亚马逊云科技大语言模型的创新科技
陈老老老板 ♂️本文专栏:生活(主要讲一下自己生活相关的内容)生活就像海洋,只有意志坚强的人,才能到达彼岸。
♂️本文简述:亚马逊云科技大语言模型的创新科技
♂️上一篇文章: 年度总结-你觉得什么叫生活?
有任何问题,都可以私聊我,在文章最后也可以加我的vx。感谢支持!
我认为人人都可以学好编程,我愿意成为你的领路人!

一.前言
近年来,人工智能领域取得了巨大的突破,其中,亚马逊云科技大语言模型是一项备受关注的创新技术。本文将探讨亚马逊云科技大语言模型的创新应用,大型语言模型(Large Language Models,或简写为 LLMs)。这是目前炙手可热的话题,采用机器学习新范式赋能业务的不断探索已经播种了几十年。但随着充足可伸缩算力的就位、海量数据的爆炸、以及机器学习技术的快速进步,各行各业的客户开始对业务进行重塑。最近,像 ChatGPT 这样的生成式 AI 应用引起了广泛的关注,引发了诸多想象。我们正处在一个令人激动的转折点上——机器学习被大规模采用,我们也相信生成式 AI 将会重塑大量客户体验和应用程序。
二.大型语言模型概述
大型语言模型指的是具有数十亿参数(B+)的预训练语言模型**(例如:GPT-3, Bloom, LLaMA)**。这种模型可以用于各种自然语言处理任务,如文本生成、机器翻译和自然语言理解等。
大型语言模型的这些参数是在大量文本数据上训练的。现有的大型语言模型主要采用 Transformer 模型架构,并且在很大程度上扩展了模型大小、预训练数据和总计算量。他们可以更好地理解自然语言,并根据给定的上下文(例如 prompt)生成高质量的文本。其中某些能力(例如上下文学习)是不可预测的,只有当模型大小超过某个水平时才能观察到。
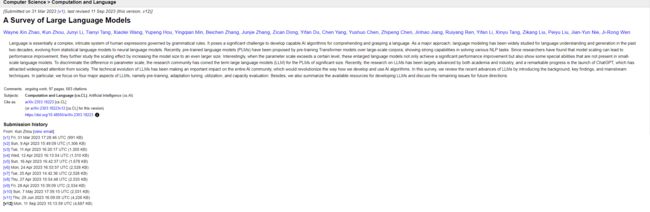
以下是 2019 年以来出现的各种大型语言模型(百亿参数以上)时间轴,其中标黄的大模型已开源。

3.大型语言模型的发展历史
我们首先来了解下大型语言模型的发展历史和最新研究方向分析。
大型语言模型 1.0。过去五年里,自从我们看到最初的Transformer模型 BERT、BLOOM、GPT、GPT-2、GPT-3 等的出现,这一代的大型语言模型在 PaLM、Chinchilla 和 LLaMA 中达到了顶峰。第一代 Transformers 的共同点是:它们都是在大型未加标签的文本语料库上进行预训练的。
大型语言模型 2.0。过去一年里,我们看到许多经过预训练的大型语言模型,正在根据标记的目标数据进行微调。第二代 Transformers 的共同点是:对目标数据的微调,使用带有人工反馈的强化学习(RLHF)或者更经典的监督式学习。第二代大型语言模型的热门例子包括:InstructGPT、ChatGPT、Alpaca 和 Bard 等。
大型语言模型 3.0。过去的几个月里,这个领域的热门主题是参数高效微调和对特定领域数据进行预训练,这是目前提高大型语言模型计算效率和数据效率的最新方法。另外,下一代大型语言模型可能以多模态和多任务学习为中心,这将为大型语言模型带来更多崭新并突破想象力的众多新功能。
4.大模型最新研究方向分析
4.1Amazon Titan
2023 年 4 月,亚马逊云科技宣布推出 Amazon Titan 模型。根据其以下官方网站和博客的信息(如下图所示):一些亚马逊云科技的客户已经预览了亚马逊全新的 Titan 基础模型。目前发布的 Amazon Titan 模型主要包括两个模型:
- 针对总结、文本生成、分类、开放式问答和信息提取等任务的生成式大语言模型;
- 文本嵌入(embeddings)大语言模型,能够将文本输入(字词、短语甚至是大篇幅文章)翻译成包含语义的数字表达(jiembeddings 嵌入编码)。

