机器学习(八)经验风险与结构风险
1.11经验风险与结构风险
策略部分:

1.11.1 经验风险
模型f(x)关于训练数据集的平均损失称之为经验风险(emprical risk)或经验损失(empirical loss),记作R(emp)

期望风险R(emp)是模型关于联合分布的期望损失,经验风险R(emp)是模型关于训练样本集的平均损失。根据大数定律,当样本容量N趋于无穷时,经验风险R(emp)趋于期望风险R(exp),所以一个很自然的想法就是利用经验风险估计期望风险。但是,由于现实中训练样本数目有限甚至很小,所以用经验风险估计期望风险常常不理想,要对经验风险进行一定的矫正,这就是关系到监督学习的两个基本策略:经验风险最小化和结构风险最小化。
1.11.2 经验风险最小化
在损失函数以及训练数据集确定的情况下,经验风险函数式就可以确定,经验风险最小化(emprical risk minimization,EMR)的策略认为,经验风险最小的模型是最优模型。

当样本容量足够大的时候,经验风险最小化能保证有很好的学习效果,在现实中被广泛应用,比如,极大似然估计(maximum likelihood estimation)就是经验风险最小化的一个例子,当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。
1.11.3 结构风险
但是,当样本容量很小时,经验风险最小化的学习的效果就未必很好,会产生“过拟合”现象。
结构风险最小化(structural risk minimization,SMR)是为了防止过拟合而提出来的策略。结构风险在经验风险基础上加上表示模型复杂度的正则化项(regularizer)或罚项(penalty term)。在假设空间,损失函数以及训练数据集确定的情况下,结构风险的定义是:
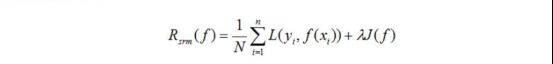
其中J(f)为模型的复杂度,是定义在假设空间F上的泛函,模型f越复杂。
1.11.4 结构风险最小化
复杂度J(f)就越大;反之,模型f就越简单,复杂度J(f)就越小,也就是说,复杂度表示对复杂模型的惩罚,lambda>=0是系数,是用以权衡经验风险和模型复杂度,结构风险小需要经验风险与模型复杂度同时小,结构风险小的模型往往对训练数据以及未知的测试数据都有较好的预测。

1.11.5模型评估和模型选择
当损失函数给定时,基于损失函数的模型的训练误差和模型的测试误差就自然成为了学习方法评估的标准。


1.12正则化
模型选择的典型方法是正则化,正则化一般形式如下:

经验风险较小的模型可能较复杂,这时正则化项的值会较大,正则化的作用是选择经验风险与模型复杂度同时较小的模型。
正则化项符合奥卡姆剃刀原理,在所有的可能的模型中,能够很好的解析已知数据并且十分简单的模型才是最好的模型,从贝叶斯估计的角度来看,正则化项对应于模型的先验概率,可以假设复杂的模型有较小的先验概率,简单的模型有较大的先验概率。
1.13交叉验证
在机器学习中常用的精度测试方法,叫做交叉验证。它的目的是得到可靠稳定的模型,具体的做法是拿出大部分数据进行建模,留小部分样本用刚刚建立的模型进行预测,并求出这小部分样本预测的误差,交叉验证在克服过拟合问题上非常有效。接下来分别阐述:
1.13.1简单交叉验证
简单交叉验证的方法是这样的,随机从最初的样本中选择部分,形成验证数据,而剩下的当作训练数据。一般来说,少于三分之一的数据被选作验证 数据。
1.13.2 K则交叉验证
10折交叉验证是把样本数据分成10份,轮流将其中9份做训练数据,
将剩下的1份当测试数据,10次结果的均值作为对算法精度的估计,通常情况下为了提高精度,还需要做多次10折交叉验证。
更进一步,还有K折交叉验证,10折交叉验证是它的特殊情况。K 折交叉验证就是把样本分为K份,其中K-1份用来做训练建立模型,留剩下的一份来验证,交叉验证重复K次,每个子样本验证一次。

1.13.3留一验证
留一验证只使用样本数据中的一项当作验证数据,而剩下的全作为训练数据,一直重复,直到所有的样本都作验证数据一次。可以看出留 一验证实际上就是K折交叉验证,只不过这里的K有点特殊,K为样本数 据个数。
后记
博客主页:https://manor.blog.csdn.net
欢迎点赞 收藏 ⭐留言 如有错误敬请指正!
本文由 Maynor 原创,首发于 CSDN博客
不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
专栏持续更新,欢迎订阅:https://blog.csdn.net/xianyu120/category_12468207.html