Attention Mechanisms in Computer Vision A Survey(注意力机制综述)
Attention Mechanisms in Computer Vision: A Survey
论文地址:https://arxiv.org/pdf/2111.07624.pdf
贡献:
这篇论文的贡献是对计算机视觉中注意力机制进行了全面的综述和分析,并提供了以下方面的贡献:
- 综述了计算机视觉领域中最常用的不同类型的注意力机制,包括空间注意力、通道注意力、自注意力、同步注意力和动态卷积滤波器。
- 深入分析了不同类型的注意力机制的优缺点和应用场景,并提供了实验结果和示例,展示了注意力机制在不同任务上的应用。
- 探讨了注意力机制的实现方法,包括软注意力和硬注意力,并提供了两种方法的优缺点和应用场景的分析。
- 探讨了与注意力机制相关的可解释性问题,并提出了一些方法来解释和可视化注意力机制。
综上所述,这篇论文的贡献是对注意力机制在计算机视觉领域中的理解和应用提供了深入的探讨和分析,有助于指导注意力机制在实际应用中的使用和改进。
创新点:
这篇论文的创新点在于提供了一种全面的视角来理解计算机视觉中的注意力机制。它综述了计算机视觉领域中最常用的不同类型的注意力机制,并深入探讨了它们的优缺点、应用和局限性。此外,该论文还探讨了注意力机制的实现方法,包括软注意力和硬注意力,以及与注意力机制相关的可解释性问题。总之,该论文提供了一种广泛的框架,帮助研究人员和从业者更好地理解、应用和改进注意力机制在计算机视觉中的应用。
Abstract
人类可以自然有效地在复杂场景中找到显著区域。在这种观察的激励下,注意力机制被引入计算机视觉,目的是模仿人类视觉系统的这一方面。这种注意机制可以看作是一个基于输入图像特征的动态权重调整过程。注意机制在许多视觉任务中取得了巨大的成功,包括图像分类、目标检测、语义分割、视频理解、图像生成、三维视觉、多模态任务和自监督学习。在这项调查中,作者全面回顾了计算机视觉中的各种注意机制,并根据方法对它们进行分类,如通道注意、空间注意、时间注意和分支注意力;作者还提出了注意机制研究的未来方向。
1、Introduction
将注意力转移到图像中最重要的区域并忽略不相关部分的方法称为注意力机制;在视觉系统中,注意机制可以被视为一个动态选择过程,通过根据输入的重要性自适应地加权特征来实现。注意机制在很多视觉任务中都有好处,例如:图像分类目标检测语义分割、人脸识别、人物再识别、动作识别、少量显示学习、医学图像处理、图像生成、姿势估计,超分辨率、3D视觉、和多模式任务。
在过去的十年里,注意机制在计算机视觉中扮演着越来越重要的角色;图3简要总结了深度学习时代计算机视觉中基于注意的模型的历史。

进展大致可分为四个阶段。第一阶段始于RAM,这是一项将深层神经网络与注意力机制相结合的开创性工作。它反复预测重要区域,并通过策略梯度以端到端的方式更新整个网络。在这个阶段,递归神经网络(RNN)是注意力机制的必要工具。在第二阶段开始时,Jaderberg等人提出了STN,它引入了一个子网络来预测用于选择输入中重要区域的仿射变换。明确预测歧视性输入特征是第二阶段的主要特征;DCN是具有代表性的作品。第三阶段始于SENet,提出了一种新的通道注意网络,它隐式地、自适应地预测潜在的关键特征。CBAM和ECANet是本阶段的代表作品。最后一个阶段是自注意力时代。并在自然语言处理领域迅速取得了巨大进展。Wang等人率先将自注意力引入计算机视觉,并提出了一种新颖的非局部网络,在视频理解和目标检测方面取得了巨大成功。接下来是一系列工作,如EMANet、CCNet、HamNet和独立网络,这些工作提高了速度、结果质量和泛化能力。最近,各种纯粹的深层自注意力网络(视觉transformers)]相继出现,显示出基于注意的模型的巨大潜力。显然,基于注意力的模型有可能取代卷积神经网络,成为计算机视觉中一种更强大、更通用的体系结构。
本文的目的是对当前计算机视觉中的注意方法进行总结和分类。如图1所示,并在图2中进一步解释:它是基于数据域的。
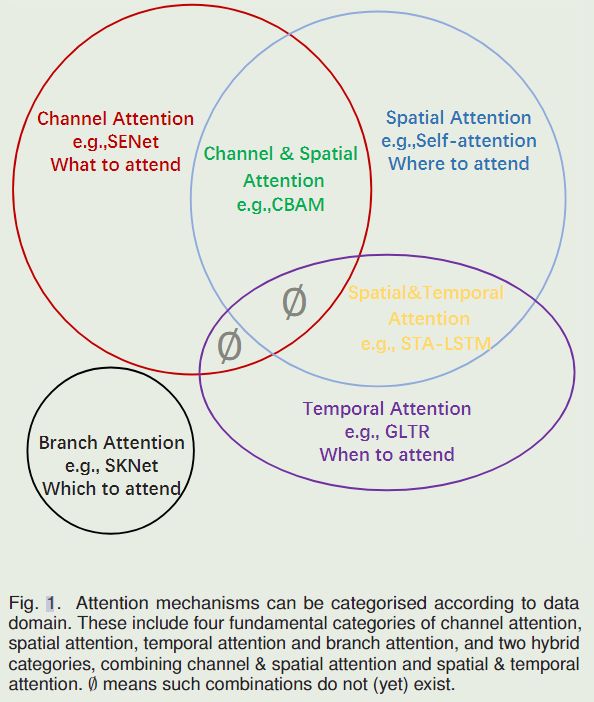

一些方法考虑重要数据何时出现,或其他方法在何处出现等问题,并相应地尝试在数据中找到关键时间或位置。作者将现有的注意方法分为六类,包括四个基本类别:通道注意力(注意图中有什么)、空间注意力(注意关键因素哪里)、时间注意(何时注意)和分支通道(注意感受野),以及两个混合组合类别:通道与空间注意和空间与时间注意。
表2将这些观点与相关工作进行了进一步的简要总结。

本文主要贡献有:
1、对视觉注意力方法的系统回顾,包括注意力机制的统一描述、视觉注意力机制的发展以及当前的研究。
2、根据数据域对注意力方法进行分类分组,使我们能够将视觉注意力方法独立于其特定应用进行链接。
3、对视觉注意未来研究的建议。
2、OTHER SURVEYS
在本节中,我们将这篇论文与现有的各种研究进行了简单的比较,这些研究综述了注意方法和visual transformers。Chaudhari等人[140]对深度神经网络中的注意力模型进行了调查,重点关注其在自然语言处理中的应用,而我们的工作则集中在计算机视觉上。三个更具体的调查[141],[142],[143]总结了visual transformers的发展,而我们的论文更广泛地回顾了视觉中的注意机制,而不仅仅是自注意机制。Wang等人[144]对计算机视觉中的注意力模型进行了研究,但它只考虑了基于RNN的注意力模型,这只是我们研究的一部分。此外,与以往的调查不同,我们提供了一种分类,根据各种注意方法的数据领域而不是根据它们的应用领域对各种注意方法进行分组。这样做使我们能够专注于注意力方法本身,而不是将其作为其他任务的补充。
3、ATTENTION METHODS IN COMPUTER VISION
在本节中,我们首先根据第3.1节中人类视觉系统的识别过程,总结出注意机制的一般形式。然后我们回顾了图1中给出的各种类别的注意模型,并对每个类别进行了专门的细分。在每个类别中,我们将该类别的代表性作品制成表格。我们也更深入地介绍了这一类别的注意策略,从动机、制定和功能三个方面考虑了它的发展。
3.1、General form
在看到我们日常生活中的场景时,我们将重点关注判别区域,并快速处理这些区域。上述过程可以表述为:
A t t e n t i o n = f ( g ( x ) , x ) Attention = f(g(x),x) Attention=f(g(x),x)
通过上述定义,我们发现几乎所有现有的注意力机制都可以写成上述公式。
在这里,我们采用self-attention [15] 和 squeeze-and-excitation(SE) attention [5]作为例子。
self-attention可以写成:
Q , K , V = L i n e a r ( x ) Q,K,V = Linear(x)\\ Q,K,V=Linear(x)
g ( x ) = S o f t m a x ( Q K ) g(x) = Softmax(QK)\\ g(x)=Softmax(QK)
f ( g ( x ) , x ) = g ( x ) V f(g(x),x) = g(x)V f(g(x),x)=g(x)V
SENet可以写成:
g ( x ) = S i g m o i d ( M L P ( G A P ( x ) ) ) g(x) = Sigmoid(MLP(GAP(x))) g(x)=Sigmoid(MLP(GAP(x)))
f ( g ( x ) , x ) = g ( x ) x f(g(x),x)=g(x)x f(g(x),x)=g(x)x
在下文中,我们将介绍各种注意力机制并将它们指定到上述公式中。
3.2、Channel Attention
在深度神经网络中,不同特征图中的不同通道通常代表不同的对象[50]。通道注意力自适应地重新校准每个通道的权重,可以将其视为一个对象选择过程,从而确定要注意的内容。Hu等人[5]首先提出了通道注意的概念,并为此提出了SENet。如图四所示:我们很快就会讨论,有三个工作流在继续以不同的方式改善通道注意力。

在本节中,我们首先总结了具有代表性的通道注意工作,并将 g ( x ) g(x) g(x)和 f ( g ( x ) , x ) f(g(x),x) f(g(x),x)过程描述为 表3 和 图5 中的Eq. 1。然后分别讨论了各种渠道关注方法及其发展历程。


3.2.1、SENet
https://arxiv.org/pdf/1709.01507.pdf

SENet开创了通道注意力的先河。SENet的核心是一个压缩和激励(SE)块,用于收集全局信息、捕获通道关系和提高表示能力。
SE模块分为两部分,挤压模块和激励模块。挤压模块通过全局平均池化收集全局空间信息。激励模块通过使用全连接层和非线性层(ReLU和sigmoid)捕捉通道关系并输出注意力向量。然后,通过乘以注意向量中的相应元素来缩放输入特征的每个通道。综上,以 X X X为输入, Y Y Y为输出的挤压激励块 F s e F_{se} Fse(参数为 θ θ θ)可表示为:
s = F s e ( X , θ ) = σ ( W 2 δ ( W 1 G A P ( X ) ) ) s=F_{se}(X,\theta) = \sigma(W_2\delta(W_1GAP(X))) s=Fse(X,θ)=σ(W2δ(W1GAP(X)))
Y = s X Y=sX Y=sX
SE模块在抑制噪声的同时,起着强调重要通道的作用。由于SE块的计算资源需求较低,因此可以在每个残差单元之后添加SE块。然而,SE块也有缺点。在挤压模块中,全局平均池过于简单,无法捕获复杂的全局信息。在激励模块中,全连接层增加了模型的复杂性。后续工作试图改进挤压模块的输出(例如 G S o P GSoP GSoP网络),通过改进激励模块(例如 E C A N e t ECANet ECANet)降低模型的复杂性,或者同时改进挤压模块和励磁模块(例如 S R M SRM SRM)。
3.2.2、GSoP-Net
https://arxiv.org/pdf/1811.12006

SE块仅通过使用全局平均池化(即一阶统计量)来捕获全局信息,这限制了其建模能力,尤其是捕获高阶特征的能力。 为了解决这个问题,Gao等人提出通过使用全局二阶池化(GSoP)块在收集全局信息的同时对高阶特征数据建模来改进挤压模块。
与SE块一样,GSoP块也有一个挤压模块和一个激励模块。在压缩模块中,GSoP块首先使用 1 x 1 1x1 1x1卷积将通道数从 c c c减少到 c ′ c' c′ ( c ′ < c c'
在激励模块中,GSoP块执行逐点卷积以保持结构信息并输出向量。然后利用全连接层和 s i g m o i d sigmoid sigmoid函数得到c维注意向量。最后,它将输入特征乘以注意向量,就像在SE块中一样。GSoP块可以表示为:
s = F g s o p ( X , θ ) = σ ( W R C ( C o v ( C o n v ( X ) ) ) ) s=F_{gsop}(X,\theta) = \sigma(WRC(Cov(Conv(X)))) s=Fgsop(X,θ)=σ(WRC(Cov(Conv(X))))
Y = s X Y=sX Y=sX
C o n v ( ⋅ ) Conv(·) Conv(⋅)表示减少通道数, C o v ( ⋅ ) Cov(·) Cov(⋅)计算协方差矩阵, R C ( ⋅ ) RC(·) RC(⋅)表示逐点卷积。 通过使用二阶池化,GSoP块提高了通过SE块收集全局信息的能力。然而,这是以额外计算为代价的。因此,通常在几个残差块之后添加单个GSoP块。
3.3.3、SRM
https://arxiv.org/pdf/1903.10829

