共识协议的技术变迁 - 既要“高”容错,又要“易”定序,还要“好”理解
There is no compression algorithm for experience. -- Andy Jassy, CEO of AWS
一、缘起
共识协议,对于从事分布式系统研发的同学们来说真可谓是最熟悉的陌生人。一方面,共识协议面向有状态分布式系统的数据一致性与服务容错性这两大难题提供了近乎完美的解决方案,绝大部分同学或多或少听说过/研究过/使用过/实现过Paxos/Raft等经典共识协议;另一方面,共识协议的确很复杂,事实上,学习并弄懂共识协议原理倒是没有那么难,但是要在实际系统中用好用正确共识协议绝非易事,共识领域里面的“双主脑裂”,“幽灵复现”等传说,也让很多同学望而生畏。这篇文章与读者朋友们好好聊一聊共识这个技术领域,期望能够让大伙儿对共识协议的前世今生以及这些年的技术演进有个大体了解。虽说经验这种东西没有压缩算法,得自身一点一点实践过才真正算数,但是认知学习是可以加速的,所谓:今日格一物,明日又格一物,豁然贯通,终知天理。
我们知道,分布式系统最朴实的目标是把一堆普通机器的计算/存储等能力整合到一起,然后整体上能够像一台超级机器一样对外提供可扩展的读写服务,设计原则上要实现即使其中的部分机器发生故障,系统整体服务不受影响。对于有状态的分布式系统而言,实现上述容错性目标的有效手段绕不开大名鼎鼎的复制状态机。该模型的原理是为一个服务器集合里的每台服务器都维护着相同机制的确定有限状态机(DFSM,Determinate Finite State Machine),如果能够保障每个状态机输入的是完全一致的命令序列,那么这个集合中的每个状态机最终都可以以相同状态对外提供服务,同时也具备了容忍部分状态机故障的能力。
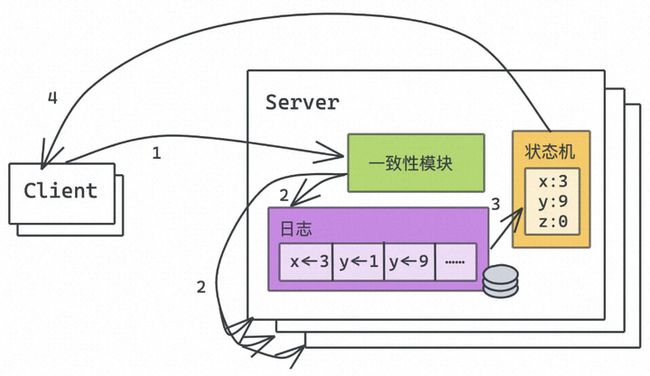
图1. 让分布式系统像“单机”一样工作的复制状态机模型
图1展示了典型的复制状态机模型,在实际应用中,上文提到的状态机的命令序列通常会使用「只读可追加日志」来实现,即每个状态机上都维护着一个日志,日志里面保存着本状态机待执行的命令序列。在图1的例子中,每台状态机看到的日志序列都必须是严格一致的「x<-3」,「y<-1」,「y<-9」,...,每个状态机执行相同的命令序列,对外呈现的最终状态均为:x的值是3,y的值是9。显然,在复制状态机模型中,如何保证状态机之间数据一致的问题转换成了如何保证各台机器上日志序列一致的问题,这个成为了复制状态机模型最核心的挑战,而这,也正是共识协议神圣的职责(不容易呀,话题总算引回来了 )。
分布式共识协议的鼻祖,通常认为是Leslie Lamport提出的Paxos。这里有个有趣的典故,事实上Lamport在1990年的时候就向TOCS(ACM Transactions on Computer Systems)投递了《The Part-Time Parliament》这篇大作,通篇以考古希腊Paxos小岛为背景,描述了古代该小岛上议会制订法令的流程,期望读者能够从中领悟出共识协议的精髓,并且能够理解到大神的「幽默感」。奈何这种描述方式太过隐晦,编辑们没看出来这层含义,幽默感当然也没get到,结果即便这是大神投稿的文章也落得石沉大海的结局。时间来到了1998年,编辑部在整理旧的文献资料的时候,从某个文件柜中发现了这篇旧文并试着重新阅读了一下,这次终于认识到了这里面蕴含着的共识问题的武学奥义。最终这篇扛鼎之作得以重见天日!不过,实话实说,这个版本论文描述的的确是晦涩难懂,今天广为流传的讲解Paxos原理的论文其实是2001年Lamport再发表的《Paxos Made Simple》。话说这篇Paxos论文的摘要挺节约版面费的,就一句话:
The Paxos algorithm, when presented in plain English, is very simple.
说实话,从今天的角度来阅读此文,Basic Paxos的思路的确是比较好懂。我们可以简单回顾一下,如图2中所展示的,Basic Paxos中一共有三类角色:其一提议者Proposer,其二接收者Acceptor,其三学习者Learner。基于实现就某个值达成共识这个具体目标,Basic Paxos全异步地经历如下三个阶段:
- PREPARE阶段,Proposer会生成全局唯一且单调递增的Proposal ID,向所有的Acceptor发送PREPARE提案请求,这里无需携带内容,只携带提案的Proposal ID即可;
- 相应的,Acceptor收到PREPARE提案消息后,如果提案的编号(不妨即为 N )大于它已经回复的所有PREPARE消息,则Acceptor将自己上次接受的决议内容回复给Proposer,承诺有二:不再回复(或者明确拒绝)提案编号小于等于 N(这里是<=)的PREPARE提案;不再回复(或者明确拒绝)提案编号小于N (这里是<)的ACCEPT决议;
- ACCEPT阶段,如果Proposer收到了多数派Acceptors对PREPARE提案的肯定回复,那么进入决议阶段。它要向所有Acceptors发送ACCEPT决议请求,这里包括编号 N 以及根据PREPARE阶段决定的 VALUE(如果PREPARE阶段没有收集到决议内容的 VALUE,那么它可以自由决定 VALUE ;如果存在已经接受决议内容 的 VALUE,那么Proposer就得继续决议这个值);
- 相应的,Acceptor收到ACCEPT决议请求后,按照之前的承诺,不回复或者明确拒绝掉提案编号小于已经持久化的 N 的决议请求,如果不违背承诺,Acceptor接受这个决议请求;
- COMMIT阶段,如果Proposer收到了多数派Acceptors对于ACCEPT决议的肯定回复,那么该决议已经正式通过,异步地,Proposer把这个好消息广播给所有的Learners;

图2. 原始Basic Paxos的基本流程,其实真的还挺简单
以上就是基础版的Basic Paxos协议,完美地解决了分布式系统中针对某一个值达成共识的问题,其实也挺好理解的,对不对?但是,实际的分布式系统显然不可能仅仅基于一个值的共识来运转。按照图1里面的复制状态机模型的要求,我们是要解决日志序列一系列值的共识问题呀。咋办?好办!直观地,我们可以反复地一轮一轮执行Basic Paxos,为日志序列中每一条日志达成共识,这个就是通常所谓的Multi Paxos。这里的所谓一轮一轮的轮号就是我们常说的Log ID,而前者提到的Proposal ID,则是我们常说的Epoch ID。对于采用Multi Paxos的有状态分布式系统而言,日志序列的Log ID必须是严格连续递增并且无空洞地应用到状态机,这个是Multi Paxos支持乱序提交所带来的约束限制,否则我们无法保证各状态机最终应用的命令序列是完全一致的。这里需要课代表记下笔记,一句话重点就是:
Proposal ID(Epoch ID)的全局唯一且单调递增的约束主要还是出于效率的考虑,Log ID的全局唯一且单调递增的约束则是出于正确性的考虑。
分享到这,特别怕读者朋友来这么一句:报告,上面的内容我都看懂了,请问什么时候可以上手开发共识协议?!其实,从Basic Paxos到Multi Paxos,这之间存在着巨大的鸿沟,实践中有着太多的挑战需要一一应对。这里我们通过两个经典的共识效率难题来感受一下:
- LiveLock问题,其实活锁问题源于Basic Paxos自身,如图3所示,在并发度较高的场景下,如果某一轮有多个Proposer同时发起PREPARE提案,那么有的Proposer会成功,譬如R1,有的会失败,譬如R5,失败的R5会提升Proposal ID重新发起PREPARE提案,如果这个足够快,会导致开始PREPARE提案成功的R1继续发起的ACCEPT决议会失败,R1会提升Proposal ID重新发起PREPARE提案,. . . ,两个副本就这样循环往复,一直在争抢提议权,形成了活锁。解决方案也是有的,一者是控制各Proposer发起提案的频率,二者是在提议失败重试的时候增加超时退避。当然,这个只能降低活锁的概率,毕竟根据著名的FLP理论,此时属于放松系统liveness去追求共识协议立身之本linearzability,因此,理论上Paxos就是可能永远也结束不了;
- CatchUp问题,在Multi Paxos中,某个Proposer在收到客户端请求后,首先要决定这条请求的Log ID,前面我们提到了,为了保证复制状态机的数据一致性,Log ID必须是全局严格连续递增的,即这个值不能够与已经持久化或者正在持久化中的日志Log ID重复,否则Proposer会陷入发现这个Log ID已经被某个决议占据、递增本地维护的Max Log ID并尝试重新提议、发现新的Log ID还是被某个决议占据、继续增加本地的Max Log ID并尝试重新提议 . . . ,一直循环至发现了一个全新未启用的Log ID。多累呀,是不是?解决方案也是有的,Proposer向所有Acceptors查询它们本地已经写盘的最大Log ID,收到了多数派的返回结果并选择其中最大值加一作为本次待提议的提案请求的Log ID。当然,这种方案的实现逻辑也不轻,并且依旧存在着争抢失败然后退避重试的概率;

图3. Basic Paxos在多个提议者同时提议的情况下面临着活锁问题
这么一分析,应该都能感受到从Basic Paxos到Multi Paxos这般升级打怪的难度。即便数学家出身的Lamport大神此时也意识到需要给工程师们指引一个可行的工程化方向,否则他们势必不会上船的 ...... 大神提供的解决方案很是简单直接,大伙儿就是喜欢这种朴素:如果Basic Paxos中绝对公平意味着低效,那么不妨在Multi Paxos中引入选举并产生唯一Leader,只有当选为Leader才能够提议请求。这样的好处很明显,首先由唯一的Leader做Log ID分配,比较容易实现全局唯一且连续递增,解决了CatchUp难题;其次,唯一的Leader提议不存在并发提议冲突问题,解决了LiveLock难题;进一步地,本来PREPARE就是为了争夺提议权,现在既然只有Leader能够提议,就至少在Leader任职时间内就不必每个提议都要再走一遍PREPARE,这样大幅提升了形成决议的效率。当然啦,引入了Leader之后,Multi Paxos也是要处理好Leader切换前后的数据一致性问题,并且新的Leader如何填补日志空洞等难题也需要好好设计。问题还是不少,不过,这些都是后话,大方向不会错,跟着大神冲吧!
