揭秘被Arm编译器所隐藏的浮点运算~
以下文章来源于Mculover666 ,作者mculover666

引言
笔者接触嵌入式领域软件开发以来,几乎用的都是 ARM Cortex-M 内核系列的微控制器。感谢C语言编译器的存在,让我不用接触汇编即可进行开发,但是彷佛也错过了一些风景,没有领域到编译器之美和CPU之美,所以决定周末无聊的休息时间通过寻找资料、动手实验、得出结论的方法来探索 ARM CPU 架构的美妙,以及C语言编译器的奥秘。(因为我个人实在是不赞同学校中微机原理类课程的教学方法)。
-
ARM探索之旅 01 | 带你认识ARM Cortex-M阵营
-
ARM探索之旅 02 | ARM Cortex-M 用什么指令集?
一、浮点数的存储
浮点数按照 IEEE 754 标准存储在计算机中,ARM浮点环境是遵循 「IEEE 754-1985」 标准实现的。
IEEE 754 标准规定浮点数的存储格式有三个域,如图:

-
sign:符号位,0表示正数、1表示负数;
-
exponent:二进制小数的指数值编码;
-
fraction:二进制小数的有效值编码;
具体的编码规则过多,本文重点不在此,不再展开,感兴趣可以阅读我之前的文章:浮点数在计算机中的存储 —— IEEE 754标准[1](可点击阅读原文查看)。
二、浮点支持软件库fplib
1. fplib介绍
ARM Cortex-M处理器中计算浮点数的方式有软件和硬件两种。
对于不带 FPU 的处理器,ARM提供了一个「浮点支持软件库」用于计算浮点数:fplib。
fplib提供的 API 以__aeabi开头,比如:
-
__aeabi_fadd:计算两个float型浮点数(float占4个字节,32位) -
__aeabi_dadd:计算两个double型浮点数(double占8个字节,64位) -
__aeabi_f2d:float型转为double型 -
__aeabi_d2f:double型转为float型
除此之外,fplib库还提供取余、开方等非常多的浮点数操作函数,如有兴趣可以查阅文末我列出的参考文档[2]。
2. 测试代码与优化等级
编写如下测试代码:
float a = 5.625;
float b = 5.625;
float res_add, res_sub, res_mul, res_div;
res_add = a + b;
res_sub = a - b;
res_mul = a * b;
res_div = a / b;
printf("res_add = %f\r\n", res_add);
printf("res_sub = %f\r\n", res_sub);
printf("res_mul = %f\r\n", res_mul);