受风格转移成功的启发,Lee等人提出了基于轻量级风格的重新校准模块(SRM)。SRM 将风格迁移与注意力机制相结合。它的主要贡献是style pooling,它利用输入特征的均值和标准差来提高捕获全局信息的能力。为了降低计算层(CFC)的完全连接要求,在全连接的地方也采用了CFC[与通道等宽的全连接层CFC(Channel-wise fully-connected layer) ]。
给定一个输入特征映射 X ∈ R C × H × W X∈ R^{C×H×W} X∈RC×H×W,SRM首先通过结合全局平均池和全局标准差池化的风格式池化 ( S P ( ⋅ ) ) (SP(·)) (SP(⋅))收集全局信息。然后使用通道全连接 ( C F C ( ⋅ ) ) (CFC(·)) (CFC(⋅))层(即每个通道全连接)、批量归一化BN和sigmoid函数σ来提供注意力向量。最后,与SE块一样,输入特征乘以注意力向量。总的来说,SRM可以写成:
s = F s r m ( X , θ ) = σ ( B N ( C F C ( S P ( X ) ) ) ) s=F_{srm}(X,\theta)=\sigma(BN(CFC(SP(X)))) s=Fsrm(X,θ)=σ(BN(CFC(SP(X))))
Y = s X Y=sX Y=sX
SRM模块改进了挤压和激励模块,但可以像SE模块一样添加到每个残差单元之后。
3.2.4、GCT
https://arxiv.org/pdf/1909.11519
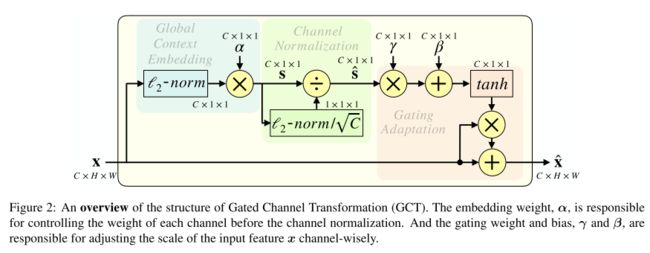
由于激励模块中全连接层的计算需求和参数数量,在每个卷积层之后使用 SE 块是不切实际的。此外,使用全连接层对通道关系进行建模是一个隐式过程。为了克服上述问题,Yang 等人,提出了门控通道变换 (GCT),以在显式建模通道关系的同时有效地收集信息。
与以前的方法不同,GCT首先通过计算每个通道的 l 2 l_2 l2范数来收集全局信息。接下来,应用可学习向量α来缩放特征。然后通过通道规范化引入竞争机制,实现通道之间的互动。与其他常见的归一化方法一样,可学习的尺度参数γ和偏差β用于重新缩放归一化。然而,与之前的注意力向量激活方法不同, t a n h tanh tanh采用的是注意力向量激活方法。最后,它不仅增加了输入注意向量,但也增加了身份映射。GCT可以写成:
s = F g c t ( X , θ ) = t a n h ( γ C N ( α N o r m ( X ) ) + β ) s=F_{gct}(X,\theta)=tanh(\gamma CN(\alpha Norm(X))+\beta) s=Fgct(X,θ)=tanh(γCN(αNorm(X))+β)
Y = s X Y=sX Y=sX
3.2.5、ECANet
https://arxiv.org/pdf/1910.03151

为了避免模型复杂度高,SENet 减少了通道数。然而,这种策略不能直接对权重向量和输入之间的对应关系进行建模,降低了结果的质量。为了克服这个缺点,Wang 等人。 (1991) 提出了有效的通道注意力 (ECA) 块,而是使用一维卷积来确定通道之间的交互,而不是降维。
ECA 块具有与 SE 块类似的公式,包括一个用于聚合全局空间信息的挤压模块和一个用于建模跨通道交互的有效激励模块。ECA块不是间接对应,而是只考虑每个通道与其k近邻之间的直接交互来控制模型的复杂性。总体而言,ECA 块的制定是:
s = F e c a ( X , θ ) = σ ( C o n v 1 D ( G A P ( X ) ) ) s=F_{eca}(X,\theta)=\sigma(Conv1D(GAP(X))) s=Feca(X,θ)=σ(Conv1D(GAP(X)))
Y = s X Y=sX Y=sX
其中 C o n v 1 D ( ⋅ ) Conv1D(·) Conv1D(⋅) 表示在通道域中具有形状 k 的核的一维卷积,以模拟局部跨通道交互。参数 k k k决定交互的覆盖范围,在ECA中,内核大小 k k k通过通道维度 C C C自适应确定,而不是通过手动调整,使用交叉验证:
k = ψ ( C ) = ∣ l o g 2 c γ + b γ ∣ o d d k=\psi(C)=|\frac{log_2{c}}{\gamma}+\frac{b}{\gamma}|_{odd} k=ψ(C)=∣γlog2c+γb∣odd
其中 γ \gamma γ 和 b b b是超参数 ∣ x ∣ o d d |x|_{odd} ∣x∣odd表示x的最近奇数函数。与SENet相比,ECANet有一个改进的激励模块,并提供了一个高效、有效的模块,可以很容易地集成到各种CNN中。
3.2.6、FcaNet
https://arxiv.org/pdf/2012.11879

仅在挤压模块中使用全局平均池会限制表征能力。为了获得更强大的表示能力,Qin等人[57]从压缩的角度对捕获的全局信息进行了重新思考,并在频域上分析了全局平均池化。他们证明了全局平均池化是离散余弦变换(DCT)的特殊情况,并利用这一观察提出了一种新的多光谱通道注意。
给定一个输入特征映射 X ∈ R C × H × W X∈ R^{C×H×W} X∈RC×H×W,多光谱通道注意力首先将 X X X分成许多部分 x i ∈ R C 0 × H × W x^i∈ R^{C_0×H×W} xi∈RC0×H×W。然后对每个部分应用 2 D 2D 2D D C T DCT DCT。请注意, 2 D 2D 2D D C T DCT DCT可以使用预处理结果来减少计算量。处理后,所有结果都被连接到一个向量中。最后,使用全连接层、ReLU激活和sigmoid来获得SE块中的注意向量。这可以表述为:
s = F f c a ( X , θ ) = σ ( W 2 σ ( W 1 [ ( D C T ( G r o u p ( X ) ) ) ] ) ) s=F_{fca}(X,\theta)=\sigma(W_2\sigma(W_1[(DCT(Group(X)))])) s=Ffca(X,θ)=σ(W2σ(W1[(DCT(Group(X)))]))
Y = s X Y=sX Y=sX
其中 G r o u p ( ⋅ ) Group(·) Group(⋅)表示将输入分成多个组, D C T ( ⋅ ) DCT(·) DCT(⋅)表示二维离散余弦变换。 这项基于信息压缩和离散余弦变换的工作在分类任务上取得了优异的性能。
3.2.7、EncNet
https://arxiv.org/pdf/1803.08904
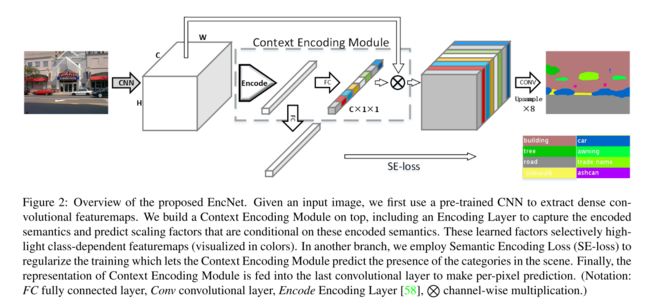
受SENet的启发,Zhang等人提出了上下文编码模块(CEM),该模块结合了语义编码损失(SE损失),以建模场景上下文和对象类别概率之间的关系,从而利用全局场景上下文信息进行语义分割。
在训练阶段,给定一个输入特征映射 X ∈ R C × H × W X ∈ R^{C×H×W} X∈RC×H×W,CEM首先学习K个聚类中心 D = d 1 , . . . , d K D={d_1,...,d_K} D=d1,...,dK和一组平滑因子 S = s 1 , … , s K S={s_1,…,s_K} S=s1,…,sK。接下来,它使用软分配权重对输入中的局部描述符和相应的聚类中心之间的差异进行求和,以获得置换不变描述符。然后,为了提高计算效率,它将聚合应用于K个簇中心的描述符,而不是级联。形式上,CEM可以写成:
e k = ∑ i = 1 N e − s k ∣ ∣ X i − d k ∣ ∣ 2 ( X i − d k ) ∑ j = 1 k e − s j ∣ ∣ X i − d j ∣ ∣ 2 e_k=\frac{\sum_{i=1}^Ne^{-s_k||X_i-d_k||^2(X_i-d_k)}}{\sum_{j=1}^ke^{-s_j||X_i-d_j||^2}} ek=∑j=1ke−sj∣∣Xi−dj∣∣2∑i=1Ne−sk∣∣Xi−dk∣∣2(Xi−dk)
e = ∑ n = 1 K ϕ ( e k ) e= \sum_{n=1}^K\phi(e_k) e=n=1∑Kϕ(ek)
s = σ ( W e ) s=\sigma(We) s=σ(We)
Y = s X Y=sX Y=sX
d k ∈ R C d_k\in R^C dk∈RC 和 s k ∈ R s_k\in R sk∈R是可学习的参数。 ψ \psi ψ 表示使用ReLU激活函数的批量标准化。除了按通道缩放向量外,紧凑的上下文描述符e还用于计算SE损失,以正则化训练,从而改进小对象的分割。
3.2.8、Bilinear Attention
http://openaccess.thecvf.com/content_ICCV_2019/papers/Fang_Bilinear_Attention_Networks_for_Person_Retrieval_ICCV_2019_paper.pdf

继GSoP Net之后,Fang等人提出,以前的注意力模型只使用一阶信息,而忽略了高阶统计信息。因此,他们提出了一种新的双线性注意块(bilinear attention block,bilinear attention)来捕获每个通道内的局部成对特征交互,同时保留空间信息。
双注意力利用注意中的注意(attention-in-attention AiA)机制捕获二阶统计信息:外部逐点通道注意向量由内部通道注意的输出计算。给定输入特征映射X,bi-attention首先使用双线性池来捕获二阶信息。
x ~ = B i ( ϕ ( X ) ) = V e c ( U T r i ( ϕ ( X ) ϕ ( X ) T ) ) \widetilde{x}=Bi(\phi(X))=Vec(UTri(\phi(X)\phi(X)^T)) x =Bi(ϕ(X))=Vec(UTri(ϕ(X)ϕ(X)T))
其中 ϕ \phi ϕ表示用于降维的嵌入函数, ϕ ( x ) T \phi(x)^T ϕ(x)T是 ϕ ( x ) \phi(x) ϕ(x)在通道域上的转置, U t r i ( ⋅ ) Utri(·) Utri(⋅)提取矩阵的上三角元素, V e c ( ⋅ ) Vec(·) Vec(⋅)是矢量化。然后,双注意将内通道注意力机制应用于特征映射 x ~ ∈ R c ′ ( c ′ + 1 ) 2 × H × W \widetilde{x}\in R^{\frac{c'(c'+1)}{2}\times H\times W} x ∈R2c′(c′+1)×H×W
x ^ = ω ( G A P ( x ~ ) ) ϕ ( x ~ ) \hat{x}=\omega(GAP(\widetilde{x}))\phi(\widetilde{x}) x^=ω(GAP(x ))ϕ(x )
这里 ω \omega ω 和 ϕ \phi ϕ 是嵌入函数。最后,使用输出特征映射 x ^ \hat{x} x^计算外部逐点注意机制的空间通道注意权重:
s = σ ( x ^ ) s=\sigma(\hat{x}) s=σ(x^)
Y = s X Y=sX Y=sX
双注意块使用双线性池来模拟沿每个通道的局部成对特征交互,同时保留空间信息。与其他基于注意的模型相比,该模型更关注高阶统计信息。双注意可以整合到任何CNN主干中,以提高其代表性,同时抑制噪音。
上图是按类别和出版日期排序的代表性通道注意机制。他们的主要目标是强调重要通道和获取全局信息。应用领域包括:Cls=分类,Det=检测,SSeg=语义分割,ISeg=实例分割,ST=风格转换,Action=动作识别。 g ( x ) g(x) g(x)和 f ( g ( x ) , x ) f(g(x),x) f(g(x),x)是由等式1描述的注意过程。范围是指注意力特征图的范围。S或H表示软注意或硬注意。(A) 通道方面的模型。(I) 强调重要中道,(II)获取全局信息。
3.3、Spatial Attention
空间注意可以看作是一种自适应空间区域选择机制:关注点在哪里。RAM、STN、GENet和Non-Local是不同类型空间注意方法的代表。RAM代表基于RNN的方法。STN代表那些使用子网络明确预测相关区域的人。GENet代表那些隐式使用子网络预测软掩码以选择重要区域的人。Non-Local表示与自注意相关的方法。我们首先总结了具有代表性的空间注意机制,并指定了过程 g ( x ) g(x) g(x)和 f ( g ( x ) , x ) f(g(x),x) f(g(x),x),如表4中的Eq. 1所示,然后根据图4讨论它们。

