算法与数据结构模版(AcWing算法基础课笔记,持续更新中)
AcWing算法基础课笔记
文章目录
-
- AcWing算法基础课笔记
-
- 第一章 基础算法
-
- 1. 排序
-
- 快速排序:
- 归并排序:
- 2. 二分
-
- 整数二分
- 浮点数二分
- 3. 高精度
-
- 高精度加法
- 高精度减法
- 高精度乘法
- 高精度除法
- 4. 前缀和与差分
-
- 前缀和
- 矩阵前缀和
- 一维差分
- 二维差分
- 5. 双指针算法
- 6. 位运算
-
- n 的二进制表示中,第k位是几
- 求二进制中1的个数
- 7. 离散化
- 8. 区间合并
- 第二章 数据结构
-
- 1. 单链表
- 2. 双向链表
- 3. 栈
- 4. 队列
- 5. 单调栈
- 6. 单调队列
- 7. KMP算法
- 8. Trie
- 9. 并查集
- 10. 堆
- 11. 哈希
-
- 开放寻址法
- 拉链法
- 字符串哈希
- 12. STL (仅记录我不知道的)
-
- vector
- string
- queue 队列
- priority_queue 优先队列,默认是大根堆
- deque 双端队列
- set, map, multiset, multimap 基于平衡二叉树(红黑树),动态维护有序序列
- set/multiset
- map/multimap
- unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
- bitset 圧位,仅占1/8
- 第三章 搜索与图论
-
- 1. DFS
- 2. BFS
- 3. 树与图的存储
-
- 邻接矩阵
- 临界表
- 最短路径问题导图
- 4. Dijkstra
-
- 朴素Dijkstra(适合稠密图,无负权值)
- 堆优化的Dijkstra(适合稀疏图,无负权值)
- 5. bellman-ford(负权值,若规定k条边最短路径则只能用它,O(nm))
- 6. SPFA(bellman-ford优化,一般O(m),最坏O(nm))
- 7. Floyd
- 最小生成树与二分图导图
- 8. Prim
- 9. Kruskal
- 10. 染色法判别二分图
- 11. 匈牙利算法
- 第四章 数学知识
-
- 1. 质数
-
- 质数的判定-试除法(稳定 O(sqrt(n)) )
- 分解质因数-试除法( O(logn)-O() )
- 埃氏筛法 O(nloglogn)
- 线性筛法 O(n)
- 2. 约数
-
- 试除法求一个数的所有约数
- 约数的个数
- 约数之和
- 欧几里得算法(辗转相除法,求最大公约数)
- 3. 欧拉函数
- 4. 快速幂
- 5. 扩展欧几里得算法
- 补充
-
- cin、cout与scanf、printf
第一章 基础算法
包括排序、二分、高精度、前缀和与差分、双指针算法、位运算、离散化、区间合并
1. 排序
快速排序:
思路:基于分治思想
- 确定分界点(取左边界,去中间点,随机取)
- 调整区间,分
x两部分分别是[l, j]、[j+1, r] - 递归左右
void quick_sort(vector<int>&q, int l, int r)
{
if (l >= r) return; //注意这里是>=
int i = l - 1, j = r + 1, x = q[l + r >> 1];
while (i < j)
{
while (q[++i] < x); //注意这里无论结果如何i都会+1,故初始化时i=l-1,且才能跳出循环
while (q[--j] > x);
if (i < j) swap(q[i], q[j]);
}
quick_sort(q, l, j), quick_sort(q, j + 1, r);
}
归并排序:
思路:基于分治思想
- 确定分界点: 中间点 mid=l+r>>1
- 递归分界点左右
- 归并
void merge_sort(int q[], int l, int r)
{
if (l >= r) return; //return边界
int mid = l + r >> 1;
merge_sort(q, l, mid); //排序左半
merge_sort(q, mid + 1, r); //排序右半
int k = 0, i = l, j = mid + 1; //将i,j分别指向两数组第一个元素
while (i <= mid && j <= r) //若两数组都没结束,选小的进
if (q[i] <= q[j]) tmp[k ++ ] = q[i ++ ];
else tmp[k ++ ] = q[j ++ ];
while (i <= mid) tmp[k ++ ] = q[i ++ ]; //一数组结束,另外一数组剩下元素依次进
while (j <= r) tmp[k ++ ] = q[j ++ ];
