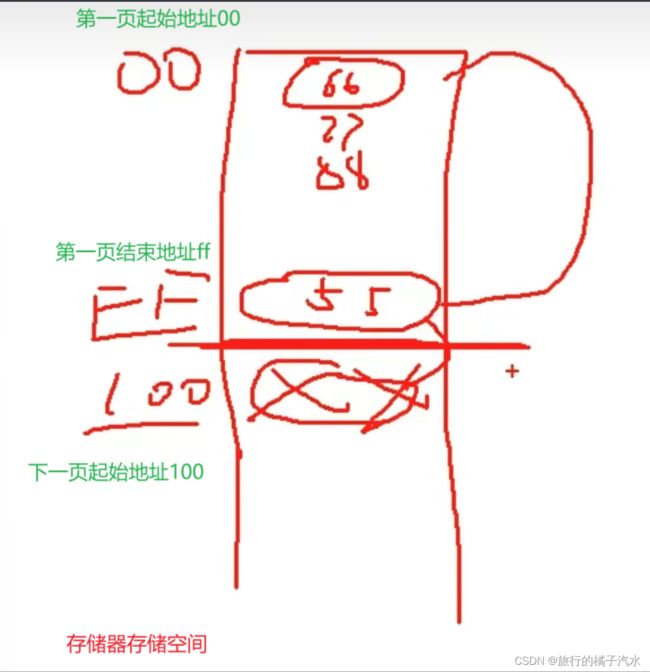
将读取改到第一页的起始位置00,之前写入的后3个字节是不是在第一页的起始位置

果然,这三个字节是在第一页这里

main.c
#include "stm32f10x.h" // Device header
#include "Delay.h"
#include "OLED.h"
#include "W25Q64.h"
uint8_t MID;
uint16_t DID;
uint8_t ArrayWrite[] = {0x01, 0x02, 0x03, 0x04};
uint8_t ArrayRead[4];
int main(void)
{
OLED_Init();
W25Q64_Init();
OLED_ShowString(1, 1, "MID: DID:");
OLED_ShowString(2, 1, "W:");
OLED_ShowString(3, 1, "R:");
//获取ID号,检测是否通信成功
W25Q64_ReadID(&MID, &DID);
OLED_ShowHexNum(1, 5, MID, 2);
OLED_ShowHexNum(1, 12, DID, 4);
//擦除扇区
W25Q64_SectorErase(0x000000);
//页编程写入
W25Q64_PageProgram(0x000000, ArrayWrite, 4);
//读取数据
W25Q64_ReadData(0x000000, ArrayRead, 4);
OLED_ShowHexNum(2, 3, ArrayWrite[0], 2);
OLED_ShowHexNum(2, 6, ArrayWrite[1], 2);
OLED_ShowHexNum(2, 9, ArrayWrite[2], 2);
OLED_ShowHexNum(2, 12, ArrayWrite[3], 2);
OLED_ShowHexNum(3, 3, ArrayRead[0], 2);
OLED_ShowHexNum(3, 6, ArrayRead[1], 2);
OLED_ShowHexNum(3, 9, ArrayRead[2], 2);
OLED_ShowHexNum(3, 12, ArrayRead[3], 2);
while (1)
{
}
}
添加通信层代码
MySPI.c
#include "stm32f10x.h" // Device header
//封装置高低电平的函数
//写SS引脚,CS片选信号A4,写数据位
void MySPI_W_SS(uint8_t BitValue)
{
GPIO_WriteBit(GPIOA, GPIO_Pin_4, (BitAction)BitValue);
}
//写SCK引脚,时钟同步信号A5,写数据位
void MySPI_W_SCK(uint8_t BitValue)
{
GPIO_WriteBit(GPIOA, GPIO_Pin_5, (BitAction)BitValue);
}
//写MOSI引脚,A7,写数据位
void MySPI_W_MOSI(uint8_t BitValue)
{
GPIO_WriteBit(GPIOA, GPIO_Pin_7, (BitAction)BitValue);
}
//读MISO引脚,读数据位
uint8_t MySPI_R_MISO(void)
{
return GPIO_ReadInputDataBit(GPIOA, GPIO_Pin_6);
}
// SPI初始化
//输出引脚配置为推挽输出,输入引脚配置为浮空或上拉输入,对于主机来说,时钟、主机输出和片选都是输出引脚
//主机输入是输入引脚
void MySPI_Init(void)
{
//引脚初始化
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE);
GPIO_InitTypeDef GPIO_InitStructure;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP;//推挽输出