printf("res_div = %f\r\n", res_div);
❝使用这段测试代码,「编译器优化等级推荐设置为-O0」,否则聪明的编译器会直接将结果计算出来编译到程序中,我们就没法研究了。
❞

3. armcc测试结果
这节我们验证是否ARM使用 fplib 库来计算浮点数,在设置中关闭FPU: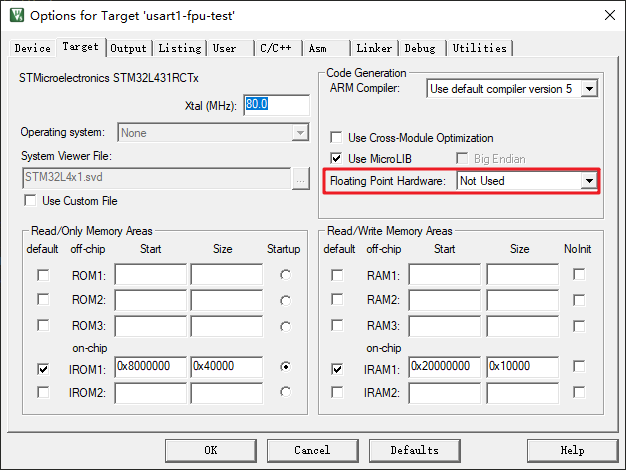
使用MDK编译之后,进入调试模式查看反汇编结果。
在反汇编中可以看到,变量a是float类型,所以编译器分配了一个寄存器用于存储值: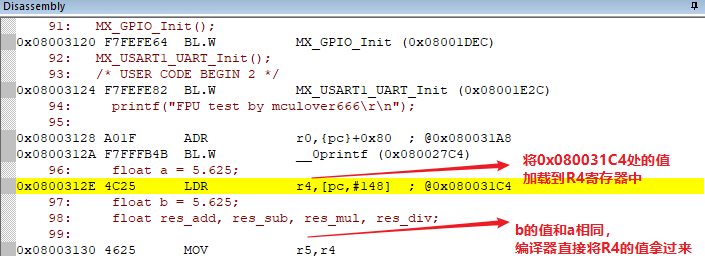
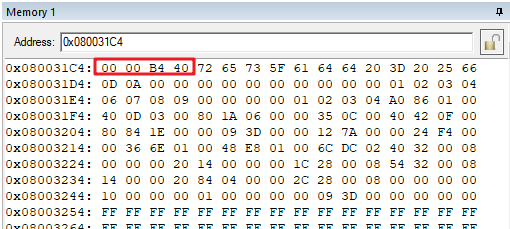
查看0x080031C4处的值,小端存储模式下(低位在低地址),变量a的值是0x40B40000,存储方式符合IEEE 754标准。
 再来看看浮点数运算操作的反汇编结果,果然调用fplib库提供的函数完成浮点数的操作:
再来看看浮点数运算操作的反汇编结果,果然调用fplib库提供的函数完成浮点数的操作: 这里还有一个有趣的小细节,在反汇编中可以看到「使用
这里还有一个有趣的小细节,在反汇编中可以看到「使用 %f 占位符打印浮点数时,printf是按照double型传参的」:
4. arm-none-eabi-gcc测试结果
使用STM32CubeMX生成makeifle工程,修改makeifle中的等级为-O0,设置为软件浮点计算: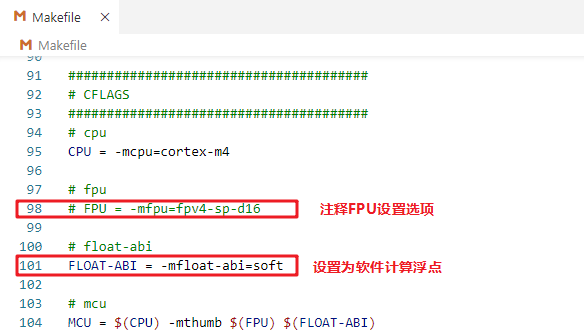 另外还需要注意,默认gcc编译时不支持printf打印浮点数,需要在 makefile 中手动加入以下链接选项:
另外还需要注意,默认gcc编译时不支持printf打印浮点数,需要在 makefile 中手动加入以下链接选项:
LDFLAGS += -u _printf_float
编译完成之后进行反汇编(注意文件名):
arm-none-eabi-objdump -s -d build/usart1-fpu-test.elf > build/usart1-fpu-test.dis
同样,在反汇编文件中即可找到浮点计算代码: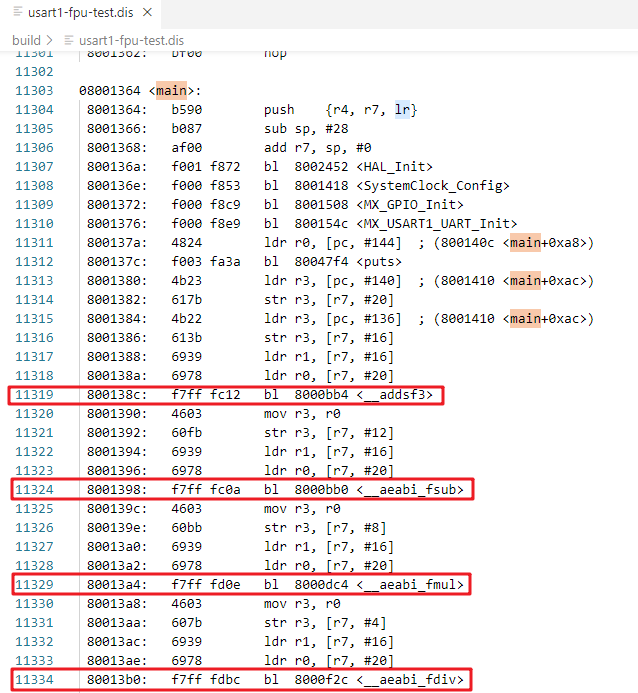
三、使用 ARM FPU 加速浮点计算
1. ARM FPU的魅力
FPU(Floating Point Unit,浮点单元)是ARM内核中的硬件外设,用于硬件计算浮点数,要想使用FPU计算浮点数,需要程序和编译器配合。
-
在程序中使能/开启FPU硬件外设,「使 FPU 硬件可以正常工作」;
-
在编译器中设置使用FPU,编译器会将所有浮点计算的代码都编译为「使用FPU操作指令完成」。