for (i = l, j = 0; i <= r; i ++, j ++ ) q[i] = tmp[j];
}
2. 二分
本质:可以划分为满足某种性质与不满足某种性质的两个区间,用二分法可以找到两区间边界的左右两个点。
整数二分
int bsearch_1(int l, int r) //寻找右边界
{
while (l < r)
{
int mid = l + r + 1 >> 1; //右边界需+1
if (q[mid]>k) r = mid-1; //mid不满足<=,直接将右边界置mid左边
else l = mid; //左边界一点点贴近右边界
}
return l;
}
int bsearch_2(int l, int r) //寻找左边界,同理
{
while (l < r)
{
int mid = l + r >> 1;
if (q[mid]<k) l = mid+1;
else r = mid;
}
return l;
}
浮点数二分
void bsearch_3(double l, double r) //所有可能的范围如[-10000,10000]
{
const double eps = 1e-8; //要求精度多两位
while (abs(r - l) > eps)
{
double mid = (l + r) / 2;
if (n-pow(mid,3)<eps) r = mid; //两者不断接近
else l = mid;
}
printf("%lf",r);
}
3. 高精度
高精度加法
void add(vector<int>&a,vector<int>&b){
if(a.size()<b.size()) return add(b,a); //确保a>b,由于都是正整数,所以可以这么操作
int c=0;
for(int i=0;i<a.size();i++){
a[i]+=c; //a+b+c(进位符)
if(i<b.size()) a[i]+=b[i]; //注意a还有,b没了
c=a[i]/10;
a[i]%=10;
}
if(c) a.push_back(1); //注意最后一位进位
for(int i=a.size()-1;i>=0;i--) printf("%d",a[i]);
}
高精度减法
void sub(vector<int>&a,vector<int>&b){
int c=0;
for(int i=0;i<a.size();i++){ //同理变成减
a[i]-=c;
if(i<b.size()) a[i]-=b[i];
if(a[i]<0) c=1;
else c=0;
a[i]=(a[i]+10)%10;
}
while(a.size()!=1&&a[a.size()-1]==0) a.pop_back(); //注意是while不是if,如果高位为0要一直减
for(int i=a.size()-1;i>=0;i--) printf("%d",a[i]);
}
高精度乘法
乘法与加法类似,但由长整数乘以短整数,故不是一位乘一位,是以长整数的一位乘整个短整数。
void mult(vector<int>&a,int b){
int c=0;
for(int i=0;i<a.size();i++){
a[i]=b*a[i]; //同理,注意先乘后加
a[i]+=c;
c=a[i]/10;
a[i]%=10;
}
while(c!=0){ //若用新数组保存值每次push_back,for循环条件可以为a.size()||c,减少这个while语句
a.push_back(c%10);
c/=10;
}
while(a.size()!=1&&a.back()==0) a.pop_back();
for(int i=a.size()-1;i>=0;i--) printf("%d",a[i]);
}
高精度除法
模拟除法,从高位开始,(余数*10+高位)除以除数得商的高位,%除数得新的余数,循环。
void div(vector<int>&a,int b){
int t=0;
vector<int> c;
for(int i=0;i<a.size();i++){
t=t*10+a[i];
if(c.size()!=0||t/b!=0) c.push_back(t/b); //用if去除高位的0,可以用reverse函数倒置去0同理
t%=b;
}
if(c.size()==0) c.push_back(0);
for(int i=0;i<c.size();i++) printf("%d",c[i]);
}
4. 前缀和与差分
前缀和
前缀和定义:S[i] = a[1] + a[2] + … a[I]
求区间(注意后者边界l-1):a[l] + … + a[r] = S[r] - S[l - 1]
补充:S0=0,消除[1,r]时的特殊处理
矩阵前缀和
同理,注意矩阵从a11开始,注意容斥问题
以(x1, y1)为左上角,(x2, y2)为右下角的子矩阵的和为:
S[x2, y2] - S[x1 - 1, y2] - S[x2, y1 - 1] + S[x1 - 1, y1 - 1]
一维差分
题目要求在某区间加一个值val
构造一个差分数组b1, b2, b3 … bn
它的前缀和数组a1, a2, a3 … an(该数组为最后答案要求数组)
原理:若在a数组的区间[l, r]上依次加val,时间复杂度on;若在b数组上bl + val、br+1 - val,最后求它的前缀和数组a得到相同结果,时间复杂度o1
思路:虽然题目初始化的数组有值,但我们仍初始化一个全0的差分数组b,在[l, l]同一位置上依次插入初始值,然后按题目要求在[l,r]上插入即可;
注意同样a0、b0都为0,插入代码:
void insert(int l,int r,int val){ //由于最后结果是前缀和数组,在差分数组l上加val,使得[l, + ∞)上都加val,在r+1上减val得到仅在区间[l,r]上加val
q[l]+=val;
q[r+1]-=val;
}
二维差分
同理,插入代码如下:
void insert(int x1,int y1,int x2,int y2,int v){ //注意容斥问题、矩阵从a11开始、矩阵初始化大小行列都得+2
q[x1][y1]+=v;
q[x1][y2+1]-=v;
q[x2+1][y1]-=v;
q[x2+1][y2+1]+=v;
}
5. 双指针算法
问题分类:
- 对于一个序列,用两个指针维护一段区间;
- 对于两个序列,维护某种次序,比如归并排序中合并两个有序序列的操作;
for (int i = 0, j = 0; i < n; i ++ )
{
while (j < i && check(i, j)) j ++ ; //寻找i,j的单调关系
// 具体问题的逻辑
}
6. 位运算
n 的二进制表示中,第k位是几
- 先把第k位移到最后一位:n >> k
- 看个位是几:x & 1
即:n >> k & 1
求二进制中1的个数
lowbit(x):返回x的最后一个1,即101000得1000;
原理:x&-x = x&(~x+1)
int lowbit(int x){
return x & -x;
}
7. 离散化
场景:目标数据稀疏的分散在大数组空间中,大部分元素为0
题目:给下标范围[-1e-9,1e-9]的数组存入几个数,求某段范围所有值的和
思路(将大下标范围的数组映射到一个小的数组中,然后具体按题目要求操作):
- 首先取操作涉及的下标,即将要存数字的下标与求和范围两端的下标,存入小数组q中
- 对数组q排序,且去重,c++代码如下
- 重新创建一个大小与q相同的数组s,从数组q中找到对应大数组要存入数据的位置映射,在s相同位置存入数据(q中找映射可以用二分法)
- 找大数组求和范围两端点在q中的映射位置,在数组s对应映射位置求和即可,可用前缀和;
sort(q.begin(), q.end()); // 对数组q排序
q.erase(unique(q.begin(), q.end()), q.end()); // 去掉重复元素
补充:题目比较综合,贴一个代码链接:
https://www.acwing.com/activity/content/code/content/3230155/
8. 区间合并
场景:离散的区间,合并相交的区间
步骤:
- 按区间的左端点排序;
- 从左到右扫描,维护一个当前区间(随着遍历,若相交则区间变长)
- 每次遍历的区间和当前区间有三种情况分类讨论:
(1)右端点小于当前区间右端点,当前区间不变;
(2)右端点大于当前区间右端点,当前区间变长;
(3)左端点大于当前区间右端点,将该区间置为当前区间;
第二章 数据结构
1. 单链表
数组模拟单链表
int v[N],l[N],idx; //初始化,分别为值、下一结点坐标、下一结点下标
void init(){
l[0]=-1;
idx=1;
}
void insert(int k,int x){ //去head,直接idx=0存头指针,使k无需-1,且消除头结点的特殊操作
v[idx]=x;
l[idx]=l[k];
l[k]=idx++;
}
void delete_v(int k){
l[k]=l[l[k]];
}
2. 双向链表
数组模拟双向链表
int v[N],l[N],r[N],idx; //同理
void init(){
l[0]=-1,r[0]=1,l[1]=0,r[1]=-1; //用最开始两个结点做头尾指针
idx=2;
}
void insertL(int k,int x){ //注意这里的三个函数,由于占用了数组前两个元素,题目给的k值需要+1
v[idx]=x;
l[idx]=l[k];
r[idx]=k;
r[l[k]]=idx;
l[k]=idx++;
}
void insertR(int k,int x){
v[idx]=x;
r[idx]=r[k];