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_4 | GPIO_Pin_5 | GPIO_Pin_7;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IPU; //上拉输入
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
//初始化后需要置初始化后引脚的默认电平
MySPI_W_SS(1); //片选信号,高电平,默认不选中从机
MySPI_W_SCK(0); //信号线,计划使用SPI模式0,因此默认低电平
//MOSI无要求
//MISO输入引脚,无需输出电平
}
/*SPI3个时序基本单元*/
//起始信号,CS信号置低电平
void MySPI_Start(void)
{
MySPI_W_SS(0);
}
//终止信号,CS信号置高电平
void MySPI_Stop(void)
{
MySPI_W_SS(1);
}
//前提是SS为下降沿
//交换一个字节(SPI核心部分),W25Q64支持模式0和模式3,一般选择模式0
uint8_t MySPI_SwapByte(uint8_t ByteSend) //ByteSend是传进来的参数,要通过交换一个字节的时序发送出去,返回值是ByteReceive是通过交换一个字节接收到的数据
{
//用于接收数据
uint8_t i, ByteReceive = 0x00;
//在ss下降沿后,开始交换字节
//实现时序
for (i = 0; i < 8; i ++)
{
//主机和从机同时移出数据,就是主机移出数据最高位放到MOSI上,从机移出它的数据最高位放到MISO上,(MISO数据变化是从机的事情,不归主机管)
//写MOSI,发送ByteSend由高到低位-->(放数据位)
MySPI_W_MOSI(ByteSend & (0x80 >> i)); //发送的数据是BySend的最高位
//SCK上升沿,主机和从机同时移入数据,从机会自动把B7读走,从机移入不归我们管,主机只需要读取MISO的数据即可
//SCK上升沿时,从机会自动把MOSI的数据读走
MySPI_W_SCK(1);
//读MISO,主机的任务就是把从机刚才放到MISO的数据读进来
if (MySPI_R_MISO() == 1){ByteReceive |= (0x80 >> i);} //读到的数据为接收的最高位
//SCK产生下降沿,主机和从机移出下一位
MySPI_W_SCK(0);
//通过循环,依次写入和读入B6、B5...B0
}
//返回接收到的数据
return ByteReceive;
}
/*软件的交换字节总体流程*/
/*
先SS下降沿
再移出数据
再SCK上升沿
再移入数据
再SCK下降沿
再移入数据
*/
以下方法更符合移位框图
//uint8_t MySPI_SwapByte(uint8_t ByteSend) //ByteSend是传进来的参数,要通过交换一个字节的时序发送出去,返回值是ByteReceive是通过交换一个字节接收到的数据
//{
// uint8_t i;
// //在ss下降沿后,开始交换字节
// //实现时序
// for (i = 0; i < 8; i ++)
// {
// MySPI_W_MOSI(ByteSend & 0x80);
// ByteSend <<= 1;
//
// MySPI_W_SCK(1);
//
// if (MySPI_R_MISO() == 1){ByteSend |= 0x01;}
//
// MySPI_W_SCK(0);
// //通过循环,依次写入和读入B6、B5...B0
// }
//
// return ByteSend;
//}
MySPI.h
#ifndef __MYSPI_H
#define __MYSPI_H
void MySPI_Init(void);
void MySPI_Start(void);
void MySPI_Stop(void);
uint8_t MySPI_SwapByte(uint8_t ByteSend);
#endif
添加驱动层代码
添加源文件和头文件