3.3.1、RAM
https://arxiv.org/pdf/1406.6247
卷积神经网络具有巨大的计算成本,特别是对于大输入。为了将有限的计算资源集中在重要区域,Mnih等人提出了重复注意模型(Recurrent Models of Visual Attention RAM),该模型采用RNN和强化学习(RL)来让网络学习需要注意的位置。RAM率先将RNN用于视觉注意力中。
如下图所示,RAM有三个关键元素:(A)glimpse sensor,(B)glimpse network和(C)RNN模型。
glimpse sensor采用坐标 l t − 1 l_{t-1} lt−1和一张图片 X t X_t Xt。它以 l t − 1 l_{t-1} lt−1为中心输出多个分辨率的patches ρ ( X t , l t − 1 ) \rho(X_t,l_{t-1}) ρ(Xt,lt−1)。glimpse network为 f g ( θ ( g ) ) f_g(θ(g)) fg(θ(g))它包括glimpse sensor,输出输入坐标 l t − 1 l_{t−1} lt−1和图像 X t X_t Xt的特征表示 g t g_t gt。RNN模型考虑 g t g_t gt和内部状态 h t − 1 h_{t−1} ht−1 ,并输出下一个中心坐标 l t l_t lt和在 s o f t m a x softmax softmax处的操作结果,以执行图像分类任务。由于整个过程是不可微的,因此在更新过程中采用了强化学习策略。

这提供了一种简单但有效的方法,将网络聚焦于关键区域,从而减少网络执行的计算数量,尤其是对于大输入,同时改善图像分类结果。
3.3.2、Glimpse Network
https://arxiv.org/pdf/1412.7755

受人类顺序执行视觉识别的启发,Ba等人提出了一种类似于RAM的深度递归网络(MULTIPLE OBJECT RECOGNITION WITH VISUAL ATTENTION),能够处理多分辨率的输入图像,称为“Glimpse”,用于多目标识别任务。所提出的网络使用Glimpse作为输入更新其隐藏状态,然后在每一步预测一个新对象以及下一个Glimpse位置。Glimpse通常比整个图像小得多,这使得网络的计算效率更高。
提出的深度递归视觉注意模型由context network, glimpse network, recurrent network, emission network, and classification network组成。首先,上下文网络将下采样的整个图像作为输入,为递归网络提供初始状态以及first glimpse的位置。然后,在当前时间步长 t t t处,给定当前gimpse x t x_t xt及其位置元组 l t l_t lt,glimpse 网络的目标是提取有用的信息,表示为
g t = f i m a g e ( X ) ⋅ f l o c ( l t ) g_t=f_{image}(X)\cdot f_{loc}(l_t) gt=fimage(X)⋅floc(lt)
其中 f i m a g e ( X ) f_{image}(X) fimage(X)和 f l o c ( l t ) f_{loc}(l_t) floc(lt)是两个输出向量都具有相同维度的非线性函数,并且 ⋅ \cdot ⋅ 表示用于融合来自两个分支的信息的元素乘积。然后,由两个堆叠的递归层组成的递归网络将从每一次单独的glimpse中收集的信息聚合在一起。递归层的输出为:
r t ( 1 ) = f r e c ( 1 ) ( g t , r t − 1 ( 1 ) ) r_t^{(1)}=f_{rec}^{(1)}(g_t,r_{t-1}^{(1)}) rt(1)=frec(1)(gt,rt−1(1))
r t ( 2 ) = f r e c 2 ( r t ( 1 ) , r t − 1 ( 2 ) ) r_t^{(2)}=f_{rec}^{2}(r_t^{(1)},r_{t-1}^{(2)}) rt(2)=frec2(rt(1),rt−1(2))
给定递归网络的当前隐藏状态 r t ( 2 ) r_t^{(2)} rt(2),发射网络预测下一次glimpse的位置。形式上,它可以写成:
l t + 1 = f e m i s ( r t ( 2 ) ) l_{t+1}=f_{emis}(r_t^{(2)}) lt+1=femis(rt(2))
最后,分类网络根据循环网络的隐藏状态 r t ( 1 ) r_t^{(1)} rt(1) 输出类标签 y y y 的预测:
y = f c l s ( r t ( 1 ) ) y=f_{cls}(r_t^{(1)}) y=fcls(rt(1))
与在整个图像上操作的 CNN 相比,所提出模型的计算成本要低得多,并且可以自然地处理不同大小的图像,因为它只在每一步处理一个glimpse。此外,通过循环注意机制提高了鲁棒性,也缓解了过拟合问题。该管道可以并入任何最先进的CNN骨干或RNN单元。
3.3.3、Hard and soft attention
https://arxiv.org/pdf/1502.03044

为了可视化图像标题生成模型应该关注的位置和内容,Xu等人引入了一个基于注意的模型以及两种不同的注意机制,硬注意和软注意(Show, Attend and Tell: Neural Image Caption Generation with Visual Attention)。
给定一组特征向量 a = a 1 , . . . , a L , a i ∈ R D a=a_1,...,a_L,a_i\in R^D a=a1,...,aL,ai∈RD从输入图像中提取特征,该模型旨在通过在每个时间步长生成一个单词来生成字幕。因此,他们采用长短时记忆(LSTM)网络作为解码器;注意力机制用于生成以特征集a和先前隐藏状态 h t − 1 h_{t-1} ht−1为条件的上下文向量 z t z_t zt,其中 t t t表示时间步长。形式上,第 t t t个时间步的特征向量 a i a_i ai的权重 α t , i α_{t,i} αt,i ,定义为:
e t , i = f a t t ( a i , h t − 1 ) e_{t,i}=f_{att}(a_i,h_{t-1}) et,i=fatt(ai,ht−1)
α t , i = e x p ( e t , i ) ∑ k = 1 L e x p ( e t , k ) \alpha_{t,i}=\frac{exp(e_{t,i})}{\sum_{k=1}^Lexp(e_{t,k})} αt,i=∑k=1Lexp(et,k)exp(et,i)
其中 $f_{att} $由以先前隐藏状态 h t − 1 h_{t-1} ht−1 为条件的多层感知器实现。正权重 α t , i α_{t,i} αt,i可以解释为位置 i i i 是关注(硬注意)的正确位置的概率,或者作为位置 i i i 对下一个单词的相对重要性(软注意力)。
为了获得上下文向量 z t z_t zt,硬注意力机制分配一个由 { α t , i \alpha_{t,i} αt,i} 参数化的多维分布,并将 z t z_t zt 视为随机变量:
p ( s t , i = 1 ∣ a , h t − 1 ) = α t , i p(s_{t,i}=1|a,h_{t-1})=\alpha_{t,i} p(st,i=1∣a,ht−1)=αt,i
z t = ∑ i = 1 L s t , i a i z_t=\sum_{i=1}^Ls_{t,i}a_i zt=i=1∑Lst,iai
另一方面,软注意机制直接使用上下文向量的期望 z t z_t zt
z t = ∑ i = 1 L α t , i a i z_t=\sum_{i=1}^L\alpha_{t,i}a_i zt=i=1∑Lαt,iai
注意力机制的使用通过允许用户理解模型关注的是什么以及在哪里,从而改进了图像字幕生成过程的可解释性。它还有助于提高网络的代表性能力。
3.3.4、Attention Gate
https://arxiv.org/pdf/1804.03999


以往的磁共振分割方法通常是在特定的感兴趣区域(ROI)上操作,这需要过度和浪费计算资源和模型参数。为了解决这个问题,Oktay等人提出了一种简单而有效的机制–注意力门(AG),用于聚焦目标区域,同时抑制无关区域中的特征激活。(Attention U-Net: Learning Where to Look for the Pancreas
Ozan)
给定输入特征映射X和选通信号 G ∈ R C ′ × H × W G\in R^{C'\times H\times W} G∈RC′×H×W,它是以粗略尺度收集的,包含上下文信息,注意力门使用附加注意力来获得门控系数。
首先将输入X和门控信号线性映射到 R F × H × W R^{F\times H\times W} RF×H×W维度空间,然后将输出在通道域中进行压缩,得到一个空间注意力权重图 S ∈ 1 × H × W S\in 1\times H\times W S∈1×H×W。整个过程可以写成:
S = σ ( ψ ( δ ( ϕ x ( X ) + ϕ g ( G ) ) ) ) S=\sigma(\psi(\delta(\phi_x(X)+\phi_g(G)))) S=σ(ψ(δ(ϕx(X)+ϕg(G))))
Y = S X Y=SX Y=SX
其中$\psi,\phi_x,和\phi_g $是线性变换,实现为 1 × 1 1\times1 1×1卷积。
注意门将模型的注意力引导到重要区域,同时抑制不相关区域的特征激活。由于其轻量化设计,在不显著增加计算成本或模型参数数量的情况下,大大增强了模型的表示能力。它具有通用性和模块化,使其易于在各种CNN模型中使用。
3.3.5、STN
https://arxiv.org/pdf/1506.02025

平移不变性使CNN适合于处理图像数据。然而,CNN缺乏其他变换不变性,如旋转不变性、缩放不变性和扭曲不变性。为了在使CNN关注重要区域的同时实现这些属性,Jaderberg等人提出了空间变换网络(STN),该网络使用显式程序学习平移、缩放、旋转和其他更一般扭曲的不变性,使网络关注最相关的区域。STN是第一个明确预测重要区域并提供具有变换不变性的深层神经网络的注意力机制。
以2D图像为例,2D仿射变换可以表示为:
[ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] = f l o c ( U ) \begin{bmatrix} \theta_{11}&\theta_{12}&\theta_{13}\\ \theta_{21}&\theta_{22}&\theta_{23}\\ \end{bmatrix} =f_{loc}(U) [θ11θ21θ12θ22θ13θ23]=floc(U)
( x i s y i s ) = [ θ 11 θ 12 θ 13 θ 21 θ 22 θ 23 ] ( x i t y i t 1 ) \left(\begin{matrix} x_i^s\\ y_i^s \end{matrix} \right)=\begin{bmatrix} \theta_{11}&\theta_{12}&\theta_{13}\\ \theta_{21}&\theta_{22}&\theta_{23}\\ \end{bmatrix} \left(\begin{matrix} x_i^t\\ y_i^t\\ 1 \end{matrix} \right) (xisyis)=[θ11θ21θ12θ22θ13θ23] xityit1
U U U是输入特征映射, f l o c f_{loc} floc可以是任何可微函数,例如轻量级全连接网络或卷积神经网络。 x i s x_i^s xis和 y i s y^s_i yis是输出特征映射中的坐标, 而 x i t x^t_i xit和 y i t y^t_i yit是输入特征映射中的对应坐标, θ \theta θ 矩阵是可学习的仿射矩阵。获得对应的数值之后,网络可以使用该对应对相关输入区域进行采样。为了确保整个过程是可微的,并且可以以端到端的方式进行更新,使用双线性采样对输入特征进行采样。STN自动关注区分区域,并学习对某些几何变换的不变性。
3.3.6、Deformable Convolutional Networks
https://arxiv.org/pdf/1703.06211



