Java——Volatile
目录
可见性问题
JMM (Java Memory Model)
现在计算机的内存模型
Java内存模型
可见性的解决方案
加锁
Volatile修饰共享变量
Volatile做了什么?
MESI (缓存一致性协议)
如何发现数据是否失效?——嗅探
嗅探的缺点——总线风暴
禁止指令重排序
无法保证原子性
volatile和sychronized的区别
应用
总结
可见性问题
首先给出一段代码:
public class Test {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
while (true) {
if (myThread.isFlag()) {
System.out.println("TRUE");
}
}
}
}
class MyThread extends Thread {
private boolean flag = false;
public boolean isFlag() {
return flag;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
System.out.println("flag=" + flag);
}
}
输出结果:
flag=true结果显示,即使线程改变了flag变量,主线程也没能输出“TRUE”
为什么会出现这种情况?
JMM (Java Memory Model)
JMM:Java内存模型,是Java虚拟机规划中所定义的一种内存模型,Java内存模型是标准化的,屏蔽了底层不同计算机的区别(注意这个跟JVM不是一个东西)。
首先介绍一些现代计算机的内存模式:
现在计算机的内存模型
在早期计算机中CPU和内存的速度是差不多的,但是现代计算机中,CPU的指令速度远超内存的存取速度,由于计算机的存储设备和处理器的运算速度有几个数量级的差距,所以现代计算机系统都加入了一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲。
将运算需要使用的数据复制到缓存中,让运算能快速进行,当运算结束后再从换从同步回内存之中,这样处理器就无需等待缓慢的内存读写了。
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来了更高的复杂度,因为它引入了一个新的问题:缓存一致性(Cache Coherence)
在多多力气系统中,每个处理器都有自己的告诉缓存,而它们又共享同一主内存。
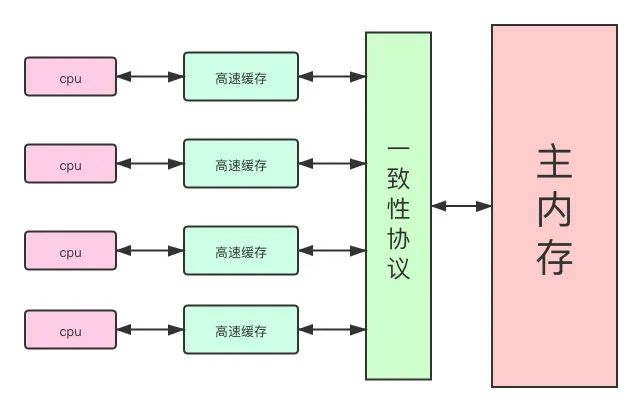
Java内存模型
Java 内存模型描述了Java程序中各种变量(线程共享变量)的访问规则,以及在JVM中将变量,存储到内存和从内存中读取变量这样的底层细节。
JMM有以下规定:
所有的共享变量都存储于主内存,这里所说的变量指的是实例变量和类变量,不包含局部变量,因为局部变量是线程私有的,因此不存在竞争问题。
每一个线程还存在自己的工作内存,线程的工作内存,保留了被线程使用的变量的工作副本。
线程对变量的所有的操作(读、取)都必须在工作内存中完成,而不能直接读写主内存中的变量。
不同内存之间也不能直接访问对方工作内存中的变量,线程间变量的值的传递需要通过主内存中转来完成。
本地内存与主内存的关系:

正是因为这样,才导致了可见性问题的存在,那我们就讨论下可见性的解决方案。
可见性的解决方案
加锁
public class Test {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
while (true) {
synchronized (myThread) {
if (myThread.isFlag()) {
System.out.println("TRUE");
}
}
}
}
}
class MyThread extends Thread {
private boolean flag = false;
public boolean isFlag() {
return flag;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
System.out.println("flag=" + flag);
}
}
为什么加锁科技解决可见性问题?
因为某一个线程进入sychronized代码块前后,线程会获得锁,清空工作内存,从主内存拷贝共享变量最新的值到工作内存成为副本,执行代码,将修改后的副本的值刷新回主内存,线程释放锁。
而获取不到锁的线程会一直等待,所以变量的值肯定一直都是最新的。
Volatile修饰共享变量
public class Test {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
while (true) {
if (myThread.isFlag()) {
System.out.println("TRUE");
}
}
}
}
class MyThread extends Thread {
private volatile boolean flag = false;
public boolean isFlag() {
return flag;
}
@Override
public void run() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = true;
System.out.println("flag=" + flag);
}
}
Volatile做了什么?
每个线程操作数据的时候会把数据从主内存读取到自己的工作内存,如果他操作了数据并且写了,其它线程读取的线程的变量副本就会失效,需要读数据进行操作又要再次去主内存中读取了。
volatile保证不同线程对共享变量操作的可见性,也就是说一个线程修改了volatile修饰的变量,当修改写回主内存时,另外一个线程立即看到最新的值。
当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致,那同步回主内存时以谁的缓存数据为准呢?
为了解决一致性问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI, MESI, MOSI, Synapse, Firefly及DrangonProtocol等。
MESI (缓存一致性协议)
当CPU写数据时,如果发现操作的变量是共享变量,即在其它CPU中也存在该变量的副本,会发出信号通知其它CPU将该变量的缓存行为置为无效状态,因此当其它CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么就会从内存中重新读取。
如何发现数据是否失效?——嗅探
每个处理器通过在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器缓存行设置为无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
嗅探的缺点——总线风暴
由于Volatile的MESI缓存一致性协议,需要不断地从主内存嗅探和CAS不断循环,无效交互会导致总线带宽达到峰值。
所以不要大量使用Volatile,至于什么时候使用Volatile时候锁,什么时候使用锁,根据场景区分。
禁止指令重排序
- 什么是重排序?
为了提高性能,编译器核处理器通常会对既定地代码执行顺序进行指令重排序。
- 重排序的类型有哪些?源码到最终执行会经过哪些重排序?