主要参考W25Q64手册的指令集

如读取ID号
时序:起始->交换发送指令9F->连续交换接收3个字节->停止
怎么知道是交换发送还是交换接收呢?
圆括号括起来的就是我们需要交换接收的数据。

第一个字节:厂商ID,表示哪个厂家生产的
第二个字节:设备ID高8位,表示存储器类型
第三个字节:设备ID低8位,表示容量

1-表示芯片还在忙
0-表示芯片不忙了
实现等待Busy为0的函数
要是busy为1,进入等待,
函数执行完,busy为0,
MySPI_SwapByte(Address >> 16);
MySPI_SwapByte(Address >> 8);
MySPI_SwapByte(Address);
第一次,如果地址是0x123456,右移16位,就是0x12
第二次,如果右移8位,就是0x1234,但是交换字节函数智能接收8位数据,所以高位舍弃,实际发送0x34,就是中间的字节。
第三次,写入0x123456,舍弃高位,实际发送0x56
W25Q64.c
#include "stm32f10x.h" // Device header
#include "MySPI.h"
#include "W25Q64_Ins.h"
void W25Q64_Init(void)
{
//作为SPI上层的W25Q64模块,需要调用底层MySPI_Init,底层初始化好,上层才能正常工作
MySPI_Init();
}
/********************************************
业务代码-拼接完整时序
********************************************/
//有两个返回值,我们使用指针来实现多返回值
void W25Q64_ReadID(uint8_t *MID, uint16_t *DID)
{
MySPI_Start();
//抛玉引砖
MySPI_SwapByte(W25Q64_JEDEC_ID); //发送的是读ID号的指令,从机收到读ID号的指令,他就会在下一次交换把ID号返回给主机
//通信过程,不同时间调用相同的函数,它的意义是不一样的
//抛砖引玉
//虽然调用同一个函数,但是它的返回值是不一样的,此时正在通信,通信是有时序的,不同时间调用相同的函数,意义是不一样的
*MID = MySPI_SwapByte(W25Q64_DUMMY_BYTE); //参数我要给从机一个东西,此时我的目的时接收,所以给它抛的东西没有意义,返回值就是厂商ID号
*DID = MySPI_SwapByte(W25Q64_DUMMY_BYTE); //收到设备ID的高8位
*DID <<= 8; //把第一次读到的数据运到DID的高8位
*DID |= MySPI_SwapByte(W25Q64_DUMMY_BYTE); //收到设备ID的低8位(第二次读取需要变为|=,不能写等于,否则高8位就置0)
MySPI_Stop(); //停止时序
}
//Write Enable
//写使能,只需要发送一个指令码06即可
void W25Q64_WriteEnable(void)
{
MySPI_Start();
MySPI_SwapByte(W25Q64_WRITE_ENABLE); //发送指令码0x06
MySPI_Stop();
}
//Read Status Register-1 主要用途是判断芯片是不是忙状态
//等待busy为0
//如果不忙,则很快退出,如果忙,就会卡在函数里面等待
void W25Q64_WaitBusy(void)
{
uint32_t Timeout;
MySPI_Start();
//发送指令码,读状态寄存器1
MySPI_SwapByte(W25Q64_READ_STATUS_REGISTER_1);
Timeout = 100000;
//接收状态寄存器(主要用途是判断芯片是不是忙状态),等待busy为0状态
//发送dumy_byte,接收数据,返回值是状态寄存器1,与上0x01,用掩码取出最低位,如果它==0x01,就是busy为1,此时进入while循环等待,否则为0
//利用连续读出状态寄存器,实现等待BUSY的功能
while ((MySPI_SwapByte(W25Q64_DUMMY_BYTE) & 0x01) == 0x01) //防止死循环
{
Timeout --;
if (Timeout == 0)
{
break;
}
}
//终止时序
MySPI_Stop();
}
//Page Program
//页编程,C语言没有24位数据类型,定义32位即可,定义指针传递数组,count表示一次写的多少个字节(256字节,因此定义为16数据类型)
//写数据的数组是输入参数,要写的数据通过数组输入,
void W25Q64_PageProgram(uint32_t Address, uint8_t *DataArray, uint16_t Count) //数组需要通过指针传递
{
uint16_t i;
W25Q64_WriteEnable();
//拼接时序
//起始
MySPI_Start();
//发送指令码
MySPI_SwapByte(W25Q64_PAGE_PROGRAM);
//交换发送3个字节地址的数据(由高到低 )
MySPI_SwapByte(Address >> 16);
MySPI_SwapByte(Address >> 8);
MySPI_SwapByte(Address);
//地址发送完毕,即可一次发送写入的数据
for (i = 0; i < Count; i ++)
{
MySPI_SwapByte(DataArray[i]);
}
//停止时序
MySPI_Stop();
W25Q64_WaitBusy();
}
//Sector Erase
//擦除功能