二、野望
Lamport推出了Multi Paxos,明确了共识协议生产落地的大方向。但是,生产系统究竟应该怎么正确、高效地使用Paxos,还是存在很多不确定性,工程师们一直在不断探索、尝试,但是并没有形成理想的结果产出,业界整体上还是处于一种观望状态。一直等到2007年,来自Google的工程师们通过《Paxos Made Live - An Engineering Perspective》一文,详细地介绍了他们在Chubby(GFS中提供分布式锁服务的关键组件,Apache ZooKeeper在很大程度上借鉴了Chubby的设计思想)中落地Multi Paxos的最佳实践。这篇文章非常经典,即使十六年后的今天读起来也完全不过时,建议有兴趣了解学习Paxos/Raft协议的读者朋友们一定要读一读。我们来总结一下这篇文章提到的Multi Paxos生产落地过程遇到的种种挑战:
- 磁盘故障(disk corruption):在Lamport的Paxos论文中特地提到过持久化的问题:
Stable storage, preserved during failures, is used to maintain the information that the acceptor must remember. An acceptor records its intended response in stable storage before actually sending the response.
但是现实系统中,用于数据持久化的设备,譬如磁盘,也会发生故障,一旦Acceptor机器上的磁盘发生了故障,那么上述持久化的性质就被打破,这个是原则性问题,显然此时的Acceptor就不再具备继续应答提议或者决议的资格,怎么办?Google工程师们想到的解决方案是,为这类发生了持久化设备故障的Acceptor机器引入一个重建窗口(这个期间不再参与提议或者决议应答),类似上面提到的Multi Paxos的CatchUp机制,通过持续的学习已有的提议,啥时候是个头?一直等到重建窗口开始后发起的提议都已经被开始学习到了,那么此时Acceptor很明确,自己可以安全地加回决议军团了;
- Master租约(master lease):Multi Paxos通过选主来有效提升提议效率,然后通过租约机制来维护当选Leader的主权。然而,基于租约的选主机制都会面临“双主”问题,即因为网络分区等缘故,旧的Leader依旧在工作,并不知道新的Leader已经产生并也已经对外提供服务。这种双主问题,对于写请求没有影响(毕竟写是走多数派决议的,旧的Leader的Epoch ID比较低,多数派Acceptors不会接受它的请求提议),可是对于读请求,特别是强一致性读,这就是个很大危害了,因为从旧的Leader可能会读到过期数据。Google工程师们想到的解决方案是,强化租约机制,即Follower收到Leader的租约更新后,严格承诺在租约有效期内不发起/接收新一轮选举,包括与Leader断连以及自身进程重启等场景,这样强化的租约机制能够将不同代的Leader之间实现物理时间上的隔离,确保同一时刻最多只有一个Leader提供内存态的强一致读服务;
- Master纪元(master epoch):这个其实就是我们所谓的“幽灵复现”问题,即旧的Leader处理某个提议请求超时了,没有形成多数派决议,在几轮重新选举之后,这条决议可能会被重新提议并最终形成多数派。这个问题的最大危害在于让客户端无所适从:提议请求超时,客户端并不知道后端系统实际处于什么状况,请求究竟是成功或失败不清楚,所以客户端做法通常是重试,这个要求后台系统的业务逻辑需要支持幂等,不然重试会导致数据不一致。Google的工程师们想到的解决方案是,为每个日志都保存当前的Epoch ID,并且Leader在开始服务之前会写一条StartWorking日志,所以如果某条日志的Epoch ID相对前一条日志的Epoch ID变小了,那么说明这是一条“幽灵复现”日志,忽略这条日志;
- 共识组成员(group membership):实际系统中显然是要面对成员变更这个需求。通过冷启动方式自然是可以完成成员变更的,但是这种机制对于在线服务无法接受。能否在不停服的情况下进行成员变更?事实上,成员变更本身也是一个共识问题,需要所有节点对新成员列表达成一致。但是,成员变更又有其特殊性,因为在成员变更的过程中,参与投票的成员会发生变化。所以这个功能该怎么实现就非常有讲究,如果新旧两个成员组的多数派可以不相交,那么就会出现脑裂,导致数据不一致的严重后果。Multi Paxos论文中提到了成员变更本身也要走共识协议,但是在实际系统中实现这个功能的时候,还是遇到了很多挑战,譬如新配置什么时候生效?譬如变更到一半,发生重新选举,那么后面究竟要不要继续成员变更;
- 镜像快照(snapshots):Google的工程师们在Multi Paxos的实践中,详细描述了快照机制的引入,这里的目的有二:其一加快节点重入的恢复,这样就不用逐条日志学习;其二有效控制日志对磁盘空间量的占用。需要特别注意的是(一定要牢记心里),打快照完全是业务逻辑,底层一致性引擎可以通知上层业务状态机何时打快照,至于快照怎么打,保存到哪里,如何加载快照,这些都是业务状态机需要支持的。快照实现本身也面临着诸多挑战,譬如快照与日志要配合且保证整体数据一致性;譬如打快照本身耗时耗力,尽可能要异步实现,不影响正常请求的决议流程;譬如打快照持久化后可能也会损坏,要增加多重备份以及必要校验等等;
以上是Multi Paxos算法在Google Chubby实际落地过程遇到的诸多挑战,我相信读者朋友们应该都能够感受到Paxos从理论到实践的确是有很多技术点需要完善。其实就上面这些还是搂着说的,实际上Google的工程师们还探讨了更多不确定性:如何保证正确地实现了Multi Paxos的真实语义?如何对一个基于共识协议的分布式系统进行有效测试验证?如何进行状态机运行态正确性检查,特别是版本升级等场景状态机前后语义可能不兼容?
读到这里,我相信,读者朋友会跟我有一样的感叹,Google的工程师们真的太强,着实让人佩服,在2007年的时候,敢为人先,把Paxos扎扎实实地应用到了生产,你看看人家上面提到的这些个问题,基本上做有状态分布式系统的研发同学在这些年的工作中或多或少都踩过类似的坑吧?想一想,早些年Google发表了号称大数据领域三驾马车的巨作:GFS,BigTable,MapReduce,算是拉开了云计算的大幕,近些年Google又开源了云原生的Kubernetes,公开了大模型Transformer ...... 不得不感慨一句,Google的确是云计算领域的弄潮儿 ......

图4. 总结起来,这些年共识领域大体可以划分为六大演进方向
话说回来,我们有理由相信,人们对于Paxos共识协议的热情被Google的这篇文章给重新点燃,越来越多的厂商、研究工作者投身其中,探索并持续改进共识协议,然后等到了2014年Raft的横空出世 ...... 如图4所示,我们梳理了这些年的共识领域的各类研究工作,把共识领域的演进工作分为六大方向,接下来的篇幅,我们集中注意力,逐一说道说道共识领域的这六大门派:
- 强主派:横空出世的Raft,真正让共识协议在工业界遍地开花,从前王谢堂前燕,由此飞入寻常百姓家;
- 无主派:你有张良计,我有过墙梯。Generalized Paxos/Mencius/EPaxos等接力探索去除单点瓶颈依赖;
- 标准派:Corfu/Delos为共识协议引入模块化层次设计,支持热升级可插拔,实现标准化接入通用化移植;
- 异步派:缘起EPaxos,Skyros/Tempo/Rabia推迟线性定序,主推异步共识,追求世间完美的一跳决议;
- 灵活派:FPaxos/WPaxos脑洞大开,解耦共识的提议组与决议组的成员列表,灵活应对跨地域容灾场景;
- 软硬一体派:NOPaxos/P4xos顺应时代大潮,探索共识各模块硬件卸载的可行性,软硬一体化加速共识;
- ......