l[idx]=k;
l[r[k]]=idx;
r[k]=idx++;
}
void delete_v(int k){
r[l[k]]=r[k];
l[r[k]]=l[k];
}
3. 栈
数组模拟过于简单,补充模拟栈处理中缀表达式:
main函数思路:
- 如果栈顶是+,即将入栈的是+,栈顶优先级高,需要先计算,再入栈;
- 如果栈顶是+,即将入栈的是*,栈顶优先级低,直接入栈;
- 如果栈顶是*,即将入栈的是+,栈顶优先级高,需要先计算,再入栈;
- 如果栈顶是*,即将入栈的是*,栈顶优先级高,需要先计算,再入栈;
#include 4. 队列
循环队列注意点:队满与队空条件需要有区别,即需要一个额外的元素空间判断队空与队满
void push_q(int x){
if((tail+N+1)%N!=head){ //判断队满
q[tail]=x;
tail=(N+tail+1)%N; //队尾插入一个数据注意指针移动需要%N,对头类似:head=(N+head+1)%N;
}
}
bool empty(){ //判断是否为空
return head==tail;
}
void pop_q(){ //对头删去一个元素
if(!empty())
head=(N+head+1)%N;
}
void query(){ //查询对头元素
if(!empty())
printf("%d\n",q[head]);
}
5. 单调栈
应用场景:求某个数左边第一个小于他的数;
思路:
在每次暴力从for循环的当前值,向左遍历找第一个小于数的O(n2)情况下进行优化;
在向左遍历过程中删去无用的数(左边小于,但值大于),利用栈形成单调增大的序列,所求数即为栈顶;
for(int i=0;i<n;i++){
scanf("%d",&v);
while(top&&s[top-1]>=v) top--; //去除比当前数大但在左边的数
if(!top) printf("-1 ");
else printf("%d ",s[top-1]); //输出栈顶元素,即第一个小于当前数的数
s[top++]=v; //当前数压入栈中
}
6. 单调队列
应用场景:滑动窗口中最小值,也可优化背包问题;
思路:同理通过删去无用的数进行优化;
(求滑动窗口中最小值)队列头保留最小的数,遍历数组,若队尾数大于遍历的数则不断删去队尾(同理无用的数),使得队列单调增,在遍历过程中,不断更新队头使得不超过滑动窗口。
for(int i=0;i<n;i++){
if(l<r&&i-q[l]>len-1) l++; //移动对头使不超过滑动窗口,为了实现,q数组存下标
while(l<r&&v[q[r-1]]>=v[i]) r--; //弹出队尾无用数,因为会在队尾弹出不满足先进先出原则,事实上也不能叫单调队列
q[r++]=i; //每次都入队一个
if(i>=len-1) printf("%d ",v[q[l]]);
}
7. KMP算法
应用场景:字符串匹配,使时间复杂度为O(n)
思路:利用next数组减少模式串回退的长度。
cin >> n >> p+1 >> m >> s+1;// char数组s是长文本,p是模式串,且从数组下标1开始存储
for(int i=2,j=0;i<=n;i++){ //求next数组
while(j&&p[i]!=p[j+1]) j=ne[j];
if(p[i]==p[j+1]) j++;
ne[i]=j;
}
for(int i=1,j=0;i<=m;i++){ //匹配
while(j&&s[i]!=p[j+1]) j=ne[j];
if(s[i]==p[j+1]) j++;
if(j==n){
j=ne[j];
//匹配成功
}
}
8. Trie
应用:高效地存储和查找字符串集合的数据结构、前缀树相关应用
int son[N][26], cnt[N], idx;
// 0号点既是根节点,又是空节点
// son[][]存储树中每个节点的子节点
// cnt[]存储以每个节点结尾的单词数量
// idx标记每个节点位置,每插入一个结点+1
// 插入一个字符串
void insert(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) son[p][u] = ++ idx;
p = son[p][u];
}
cnt[p] ++ ;
}
// 查询字符串出现的次数
int query(char *str)
{
int p = 0;
for (int i = 0; str[i]; i ++ )
{
int u = str[i] - 'a';
if (!son[p][u]) return 0;
p = son[p][u];
}
return cnt[p];
}
9. 并查集
很容易考察:代码短,思路精巧
原理:每个集合用一棵树表示。树根的编号就是整个集合的编号。每个节点存储它的父节点,p[x]表示x的父节点。
血的教训!!!