目前Cortex-M4、Cortex-M7、Cortex-M33、Cortex-M35P、Cortex-M55处理器中都具备FPU硬件。
在上一节中我们使用fplib软件库来计算浮点数,但是fplib终归还是软件方式,每个计算函数的实现都是通过很多的指令去完成计算,并且最终的程序中还会把函数链接进可执行程序,导致程序体积变大。
「ARM FPU的魅力在于,浮点计算可以通过简单的FPU操作指令去完成,相比之下,不仅计算快,也不会增大程序体积。」
2. 如何使能FPU硬件
ARM Cortex - M4内核中将 FPU 作为协处理器设计的,所以通过设置协处理器访问控制(CPACR,Co-processor access control register)来控制是否使能FPU。
 复位之后CP11=0、CP10=0,默认禁止访问FPU,因为这是Cortex-M内核的外设,寄存器定义
复位之后CP11=0、CP10=0,默认禁止访问FPU,因为这是Cortex-M内核的外设,寄存器定义CMSIS-Core中,所以可以直接通过下面这行代码设置CP11=1、CP10=1来允许访问FPU:
SCB->CPACR = 0x00F00000; // Enable the floating point unit for full access
无论是STM32 HAL库还是标准库,在SystemInit()函数中已经存在使能代码,通过__FPU_PRESENT和__FPU_USED来控制:
/* FPU settings ------------------------------------------------------------*/
#if (__FPU_PRESENT == 1) && (__FPU_USED == 1)
SCB->CPACR |= ((3UL << 10*2)|(3UL << 11*2)); /* set CP10 and CP11 Full Access */
#endif
并且,在头文件 stm32l431xx.h 中已经使能__FPU_PRESENT宏定义:
__FPU_PRESENT宏定义是一直使能的,那么如何来控制FPU的使能呢?
别忘了还有一个宏定义__FPU_USED,这是留给编译器来控制的!
3. ARMCC编译器如何开启FPU
MDK编译器开启FPU的方法非常简单,如图: 在MDK中使能FPU,一方面编译器会设置宏定义
在MDK中使能FPU,一方面编译器会设置宏定义__FPU_USED == 1,不放心的话可以在任意位置添加下面的预处理代码,分别在使用/不使用的情况编译一下,查看编译器输出结果:
#if __FPU_USED == 1
#error "ok!"
