LRU算法学习笔记:实现以及应用
文章目录
- 一、LRU算法的实现
- 二、LRU算法的实现(C++)
-
- 三、LRU的实际应用
-
- 1. 在MySQL上的应用
- 2. 在Redis上的应用
一、LRU算法的实现
其实很久以前就已经学过了LRU算法,在秋招面试之余整理成文章,以便面试的时候说得条理清晰一点。
所谓LRU(Least Recently Used)就是最近最少使用算法。其核心的思想就是根据每个节点的最后一次访问事件来对每个结点进行排序。最近一次使用的排在队头,依次类推。
如果实现这样的一个链表,一般需要实现两个功能:
- 快速插入元素(这个元素包含key,value两个部分)
- 快速访问元素(根据key快速拿到value)
此外,这个链表随着不断的插入新的元素,肯定不断变长。因此对于这个链表来说,需要一个容量上限。超过了这个容量的上限,那么就需要把链表尾部(距离现在最久一次访问的结点)进行删除。
所以,实现这个链表,还隐藏了第三个功能:
- 快速删除元素
因此:
- 从快速删除、插入的角度来看的话,需要一个链表来维护结点的时序关系。
- 从快速根据元素的key来拿到value来看的话,需要一个哈希表来维护key和value的关系。
根据这种思路,我们可以很快的想到:
维护一个链表,链表中的结点放value,然后维护一个哈希表,可以根据key快速的拿到结点,然后取出里面的key。
实际上,还需要考虑一些其他的细节:
- 链表是单向还是双向?
- 结点这样设计真的可以吗?
回答:
链表需要双向。我们思考什么时候会删除一个元素:- 链表满了,我们需要删除尾部的结点。
- 访问了链表中间的结点,需要把这个结点删除,然后插到链表头。
在上面的这两种情况下,删除一个结点cur需要将这个结点的前一个结点的next指针指向cur的下一个结点。因此,需要知道cur的前一个结点是谁。
结点需要同时维护key和value,不能只有value。假设现在因为插入一个结点到链表里面,导致链表满了,需要删除尾部的结点。那么尾部结点是很容易删除,但是哈希表中维护了这个结点的信息也要被删除。结点里面只有value,怎么知道哈希表里面删除谁呢?
有了这些思考,我们就可以实现一个LRU结构了。
二、LRU算法的实现(C++)
根据上面的分析,我们实现的LRU数据结构图如下:
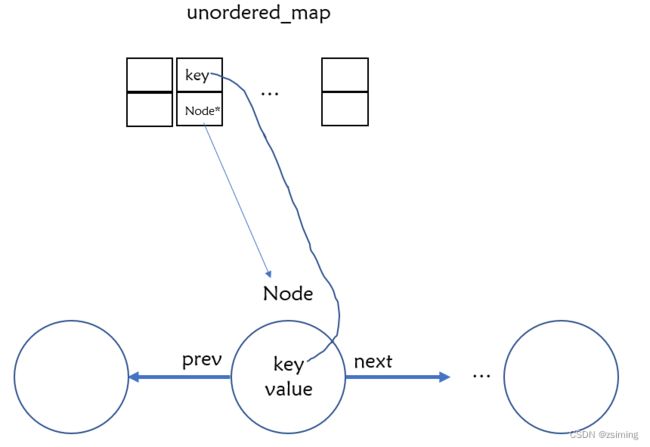
-
unordered_map用于快速根据key找到结点
-
链表中的结点包括四个变量:
1. prev_:指向上一个结点
2. next_:指向下一个结点
3. key_:关键字
4. value_:存储元素
下面是具体实现:
class LRUCache {
private:
struct Node {
Node(int key = -1, int val = 0, Node* prev = nullptr, Node* next = nullptr) : key_(key), val_(val), prev_(prev), next_(next) {}
Node* prev_;
Node* next_;
int key_;
int val_;
};
public:
LRUCache(int capacity) : cap_(capacity), size_(0) {
head_ = new Node();
tail_ = new Node();
head_->next_ = tail_;
tail_->prev_ = head_;
}
int get(int key) {
auto it = key2Node_.find(key);
if (it == key2Node_.end()) return -1;
Node* node = it->second;
int res = node->val_;
//1. 从链表中拆下这个节点
deleteNode(node);
//2. 添加到链表头
addToHead(node);
return res;
}
void deleteNode(Node* node) {
node->prev_->next_ = node->next_;
node->next_->prev_ = node->prev_;
}
void addToHead(Node* node) {
node->next_ = head_->next_;
head_->next_->prev_ = node;
node->prev_ = head_;
head_->next_ = node;