虽然这种大语言模型不生成文本,但对个性化推荐和搜索等应用程序却大有裨益,因为相对于匹配文字,对比编码可以帮助模型反馈更相关、更符合情境的结果。实际上,Amazon.com 的产品搜索能力就是采用了类似的文本嵌入模型,能够帮助客户更好地查找所需的商品。为了持续推动使用负责任AI的最佳实践,Titan 基础模型可以识别和删除客户提交给定制模型的数据中的有害内容,拒绝用户输入不当内容,过滤模型中包含不当内容的输出结果,如仇恨言论、脏话和语言暴力。
4.2Alpaca: LLM Training LLM
2023 年 3 月 Meta 的 LLaMA 模型发布,该模型对标 GPT-3。已经有许多项目建立在 LLaMA 模型的基础之上,其中一个著名的项目是 Stanford 的羊驼(Alpaca)模型。Alpaca 基于 LLaMA 模型,是有 70 亿参数指令微调的语言 Transformer。Alpaca 没有使用人工反馈的强化学习(RLHF),而是使用监督学习的方法,其使用了 52k 的指令-输出对(instruction-output pairs)。
Source: https://github.com/tatsu-lab/stanford_alpaca?trk=cndc-detail
研究人员没有使用人类生成的指令-输出对,而是通过查询基于 GPT-3 的 text-davinci-003 模型来检索数据。因此,Alpaca 本质上使用的是一种弱监督(weakly supervised)或以知识蒸馏(knowledge-distillation-flavored)为主的微调。

5.亚马逊云科技的AI创新应用
5.1Amazon CodeWhisperer
AWS 2023/4月已正式推出Amazon CodeWhisperer,是亚马逊的用几十亿行开源代码训练出来的 AI 工具,它可以根据你的代码注释和现有代码实时生成代码建议。其中CodeWhisperer个人套餐,所有开发人员均可免费使用。
Amazon CodeWhisperer目前支持多种语言(Python, Java, JavaScript, TypeScript, C#, Go, Rust, PHP, Ruby, Kotlin, C, C++, Shell scripting, SQL, and Scala);并同时支持多种IDE(JetBrains IDEs,Visual Studio (VS) Code,AWS Cloud9,AWS Lambda console)
目前市面上上有很多AI编程助手,比如GitHub Copilot,tabnine等,相比前面的一些AI编程助手,Amazon CodeWhisperer有哪些不同之处呢,具体有如下区别:
- Amazon CodeWhisperer对个人免费,而GitHub Copilot要收费,而tabnine免费版只提供较为基础的补全功能
- Amazon CodeWhisperer的模型训练不仅基于开源库比如GitHub,也加入了Amazon和AWS自己的代码库,用户在编写AWS SDK相关的API或者使用AWS服务的时候更加准确,更侧重于提高AWS开发体验;而Copilot使用GitHub开源代码库进行广域的训练,支持更普适的场景。
- Amazon CodeWhisperer在安全方面做了强化,能辅助定位代码安全的问题,帮助用户及时发现代码漏洞
- 提供当前代码建议的来源。可以让开发人员知道codewhisperer基于哪些可信的代码,这样开发人员写代码的时候能做进一步的参考和鉴别,避免AI一本正经的提供错误的建议的情况,这样我们的代码更加可靠可信。
5.2安装CodeWhisperer
在IDEA中打开配置窗⼝,选择Plugins,搜索AWS Toolkit,点击Install,点击OK按钮,如下图:

安装完之后重启IDEA
注意:如果搜不到该插件,请将IDEA升级⾄较新版本,亲测是IDEA 2022以上版本是可以安装的。


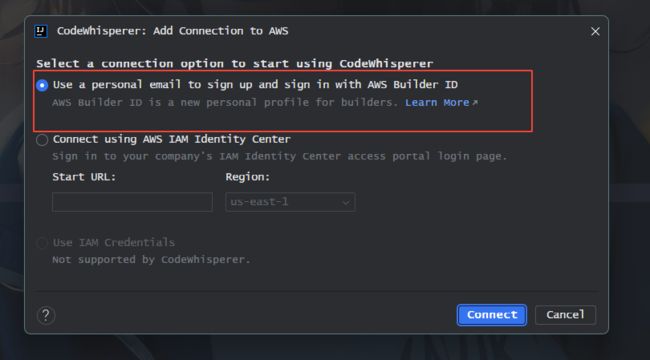
弹出的窗⼝中选择Use a personal email to sign up and sign in with AWS Builder ID,点击Connect按钮,如下图:
在弹出的窗⼝中,选择Open and Copy Code,如下图:

此时会在浏览器中打开⼀个⻚⾯,按ctrl-v粘贴code值,点击“Next“,如下图

输⼊邮箱地址,点击Next,如下图:

输⼊名字,点击“Next”,CodeWhisperer会向邮箱中发送⼀个验证码,如下图:
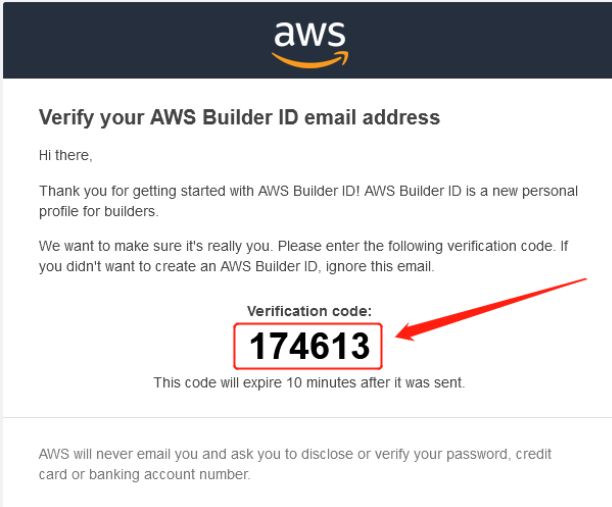
复制验证码,粘贴到输入框,点击Verify按钮,如下图:
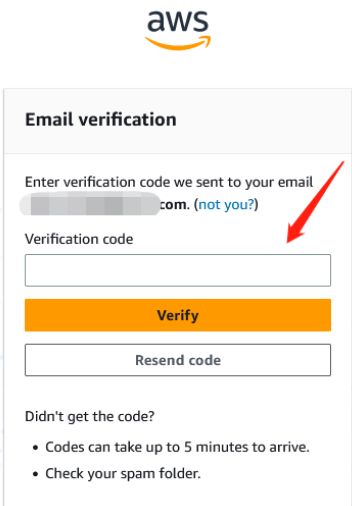
设置密码,点击Create AWS Builder ID,如下图:

出现如下提示后,即表示注册AWS builder ID成功,如下图

返回IDEA,在AWS Toolkit视图中的Developer Tools中可以打开或关闭代码⽣成功能,如下图:


点击tab键即可完成代码生成,如下图

我们运行代码,看下生成的代码是不是符合我们的预期:

可以看到,确实是通过冒泡排序进行打印。完美!
注释写的越精确,⽣成的代码质量越好。当然,CodeWhisperer⽣成的代码并不总是正确或最优,需要视情况进⾏修改或优化。
趁热打铁,我们再看一个案例,通过详细的注释,让他更明确的理解我们的需求:

我这里在D盘准备了一个2.mp4,通过运行代码,可以发现

成功的复制了我们的文件。
6.Amazon CodeWhisperer 实测体验总结
6.1 CodeWhisperer 可以帮助我成为一个更好的开发者吗?
通过以上测试,我觉得它可以帮助我成为一个更好的开发者。
首先,它可以为我节省大量的时间和精力,让我能够专注于改进、重构和测试。
其次,它通过承担一些同质化的繁重工作,让我有机会成为一个更好的程序开发人员。
比如上面的测试的例子是 Amazon 工具(经过 Amazon 开源代码训练)能够表现出色的例子。
当然,在大多数开发人员需要花费很多时间的地方,比如编写领域相关的逻辑时,我又多测试了一下,让我们看看 CodeWhisperer 会不会也有帮助。
比如从 Python 文档中的数据类示例开始。
@dataclass
class InventoryItem:
"""Class for keeping track of an item in inventory."""
name: str
unit_price: float
quantity_on_hand: int = 0
def total_cost(self) -> float:
return self.unit_price * self.quantity_on_hand
其实我想知道 CodeWhisperer 是否可以向这个类添加一个方法。让我们看看如果添加注释:" Function that return this item costs more than $10",会发生什么?
@dataclass
class InventoryItem:
"""Class for keeping track of an item in inventory."""
name: str
unit_price: float
quantity_on_hand: int = 0
def total_cost(self) -> float:
return self.unit_price * self.quantity_on_hand
# Function that returns whether this item costs more than $10
def expensive(self) -> bool:
return self.unit_price > 10
结果是非常酷的。值得注意的是,CodeWhisperer 给函数起了一个直观的名字,并包含了对 self 的引用。
接着,让我们尝试用 CodeWhisperer 来做测试,看是否会触及它的极限。
# Function to test InventoryItem class
def test_inventory_item():
"""
Test InventoryItem class
:return:
"""
item = InventoryItem("Widget", 10, 5)
assert item.name == "Widget"
assert item.unit_price == 10
assert item.quantity_on_hand == 5
assert item.total_cost() == 50
assert not item.expensive()
在上面的代码中,我输入了注释,CW 自动完成了剩下的工作。 测试似乎是一个极好的证明 CW 可以节省时间的例子。我不需要浪费时间去想测试的值,也不用输入所有的成员变量和方法。
总的来说,可以帮助我成为一个更好的开发者,但是任何辅助工具都有利有弊。
8.总结
亚马逊云科技大语言模型给各种领域带来了创新和广泛应用。在实际应用中,我们应根据需求和优势进行选择,并充分评估其性能、功能支持、扩展性以及社区支持和文档资料等因素。随着技术的不断进步和发展,这些技术将为我们带来更多创新和应用的可能性。