void W25Q64_SectorErase(uint32_t Address)
{
//写使能
W25Q64_WriteEnable();
//起始
MySPI_Start();
//发送擦除扇区指令码20
MySPI_SwapByte(W25Q64_SECTOR_ERASE_4KB);
//再发送三个字节的地址,这样指定地址所在的整个扇区就会被擦除
MySPI_SwapByte(Address >> 16); //
MySPI_SwapByte(Address >> 8);
MySPI_SwapByte(Address);
//停止
MySPI_Stop();
W25Q64_WaitBusy();
}
//Read Data
//读数据的数组是输出参数,读到的参数通过数组输出
//读取数据没有页限制,所以读取count范围非常大
void W25Q64_ReadData(uint32_t Address, uint8_t *DataArray, uint32_t Count)
{
uint32_t i;
MySPI_Start();
MySPI_SwapByte(W25Q64_READ_DATA); //发送指令03,
//再发送3个字节地址
MySPI_SwapByte(Address >> 16);
MySPI_SwapByte(Address >> 8);
MySPI_SwapByte(Address);
//随后转入接收,可跨页读取,无限制
//开始读数据(抛砖引玉)
for (i = 0; i < Count; i ++)
{
//发送FF,置换为有用的数据
//在每次调用交换读取之后,存储器芯片内部地址指针自动自增,依次返回指定地址开始,往后线性区域地址下的数据
DataArray[i] = MySPI_SwapByte(W25Q64_DUMMY_BYTE);
}
//结束
MySPI_Stop();
}
/*注意*/
//涉及到写入操作的时序有扇区擦除和页编程(写入前需要写使能)
//在每次写操作时序结束后,调用waitBusy,事前等待、事后等待(高效)(写入操作后,芯片进入忙状态)
W25Q64.h
#ifndef __W25Q64_H
#define __W25Q64_H
void W25Q64_Init(void);
void W25Q64_ReadID(uint8_t *MID, uint16_t *DID);
void W25Q64_PageProgram(uint32_t Address, uint8_t *DataArray, uint16_t Count);
void W25Q64_SectorErase(uint32_t Address);
void W25Q64_ReadData(uint32_t Address, uint8_t *DataArray, uint32_t Count);
#endif
W25Q64_Ins.h
#ifndef __W25Q64_INS_H
#define __W25Q64_INS_H
//根据W25Q64手册,写出所有的指令名称和指令码
#define W25Q64_WRITE_ENABLE 0x06
#define W25Q64_WRITE_DISABLE 0x04
#define W25Q64_READ_STATUS_REGISTER_1 0x05
#define W25Q64_READ_STATUS_REGISTER_2 0x35
#define W25Q64_WRITE_STATUS_REGISTER 0x01
#define W25Q64_PAGE_PROGRAM 0x02
#define W25Q64_QUAD_PAGE_PROGRAM 0x32
#define W25Q64_BLOCK_ERASE_64KB 0xD8
#define W25Q64_BLOCK_ERASE_32KB 0x52
#define W25Q64_SECTOR_ERASE_4KB 0x20
#define W25Q64_CHIP_ERASE 0xC7
#define W25Q64_ERASE_SUSPEND 0x75
#define W25Q64_ERASE_RESUME 0x7A
#define W25Q64_POWER_DOWN 0xB9
#define W25Q64_HIGH_PERFORMANCE_MODE 0xA3
#define W25Q64_CONTINUOUS_READ_MODE_RESET 0xFF
#define W25Q64_RELEASE_POWER_DOWN_HPM_DEVICE_ID 0xAB
#define W25Q64_MANUFACTURER_DEVICE_ID 0x90
#define W25Q64_READ_UNIQUE_ID 0x4B
#define W25Q64_JEDEC_ID 0x9F
#define W25Q64_READ_DATA 0x03
#define W25Q64_FAST_READ 0x0B
#define W25Q64_FAST_READ_DUAL_OUTPUT 0x3B
#define W25Q64_FAST_READ_DUAL_IO 0xBB
#define W25Q64_FAST_READ_QUAD_OUTPUT 0x6B
#define W25Q64_FAST_READ_QUAD_IO 0xEB
#define W25Q64_OCTAL_WORD_READ_QUAD_IO 0xE3
//在接收数据时交换过去的无用数据
#define W25Q64_DUMMY_BYTE 0xFF
#endif
跨页连续写入(可参考野火)
硬件SPI读写W25Q64(代码)
软件SPI就是用代码手动翻转电平,来实现时序,优势是方便灵活
硬件SPI就是使用STM32内部的SPI外设来实现时序,优势是高性能,节省软件资源
SPI外设简介