出于与STN类似的目的,Dai等人提出了可变形卷积网络(可变形卷积网络)对几何变换保持不变,但它们以不同的方式关注重要区域。 可变形网络不学习仿射变换。他们将卷积分为两步,首先从输入特征映射中对规则网格R上的特征进行采样,然后使用卷积核通过加权求和对采样特征进行聚合。该过程可以写成:
Y ( p 0 ) = ∑ p i ∈ R ω ( p i ) X ( p 0 + p i ) Y(p_0)=\sum_{p_i\in R}\omega(p_i)X(p_0+p_i) Y(p0)=pi∈R∑ω(pi)X(p0+pi)
R = ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 1 , 1 ) R={(-1,-1),(-1,0),...,(1,1)} R=(−1,−1),(−1,0),...,(1,1)
可变形卷积通过引入一组可学习的偏移来增强采样过程, ∆ p i ∆pi ∆pi可以由一个轻量级的CNN生成。使用偏移量 ∆ p i ∆pi ∆pi,可变形卷积可以表示为:
Y ( p 0 ) = ∑ p i ∈ R ω ( p i ) X ( p 0 + p i + ∆ p i ) Y(p_0)=\sum_{p_i\in R}\omega(p_i)X(p_0+p_i+∆p_i) Y(p0)=pi∈R∑ω(pi)X(p0+pi+∆pi)
通过上述方法,实现了自适应采样。然而 ∆ p i ∆pi ∆pi 是一个不适合网格采样的浮点值。为了解决这个问题,使用了双线性插值。还使用了可变形的RoI池,这大大提高了对象检测的性能。
可变形神经网络自适应地选择重要区域,扩大卷积神经网络的有效感受野;这在目标检测和语义分割任务中很重要。
3.3.7、Self-attention and variants
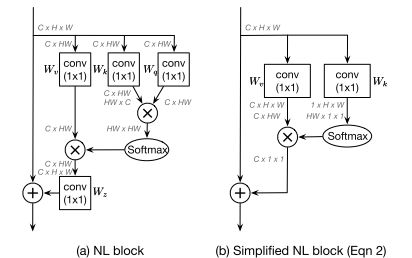
自注意力被提出后,在自然语言处理(NLP)领域取得了巨大成功。最近,它还显示出成为计算机视觉领域主导工具的潜力。通常,自注意力被用作一种空间注意机制来捕捉全局信息。由于卷积运算的局限性,CNN固有的感受野狭窄,这限制了CNN全面理解场景的能力。为了增加感受野,Wang等人将自注意力引入计算机视觉。
以二维图像为例,给出了特征映射 F ∈ R C × H × W F\in R^{C×H×W} F∈RC×H×W,self-attention首先通过线性投影和整形操作计算查询、键和值 Q , K , V ∈ R C ′ × N , N = H × W Q,K,V\in R^{C'\times N},N=H\times W Q,K,V∈RC′×N,N=H×W。自注意力可以表述为:
A = ( a ) i , j = S o f t m a x ( Q K T ) A=(a)_{i,j}=Softmax(QK^T) A=(a)i,j=Softmax(QKT)
Y = A V Y=AV Y=AV
A ∈ R N × N A\in{R^{N×N}} A∈RN×N是注意力矩阵, α i , j \alpha_{i,j} αi,j是 i t h i_{th} ith和 j t h j_{th} jth元素之间的关系。整个过程如图7(左)所示。

然而,自我注意机制有几个缺点,尤其是它的二次复杂性,这限制了它的适用性。已经引入了几个变种来缓解这些问题,disentangled non-local(解缠的非局部方法)提高了自我注意的准确性和有效性,但大多数变体侧重于降低其计算复杂性。
计算机视觉中的自注意力机制及其常见变体简介如下:
1、CCNet
https://arxiv.org/pdf/1811.11721

CCNet将自注意操作视为一个图卷积,用几个稀疏连接图代替自注意处理的密集连接图。为此,它提出了交叉式注意,它反复考虑行注意和列注意,以获取全局信息。CCNet将自注意力的复杂度从 O ( N 2 ) O(N^2) O(N2)降低到 O ( N N ) O(N\sqrt{N}) O(NN)。
2、EMANet
https://arxiv.org/pdf/1907.13426

EMANet[40]从期望最大化(EM)的角度来看待自注意力。提出了EM-attention算法,采用EM算法得到一组紧凑的基,而不是使用所有的点作为重构基。这将复杂性从 O ( n 2 ) O(n^2) O(n2)降低到 O ( N K ) O(NK) O(NK),其中K是紧凑基的数量。
3、ANN
https://arxiv.org/pdf/1908.07678

ANN认为使用所有位置特征作为键和向量是多余的,并采用空间金字塔池化来获得几个具有代表性的键和值特征来代替,以减少计算量。
4、GCNet
https://arxiv.org/pdf/1904.11492
分析了自注意力中使用的注意特征图,发现在同一幅图像中,通过自注意力获得的全局上下文对于不同的查询位置是相似的。因此,它首先提出预测所有查询点共享的单个特征图,然后根据该注意图从输入特征的加权和中获取全局信息。这类似于平均池化,但却是一个收集全局信息的过程。
5、 A 2 A^2 A2Net
https://arxiv.org/pdf/1810.11579

A2Net的动机是SENet,使用两种不同的注意力,将注意力分为特征收集和特征分布过程。第一种是通过二阶注意池聚集全局信息,第二种是通过软选择注意来分发全局描述符。
6、GloRe
https://arxiv.org/pdf/1811.12814

从图形学习的角度理解自注意力机制。它首先将N个输入特征收集到 M < < N M<
7、OCRNet
https://arxiv.org/pdf/1909.11065

提出了对象上下文表示的概念,它是同一类别中所有对象区域表示的加权聚合,例如所有汽车区域表示的加权平均值。它用这种对象上下文表示替换了键和向量,从而成功地提高了速度和效率。
8、HamNet
https://arxiv.org/pdf/2109.04553

将捕获全局关系建模为一个低秩问题,并设计了一系列白盒方法来使用矩阵分解捕获全局上下文。这不仅降低了复杂性,而且增加了自我关注的可解释性。
9、EANet
https://arxiv.org/pdf/2105.02358

自注意力只应考虑单个样本中的相关性,而应忽略不同样本之间的潜在关系。为了探索不同样本之间的相关性并减少计算量,它利用外部注意力,采用可学习、轻量级和共享的键和值向量。它进一步揭示了使用softmax规范化注意图并不是最优的,并且提出了双重规范化作为更好的选择。
10、SASA
https://arxiv.org/pdf/1906.05909
除了作为CNN的一种补充方法,自注意力还可以用来代替卷积运算来聚集邻域信息。卷积运算可以表示为输入特征X和卷积核W之间的点积:
Y i , j c = ∑ a , b ∈ 0 , . . . , k − 1 W a , b , c X a ^ , b ^ Y_{i,j}^c=\sum_{a,b\in{0,...,k-1}}W_{a,b,c}X_{\hat{a},\hat{b}} Yi,jc=a,b∈0,...,k−1∑Wa,b,cXa^,b^
其中:
a ^ = i + a − ⌊ k / 2 ⌋ , b ^ = j + b − ⌊ k / 2 ⌋ \hat{a}=i+a-\lfloor k/2\rfloor,\hat{b}=j+b-\lfloor k/2\rfloor a^=i+a−⌊k/2⌋,b^=j+b−⌊k/2⌋
k k k是内核大小, c c c表示通道。上述公式可以被视为通过卷积核使用加权和来聚集邻域信息的过程。聚合邻域信息的过程可以更一般地定义为:
Y i , j c = ∑ a , b ∈ 0 , . . . , k − 1 R e l ( i , j , a ^ , b ^ ) f ( X a ^ , b ^ ) Y_{i,j}^c=\sum_{a,b\in{0,...,k-1}}Rel(i,j,\hat{a},\hat{b})f(X_{\hat{a},\hat{b}}) Yi,jc=a,b∈0,...,k−1∑Rel(i,j,a^,b^)f(Xa^,b^)
其中 R e l ( i , j , a ^ , b ^ ) Rel(i,j,\hat{a},\hat{b}) Rel(i,j,a^,b^)为位置 ( i , j ) (i,j) (i,j)与位置 ( a , b ) (a, b) (a,b)之间的关系。根据这个定义,局部自我关注是一个特例。
例如,SASA将其写为:
Y i , j = ∑ a , b ∈ N k ( i , j ) S o f t m a x a b ( q i j T k a b + q i j r a − b , b − j ) v a b Y_{i,j}=\sum_{a,b\in \mathcal{N}_k(i,j)}Softmax_{ab}(q_{ij}^Tk_{ab}+q_{ij}r_{a-b,b-j})v_{ab} Yi,j=a,b∈Nk(i,j)∑Softmaxab(qijTkab+qijra−b,b−j)vab
其中 q , k , v q,k,v q,k,v是输入特征 x x x的线性投影, r a − i , b − j r_{a−i,b−j} ra−i,b−j是 ( i , j ) (i, j) (i,j)和 ( a , b ) (a, b) (a,b)的相对位置嵌入。
我们现在考虑几个使用局部自注意作为基本神经网络块的具体工作
SASA [43] 表明,使用自注意力来收集全局信息的计算量太大,而是采用局部自注意力来替换 CNN 中的所有空间卷积。作者表明,这样做提高了速度,参数的数量和结果的质量。他们还探讨了位置嵌入的行为,并表明相对位置嵌入[160]是合适的。他们的工作还研究了如何将局部自关注与卷积结合起来。
11、LR-Net
https://arxiv.org/pdf/1904.11491

LR-Net与SASA同时出现。研究了如何利用局部自注意对局部关系进行建模。综合研究了位置嵌入、核大小、外观可组合性和对抗性攻击的影响。
12、SAN
https://arxiv.org/pdf/2004.13621

SAN探索了两种利用注意力进行局部特征聚合的模式,即成对模式和补丁模式。它提出了一种在内容和渠道上都适应的新型矢量注意,并从理论和实践上评估了其有效性。除了在图像域提供显著改进外,它还被证明在3D点云处理中很有用。
3.3.8、Vision Transformers
Transformers在自然语言处理方面取得了巨大的成功,最近,iGPT和DETR证明了基于Transformers的模型在计算机视觉中的巨大潜力。受此启发,Dosovitskiy等人提出了视觉转换器(vision transformer, ViT),这是第一个用于图像处理的纯转换器架构。它能够获得与现代卷积神经网络相当的结果。
如图7所示,ViT的主要部分是多头注意(MHA)模块。MHA以序列作为输入。它首先将一个类标记与输入特征连接起来 F ∈ R N × C F\in R^{N\times C} F∈RN×C,其中 N 是像素数。然后它通过线性投影得到 Q , K ∈ R N × C ′ 和 V ∈ R N × C Q,K\in R^{N ×C'}和V\in R^{N ×C} Q,K∈RN×C′和V∈RN×C。接下来,Q、K和V被分为通道域中的H个头,并对它们分别施加自我关注。MHA方法如图8所示。ViT堆叠了许多具有完全连接层、归一化层和GELU激活函数的MHA层。

VIT表明,对于JFT-300和ImageNet-21K这样的大数据集,纯粹的基于注意力的网络可以取得比卷积神经网络更好的结果。
3.3.9、GENet
https://arxiv.org/pdf/1810.12348

受SENet的启发,Hu等人设计了GENet,通过在空间域中提供重新校准功能来捕获远程空间上下文信息。GENet将部件收集和激励操作结合在一起。在第一步中,它聚集整体的输入特征,并建模不同空间位置之间的关系。在第二步中,它首先使用插值生成与输入特征图大小相同的注意力图。然后,将输入特征图中的每个位置乘以注意力图中相应的元素来缩放。这个过程可以用以下方式描述:
g = f g a t h e r ( X ) g=f_{gather}(X) g=fgather(X)
s = f e x c i t e ( g ) = σ ( I n t e r p ( g ) ) s=f_{excite}(g)=\sigma(Interp(g)) s=fexcite(g)=σ(Interp(g))
Y = s X Y=sX Y=sX
在这里, f g a t h e r f_{gather} fgather可以采用任何捕获空间相关性的形式,例如全局平均池或沿深度卷积的序列; I n t e r p ( ⋅ ) Interp(·) Interp(⋅)表示内插。GENet块是轻量级的,可以像SE块一样插入到每个残差单元中。它强调重要的特征,同时抑制噪音。
3.3.10、PSANet
https://openaccess.thecvf.com/content_ECCV_2018/papers/Hengshuang_Zhao_PSANet_Point-wise_Spatial_ECCV_2018_paper.pdf
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SSyWAGQq-1683177879286)(https://gitee.com/gly998_admin/images/raw/master/image-20230430174959786.png)]
在成功捕获卷积神经网络中的长程依赖关系的激励下,提出了新的PSANet框架来聚合全局信息。它将信息聚合建模为一种信息流,并提出了一种双向信息传播机制,使信息在全局范围内流动。 PSANet将信息聚合规定为:
z i = ∑ j ∈ Ω ( i ) F ( x i , x j , Δ i j ) x j z_i=\sum_{j\in\Omega(i)}F(x_i,x_j,\Delta_{ij})x_j zi=j∈Ω(i)∑F(xi,xj,Δij)xj
其中 Δ i j \Delta ij Δij表示 i i i和 j j j之间的位置关系。 F ( x i , x j , Δ i j ) F(xi,xj,\Delta ij) F(xi,xj,Δij)是考虑 x i 、 x j 和 Δ i j xi、xj 和 \Delta ij xi、xj和Δij 以控制从 j 到 i j到i j到i的信息流的函数。 Ω i \Omega i Ωi表示位置i的聚合邻域;如果我们希望捕获全局信息, Ω i \Omega i Ωi应该包括所有空间位置。
由于计算函数 F ( x i , x j , Δ i j ) F(xi,xj,\Delta ij) F(xi,xj,Δij)的复杂性,它被分解为近似值:
F ( x i , x j , Δ i j ) ≈ F Δ i j ( x i ) + F Δ i j ( x j ) F(x_i,x_j,\Delta_{ij})\approx F_{\Delta_{ij}}(x_i)+F_{\Delta_{ij}}(x_j) F(xi,xj,Δij)≈FΔij(xi)+FΔij(xj)
式55可化简为:
z i = ∑ j ∈ Ω ( i ) F Δ i j ( x i ) x j + ∑ j ∈ Ω ( i ) F Δ i j ( x j ) x j z_i=\sum_{j\in\Omega(i)}F_{\Delta_{ij}}(x_i)x_j+\sum_{j\in\Omega(i)}F_{\Delta_{ij}}(x_j)x_j zi=j∈Ω(i)∑FΔij(xi)xj+j∈Ω(i)∑FΔij(xj)xj
第一项可以看作是收集位置 i i i的信息,而第二项则是分配位置 j j j的信息。函数 F ∆ i j ( x i ) F_{∆ij}(x_i) F∆ij(xi)和 F ∆ i j ( x j ) F_{∆ij}(x_j) F∆ij(xj)可视为自适应注意权重。上述过程在强调相关特征的同时聚合全局信息。它可以添加到卷积神经网络的末端,作为一个有效的补充,大大提高语义分割。
3.4、Temporal Attention
时间注意力可以看作是一种决定何时注意的动态时间选择机制,因此通常用于视频处理。以前的工作经常强调如何捕捉短期和长期的跨帧特征依赖关系。在这里,我们首先总结具有代表性的时间注意机制,并具体说明表5中Eq. 1所描述的过程 g ( x ) g(x) g(x)和 f ( g ( x ) , x ) f(g(x),x) f(g(x),x),然后按照图4中的顺序讨论各种时间注意机制。