注意很多题目需要在合并时去最小值,若f数组存父亲值
f[y]=min(f[x],f[y]),f[x]=min(f[x],f[y]);
每次执行find操作,确实会让每个节点直接存根节点的值,之后查找的时间复杂度接近O(1),但仅仅是接近,不一定全是1次找到,即之后查找要用find函数而不是直接f[]找。
//经典find函数
int find(int x)
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
//维护到祖宗节点距离的并查集(题目:食物链)
int find(int x)
{
if (p[x] != x)
{
int u = find(p[x]); //直接一路递归到根节点
d[x] += d[p[x]]; //从根节点回来,加上一路的距离
p[x] = u;
}
return p[x]; //由于d[x]直接保存了到根节点的总长度,故查询完后需要将x直接连在根节点下(直接连在根节点,即路径压缩)
}
10. 堆
- 建堆:for(int i=size/2;i>0;i–) down(i); //注意从heap[1]开始存
- 插入一个数:heap[++size] = x; up(size);
- 删除最小值:heap[1] = heap[size–]; down(1);
- 删除任意一个元素:heap[k] = heap[size–]; down(k); up(k);
- 修改任意一个元素:heap[k]=x; down(k); up(k);
//注意一个个插入,仅保证堆顶为最小值,其他元素没有严格按照堆的标准,故down和up操作不是if…else的关系;
void down(int u)
{
int t = u;
if (u * 2 <= size && h[u * 2] < h[t]) t = u * 2;
if (u * 2 + 1 <= size && h[u * 2 + 1] < h[t]) t = u * 2 + 1; //同样操作,先根左,后根右,注意第二次用的是h[t];
if (u != t)
{
swap(u, t);
down(t);
}
}
void up(int u)
{
while (u / 2 && h[u] < h[u / 2])
{
swap(u, u / 2);
u >>= 1;
}
}
11. 哈希
开放寻址法
N一般取数据范围的2-3倍,大概率无冲突
int h[N];
// 如果x在哈希表中,返回x的下标;如果x不在哈希表中,返回x应该插入的位置
int find(int x)
{
int t = (x % N + N) % N;
while (h[t] != INT_MAX && h[t] != x) //INT_MAX在头文件limits.h中
{
t ++ ;
if (t == N) t = 0;
}
return t;
}
拉链法
N取大于空间的第一个质数
int h[N], e[N], ne[N], idx; //类似图论中的临界表存储
// 向哈希表中插入一个数
void insert(int x)
{
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx ++ ;
}
// 在哈希表中查询某个数是否存在
bool find(int x)
{
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i])
if (e[i] == x)
return true;
return false;
}
字符串哈希
将字符串看成P进制数,P的经验值是131或13331,取这两个值的冲突概率低
取模的数用2^64,这样直接用unsigned long long存储,溢出的结果就是取模的结果
// 初始化
p[0] = 1;
for (int i = 1; i <= n; i ++ )
{
h[i] = h[i - 1] * P + str[i]; //存前缀哈希值
p[i] = p[i - 1] * P; //存P的x次方
}
// 计算子串 str[l ~ r] 的哈希值
long long get(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
12. STL (仅记录我不知道的)
vector
支持比较运算,按字典序
front() / back()
push_back() / pop_back()
string
c_str() 返回字符串所在字符数组的起始地址
queue 队列
front() 返回队头元素
back() 返回队尾元素
priority_queue 优先队列,默认是大根堆
定义成小根堆的方式:priority_queue
deque 双端队列
front()/back()
push_back()/pop_back()
push_front()/pop_front()
begin()/end()
[]
set, map, multiset, multimap 基于平衡二叉树(红黑树),动态维护有序序列
++, – 返回前驱和后继,时间复杂度 O(logn)
set/multiset
insert() 插入一个数
find() 查找一个数
count() 返回某一个数的个数
erase()
(1) 输入是一个数x,删除所有x O(k + logn)
(2) 输入一个迭代器,删除这个迭代器
lower_bound()/upper_bound()
lower_bound(x) 返回大于等于x的最小的数的迭代器
upper_bound(x) 返回大于x的最小的数的迭代器
map/multimap
insert() 插入的数是一个pair
erase() 输入的参数是pair或者迭代器
find()
[] 注意multimap不支持此操作。 时间复杂度是 O(logn)
lower_bound()/upper_bound()
unordered_set, unordered_map, unordered_multiset, unordered_multimap, 哈希表
和上面类似,增删改查的时间复杂度是 O(1)
不支持 lower_bound()/upper_bound(), 迭代器的++,–
bitset 圧位,仅占1/8
bitset<10000> s;
~, &, |, ^
>>, <<
==, !=
[]
count() 返回有多少个1
any() 判断是否至少有一个1
none() 判断是否全为0
set() 把所有位置成1
set(k, v) 将第k位变成v
reset() 把所有位变成0
flip() 等价于~
flip(k) 把第k位取反
第三章 搜索与图论
1. DFS
思路:本质上用dfs去枚举,在此基础上剪枝,以皇后问题为例:
void dfs(int l,int x,int y){
if(y==n){ //让x,y坐标走下去
y=0;
x++;
}
if(x==n){ //递归边界,结束跳出递归
if(l==n){
for(int i=0;i<n;i++) puts(c[i]);
printf("\n");
}
return;
}
if(!col[y]&&!row[x]&&!m[x-y+n]&&!p[x+y]){ //用条件剪枝
col[y]=row[x]=m[x-y+n]=p[x+y]=1;
c[x][y]='Q';
dfs(l+1,x,y+1);
col[y]=row[x]=m[x-y+n]=p[x+y]=0; //注意恢复现场,重要!!