1、硬件电路自动生成时序,不用手动翻转电平,节省软件资源
2、SPI外设的功能和参数
常用:8位(一个字节),高位先行
SPI、IIC高位先行
串口低位先行
(低位先行要反过来看)

时钟频率:传输速率
PCLK:外设时钟
SPI1挂载在APB2,PCLK是72M
SPI2挂载在APB1,PCLK是36M
最高频率是PCLK的2分频,最低频率是PCLK的256分频。
常用:SPI做主机
全双工:一根MOSI用于主机发送,一根MISO用于主机接收

半双工:去掉其中一根线,只在其中一根线上分时进行发送或接收
单工:直接去掉接收的数据线,再发送数据线进行只发的数据传输,只发模式,只收模式同理
野火SPI框图

1、通讯引脚
2、 时钟控制逻辑
STM32提供分频功能,是为了更好兼容低频设备
3、 数据控制逻辑
MSB:高位先行
LSB:低位先行

4、整体控制逻辑

SPI框图

图上表示的是低位先行:移位寄存器,右边的数据低位一位一位地从MOSI移出去,然后MISO的数据一位一位地移入到左边的数据高位

如果是高位先行,那么输出由左边移出去,输入由右边移进来

主从模式切换:

两个缓冲区实际上就是数据寄存器DR。发送数据缓冲区,就是发送数据寄存器TDR,接收缓冲区就是接收数据寄存器RDR。与串口一样,TDR和RDR占用同一个地址,统一叫做DR。

数据寄存器和移位寄存器打配合,可以实现连续的数据流
比如需要连续发送一批数据,第一个数据写入到TDR(发送缓冲区,当移位寄存器没有数据移位时,TDR的数据会立刻转入移位寄存器,开始移位,这个转入时刻,会置状态寄存器的TXE为1,表示发送寄存器为空,当我们检查TXE置1后,紧跟着,下一个数据,就可以提前写入到TDR里等候,一旦上一个数据发送完毕,下一个数据就可以立刻跟进,实现不间断的连续传输。然后移位寄存器这里,一旦有数据过来,它就会自动产生时钟,将数据移出去。在移出的过程中,MISO的数据也会移入。一旦数据移出完成,数据移入也就完成了。这时,移入的数据就会从移位寄存器转入到接收缓冲区RDR,此时,会置状态寄存器的RXNE为1,表示接受寄存器非空,当我们检查RXNE置1后,就要尽快把数据从RDR读出来。在写一个数据到来之前,读出RDR,就可以实现连续接收。否则,如果下一个数据已经收到了,上一个数据还没从RDR读出来,那RDR的数据就会被覆盖。就不能实现连续的数据流。)
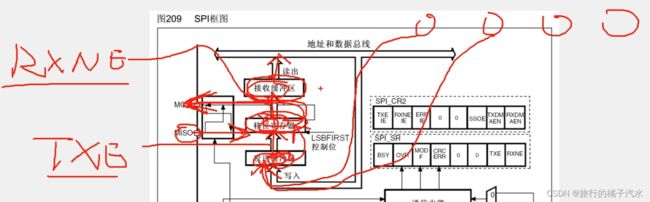
简而言之
发送数据先写入TDR,再转到移位寄存器发送,移位寄存器在发送的同时接收数据,接收到的数据转到RDR,再从RDR读取数据。
全双工

I2C是半双工,发送和接收不会同时进行,所以它的发送和接收都可以是共用的。
 串口通信(USART):全双工,并且发送和接收可以异步进行。这就要求数据寄存器,发送和接收是分离的。移位寄存器发送和接收也是分离的。
串口通信(USART):全双工,并且发送和接收可以异步进行。这就要求数据寄存器,发送和接收是分离的。移位寄存器发送和接收也是分离的。
SPI简洁框图

移位寄存器是左移,高位移出去,通过GPIO到MOSI,从MOSI输出,显然这时SPI的主机
之后移入的数据从MISO进来,通过GPIO,到移位寄存器的低位,这样循环8次,就能实现主机和从机交换一个字节。
然后TDR和RDR的配合可以实现连续的数据流。
TDR数据,整体转入移位寄存器的时刻,置TXE标志位(空),移位寄存器数据,整体转入RDR的时刻,置RXNE标志位(非空)
波特率发生器,产生时钟,输出到SCK引脚
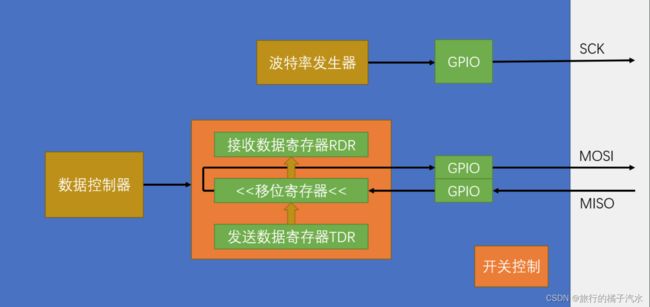
数据控制器就看成是一个管理员,它控制着所有电路的运行。
最后开关控制就是SPI_Cmd, 初始化后,给个ENABLE,使能整个外设。
在一主多从的模型下,使用普通的GPIO模拟的SS是最佳选择。
运行控制部分
如何产生具体时序,什么时候写DR,什么时候读DR
主模式全双工连续传输
借助缓冲区,数据前仆后继,实现连续数据流的过程,传输更快,但是操作复杂,难封装
实例使用的是SPI模式3
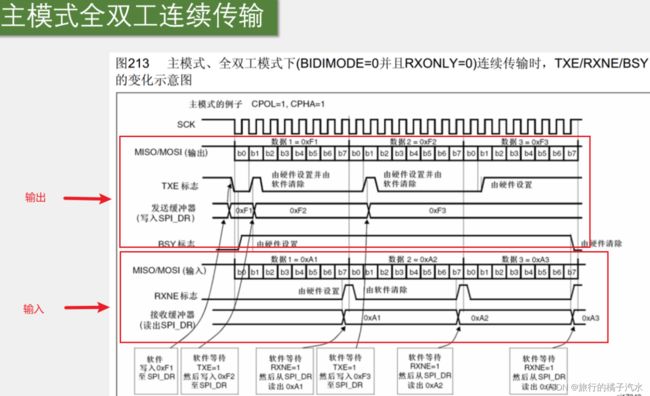
整体流程:
发送流程
示例演示的是低位先行
首先,SS置低电平,开始时序,在刚开始时,TXE为1,表示TDR为空,可以写入数据开始传输,0xF1就是发送的第一个数据,之后可以看到,写入之后,TDR变为0xF1,同时TXE变为0,表示TDR已经有数据,此时TDR为等候区,移位寄存器才是真正的发送区。移位寄存器刚开始肯定没有数据,所以在TDR的0xF1就会立刻转入到移位寄存器,开始发送,转入瞬间,置TXE标志为1,表示发送寄存器为空,然后移位寄存器有数据了,波形就自动开始生成。(江主任猜测这里画的数据波形时机可能有点早,应该是在以下图片时刻,b0的波形才开始产生。因为在这之前,数据还没有转入移位寄存器)。
在数据转入移位寄存器之后,数据F1的波形就开始产生,在移位产生F1波形的同时,等候区TDR是空的,为了移位完成时,下一个数据能不间断地跟随,这里,我们就要提早把下一个数据写入到TDR里等候,所以下面指示第二部操作是,写入F1之后,软件等待TXE=1,一旦TDR空了,就写入F2至SPI_DR,写入之后,TDR的内容就变为F2了,即把下一个数据放到TDR里等候,后面发送流程同理。F1数据波形产生完毕后,F2转入移位寄存器开始发送,此时TXE=1,尽快把下一个数据F3写入到TDR等候。