3.4.1、Self-attention and variants(GLTR)
https://openaccess.thecvf.com/content_ICCV_2019/papers/Li_Global-Local_Temporal_Representations_for_Video_Person_Re-Identification_ICCV_2019_paper.pdf
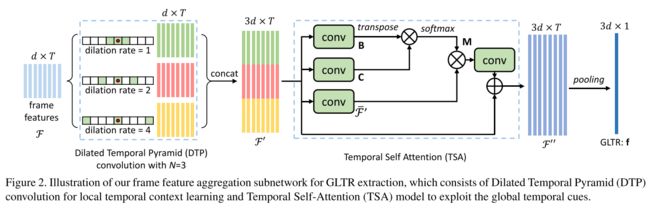
RNN和时间池或权重学习已广泛应用于视频表示学习以捕获帧间交互,但这些方法在效率或时间关系建模方面都有局限性。
为了克服这些问题,Li等人提出了一种全局局部时间表示(GLTR)来利用视频序列中的多尺度时间线索。GLTR由一个用于局部时间上下文学习的扩展时间金字塔(DTP)和一个用于捕获全局时间交互的时间自我注意模块组成。DTP采用扩张卷积,扩张率逐渐增加,以覆盖各种时间范围,然后将各种输出连接起来,汇总多尺度信息。给定输入帧特征 F = { f 1 , . . . , f T } F=\{f_1,...,f_T\} F={f1,...,fT}, DTP可以写成:
{ f 1 ( r ) , . . . , f T ( r ) } = D C o n v ( r ) ( F ) \{f_1^{(r)},...,f_T^{(r)}\}=DConv^{(r)}(F) {f1(r),...,fT(r)}=DConv(r)(F)
f t ’ = [ f t ( 1 ) ; . . . f t ( 2 n − 1 ) . . . ; f t ( 2 N − 1 ) ] f_t’=[f_t^{(1)};...f_t^{(2^{n-1})}...;f_t^{(2^{N-1})}] ft’=[ft(1);...ft(2n−1)...;ft(2N−1)]
式中 D C o n v ( r ) ( ⋅ ) DConv^{(r)}(·) DConv(r)(⋅)为扩张卷积,扩张速率为 r r r。自我注意机制采用卷积层,然后进行批量归一化和ReLU激活函数,根据输入的特征映射 F ′ = { f 1 ’ , . . . f T ′ } F'=\{f_1’,...f_T'\} F′={f1’,...fT′},生成查询 Q ∈ R d × T Q\in R^{d×T} Q∈Rd×T,键 K ∈ R d × T K\in R^{d×T} K∈Rd×T,值 V ∈ R d × T V\in R^{d×T} V∈Rd×T,可以写成
F o u t = g ( V S o f t m a x ( Q T K ) ) + F ′ F_{out}=g(VSoftmax(Q^TK))+F' Fout=g(VSoftmax(QTK))+F′
其中 g g g表示由卷积实现的线性映射。
来自相邻帧的短期上下文信息有助于区分视觉上相似的区域,而长期上下文信息有助于克服遮挡和噪声。GLTR结合了这两个模块的优点,增强了表示能力并抑制了噪音。它可以被纳入任何先进的CNN骨干网,为整个视频学习一个全局描述符。然而,自我关注机制有二次时间复杂性,限制了其应用。
3.4.2、TAM
https://arxiv.org/pdf/2005.06803


为了高效灵活地捕捉复杂的时间关系,Liu等提出了一种时间自适应模块(TAM)。TAM 有两个分支,一个本地分支和一个全局分支。给定输入特征图 X ∈ R C × T × H × W X\in R^{C×T×H×W} X∈RC×T×H×W ,首先将全局空间平均池化 GAP 应用于特征图,以确保 TAM 的计算成本较低。然后,TAM中的局部分支采用了几个具有ReLU非线性的一维卷积,在整个时域中产生位置敏感的重要性图,以增强帧的特征。本地分支可以写成:
s = σ ( C o n v 1 D ( δ ( C o n v 1 D ( G A P ( X ) ) ) ) ) s=\sigma(Conv1D(\delta(Conv1D(GAP(X))))) s=σ(Conv1D(δ(Conv1D(GAP(X)))))
X 1 = s X X^1=sX X1=sX
与局部分支不同,全局分支是位置不变的,专注于基于每个通道中的全局时间信息生成通道自适应内核。对于第 c c c个通道,内核可以写成:
θ = S o f t m a x ( F C 2 ( δ ( F C 1 ( G A P ( X ) c ) ) ) ) \theta=Softmax(FC_2(\delta(FC_1(GAP(X)_c)))) θ=Softmax(FC2(δ(FC1(GAP(X)c))))
其中 $\theta _c\in R^K $和 K K K是自适应内核大小。最后,TAM 将自适应内核$\theta $与 X o u t 1 X^1_{out} Xout1进行卷积:
Y = θ ⨂ X 1 Y=\theta \bigotimes X^1 Y=θ⨂X1
在局部分支和全局分支的帮助下,TAM 可以捕获视频中的复杂时间结构,并以更低的计算成本增强每帧特征。由于其灵活性和轻量级设计,TAM 可以添加到任何现有的 2D CNN 中。
3.5、Branch Attenion
分支注意可以被看作是一种动态的分支选择机制:注意哪些分支,与多分支结构一起使用。
3.5.1、Highway networks
https://arxiv.org/pdf/1507.06228
受长短期记忆网络的启发,Srivastava等人提出了Highway networks,该网络采用自适应选通机制,使信息能够跨层流动,以解决训练非常深层网络的问题。 假设一个普通的神经网络由L层组成,并且 H l ( X ) H_l(X) Hl(X)表示第L层上的非线性变换,那么Highway networks可以表示为:
Y l = H l ( X l ) T l ( X l ) + X l ( 1 − T l ( X l ) ) Y_l=H_l(X_l)T_l(X_l)+X_l(1-T_l(X_l)) Yl=Hl(Xl)Tl(Xl)+Xl(1−Tl(Xl))
T l ( X ) = σ ( W l T X + b l ) T_l(X)=\sigma(W_l^TX+b_l) Tl(X)=σ(WlTX+bl)
T 1 ( X ) T_1(X) T1(X)表示调节第l层的信息流的变换门。 X l X_l Xl和 Y l Y_l Yl是第 l l l层的输入和输出。
门控机制和跳跃连接结构使得使用简单的梯度下降方法直接训练非常深的Highway networks成为可能。与固定的跳过连接不同,门控机制适应输入,这有助于跨层路由信息。Highway networks可以合并到任何 CNN 中。
3.5.2、SKNet
https://arxiv.org/pdf/1903.06586

神经科学社区的研究表明,视觉皮层神经元根据输入刺激自适应地调整其感受野 (RF) 的大小。这启发了Li等人[114]提出了一种自动选择操作,称为选择性核(SK)卷积。
SK 卷积使用三种操作实现:拆分、融合和选择。在拆分过程中,将具有不同内核大小的转换应用于特征图以获得不同大小的 RF。然后将来自所有分支的信息通过元素求和合并在一起以计算门向量。这用于控制来自多个分支的信息流。最后,通过聚合由门向量引导的所有分支的特征图来获得输出特征图。这可以表示为:
U k = F k ( X ) k = 1 , . . . , K U_k=F_k(X)\ \ \ \ \ \ \ \ k=1,...,K Uk=Fk(X) k=1,...,K
U = ∑ k = 1 K U k U=\sum_{k=1}^KU_k U=k=1∑KUk
z = δ ( B N ( W G A P ( U ) ) ) z=\delta(BN(WGAP(U))) z=δ(BN(WGAP(U)))
s k ( c ) = e W k ( c ) z ∑ k = 1 K e W k ( c ) z k = 1 , . . . , K , c = 1 , . . . , C s_k^{(c)}=\frac{e^{W_k^{(c)}z}}{\sum_{k=1}^Ke^{W_k^{(c)}z}}\ \ \ \ \ k = 1, . . . , K, c = 1, . . . , C sk(c)=∑k=1KeWk(c)zeWk(c)z k=1,...,K,c=1,...,C
Y = ∑ k = 1 K s k U k Y=\sum_{k=1}^Ks_kU_k Y=k=1∑KskUk
在这里,每个变换 F k F_k Fk 都有一个唯一的内核大小来为每个分支提供不同尺度的信息。为了提高效率, F k F_k Fk 是通过分组或深度卷积实现的,然后是扩张卷积、批量归一化和 ReLU 激活。 t ( c ) t^{(c)} t(c) 表示向量 t 的第 c 个元素,或矩阵 t 的第 c 行。
SK 卷积使网络能够根据输入自适应地调整神经元的感受野(RF)大小,以很少的计算成本显着改善结果。SK卷积中的门机制用于融合来自多个分支的信息。由于其轻量级的设计,SK通过替换所有大核卷积,可以将卷积应用于任何 CNN 主干。
3.5.3、CondConv
https://arxiv.org/pdf/1904.04971
CNN中的一个基本假设是所有卷积核都是相同的。一般情况下增强网络表现力的典型方法是增加其深度或宽度,这会带来大量额外的计算成本。为了更有效地提高卷积神经网络的容量,Yang等人提出了一种新的多分支算子CondConv,可以定义一个普通的卷积 :
Y = W ∗ X Y=W*X Y=W∗X
∗ ∗ ∗ 表示卷积。所有样本的可学习参数W都相同。CondConv自适应地组合了多个卷积核,可以写成:
Y = ( α 1 W 1 + ⋯ + α n W n ) ∗ X Y=(\alpha_1W_1+\cdots+\alpha_nW_n)*X Y=(α1W1+⋯+αnWn)∗X
α \alpha α 是一个可学习的权重向量:
α = σ ( W r ( G A P ( X ) ) ) \alpha=\sigma(W_r(GAP(X))) α=σ(Wr(GAP(X)))
这个过程相当于多个experts的集合,如下图所示:

CondConv充分利用了多分支结构的优点,采用了一种计算量小的分支注意方法。它提供了一种有效提高网络容量的新方法。
3.5.4、Dynamic Convolution
https://arxiv.org/pdf/1912.03458