三、进击
我个人比较喜欢读历史类的书籍,其中《大秦帝国》这部著作反复阅读过几遍。这个系列共计有六部,讲述了从秦孝公变法图强开始,直至秦末群雄并起的这段恢弘历史。我发觉《大秦帝国》六个篇章的鲜明标题(黑色裂变,国命纵横,金戈铁马,阳谋春秋,铁血文明,帝国烽烟)用来概括共识领域这些年六大演进方向还算是比较贴合,为了增加文章阅读的趣味性,斗胆引征了过来,诸君请听我细细道来。
3.1 黑色裂变
黑色裂变这个篇章,必须要留给Raft,并且为了表示尊重,这个章节我们只放Raft这一个共识协议。正是Raft的横空出世,解决了共识协议工业落地困难的问题,并且Raft在现代分布式系统的状态一致性保持这个关键性质上起到了巨大作用。事实上,今天我们在GitHub上搜索带有Raft关键字的开源库,可以查看有1300+个开源库,其中stars破1000的也有30+,不乏etcd-io/etcd,tikv/tikv,baidu/braft,polardb/polardbx-sql,sofastack/sofa-jraft,hashicorp/raft等业界各大知名厂商的代表作。这里,特别致敬一下Raft的提出者,Diego Ongaro。
正如前文所言,Multi Paxos的工业落地并不顺畅,如何解决活锁,如何有效选举,如何打快照,如何解决空洞等问题。关键这些问题的解决让Multi Paxos变得异常复杂,我们怎么保证实现正确呢?来自Standford的计算机博士Diego Ongaro没有选择跟Multi Paxos死磕,他的博士期间的研究关注点都放在了探寻一种可理解性以及易于生产应用这两大维度上更优的全新共识协议,最终在2014年USENIX ATC展示了他「探寻」的答案,Raft。
我认为Raft最出色的地方是在共识协议中引入了强主。是的,你没有听错。读者朋友们肯定有疑惑:你明明在刚才介绍中提到了Multi Paxos同样是引入Leader来解决提议效率问题的。这么说吧,相较于Raft中的Leader被定义为「强主」模式,我更愿意把Multi Paxos中的Leader定义为「代理」模式。先说Multi Paxos,事实上,每个Proposer都可以成为那个唯一提议者,这里仅仅是需要一个「代理」上位,省得七嘴八舌效率低。并且「代理」是可以随时被更换的,大家没有心理负担;而到了Raft,Leader成为了智者,是拥有最多信息的那个Proposer,Leader的标准就是整个分组的标准,不一致的地方统统以Leader为准。事实上,其余角色都指着Leader存活,成为了Leader的依附,更换Leader也就成为了一件非常慎重的事情,中间甚至会产生共识停服的窗口。「强主」模式体现了Raft的「简单有效好实现」的设计理念,也直接支撑了其它如日志复制、一致性保障等模块的简化。
具体的请看图5,在Raft共识协议中,所有的日志流均是严格按顺序从Leader发送给Follower,这个共识组里面并不存在其它通信通道。此外,Leader给Follower发送的每条日志X都包含有Leader记录的该Follower上一条消费的日志Y,在Follower这边收到Leader发送过来的日志X并准备接受之前,会检查本地记录的上一条日志是否是Y,如果不一致,那么一切以Leader为标准,Follower继续往前追溯,找到与Leader分叉点,消除掉本地分叉并坚决学习Leader的日志。通过这个强主逻辑的设计,日志复制管理得到了质的简化,而且服务器的状态空间也被大为简化,是不是?
另外,不知道大家注意没有,通过这种强主逻辑的设计,Raft事实上消除了日志空洞的情形,这也将更加方便拉平两个节点的最新日志。回忆一下,Multi Paxos支持提议的乱序提交,允许日志空洞存在,这个虽然是提供了协议的灵活性,并发性也更优,但是的确让协议变得更加的复杂,阻碍了协议的工业落地。
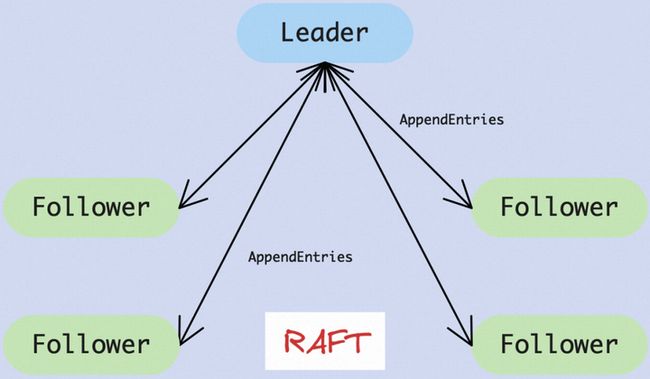
图5. 引入强主模式Leader,简化了日志复制管理,大大提升了协议可理解性
我们继续来说一说Raft的选举算法,它摒弃了Multi Paxos使用原生共识协议来进行选举的复杂机制,而是解耦出来,通过引入简单的“随机超时+多数派”机制来进行有效选举。图6展示了Raft共识协议中角色状态转换图,所有角色初始状态都是Follower,有个随机的选举超时时间,如果在这个时间内没有Leader主动联络过来,进入Candidata状态,将选举的Epoch加一,发起新一轮选举:1)如果收到本轮多数派选举投票,那么当选Leader,通知其它同代的角色进入Follower状态;2)如果发现了本轮Leader的存在,则自身转换成Follower状态;3)如果超时时间内没有发生上述两类事件,随机超时后再次发起新一轮选举。注意,在Raft选举算法中,根据多数派原则,每一代(通过Epoch来表示)至多产生一个Leader。并且,为了保证数据一致性,仅允许拥有最新日志的节点当选为Leader。这里我要再次敲一敲小黑板,Multi Paxos中任意节点都可以当选Leader,好处是灵活,缺点是补全空洞等事宜让Leader上任过程变得很复杂;Raft中只有拥有最新日志的节点可以当选Leader,新官上任无需三把火。Raft的这个设计好,真好,怎么那么好呢?!

图6. Raft着重简化设计,单独剥离出来的选举算法主要依赖随机超时机制
在Raft原生的选举协议中,如果Leader发现了更大的Epoch,会主动退出角色。这个在实际落地时候会产生一个所谓StepDown问题:如果某个Follower与其他副本之间发生了网络分区,那么它会持续地选举超时,持续地触发新一轮选举,然后它的Epoch会越来越大。此时,一旦网络恢复,Leader会发现这个更大Epoch,直接退出当前角色,系统服务被中断,显然这个是系统可用性的隐患。根据多数派原则,每个Epoch至多只有一个Leader当选,因此,每次发起选举之前提升Epoch是必要的操作,那应该怎样面对这个StepDown挑战?通常的解决方案是,在正式选举之前,即把Epoch正式提升并发起选举之前,先发起一轮预选举PreVote,只有PreVote确认自己能够获胜,那么才会发起正式选举。注意,这里的巧妙之处是,PreVote不会修改任何副本的选举状态。
最后我们聊一聊Raft的成员变更,这个就是Raft的特点,方方面面给你考虑的透透的,恨不得帮你把实现的代码都写了。Raft首次提出了Joint Consensus(联合一致)的成员变更方法,将过程拆分成旧成员配置Cold生效,到联合一致成员配置Cold,new生效,然后再到新成员配置Cnew生效这三个阶段。如图7所示,Leader收到成员变更请求后,先向Cold和Cnew同步一条Cold,new日志,这条日志比较特殊,需要在Cold和Cnew都达成多数派之后方可提交,并且这个之后其它的请求提议也都得在Cold和Cnew都达成多数派之后方可提交。在Leader认识到Cold,new日志已经形成了决议,那么继续再向Cold和Cnew同步一条只包含Cnew的日志,注意,这条日志只需要Cnew的多数派确认即可提交,不在Cnew中的成员则自行下线,此时成员变更即算完成。在Cnew之后的其它的请求提议也都得在Cnew达到多数派即可。成员变更过程中如果发生failover,譬如老Leader宕机,那么Cold,new中任意一个节点都可能成为新Leader,如果新Leader上没有Cold,new日志,则继续使用Cold,本次成员变更宣告失败;如果新Leader上有Cold,new日志,那么它会继续将未完成的成员变更流程走完直至Cnew生效。
Raft提出的Joint Consensus成员变更比较通用并且容易理解,之所以分为两个阶段是为了避免Cold和Cnew各自形成不相交的多数派而选出两个Leader导致数据写坏。实践中,如果增强成员变更的限制,假设Cold与Cnew任意的多数派交集不为空(这个并非强假设,日常我们的分布式一致性系统做的成员变更几乎都是加一/减一/换一,的确就是能够满足「Cold与Cnew无法独自形成多数派」),则成员变更就可以进一步简化为一阶段。
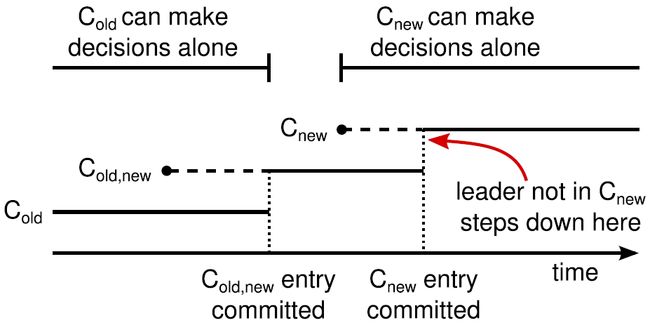
图7. Raft首创的Joint Consensus成员变更法,清晰指导工业实现
共识协议通常被用以解决分布式系统中数据一致性这个难题,是个强需求强依赖。Raft协议的问世无疑大大降低了实现一个正确共识协议的门槛,业界有非常多不错的实践,很多也开源了相关的一致性库,特别是国内的一众厂商,如图8所展示的。说实话,在正确性基础之上,要实现一个高效稳定的一致性库,保证分布式系统能够持续的平稳运行,还是要花费很多很多心思的。这里我们介绍几个业界比较知名的一致性库:
- 蚂蚁的Oceanbase,OB应该是在2012年就开始捣鼓Paxos协议了,时间上在Raft问世之前,应该算是Google之外,另一个把Paxos整明白的团队。网上很多经典的Paxos科普文也是OB团队以前的一些成员分享的。事实上,在解决了高高的技术门槛之后,业务是可以充分享受Multi Paxos乱序提交日志带来的可用性和同步性能的提升。我记得阳振坤老师之前有提过,Raft的「要求严格按照顺序决议事务」的局限对数据库的事务有着潜在性能和稳定性风险,让不相关的事务产生了互相牵制,相较而言Multi Paxos就没了这个约束。不过,总的来说,Multi Paxos还是有些曲高和寡,业界实际采用的屈指可数;