c[x][y]='.';
}
dfs(l,x,y+1);
}
2. BFS
应用场景:求最短路径(要求每步权重相等),模版如下:
st[1] = true; // 表示1号点已经被遍历过
q.push(1);
while (q.size())
{
int t = q.front();
q.pop();
for (int i = h[t]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true; // 表示点j已经被遍历过
q.push(j);
}
}
}
3. 树与图的存储
注意初始化与有重边取小问题,如果有负权边判定条件由=INF为>INF/2。
邻接矩阵
g[a][b]存储边a->b
临界表
// 对于每个点k,开一个单链表,存储k所有可以走到的点。h[k]存储这个单链表的头结点
int h[N], e[N], ne[N], idx;
// 添加一条边a->b
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx ++ ;
}
// 初始化
idx = 0;
memset(h, -1, sizeof h); //在头文件cstring中
最短路径问题导图
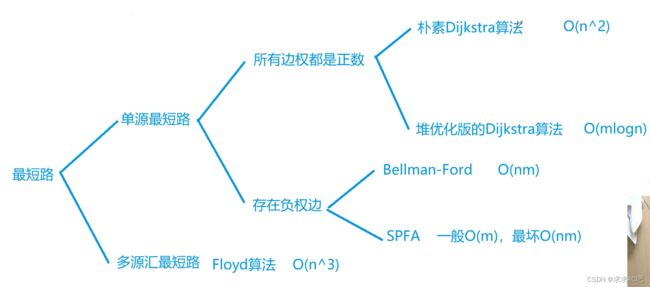
4. Dijkstra
朴素Dijkstra(适合稠密图,无负权值)
思路:
- 初始化(初始化dist,邻接矩阵)
- 循环n-1次,每次找最短dist[t],用t更新其它点的距离
//初始化
memset(g,0x3f,sizeof g);
memset(dist,0x3f,sizeof dist);
g[a][b]=min(c,g[a][b]); //如果有重边,需要选小的
//Dijkstra
bool dijkstra(){
dist[1]=0;
for(int i=0;i<n-1;i++){
int t=-1;
//找最小的dist
for(int j=1;j<=n;j++){
if((t==-1||dist[j]<dist[t])&&!b[j]){
t=j;
}
}
//更新已访问的点
b[t]=1;
//更新该点其它距离
for(int j=1;j<=n;j++)
dist[j]=min(g[t][j]+dist[t],dist[j]);
}
if(dist[n]==0x3f3f3f3f) return 0;
else return 1;
}
堆优化的Dijkstra(适合稀疏图,无负权值)
思路:
在朴素Dijkstra算法的基础上
- 初始化(初始化dist,邻接矩阵)
- 循环n-1次,每次找最短dist[t],用t更新其它点的距离
其中找最短dist[t]需要O(n2),故利用一个堆把该步骤降为O(n)
随之用堆更新的时间复杂度上升为O(mlogn),故适合于稀疏图
int dijkstra(){
priority_queue<pair<int,int>,vector<pair<int,int>>,greater<pair<int,int>>> q;
dist[1]=0;
q.push({0,1});
while(q.size()){
pair<int,int> temp=q.top();
q.pop();
if(st[temp.second]) continue; //若已访问直接跳过,若在下方if语句中判断时间差很多
st[temp.second]=1;
//更新操作
for(int i=h[temp.second];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>temp.first+w[i]){
dist[j]=temp.first+w[i];
q.push({dist[j],j});
}
}
}
if(dist[n]!=0x3f3f3f3f) return dist[n];
else return -1;
}
5. bellman-ford(负权值,若规定k条边最短路径则只能用它,O(nm))
思路:(很暴力,边的存储仅需要用结构体数组即可)
for n 次
用back数组备份dist,防止串联(访问前几条边改变数据后影响后面的访问,会破坏k条边的条件)
for 所有边 a,b,w
dist[b] = min(dist[b], back[a]+w); //松弛操作
三角不等式:dist[b] <= dist[a]+w
补充:如果执行n次依然更新了路径,说明有n条的最短路径,即有负权边
struct line{ //定义结构体
int a,b,w;
}lines[N];
void bellman_ford(){
dist[1]=0;
for(int i=0;i<k;i++){
memcpy(back,dist,sizeof dist); //备份防止串联
for(int j=0;j<m;j++){