#endif
另一方面,编译器在编译的时候,会将所有的浮点运算都编译为使用FPU操作指令去完成,比如本文最开始的测试代码编译结果如下: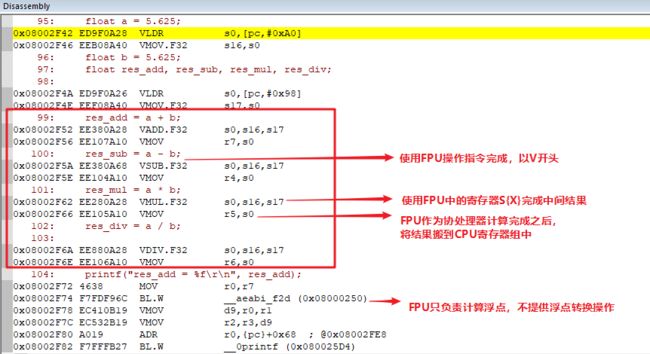
4. gcc编译器如何开启FPU
在Makefile中加入以下gcc编译设置项:
# fpu
FPU = -mfpu=fpv4-sp-d16
# float-abi
FLOAT-ABI = -mfloat-abi=hard
ABI是应用程序二进制接口(Application Binary Interface),-mfloat-abi用来指定使用哪种方式:
-
soft:使用CPU寄存器组+软件库(fplib)完成浮点操作; -
softfp:使用CPU寄存组+FPU硬件+软件库完成浮点操作; -
hard:使用FPU寄存器组+FPU硬件+软件库完成浮点操作;
mfpu选项用来指定FPU架构,具体值可以阅读我在文末给出的参考文档,本文所使用的值fpv4-sp-d16,意味着仅仅使能Armv7 FPv4-SP-D16 单精度浮点单元扩展。
同样,对之前的测试代码编译,查看反汇编结果,可以看到使用了浮点操作全部使用了FPU相关指令。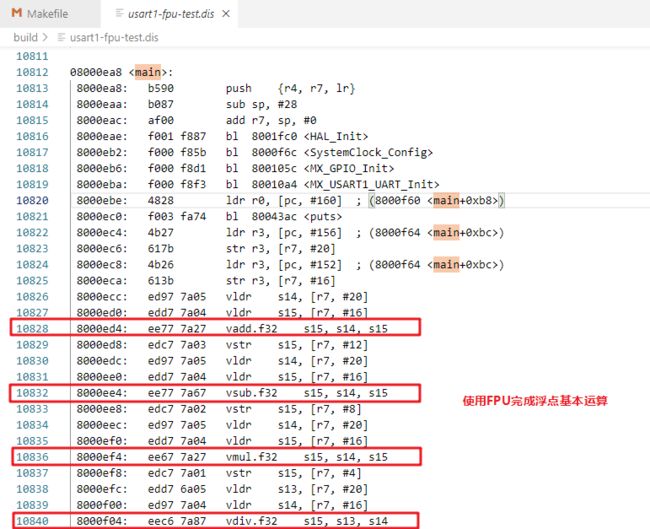
四、使用Julia测试FPU加速性能
1. 测试准备
需要准备一份裸机工程,具有屏幕打点显示功能和串口打印功能。
参考:STM32CubeMX_17 | 使用硬件SPI驱动TFT-LCD(ST7789)。
2. 移植Julia分形测试代码
Julia测试是通过计算几帧Julia分形的数据来测试单精度浮点运算的性能,测试代码参考正点原子,如下:
/* Private user code ---------------------------------------------------------*/
/* USER CODE BEGIN 0 */
#define ITERATION 128 //迭代次数
#define REAL_CONSTANT 0.285f //实部常量
#define IMG_CONSTANT 0.01f //虚部常量
//颜色表
uint16_t color_map[ITERATION];
//缩放因子列表
const uint16_t zoom_ratio[] =
{
120, 110, 100, 150, 200, 275, 350, 450,
600, 800, 1000, 1200, 1500, 2000, 1500,
1200, 1000, 800, 600, 450, 350, 275, 200,
150, 100, 110,
};
//初始化颜色表
//clut:颜色表指针
void InitCLUT(uint16_t * clut)
{
uint32_t i = 0x00;
uint16_t red = 0, green = 0, blue = 0;
for (i = 0;i < ITERATION; i++) {
//产生 RGB 颜色值
red = (i*8*256/ITERATION) % 256;
green = (i*6*256/ITERATION) % 256;
blue = (i*4*256 /ITERATION) % 256;
//将 RGB888,转换为 RGB565
red = red >> 3;
red = red << 11;
green = green >> 2;
green = green << 5;
blue = blue >> 3;
clut[i] = red + green + blue;
}
}
//产生 Julia 分形图形
//size_x,size_y:屏幕 x,y 方向的尺寸
//offset_x,offset_y:屏幕 x,y 方向的偏移
//zoom:缩放因子
void GenerateJulia_fpu(uint16_t size_x,uint16_t size_y,uint16_t offset_x,uint16_t offset_y,uint16_t zoom)
{
uint8_t i;
uint16_t x,y;
float tmp1,tmp2;
float num_real,num_img;
float radius;
for (y = 0; y < size_y; y++) {