- 腾讯的PhxPaxos,PhxPaxos是腾讯公司微信后台团队自主研发的一套基于Paxos协议的多机状态拷贝类库,2016年正式开源,比较忠实地遵照了Basic Paxos原本协议的工业级实现,宣称在微信服务里面经过一系列的工程验证和大量恶劣环境下的测试,数据一致性有着很强健壮性保证,微信内部支持了PhxSQL,PaxosStore等存储产品。不过,因为PhxPaxos对于请求提议处理同样做了串行化的处理,并且选举出来的Leader必须有最新日志,这些优化设定已经比较多地参考借鉴了Raft的设计;
- 百度的Braft,这个可谓是开源里面Raft协议的工业级实现。百度是在2018年2月初开源了其基于Brpc的Raft 一致性算法和可复制状态机的工业级C++实现,Braft。这个项目最初是为了解决百度各业务线上的状态服务单点隐患,后来则帮助业务快速实现支持高负载和低延迟的分布式系统。作为一款开源基础库,除了在业界有庞大的拥趸群体,Braft在百度内部应用十分广泛,包括块存储、NewSQL存储以及强一致性MYSQL等等,都是原生基于Braft构建的其可容错的高效有状态分布式系统;

图8. 国内各大厂商在共识开源这块热情很高,几乎人手一个代表作
3.2 国命纵横
看完Raft的横空出世,是不是有种「物理学的大厦已基本建成」的感觉?那不能够。无论是代理模式的Multi Paxos,抑或是强主模式的Raft,都是选择引入Leader来解决提议冲突问题,这个事实上也就产生了性能、稳定性的单点瓶颈:一旦Leader挂掉,整个系统停止服务进入重新选举阶段,在新Leader产生之前这段时间即为系统不可用窗口。那么,是否存在能够有效解决提议冲突,同时又能够去Leader依赖的更优雅的方案呢?所谓“你有张良计,我有过墙梯”,正如战国时代的合纵连横一般,很多研究工作者在孜孜不倦地寻找、探索去Leader依赖或者是弱Leader依赖的共识协议。该方向比较有代表性的工作有Fast Paxos,Generalized Paxos, Multicoordinated Paxos,Mencius,EPaxos等等。这里我们挑选Generalized Paxos,Mencius以及EPaxos给大伙儿介绍一下。
Generalized Paxos很值得一提,它同样是来自Lamport大神的作品。这个共识协议源于对实际系统的观察:对于复制状态机而言,通过一轮一轮强共识敲定每一轮的值,然后业务状态机拿到的日志序列完全一样,这样当然没什么毛病,但是约束过于强了。如果某些并发提议请求之间并不相关,譬如KV存储中修改不同KEY的请求,那么这些并发请求的先后顺序其实并不会影响状态机的最终一致性,此时就没有所谓提议冲突这一说,那么这里是不是就不需要引入Leader来做提议仲裁了?回顾一下,Multi Paxos定义了三类角色:Proposer,Acceptor,Learner,并引入Leader多协议仲裁。在Generalized Paxos协议中,Proposer直接发送提议请求(包括提议的值)给Acceptors,每个Acceptor会把收到的提议请求的序列发送给Learners。每个Learner独立处理接收到的提议请求序列,根据请求冲突判定规则,如果能够确认某些请求没有仲裁的必要并且已经形成多数派,那么Learner将这些提议请求直接应用于状态机,整个过程2个RTT搞定;如果请求之间存在冲突需要仲裁,那么Leader会主动参与进来,进一步给Learners再发一跳请求,指导它们行为一致地定序冲突提议并应用至业务状态机。整个过程起步得要3个RTT才能搞定。实际生产系统里面,直接应用Generalized Paxos的很少。不过,我们认为它更多提供了一个创新思路:通过挖掘生产系统中请求之间的不相关性,可以加速决议提交,弱化对Leader的强依赖。
接着来说一说Mencius,取自春秋战国时期儒家大师孟子之名。这个共识协议的取名就很讨喜,我们都记得正是孟子提出的「民为贵,社稷次之,君为轻」的思想,这个是不是跟弱化Leader依赖这个课题很契合?!该共识协议的想法也很朴实:如果单个Leader是性能以及稳定性的瓶颈,那么就让每个副本通过某种策略轮流成为某些轮次的Leader。在同构的环境里面,这种Leader轮转策略可以最大程度分摊访问压力,提升系统整体吞吐,很好很强大,对不对?不过,这里的问题也很明显:在实际系统中,某些副本会变慢甚至挂掉,那么这种轮转机制就运行不下去了,怎么办?Mencius的解决方案是,找其它副本临时替个班,其它副本能够通过发送NO-OP请求的方式(这类请求在经典的Basic Paxos论文中就提到过,不影响业务状态机的状态,可以认为是占位某轮提议),为出问题的副本跳过当值轮次的请求提议,等待出问题的副本恢复。总的来说,Mencius的轮转值班依次提议可谓是弱化Leader依赖的一次很不错的尝试,并且很大程度上启发了后来共识协议的演进。现在生产系统里面用到的支持分区的Raft共识协议,灵感很大程度即来源于此处。
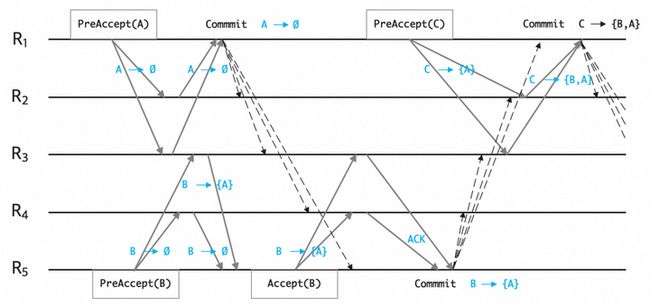
图9. EPaxos引入二维序号空间解决了提议冲突,焦点转移到多副本如何一致定序
上面这两个共识协议,Generalized Paxos在挖掘请求之间的不相关性,Mencius则是在所有副本之间轮转Leader,方案不一,都是为了弱化单点瓶颈。不过,要说无主共识协议的集大成者,绕不开Egalitarian Paxos,简称EPaxos。EPaxos引入了二维序号空间,让每个节点都可以独立的、无竞争的提议请求。当然,分布式领域有一句至理名言:复杂度不会消失,只会转移。EPaxos面临的挑战转换成了如何让多个副本能够一致地给提议请求的二维序号进行线性定序。换句话说,Paxos/Raft定义的共识是针对一个具体的值的,EPaxos重定义的共识是针对一系列请求的提议顺序的,并且进一步巧妙地将这个过程拆分成两阶段:a)针对一个提议请求,以及其依赖项(在最终全局顺序中必须要遵守的线性依赖)达成共识;b)异步地,针对一系列值以及依赖项,做个确定性的、全局一致的线性排序。
以图10为例,副本R1提议请求A,收集多数派情况没有发现有依赖关系,直接发送COMMIT消息;而副本R5发送的提议B请求,多数派回复收集回来发现有B依赖A的关系,那么再将B->{A}这个依赖作为ACCEPT请求广播给其余副本。在收到多数派相应之后(请求之间依赖关系是面向过去的,因此多数派反馈的依赖合集就可以作为决议直接使用),广播COMMIT给各个副本。进一步地,副本R1再提议请求C,多数派响应都是C->{B, A},那么也是直接达成共识,广播COMMIT给各个副本。

图10. EPaxos需要一个额外排序过程得到确定性的、全局一致决议序列
当请求提议以及它的依赖项达成共识之后,请求就算提交成功,可以返回客户端了。但是,此时请求决议在全局请求序列中的顺序还没有最终确定,无法直接应用至业务状态机,因此,EPaxos还需要一个额外的排序过程,对已提交的决议进行排序。当决议以及其依赖集合中所有决议都已经完成提交后,副本就可以开始排序过程。我们在图10中给出了一个示例:将每个持久化的决议看作图的节点,决议之间的依赖看作节点的出边,因为每个二维序号对应的决议和依赖项是达成全局共识的,即图的节点和出边在各副本之间已经达成了一致,因此各副本会看到相同依赖图。接下来对决议的排序过程,类似于对图进行确定性拓扑排序,结果即为提议请求的线性顺序。
需要注意的是,如图10,请求决议之间的依赖可能会形成环,即图中可能会有环路,因此这里也不完全是拓扑排序。为了处理循环依赖,EPaxos对请求决议排序的算法需要先寻找图的强连通分量,环路都包含在了强连通分量中,此时如果把一个强连通分量整体看作图的一个顶点,则所有强连通分量构成一个有向无环图,然后对所有的强连通分量构成的有向无环图再进行拓扑排序。寻找图的强连通分量一般使用Tarjan算法,这是一个递归实现,在我们实践过程中发现这里的递归实现很容易爆栈,这点将给EPaxos的工程应用带来一定挑战。此外,随着新的请求提议不断产生,旧的提议可能依赖新的提议,新的提议又可能依赖更新的提议,如此下去可能导致依赖链不断延伸,没有终结,排序过程一直无法进行从而形成新的活锁问题,这个是EPaxos工程应用的另一大挑战。
总结一下,无主共识领域的探索方向工作还蛮多,有挖掘请求之间不相关性的,有副本间轮转请求提议权的,还有引入二维序号空间将问题转移成异步线性定序的 ...... 上述这些无主方向的技术探索,最终工业落地的不多,我们认为这个跟该方向的协议普遍比较复杂有很大关系,有点高射炮打蚊子的味道。不过,必须要补充一句,业界完全是需要这类探索存在的。事实上,正是Generalized Paxos这类挖掘请求之间不相关性的工作,启发了Paralle Raft这些工业界的尝试;正是Mencius这类轮转请求提议权的工作,启发了多分区的Raft这些工业界的尝试;EPaxos更是在很大程度上启发了后面介绍的「异步共识」这个流派 ...... 所以怎么说呢,每一次尝试都是成功的序曲。理想还是要有的,万一实现了呢?