if(dist[lines[j].b]>back[lines[j].a]+lines[j].w){//这里用back
dist[lines[j].b]=back[lines[j].a]+lines[j].w;
}
}
}
if(dist[n]>0x3f3f3f3f/2) printf("impossible");
else printf("%d",dist[n]);
}
6. SPFA(bellman-ford优化,一般O(m),最坏O(nm))
思路:在bellman-ford的基础上,利用一个队列与广度优先搜索,仅将变小的点加入队列中;
补充:
用一个cnt[]数组维护每个节点的最短路径边数,若边数=n即有负权边。需要考虑图不连通,故需要初始化时把所有点加入队列,且dist都相等即可。
void spfa(){
q.push(1);
dist[1]=0;
st[1]=1;
while(q.size()){
int t=q.front();
q.pop();
st[t]=0; //SPFA与Dijkstra不同仅在于标记数组用于标记是否重复进去队列而非是否访问过
for(int i=h[t];i!=-1;i=ne[i]){
int j=e[i];
if(dist[j]>dist[t]+w[i]){
dist[j]=dist[t]+w[i];
if(!st[j]){ //改变后进行判断是否需要加入队列
st[j]=1;
q.push(j);
}
}
}
}
if(dist[n]==0x3f3f3f3f) printf("impossible");
else printf("%d",dist[n]);
}
7. Floyd
思路:三重循环,用邻接矩阵存储
外层循环每个要加入的点,双层循环两个要加入的节点,如果可加入其中且路径边短则更新即可。
初始化:
for (int i = 1; i <= n; i ++ )
for (int j = 1; j <= n; j ++ )
if (i == j) d[i][j] = 0;
else d[i][j] = INF;
// 算法结束后,d[a][b]表示a到b的最短距离
void floyd()
{
for (int k = 1; k <= n; k ++ ) //每次要加入的点
for (int i = 1; i <= n; i ++ ) //加入点i,j中
for (int j = 1; j <= n; j ++ )
d[i][j] = min(d[i][j], d[i][k] + d[k][j]);
}
最小生成树与二分图导图
朴素Prim算法用于稠密图,优化版Prim和Kruskal算法侧重于稀疏图,由于堆优化代码长,故一般直接用Kruskal算法。
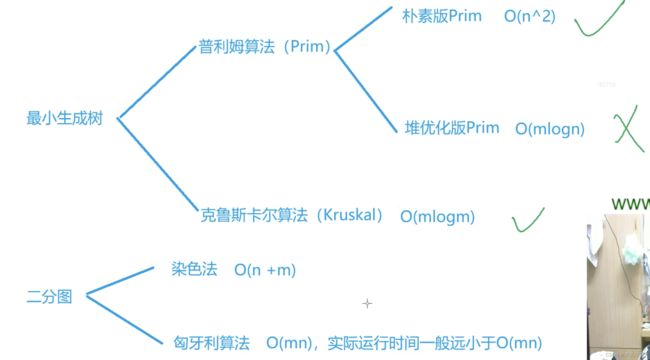
8. Prim
思路:几乎和dijkstra一样,区别在标记数组记录的是进入生成树的节点,dist数组记录的是各节点到生成树的最短路径;
void prim(){
dist[1]=0;
for(int i=0;i<n;i++){
int t=-1;
for(int j=1;j<=n;j++){
if(!st[j]&&(t==-1||dist[t]>dist[j])){
t=j;
}
}
st[t]=1;
res+=dist[t];
for(int j=1;j<=n;j++){
if(dist[j]>g[t][j]){
dist[j]=g[t][j];
}
}
}
}
9. Kruskal
思路:用结构体存边,并排序,从最短的边找起,若两点不在一颗树则连接在一起(并查集思想),直到所有点都用最短的边连在一起。
sort(lines,lines+m); //边排序
for(int i=0;i<m;i++){
int a=find(lines[i].a),b=find(lines[i].b);
if(a!=b){
h[b]=a; //若不是一棵树操作
res+=lines[i].c;
cnt++;
}
}
10. 染色法判别二分图
二分图:
- 当且仅当图中不含有奇数环;
- 图中所有点可以划分为两个区域,所有的边在两个区域之间。
思路:利用深度优先便利,相邻节点染上不同颜色,若无冲突则为二分图。
bool dfs(int x,int c){
st[x]=c; //所有深度优先做什么都放在最前面,判断中则会有多余的遍历
for(int i=h[x];i!=-1;i=ne[i]){
int j=e[i];
if(!st[j]){
if(!dfs(j,3-c)) return false;
}else if(st[j]==c) return false;
}
return true;
}
11. 匈牙利算法
二分图最大匹配问题:分两堆且给出部分边后,尽可能使左右一对一匹配。
//主函数
for(int i=1;i<=n1;i++){
memset(st,0,sizeof st);
if(find(i)) res++;