一个好的内存模型实际上会放松对处理器和编译器规则的束缚,也就是说软件技术和硬件技术都为同一个目标,而进行奋斗:在不改变程序执行结果的前提下,尽可能提高执行效率。
JMM对底层尽量减少约束,使其能够发挥自身优势。
因此,在执行程序时,为了提高性能,编译器和处理器常常会对指令进行重排序,一般重排序可以分为如下三种:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序;
- 指令级并行的重排序。现在处理器采用了指令级并行技术来将多条指令重叠执行,如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序;
- 内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
- as-if-serial
不管怎么重排序,单线程下的执行结果不能被改变。
编译器、runtime和处理器都必须遵守as-if-serial语义。
- volatile如何如何保证不会被执行重排序?
java编译器会在生成指令系列时在适当的位置会插入内存屏障指令来禁止特定类型的处理器重排序。
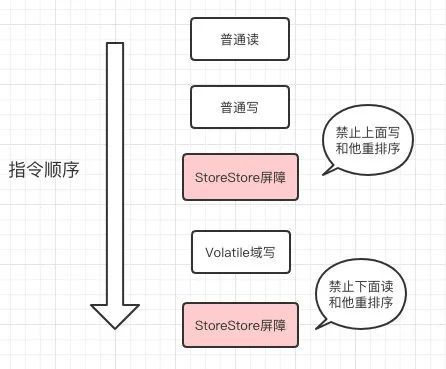
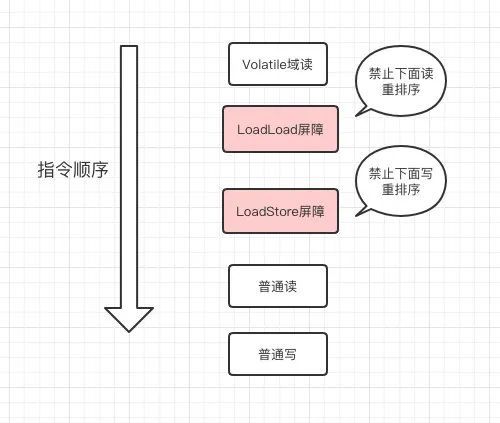
为了实现volatile的内存语义,JMM会限制特定类型的编译器和处理器重排序,JMM会针对编译器指定volatile重排序规则表:

需要注意的是,volatile写是在前面和后面分别插入内存屏障,而volatile读操作是在后面插入两个内存屏障。
写:
读:
上面提到的重排序原则,为了提高处理速度,JVM会对代码进行编译优化,也就是指令重排序优化,并发编程下指令重排序会带来一些安全隐患:如指令重排序导致的多个线程操作之间的不可见性。
从JDK5开始,提出了happens-before的概念,通过这个概念来阐述操作之间的内存可见性。
- happens-before
如果一个操作执行的结果需要对另一个操作可见,那么这两个操作之间必须存在happens-before关系。
volatile域规则:对一个volatile域的写操作,happens-before于任意线程后续对这个volatile域的读。
如果flag变成了false,那么后面的操作一定知道flag改变了。
无法保证原子性
原子性就是一次操作,要么完全成功,要么完全失败。
假设现在有N个线程对同一个变量进行累加也是没有办法保证结果是对的,因为读写这个过程并不是原子性的。
解决办法:要么使用原子类,要么加锁。
volatile和sychronized的区别
volatile只能修饰实例变量和类变量,而synchronized可以修饰方法,以及代码块。
volatile保证数据的可见性,但是不保证原子性;而synchronized是一种互斥机制。
volatile用于禁止指令重排序,可以解决单例双重检查对象初始化代码执行乱序问题。
volatile可以看作是轻量版的synchronized,volatile不保证原子性,但是如果是对一个共享变量进行多个线程的赋值,而没有其它操作,就可以用volatile来代替synchronized,因为赋值本身是原子性的,而volatile又保证了可见性,所以就可以保证线程安全了。
应用
class Singleton {
private volatile static Singleton instance = null;
private Singleton() {}
public static Singleton getInstance() {
// 第一重锁检查
if (instance == null) {
// 同步锁定代码块
synchronized (Singleton.class) {
//第二重检查锁定
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}为什么要双重检查?不用Volatile会怎么样?
对象实际上创建对象要经过如下几个步骤:
- 分配内存空间
- 调用构造器,初始化实例
- 返回地址给引用
因为可能发生指令重排序,有可能构造函数在对象初始化完成前就赋值完成了,在内存里面开辟了一片储存区域后返回内存的引用,这个时候还没真正的初始化完成对象。
但是别的线程去判断instance != null,直接就拿去用了,其实这个对象是个半成品,那就有空指针异常了。
总结
- volatile修饰符适用于以下场景:某个属性被多个线程共享,其中有一个线程修改了此属性,其它线程可以立即得到修改后的值;后者作为触发器,实现轻量级同步。
- volatile属性的读写操作都是无锁的,它不能代替synchronized,因为它没有提供原子性和互斥性。因为无所,不需要花费时间在获取锁和释放锁上,所以它是低成本的。
- volatile只能作用于属性,使用volatile修饰属性,这样编译器就不会对这个属性做指令重排序。
- volatile提供了可见性,任何一个线程对其的修改将立马对其它线程可见,volatile属性不会被线程缓存,始终从主内存中读取。
- volatile提供了happens-before保证,对volatile变量的写入happens-before所有线程后续对变量的读操作。
- volatile可以使得long和double的赋值是原子的。
- volatile可以在单例双重检查中实现可见性和禁止指令重排序,从而保证安全性。