3.3 金戈铁马
「金戈铁马」这个命名可以用来形容共识领域的「灵活派」。共识协议从提出之初,在AZ内的有状态的分布式系统中可谓大杀四方。随着业务系统的快速发展,逐步演进出多AZ容灾甚至是跨地域容灾的需求。那么,此时的共识协议还能应对自如吗?毕竟印象中传统共识协议的最佳应用场景还得是同构环境的,多AZ以及跨地域则是引入了异构场景,共识协议该如何征战这片沙场?
「灵活派」的开山之作被称为Flexible Paxos,它的灵感来自一个非常简单的观察:假设共识协议中成员总数是N,PREPARE阶段参与的成员数是Q1,ACCEPT阶段参与的成员数是Q2,那么Basic Paxos正确性保障最本质的述求是Q1与Q2两个阶段要有重合成员,以确保信息可以传承。满足上述要求最直观的机制是Q1与Q2两个阶段都选择多数派(majority)成员参与。可是,我们发现只要保证PREPARE与ACCEPT两个阶段参与的成员数超过成员总数,即Q1+Q2>N,那一样能够满足Q1与Q2两个阶段要有重合成员的要求,并且这里的参数选择挺多,也很灵活,是不是?嗯,「灵活派」所有的故事就是从这里开始讲起的 ......
也许有人会说,是不是闲的慌,调整这两参数有啥意义?别急,我们回顾一下这两个阶段,PREPARE阶段事实上做的是Leader选举,ACCEPT阶段则是做日志同步,前者可以认为是管控依赖,后者是IO依赖,那么我们是否可以把Q1调大,而Q2调小?这样IO路径依赖可以更加高效更加可靠。还是没有心动的感觉??好吧,再看一个更加具体的例子,如图11所示,我们非常熟悉的3 AZ场景,处于业务IO链路依赖的角色通常会选择“3+3+3”部署模式,即Q1=Q2=5,实现「挂1个AZ+挂另一个AZ的1个节点」这样高标准容灾能力。3 AZ部署讲求个对称结构,如果“2+2+2”部署模式,对于传统的Multi Paxos来说,相较于“2+2+1”不会增加额外容灾能力,ACCEPT阶段还得多同步一个节点,吃力不讨好。而在“2+2+2”部署模式下,我们选用Flexible Paxos的话,Q1不妨设置为4,Q2不妨设置为3。那么首先这种模式能够抗住挂1个AZ,即使此时故障AZ内有Leader节点,剩余AZ内的节点也能够迅速选举出新的Leader,并且在正常ACCEPT阶段,该部署模式同样具备「挂1个AZ+挂另一个AZ的1个节点」这样高标准容灾能力。感觉到Flexible Paxos的美了吗?我们的观点是,Flexible Paxos思想指导下的“2+2+2”模式是非常适合一些有状态的管控类服务选用为3 AZ部署方案的。
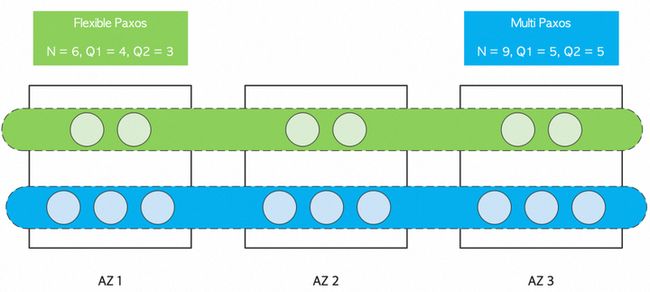
图11. 面对越来越常见的3 AZ场景,逐步发现了Flexible Paxos的美
事实上Flexible Paxos还提供了一个思路,可以选择性的确定参与PREPARE阶段的成员列表与参与ACCEPT阶段的成员列表,这里连Q1+Q2>N这个条件都不需要,而放松至仅仅需要Q1与Q2有重合成员即可,这种成员列表确定思路也被称为GRID QUORUM模式,这种模式跟跨地域场景非常的搭。后续研究工作者相继推出的DPaxos,WPaxos都是这个思路指导下的共识协议跨域容灾方面的最佳实践。这里我们介绍一下WPaxos。该共识协议明确引入了AZ容灾以及节点容灾两个维度的容灾标准,假定参数fn是一个AZ可以容忍的挂的节点数,fz是可以容忍挂的AZ数目,我们来看看WPaxos原文《WPaxos: Wide Area Network Flexible Consensus》是怎么进行参数选择的。论文里面也有详细证明为什么这样的选择下,虽然Q1+Q2不大于N,但是Q1与Q2一定是有交集的,这里证明我们就不展开介绍了,主要看看参数是如何选择的:
In order to tolerate fn crash failures in every zone, WPaxos picks any fn + 1 nodes in a zone over l nodes, regardless of their row position. In addition, to tolerate fz zone failures within Z zones, q1 ∈ Q1 is selected from Z - fz zones, and q2 ∈ Q2 from fz + 1 zones.