}
void put(int key, int value) {
auto it = key2Node_.find(key);
if (it == key2Node_.end()) {
// 1. 创建节点
Node* addNode = new Node(key, value);
key2Node_[key] = addNode;
// 2. 插到队头
addToHead(addNode);
// 3. 判断是否溢出
++size_;
if (size_ > cap_) {
key2Node_.erase(tail_->prev_->key_);
deleteNode(tail_->prev_);
--size_;
}
} else {
// 1. 更改节点的值
Node* node = it->second;
node->val_ = value;
// 2. 删除节点
deleteNode(node);
// 3. 插到队头
addToHead(node);
}
}
private:
unordered_map<int, Node*> key2Node_;
Node* head_ = nullptr;
Node* tail_ = nullptr;
int size_ = 0;
int cap_ = 0;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
三、LRU的实际应用
LRU算法实际上在MySQL上和Redis上都有应用,不过都是LRU算法的变种。
1. 在MySQL上的应用
在MySQL中,LRU算法主要用于缓存的淘汰。所谓缓存,就是在每次查询的时候把结果用链表形式串起来,下次访问相同的内容时,就可以直接从链表中查询了。
这条链表,就是LRU中的链表,链表的“结点”,就是磁盘中一页的数据,也就是16K的数据。但是,使用这种原始的LRU算法确是不妥的,原因有两个:全表扫描 和 磁盘预读。
全表扫描
对于MySQL来说,有些SQL语句的查询需要遍历整个数据库,在遍历的过程中,MySQL在磁盘中的每一页数据都频繁的在LRU链表中移动。
更糟糕的是,遍历的数据太多,而且遍历完可能完全就没有用了,但是数据却把原来LRU上频繁使用的数据给挤掉了。那么,在下次一大批热点数据的查询过来的时候,数据库(假设没有Redis)可能就直接崩溃了。
磁盘预读
学过操作系统的同学应该知道,操作系统在访问磁盘的数据的时候,也不是仅仅加载所需要的数据到内存中,而是进行了一部分的预读。因为根据程序的局部性原理,接下来的数据很可能也会被访问到。对于MySQL也是如此,访问了磁盘的内容,MySQL就会预读一部分的数据
如果在MySQL中,访问一个区的数据超过56页,那么MySQL就会把下个区的全部内容都加入到MySQL的缓存中。
如果在MySQL中,缓存已经有了某个区的13页的内容,那么这个区的其余内容也会被加载到MySQL的缓存中。
由于这两个缺点,MySQL做了自己的LRU算法的改进。改进方式是维护了两条LRU链表,也称为冷热LRU链表。
冷LRU维护的都是冷数据。在MySQL中,从磁盘刚读进来的数据都放在冷LRU链表中。
如果冷LRU的数据在1秒后又被访问了,才会从冷LRU链表转移到热LRU链表中。
这样就完美解决了磁盘预读和全表扫描的问题了。
2. 在Redis上的应用
Redis是专门来作为数据库缓存的内存型数据库,也就是所有的数据都放在了内存中。因此,和MySQL一样,Redis需要对一些数据进行淘汰。
从Redis数据库设计者的角度来看,也不将LRU原始算法作为数据库内存的淘汰策略,其主要考虑了两个问题:
- 维护链表需要时间
- 大量数据的访问需要频繁的移动链表,又是十分耗时的操作。
基于以上两个问题,Redis使用的LRU算法是一种近似LRU算法,其实现十分简单:
在数据对象的结构体上增加一个时间字段,记录了最后一次使用的时间。当需要进行淘汰的时候,直接随机选出5个数据对象,然后删除最久未使用的那个数据。
因此,在Redis中,不要维护链表、也没有链表结点被访问时的频繁移动,速度快很多。
但是,不像MySQL,Redis的这种策略是没办法解决缓存污染的问题的。也就是一次性访问很多数据,只访问了一次但是淘汰的时候被考虑到的优先级却低很多。
因此,在Redis中,引入了LFU算法来实现内存的淘汰策略。(挖坑,后面有时间补上)
参考文献:
- MySQL是如何对LRU算法进行优化的?又该如何对MySQL进行调优?
- Redis 过期删除策略和内存淘汰策略有什么区别?