如果我们只想发送3个数据,F3转入移位寄存器之后,TXE=1,无需继续写入。注意,TXE置1后,还需要继续等待一段时间,F3的波形才能完整发送。等F3波形完整发送后,BUSY标志由硬件清除,这才表示波形发送完成。
接收流程
SPI是全双工,发送的同时还有接收。所以可以看到,在第一个字节发送完成后,第一个字节的接收也完成了。接收到的数据是A1。这时,移位寄存器的数据整体转入RDR,RDR随后存储的就是A1,转入的同时,RXNE标志位置1(RDR非空),表示收到数据了,然后从SPI_DR,即RDR读出数据A1,这是第一个接收的数据,接收之后,软件清除RXNE标志位。然后,当下一个数据2收到后,RXNE重新置1,当检测到RXNE=1时,就继续读出RDR,这是第二个数据A2,最后,在最后一个字节时序完全产生之后,数据3才能收到。
注意,一个字节的波形收到后,移位寄存器的数据自动转入RDR,会覆盖原有的数据,所以,我们要及时读取RDR。
比如A1收到后,最迟也要在RXNE重新置1前把A1读走。否则,写一个数据A2会覆盖A1. 就不能实现连续数据流的接收了。

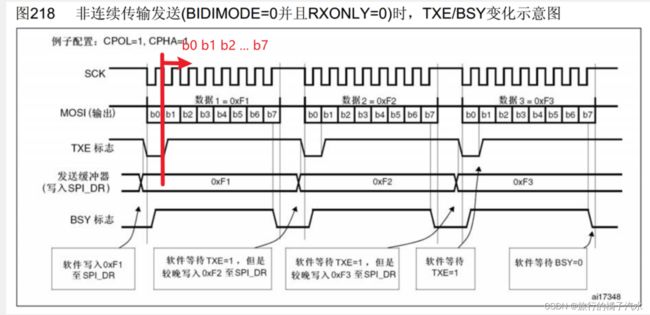
非连续传输
容易封装,好理解,好用,但是会丢失性能

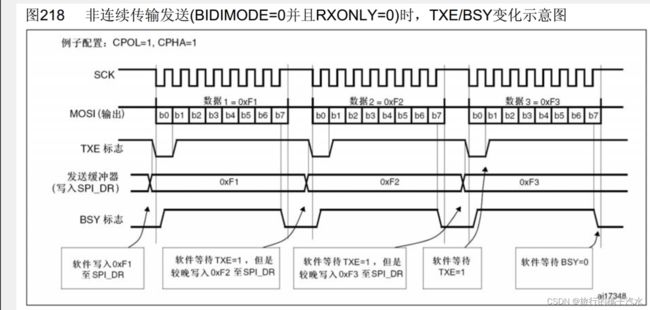
首先,配置还是SPI模式3,SCK默认高电平。我们想要发送数据时,如果检测到TXE=1,TDR为空,就软件写入0xF1到SPI_DR,TDR的值变为F1,TXE变为0(TDR非空),目前移位寄存器为空。所以F1会立刻转入移位寄存器开始发送,波形产生,并且TXE重置为1,表示TDR为空,表示你可以把下一个数据放在TDR里等候。连续传输与非连续传输的区别:此时,TXE=1,不着急把下一个数据写进去,而是一直等待,等第一个字节的时序结束,此时接收第一个字节也完成,RXNE置1,等待RXNE置1后,先把第一个接收到的数据读出来,之后再写入下一个字节数据。
总结:
第一步:等待TXE为1
第二步:写入发送的数据到TDR(当移位寄存器为空,该数据会立刻转入移位寄存器开始发送)
第三步:等待RXNE为1(表示RDR非空)
第四步:读取RDR接收的数据
之后交换第二个字节,重复这4步
因此,可以将以上4步封装为1个函数,调用一次,交换一个字节。
不同SCK的频率,间隙的影响(拖后腿情况)
频率越高,间隙越明显。
软件/硬件波形对比
硬件波形数据线的变化是紧贴SCK边沿的,而软件波形,数据线的变化,再边沿后有一些延迟。
下降沿和低电平期间,都可以作为数据变化的时刻,只是硬件波形会紧贴边沿,软件波形,一半只能在电平期间。
手册
CPOL,时钟极性,决定空闲状态SCK的默认电平,CPHA,时钟相位,决定第一个(奇数)边沿开始采样还是第二个(偶数)边沿开始采样。
SPI从模式(少用)
SPI主模式(常用)
代码
硬件SPI读写W25Q64接线图
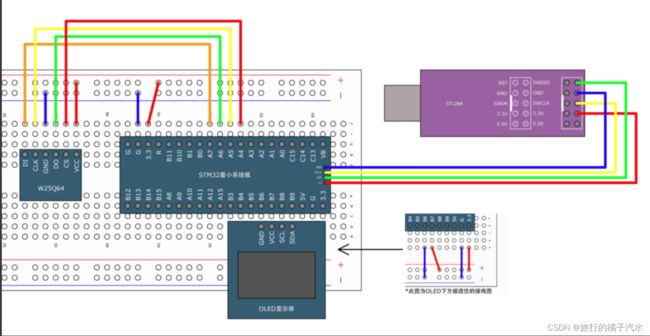
SPI1和SPI2得引脚复用功能


重定义得外设引脚

底层实现由软件改为硬件(初始化和时序执行步骤),在MySPI.c程序修改即可。