}
//找右半堆
bool find(int x){
for(int i=h[x];i!=-1;i=ne[i]){
int j=e[i];
if(!st[j]){
st[j]=1; //注意标记置1
if(!match[j]||find(match[j])){ //如果已经匹配,递归看看拆散一对会不会更好
match[j]=x;
return true;
}
}
}
return false;
}
第四章 数学知识
1. 质数
质数的判定-试除法(稳定 O(sqrt(n)) )
bool is_prime(int x){
if(x<2) return false; //记得判断<2都不是质数
for(int i=2;i<=x/i;i++) //注意有=号
if(x%i==0)
return false;
return true;
}
分解质因数-试除法( O(logn)-O() )
void divide(int x){
for(int i=2;i<=x/i;i++){
int s=0;
while(x%i==0){ //for里面加个while计数即可
x/=i;
s++;
}
if(s!=0) printf("%d %d\n",i,s);
}
if(x!=1) printf("%d %d\n",x,1);
}
埃氏筛法 O(nloglogn)
void get_primes(int n){
for(int i=2;i<=n;i++){
if(!p[i]){ //若是素数,将它所有倍数的标记置1
res++;
for(int j=i;j<=n;j+=i) p[j]=1;
}
}
}
线性筛法 O(n)
思路:
不同于埃氏筛法,把质数的所有倍数标记置1,该算法将会有很多重复的置1操作(质数的公倍数多次被置1)
线性筛法将以后素数存入数组,实现仅更新当前素数的部分倍数,实现每个数仅被置一次,从而实现线性的时间复杂度。
void get_primes(int n){
for(int i=2;i<=n;i++){
if(!p[i]) prime[res++]=i; //若为素数,加入数组
for(int j=0;prime[j]<=n/i;j++){ //prime[j]
p[prime[j]*i]=true;
if(i%prime[j]==0) break; //如果该数为已有素数的公倍数就break,两个跳出条件缺一不可
}
}
}
2. 约数
试除法求一个数的所有约数
约数数量未知,故用vector来存储
void get_dividors(int x){
vector<int> v;
for(int i=1;i<=x/i;i++){
if(x%i==0){
v.push_back(i);
if(i!=x/i) v.push_back(x/i); //防止相同的数进入
}
}
sort(v.begin(),v.end());
for(int i=0;i<v.size();i++)
printf("%d ",v[i]);
}
约数的个数
N=P1^α1 * P2^α2 * … * Pk^αk
约数个数公式:(α1+1)(α2+1)…(αk+1)
//用unordered_map求约数,约数个数和约数之和一样
void get_dividor(int x){
for(int i=2;i<=x/i;i++){
while(x%i==0){
x/=i;
m[i]++;
}
}
if(x>1) m[x]++;
}
//按公式相乘取余
for(auto it=m.begin();it!=m.end();it++){
res=res*(it->second+1)%N;
}
约数之和
N=P1^α1 * P2^α2 * … * Pk^αk
约数之和公式:(P1^0 + P1^1 + P1^α1) … (Pk^0 + Pk^1 + Pk^α1)
//按公式相乘取余
long long get_p(int a,int b){
long long r=1;
for(int i=0;i<b;i++){
r=(r*a+1)%N;
}
return r;
}
for(auto it=m.begin();it!=m.end();it++){
res=res*get_p(it->first,it->second)%N;
}
欧几里得算法(辗转相除法,求最大公约数)
(a, b)的最大公约数=(b, a mod b)的最大公约数
//有点难理解,但一行直接背
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
3. 欧拉函数
4. 快速幂
5. 扩展欧几里得算法
补充
cin、cout与scanf、printf
用cin.tie(0);和ios::sync_with_stdio(false);加快cin、cout输入输出,但不能再使用scanf与printf且依然慢;
原理是让cin、cout与标准数输入输出不同步;