继续举个具体的例子来生动地理解WPaxos的意义吧。譬如有些区域如果是2 AZ,怎么做容灾呢?我们可以在临近一个区域选择一个AZ,这样也是一个3 AZ部署。如图12所示,假如AZ1,AZ2是本地域的2 AZ,而AZ3是跨地域的AZ。按照WPaxos的协议约束,我们可以设定9节点部署,每个AZ部署3个节点。基于“挂1个AZ+挂另一个AZ的1个节点”这个容灾能力的约束,参考上面的WPaxos的参数选择机制,我们可以设定:fz = fn = 1,即Q1是“任意2 AZ,每个AZ任意2个节点”,Q2亦如此。这样的设定真的跟跨地域容灾很搭:无论是PREPARE阶段,还是ACCEPT阶段,提议者都是给所有的节点发送提议或者决议请求,因为就近处理的延时比较低,很大概率我们会先迎回来AZ1/AZ2的请求回应。因此,在常态情况下,我们的IO请求都会在本区域完成。当然,选举也是可以在本区域即可完成。当发生AZ1或者AZ2挂掉的灾难场景,那么两个阶段的参与者会自动切换到AZ2/AZ3,或者是AZ2/AZ3,此时延迟会有所增加,但是服务可用性还在。

图12. 进一步地,共识协议WPaxos在跨地域场景下的最佳容灾实践
AZ容灾甚至是地域容灾越来越多地出现了云产品的建设要求里面,我们相信,「灵活派」共识协议的灵活设计思路会在容灾场景下发挥着越来越大的作用。
3.4 阳谋春秋
《大秦帝国》的「阳谋春秋」这个篇章主要讲述了六国统一者嬴政上位之前,秦国连续经历的三次重大交接危机的这段恢弘历史。共识领域里「异步共识」发源点应该说是EPaxos (SOSP'13),前面章节也详细介绍过,理想很美好,实际落地却存在诸多挑战。在EPaxos提出之后,领域里面也一直陆陆续续有研究工作跟进,譬如来自OSDI'16的Janus。一直等到了2021年,这一年可谓是「异步共识」门派发展历史上里程碑式的一年,该方向的研究成果在各大顶会遍地开花(有来自SOSP'21的Skyros,Rabia;有来自NSDI'21的EPaxos Revisited;以及来自EuroSys'21的Tempo)。正如阳谋春秋字面的意思,如果把传统的Paxos/Raft等共识协议都视为同步共识协议的话,那么「异步共识」算是站到了对立面,并且的确找到了能够最大发挥其优势的典型应用场景。
我们首先来介绍下「异步共识」是如何开脑洞的。传统的共识协议就像一个复杂精密的仪器,如图13所示,一个请求从提交至返回,大体会经历三个阶段:1)请求会被复制给多个副本,这一个阶段是为了保证数据持久性(durability);2)每个请求都会被指定一个全局唯一,单调递增的序号,这一个阶段是为了保证请求之间的线性顺序(linearizability);3)请求会被最终在业务状态机执行保证数据外显性(externality)。注意,这个阶段是根据前一阶段确定的顺序依次执行。这么一个流程执行下来,一个请求至少要2 RTT才能返回,并且因为并发请求线性定序天然会存在冲突导致的效率问题,传统共识协议的最佳实践就是要引入一个Leader来做高效定序,这个就反过来让请求提议阶段存在服务单点的问题。所以「异步共识」的阳谋就是:用户提议的请求仅需经历数据复制阶段即返回,服务端异步地执行请求的线性定序以及决议执行阶段。这样解构的好处是可以专项优化数据复制阶段的延时,甚至实现无主的高可用。当然,这里的难点是,在数据复制阶段,请求要留下足够的痕迹,这些痕迹要足够支持服务端仅根据大部分副本即可异步地恢复出请求之间正确的线性顺序。异步共识最大的挑战就在于此,目前业界复制留痕有三大思路:1)依赖请求落在每个副本上的偏序;2)依赖复制阶段加锁强定序;3)引入时间戳,给每个请求分配单调递增的时间戳。

图13. 根据请求类型是否需要「即时外显」,我们可以把共识分为同步与异步两类
「异步共识」这里其实蕴含有一个强假设,实际分布式系统中,是否存在这样的写请求,它不需要即时执行状态机,只要确保该请求被持久化了就可以返回。咋一听还是有些反直觉的,不过事实上实际存储系统中这类写请求接口并不少见。最典型的是Key/Value存储系统,譬如Put接口,并不需要即时APPLY,即返回客户端的时候并不需要告知相应的KEY是否已经存在;譬如Delete接口,也并不需要即时APPLY,即返回客户端的时候并不需要告知相应的KEY是否并不存在。业界类似的系统,包括有RocksDB,LevelDB等LSM-Tree结构的存储系统,还有Memcached里面的Set请求,ZippyDB里面的Put/Delete/Merge等主要接口均是如此。认识到这些,相信读者朋友们也会认同「异步共识」的出发点,也能够看清「异步共识」想要打的靶子。
在正式介绍「异步共识」的各类协议之前,我们要重新学习一下何谓请求的线性序。在传统共识协议的强主模式下,所谓线性序来的是理所当然,但是在异步共识之下,我们要尝试恢复并保持请求之间的线性序,自然,我们要非常明确它的要求。下面这个摘自EPaxos对于线性序的定义:如果两个请求γ和δ,如果δ是在γ被确认形成决议之后才发起的,那么我们就称δ是线性依赖的γ,每个副本状态机都需要先执行γ,再执行δ。
Execution linearizability: If two interfering commands γ and δ are serialized by clients (i.e., δ is pro- posed only after γ is committed by any replica), then every replica will execute γ before δ.
这个章节以SOSP'21的Skyros为例来介绍异步共识,它是属于依赖偏序恢复线性序的流派。我们认为这篇文章在提取异步共识的应用场景这方面做的非常出色。如下图14所示,Skyros的思路很简单,在同步复制阶段引入一个Leader,客户端直接写包括Leader在内的super-majority的副本,一旦返回则请求完成。在正常情况下,后台以Leader的请求顺序作为执行顺序,依照该请求顺序执行状态机;在Leader节点挂掉的情况下,剩余副本中选举出新的Leader,收集存活副本中请求的偏序集合,尝试恢复请求之间实际的线性序(这里的做法很大程度上会参考EPaxos的图排序算法),然后继续履行Leader的职责。通过这样的设计,Skyros实现了极致的一跳请求决议提交延迟,并且这个方案看起来非常简单,是不是?

图14. Skyros明确提出推迟定序以及执行过程,极致优化提议过程
绝大多数时候,现实没有想象的那么美好,当然,也没有想象的那么糟糕。Skyros美好的有些不真实。事实也如此,在Skyros的机制里面,很大篇幅是在解决一旦Leader挂掉之后,新当选的Leader如何恢复出已经持久化的请求之间的线性顺序,这里实际新的Leader能够利用的信息只有请求在每个副本上的偏序关系,但是我们发现这些信息并不足以支撑线性顺序的恢复!图15给出了一个我们用来证伪Skyros的简单例子,有三个请求W1,W2,W3,有四个副本R1,R2,R3,R4,其中R4是Leader,从实际事实来看,可以确定是W1是先发生的,线性顺序早于W2,而W3则是跟W1以及W2完全并发的一个请求。此时如果副本R4挂掉了,试问,此时根据什么信息能够推断得出这个实际的线性序。毕竟,此时根据剩余节点上请求的偏序关系,你得到了W1,W2,W3之间的循环依赖,并且,没有更多的信息能够支持破除这个循环依赖!
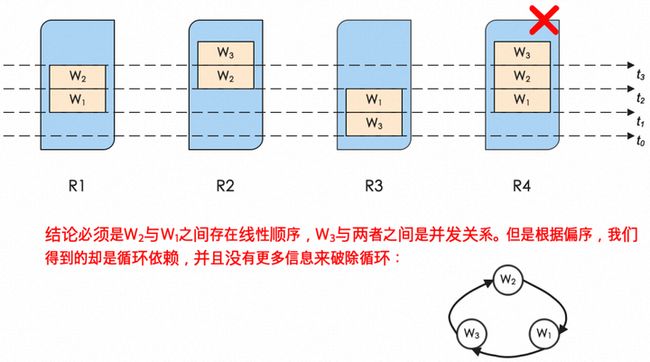
图15. Skyros的依赖偏序对来推导线性序的做法有概率存在循环依赖,无法破环
来自EuroSys'21的Tempo找到了可能是解决异步共识里线性定序难题的最佳方案:引入逻辑时间戳。我们即便从直观上感受,也会觉得逻辑时间戳的方案的确更加高效,毕竟相较于EPaxos/Skyros动不动就给你上个图排序,逻辑时间戳的直接比大小的线性定序方法要简单很多。在Tempo中,每个提议请求会有指定的Coordinator来负责最终决定请求的逻辑时间戳,它收集各副本已经分配的逻辑序号情况,确定具体分配哪个时间戳序号给相关请求,并且这样的分配要确保后来的请求不会被分配更小的逻辑序号。对于可能发生的提议冲突的情况,Tempo参考了Fast Paxos来解决,多走几轮共识给有冲突的提议请求提供确定、线性的逻辑时间戳分配。思路大体如此。Tempo引入时间戳的做法很有新意,但是一方面引入单独的Coordinator角色,另一方面依赖Fast Paxos仲裁提议冲突。整体的协议复杂度又上来了,不利于工业落地实现。
3.5 铁血文明
共识协议对于有状态的分布式系统至关重要,现实的情况是,一个有状态的分布式系统可能花费了九牛二虎之力才把一个共识协议实现正确并且有效运维起来。但是接下来面临的问题是,这个宝贵的积累很难直接复制到另外一个系统,并且这个系统也就绑定上了一开始选择的共识协议,几乎没有可能继续演进迭代至全新的共识协议。以Apache ZooKeeper为例,其至今使用的共识协议还是十多年前的ZAB,并且该共识协议也没有被ZooKeeper以外其它系统所采用。我们看看其它领域,像OS操作系统,像Network网络系统等,这些系统的模块化以及清晰的分层设计使得新的机制甚至是现有机制的迭代都能够以可插拔的方式被快速引入,促进了这些技术领域的蓬勃发展。看着真是眼馋呀,我们不禁要问,共识协议能够实现这样可移植,可插拔,热升级吗?当然,这个其实也就是Corfu/Delos等共识协议发力的点,目标Replication-as-a-Service,打造出属于共识协议的的铁血文明!
首先要探讨一个问题,我们能否以LIB形式提供通用一致性引擎库?答曰,很难。不可行的原因是各种共识协议譬如Multi Paxos,Raft,ZAB以及EPaxos等等,语义差别还是很大的,很难给出一个通用的接口能够兼容现有的这些共识协议。继续来探讨第二个问题,使用确定的某个共识协议的一致性引擎库,成本高吗?答曰,很高。虽然说像Braft等开源库在接口设计上已经尽量简洁了,但是作为一个库,自身没有状态,必然要暴露状态管理的细节,譬如角色信息、成员信息、甚至镜像信息等给到业务进程并与之耦合,包括状态机的runtime consistency检查等等,所以要用正确用好任何一个开源的一致性引擎库,是需要业务长年累月地打磨投入的。最后再探讨一个问题,作为一致性引擎库,能够支持持续演进包括协议的更新换代吗?答曰,至今没见过 ......