基于通讯层的业务代码(W25Q64)不需要更改,因为这些部分只是调用底层的通信函数来实现功能。
SPI的硬件实现:非连续传输方案
初始化流程:
1、开启时钟,开启SPI和GPIO的时钟
2、初始化GPIO口,其中SCK和MOSI是由硬件外设控制的输出信号,所以配置为复用推挽输出,MISO是硬件外设的输入信号,所以可以配置为上拉输入。SS引脚是软件控制的输出信号,所以配置为通用推挽输出。
3、配置SPI外设,使用一个结构体选参数即可,再调用SPI_init(),里面的各种参数,如8位/16位数据帧、高位先行/低位先行,spi模式几,主机还是从机等。
4、开关控制SPI_cmd,给SPI使能。
运行控制部分:产生交换字节的时序
- 写DR
- 读DR
- 获取状态标志位
SPI相关的库函数:

当我们调用交换字节的函数,硬件的SPI外设就要自动控制SCK、MOSI、MISO这三个引脚,来生成时序。
交换一个字节时序:
第一步:等待TXE为1,发送寄存器为空(如果发送寄存器不为空,那我们就不着急写)
//等待TXE为1,发送寄存器为空
while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_TXE) != SET); //标志位等于SET后就会跳出循环
第二步:软件写入数据置SPI_DR。
//软件写入数据至SPI_DR
SPI_I2S_SendData(SPI1, ByteSend); //传入ByteSend后,ByteSend写入到TDR,之后ByteSend自动转入到移位寄存器,一旦移位寄存器有数据,时序波形自动产生
在时序自动生成后,ByteSend这个数据就会通过MOSI一位一位地移出去,在MOSI线上,就会自动产生发送的时序波形。由于这是非连续传输,所以时序产生的这段时间,直接死等过去。那该等到什么时候,这一个字节地时序才会完成呢?
注意
在发送的同时,MISO还会移位进行接收,发送和接收是同步的,接收移位完成时,会收到一个字节数据,这时会置标志位RXNE
第三步:等待RXNE置1
//等待RXNE为1,表示接收到了数据,同时表示发送时序产生完成
while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_RXNE) != SET); //标志位等于SET后就会跳出循环
第四步:读取DR,从RDR里,把交换接收的数据读出来,即置换接收的一个字节
//读取数据
return SPI_I2S_ReceiveData(SPI1);
自此简单的四步完成了SPI一个字节的交换
在这里,我们并不需要像软件SPI那样,手动给SCK,MOSI置高低电平,也不用关心怎么把数据位一个个取出来,这些工作,硬件电路自动帮我们完成。
注意事项:
1、这里的硬件SPI必须是发送,同时接收。(要想接收,必须先得发送,因为只有给TDR写数据,才会触发时序的生成)
2、TXE和RXNE是不是会自动清除的问题。
不需要
等待TXE置1后,不需要再手动调用一个ClearFlag函数清除TXE标志位,因为当写入SPI_DR时,TXE标志被清除。RXNE标志位同理。