轻量级CNN极低的计算成本限制了网络的深度和宽度,进一步降低了其代表性。为了解决上述问题,Chen等人提出了动态卷积,这是一种新的算子设计,可以增加表征能力,但额外的计算成本可以忽略不计,并且不会与CondConv并行改变网络的宽度或深度。动态卷积使用K个大小和输入/输出维度相同的并行卷积核,而不是每层一个核。与SE块一样,它采用挤压和激励机制为不同的卷积核生成注意权重。这些卷积核通过加权求和动态聚合,并应用于输入特征映射X:
s = s o f m a x ( W 2 δ ( W 1 G A P ( X ) ) ) s=sofmax(W_2\delta(W_1GAP(X))) s=sofmax(W2δ(W1GAP(X)))
D y C o n v = ∑ i = 1 K s k C o n v k DyConv=\sum_{i=1}^{K}s_kConv_k DyConv=i=1∑KskConvk
Y = D y C O n v ( X ) Y=DyCOnv(X) Y=DyCOnv(X)
卷积通过卷积核的权重和偏差之和进行组合。
与将卷积应用于特征映射相比,压缩、激励和加权求和的计算成本极低。因此,动态卷积提供了一种有效的操作来提高表示能力,并且可以轻松地用作任何卷积的替代品。
3.6、Channel & Spatial Attention
通道和空间注意力结合了通道注意力和空间注意力的优势。它自适应地选择重要的对象和区域。残差注意力网络开创了通道和空间注意力领域,强调了信息特征在空间和通道维度上的重要性。它采用自下而上的结构,由几个卷积组成,生成一个3D(高度、宽度、通道)注意力图。然而,它有很高的计算成本和有限的接受领域。 为了利用全局空间信息,后来的工作中引入了全局平均池化,并将通道注意力和空间通道注意力解耦,从而增强了特征的辨别能力。
3.6.1、Residual Attention Network
https://arxiv.org/pdf/1704.06904

受ResNet的成功启发,Wang等人通过将注意机制与残差连接相结合,提出了非常深的卷积残差注意网络(RAN)。
堆叠在残差注意力网络中的每个注意力模块可分为掩码分支和主干分支。主干分支提取特征,并且可以由任何最先进的结构实现,包括预激活残差单元和初始模块。掩码分支使用自下而上自上而下的结构来学习与主干分支的输出特征具有相同大小的掩码。在两个1×1卷积层之后,sigmoid层将输出标准化为[0,1]。总的来说,残差注意力机制可以写成:
s = σ ( C o n v 2 1 × 1 C o n v 1 1 × 1 ( h u p ( h d o w n ( X ) ) ) ) s=\sigma(Conv_2^{1\times1}Conv_1^{1\times1}(h_{up}(h_{down}(X)))) s=σ(Conv21×1Conv11×1(hup(hdown(X))))
X o u t = s f ( X ) + f ( X ) X_{out}=sf(X)+f(X) Xout=sf(X)+f(X)
其中, h u p h_{up} hup是一种自下而上的结构,在残差单位之后使用多次最大池化来增加感受野,而 h d o w n h_{down} hdown是自上而下的部分,使用线性插值来保持输出大小与输入特征图相同。这两个部分之间也存在跳过连接,这在公式中被省略。 f f f 代表主干分支,可以是任何最先进的结构。
在每个注意力模块内部,自下而上,自上而下的前馈结构对空间和跨通道依赖性进行建模,从而实现一致的性能改进。残差注意力可以以端到端的训练方式融入任何深层网络结构。然而,提议的自下而上自上而下的结构未能利用全局空间信息。此外,直接预测3D注意力特征图的计算成本很高。
3.6.2、CBAM
https://arxiv.org/pdf/1807.06521

为了增强信息通道和重要区域,Woo等人提出了卷积块注意模块(convolutional block attention module, CBAM),该模块依次堆叠通道注意和空间注意。它将通道注意力图和空间注意力图解耦以提高效率,并通过引入全局池化来利用空间全局信息。
CBAM有两个顺序子模块,通道和空间。给定一个输入特征映射 X ∈ R C × H × W X\in R^{C×H×W} X∈RC×H×W,它依次推断出一个一维通道注意向量 s c ∈ R C s_c\in R^C sc∈RC和一个二维空间注意图 s s ∈ R H × W s_s\in R^{H×W} ss∈RH×W。通道注意子模块的公式类似于SE块的公式,只是它采用多种类型的池化操作来聚合全局信息。具体来说,它有两个并行分支,使用最大池和平均池操作:
F a v g c = G A P s ( X ) F_{avg}^c=GAP^s(X) Favgc=GAPs(X)
F m a x c = G M P s ( X ) F_{max}^c=GMP^s(X) Fmaxc=GMPs(X)
s c = σ ( W 2 δ ( W 1 F a v g c ) + W 2 δ ( W 1 F m a x c ) ) s_c=\sigma(W_2\delta(W_1F_{avg}^c)+W_2\delta(W_1F_{max}^c)) sc=σ(W2δ(W1Favgc)+W2δ(W1Fmaxc))
M c ( X ) = s c X M_c(X)=s_cX Mc(X)=scX
其中 G A P s GAP^s GAPs和 G M P s GMP^s GMPs 表示空间域中的全局平均池化和全局最大池化操作。空间注意子模块对特征之间的空间关系进行建模,是对通道注意的补充。与通道注意力不同,它应用具有大内核的卷积层来生成注意力图:
F a v g s = G A P c ( X ) F_{avg}^s=GAP^c(X) Favgs=GAPc(X)
F m a x s = G M P c ( X ) F_{max}^s=GMP^c(X) Fmaxs=GMPc(X)
s s = σ ( C o n v ( [ F a v g s ; F m a x s ] ) ) s_s=\sigma(Conv([F_{avg}^s;F_{max}^s])) ss=σ(Conv([Favgs;Fmaxs]))
M s ( X ) = s s X M_s(X)=s_sX Ms(X)=ssX
其中 C o n v ( ⋅ ) Conv(·) Conv(⋅) 表示卷积操作,而 G A P c GAP^c GAPc 和 G M P c GMP^c GMPc 是通道域中的全局池化操作。[] 表示通道的串联。整体注意力过程可以概括为:
X ′ = M c ( X ) X'=M_c(X) X′=Mc(X)
Y = M s ( X ′ ) Y=M_s(X') Y=Ms(X′)
依次结合通道注意力和空间注意力,CBAM 可以利用特征的空间和时间通道关系来判断网络要关注什么以及要关注的位置。更具体地说,它强调有用的通道和增强信息丰富的局部区域。由于其轻量级设计,CBAM可以无缝集成到任何CNN架构中,而额外成本可以忽略不计。然而,通道和空间注意机制仍有改进的空间。例如,CBAM 采用卷积来产生空间注意力图,因此空间子模块可能会受到有限的感受野的影响。
3.6.3、BAM
https://arxiv.org/pdf/1807.06514

Park等人与CBAM同时提出了瓶颈注意力模块(bottleneck attention module BAM),旨在有效提高网络的表征能力。它使用扩张卷积来扩大空间注意力子模块的感受野,并按照ResNet的建议构建瓶颈结构以节省计算成本。
对于给定的输入特征映射X,BAM推断通道注意 s c ∈ R C s_c\in R^C sc∈RC 与空间注意 s s ∈ R H × W s_s\in R^{H×W} ss∈RH×W将两个分支输出的大小调整为 R C × H × W R^{C\times H\times W} RC×H×W后,将两个注意力图相加。与SE块一样,通道注意力分支对特征映射应用全局平均池化来聚合全局信息,然后使用具有通道降维的MLP。为了有效地利用上下文信息,空间注意力分支结合了瓶颈结构和膨胀卷积。总的来说,BAM可以写成:
s c = B N ( W 2 ( W 1 G A P ( X ) + b 1 ) + b 2 ) s_c=BN(W_2(W_1GAP(X)+b_1)+b_2) sc=BN(W2(W1GAP(X)+b1)+b2)
s s = B N ( C o n v 2 1 × 1 ( D C 2 3 × 3 ( D C 1 3 × 3 ( C o n v 1 1 × 1 ( X ) ) ) ) ) s_s=BN(Conv_2^{1\times1}(DC_2^{3\times3}(DC_1^{3\times3}(Conv_1^{1\times1}(X))))) ss=BN(Conv21×1(DC23×3(DC13×3(Conv11×1(X)))))
s = σ ( E x p a n d ( s s ) + E x p a n d ( s c ) ) s=\sigma(Expand(s_s)+Expand(s_c)) s=σ(Expand(ss)+Expand(sc))
Y = s X + X Y=sX+X Y=sX+X
其中 W i 、 b i W_i、b_i Wi、bi分别表示全连接层的权重和偏置, C o n v 1 1 × 1 Conv_1^{1\times1} Conv11×1和 C o n v 2 1 × 1 Conv_2^{1\times1} Conv21×1 是用于通道缩减的卷积层。 D C i 3 × 3 DC_i^{3\times3} DCi3×3表示一个具有3×3核的膨胀卷积,用于有效利用上下文信息。扩展将注意力映射 s s s_s ss和 s c s_c sc扩展为 R C × H × W R^{C\times H\times W} RC×H×W。
BAM可以在空间和通道维度上强调或抑制特征,并提高有代表性的特征。应用于通道和空间注意力分支的降维使其能够与任何卷积神经网络集成,而只需很少的额外计算成本。然而,尽管膨胀卷积有效地扩大了感受野,但它仍然无法捕获远程上下文信息以及编码跨域关系。
3.6.4、scSE
https://arxiv.org/pdf/1808.08127.pdf

为了聚合全局空间信息,SE块对特征图应用全局池化。然而,它忽略了像素级的空间信息,这在密集预测任务中很重要。因此,Roy等人提出了空间和通道SE块(scSE)。与BAM一样,使用空间SE块作为SE块的补充,提供空间注意力权重,以关注重要区域。
给定输入特征映射X,将空间SE和通道SE两个并行模块应用于特征映射,分别对空间和通道信息进行编码。信道SE模块为普通SE块,而空间SE模块采用1×1卷积进行空间压缩。这两个模块的输出被融合。整个过程可以写成:
s c = σ ( W 2 δ ( W 1 G A P ( X ) ) ) s_c=\sigma(W_2\delta(W_1GAP(X))) sc=σ(W2δ(W1GAP(X)))
X c h n = s c X X_{chn}=s_cX Xchn=scX
s s = σ ( C o n v 1 × 1 ( X ) ) s_s=\sigma(Conv^{1\times1}(X)) ss=σ(Conv1×1(X))
X s p a = s s X X_{spa}=s_sX Xspa=ssX
Y = f ( X s p a , X c h n ) Y=f(X_{spa},X_{chn}) Y=f(Xspa,Xchn)
其中f表示融合函数,可以是最大值、加法、乘法或级联。 提出的scSE块结合了通道和空间注意力,以增强特征,并捕获像素级的空间信息。分割任务因此受益匪浅。在F-CNN中集成一个scSE块可以在语义切分方面取得一致的改进,而额外的成本可以忽略不计。
3.6.5、Triplet Attention
https://arxiv.org/pdf/2010.03045
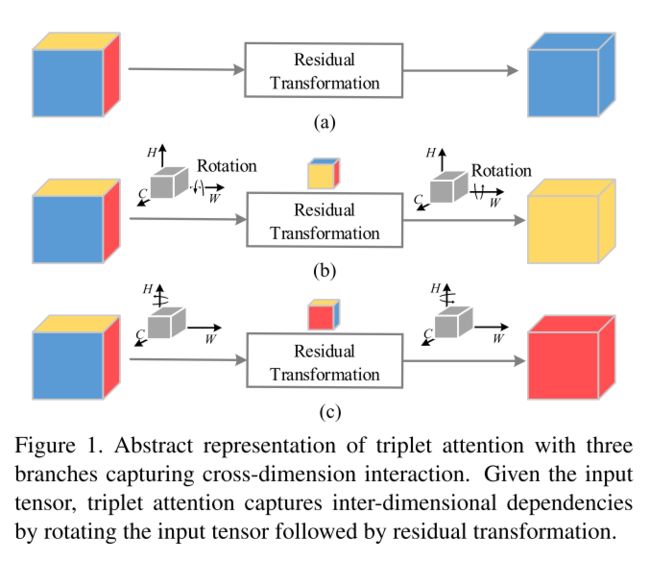
在CBAM和BAM中,通道注意和空间注意是独立计算的,忽略了这两个领域之间的关系。Misra等人受空间注意力的激励,提出了三重注意,这是一种轻量级但有效的注意机制,用于捕捉跨域交互。
给定一个输入特征映射X,三重注意使用三个分支,每个分支都在捕获H、W和C中任意两个域之间的跨域交互中发挥作用。在每个分支中,首先对输入应用沿不同轴的旋转操作,然后Z-pool层负责聚合零维信息。最后,一个内核大小为k×k的标准卷积层对最后两个领域之间的关系进行建模。这个过程可以写成:
X 1 = P m 1 ( X ) X_1=Pm_1(X) X1=Pm1(X)
X 2 = P m 2 ( X ) X_2=Pm_2(X) X2=Pm2(X)
s 0 = σ ( C o n v 0 ( Z − P o o l ( X ) ) ) s_0=\sigma(Conv_0(Z-Pool(X))) s0=σ(Conv0(Z−Pool(X)))
s 1 = σ ( C o n v 1 ( Z − P o o l ( X 1 ) ) ) s_1=\sigma(Conv_1(Z-Pool(X_1))) s1=σ(Conv1(Z−Pool(X1)))
s 2 = σ ( C o n v 2 ( Z − P o o l ( X 2 ) ) ) s_2=\sigma(Conv_2(Z-Pool(X_2))) s2=σ(Conv2(Z−Pool(X2)))
Y = 1 3 ( s 0 X + P m 1 − 1 ( s 1 X 1 ) + P m 2 − 1 ( s 2 X 2 ) ) Y=\frac{1}{3}(s_0X+Pm_1^{-1}(s_1X_1)+Pm_2^{-1}(s_2X_2)) Y=31(s0X+Pm1−1(s1X1)+Pm2−1(s2X2))
其中 P m 1 Pm_1 Pm1和 P m 2 Pm_2 Pm2表示分别沿H轴和W轴逆时针旋转90度。 P m − 1 Pm^{−1} Pm−1表示倒数。Z-Pool沿第零维连接最大池化和平均池化。
Y = Z − P o o l ( X ) = [ G M P ( X ) ; G A P ( X ) ] Y=Z-Pool(X)=[GMP(X);GAP(X)] Y=Z−Pool(X)=[GMP(X);GAP(X)]
与CBAM和BAM不同,三重态注意强调捕获跨域交互的重要性,而不是独立计算空间注意和通道注意。这有助于捕获丰富的区分性特征表示。由于其简单而高效的结构,三重态注意可以很容易地添加到经典骨干网络中。
3.6.6、SimAM
http://proceedings.mlr.press/v139/yang21o/yang21o.pdf