图16. Share Log对共识协议做了抽象,隐藏了实现细节,有利于模块解耦独立演进
聊回这个章节的主角,Share Log,这个我认为也是NSDI’12 Corfu这篇文章最为出彩的贡献,为共识协议提供了一个简单朴素而又精准的抽象(这里面学习到一个道理:当我们对一个问题无法给出通用解释的时候,那么一定是抽象的还不够),答案就是日志序列,这个日志序列是可容错,强一致,支持线性定序的可追加日志序列。如图16所示,Share Log提供的APIs有如下四个:
- O = append(V):追加日志V,返回日志所占据的逻辑序号O;
- V = read(O):读取逻辑序号O对应的日志;
- trim(O):标记逻辑序号O(包括之前的序号)对应的日志不再需要,可清理;
- check():返回下一个可写的逻辑序号O;
相当于,上层业务状态机基于Share Log的接口来实现具体业务逻辑,无需关心持久化、线性保持、一致性等难点技术。以复制状态机模型为例,业务状态机直接向底层的Share Log追加日志,Share Log内部使用共识协议将日志复制到其它节点,业务状态机从Share Log中学习最新日志,依次应用到状态机。基于这层抽象,共识协议的细节被隐藏在Share Log内部,业务逻辑和共识协议可以独立演进,互不影响,并且Share Log可以做成通用模块,移植给不同的业务使用。事实上,Share Log这层抽象是那么的简单朴素并且准确,类似这种机制已经成为了现代分布式系统设计的基石,我们来看到Share Log广泛应用的三大场景:
- Pub/Sub:共享日志其中一大应用场景是作为可扩缩的异步消息传递服务,将生成消息的服务与处理这些消息的服务分离开来。这种解耦的设计大大简化了分布式应用开发,Pub/Sub在生产系统中被广泛部署应用。各大云厂商也都推出了消息队列的重磅产品,譬如Alibaba MQ,Amazon Kinesis,Google Pub/Sub,IBM MQ,Microsoft Event Hubs以及Oracle Messaging Cloud Service。消息队列对日志需求是持久性(durability),唯一定序(uniquely ordered)以及线性定序(linearizability)。Share Log自然能够满足此类场景需求。分布式存储系统在做跨地域容灾的时候,异步复制方案通常要求对IO链路的影响降到最低,同时尽可能地降低RPO,此时标准的技术选型就是基于消息队列来拖Redo Log;
- Distributed Journal:LSM-Tree在现代存储系统中得到了广泛应用,该这里面关键的journaling机制很好地解决了写放大问题,每次仅持久化增量的更改数据,而不需要全量数据持久化,同时通过严格顺序写入的设计大幅提升了写入性能,对于写多读少的场景尤其的友好。在分布式场景下,journaling也会升级为一个append-only的分布式日志系统,类似GFS、HDFS等等。这正是Share Log主打场景。根据业务请求是否需要即时外显,又细分出两个场景:1)要求即时外显,那么这里的append-only的分布式日志系统必须单写,即同一时间某个文件最多只允许一个客户端操作,否则状态机APPLY的请求序列与持久化的日志序列可能不一样,failover场景下数据一致性将被打破。此时分布式日志对日志的需求是持久性(durability),外显性(externality),唯一定序(uniquely ordered),以及线性定序(linearizability);2)不要求即时外显,这里的append-only的分布式日志系统需要支持多写定序,最大程度提升访问吞吐,降低请求延迟。此时分布式日志对日志的需求是持久性(durability),可定序(orderable)以及线性定序(linearizability);
- Replicated State Machie:如前文所言,复制状态机模型是当前有状态的分布式系统广泛采用的容错机制。正如图1里面描述的,Share Log可以面向复制状态机提供线性单调,强一致,可容错的日志序列,再合适不过了。复制状态机对日志的需求是持久性(durability),外显性(externality),唯一定序(uniquely ordered),以及线性定序(linearizability)。事实上,传统的消息中间件Apache Kafka,Apache Pulsar同样能够胜任此职责(所谓艺多不压身,Kafka这类中间件已经打造的十八般武艺样样精通),业界很多数据库公司也是基于消息队列解决了同步复制的需求。该场景下,Share Log处于业务的直接IO依赖,事实上是跟业务耦合了,因此会产生新的挑战。以基于分区调度架构的分布式存储场景为例,其在依赖Share Log的时候,如何支持业务的分区变配(即保证变配前后日志线性顺序)就变得很棘手;
自从Corfu提出了Share Log这个概念之后,研究领域相继推出Tango,Scalog以及Chariots等演进版本,工业界里面CorfuDB,LogDevice,Aurora也都借鉴了类似Share Log的设计思想,实现了共识协议的平替。细心的读者应该还记得我们的第三问,共识协议能够支持可插拔,热升级吗?这个就要提到Corfu之后集大成者Delos了。事实上,共识协议自身也是存在控制与数据平面的,其中控制平面负责选主,元数据管理,成员变更,服务容错等复杂能力,而数据平面仅仅需要定序以及数据持久化。类似Multi Paxos/Raft/ZAB等传统共识协议耦合了控制与数据平面,事实上,Share Log对外展示的恰恰就是共识协议的数据平面,这个是可以解耦出来单独演进的,而这也就是Delos里面推出的所谓Virtual Log的思路。总结起来就是,让传统的共识协议负责控制平面的实现,而数据平面仅负责日志定序及数据持久化,因此可以有各种更加高效的实现(有点套娃的意思,共识里面套共识)。这个思路在业界并不新鲜,已经被广泛采用,譬如Apache Kafka里面即使用Apache ZooKeeper(新版本是自研的KRaft)来管理元数据的控制平面,使用ISR协议负责高吞吐灵活的数据平面;Apache BookKeeper(这个读者可能会比较陌生,基于它长出来的EventBus,Pulsar,DistributedLog,Pravega等明星开源产品,你总听说过一款吧)也是使用了Apache ZooKeeper来做控制平面管理,而自研的Quorum协议负责高吞吐的写以及低延迟的读;类似的例子还有很多,像Microsoft的PacificA也是采用管控数据平面分离的架构。
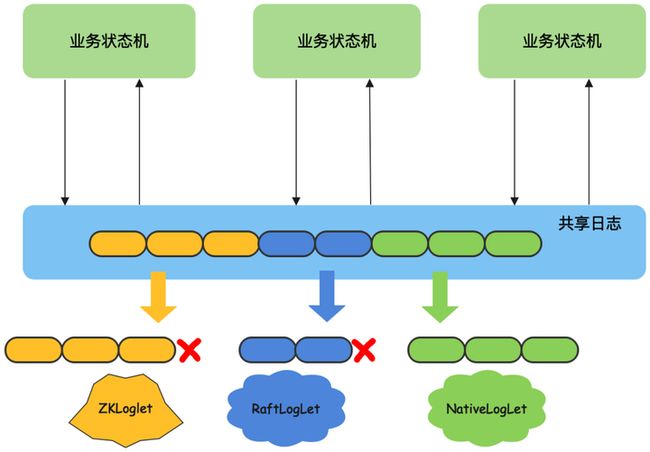
图17. Facebook Delos的共识技术架构,在共识迭代这块可插拔支持热升级
当然,出身名门的Delos做了更多抽象,特别是创新性地在Share Log基础API之上,引入SEAL能力。如图17所示,Delos支持客户端通过SEAL接口将前一个日志序列禁写(譬如原先是基于ZK共识协议实现的请求定序),进而开启全新的可写日志序列(新的可以是基于Raft实现的请求定序),通过这样的实现达到了Share Log底层的共识协议能够热切换热升级的目的。这个是不是很好地解答了我们的第三问?
在这个章节的最后,我要特别推荐一下大名鼎鼎的Jay Kreps在2013年发表的大作《The Log: What every software engineer should know about real-time data's unifying abstraction》。这个文章真的非常不错,值得大家耐着性子好好读一读。Jay Kreps把日志这个概念讲的非常清楚,以一个非常广的视角揭示了日志其实是很多分布式系统最本质的东西,解释了为什么日志是更好的抽象(相对于共识协议本身)。如果用一段话来概括日志对于分布式系统的意义,那么我认为应该是文章里的这段描述:
At this point you might be wondering why it is worth talking about something so simple? How is a append-only sequence of records in any way related to data systems? The answer is that logs have a specific purpose: they record what happened and when. For distributed data systems this is, in many ways, the very heart of the problem.