实验效果
MySPI.c
#include "stm32f10x.h" // Device header
//封装置高低电平的函数
//写SS引脚
void MySPI_W_SS(uint8_t BitValue)
{
GPIO_WriteBit(GPIOA, GPIO_Pin_4, (BitAction)BitValue);
}
// SPI初始化
//输出引脚配置为推挽输出,输入引脚配置为浮空或上拉输入,对于主机来说,时钟、主机输出和片选都是输出引脚
//主机输入是输入引脚
void MySPI_Init(void)
{
//1、开启时钟
RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOA, ENABLE); //开启GPIO时钟
RCC_APB2PeriphClockCmd(RCC_APB2Periph_SPI1, ENABLE); //开启SPI1外设时钟
//2、配置相应的GPIO口——SS
GPIO_InitTypeDef GPIO_InitStructure;
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP;//通用推挽输出
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_4;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
//SCK和MOSI
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_AF_PP;//复用推挽输出
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_5 | GPIO_Pin_7;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
//MISO
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_IPU;//上拉输入模式
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_6;
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz;
GPIO_Init(GPIOA, &GPIO_InitStructure);
//3、初始化SPI外设
SPI_InitTypeDef SPI_InitStructure;
SPI_InitStructure.SPI_DataSize = SPI_DataSize_8b; //8位
SPI_InitStructure.SPI_Direction = SPI_Direction_2Lines_FullDuplex; //双线全双工
SPI_InitStructure.SPI_FirstBit = SPI_FirstBit_MSB; //高位先行
SPI_InitStructure.SPI_Mode = SPI_Mode_Master; //决定当前设备是SPI的主机还是从机
SPI_InitStructure.SPI_BaudRatePrescaler = SPI_BaudRatePrescaler_128; //配置SCK时钟频率-->目前72M / 128 ~~ 500KHZ
//模式0
SPI_InitStructure.SPI_CPHA = SPI_CPHA_1Edge; //第几个边沿采样
SPI_InitStructure.SPI_CPOL = SPI_CPOL_Low ; //空闲状态默认低电平
SPI_InitStructure.SPI_CRCPolynomial = 7;
SPI_InitStructure.SPI_NSS = SPI_NSS_Soft; //软件NSS
SPI_Init(SPI1,&SPI_InitStructure);
//4、开始控制
SPI_Cmd(SPI1,ENABLE);
//默认给SS输出高电平,默认不选中从机
MySPI_W_SS(1);
/*自此,初始化完成,SPI外设就绪*/
}
/*SPI3个时序基本单元*/
//起始信号,置低电平
void MySPI_Start(void)
{
MySPI_W_SS(0);
}
//终止信号,置高电平
void MySPI_Stop(void)
{
MySPI_W_SS(1);
}
//交换一个字节(SPI核心部分),W25Q64支持模式0和模式3,一般选择模式0
uint8_t MySPI_SwapByte(uint8_t ByteSend) //ByteSend是传进来的参数,要通过交换一个字节的时序发送出去,返回值是ByteReceive是通过交换一个字节接收到的数据
{
//等待TXE为1,发送寄存器为空
while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_TXE) != SET); //标志位等于SET后就会跳出循环
//软件写入数据至SPI_DR
SPI_I2S_SendData(SPI1, ByteSend); //传入ByteSend后,ByteSend写入到TDR,之后ByteSend自动转入到移位寄存器,一旦移位寄存器有数据,时序波形自动产生
//等待RXNE为1,表示接收到了数据,同时表示发送时序产生完成
while(SPI_I2S_GetFlagStatus(SPI1, SPI_I2S_FLAG_RXNE) != SET); //标志位等于SET后就会跳出循环
//读取数据
return SPI_I2S_ReceiveData(SPI1);
}