Yang等人强调了在提出SimAM时学习不同通道和空间领域的注意力权重的重要性,SimAM是一个简单、无参数的注意模块,能够直接估计3D权重,而不是扩展一维或二维权重。SimAM的设计基于著名的神经科学理论,因此无需手动微调网络结构。 受空间抑制现象的启发,他们提出应强调显示抑制效应的神经元,并将每个神经元的能量函数定义为:
e t ( w t , b t y , x i ) = ( y t − t ^ ) 2 + 1 M − 1 ∑ i = 1 M − 1 ( y o − x i ^ ) e_t(w_t,b_ty,x_i)=(y_t-\hat{t})^2+\frac{1}{M-1}\sum_{i=1}^{M-1}(y_o-\hat{x_i}) et(wt,bty,xi)=(yt−t^)2+M−11i=1∑M−1(yo−xi^)
式中, t ^ = w t t + b t , x i ^ = w t x i + b t , \hat{t}=w_tt+b_t, \hat{x_i} = w_tx_i+b_t, t^=wtt+bt,xi^=wtxi+bt, t t t 和 x i x_i xi分别为目标单位和同一通道内的所有其他单位; i ∈ 1 , . . . , N , 并且 N = H × W i\in1,...,N,并且 N=H\times W i∈1,...,N,并且N=H×W。
方程106存在最优闭型解:
e t ∗ = 4 ( σ ^ 2 + λ ) ( t − μ ^ ) 2 + 2 σ ^ 2 + 2 λ e_t^*=\frac{4(\hat{\sigma}^2+\lambda)}{(t-\hat{\mu})^2+2\hat{\sigma}^2+2\lambda} et∗=(t−μ^)2+2σ^2+2λ4(σ^2+λ)
其中, μ ^ \hat{\mu} μ^为输入特征的均值, σ ^ 2 \hat{\sigma}^2 σ^2为输入特征的方差。sigmoid 函数用于控制注意力向量的输出范围;应用元素乘积得到最终输出:
Y = S i g m o i d ( 1 E ) X Y=Sigmoid(\frac{1}{E})X Y=Sigmoid(E1)X
这项工作简化了注意力的设计过程,并成功地提出了一种基于数学和神经科学理论的新型三维无权重参数注意模型。
3.6.7、Coordinate attention
https://arxiv.org/pdf/2103.02907

SE块在建模跨通道关系之前使用全局池聚合全局空间信息,但忽略了位置信息的重要性。BAM和CBAM采用卷积来捕获局部关系,但无法建模长期依赖关系。为了解决这些问题,Hou等人提出了坐标注意力,这是一种新的注意机制,它将位置信息嵌入到通道注意中,从而使网络能够以较小的计算成本关注大的重要区域。 坐标注意力机制有两个连续的步骤:坐标信息嵌入和坐标注意力生成。首先,池化内核的两个空间范围对每个通道进行水平和垂直编码。在第二步中,对两个池化层的级联输出应用共享的1×1卷积变换函数。然后,坐标注意力将得到的张量拆分为两个独立的张量,以产生具有相同数量的通道注意力向量 ,用于输入X的水平和垂直坐标。这可以写成
z h = G A P h ( X ) z^h=GAP^h(X) zh=GAPh(X)
z w = G A P w ( X ) z^w=GAP^w(X) zw=GAPw(X)
f = δ ( B N ( C o n v 1 1 × 1 ( [ z h ; z w ] ) ) ) f=\delta(BN(Conv_1^{1\times1}([z^h;z^w]))) f=δ(BN(Conv11×1([zh;zw])))
f h , f w = S p l i t ( f ) f^h,f^w=Split(f) fh,fw=Split(f)
s h = σ ( C o n v h 1 × 1 ( f h ) ) s^h=\sigma(Conv_h^{1\times1}(f^h)) sh=σ(Convh1×1(fh))
s w = σ ( C o n v w 1 × 1 ( f w ) ) s^w=\sigma(Conv_w^{1\times1}(f^w)) sw=σ(Convw1×1(fw))
Y = X s h s w Y=Xs^hs^w Y=Xshsw
其中 G A P h GAP^h GAPh和 G A P w GAP^w GAPw表示垂直坐标和水平坐标的池化函数, s h ∈ R C × 1 × W 和 s w ∈ R C × W × 1 s^h\in R^{C\times1\times W}和s_w\in R^{C\times W\times1} sh∈RC×1×W和sw∈RC×W×1,代表相应的注意权重。 通过坐标注意力,网络可以准确地获得目标的位置。这种方法比BAM和CBAM有更大的感受野。与SE块一样,它还模拟了跨通道关系,有效地增强了学习功能的表达能力。由于其轻量级设计和灵活性,它可以轻松地用于 mobile networks的经典构建块。
3.6.8、DANet
https://arxiv.org/pdf/1809.02983

在场景分割领域,编码器-解码器结构不能利用对象之间的全局关系,而基于RNN的结构严重依赖于长期记忆的输出。为了解决上述问题,Fu等人提出了一种用于自然场景图像分割的新框架——双注意网络(DANet)。与CBAM和BAM不同,它采用自注意机制,而不是简单地叠加卷积来计算空间注意图,使网络能够直接捕获全局信息。
DANet并行使用位置注意模块和通道注意模块来捕获空间和通道域中的特征依赖关系。给定输入的特征图X,首先在位置注意模块中应用卷积层来获得新的特征图。然后,位置关注模块使用所有位置特征的加权和来选择性地聚合每个位置的特征,其中权重由对应位置对之间的特征相似性决定。通道注意模块除了通过降维来模拟跨通道关系外,具有类似的形式。最后将两个分支的输出进行融合,得到最终的特征表示。为简单起见,我们将特征映射X重塑为 C × ( H × W ) C × (H × W) C×(H×W),因此整个过程可以写成:
Q , K , V = W q X , W K X , W v X Q,\ K,\ V=W_qX,\ \ W_KX,\ \ W_vX Q, K, V=WqX, WKX, WvX
Y p o s = X + V S o f t m a x ( Q T K ) Y^{pos}=X+VSoftmax(Q^TK) Ypos=X+VSoftmax(QTK)
Y c h n = X + S o f t m a x ( X X T ) X Y^{chn}=X+Softmax(XX^T)X Ychn=X+Softmax(XXT)X
Y = Y p o s + Y c h n Y=Y^{pos}+Y^{chn} Y=Ypos+Ychn
其中 W q , W k , W v ∈ R C × C Wq, Wk, Wv\in R^{C×C} Wq,Wk,Wv∈RC×C用于生成新的特征图。
位置注意模块使DANet能够捕捉长距离的上下文信息,并从全局角度自适应地整合任何规模的类似特征,而通道注意模块则负责增强有用的信道以及抑制噪音。考虑到空间和通道的关系,明确地改进了场景分割的特征表示。然而,它的计算代价很高,尤其是对于大的输入要素地图。
3.6.9、RGA
https://arxiv.org/pdf/1904.02998

与强调捕捉长距离背景的坐标注意和DANet不同,在关系意识全局注意(RGA)中,Zhang等人强调由成对关系提供的全局结构信息的重要性,并利用它来产生注意图。
RGA有两种形式,空间RGA(RGA-S)和通道RGA(RGA-C)。RGA-S首先将输入特征映射X重塑为 C × ( H × W ) C×(H×W) C×(H×W)和成对关系矩阵 R ∈ R ( H × W ) × ( H × W ) R\in R^{(H\times W)\times (H\times W)} R∈R(H×W)×(H×W)的计算采用:
Q = δ ( W Q X ) Q=\delta(W^QX) Q=δ(WQX)
K = δ ( W K X ) K=\delta(W^KX) K=δ(WKX)
R = Q T K R=Q^TK R=QTK
位置 i i i 处的关系向量 r i r_i ri通过在所有位置叠加成对关系来定义:
r i = [ R ( i , : ) ; R ( : , i ) ] r_i=[R(i,:);R(:,i)] ri=[R(i,:);R(:,i)]
空间关系感知特征 y i y_i yi 可以写成:
Y i = [ g a v g c ( δ ( W φ x i ) ; δ ( W ϕ r i ) ) ] Y_i=[g_{avg}^c(\delta(W^{\varphi}x_i);\delta(W^{\phi}r_i))] Yi=[gavgc(δ(Wφxi);δ(Wϕri))]
其中 g a v g c g^c_{avg} gavgc 表示通道域中的全局平均池化。最后,位置 i i i 的空间注意力得分由:
a i = σ ( W 2 δ ( W 1 y i ) ) a_i=\sigma(W_2\delta(W_1y_i)) ai=σ(W2δ(W1yi))
GA-C与RGA-S的形式相同,只是将输入特征映射作为一组H×W维特征。RGA使用全局关系为每个特征节点生成注意力分数,从而提供有价值的结构信息并显著增强表征能力。RGA-S和RGA-C足够灵活,可用于任何CNN网络;Zhang等人建议按顺序联合使用它们,以更好地捕捉空间和跨通道关系。
3.6.10、Self-Calibrated Convolutions
https://openaccess.thecvf.com/content_CVPR_2020/papers/Liu_Improving_Convolutional_Networks_With_Self-Calibrated_Convolutions_CVPR_2020_paper.pdf

受分组卷积的成功启发,Liu提出了自校准卷积,作为一种在每个空间位置扩大感受野的方法。自校准卷积与标准卷积一起使用。它首先在通道域中将输入特征X划分为 X 1 X_1 X1和 X 2 X_2 X2。自校准卷积首先使用平均池化来减少输入大小并扩大感受野。
T 1 = A V G P o o l r ( X 1 ) T_1=AVGPool_r(X_1) T1=AVGPoolr(X1)
其中 r r r是池化核的大小和步幅。然后使用卷积对通道关系进行建模,并使用双线性插值算子 U p U_p Up对特征图进行上采样:
X 1 ′ = U p ( C o n v 2 ( T 1 ) ) X_1^{'}=Up(Conv_2(T_1)) X1′=Up(Conv2(T1))
接下来,元素相乘完成自校准过程:
Y 1 ′ = C o n v 3 ( X 1 ) σ ( X 1 + X 1 ′ ) Y_1^{'}=Conv_3(X_1)\sigma(X_1+X_1^{'}) Y1′=Conv3(X1)σ(X1+X1′)
最后,形成的输出特征映射为:
Y 1 = C o n v 4 ( Y 1 ′ ) Y_1=Conv_4(Y_1^{'}) Y1=Conv4(Y1′)
Y 2 = C o n v 1 ( X 2 ) Y_2=Conv_1(X_2) Y2=Conv1(X2)
Y = [ Y 1 ; Y 2 ] Y=[Y_1;Y_2] Y=[Y1;Y2]
这种自校准卷积可以扩大网络的接收范围,提高网络的适应性。它在图像分类和某些下游任务(如实例分割、目标检测和关键点检测)中取得了优异的效果。
3.6.11、SPNet
https://arxiv.org/pdf/2003.13328