事实上,作为Kafka创始人之一,Jay Kreps在文中也预言了日志最终应该会做成通用的产品组件,在分布式系统中将被广泛使用。有关日志的深度思考,对于Jay Kreps自己也很重要,他个人命运的齿轮开始转动 ......,很快推出了Kafka(这个应该不用多做一句介绍吧?),商业化也做的非常的成功(它的一个口号是:More than 80% of all Fortune 100 companies trust, and use Kafka ......,母公司Confluent的最新市值也已经达到了100亿美金)。另外,有个有意思的小插曲,在发表这篇日志博文的时候,Raft刚面世,Jay Kreps对这个协议非常的赏识,文中也强力推荐了Raft,真可谓英雄惜英雄也。
这个章节也聊了那么多,总结起来是,Share Log对共识协议对了很好的抽象,标准化了共识协议对外的使用界面,实现了可插拔;进一步的抽象来自升级版的Virtual Log,通过控制平面与数据平面的分离,实现了共识协议热升级的理想。如果说还能够进一步再抽象的话,我们认为那应该是以Kafka/Pulsar为首的日志复制服务所代表的Replication-as-a-Service(RaaS)的趋势。随着云原生大潮的来临,应用程序开发者一定需要学会借力开发,降低业务系统的复杂性,譬如可以使用RaaS解决状态同步问题,可以采用OSS等元原生存储解决状态存储问题,以及可以倚赖Etcd/ZooKeeper等组件解决状态管理问题等等。
3.6 帝国烽烟
哇呜,能坚持看到现在的你们,的确是共识协议的真爱粉。我们能够领略到,这么些年研究工作者们在跟随着Lamport大师指引的方向上,逐步建立起了庞大的共识帝国。不过,以上我们介绍的所有研究方向都是软件算法层面的优化。而在这个章节,我们将讲述的是全新的软硬一体化视角下的共识协议研究工作。在智能网卡,RDMA,可编程交换机等数据中心的各类技术快速发展的当下,探索共识协议硬件卸载(offline)的各种可能性,很多时候能够打破我们的既定认知,带来降维打击般的改进效果。所以,这个章节,我们选用“帝国烽烟”作为标题来提醒传统的共识协议的研究人员。话说这个标题起的呀,一个字,绝!
大体上,我们可以把迄今为止软硬一体化方向的共识协议的研究工作分成三类:1)随着数据中心技术的快速迭代,预期网络可以提供更多的承诺,譬如可靠传输不丢包,譬如可线性定序的传输。基于这样的假定,共识协议围绕着异步网络(信息传输回丢失,乱序,超时等等)做的很多复杂设计可以拿掉,进而更简单更高效地达成决议;2)可编程的交换机技术的快速发展,提供了将整个共识协议的三阶段能力都卸载到交换机上的可能性,这将相当于把共识变成网络提供的原语服务。从提议请求的处理吞吐角度而言,交换机的能力显然是要远胜于节点的CPU能力,那么可以预期共识吞吐可以获得几个数量级的提升;3)异步共识很适合存储领域的分布式日志场景,其中数据复制逻辑简单,对稳定性要求高,吞吐延迟的指标也很敏感,比较适合将这部分逻辑卸载到智能网卡里面实现。而线性定序以及状态机执行者两个阶段逻辑复杂,可以保留在软件层面灵活控制,异步地执行。

图18. 随着对网络依赖的强弱变化,所谓共识的实现难度会发生巨大变化
我们首先来看第一类研究工作,增加网络能力的承诺。我们知道,Lamport提出共识协议时候对于网络的假设是完全异步的,也就是说信息传输可能会丢失,可能会乱序,也可能发生延迟抖动甚至超时等等。基于这样的假设,Paxos等共识从协议层面增加了各种设计,保证了一致性的性质,但是也增加了软件复杂性并且存在执行效率的瓶颈。必须得说,Lamport的异步网络假定对于Internet网络是合理的人设设定。不过当前数据中心内的网络状态显然要可控多了,能否提供一些可靠性的保证呢?如图18所示,事实上,如果网络侧能够做出更多可靠性承诺,共识达成的难度会降低很多。这个方向已经有很多相关研究成果,譬如NetPaxos,Speculative Paxos,NOPaxos,Hydra等。这里我们着重介绍一下来自OSDI’16的NOPaxos(注意,这个取名是抖了个机灵,实际是指Network Ordering Paxos),它的假定即网络可以提供可靠的定序保证,虽然可能会丢失一些链路的请求包。

图19. NOPaxos定义的支持全局定序的请求广播接口,相关功能卸载到交换机实现
具体来说,NOPaxos定义了一组名为OUM(Ordered Unreliable Multicast)的网络接口,通过可编程的交换机(例如P4)在交换机硬件上直接支持这样的广播接口,如图19。在指定的网络定序者(最佳选择是基于可编程交换机实现)为每个OUM组都维护了一个计数器,在每个转发过来的OUM请求的包头填充严格连续递增的计数。最终达成的效果如图20所示,包括Leader在内的各个副本收到的请求是严格有序的,正常情况下都不需要有协同动作,非常高效。每个副本自己会检查是否发生丢包,如果发生了丢包,非Leader副本向Leader学习具体丢失的请求包;Leader副本则通过NO-OP请求走Basic Paxos来学习丢失的请求包。另外,客户端一旦收到包括Leader在内的多数派副本的请求回复,即可认为请求完成,这里仅仅需要一跳网络延迟。
当然,NOPaxos这个工作存在一个设计上的硬伤,即作为定序的交换机是个单点,这个就导致了系统在可扩展性、容错性以及负载平衡等诸多方面存在限制。这个工作的延续是Hydra,进一步引入多台交换机来做定序,缓解了上述的单点瓶颈。可能读到这里,读者朋友们会有点惊讶,看了共识领域其他门派各种精巧复杂的协议设计,这个来自OSDI'16的NOPaxos共识协议是不是有点简单过头了?好吧,的确有点降维打击的味道,事实上,如果网络定序本身不是问题的话,复制的难度的确没有那么大。对该方向感兴趣的读者朋友们可以继续研究下Hydra,Speculative Paxos等工作,感受下更可靠的网络是如何有效提升共识的。

图20. NOPaxos利用交换机的定序能力实现了高效一跳共识,容错、成员变更等能力由软件侧保障
我们继续看第二类研究工作,整个卸载掉共识的能力。这个方向的代表作是P4xos,看这个协议的名字就明白是把共识的能力直接给卸载到了P4可编程交换机。如图21所示,P4xos的工作是在数据中心基于传统的三层网络架构来设计的,所有的请求会经过ToR(Top of Rack)交换机,Aggregate汇聚交换机,以及Spine核心交换机。基于这种网络架构,我们看到传统的Paxos共识协议从Proposer提议到Leader学到决议共经历3/2 RTT。P4xos把三层网络架构下的交换机都安排成共识协议中的角色:Spine核心交换机做Leader定序,Aggregate汇聚交换机做Accept接收决议,ToR交换机则做Learner学习决议。整个链路下来仅需要RTT/2。我想聊到现在,大家应该也有点感觉到传统共识协议的瓶颈之所在:从延迟上来讲,主要消耗在网络传输;从整体吞吐上来讲,主要瓶颈在单机CPU处理能力。P4xos通过将共识三阶段能力整体卸载到P4交换机,相较于传统共识协议,不仅仅是延迟得到了明显改善,整体的共识吞吐能力有了质的飞跃(P4xos的论文中宣称有4个数量级的提升)。当然,这里选用Spine核心交换机做Leader定序同样存在单点问题,需要引入传统共识协议的重新选举过程。

图21. P4xos尝试全面卸载Paxos的共识协议,实验展示了惊人的优化效果
软硬一体化方向的第三类研究工作,跟前文提到的异步共识的工作紧密相关。回顾一下,异步共识将复杂的线性定序以及状态机执行等逻辑推迟处理,而用户的请求仅仅在前面简单的复制阶段完成即可返回。这个思路跟硬件卸载的极简主义的原则非常契合,实现了存储系统的核心IO链路和周边功能分离,并且有效防止故障扩散,在整个集群管控都不可用的情况下,IO请求还是可以正常工作。所以试着YY一下,下一代存储的技术选型会不会就长这样?即将复制阶段卸载到智能网卡,而将定序、转储的工作放在存储软件侧,从而实现极致高吞吐,极致低延迟,稳定高可靠?
随着时代的演进,软硬一体化技术还在快速迭代,我们非常期待并也积极参与了其中。“莫道桑榆晚,为霞尚满天”,我们相信共识协议能够搭上软硬一体化这列时代的高铁,继续在未来有状态分布式系统的构建中发挥着中流砥柱的作用!
四、尾声
写到最后,我们也不得不感慨,共识真的很重要,共识领域也真的是研究红海,但凡你能想到的方面都有一堆研究工作者在涉猎,这个恰恰也验证了共识协议对于分布式系统的至关重要性。写这篇文章,很大一部分目的也在于,告诉更多的分布式系统的从业者,共识领域的研究成果绝对不仅仅只有Paxos/Raft。事实上,随着业务的蓬勃发展,分布式领域的越来越丰富的场景都对共识协议提出了更多更新的要求,这里也绝非依靠Paxos/Raft就可以一招鲜吃遍天的。这个世界很大,大到足以容纳Paxos,Raft,EPaxos,FPaxos, Skyros,P4xos ......
图22. 希腊群岛被各种类型的共识协议拿来命名,有点不够用了 . . .
最后说一个有趣的现象,从早先年Leslie Lamport考古希腊群岛,并以其中的Paxos小岛命名初始的共识协议开始,这个小岛成为了共识领域的圣地,至今围绕着Paxos岛的很多希腊小岛也都被用来命名新的共识协议,譬如Corfu,Delos,Skyros,Hydra等等。所以,加油吧!希望共识领域保持着当前推陈出新的旺盛势头,尽早把希腊群岛的名字给用光了:)
作者|朱云峰
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载