for (x = 0; x < size_x; x++) {
num_real = y - offset_y;
num_real = num_real / zoom;
num_img = x-offset_x;
num_img = num_img / zoom;
i = 0;
radius = 0;
while ((i < ITERATION-1) && (radius < 4)) {
tmp1 = num_real * num_real;
tmp2 = num_img * num_img;
num_img = 2*num_real*num_img + IMG_CONSTANT;
num_real = tmp1 - tmp2 + REAL_CONSTANT;
radius = tmp1 + tmp2;
i++;
}
//绘制到屏幕
lcd_draw_color_point(x, y, color_map[i]);
}
}
}
/* USER CODE END 0 */
在main函数中创建一些需要的变量:
/* USER CODE BEGIN 1 */
uint8_t zoom_index = 0;
uint32_t start_time = 0, end_time = 0;
/* USER CODE END 1 */
调用初始化函数:
/* USER CODE BEGIN 2 */
printf("Julia test by Mculover666\r\n");
lcd_init();
//初始化颜色表
InitCLUT(color_map);
/* USER CODE END 2 */
调用测试函数:
/* Infinite loop */
/* USER CODE BEGIN WHILE */
while (1)
{
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */
start_time = HAL_GetTick();
GenerateJulia_fpu(240, 240, 120, 120, zoom_ratio[zoom_index]);
end_time = HAL_GetTick();
printf("diff time is %d ms\r\n", end_time - start_time);
zoom_index++;
if (zoom_index > sizeof(zoom_ratio)) {
zoom_index = 0;
}
}
/* USER CODE END 3 */
3. 测试结果
使用-O2优化等级,在不开 FPU 的情况下,「显示一帧平均需要11s左右」: 程序大小情况:
程序大小情况: 使用-O2优化等级,在开启 FPU 的情况下,「显示一帧平均需要4s左右」:
使用-O2优化等级,在开启 FPU 的情况下,「显示一帧平均需要4s左右」: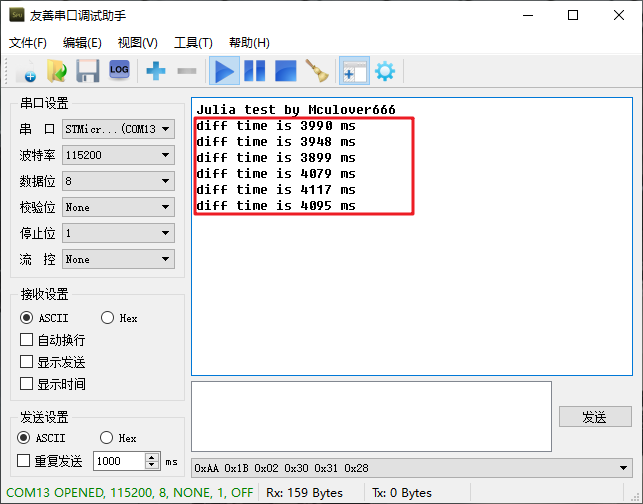 程序大小情况:
程序大小情况: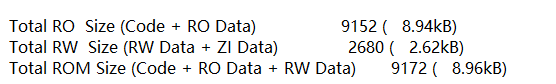 最后放上好看的Julia分形图:
最后放上好看的Julia分形图:
五、参考资料
[1] 浮点数在计算机中的存储 —— IEEE 754标准(https://mculover666.blog.csdn.net/article/details/93382331)
[2] About floating-point support,ARM Keil(https://www.keil.com/support/man/docs/armlib/armlib_chr1358938940990.htm)
[3] Compiler Reference Guide,ARM Keil(https://www.keil.com/support/man/docs/armclang_ref/armclang_ref_chr1392305424052.htm)
[4] ARM Cortex-M3与M4权威指南
![]()
1.对国产嵌入式操作系统,你了解多少?
2.“构建安全的嵌入式系统”线上课程,6月1日正式报名!
3.Arm亮出多款大小核CPU!
4.在51单片机上跑RTOS有没有意义?
5.国产芯片创业的战略思考
6.嵌入式开发中,数值常量如何转化为内存地址?