空间池化通常在一个小区域上运行,这限制了它捕获远程依赖关系并将重点放在遥远区域的能力。为了克服这一点,Hou等人提出了 strip pooling,这是一种新的池化方法,能够在水平或垂直空间域中编码远程上下文。
strip pooling有两个分支用于水平和垂直strip pooling。水平strip pooling汇集部分首先汇集输入特征水平方向上的特征 F ∈ R C × H × W F\in R^{C\times H\times W} F∈RC×H×W
y 1 = G A P w ( X ) y^1=GAP^w(X) y1=GAPw(X)
然后在 y y y 中应用核大小为3的一维卷积来捕获不同行和通道之间的关系。重复W次,使输出 y v y_v yv与输入形状一致:
y h = E x p a n d ( C o n v 1 D ( y 1 ) ) y_h=Expand(Conv1D(y^1)) yh=Expand(Conv1D(y1))
垂直strip pooling以类似的方式执行。最后,两个分支的输出使用元素求和进行融合,以生成注意特征图:
s = σ ( C o n v 1 × 1 ( y v + y h ) ) s=\sigma(Conv^{1\times 1}(y_v+y_h)) s=σ(Conv1×1(yv+yh))
Y = s X Y=sX Y=sX
在混合池模块(MPM)中进一步开发了strip pooling模块(SPM)。两者都考虑空间和通道关系,以克服卷积神经网络的局部性。SPNet实现了几个复杂语义分割基准的最新结果。
3.6.12、SCA-CNN
https://arxiv.org/pdf/1611.05594

由于CNN具有自然的空间性、通道性和多层性,Chen等人提出了一种新的基于空间和通道性注意力的卷积神经网络(SCA-CNN)。它是为图像字幕的任务而设计的,并使用了一个编码器-解码器框架,其中CNN首先将输入图像编码为一个向量,然后LSTM将该向量解码为一个单词序列。给定输入特征映射X和上一时间步LSTM隐藏状态 h t − 1 ∈ R d h_{t-1}\in R^d ht−1∈Rd是一种空间注意机制,它在LSTM隐藏状态 h t − 1 h_{t−1} ht−1的指导下,更加关注语义有用的区域, 空间注意力模型为:
α ( h t − 1 , X ) = t a n h ( C o n v 1 1 × 1 ( X ) ⨁ W 1 h t − 1 ) \alpha(h_{t-1},X)=tanh(Conv_1^{1\times1}(X)\bigoplus W_1h_{t-1}) α(ht−1,X)=tanh(Conv11×1(X)⨁W1ht−1)
Φ ( h t − 1 , X ) = S o f t m a x ( C o n v 2 1 × 1 ( a ( h t − 1 , X ) ) ) \Phi(h_{t-1},X)=Softmax(Conv_2^{1\times1}(a(h_{t-1},X))) Φ(ht−1,X)=Softmax(Conv21×1(a(ht−1,X)))
⨁ \bigoplus ⨁ 表示矩阵和向量的加法。类似地,通道注意力首先聚合全局信息,然后使用隐藏状态计算通道注意力权重向量h h t − 1 h_{t−1} ht−1:
b ( h t − 1 , X ) = t a n h ( W 2 G A P ( X ) + b 2 ) ⨁ W 1 h t − 1 b(h_{t-1},X)=tanh(W_2GAP(X)+b_2)\bigoplus W_1h_{t-1} b(ht−1,X)=tanh(W2GAP(X)+b2)⨁W1ht−1
Φ ( h t − 1 , X ) = S o f t m a x ( W 3 ( b ( h t − 1 , X ) ) + h 3 ) \Phi(h_{t-1},X)=Softmax(W_3(b(h_{t-1},X))+h_3) Φ(ht−1,X)=Softmax(W3(b(ht−1,X))+h3)
总的来说,SCA机制可以用两种方式之一编写。如果在空间注意力之前应用通道注意力:
Y = f ( X , Φ s ( h t − 1 , X Φ c ( h t − 1 , X ) ) , Φ c ( h t − 1 , X ) ) Y=f(X,\Phi_s(h_{t-1},X\Phi_c(h_{t-1},X)),\Phi_c(h_{t-1},X)) Y=f(X,Φs(ht−1,XΦc(ht−1,X)),Φc(ht−1,X))
如果空间注意力最先被使用:
Y = f ( X , Φ s ( h t − 1 , X ) , Φ c ( h t − 1 , X Φ s ( h t − 1 , X ) ) ) Y=f(X,\Phi_s(h_{t-1},X),\Phi_c(h_{t-1},X\Phi_s(h_{t-1},X))) Y=f(X,Φs(ht−1,X),Φc(ht−1,XΦs(ht−1,X)))
f ( ⋅ ) f(⋅) f(⋅)表示调制函数,该函数将特征映射X和注意映射作为输入,然后输出调制后的特征映射Y。 与以前的注意机制不同,SCA Net平等地考虑每个图像区域,并使用全局空间信息告知网络关注的位置,SCA Net利用语义向量生成空间注意力特征图以及通道方向的注意权重向量。SCA-CNN不仅仅是一个强大的注意力模型,它还提供了一个更好的理解,即在句子生成过程中,该模型应该关注的地方和内容。
3.6.13、GALA
https://arxiv.org/pdf/1805.08819
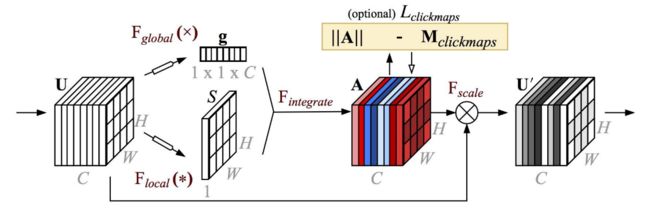
大多数注意力机制只使用来自类别标签的微弱监督信号来学习关注点,这启发了Linsley等人研究显性人类监督如何影响注意力模型的表现和可解释性。作为概念证明,Linsley等人提出了全局和局部注意力(GALA)模块,该模块通过空间注意机制扩展了SE块。
给定输入功能映射X,GALA使用一个注意力掩码,将全局和本地注意力结合起来,告诉网络关注的位置和内容。在SE块中,全局注意力通过全局平均池化聚合全局信息,然后使用多层感知器生成通道方向的注意力权重向量。在局部注意力中,对输入进行两次连续的1×1卷积以生成位置权重图。局部和全局路径的输出通过加法和乘法进行组合。GALA可以表示为:
s g = W 2 δ ( W 1 G A P ( x ) ) s_g=W_2\delta(W_1GAP(x)) sg=W2δ(W1GAP(x))
s l = C o n v 2 1 × 1 ( δ ( C o n v 1 1 × 1 ( X ) ) ) s_l=Conv_2^{1\times1}(\delta(Conv_1^{1\times1}(X))) sl=Conv21×1(δ(Conv11×1(X)))
s g ∗ = E x p a n d ( s g ) s_g^*=Expand(s_g) sg∗=Expand(sg)
s l ∗ = E x p a n d ( s l ) s_l^*=Expand(s_l) sl∗=Expand(sl)
s = t a n h ( a ( s g ∗ + s l ∗ ) + m ⋅ ( s h ∗ s l ∗ ) ) s=tanh(a(s_g^*+s_l^*)+m\cdot(s_h^*s_l^*)) s=tanh(a(sg∗+sl∗)+m⋅(sh∗sl∗))
Y = s X Y=sX Y=sX
a , m ∈ R C a,m\in R^C a,m∈RC是表示通道权重向量的可学习参数。 在人工提供的功能重要性地图的监督下,GALA显著提高了代表性,可以与任何CNN主干网结合。
3.7、Spatial & Temporal Attention
时空注意结合了空间注意和时间注意的优点,因为它自适应地选择重要区域和关键帧。

3.7.1、STA-LSTM
https://arxiv.org/pdf/1611.06067


在人类动作识别中,每种类型的动作一般只取决于几个特定的运动关节。此外,随着时间的推移,可能会执行多个动作。在这些观察的推动下,Song等人提出了一种基于LSTM的时空联合注意网络,自适应地发现区分特征和关键帧。其主要关注点是空间关注子网络和时间关注子网络,空间关注子网络用于选择重要区域,时间关注子网络用于选择关键帧。空间注意子网络可以写成:
s t = U s t a n h ( W x s X t + W h s h t − 1 s + b s i ) + b s o s_t=U_stanh(W_{xs}X_t+W_{hs}h_{t-1}^s+b_{si})+b_{so} st=Ustanh(WxsXt+Whsht−1s+bsi)+bso
α t = S o f t m a x ( s t ) \alpha_t=Softmax(s_t) αt=Softmax(st)
Y t = α t X t Y_t=\alpha_tX_t Yt=αtXt
其中 X t X_t Xt是时刻 t t t 的输入特征, U s , W h s , b s i , b s o U_s,W_{hs},b_{si},b_{so} Us,Whs,bsi,bso,是可学习的参数, h t − 1 s h_{t-1}^s ht−1s是步长 t − 1 t−1 t−1处的隐藏状态。注意,隐藏状态 h h h的使用意味着注意过程考虑了时间关系。时间注意子网络类似于空间分支,并使用以下方法生成其注意图:
β = δ ( W x p X t + W h p h t − 1 p + b p ) \beta_=\delta(W_{xp}X_t+W_{hp}h_{t-1}^p+b_p) β=δ(WxpXt+Whpht−1p+bp)
为了便于优化,它采用了ReLU函数而不是规范化函数。它还使用正则化目标函数来提高收敛性。总的来说,本文提出了一种联合时空注意方法,将重点放在重要的关节和关键帧上,在动作识别任务上取得了很好的效果。
3.7.2、RSTAN
Recurrent Spatial-Temporal Attention Network for Action Recognition in Videos | IEEE Journals & Magazine | IEEE Xplore
为了在视频帧中捕获时空上下文,Du等人。[16]引入时空注意,以全局方式自适应地确定关键特征。
RSTAN中的时空注意机制由空间注意模块和时间注意模块组成。给定输入特征映射 X ∈ R d × T × H × W X\in R^{d×T×H×W} X∈Rd×T×H×W和RNN模型的先前隐藏状态 h t − 1 h_{t−1} ht−1,时空注意的目标是为动作识别产生时空特征表征。首先,将给定的特征映射X重构为 R D × T × ( H × W ) R^{D\times T\times (H\times W)} RD×T×(H×W),定义 X ( n , k ) X(n, k) X(n,k)为第 n n n 帧的第 k k k 个位置的特征向量。在时间 t t t ,空间注意机制的目的是为每一帧产生一个全局特征 l n l_n ln,它可以写为:
α t ( n , k ) = ω α t a n h ( W h h t − 1 + W x X ( n , k ) + b α ) \alpha_t(n,k)=\omega_{\alpha}tanh(W_hh_{t-1}+W_xX(n,k)+b_{\alpha}) αt(n,k)=ωαtanh(Whht−1+WxX(n,k)+bα)
α t ∗ ( n , k ) = e γ α α t ( n , k ) / ∑ j = 1 W × H e γ α α t ( n , k ) \alpha_t^*(n,k)=e^{\gamma_\alpha\alpha_t(n,k)}/\sum_{j=1}^{W\times H}e^{\gamma_\alpha\alpha_t(n,k)} αt∗(n,k)=eγααt(n,k)/j=1∑W×Heγααt(n,k)
l n = ∑ k = 1 H × W α t ∗ ( n , k ) X ( n , k ) l_n=\sum_{k=1}^{H\times W}\alpha_t^*(n,k)X(n,k) ln=k=1∑H×Wαt∗(n,k)X(n,k)
其中引入 γ α \gamma_\alpha γα来控制位置分数图的清晰度。在获得逐帧特征 { l 1 , . . . , l T } \{l_1,...,l_T\} {l1,...,lT} 后,RSTAN使用一种时间注意机制来估计每个帧特征的重要性:
β t ( n ) = ω β t a n h ( W h ′ h t − 1 + W l l ( n ) + b β ) \beta_t(n)=\omega_\beta tanh(W_h^{'}h_{t-1}+W_ll(n)+b_\beta) βt(n)=ωβtanh(Wh′ht−1+Wll(n)+bβ)
β t ∗ ( n ) = e γ β β t ( n ) / ∑ j = 1 T e γ β β t ( n ) \beta_t^*(n)=e^{\gamma_\beta\beta_t(n)}/\sum_{j=1}^Te^{\gamma_\beta\beta_t(n)} βt∗(n)=eγββt(n)/j=1∑